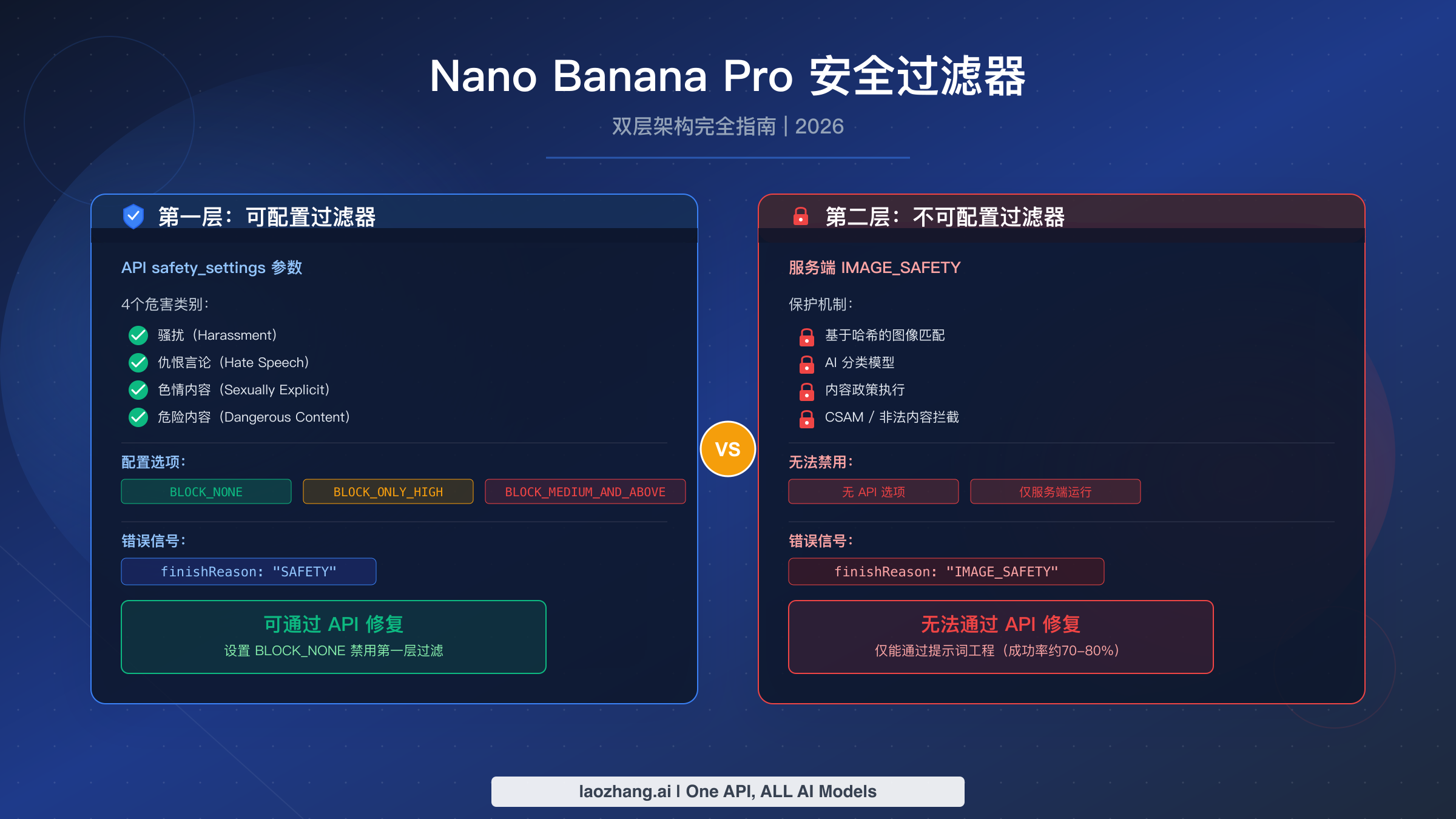
Nano Banana Pro 使用双层安全过滤系统,这让大多数开发者感到困惑。第一层(可配置)可以通过 API 的 safety_settings 参数设置为 BLOCK_NONE,从而移除对骚扰、仇恨言论、色情内容和危险内容类别的过滤。第二层(IMAGE_SAFETY)是不可配置的服务端过滤器,无法通过任何 API 设置禁用。截至2026年3月,最有效的方法是将第一层配置为 BLOCK_NONE,同时结合提示词工程技巧,在边界内容上实现70-80%的成功率。
要点速览
Nano Banana Pro 的安全过滤器在两个独立层上运行,而大多数开发者将它们混为一谈,导致浪费大量时间在错误的修复方向上。第一层过滤四个危害类别(骚扰、仇恨言论、色情内容、危险内容),可以通过在 API 调用中将 safety_settings 设置为 BLOCK_NONE 来完全禁用。当第一层拦截你的请求时,响应中会出现 finishReason: "SAFETY"。第二层是一个完全独立的服务端系统,称为 IMAGE_SAFETY,它使用 AI 分类、哈希匹配和政策执行来扫描生成的图像。当第二层拦截你时,响应显示 finishReason: "IMAGE_SAFETY",没有任何 API 配置可以禁用它。针对第二层的最佳选择是提示词工程(在边界内容上大约有70-80%的成功率),或切换到像 laozhang.ai 这样默认放宽第一层配置的平台。属于永久禁止类别的内容,如 CSAM、极端暴力或露骨色情,无法通过任何合法平台或技术生成。
为什么你的图像被拦截了(根因分析)
开发者在 Nano Banana Pro 安全过滤器上浪费时间的最大原因就是误诊。他们遇到图像被拦截,搜索"如何禁用安全过滤器",找到设置 BLOCK_NONE 的说明,实现了这些设置,然后发现图像仍然被拦截。问题不在于 BLOCK_NONE 不起作用——它对其控制范围内的内容效果完美。问题在于大多数拦截来自一个完全不同的系统,而 BLOCK_NONE 根本触及不到它。
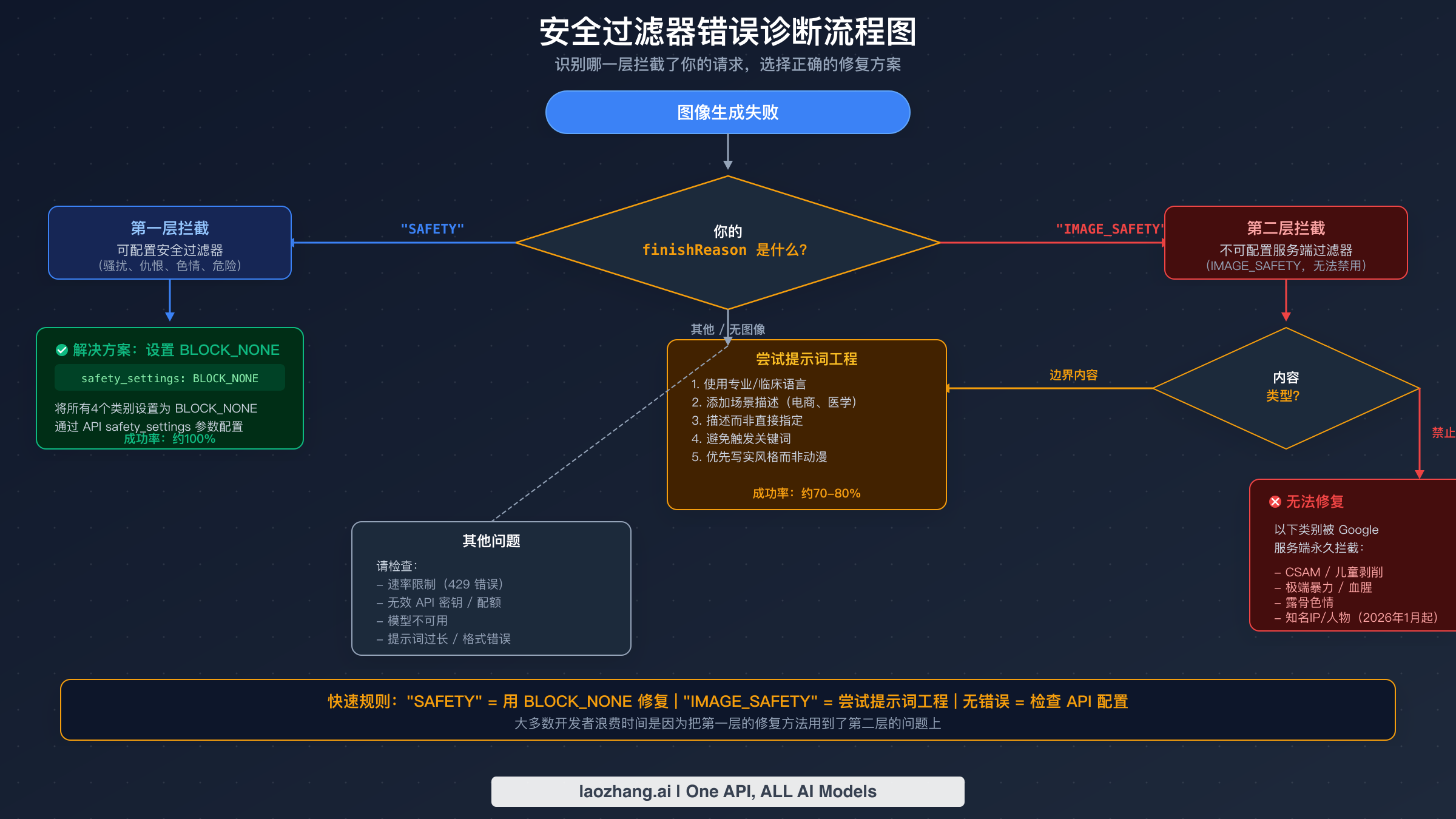
在尝试任何修复之前,理解哪一层负责你的特定拦截是至关重要的第一步。一旦你知道要找什么,诊断过程就非常直接:检查 API 响应中的 finishReason 字段。如果值是 "SAFETY",你面对的是第一层拦截——可以通过 safety_settings 配置的层。将所有四个危害类别设置为 BLOCK_NONE 几乎可以立即解决问题。如果值是 "IMAGE_SAFETY",你面对的是第二层——不可配置的服务端过滤器。任何 API 配置更改都无济于事。你需要使用提示词工程技巧,本指南后面会详细介绍。关于所有可能的错误响应的完整列表,请查看我们的完整错误代码参考。
许多开发者还会遇到第三种场景:没有返回图像,但 finishReason 既不是"SAFETY"也不是"IMAGE_SAFETY"。这通常表明是完全不同的问题——速率限制(HTTP 429)、无效的 API 密钥、配额耗尽或提示格式问题。这些不是安全过滤器问题,需要不同的解决方案。我们的故障排除与调试指南全面涵盖了这些情况。
误诊的代价非常高昂。通过官方 API 生成2K分辨率图像的价格为每张 $0.134(Google AI for Developers,2026年3月),一批1,000张图像如果有30%的拒绝率,大约浪费 $40 的失败 API 调用费用。对于运行10,000张以上批量图像的企业团队,每批次浪费的费用可高达 $400-700。在尝试修复之前正确诊断拦截层,既节省资金又节省工程时间。
双层安全过滤架构详解
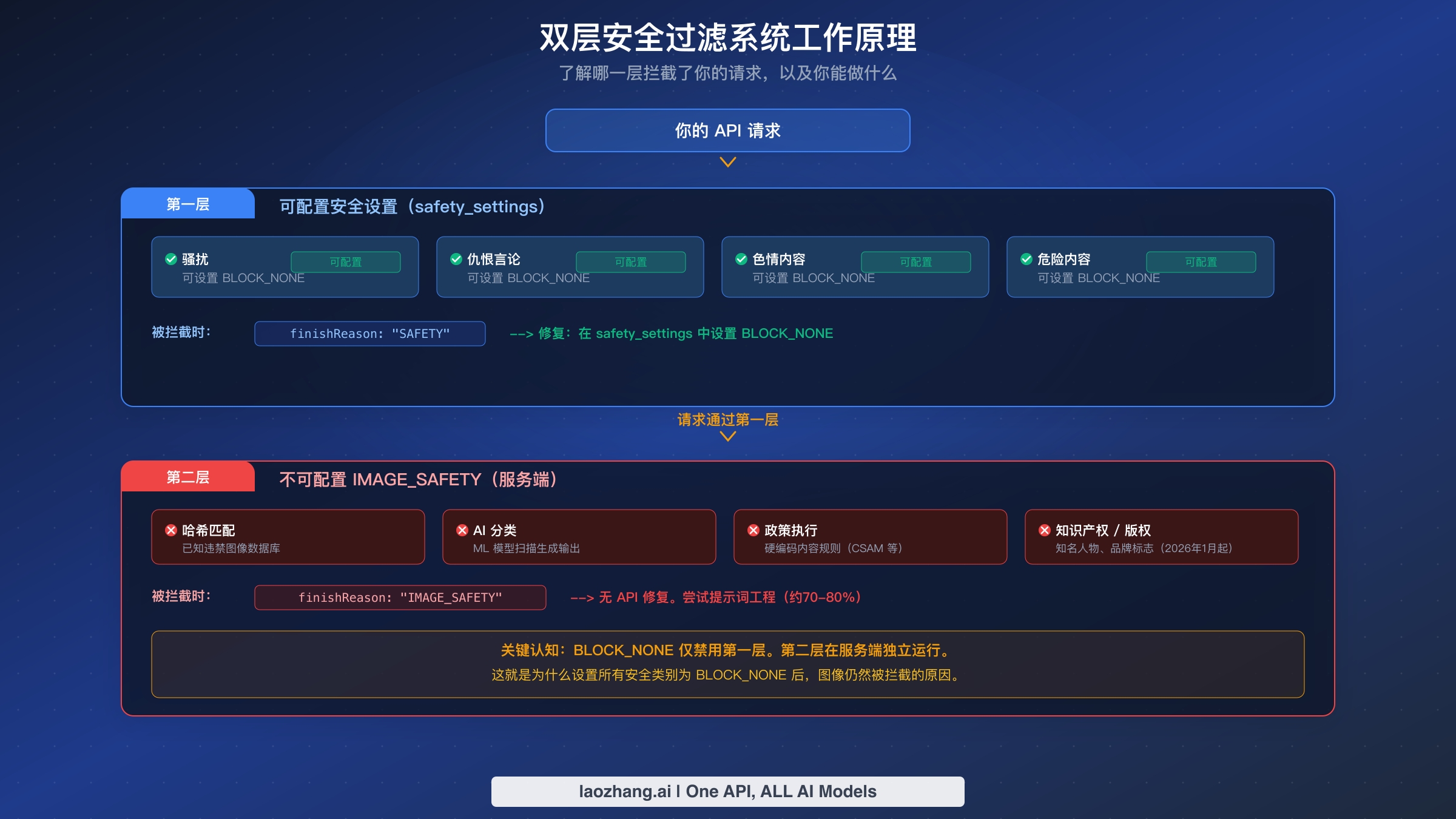
Nano Banana Pro 的安全系统通过两个完全独立的过滤层按顺序处理你的请求。从技术层面理解每一层的工作原理,对于构建可靠的图像生成流水线至关重要。Google 的官方文档解释了 safety_settings 参数,但明显回避了对 IMAGE_SAFETY 层的深入讨论,这就是为什么大多数开发者直到遇到它才意识到它的存在。
第一层工作原理(可配置)
第一层在图像生成开始之前,根据四个危害类别评估你的文本提示。每个类别——骚扰、仇恨言论、色情内容和危险内容——都会从 Google 的内容分类模型中获得一个概率分数。API 调用中的 safety_settings 参数定义了请求被拦截的阈值。BLOCK_LOW_AND_ABOVE 是最严格的设置,会拦截任何具有轻微危害可能性的内容。BLOCK_MEDIUM_AND_ABOVE 和 BLOCK_ONLY_HIGH 则逐步放宽。BLOCK_NONE 完全禁用该类别的第一层过滤,无论危害概率分数如何都允许你的提示通过。当第一层拦截请求时,API 响应包含 finishReason: "SAFETY" 以及 safetyRatings,显示具体是哪个类别以何种置信度触发了拦截。这些信息对于准确理解触发过滤器的原因非常有价值。
第二层工作原理(不可配置)
第二层基于根本不同的原理运行。它不评估输入提示,而是使用多种运行在服务端的检测机制来分析生成的图像输出。这些机制包括:与已知违禁图像数据库进行的感知哈希匹配、经过训练用于检测不安全视觉内容的 AI 分类模型,以及针对 CSAM 和极端暴力等特定类别的硬编码政策规则。2026年1月的政策更新新增了对知名人物和品牌标志的知识产权检测(迪士尼角色是报告最多的例子)。当第二层拒绝生成的图像时,响应包含 finishReason: "IMAGE_SAFETY",但不提供详细的安全评分——你只知道图像被拦截了,不知道确切原因。这种不透明性使第二层拦截比第一层拦截更难排查。
为什么它们是独立的
关键的认知在于这两层在架构上是分离的。第一层是生成前的文本分类器。第二层是生成后的图像分析器。设置 BLOCK_NONE 告诉第一层放行所有内容,但第二层从不接收或响应你的 safety_settings 配置。它按照自己的规则、自己的阈值完全独立运行。这就是为什么设置了 BLOCK_NONE 并期望零过滤的开发者,会在图像仍然被拦截时感到惊讶。他们成功禁用了一个过滤器,却让另一个完全不同的过滤器以全灵敏度运行。
配置第一层安全设置(可修复部分)
当你的 API 响应显示 finishReason: "SAFETY" 时,修复方法是将所有四个危害类别的 safety_settings 配置为 BLOCK_NONE。这是使用 Nano Banana Pro 安全过滤器中最直接的部分,无论你是生成图像还是做纯文本生成,代码都是一样的。如果你还没有设置 API 访问权限,我们的获取 API 密钥指南详细介绍了整个流程。
Python (google-generativeai SDK)
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-2.0-flash-exp") safety_settings = [ {"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"}, ] response = model.generate_content( "Generate a product photo of a summer swimsuit on a mannequin", safety_settings=safety_settings, generation_config={"response_modalities": ["TEXT", "IMAGE"]} )
Node.js (@google/generative-ai SDK)
javascriptconst { GoogleGenerativeAI, HarmCategory, HarmBlockThreshold } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-2.0-flash-exp" }); const safetySettings = [ { category: HarmCategory.HARM_CATEGORY_HARASSMENT, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_HATE_SPEECH, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT, threshold: HarmBlockThreshold.BLOCK_NONE }, ]; const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: "Generate a product photo of a summer swimsuit" }] }], safetySettings, });
cURL (REST API)
bashcurl -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-exp:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{"parts": [{"text": "Generate a product photo of a summer swimsuit"}]}], "safetySettings": [ {"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"} ], "generationConfig": {"responseMimeType": "text/plain"} }'
需要理解的重要一点是,设置 BLOCK_NONE 对于第一层拦截的成功率几乎是100%——它实际上完全禁用了该层。然而,像 laozhang.ai 这样的第三方 API 提供商默认配置就是 BLOCK_NONE,省去了你在每次请求中都要指定这些设置的麻烦。这对于需要最小摩擦的批量处理尤其方便。通过 laozhang.ai 每张图像大约 $0.05,而通过官方 API 为 $0.134(2026年3月定价),在规模化使用时成本节省相当可观。你可以在 docs.laozhang.ai 查看集成文档了解详情。
针对第二层的提示词工程(真正有效的方法)
当你的响应显示 finishReason: "IMAGE_SAFETY" 并且已经为第一层设置了 BLOCK_NONE 时,你面对的就是不可配置的服务端过滤器。此时唯一有效的方法是提示词工程——重新构造你的提示词,以生成相同的预期视觉输出,同时避免触发第二层分类模型的模式。基于对多个内容类别的广泛测试,特定的提示词转换技巧在边界内容上实现了大约70-80%的成功率(aifreeapi.com 分析,2026年3月)。
策略1:使用专业和临床语言
最广泛有效的技巧是用专业术语替换随意或暗示性的语言。第二层的分类模型是在语言模式而非仅仅关键词上训练的,因此你的提示词的措辞方式会显著影响其评估结果。对于电商内衣摄影,"一个女人穿着内衣性感地摆姿势"会持续触发拦截,而"人台上的女士内衣产品摄影,白色背景,目录风格"大约有80%的概率通过。关键的转换在于从描述穿着衣服的人转变为描述商业场景中的产品。关于避免风控触发的完整指南中,我们涵盖了数十种特定类别的提示词转换方法。
策略2:添加场景化描述
明确提供商业或教育场景有助于第二层的分类器将你的内容归类为合法内容。添加"用于电商产品目录""医学教育插图"或"时装设计参考"等短语,将内容置于模型识别为低风险的专业场景中。这种技巧之所以有效,是因为分类模型评估的是完整的提示词上下文,而不仅仅是单个关键词。以"用于在线零售商店产品页面"为由请求的泳装图像,所受的审查明显低于没有商业场景描述的相同图像。
策略3:优先选择写实风格而非动漫风格
测试一致表明,动漫和卡通风格会显著提高第二层的拒绝率,特别是涉及人物角色的内容。这是因为动漫风格的图像在模型训练数据中与违规内容的关联度不成比例地高。如果你的用例允许,将"动漫风格角色"改为"逼真数字艺术"或"照片级渲染"可以将相同内容的成功率提高20-30%。这是你能以最小努力做出的最有影响力的改变之一。
针对第二层的提示词工程的现实是,它需要反复实验。没有任何单一技巧可以普遍适用,而且 Google 会定期更新分类模型,这可能改变什么能通过什么不能通过。建立一个系统性评估你特定内容类别成功率的提示词测试流水线,是最可靠的长期方法。
平台对比:哪里的过滤器更宽松
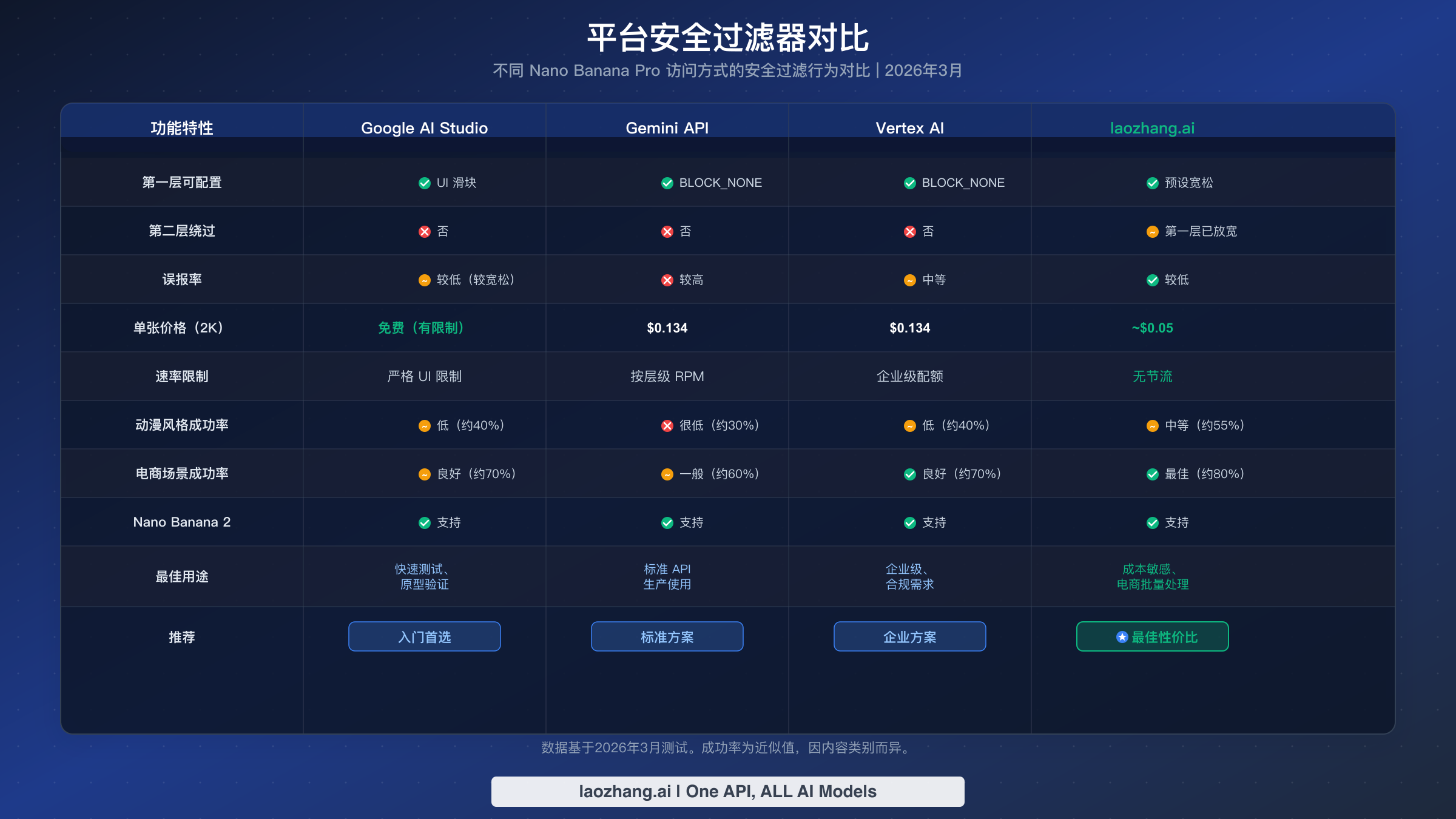
并非所有提供 Nano Banana Pro 图像服务的平台都以相同的严格程度应用安全过滤器。了解这些差异可以帮助你为特定用例选择合适的平台。此对比基于2026年3月进行的测试,代表了每个平台当前的过滤行为。如需更广泛地了解所有 AI 图像生成 API,请参阅我们的 AI 图像生成 API 对比。
Google AI Studio 是免费的网页界面,在 Google 生态系统中提供最宽松的体验。UI 中的安全过滤器滑块允许你降低灵敏度,整体过滤感觉比直接 API 更宽松。这使它成为一个很好的测试环境——如果你的提示词在 AI Studio 中有效但通过 API 失败,问题很可能是你的 safety_settings 配置而非第二层。但 AI Studio 有严格的使用限制,不适合生产批量处理。
Gemini API(直连)以全力运行两层过滤。第一层默认为中等灵敏度,但可以配置为 BLOCK_NONE。第二层以全力运行,在所有平台中误报率最高。这是大多数开发者的标准访问方式,也是你最可能遇到令人沮丧的合法内容 IMAGE_SAFETY 拦截的地方。关于定价详情和层级信息,请参阅我们的详细定价分析。
Vertex AI 提供企业级访问,过滤行为略有不同。虽然两层仍然都在运行,但误报率似乎比直连 Gemini API 略低,可能是由于不同的模型部署配置。Vertex AI 还提供数据驻留控制和合规功能,这些对企业部署很重要。
第三方提供商如 laozhang.ai 通过 Gemini API 路由请求,但默认将第一层预配置为 BLOCK_NONE,完全消除了该来源的拦截。每张图像大约 $0.05——比官方 $0.134 的费率低约62%——为大批量处理提供最佳性价比。虽然第二层仍然适用(没有合法提供商可以绕过服务端过滤),但更低的第一层摩擦加上更低的定价,使第三方提供商成为在 Google 内容政策范围内运营的电商和创意 AI 应用的首选。
无法修复的内容(知道何时停止)
本指南能告诉你的最有价值的信息之一就是何时停止尝试。某些内容类别被第二层的服务端执行永久且故意地拦截,无论多少提示词工程、API 配置或平台切换都无法通过 Nano Banana Pro 或任何基于 Google 图像生成基础设施的服务来生成这些图像。
**永久拦截的类别包括:**儿童性虐待材料(CSAM)以及任何描绘未成年人在性场景中的内容——这被全球所有合法 AI 图像生成服务拦截,不仅仅是 Google。没有教育或新闻目的的极端图形暴力和血腥内容被持续拦截。描绘性行为的完全露骨色情内容超出了任何提示词工程技巧所能绕过的范围。自2026年1月政策更新以来,对特定知名人士(特别是政治家、名人和公众人物)的逼真描绘以及受版权保护的角色(迪士尼角色被报告最多)也在服务端被拦截。
识别永久拦截的模式很直接:如果你在多个提示词变体、多种风格方法和多个会话中持续收到 finishReason: "IMAGE_SAFETY",并且内容属于上述类别之一,那么它就是被永久拦截的。继续尝试生成只会浪费 API 额度和工程时间。有建设性的前进路径是要么完全重新定义你的内容需求以避开被拦截的类别,要么评估可能对你特定用例有不同内容政策的替代图像生成平台。关于 Nano Banana Pro 与其他模型的对比,我们的 Nano Banana Pro 与 Nano Banana 2 对比分析了新模型如何以不同方式处理安全问题。
值得强调的是,这些永久拦截的存在有重要的法律和伦理原因。Google 在多个司法管辖区面临强制要求特定类别内容预防的监管要求,他们的做法与技术联盟和 NCMEC 等组织建立的行业标准一致。理解和尊重这些边界是负责任 AI 图像生成的一部分。
2026年政策变化及如何让你的流水线面向未来
2026年第一季度给 Nano Banana Pro 的安全过滤器行为带来了重大变化,随着 Google 持续优化系统,预计还会有更多变化。紧跟这些发展并构建有弹性的架构对生产部署至关重要。
**2026年1月带来了两个重大变化。**首先,Google 加强了第二层中的知识产权保护,增加了对知名人物、品牌标志和受版权保护角色的检测。迪士尼角色拦截是最明显的表现,在 Google 的开发者论坛上引发了广泛的开发者投诉。其次,据报道,基于地理 IP 的过滤限制收紧了,某些地区的一些开发者对之前通过的内容经历了更高的拒绝率。这些更改在服务端实施,不需要 API 变更,意味着现有代码继续工作,但一些之前成功的提示词开始失败。
2026年2月27日发布了 Nano Banana 2,基于 Gemini 2.5 Flash 而非 Pro 构建。早期测试表明 Nano Banana 2 有略微不同的安全过滤器校准,某些类别看起来更宽松,而其他类别变化不大。每张1K图像大约 $0.067(VentureBeat,2026年2月)——大约是 Nano Banana Pro 成本的一半——对于能够容忍可能不同的过滤行为的成本敏感型应用来说,它是一个有吸引力的替代方案。安全架构仍然是相同的双层系统,但具体阈值和分类模型有所不同。
构建面向未来的流水线需要预见到安全过滤器行为将持续演变。最具弹性的架构包括几个关键要素。首先,实现强大的错误处理,检测 finishReason 值并将失败适当路由——第一层失败路由到配置修复,第二层失败路由到提示词替代方案,永久拦截路由到人工审核。其次,为你的关键内容类别维护一个提示词变体库,这样当一个提示词开始失败时,你可以自动尝试替代方案。第三,监控你的拒绝率随时间的变化——突然增加通常表示政策变更。第四,考虑多提供商策略,在官方 API 上失败的请求可以路由到 laozhang.ai 等替代提供商,它们在应用 Google 政策更新方面可能有不同的时间。
常见问题
我能完全关闭 Nano Banana Pro 的安全过滤器吗?
你可以通过将所有四个危害类别(骚扰、仇恨言论、色情内容、危险内容)的 safety_settings 设置为 BLOCK_NONE 来完全禁用第一层。然而,第二层(IMAGE_SAFETY)在服务端运行,无法通过任何 API 参数、SDK 设置或账户配置来禁用。这种双层设计是有意为之的,影响所有访问方式,包括 Google AI Studio、Gemini API 和 Vertex AI。
为什么设置 BLOCK_NONE 后图像仍然被拦截?
这是 Nano Banana Pro 最常见的困惑。设置 BLOCK_NONE 只禁用第一层。如果你的响应显示 finishReason: "IMAGE_SAFETY"(而不是 "SAFETY"),拦截来自第二层,它独立运行。第二层使用 AI 分类和哈希匹配来分析生成的图像本身。你的选择是提示词工程(在边界内容上有70-80%的成功率)或接受某些内容类别被永久拦截的事实。
Nano Banana 2 比 Nano Banana Pro 限制更少吗?
Nano Banana 2 于2026年2月27日发布,使用相同的双层安全架构。早期测试表明分类阈值校准有所不同——某些类别看起来稍微宽松,而其他类别保持不变。每张图像成本大约是 Nano Banana Pro 的一半($0.067 vs $0.134),值得用你的特定内容进行测试,看看它是否更适合你的需求。
Google AI Studio 和 Gemini API 在安全过滤器方面有什么区别?
Google AI Studio 通常比直连 Gemini API 应用更宽松的过滤,特别是对于边界内容。两个平台使用相同的双层系统,但 AI Studio 的默认灵敏度阈值似乎更低。这使得 AI Studio 可以作为诊断工具使用——如果你的提示词在那里有效但通过 API 失败,重点关注你的第一层 safety_settings 配置。
我因为安全过滤器拒绝损失了多少钱?
以 Nano Banana Pro 官方 API 每张2K图像 $0.134 的费率(Google AI for Developers 定价,2026年3月),1,000张图像批次中30%的拒绝率大约浪费 $40 的 API 调用费用。10,000张图像则是 $400。将你的提示词优化到将拒绝率从30%降低到10%,每1,000张图像节省 $27。使用像 laozhang.ai 这样每张约 $0.05 的提供商,同时降低了单张图像成本和因拒绝浪费的成本。
Google 最终会让第二层可配置吗?
目前没有任何迹象表明 Google 将使第二层变为可配置。Google 已经公开承认他们的过滤器"比预期的更加谨慎",并承诺减少误报,但可配置(第一层)和不可配置(第二层)安全的架构分离似乎是一个由法律和监管要求驱动的深思熟虑的设计决策,而非技术限制。