Gemini API 429 RESOURCE_EXHAUSTED means the request crossed a limit boundary. The useful fix is not "retry harder." First identify which boundary was hit: a live AI Studio rate limit, a project-level quota pool shared by more than one workload, a billing or prepay state that cannot serve traffic, a bursty request pattern, or a Vertex AI capacity contract that behaves differently from the Gemini Developer API.
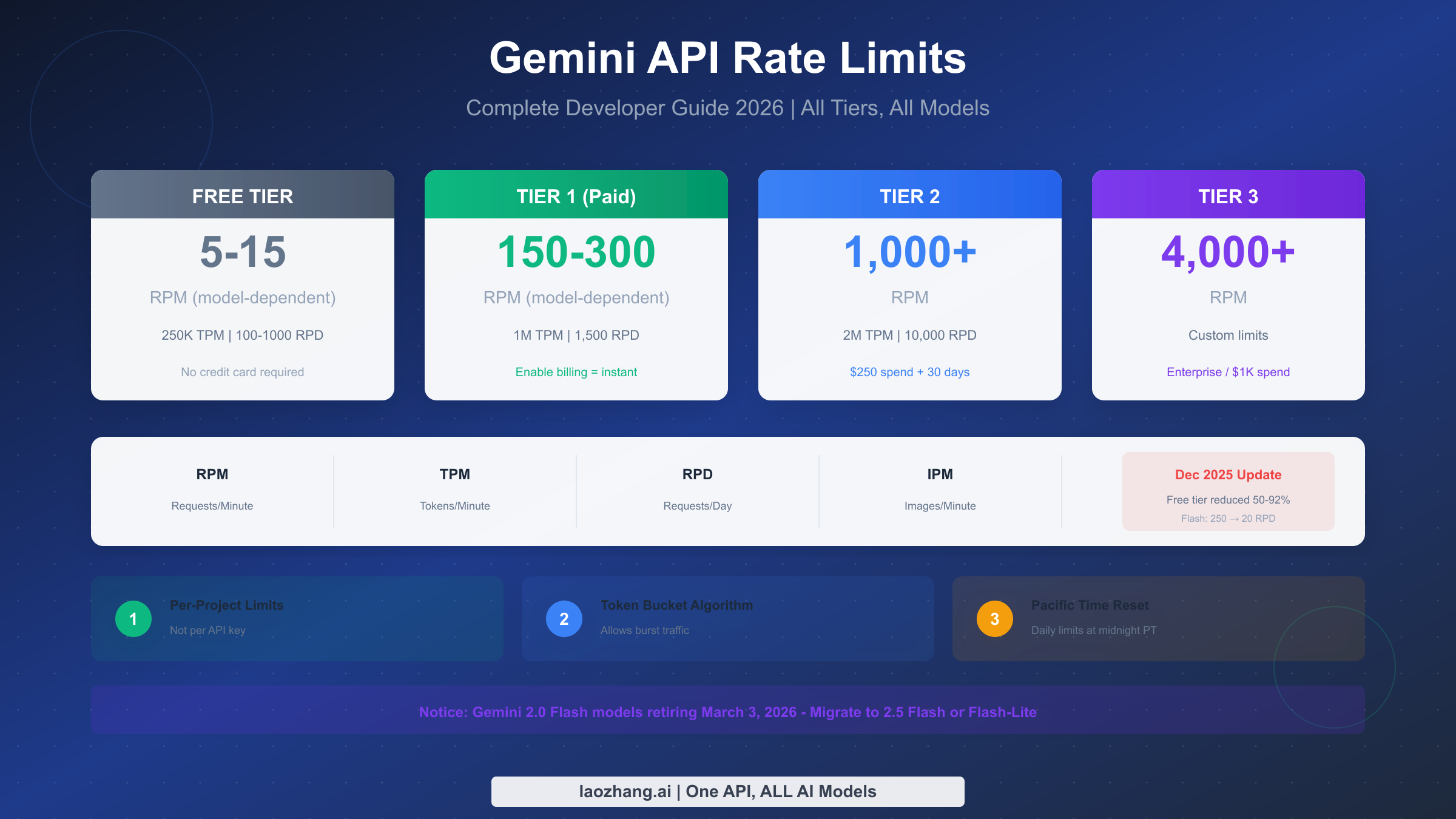
Google's current troubleshooting guide maps HTTP 429 to RESOURCE_EXHAUSTED and says the caller has exceeded the rate limit. The current rate-limits page adds the operational detail that limits are measured across RPM, input TPM, and RPD, apply per project rather than per API key, and should be checked in AI Studio because specified limits are not guaranteed. That is the contract to use on May 3, 2026.
Start with this order:
| Check | What it proves | Next move |
|---|---|---|
| Same error body | Confirms this is 429 RESOURCE_EXHAUSTED, not a 400 billing precondition or 503 capacity event | Log status, message, model, project, and endpoint |
| AI Studio active limits | Shows the live RPM, TPM, RPD, IPM, or batch limit for the exact project and model | Reduce load, switch route, or request quota increase |
| Project ownership | Shows whether several API keys and apps share one project pool | Separate workloads only when the project boundary is legitimate |
| Billing state | Shows whether tier, prepay balance, or setup status can serve requests | Fix billing or credits before retry logic |
| Traffic shape | Shows whether bursts, long contexts, or bad retries create pressure | Add backoff, queueing, idempotency, and concurrency caps |
Freshness note: official Gemini API rate limits, troubleshooting, billing, pricing, Vertex AI 429 behavior, and the Google Cloud 429 resource-exhaustion guidance were re-checked on May 3, 2026.
Read the error as a limit branch, not a generic outage

The first minute matters. If the error body says RESOURCE_EXHAUSTED, stay on the limit branch until evidence says otherwise. A 503 UNAVAILABLE points to temporary service capacity. A 400 FAILED_PRECONDITION can mean the free tier is not available in the caller's region and billing needs setup. A 429 RESOURCE_EXHAUSTED is different: the current route accepted the request shape but refused to serve it because a limit boundary was crossed.
The most common mistake is to treat every 429 as a code bug. A backoff wrapper is useful when traffic is bursty or capacity is temporarily tight. It is not useful when the project is simply out of daily requests, when another workload shares the project quota, when the prepay balance is depleted, or when the selected model is not available on the free API path you assumed.
Keep the error body in the log. For JavaScript with @google/genai, Google documents API errors as objects that expose fields such as name, message, and status. That is enough to classify retryable status codes while keeping the human-readable message for escalation.
Check AI Studio before memorizing a quota table
Google's rate-limits page says limits are tied to usage tier, but it also points developers to AI Studio for active rate limits. That changes the debugging habit. A copied public table can explain the tier ladder; it cannot prove the live serving limit for the project and model that just failed.
Use AI Studio to answer three questions:
- Which metric is exhausted: RPM, TPM, RPD, image-per-minute, or a batch-specific limit?
- Which model and route produced the error?
- Is the project near a live limit, or does the error not match visible usage?
If the dashboard confirms saturation, the next move is capacity or traffic shaping. If the dashboard does not match the error, collect the request time, model, project, response body, and usage view before escalating. Do not create extra API keys as a reflex. Gemini API limits apply per project, so multiple keys inside the same project still draw from the same pool.
Separate project quota, billing, and route eligibility
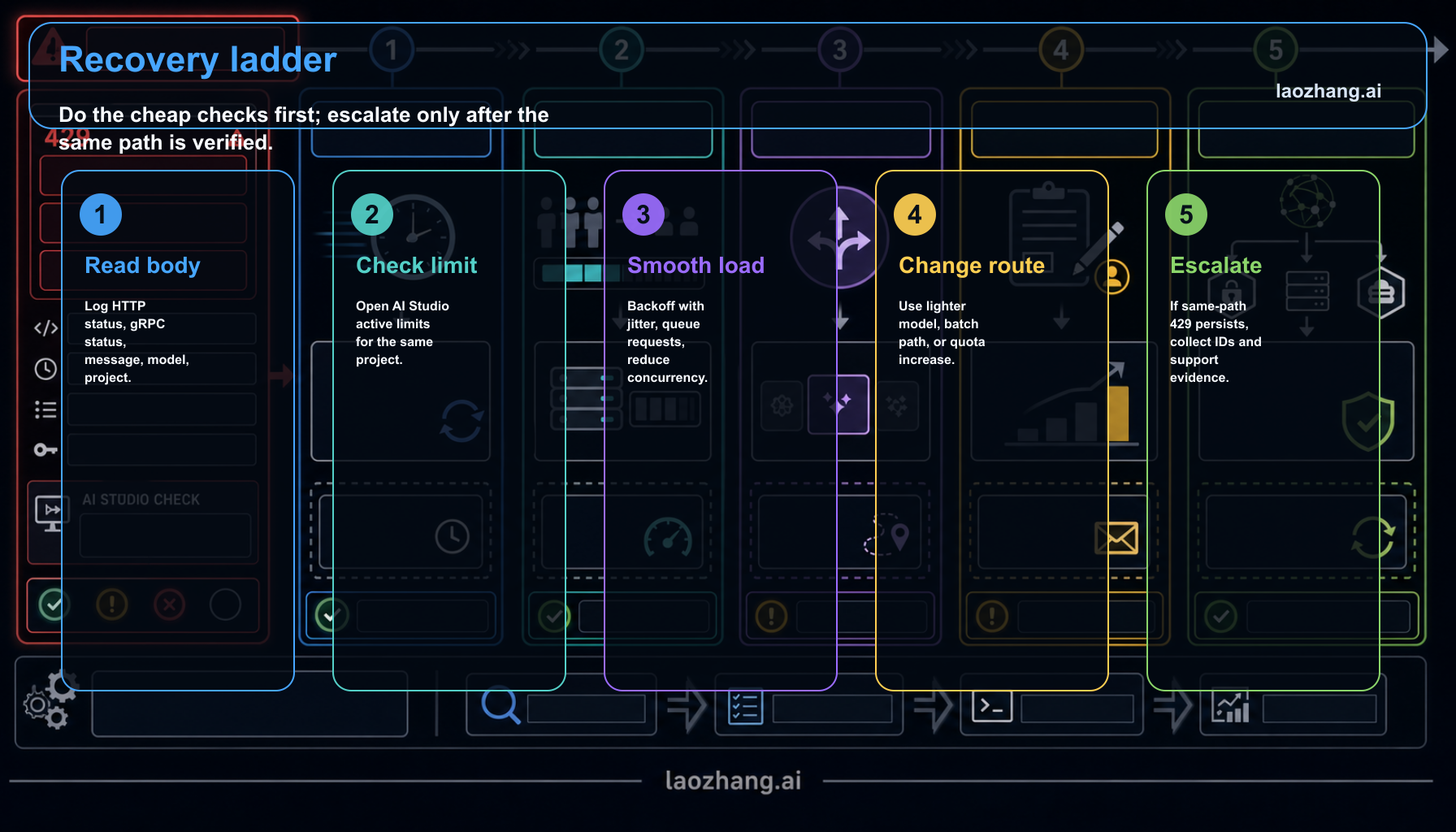
Three boundaries often get mixed together.
Project quota is the pool. A staging app, a batch worker, a local script, and production traffic can all compete if they use keys from the same Google Cloud project. More keys inside the same project do not create more quota. Move noisy workloads only when the project split is real and governance-safe.
Billing is the account state. Google's current billing docs say paid tier status is dynamic, new users can be assigned to Prepay, and when the prepay credit balance hits $0, API keys in projects linked to that billing account stop working. That means "billing was enabled" is not a complete diagnosis. Check the billing tier column, the available credits, and any status action in AI Studio.
Route eligibility is the model contract. Some current Gemini routes list free API pricing, while others are paid-only. If the selected route is not free-capable, a free-tier tuning plan will not stabilize it. Switch to a route that fits the workload, or finish the paid setup intentionally.
Use retry logic only after the limit owner is known
Backoff is a pressure-management tool, not a substitute for capacity. Use it when the same project and model can serve the request but your traffic arrives too sharply.
javascriptimport { GoogleGenAI } from "@google/genai"; const retryable = new Set([429, 500, 503, 504]); export async function callGeminiWithBackoff(run, { maxRetries = 5, baseDelayMs = 1000, maxDelayMs = 30000, } = {}) { let lastError; for (let attempt = 0; attempt <= maxRetries; attempt += 1) { try { return await run(); } catch (error) { lastError = error; const status = Number(error?.status || error?.code || 0); const shouldRetry = retryable.has(status); if (!shouldRetry || attempt === maxRetries) { throw error; } const jitterMs = Math.floor(Math.random() * 500); const delayMs = Math.min(baseDelayMs * 2 ** attempt + jitterMs, maxDelayMs); await new Promise((resolve) => setTimeout(resolve, delayMs)); } } throw lastError; } const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const response = await callGeminiWithBackoff(() => ai.models.generateContent({ model: "gemini-2.5-flash", contents: "Summarize the incident in three bullets.", }), );
Add a concurrency cap around that wrapper. If ten workers all retry at once, the retry layer becomes the load spike. For batch jobs, queue requests and checkpoint progress. For interactive products, cache repeated prompts, make retries idempotent, and surface a short wait state rather than silently running a retry storm.
Developer API and Vertex AI have different 429 contracts

The phrase RESOURCE_EXHAUSTED can appear in both the Gemini Developer API and Google Cloud / Vertex AI material, but the fix path is not identical.
For the Gemini Developer API, start with AI Studio: API key, project, usage tier, active limits, billing plan, and prepay credits. For Vertex AI, start with the Google Cloud project, endpoint, region or global endpoint, quota framework, and whether Provisioned Throughput is involved. Google's Vertex AI 429 documentation says pay-as-you-go 429 fixes include using a global endpoint when possible, truncated exponential backoff, quota increase requests for quota-based models, traffic smoothing for standard pay-as-you-go, or Provisioned Throughput for more consistent service.
That distinction prevents a common dead end. If your request goes through Vertex AI, AI Studio's Developer API limit view is not the whole diagnosis. If your request goes through an API key from ai.google.dev, Vertex AI Provisioned Throughput advice may be the wrong contract.
When more capacity is the correct answer
After the route, project, billing, and traffic shape are clear, capacity choices become simpler.
Use a lighter model when quality allows. gemini-2.5-flash or gemini-2.5-flash-lite often fits high-volume work better than a heavier reasoning route. Use Batch API for offline work that does not need immediate response. Request a rate-limit increase when the live limit is too low for a paid workload. Move to Vertex AI or Provisioned Throughput when the operational contract needs Google Cloud controls, region selection, or reserved capacity.
If a single provider's 429s are now an uptime risk, a multi-provider gateway can also be a deliberate architecture choice. A gateway such as laozhang.ai is relevant when the reader needs unified routing and fallback across models, not when the problem is just one local retry loop.
FAQ
Does each Gemini API key get its own 429 limit?
No. The Gemini API rate-limit docs say limits apply per project, not per API key. Different keys in the same project still share the same quota pool.
Does enabling billing always fix RESOURCE_EXHAUSTED?
No. Billing can change tier and route eligibility, but it does not fix shared project usage, a depleted prepay balance, daily exhaustion, or bursty traffic.
Should 429 always be retried?
No. Retry only after you know the owner of the limit. Retry helps temporary pressure and burst traffic. It does not create daily quota, fix billing state, or turn a paid-only route into a free route.
Where is the current Gemini API limit number?
Use AI Studio's active rate-limit view for the exact project and model. Public docs explain the mechanics and tier ladder, but Google warns that specified limits are not guaranteed.
When should I switch to Vertex AI?
Switch when you need Google Cloud project governance, endpoint or region control, quota increase workflow, Provisioned Throughput, or a Vertex-owned production path. Do not switch just because one retry loop is missing backoff.
Practical rule
Treat 429 RESOURCE_EXHAUSTED as a routing problem first. Same error body, same project, same model, same endpoint, same time window. Once those match, choose the narrowest fix: billing action, project isolation, traffic smoothing, model change, quota increase, Vertex capacity, or gateway fallback.