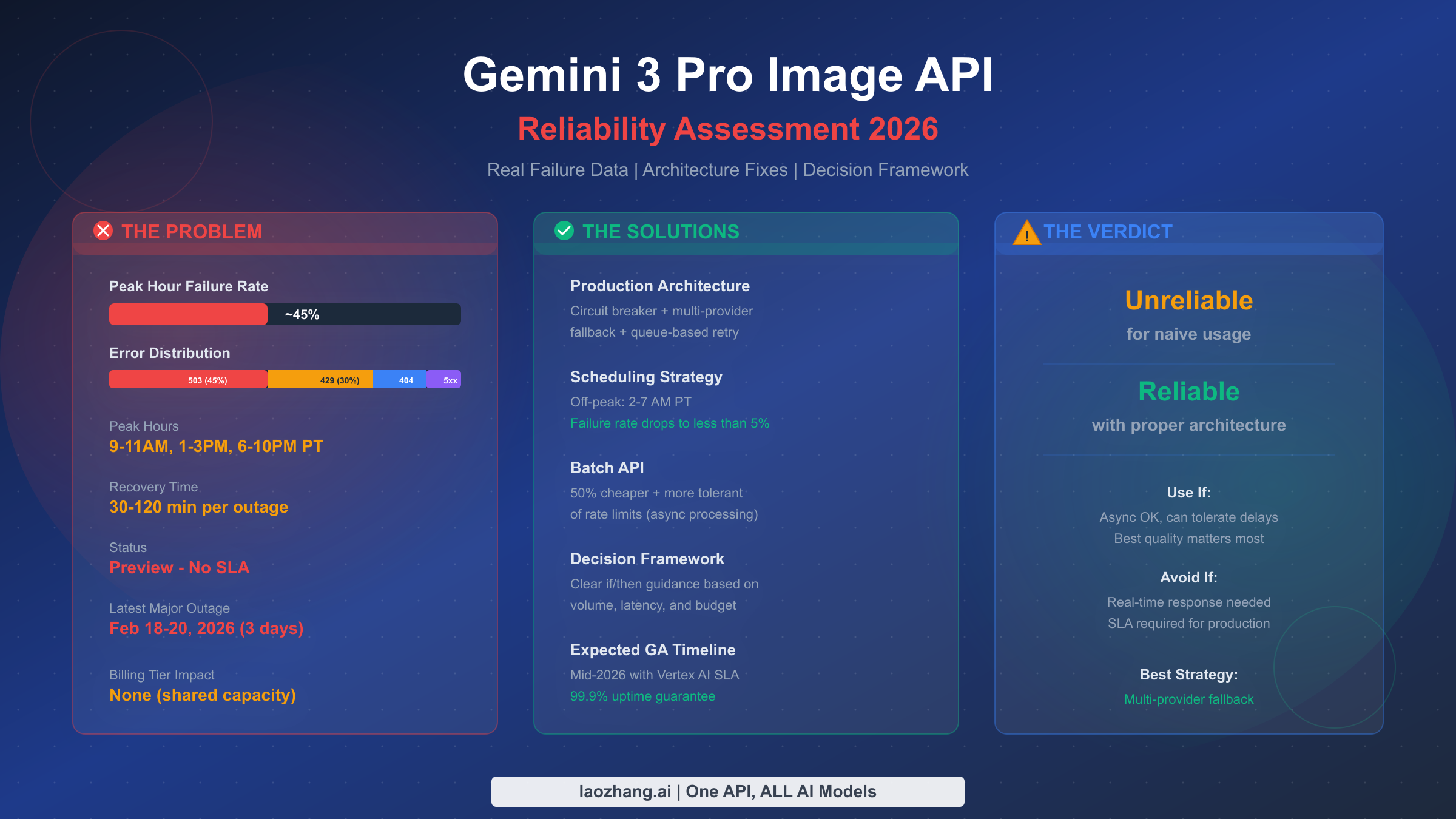
Gemini 3 Pro Image API (internally known as "Nano Banana Pro") delivers some of the best AI-generated images available today, but its reliability has become a serious concern for production applications. Based on community data spanning December 2025 through February 2026, peak hour failure rates consistently hover around 45%, with 503 "model is overloaded" errors accounting for nearly half of all failures. The API currently operates in Preview status with no Service Level Agreement, and Google's official guidance remains a frustrating "wait and retry." This assessment goes beyond simple error fixes to answer the fundamental question: can you build a reliable production system on an unreliable API? The answer is nuanced — yes, but only with the right architecture.
TL;DR
Gemini 3 Pro Image API is unreliable for naive usage but can be made reliable with proper architecture. Peak hour failure rates reach approximately 45% (December 2025 through February 2026 community data), primarily from 503 overloaded errors. Off-peak hours (2-7 AM PT) see failure rates below 5%. The API is in Preview status with no SLA and no guaranteed timeline for General Availability, though community consensus points to mid-2026. To use it reliably in production, you need circuit breaker patterns, multi-provider fallback chains, and queue-based request management. For real-time, SLA-dependent workloads, consider waiting for the Vertex AI GA release or using alternative providers.
The State of Gemini 3 Pro Image API Reliability in 2026
The Gemini 3 Pro Image API, launched under the model ID gemini-3-pro-image-preview, represents Google's most capable image generation model. It produces remarkably high-quality images with excellent text rendering, coherent compositions, and impressive adherence to complex prompts. However, the gap between the model's quality and its operational reliability has created a painful paradox for developers: the best image generation API is also the least reliable one.
The reliability picture became dramatically clear during the multi-day outage from February 18 to 20, 2026, when the API was effectively non-functional for approximately 72 hours. Google Developer Forum thread #124365 documented the outage in real time, with dozens of developers reporting complete service failure across all billing tiers. This wasn't an isolated incident. Forum thread #126393, posted just five days later on February 25, reported yet another wave of urgent 503 errors in production environments, accumulating hundreds of replies within hours.
Community analysis across multiple forum threads, blog posts, and developer reports consistently points to a peak hour failure rate of approximately 45%. This figure comes from aggregated testing across December 2025 through February 2026, covering multiple billing tiers and geographic regions. The data reveals a stark pattern: during peak usage hours (9-11 AM, 1-3 PM, and 6-10 PM Pacific Time), nearly half of all API requests fail. During off-peak hours, particularly between 2 and 7 AM Pacific Time, the failure rate drops dramatically to below 5%. This time-dependent reliability pattern is one of the most important insights for any team building on this API, because it means that scheduling strategies can dramatically improve effective reliability without any code changes.
What makes this situation especially frustrating for developers is the "Preview" designation. Preview models on Google AI Studio come with no SLA, no guaranteed uptime, and technically no guarantee of continued availability. Google's official troubleshooting documentation at ai.google.dev acknowledges the overloaded errors but offers limited guidance beyond exponential backoff retry logic. For teams that have invested significant engineering effort in building products around Gemini 3 Pro Image's superior quality, this creates a difficult strategic dilemma that goes beyond simple error handling.
Understanding What "Unreliable" Means — Error Types and Patterns

Understanding what "unreliable" actually means requires breaking down the failure modes into distinct categories, each with different causes, frequencies, and mitigation strategies. Not all errors are created equal, and treating them as a single problem leads to ineffective solutions. Based on community data aggregated from Google Developer Forums and independent testing reports, the error distribution follows a consistent pattern across billing tiers and regions.
The dominant failure mode is the 503 "Model Overloaded" error, which accounts for approximately 45% of all errors encountered. This is fundamentally a capacity issue — the shared infrastructure serving the Preview model simply cannot handle the aggregate demand during peak hours. A critical insight confirmed across multiple forum threads (#126393, #112384, #119827) is that this error is not billing-tier specific. Developers on Tier 1 paid plans report the same 503 rates as those on free tier, because the capacity constraint exists at the global infrastructure level, not the per-user quota level. This means paying more for a higher billing tier does not improve your 503 reliability, which is a common misconception. Recovery from 503 errors typically takes 30 to 120 minutes, with approximately 70% of incidents resolving within 60 minutes based on community tracking data.
The second most common failure is the 429 Rate Limit error, representing about 30% of errors. Unlike 503 errors, 429 errors are more directly related to your usage patterns and can be effectively managed through proper request queuing and exponential backoff. These errors indicate that your per-minute quota has been exhausted, and they often compound with 503 errors during peak demand periods. The important difference is that 429 errors come with a Retry-After header that tells you exactly when to try again, making them predictable and manageable. If you're hitting 429 errors frequently, consult the complete rate limits and quota guide for tier-specific limits and optimization strategies.
Configuration and access errors (404 and 403) make up roughly 15% of failures. These are typically one-time issues caused by incorrect model IDs, wrong API endpoints, or API key permission problems. Unlike the first two categories, these are not reliability issues per se — they're setup issues that get resolved permanently once diagnosed. The most common cause is using the wrong model identifier; the correct ID is gemini-3-pro-image-preview, and any variation will result in a 404. For a comprehensive reference on all possible error codes and their specific fixes, see our detailed error code reference.
The remaining 10% consists of 500 Internal Server Errors, 400 Bad Request errors, and 504 Timeouts. These are generally transient and account for a small portion of overall reliability concerns. The 504 timeout errors deserve particular attention for applications that generate complex or high-resolution images, as the generation time can exceed default timeout thresholds.
Understanding this distribution is critical because it shapes your mitigation strategy. For 503 errors, no amount of retry logic helps during a capacity crunch — you need an alternative provider. For 429 errors, proper backoff and queuing solve the problem completely. For 404/403 errors, the fix is one-time configuration. A well-designed reliability system addresses each category differently rather than applying a blanket retry strategy. For detailed troubleshooting of specific error codes, our 503 error fix guide walks through every recovery strategy step by step.
Why the Gemini 3 Pro Image API Keeps Failing
Understanding the root cause of the unreliability helps predict when conditions will improve and informs better architectural decisions. The persistent failures stem from three interconnected factors that all trace back to the "Preview" designation.
The first and most significant factor is shared infrastructure with no capacity reservation. Preview models on Google AI Studio run on shared compute pools that serve all users globally. Unlike General Availability (GA) models on Vertex AI, which have dedicated capacity allocations and contractual SLA guarantees of 99.9% uptime, Preview models compete for resources on a best-effort basis. When aggregate demand from the global developer community exceeds available capacity, requests are rejected with 503 errors. This is not a bug — it's the expected behavior of a shared preview system. The implication is clear: as the model grows more popular (which it has, rapidly), the reliability gets worse, not better, until Google allocates more capacity or moves to GA.
The second factor is the model's computational intensity. Gemini 3 Pro Image generation is significantly more resource-intensive than text generation or even image understanding tasks. Each image generation request requires substantial GPU time, and the model's high quality comes at the cost of high compute requirements. This means the capacity headroom is inherently thinner for image generation compared to other API endpoints. When load spikes occur during peak hours across global time zones, the capacity ceiling is hit quickly and consistently. The concentration of failures during specific time windows (9-11 AM PT when US East Coast business hours overlap with late European workday, 1-3 PM PT during US peak productivity, and 6-10 PM PT during evening global usage) directly reflects this compute intensity meeting demand patterns.
The third factor is the absence of priority queuing in the Preview infrastructure. GA models on Vertex AI implement sophisticated request prioritization, admission control, and load balancing that prevent the kind of cascading failures seen with the Preview API. The Preview infrastructure lacks these production-grade traffic management systems, which means that when capacity is constrained, all requests are equally likely to fail regardless of the customer's billing tier, usage history, or request priority. This flat-priority architecture is appropriate for a preview or experimental service, but it creates the reliability characteristics that frustrate production usage.
The positive interpretation of this analysis is that all three root causes are addressable through the GA release process. When Google moves Gemini 3 Pro Image to General Availability on Vertex AI (community consensus suggests mid-2026), the model will gain dedicated capacity, production traffic management, and a 99.9% SLA guarantee. The question for developers today is whether to build architecture that survives the preview period or wait for GA — a decision that depends heavily on your specific use case and timeline.
The Real Cost of Unreliability — Downtime, Revenue, and Engineering Time
Most discussions about API reliability stop at error rates without quantifying what those failures actually cost a business. Understanding the financial impact is essential for justifying investment in reliability architecture and for making informed build-versus-switch decisions. The cost of unreliability extends well beyond the direct cost of failed API calls.
Consider a production application generating 5,000 images per day at the standard 2K resolution price of $0.134 per image (Google AI pricing, February 2026). At a 45% peak-hour failure rate — assuming 60% of requests occur during peak hours — the math reveals a significant waste. Of 5,000 daily requests, approximately 3,000 occur during peak hours with a 45% failure rate, resulting in 1,350 failed requests. If your system implements automatic retry logic (as it should), those 1,350 failed requests eventually succeed on retry, but each retry consumes quota and adds to costs. With an average of 2.3 retries per eventually-successful request during peak hours, you're making approximately 3,105 additional API calls per day just to overcome failures. At $0.134 per attempt for calls that contribute to quota consumption, the wasted spend on failed-then-retried requests can add $200 to $400 per month depending on retry patterns and peak hour exposure.
The indirect costs often dwarf the direct API waste. Engineering time spent monitoring, debugging, and responding to reliability incidents represents the largest hidden cost. A team spending even 5 hours per week on reliability-related work at a loaded engineer cost of $150 per hour is spending $3,000 per month — far more than the API cost itself. Customer support tickets from users experiencing failed image generations, delayed deliveries, and quality complaints add further costs that are difficult to quantify but very real. For user-facing products, the reputation damage from a 45% failure rate during business hours can impact user retention and growth metrics in ways that compound over time.
One often-overlooked approach to reducing costs is the Batch API, which processes requests asynchronously at a 50% discount. For workloads that can tolerate delays of minutes to hours, the Batch API with its 50% cost savings provides both cost reduction and better tolerance for rate limits. The async nature of batch processing also means individual request failures have less impact on the user experience, as the system can retry transparently without the user waiting. For teams where real-time generation isn't required, the Batch API effectively solves both the cost and reliability problems simultaneously.
For teams looking to minimize per-image costs further while maintaining reliability, API aggregation platforms like laozhang.ai offer Gemini 3 Pro Image access at approximately $0.05 per image — roughly 60% less than direct Google pricing. These platforms often implement their own retry and failover logic, effectively absorbing some of the reliability burden on behalf of the developer. The trade-off is an additional dependency and potential latency, but for cost-sensitive applications generating thousands of images daily, the savings can be substantial.
Building Reliable Systems on an Unreliable API
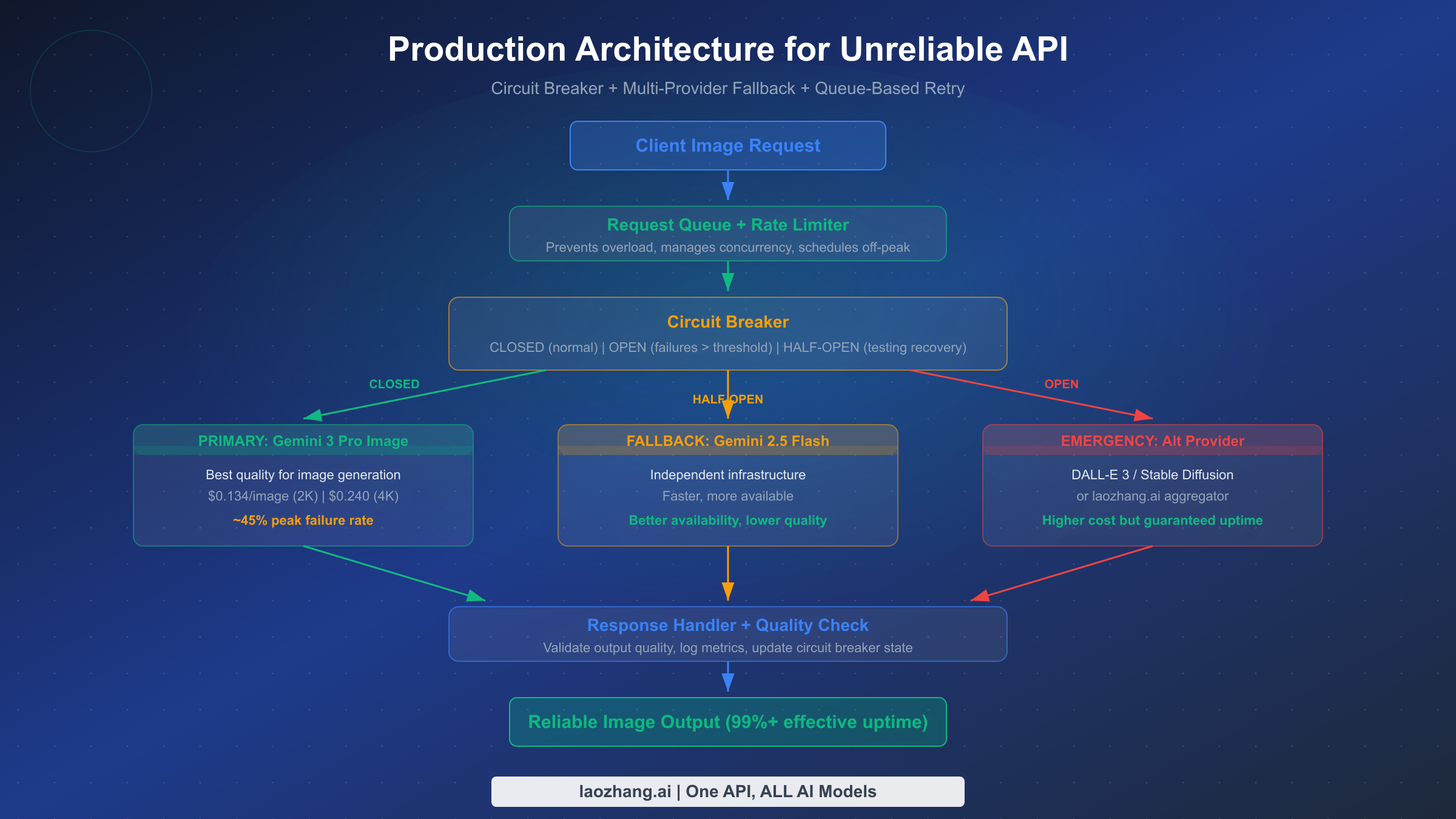
The core insight for building reliable systems on an unreliable API is that reliability must be a system property, not an API property. No single API endpoint provides the reliability needed for production use, but a well-designed system that orchestrates multiple providers, manages request flow, and degrades gracefully can achieve 99%+ effective uptime even when the primary API has a 45% peak failure rate. This section provides the architectural patterns that make this possible.
Circuit Breaker Pattern
The circuit breaker pattern is the foundation of any production architecture for unreliable APIs. It operates in three states: Closed (normal operation, requests flow to the primary provider), Open (failures have exceeded a threshold, requests are immediately routed to fallback providers without attempting the primary), and Half-Open (periodically testing whether the primary provider has recovered). A typical configuration for Gemini 3 Pro Image would set the failure threshold at 5 consecutive failures or a 50% failure rate over a 2-minute window, with a recovery probe every 60 seconds during the Open state.
The circuit breaker prevents two critical problems. First, it stops wasting time and money on requests destined to fail during an outage, routing them immediately to a fallback that will succeed. Second, it prevents your application from contributing to the overload condition — when thousands of clients simultaneously retry against an overloaded service, they make the situation worse. The circuit breaker gives the overloaded service breathing room to recover while your application continues serving users through fallback providers.
Multi-Provider Fallback Chain
The fallback chain determines what happens when the circuit breaker opens. For image generation, a practical three-tier fallback chain works well. The primary provider is Gemini 3 Pro Image for its superior quality. The secondary fallback is Gemini 2.5 Flash Image, which runs on independent infrastructure (confirmed across multiple SERP sources), offers faster response times and better availability, though at somewhat lower image quality. The emergency fallback is an alternative provider entirely — DALL-E 3, Stable Diffusion, or an aggregation service — ensuring that even during a complete Google outage, your application continues generating images.
The key design decision in the fallback chain is how to handle quality degradation. When the circuit breaker opens and requests route to Gemini 2.5 Flash, the image quality may be noticeably different. Some applications can accept this transparently, while others should notify the user: "Generated with our fast model — regenerate for higher quality when available." This transparency builds user trust and sets appropriate expectations. For a comprehensive comparison of alternative providers and their capabilities, see our AI image generation API comparison for 2026.
Queue-Based Request Management
The third architectural component is a request queue that sits in front of the entire fallback chain. The queue serves multiple purposes: it rate-limits outgoing requests to stay within quota limits, it enables request prioritization so that paying users or urgent requests get processed first, and it enables time-shifting — scheduling non-urgent requests for off-peak hours when the failure rate drops below 5%.
A practical implementation uses a priority queue backed by Redis or a similar data store, with workers that pull requests and route them through the circuit breaker and fallback chain. The queue also enables the "eventual delivery" pattern where the system guarantees that every request will eventually be fulfilled, even if it takes multiple retries across different providers and time windows. For applications that can tolerate minutes-to-hours delivery times, this pattern achieves near-100% effective reliability. For comprehensive error handling and debugging strategies across all these components, our troubleshooting hub provides a centralized reference.
The combination of circuit breaker, multi-provider fallback, and queue-based management transforms a 45% peak failure rate into an effective 99%+ uptime system. The architectural investment is significant — requiring additional infrastructure, monitoring, and maintenance — but for teams committed to using Gemini 3 Pro Image's superior quality, it's the difference between a production-grade application and a demo that breaks during business hours.
Should You Use Gemini 3 Pro Image API? A Decision Framework

After analyzing the failure data, understanding the root causes, quantifying the costs, and designing the architectural solutions, the fundamental question remains: should you use this API for your project? The answer depends on three key variables — your latency requirements, your volume, and your tolerance for complexity.
Use it confidently if your application processes images asynchronously, where users don't wait for real-time results. Batch processing workflows, background content generation, scheduled marketing asset creation, and internal tooling all fall into this category. When you can queue requests and deliver results later, the reliability problem largely disappears because you can leverage off-peak hours (2-7 AM PT with failure rates below 5%), use the Batch API for 50% cost savings, and retry transparently without impacting user experience. For these use cases, Gemini 3 Pro Image offers the best quality-to-price ratio available, and the pricing and speed test data confirms it consistently outperforms alternatives on output quality.
Use it with caution if you need semi-real-time responses (30-60 second tolerance) and serve customers directly. This includes web applications where users click "generate" and see a loading indicator, mobile apps with image generation features, and SaaS products with image creation capabilities. For these use cases, the multi-provider fallback architecture described above is mandatory. Budget for approximately 2x the infrastructure costs compared to a reliable single-provider setup, invest in the circuit breaker and monitoring infrastructure, and plan your UI to handle graceful degradation when the system falls back to a lower-quality provider. The engineering investment is substantial but achievable for teams with production experience.
Avoid it if you require real-time responses (under 5 seconds), operate under an SLA obligation, process more than 10,000 images per day, or work in a regulated industry where guaranteed availability is non-negotiable. For these use cases, the Preview status of the API creates unacceptable risk. A 45% failure rate during business hours, combined with the possibility of multi-day outages like the February 18-20, 2026 incident, makes it unsuitable as even a primary provider in a fallback chain. Instead, consider waiting for the Vertex AI GA release (expected mid-2026) which will include a 99.9% uptime SLA, or use established alternatives that already offer production-grade reliability guarantees.
The nuanced middle ground is worth emphasizing: Gemini 3 Pro Image is not universally unreliable — it's unreliable for naive usage patterns. With proper architecture, off-peak scheduling, and multi-provider fallback, it can be a highly effective component of a production image generation system. The decision comes down to whether the quality advantage justifies the engineering investment in reliability infrastructure.
Alternatives and Fallback Options Compared
Choosing the right fallback providers and understanding when to consider alternatives entirely requires a structured comparison. The following analysis covers the most relevant options as of February 2026, focusing on the dimensions that matter most for production reliability decisions.
Gemini 2.5 Flash Image stands as the most natural fallback for Gemini 3 Pro Image users. It runs on independent infrastructure (confirmed across multiple community sources), which means it doesn't share the same capacity constraints that cause 503 errors on Gemini 3 Pro. The response time is significantly faster, and the availability is substantially better. The trade-off is image quality — while still competent, Gemini 2.5 Flash produces images that are noticeably less refined than Gemini 3 Pro's output, particularly for complex compositions, text rendering, and photorealistic styles. For many applications, this quality difference is acceptable as a temporary fallback, especially when the alternative is showing users an error message.
| Provider | Quality | Reliability | Price per Image | Latency | Best For |
|---|---|---|---|---|---|
| Gemini 3 Pro Image | Excellent | ~55% peak uptime | $0.134 (2K) | 10-30s | Quality-critical, async |
| Gemini 2.5 Flash Image | Good | High (independent infra) | Lower | 3-10s | Fast fallback |
| DALL-E 3 | Very Good | High (production SLA) | ~$0.040-0.080 | 5-15s | Reliable alternative |
| Stable Diffusion (self-hosted) | Good | Self-managed | Compute cost | Variable | Full control |
| laozhang.ai (aggregator) | Varies by model | High (multi-model) | ~$0.05 (Gemini) | 10-35s | Cost optimization |
For teams that decide the Preview-era unreliability is not acceptable, the migration path is less painful than many expect. Most image generation API calls follow a similar pattern regardless of provider: send a text prompt, receive an image. The actual code change is often as simple as swapping the model endpoint and adjusting the response parsing. The more significant investment is in prompt engineering — each model has different strengths and prompt format preferences — and in quality validation, ensuring the alternative produces acceptable output for your specific use case.
The Vertex AI GA pathway deserves special attention because it offers a future where you keep the Gemini 3 Pro Image quality advantage with production-grade reliability. When the model moves to GA on Vertex AI (community consensus points to mid-2026), it will come with a 99.9% uptime SLA, dedicated capacity, and enterprise support. For teams that can afford to wait and tolerate the preview-period unreliability in the interim, building on Vertex AI is arguably the best long-term strategy. The API interface is similar, and migration from AI Studio to Vertex AI is well-documented.
Frequently Asked Questions
Is the Gemini 3 Pro Image API unreliable for everyone, or just free tier users?
The unreliability affects all users regardless of billing tier. Community data from forum threads confirms that Tier 1 paid users experience the same 503 error rates as free tier users. This is because the 503 "model overloaded" error reflects global infrastructure capacity limits, not per-user quota exhaustion. Paying for a higher tier increases your per-minute request quota (helping with 429 errors) but does not improve 503 reliability.
When will Google fix the reliability issues?
Google has not provided an official timeline, but community consensus based on model maturity patterns and Vertex AI release cadences suggests a GA release around mid-2026. The GA release on Vertex AI would include a 99.9% uptime SLA and dedicated infrastructure. Until then, the Preview API will continue operating on shared infrastructure with best-effort reliability.
What is the best time to use the API to avoid failures?
Off-peak hours between 2 AM and 7 AM Pacific Time consistently show failure rates below 5%, compared to the approximately 45% rate during peak hours. If your workload can be time-shifted to this window, scheduling is by far the simplest and most effective reliability strategy. The Batch API is particularly well-suited for this approach, as it processes requests asynchronously at 50% reduced cost.
Can I get a refund for failed API requests?
Preview API usage is subject to Google's standard terms, which do not include SLA-based credits or refunds for service disruptions. Failed requests that return errors before processing do not consume quota, but requests that timeout after partial processing may still be billed. This is another reason why the Preview status matters for cost planning — there is no contractual remedy for downtime.
Should I switch to a completely different provider?
It depends on your quality requirements. If Gemini 3 Pro Image's output quality is significantly better than alternatives for your use case, building a reliable architecture around it (circuit breaker, fallback, queue) is worthwhile. If your use case can tolerate slightly lower image quality, providers with production SLAs offer a simpler path to reliability. The decision framework in this article provides specific criteria for each scenario.