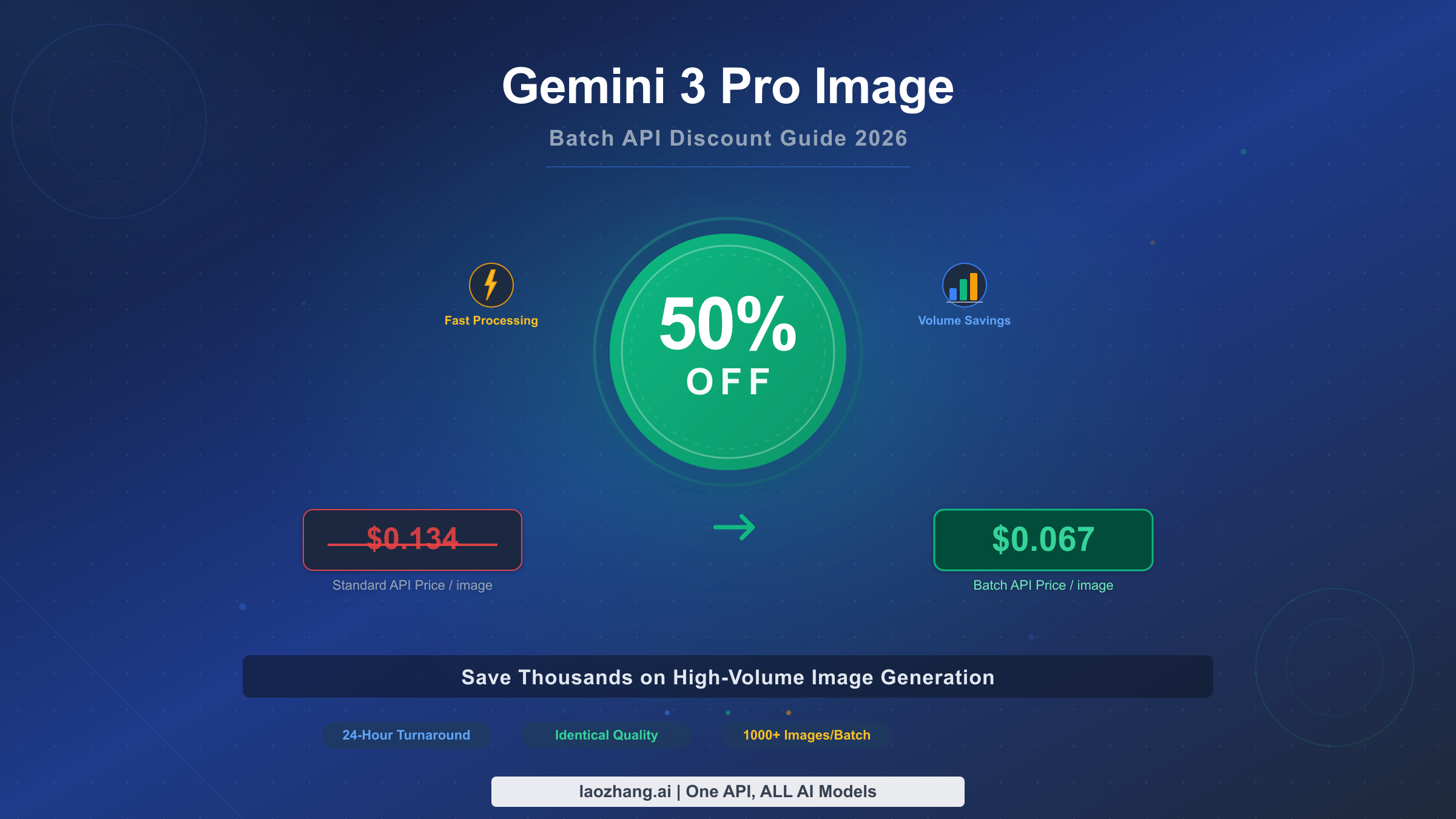
Google's Gemini 3 Pro Image Batch API provides a flat 50% discount on all image generation requests, reducing 2K image costs from $0.134 to $0.067 and 4K images from $0.24 to $0.12 per image (Google AI official pricing, February 2026). For teams generating hundreds or thousands of images monthly, this single change can save thousands of dollars without sacrificing any image quality. This guide walks you through exactly how the batch discount works, how to implement it in Python, and how to stack additional strategies for savings up to 80%.
Understanding the Gemini 3 Pro Image Batch API Discount
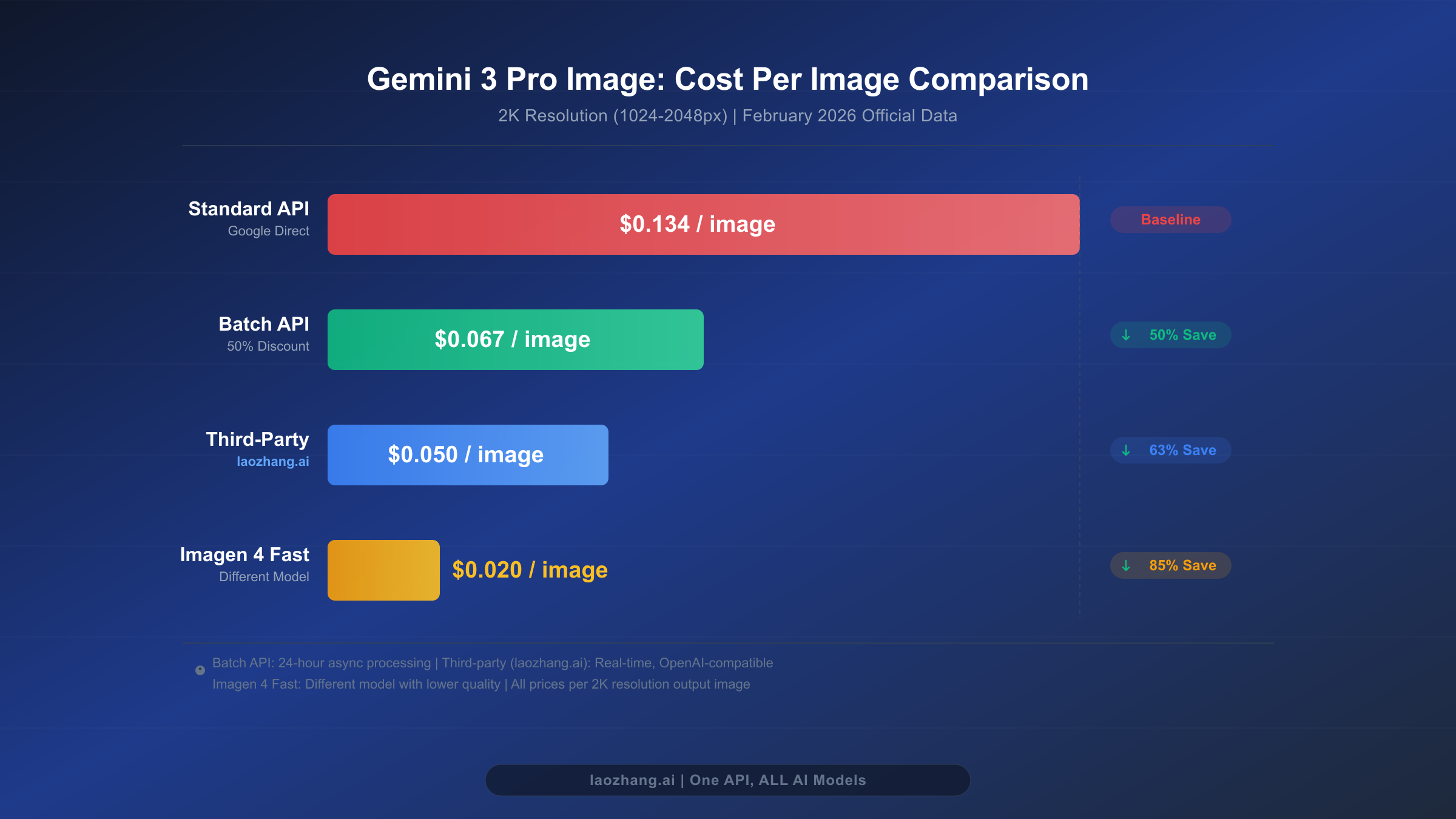
The Gemini 3 Pro Image model — internally codenamed Nano Banana Pro and accessed via the gemini-3-pro-image-preview model ID — is Google's most capable image generation model as of February 2026. It delivers exceptional text rendering accuracy at 94%, professional-grade output quality with an FID score of 12.4, and support for resolutions up to 4K. However, its standard API pricing at $0.134 per 2K image can add up quickly when you move beyond occasional use into production-scale image generation. That is precisely where the Batch API discount becomes transformative.
The Batch API applies a straightforward 50% reduction across all pricing tiers. When you submit image generation requests through the batch endpoint instead of the standard synchronous API, Google charges exactly half the normal rate. This discount is not promotional or time-limited — it is a permanent feature of the Batch API designed to incentivize asynchronous workloads that are easier for Google to schedule and process efficiently. The trade-off is simple: you accept a processing window of up to 24 hours in exchange for cutting your costs in half. For a detailed breakdown of all Gemini 3 Pro Image pricing tiers, you can refer to our comprehensive Gemini 3 Pro Image pricing and speed test guide.
Here is exactly how the pricing breaks down across resolutions:
| Resolution | Standard API Price | Batch API Price | Savings |
|---|---|---|---|
| 1K (up to 1024px) | $0.134/image | $0.067/image | 50% |
| 2K (1024-2048px) | $0.134/image | $0.067/image | 50% |
| 4K (up to 4096px) | $0.240/image | $0.120/image | 50% |
One detail worth noting is that the text input cost for prompts is also halved — from $2.00 to $1.00 per million tokens. However, for a typical image generation prompt of around 100-150 tokens, this translates to roughly $0.0001 per request, making it essentially negligible compared to the image output cost. The real savings come entirely from the output pricing reduction.
How the Batch API Actually Works for Image Generation
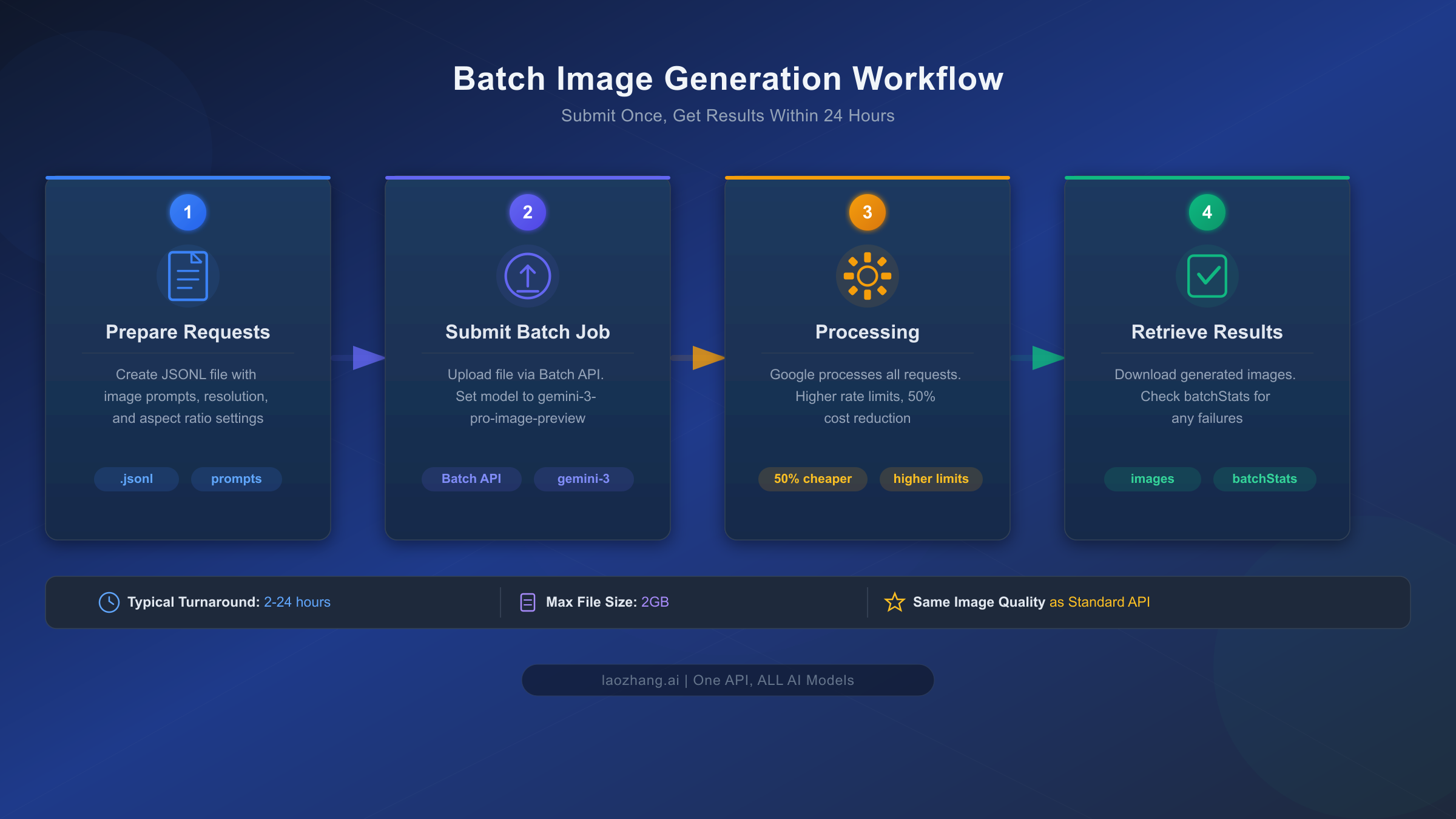
Understanding the mechanics of batch processing is essential before you decide whether it fits your workflow. The Batch API is not a separate model or a degraded service — it uses the exact same Gemini 3 Pro Image model with identical quality, resolution capabilities, and feature support. The only difference is the delivery timeline: instead of receiving your generated image within 8-12 seconds, you submit a collection of requests and retrieve the completed results within a processing window that targets 24 hours but frequently completes much faster.
The batch processing pipeline operates in four distinct stages. First, you prepare your requests by creating either an inline list of generation requests (suitable for smaller batches under 20MB) or a JSONL file where each line contains a complete request object (recommended for larger workloads up to 2GB). Each individual request within the batch supports the full range of Gemini 3 Pro Image capabilities — you can specify resolution (1K, 2K, or 4K using uppercase notation), aspect ratios across ten supported formats from 1:1 to 21:9, reference images for style consistency, and even enable Google Search grounding for real-time data visualization. The model processes each request independently within the batch, meaning a failure in one request does not affect the others.
Second, you submit the batch job through the Batch API endpoint, specifying the model and your request source. Google assigns a unique batch job ID and begins scheduling your requests for processing. The system automatically manages rate limiting, retry logic, and request distribution — eliminating the client-side complexity you would normally need to handle with synchronous API calls. This is a significant operational benefit beyond just the cost savings, particularly for teams that have been building custom queuing systems to manage high-volume generation workloads.
Third, during processing, Google executes your requests with higher rate limits than the standard API provides. While the standard synchronous API enforces per-minute and per-day rate limits that can throttle high-volume operations, the Batch API was specifically designed for throughput. According to the Gemini API rate limits documentation, batch jobs can process hundreds of thousands of requests in a single submission. The processing typically completes well within the 24-hour window — many users report turnaround times of 2-6 hours for moderate batch sizes.
Finally, you retrieve the results by polling the batch job status or setting up a callback. Each completed request includes the generated image data along with any text responses and metadata. The system also provides a batchStats object with counts of successful and failed requests, allowing you to identify and retry any failures programmatically. Jobs that remain in a pending or running state for more than 48 hours are automatically expired, though this is an edge case that rarely occurs in practice.
Real Savings Calculator — Costs at Every Volume
The per-image pricing difference becomes dramatically meaningful when multiplied across realistic production volumes. Most articles about the Batch API discount stop at showing the per-image price, but what actually matters for budget planning is the monthly and annual cost at the volume you operate. The following table shows exactly what you would pay across four pricing options at common production volumes, all calculated for 2K resolution images.
| Monthly Volume | Standard API | Batch API | Third-Party (laozhang.ai) | Imagen 4 Fast |
|---|---|---|---|---|
| 100 images | $13.40 | $6.70 | $5.00 | $2.00 |
| 500 images | $67.00 | $33.50 | $25.00 | $10.00 |
| 1,000 images | $134.00 | $67.00 | $50.00 | $20.00 |
| 5,000 images | $670.00 | $335.00 | $250.00 | $100.00 |
| 10,000 images | $1,340.00 | $670.00 | $500.00 | $200.00 |
| 50,000 images | $6,700.00 | $3,350.00 | $2,500.00 | $1,000.00 |
Annual savings comparison at 5,000 images/month:
| Pricing Option | Monthly Cost | Annual Cost | Annual Savings vs Standard |
|---|---|---|---|
| Standard API | $670.00 | $8,040.00 | — |
| Batch API | $335.00 | $4,020.00 | $4,020 saved (50%) |
| Third-Party | $250.00 | $3,000.00 | $5,040 saved (63%) |
| Imagen 4 Fast | $100.00 | $1,200.00 | $6,840 saved (85%) |
The Imagen 4 Fast numbers require an important caveat: while it is the cheapest option at $0.02 per image, it is a fundamentally different model with lower text rendering accuracy (approximately 85% versus Gemini 3 Pro Image's 94%), fewer supported resolutions, and no support for reference images or multi-turn editing. If your use case demands the highest quality text-in-image rendering, character consistency, or 4K output, Gemini 3 Pro Image remains the appropriate choice — and the Batch API is the most straightforward way to reduce its cost.
For teams processing 10,000 or more images monthly, the annual savings from switching to the Batch API alone exceed $8,000 compared to standard pricing. When combined with third-party providers for latency-sensitive workloads (discussed in the optimization section below), the savings potential grows even further.
Step-by-Step Batch Image Generation Guide
Implementing batch image generation requires minimal code changes if you are already using the Gemini API. The core workflow involves packaging your requests, submitting them as a batch, and retrieving the results. Before you start, make sure you have a valid API key — if you need one, follow our guide to getting your Nano Banana Pro API key.
Setting up your environment is straightforward. Install or update the Google Generative AI Python SDK with pip install -U google-genai, then you are ready to start creating batch jobs.
Creating a Batch Job with Inline Requests
For smaller batches (under 20MB total), you can embed requests directly. This approach is ideal for generating up to a few hundred images:
pythonfrom google import genai from google.genai import types import base64 import time client = genai.Client(api_key="YOUR_API_KEY") image_prompts = [ "A professional product photo of a minimalist ceramic vase on a marble surface", "An isometric illustration of a modern home office workspace", "A watercolor painting of a coastal sunset with sailboats", "A flat design infographic showing quarterly revenue growth", ] # Build inline requests with resolution and aspect ratio settings inline_requests = [] for prompt in image_prompts: inline_requests.append({ "contents": [{"parts": [{"text": prompt}], "role": "user"}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], "imageConfig": { "imageSize": "2K", "aspectRatio": "16:9" } } }) # Submit the batch job batch_job = client.batches.create( model="gemini-3-pro-image-preview", src=inline_requests, config={"display_name": "product-images-batch-001"} ) print(f"Batch job created: {batch_job.name}") print(f"State: {batch_job.state}")
Creating a Batch Job with JSONL File
For larger production workloads, the JSONL file approach supports up to 2GB of requests and is the recommended method for processing thousands of images:
pythonimport json import tempfile # Generate JSONL file with image requests prompts = [f"Product photo variation {i} of a leather backpack" for i in range(1000)] with tempfile.NamedTemporaryFile(mode='w', suffix='.jsonl', delete=False) as f: for prompt in prompts: request = { "contents": [{"parts": [{"text": prompt}], "role": "user"}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], "imageConfig": { "imageSize": "2K", "aspectRatio": "1:1" } } } f.write(json.dumps(request) + "\n") jsonl_path = f.name # Upload the JSONL file uploaded_file = client.files.upload(file=jsonl_path) # Submit batch job using the uploaded file batch_job = client.batches.create( model="gemini-3-pro-image-preview", src=uploaded_file, config={"display_name": "backpack-variations-1000"} ) print(f"Batch job created: {batch_job.name}")
Monitoring and Retrieving Results
Once submitted, you need to poll the job status and download results when processing completes:
pythonimport time from PIL import Image from io import BytesIO # Poll for completion while True: job = client.batches.get(name=batch_job.name) print(f"State: {job.state} | Progress: {getattr(job, 'batch_stats', 'N/A')}") if job.state == "JOB_STATE_SUCCEEDED": break elif job.state in ("JOB_STATE_FAILED", "JOB_STATE_CANCELLED"): print(f"Job ended with state: {job.state}") break time.sleep(60) # Check every minute # Retrieve and save generated images if job.state == "JOB_STATE_SUCCEEDED": for i, result in enumerate(job.results): if hasattr(result, 'response'): for part in result.response.candidates[0].content.parts: if hasattr(part, 'inline_data') and part.inline_data: img_data = base64.b64decode(part.inline_data.data) img = Image.open(BytesIO(img_data)) img.save(f"output_image_{i:04d}.png") print(f"Saved image {i}") # Check for failures stats = job.batch_stats print(f"\nCompleted: {stats.success_count} succeeded, {stats.failed_count} failed")
This complete implementation handles the entire batch lifecycle — from request preparation through result retrieval. The key advantage over building your own queuing system is that Google handles all retry logic, rate limiting, and scheduling automatically, while you benefit from both the 50% cost reduction and higher throughput limits.
Advanced Batch Processing — Monitoring, Errors, and Optimization
Moving beyond basic implementation, production batch processing requires robust error handling and optimization strategies. Understanding the batch job lifecycle and its edge cases helps you build reliable pipelines that process thousands of images without manual intervention.
Handling Partial Failures
Batch jobs can succeed overall while individual requests within them fail. This happens when a specific prompt triggers content safety filters, exceeds token limits, or encounters temporary processing errors. The batchStats object on a completed job tells you exactly how many requests succeeded and failed, but you need to inspect each result to identify which ones need retry:
python# Identify and collect failed requests for retry failed_requests = [] for i, result in enumerate(job.results): if hasattr(result, 'error'): failed_requests.append({ "index": i, "error": result.error, "original_prompt": image_prompts[i] }) if failed_requests: print(f"{len(failed_requests)} requests failed. Resubmitting...") retry_requests = [ {"contents": [{"parts": [{"text": fr["original_prompt"]}], "role": "user"}], "generationConfig": {"responseModalities": ["TEXT", "IMAGE"], "imageConfig": {"imageSize": "2K"}}} for fr in failed_requests ] retry_job = client.batches.create( model="gemini-3-pro-image-preview", src=retry_requests, config={"display_name": "retry-failed-images"} )
Optimizing Batch Size and Structure
Google's documentation recommends combining smaller requests into larger batch jobs for better throughput. Submitting one batch job with 10,000 requests performs significantly better than submitting 100 jobs with 100 requests each, because each job incurs scheduling overhead. However, extremely large jobs also carry more risk — if a system issue causes a job to fail, you lose the entire batch's progress. A practical balance is batching 1,000 to 5,000 requests per job, which provides efficient processing while limiting the blast radius of any single failure.
For organizations processing images at enterprise scale, consider implementing a job orchestration layer that splits your total workload into manageable batch jobs, tracks their completion status in a database, and automatically retries failed individual requests across new batches. This pattern provides both the cost benefits of batch processing and the reliability of granular request tracking.
Cancellation and Timeout Management
Jobs that have been submitted but not yet completed can be cancelled through the API. This is useful when you realize a batch contains errors or when business requirements change. Jobs left in a pending or running state for more than 48 hours are automatically expired by Google's system, though this timeout is generous enough that it rarely triggers under normal conditions. If you need tighter control over processing time, implement a client-side timeout that cancels jobs exceeding your acceptable window:
pythonimport datetime # Submit job and track start time start_time = datetime.datetime.now() max_wait_hours = 12 # Cancel if not done in 12 hours while True: job = client.batches.get(name=batch_job.name) elapsed = (datetime.datetime.now() - start_time).total_seconds() / 3600 if job.state == "JOB_STATE_SUCCEEDED": print(f"Completed in {elapsed:.1f} hours") break elif elapsed > max_wait_hours: client.batches.cancel(name=batch_job.name) print(f"Cancelled after {elapsed:.1f} hours") break time.sleep(300) # Check every 5 minutes
Batch vs Standard vs Third-Party — Which One Is Right for You?
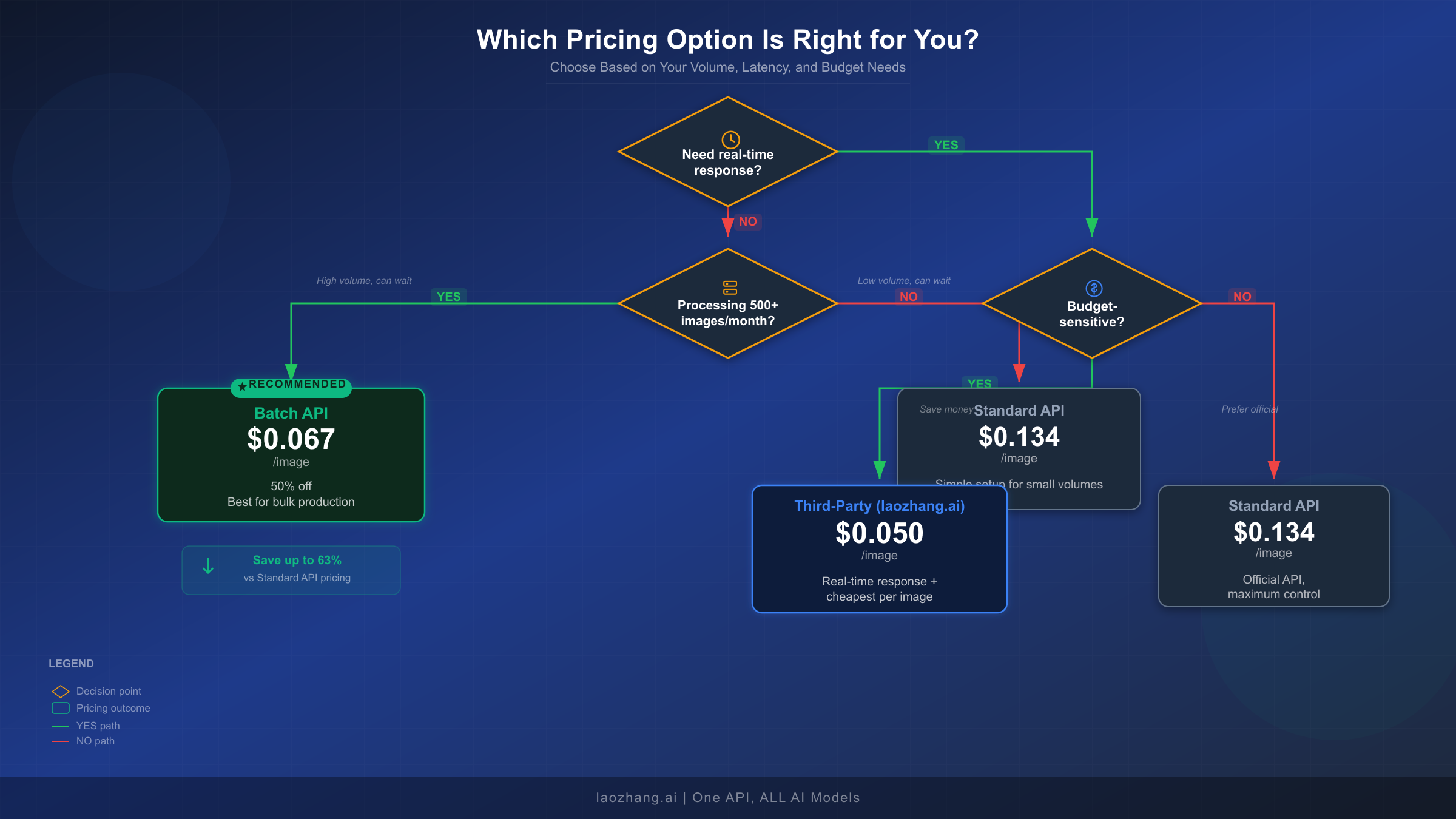
Choosing the right pricing option depends on three factors: your latency requirements, your monthly volume, and your budget sensitivity. Each option serves a distinct segment of use cases, and the right choice varies significantly based on your specific situation. For an even broader comparison across all AI image generation APIs, see our 2026 AI image generation API comparison.
The Standard API ($0.134/image) works best when you need real-time image generation with responses in 8-12 seconds, your monthly volume is under 500 images, or you require maximum control over the generation pipeline with direct synchronous feedback. Typical use cases include chatbot image generation, interactive design tools, and real-time content creation applications where users are waiting for results. The standard API gives you the simplest integration path with immediate response handling and no job management overhead.
The Batch API ($0.067/image) becomes the clear winner when you can tolerate processing delays of 2-24 hours, you are generating 500 or more images monthly, and cost reduction is a priority. This is the ideal choice for e-commerce product image catalogs where you generate images overnight for next-day listing updates, marketing teams producing batch campaign visuals for scheduled social media posts, content platforms generating illustration libraries, and any workflow where images are prepared in advance rather than on demand. The 50% savings compound dramatically at scale — a team generating 5,000 images monthly saves over $4,000 annually by switching from standard to batch processing.
Third-party providers like laozhang.ai ($0.05/image) offer a compelling alternative when you need both real-time responses and lower pricing than Google's standard API. These platforms provide access to the same Gemini 3 Pro Image model through their own infrastructure, typically at 60-80% below official pricing. The trade-off is that your requests route through a third-party service, which may raise considerations for sensitive workloads. For a detailed comparison of third-party options, our complete guide to finding the cheapest Gemini image API covers the major providers. Third-party providers are particularly well-suited for high-volume, latency-sensitive workloads where the Batch API's 24-hour window is too slow but standard API pricing is too expensive.
The optimal strategy for many production environments is actually a hybrid approach: use the Batch API for planned, high-volume generation tasks like catalog updates and campaign preparation, while routing urgent, real-time requests through a cost-effective third-party provider. This combination captures the deepest discounts for bulk work while maintaining responsiveness for interactive use cases.
Stacking Discounts — How to Save Up to 80% on Image Generation
The Batch API's 50% discount is the foundation, but it is not the only cost reduction strategy available. By combining multiple optimization techniques, you can reduce your effective cost per image from $0.134 down to as little as $0.027 — an 80% total reduction. Here are the strategies that stack together, ordered by their impact and ease of implementation.
Resolution optimization is the simplest and most impactful first step. If your output requirements allow it, generating images at 2K resolution instead of 4K reduces batch pricing from $0.12 to $0.067 per image — a 44% savings on top of the batch discount. Many web and social media applications display images at 1024px or smaller, making 4K generation unnecessary overhead. Audit your actual display sizes before defaulting to maximum resolution. For more details on resolution trade-offs, our Nano Banana Pro 4K guide covers this topic in depth.
Prompt optimization reduces token costs and improves generation consistency. While prompt input costs are negligible (approximately $0.0001 per request), shorter, more precise prompts actually produce better results than verbose descriptions. A concise 50-token prompt generates images with fewer artifacts and misinterpretations than a 500-token prompt stuffed with redundant details. This does not directly reduce per-image cost but improves your success rate, reducing the number of regenerations needed to achieve acceptable output.
Context caching, available even in batch mode, saves on repeated prompt elements. If you are generating multiple images with shared system instructions or style guidelines, context caching charges only 10% of the standard input price for cached content. For batch jobs where every request includes the same 1,000-token style guide, this reduces your per-request prompt cost by 90% — a minor but measurable optimization at very high volumes.
Combining batch processing with a third-party provider creates the deepest discount stack. For organizations with both planned and on-demand image generation needs, routing batch workloads through Google's Batch API at $0.067/image and real-time requests through laozhang.ai at $0.05/image produces an effective blended rate that beats any single pricing option. A team splitting 5,000 monthly images between 3,000 batch and 2,000 real-time would pay ($3,000 × $0.067) + ($2,000 × $0.05) = $301 per month, compared to $670 at standard pricing — a 55% blended savings.
The maximum savings scenario stacks batch processing (50% off), 2K resolution selection (saving the 4K premium), prompt optimization (fewer retries), and strategic use of Google AI Studio's daily free allocation (approximately 50 free images per day, or 1,500 per month). For a team needing 5,000 images monthly: 1,500 free + 3,500 batch at $0.067 = $234.50 per month, down from $670 at standard pricing — a 65% total reduction. Teams willing to route some volume through third-party providers can push total savings beyond 80%.
Frequently Asked Questions
Does the Batch API produce lower quality images than the Standard API?
No, the Batch API uses the identical Gemini 3 Pro Image model with the same quality, resolution support, and capabilities. The 50% discount is purely a pricing incentive for asynchronous processing — Google can schedule batch jobs more efficiently, and they pass those savings to users. Your batch-generated images are pixel-for-pixel equivalent to standard API output.
How long does batch image generation actually take?
Google's target turnaround is 24 hours, but in practice most batch jobs complete significantly faster. Users frequently report completion times of 2-6 hours for moderate batches (hundreds to low thousands of images). The actual processing time depends on system load, batch size, and the complexity of your image generation requests. For planning purposes, design your workflows to accommodate the full 24-hour window while expecting faster delivery.
What is the maximum number of images I can generate in one batch?
The Batch API supports up to 2GB of request data in a single JSONL file, which can contain hundreds of thousands of individual image generation requests. For inline requests, the limit is 20MB. There is no explicit cap on the number of requests per job, but Google recommends batching 1,000-5,000 requests per job for optimal throughput and manageability.
Is the Gemini 3 Pro Image free tier available for batch processing?
The Gemini 3 Pro Image model (gemini-3-pro-image-preview) does not have a free tier for either standard or batch API access (Google AI official pricing, February 2026). However, Google AI Studio provides approximately 50 free image generations per day through its web interface, which can supplement your paid API usage for testing and small-scale production.
Can I use reference images and multi-turn editing in batch mode?
The Batch API supports the full range of Gemini 3 Pro Image capabilities, including text-to-image generation, reference images (up to 14 per request: 6 object images and 5 human images), resolution control, aspect ratio selection, and Google Search grounding. However, multi-turn conversational editing is not directly supported in batch mode since batch requests are stateless — each request is processed independently without conversation context.