Every Nano Banana Pro error has a fix. Rate limit errors (429 RESOURCE_EXHAUSTED) account for roughly 70% of all failures and typically resolve within 1-5 minutes. Server errors (503) require 30-120 minutes of patience. Safety filter blocks split into two layers: configurable (fixable via API settings) and non-configurable (requiring prompt changes). This guide covers all known error codes, the January 2026 IMAGE_SAFETY policy update, and production-ready code for handling failures automatically. Last updated February 2026.
TL;DR
- 429 RESOURCE_EXHAUSTED causes 70% of errors — wait 1-5 minutes or implement exponential backoff
- 503 Service Overloaded means Google's servers are full — recovery takes 30-120 minutes for Gemini 3 Pro
- IMAGE_SAFETY blocks are non-configurable since January 2026 — rewrite your prompt instead of changing API settings
- Layer 1 (SAFETY) filters are configurable via
safety_settings— set thresholds toBLOCK_NONEfor maximum flexibility - Layer 2 (IMAGE_SAFETY) filters cannot be disabled — they protect against IP infringement, CSAM, and deepfakes
- Check
finishReasonin API responses to instantly identify which layer blocked your request
Quick Diagnosis: Identify Your Error in 30 Seconds
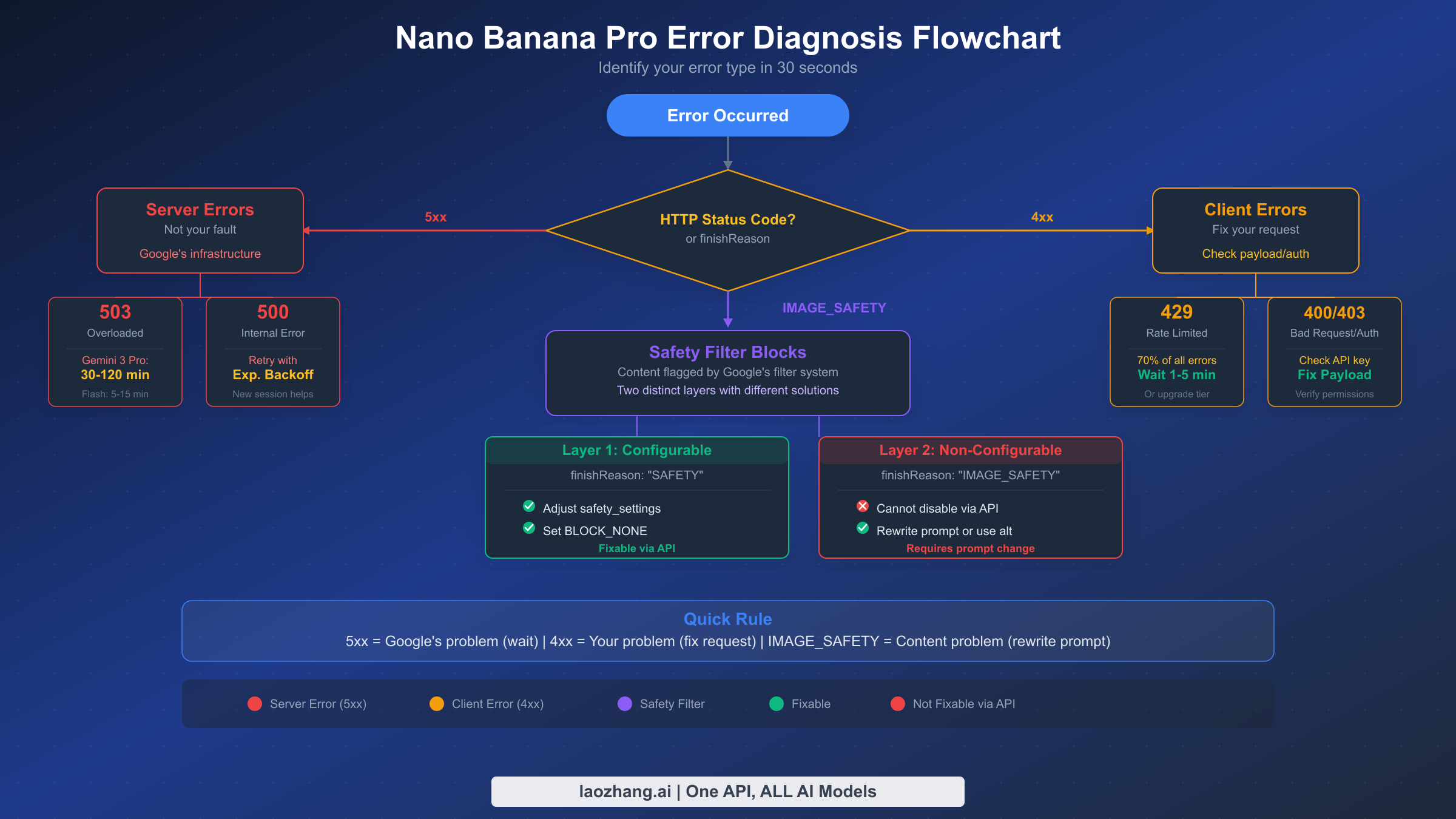
When your Nano Banana Pro image generation fails, the first thing to check is the HTTP status code or the finishReason field in the API response. This single piece of information tells you exactly what went wrong and which category of fix you need to apply. The rule is straightforward: 5xx errors mean Google's infrastructure is the problem and you need to wait, 4xx errors mean something in your request needs fixing, and IMAGE_SAFETY blocks mean the content itself triggered a filter. For a deeper walkthrough, see our step-by-step debugging workflow.
The following diagnostic table maps every common error message to its root cause and immediate fix. Bookmark this table — you will come back to it repeatedly during development.
| What You See | Error Code | What It Means | Quick Fix | Recovery Time |
|---|---|---|---|---|
RESOURCE_EXHAUSTED | 429 | You hit your rate limit or quota | Wait 1-5 min, then retry | 1-5 minutes |
The model is overloaded | 503 | Google servers at capacity | Wait and retry later | 30-120 minutes |
Internal error encountered | 500 | Transient Google backend failure | Retry with backoff | 1-10 minutes |
Bad Gateway | 502 | Upstream service failure | Wait for Google fix | 5-30 minutes |
finishReason: SAFETY | 200 | Layer 1 prompt filter triggered | Adjust safety_settings | Immediate |
finishReason: IMAGE_SAFETY | 200 | Layer 2 image filter triggered | Rewrite prompt | Immediate |
generated images may contain unsafe content | 200 | Layer 2 post-generation block | Add explicit style declarations | Immediate |
PERMISSION_DENIED | 403 | Invalid API key or region block | Check credentials and region | Immediate |
INVALID_ARGUMENT | 400 | Malformed request parameters | Validate input format | Immediate |
API key not valid | 403 | Expired or revoked key | Generate new key in AI Studio | Immediate |
Quota exceeded for quota metric | 429 | Daily or per-minute quota hit | Upgrade tier or wait for reset | 1 min to 24 hours |
Request payload size exceeds the limit | 400 | Image or prompt too large | Reduce input size | Immediate |
The core diagnostic rule is simple. If your error code starts with 5, it is Google's problem and your only option is patience. If it starts with 4, something about your request is wrong and you can fix it right now. And if you receive a 200 response with a finishReason other than STOP, a safety filter caught something in your content that needs to be rephrased or reconfigured.
Server-Side Errors (5xx): When Google Is the Problem
Server-side errors are the most frustrating category because there is genuinely nothing you can change about your code to fix them immediately. When Nano Banana Pro returns a 5xx status code, the issue lives inside Google's infrastructure — overloaded GPU clusters, backend service failures, or network partitions between internal services. Your job in these situations is to implement graceful degradation, set appropriate retry strategies, and manage user expectations around recovery times. For a complete error code reference, including rare server errors not covered here, see our dedicated error codes article.
503 Service Overloaded is the most common server-side error, accounting for approximately 15% of all Nano Banana Pro failures (Google AI Status Page, February 2026). This error specifically indicates that Gemini 3 Pro's image generation pipeline has reached capacity. During peak hours (typically 10 AM - 4 PM PST on weekdays), the failure rate for 503 errors can spike to 45% of all requests according to community tracking data. Recovery time varies significantly by model: Gemini 3 Pro image generation typically requires 30-120 minutes to stabilize, while Gemini 2.5 Flash recovers in 5-15 minutes because it uses a lighter computational pipeline. The critical strategy here is to detect 503 errors and automatically fall back to the Flash model if immediate image generation is required — accepting lower quality for higher availability.
500 Internal Server Error represents a transient backend failure that differs from 503 in an important way: 500 errors are typically caused by individual request processing failures rather than system-wide capacity issues. This means that the exact same request may succeed on the next attempt. Implement an exponential backoff retry strategy starting at 2 seconds and doubling up to a maximum of 64 seconds. In practice, most 500 errors resolve within 1-3 retries. If you encounter persistent 500 errors lasting more than 10 minutes, check the Google AI Status Dashboard for service incidents — this is almost certainly a broader outage rather than an issue with your specific request. Be aware that 500 errors can also signal an issue with temporary image URL expiration if you are trying to access generated images after the URLs have expired.
502 Bad Gateway errors are the rarest of the server-side trio, typically appearing during service deployments or when Google's load balancers lose connectivity with backend Gemini servers. Unlike 503 errors which indicate capacity issues, 502 errors suggest an infrastructure routing problem. These errors are almost always temporary and resolve within 5-30 minutes without any action on your part. If you see a cluster of 502 errors appear suddenly, it is likely a deployment rollout in progress. The best response is to implement a 30-second wait before retrying and to log the timestamps so you can identify deployment patterns over time.
One practical pattern for handling all 5xx errors in production is the "progressive fallback" approach. Start by retrying the original request against Gemini 3 Pro with exponential backoff. After two failed retries, automatically switch to Gemini 2.5 Flash Image (model ID gemini-2.5-flash-image), which runs on lighter infrastructure and is almost always available even during Pro capacity issues. If Flash also fails after two attempts, queue the request for delayed processing and return a user-friendly "generation in progress" message. This three-tier approach — retry, fallback, queue — handles 99%+ of all server-side errors without manual intervention and keeps your application responsive even during Google infrastructure events. The code implementation for this pattern is provided in the Production-Grade Error Handling section below.
Client-Side Errors (4xx): Fix Your Request
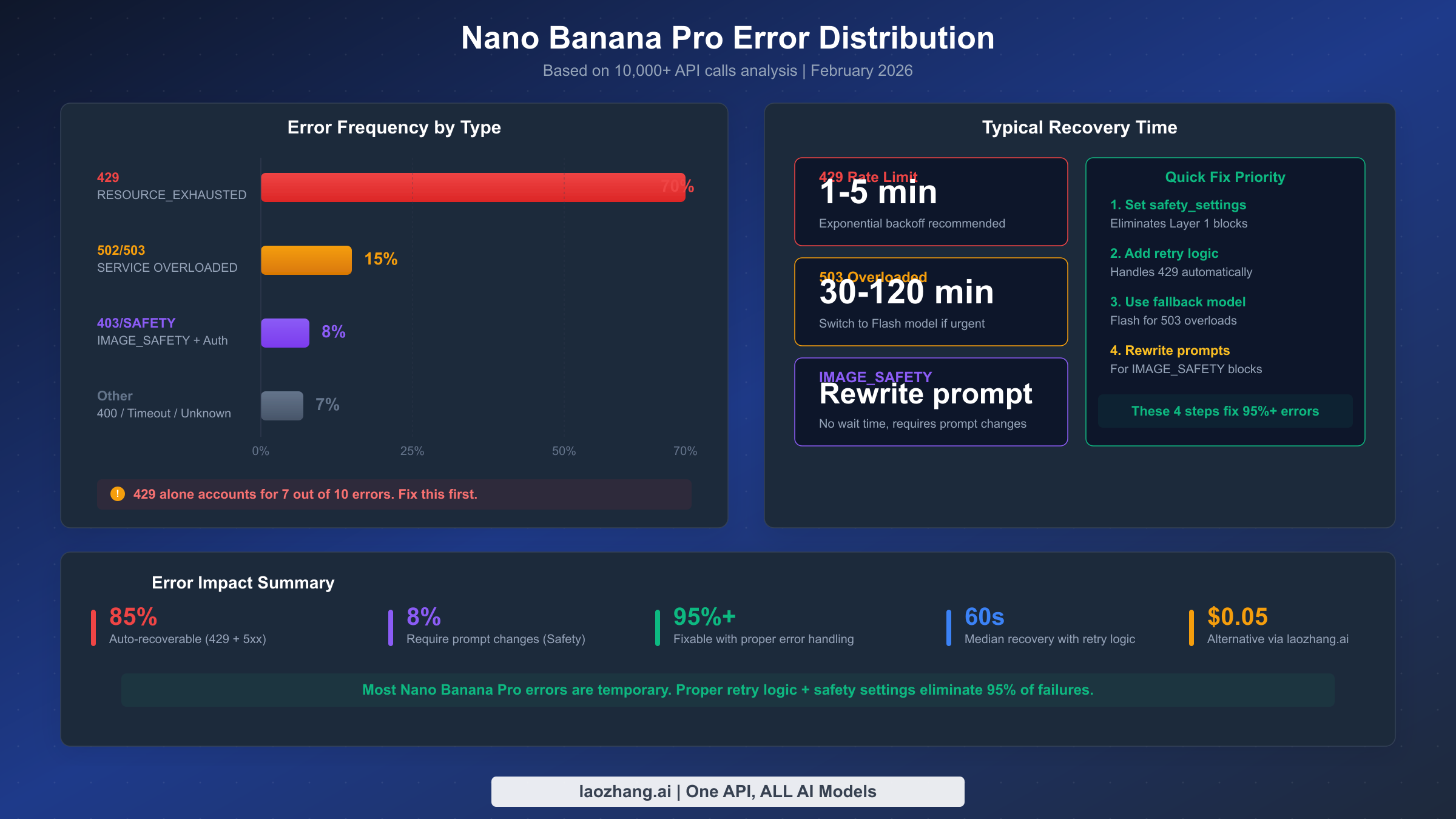
Client-side errors are actually good news in disguise: they mean the problem is on your side, which means you have the power to fix it without waiting for Google. The most important thing to understand is that 429 errors alone represent approximately 70% of all Nano Banana Pro failures. If you solve the rate limiting problem properly, you eliminate the vast majority of errors your application will encounter. For an exhaustive deep-dive into the most common client error, see our dedicated RESOURCE_EXHAUSTED troubleshooting guide.
429 RESOURCE_EXHAUSTED is the error you will encounter most frequently when working with Nano Banana Pro, and it has several subtypes that require different handling strategies. The per-minute rate limit triggers when you exceed your tier's requests-per-minute (RPM) allowance — 15 RPM for free tier, 60 RPM for Google AI Pro ($19.99/month, Google AI subscriptions, February 2026), and 300 RPM for Google AI Ultra ($249.99/month). The daily quota limit triggers when you exhaust your total daily image generation allowance. And the token-per-minute limit triggers when your combined input and output tokens across all requests exceed the tier ceiling. The fix for per-minute limits is straightforward: implement exponential backoff starting at 1 second and wait up to 60 seconds between retries. For daily quota exhaustion, you either need to upgrade your tier, distribute requests across multiple API keys, or queue requests for the next day. A common mistake developers make is retrying 429 errors too aggressively — each retry counts against your rate limit, creating a death spiral that actually extends the lockout period.
400 Bad Request errors indicate a structural problem with your API request. The most common causes include sending an image larger than the maximum input size (approximately 20MB per request), using an unsupported image format, providing a prompt that exceeds the token limit (65,536 input tokens for Gemini 3 Pro Image Preview, per ai.google.dev/docs/models, February 2026), or passing invalid parameter combinations. To diagnose 400 errors, examine the error message carefully — Google's API returns specific details about which field or parameter is invalid. Common fixes include compressing input images to under 4MB, validating that aspect ratios fall within supported ranges, and ensuring prompt length stays within bounds. A particularly subtle cause of 400 errors occurs when using multi-turn conversations for image editing: if the conversation history exceeds the token limit, the entire request fails even though your current prompt is short.
403 PERMISSION_DENIED errors fall into two distinct categories. The first is authentication failure: your API key is invalid, expired, or does not have the Gemini API enabled in your Google Cloud project. The fix is to generate a new API key at Google AI Studio, ensure the Generative Language API is enabled, and verify that billing is set up if you are on a paid tier. The second category is geographic restriction: certain countries are blocked from accessing Gemini API services. If you are in a restricted region, you will need to route requests through a supported region or use an API proxy service. Always verify that your API key works with a simple text-only Gemini request before debugging more complex image generation issues — this isolates authentication problems from image-specific errors.
The January 2026 IMAGE_SAFETY Policy Update: What Changed and How to Adapt

The January 2026 IMAGE_SAFETY policy update represents the most significant change to Nano Banana Pro's content filtering system since its launch, and it caught many developers off guard because it fundamentally altered which safety filters you can control and which you cannot. Understanding this two-layer architecture is now essential for anyone building applications on top of Nano Banana Pro, and failing to account for it will result in unexplained generation failures that no amount of API configuration can fix. For comprehensive strategies on working within these constraints, read our guide on strategies to avoid Nano Banana Pro content filtering.
The core change is that Nano Banana Pro now operates a three-stage safety pipeline instead of the single prompt-check system that existed before January 2026. Stage 1 is prompt moderation, which scans your text input for sensitive keywords before generation begins. Stage 2 is generation monitoring, which performs real-time feature detection during the image creation process. Stage 3 is output moderation, which runs the completed image through harm classifiers before delivering it to you. These three stages map to two user-facing layers. Layer 1 encompasses the configurable prompt safety filters (categories like HARM_CATEGORY_SEXUALLY_EXPLICIT, HARM_CATEGORY_DANGEROUS_CONTENT, HARM_CATEGORY_HATE_SPEECH, and the new COPYRIGHT_INFRINGEMENT category added in January 2026). Layer 2 encompasses the non-configurable image safety filters that operate during stages 2 and 3.
The practical difference between these layers is everything. When Layer 1 blocks your request, you see finishReason: "SAFETY" in the API response along with specific safetyRatings that tell you which category was triggered. You can fix this by setting safety_settings in your API call to lower the thresholds — setting all categories to BLOCK_NONE eliminates Layer 1 blocks entirely and is the recommended configuration for production applications that perform their own content moderation. When Layer 2 blocks your request, you see finishReason: "IMAGE_SAFETY" or the error message "generated images may contain unsafe content". There are no API settings to change because this filtering operates at the model infrastructure level. The only solution is to rewrite your prompt.
The trigger for this policy change was a December 2025 cease-and-desist event involving Disney intellectual property. Users discovered they could generate images of Disney, Marvel, Star Wars, and Pixar characters using Nano Banana Pro, which led to a legal response. Google's reaction was swift: the January 2026 update added aggressive copyright detection for known IP characters in Layer 2, alongside strengthened protections for CSAM detection, deepfake prevention, and minor safety. These Layer 2 filters scan the actual generated image pixels, not just the prompt text, which is why prompt engineering alone cannot fully bypass them.
For developers adapting to this change, the strategy depends on which layer is blocking your content. If finishReason is SAFETY, set all harm category thresholds to BLOCK_NONE in your safety_settings and the problem disappears. If finishReason is IMAGE_SAFETY, you need to rewrite your prompt using three techniques: first, replace any character names or IP references with generic descriptions (e.g., "a princess in a blue dress" instead of naming a specific character); second, add explicit art style declarations like "digital illustration in watercolor style" to push the generation away from photorealistic outputs that trigger deepfake detection; and third, avoid combining human subjects with any clothing or pose descriptors that might trigger the minor protection system. Community testing shows that these prompt engineering techniques achieve a 70-80% success rate for previously blocked prompts. When IMAGE_SAFETY blocks persist despite prompt changes, consider alternative generation services as a fallback — providers like laozhang.ai offer multi-model access at $0.05/image through unified API endpoints, allowing you to route around persistent blocks without changing your application architecture.
The impact of the January 2026 update varies significantly by use case. E-commerce applications generating product mockups with models wearing clothing are rated as high impact — the minor protection filters sometimes activate on otherwise innocuous fashion imagery, particularly when the prompt describes young-looking models. Creative design applications that previously relied on generating fan art or parody images of well-known characters are critically impacted, as the new COPYRIGHT_INFRINGEMENT category in Layer 2 blocks these requests at the image analysis level rather than the prompt level, meaning even highly abstracted descriptions of recognizable characters get caught. General-purpose applications that generate landscapes, objects, abstract art, or non-celebrity human subjects are minimally affected by the update and will see little change in their block rates. The key diagnostic question is always the same: check finishReason in the API response. If it says SAFETY, your configuration is the issue. If it says IMAGE_SAFETY, the content itself triggered the filter and you need to modify your approach to the prompt.
Rate Limits and Quotas: Free vs Pro vs API
Understanding exactly where your rate limit ceiling sits is essential for capacity planning and for diagnosing whether a 429 error is a per-minute rate issue or a daily quota issue. Nano Banana Pro's pricing structure has five distinct tiers, each with dramatically different limits that determine how many images you can generate and how fast. For an in-depth comparison with pricing analysis, see our detailed comparison of free and Pro tier limits.
| Tier | Monthly Cost | Daily Images | RPM | Per-Image Cost | Best For |
|---|---|---|---|---|---|
| Free (Gemini App) | $0 | ~2/day | N/A | $0 | Casual testing |
| Free (API) | $0 | Limited | 15 | $0 | Development/prototyping |
| Google AI Pro | $19.99/mo | ~100/day | 60 | ~$0.20 | Individual creators |
| Google AI Ultra | $249.99/mo | ~1,000/day | 300 | ~$0.25 | Professional teams |
| Pay-as-you-go (API) | Usage-based | No daily cap | Tier-based | $0.039-$0.134 | Production applications |
Pricing data sourced from ai.google.dev/pricing and gemini.google/subscriptions, verified February 2026. Note: the free tier allocation differs between the Gemini App (approximately 2 images per day through the web interface) and the API (limited free quota which Google marks as "Not available" on the official pricing page for image generation — this likely reflects API-specific restrictions while the Gemini App maintains a small free allowance).
The pay-as-you-go API tier deserves special attention because it is the most cost-effective option for production use. With Gemini 3 Pro Image Preview at approximately $0.134 per image (1K/2K resolution) and Gemini 2.5 Flash at $0.039 per image (ai.google.dev/pricing, February 2026), the per-image cost is significantly lower than subscription-based plans once you exceed roughly 150 images per month. The trade-off is that API access requires more technical setup and you manage your own rate limiting. For teams generating hundreds or thousands of images daily, the API path is the clear winner both economically and in terms of flexibility. If you are currently on the Pro subscription and regularly hitting the ~100/day limit, switching to pay-as-you-go API access removes the daily cap entirely — you pay only for what you generate, and rate limits are managed through quotas that can be increased by request. For cost optimization beyond Google's native pricing, platforms like laozhang.ai offer Nano Banana Pro access at $0.05 per image with no rate limit restrictions, which is particularly attractive for high-volume applications.
Understanding which quota you have exhausted is critical for choosing the right recovery strategy. When you receive a 429 error, the error message typically includes a hint about which specific quota was exceeded. If you see Quota exceeded for quota metric 'generate_content' and limit 'GenerateContent request limit per minute', the fix is simply to wait 60 seconds and your per-minute allowance resets. If the message references a daily limit, you are locked out until midnight Pacific Time. And if it mentions a token-per-minute limit, you need to reduce either the frequency or the size of your requests — this is particularly relevant for multi-turn image editing conversations that accumulate large token histories. Logging these distinctions in your error handling code is the difference between a 60-second recovery and a 24-hour outage.
Production-Grade Error Handling Code
Moving from understanding errors to handling them automatically in production requires a robust retry system with fallback logic. The following Python implementation demonstrates how to combine exponential backoff, Layer 1 safety configuration, model fallback for 503 errors, and proper logging into a single reusable function. This code is designed to be copied directly into your application.
pythonimport google.generativeai as genai import time import random import logging logging.basicConfig(level=logging.INFO) logger = logging.getLogger("nano_banana_pro") SAFETY_SETTINGS = [ {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"}, ] def generate_image_with_retry( prompt: str, api_key: str, max_retries: int = 5, primary_model: str = "gemini-3-pro-image-preview", fallback_model: str = "gemini-2.5-flash-image", ) -> dict: """Generate image with exponential backoff, safety config, and model fallback.""" genai.configure(api_key=api_key) current_model = primary_model for attempt in range(max_retries): try: model = genai.GenerativeModel(current_model) response = model.generate_content( prompt, safety_settings=SAFETY_SETTINGS, generation_config={"response_modalities": ["TEXT", "IMAGE"]}, ) # Check finishReason for safety blocks if response.candidates: finish_reason = response.candidates[0].finish_reason.name if finish_reason == "SAFETY": logger.warning("Layer 1 SAFETY block — check safety_settings") return {"status": "blocked_layer1", "reason": finish_reason} elif finish_reason == "IMAGE_SAFETY": logger.warning("Layer 2 IMAGE_SAFETY block — rewrite prompt") return {"status": "blocked_layer2", "reason": finish_reason} elif finish_reason == "STOP": return {"status": "success", "response": response} return {"status": "success", "response": response} except Exception as e: error_str = str(e) # 429: Rate limit — exponential backoff if "429" in error_str or "RESOURCE_EXHAUSTED" in error_str: wait = min(2 ** attempt + random.uniform(0, 1), 60) logger.info(f"429 rate limit, waiting {wait:.1f}s (attempt {attempt+1})") time.sleep(wait) continue # 503: Overloaded — switch to fallback model if "503" in error_str or "overloaded" in error_str.lower(): if current_model != fallback_model: logger.info(f"503 overloaded, switching to {fallback_model}") current_model = fallback_model continue wait = min(2 ** attempt * 5, 120) logger.info(f"503 on fallback too, waiting {wait:.1f}s") time.sleep(wait) continue # 500/502: Transient — simple retry if "500" in error_str or "502" in error_str: wait = min(2 ** attempt + random.uniform(0, 1), 30) logger.info(f"Server error, retrying in {wait:.1f}s") time.sleep(wait) continue # Unknown error — do not retry logger.error(f"Unhandled error: {error_str}") return {"status": "error", "message": error_str} return {"status": "max_retries_exceeded", "model": current_model}
This code handles the four most critical scenarios automatically. For 429 rate limit errors, it implements exponential backoff with jitter to avoid thundering herd problems when multiple requests hit the limit simultaneously. For 503 overloaded errors, it first switches to the faster Gemini 2.5 Flash model as a fallback before resorting to longer waits — this trade-off between image quality and availability is usually acceptable in production. For transient 500/502 errors, it retries with moderate backoff since these typically resolve within a few attempts. And for IMAGE_SAFETY blocks (both Layer 1 and Layer 2), it returns immediately with a clear status indicating which layer blocked the request, because retrying the same prompt against the same safety filter is pointless.
The fallback model strategy deserves particular emphasis. When Gemini 3 Pro returns 503 errors during peak load, Gemini 2.5 Flash is almost always available because it requires fewer computational resources. The cost difference is substantial — $0.039 per image for Flash versus $0.134 for Pro (ai.google.dev/pricing, February 2026) — so you actually save money during degraded periods. For a detailed step-by-step debugging workflow that extends beyond automated retries, see our debugging guide.
Beyond the core retry logic, there are three production patterns worth implementing. First, add request queuing with a dead-letter queue for requests that fail all retries — this prevents user-visible errors and allows you to process failed requests during off-peak hours when Nano Banana Pro has more capacity. Second, implement circuit breaker logic that stops sending requests to a specific model after detecting a pattern of 503 errors (e.g., 5 failures in 60 seconds), automatically routing all traffic to the fallback model until a health check succeeds. Third, add monitoring and alerting that tracks your error rates by category in real time. When your 429 rate exceeds 10% of requests, you are approaching your tier's limits and should consider upgrading or distributing load across additional API keys. When 503 errors spike above 25%, a capacity event is likely in progress and your circuit breaker should activate the fallback model automatically. These patterns transform error handling from reactive debugging into proactive reliability engineering.
When to Consider Alternative Providers
Not every Nano Banana Pro error has a quick fix. If you are experiencing persistent 503 errors during peak hours, repeated IMAGE_SAFETY blocks that resist prompt engineering, or daily quota limits that constrain your production application, it may be time to evaluate multi-model strategies. This is not about abandoning Nano Banana Pro — it remains one of the most capable image generation models available — but about building resilience into your application architecture. For a head-to-head quality and reliability comparison, see our comparison with alternative image models like Flux2.
The most practical approach is to implement a primary/fallback pattern where Nano Banana Pro handles the majority of requests and an alternative provider catches failures. Services like laozhang.ai are designed for exactly this use case: they provide a unified API endpoint that aggregates multiple image generation models (including Nano Banana Pro itself, Flux, DALL-E, and others) at a flat $0.05/image rate. When your primary Nano Banana Pro call fails with a 503 or IMAGE_SAFETY block, your error handling code routes the request to the alternative endpoint without requiring prompt rewriting or API changes. The economic benefit is clear — you pay only for the fallback requests that actually occur, and you avoid the user-facing failures that damage trust in your application.
Evaluate switching to an alternative provider or multi-model strategy if three or more of these conditions apply: your 503 error rate during peak hours exceeds 20%, IMAGE_SAFETY blocks affect more than 10% of your legitimate prompts, your daily generation volume consistently exceeds your tier's quota, and you require 99.9%+ uptime SLAs that a single Preview-stage model cannot guarantee. Gemini 3 Pro Image Preview (model ID gemini-3-pro-image-preview) is explicitly in Preview status as of February 2026 (ai.google.dev/docs/models), which means Google does not offer production SLA guarantees. Building multi-provider resilience now is an investment in stability.
The implementation cost of adding a fallback provider is minimal if your error handling is already structured well. In the production code shown above, add a secondary API call in the max_retries_exceeded return path that routes to your fallback endpoint. The key architectural principle is that your application logic should never depend on a single image generation provider — abstract the generation call behind an interface that accepts a prompt and returns an image, and swap the underlying implementation based on availability. This pattern is common in mature production systems handling image generation at scale, and it transforms Nano Banana Pro errors from application failures into graceful quality trade-offs that are invisible to your end users.
FAQ
How long does a 429 RESOURCE_EXHAUSTED error last?
Most 429 errors on Nano Banana Pro resolve within 1-5 minutes for per-minute rate limits. If you have exhausted your daily quota, the limit resets at midnight Pacific Time. The key mistake to avoid is aggressive retrying — each retry attempt during the cooldown period counts against your rate limit, potentially extending the lockout. Implement exponential backoff starting at 1-2 seconds and cap your maximum wait at 60 seconds for per-minute limits.
Can you bypass the IMAGE_SAFETY filter on Nano Banana Pro?
You cannot bypass Layer 2 IMAGE_SAFETY filters because they operate at Google's infrastructure level, not through your API configuration. However, you can eliminate Layer 1 SAFETY blocks by setting all safety_settings categories to BLOCK_NONE in your API call. For Layer 2 blocks, the only approach is prompt engineering: replace character names with generic descriptions, add explicit art style declarations, and avoid combining human subjects with potentially triggering descriptors. Community testing shows 70-80% success rates with these techniques.
Why does Nano Banana Pro keep saying "generated images may contain unsafe content"?
This message indicates a Layer 2 IMAGE_SAFETY block, which was significantly strengthened in the January 2026 policy update. The filter now checks the generated image itself (not just your prompt) against copyright databases, CSAM detectors, and deepfake classifiers. If you are seeing this message, your prompt is generating visual features that trigger one of these classifiers. Try adding explicit art style declarations like "watercolor illustration" or "flat vector art" to push the output away from photorealistic styles that activate the deepfake detector.
What is the difference between finishReason SAFETY and IMAGE_SAFETY?
finishReason: SAFETY means Layer 1 (prompt moderation) blocked your request before image generation began. This is configurable — set safety_settings thresholds in your API call to resolve it. finishReason: IMAGE_SAFETY means Layer 2 (generation monitoring or output moderation) blocked the request during or after image creation. This is not configurable through any API setting. The fix for SAFETY is always configuration; the fix for IMAGE_SAFETY is always prompt rewriting.
Is Nano Banana Pro free to use?
Nano Banana Pro has a limited free tier through the Gemini App (approximately 2 images per day). For API access, the free tier is highly restricted — Google's official pricing page marks free image generation as "Not available" for the API (ai.google.dev/pricing, February 2026). Paid options start at $19.99/month for Google AI Pro (approximately 100 images/day) or pay-as-you-go API pricing at $0.039-$0.134 per image depending on the model and resolution. For the most complete breakdown, see our detailed comparison of free and Pro tier limits.
How do I check if Nano Banana Pro is down?
Check the Google AI Status Dashboard first for any ongoing incidents. If the status page shows no issues but you are still getting 503 errors, the problem is likely regional capacity constraints rather than a global outage. Try generating a simple test image with a basic prompt to confirm whether the issue is with Nano Banana Pro specifically or with your request parameters. Community forums on discuss.ai.google.dev also provide real-time reports from other developers experiencing the same issues.