
Nano Banana Pro 的风控机制包含五个不同类别,可能阻止或减慢你的图像生成:内容安全过滤、速率限制、服务端限流、账号级别限制和基于 IP 的管控。基于对 Gemini API 的测试(2026 年 2 月验证),合理的提示词工程可以在此前被拦截的内容上达到 70-80% 的成功率,而正确的 API 配置可以完全消除配置相关的误判。本指南涵盖所有五种风控类型的预防策略,提供可直接用于生产环境的代码和经过测试的提示词模板。
要点速览
Nano Banana Pro(Google 的 Gemini 3 Pro Image 模型)有两个独立的过滤层:四个可配置的安全类别(可设置为 BLOCK_NONE),以及无论你如何设置都始终生效的不可配置输出过滤器(IMAGE_SAFETY、CSAM、SPII)。大多数开发者只处理了其中一层。实现可靠图像生成的关键在于三管齐下:针对不可配置层优化提示词(70-80% 成功率),正确配置 API 以处理可配置层(消除误判),并为剩余失败构建自动供应商回退机制。通过这些策略,你可以实现超过 95% 的管线可靠性,每张成功图像的有效成本为 $0.06-0.10。
理解 Nano Banana Pro 的 5 种风控类型
在深入解决方案之前,你需要准确了解是什么类型的风控在拦截你的请求。Nano Banana Pro 有五个不同类别的限制,每种都有不同的症状、原因和解决方案。错误识别风控类型会浪费时间去应用错误的修复方法,这就是为什么系统化的分类方法比任何单一的解决方案都更重要。
根据社区测试数据,最常见的类型是速率限制,约占所有错误的 70%。当你的应用达到每分钟请求数(RPM)、每日请求数(RPD)或每分钟图片数(IPM)上限时,Google 会返回 429 错误码。修复方法很直接:实现指数退避、升级计费层级,或将请求分散到多个 API 密钥。关于速率限制层级和配额的深入了解,请参阅我们的速率限制完全指南,其中涵盖了从免费版到 Tier 3 的完整层级体系。
内容安全过滤是第二大影响类型,也是让开发者最头疼的一种。这包括可配置的 HARM_CATEGORY 过滤器和不可配置的 IMAGE_SAFETY 输出过滤器。触发时,你的请求要么返回带有安全评级注释的空响应,要么收到明确的 IMAGE_SAFETY 拦截原因。这两个子类型之间的区别至关重要,我们将在下一节详细介绍。如果你遇到特定的错误码,我们的 Nano Banana Pro 错误码完整参考提供了完整的诊断查找表。
服务端限流约占 15% 的失败率,在 2026 年 1 月 17 日的事件中尤为明显,当时响应时间从正常的 20-40 秒跳到超过 180 秒,许多请求完全超时。与速率限制(返回明确的 429 错误)不同,服务端限流表现为 502 或 503 错误,或者请求无限挂起。Google 不发布 Gemini API 的实时容量状态,因此唯一可靠的检测方法是监控你自己的响应时间和错误率。当检测到性能下降时,最佳策略是自动故障转移到替代供应商,而不是对过载的服务进行重试循环。我们的 resource exhausted 错误解决方案指南涵盖了你在这些事件中会遇到的具体错误模式。
账号级别限制是最严重的类型,也可能造成最大的损害。Google 的官方使用政策(2026 年 2 月 11 日更新)确立了明确的升级路径:首先是邮件警告,然后是临时速率限制降低,接着是临时账号暂停,最终是永久关闭。监控窗口跨越 55 天的存储数据,这意味着近两个月内的违规模式可以触发执行操作。特别危险的是,账号暂停会影响所有 Google Cloud 服务,而不仅仅是 Gemini API。
第五种类型是基于 IP 的限制,在 2026 年 1 月 24 日的政策调整后变得突出。在一起广泛报道的迪士尼知识产权事件导致停止侵权行动之后,Google 收紧了版权相关的过滤,并实施了地理执行差异。与大量自动化生成相关的某些 IP 范围面临更严格的审查,涉及可识别知识产权的请求会根据版权管辖区面临特定区域的拦截。这是最不可预测的风控类型,也是最难诊断的,因为错误消息通常与标准内容过滤器拦截相同。
| 风控类型 | 错误码 | 频率 | 可修复? | 最佳应对 |
|---|---|---|---|---|
| 速率限制 | 429 | ~70% | 是 | 退避 + 层级升级 |
| 内容过滤 | IMAGE_SAFETY / 空响应 | ~15% | 部分可修复(70-80%) | 提示词工程 + API 配置 |
| 服务端限流 | 502 / 503 / 超时 | ~10% | 否(等待恢复) | 供应商故障转移 |
| 账号级别 | 403 | ~4% | 需要申诉 | 合规审查 |
| IP 限制 | 不固定 | ~1% | 有限 | 网络轮换 |
Google 双层安全过滤器的实际工作原理

理解 Google 安全系统的架构是减少误判最重要的一步。大多数开发者犯的错误是将所有安全类别设置为 BLOCK_NONE,然后以为已经完全禁用了内容过滤。实际上,他们只处理了两个完全独立的过滤层中的一个,而导致大多数图像生成拦截的那一层完全未被触及。
第一层由四个可配置的有害内容类别组成,你可以通过 API 请求中的 safety_settings 参数来控制。这些类别是 HARM_CATEGORY_HARASSMENT、HARM_CATEGORY_HATE_SPEECH、HARM_CATEGORY_SEXUALLY_EXPLICIT 和 HARM_CATEGORY_DANGEROUS_CONTENT(Google AI for Developers,2026 年 2 月 19 日验证)。每个类别可以设置为五个阈值级别之一:OFF、BLOCK_NONE、BLOCK_ONLY_HIGH、BLOCK_MEDIUM_AND_ABOVE 或 BLOCK_LOW_AND_ABOVE。将这些设置为 BLOCK_NONE 是减少提示词级别内容分析误判的有效策略。当你的图像生成因提示词中的某些内容触发了其中一个类别而失败时,可配置设置就是你的修复方案。
第二层才是问题变得复杂的地方。这一层包括 IMAGE_SAFETY(输出图像分析)、CSAM 检测(儿童安全)、PROHIBITED_CONTENT 和 SPII(敏感个人身份信息)检测。这些过滤器分析的是生成的图像本身,而不仅仅是提示词,并且不能通过任何 API 设置禁用。即使将所有四个可配置类别设置为 BLOCK_NONE,第二层过滤器仍然完全活跃。这是设计使然:Google 对所有生成内容应用这些保护措施,不受开发者偏好影响,正如其官方安全文档所述。
实际含义很直接。当你收到 IMAGE_SAFETY 拦截时,意味着模型生成了(或开始生成)一张触发输出分析过滤器的图像。你的提示词可能完全通过了第一层,但生成的图像超过了第二层的阈值。这就是为什么相同的提示词有时成功有时失败:模型的随机生成过程每次产生略有不同的输出,而边缘情况有时会跨过第二层的阈值。
区分有效缓解策略和无效尝试的关键见解是:认识到第一层和第二层需要完全不同的策略。对于第一层,解决方案是 API 配置(在 API 配置章节中介绍)。对于第二层,解决方案是提示词工程,引导模型的输出远离触发输出分析器的内容。你无法通过配置来解决第二层拦截;你必须精心设计提示词,引导模型产生安全的视觉输出。这就是为什么正确的 API 配置加上策略性提示词工程的组合方法,效果远超任何单一策略。
真正有效的提示词工程策略
提示词工程是你对抗不可配置第二层过滤器的主要防线,而简单提示词和优化提示词之间的差异是巨大的。社区测试数据和多个 SERP 来源记录表明,当应用了适当的提示词工程技术时,边缘内容的成功率提高了 70-80%,而基本主题在通过艺术或专业上下文框架构建时,可以达到约 95% 的成功率。
基本原则是上下文声明。每个提示词都应该从建立艺术或专业上下文开始。不要直接描述你想要什么,而是将其框架化在一个被认可的创意领域中。当模型的安全系统理解输出目的是"专业产品摄影"而非对同一场景的直白描述时,它对内容的评估方式完全不同。这不是一种黑客手段或漏洞利用;它反映了安全模型在进行分类决策时如何权衡上下文。
风景和环境类提示词
对于自然场景,最有效的模式是先声明艺术媒介和风格,然后用具体的技术细节描述场景。像"生成一个海滩场景"这样的提示词存在中等风险,因为它足够模糊,模型可能产生被输出过滤器判定为有问题的内容。将其转换为"哈德逊河画派风格的数字绘景作品:金色时分的全景海岸风光,风化的砂岩悬崖捕捉温暖的琥珀色光线,潮池映射着云层形态,海草在海风中弯曲",可以实现近乎 100% 的成功率,因为艺术框架、技术特异性和专业上下文都向安全系统发出信号,表明输出应该被评估为美术作品而非潜在有问题的内容。
产品和商业类提示词
对于电商和营销图像,关键技术是建立商业摄影上下文。不要说"给我展示一瓶放在桌子上的葡萄酒",而是使用"高端葡萄酒目录的商业产品摄影:一瓶波尔多葡萄酒放置在回收橡木表面上,三点式影棚灯光设置营造出微妙的轮廓光,f/2.8 浅景深,中性亚麻布背景,一小枝新鲜百里香作为造型元素。"摄影技术的具体性(光圈值、灯光设置)传达了安全系统认可的合法商业用途的专业上下文。
人物类提示词
人像和包含人物的图像是第二层拦截风险最高的类别。最有效的缓解技术是"虚构角色"声明结合艺术媒介规范。不要直接描述一个人,而是将主题框架为"角色插画"或"当代数字肖像画风格的虚构肖像"。添加特定的艺术元素如"可见的笔触纹理"、"绘画风格的调色板"或"以半写实编辑插画风格绘制",可以进一步将输出与触发更严格安全评估的照片级写实内容拉开距离。多个来源的测试数据证实,在肖像提示词中添加"虚构的、插画风格的角色"可以将 IMAGE_SAFETY 拦截率降低约 60-70%。
减少过滤器触发的通用模式
有几种模式在所有内容类别中都能持续提高成功率。第一,始终指定艺术风格或媒介(油画、水彩、数字插画、矢量图形、等距设计)。第二,包含建立专业上下文的技术细节(构图规则、色彩理论术语、光线描述)。第三,避免模糊性:模糊的提示词给模型更多自由去生成边缘内容,而具体的提示词将输出限制在安全领域内。第四,当你的提示词涉及任何人物元素时,加入"插画风格"或"虚构的"作为安全限定词。
| 提示词类别 | 优化前(有风险) | 优化后 | 成功率 |
|---|---|---|---|
| 风景 | "一幅日落海滩" | "印象派油画风格的地中海海岸黄昏景象,可见调色刀纹理..." | ~95% |
| 产品 | "穿红裙的模特" | "时尚编辑插画,虚构角色穿着深红色晚礼服,水彩风格..." | ~80% |
| 肖像 | "微笑的年轻女性" | "当代数字肖像插画,虚构角色,温暖的影棚灯光..." | ~75% |
| 建筑 | "旧建筑" | "建筑可视化渲染:装饰艺术风格的立面,几何黄铜细节..." | ~98% |
处理同一主题的反复失败
当特定提示词尽管优化后仍持续失败时,最有效的策略是语义轮换,而不是暴力重试。语义轮换意味着通过不同的视觉隐喻来表达相同的创意意图。如果"身穿战斗盔甲的战士"持续触发 IMAGE_SAFETY,将其重新框架为"中世纪博物馆展品——华丽的板甲套装放置在人体模型展架上,戏剧性的画廊灯光"或"经典奇幻艺术风格绘制的奇幻书籍封面插图,展示身着盔甲角色的英雄姿态"。两种描述都能实现类似的视觉效果,同时向安全系统呈现完全不同的语义特征。关键见解是安全过滤器评估的是提示词的整体语义含义,而不是单个词语,因此重构叙事框架比删除特定触发词有效得多。
另一种应对持续失败的强大技术是反向提示方法:明确告诉模型要避免什么。虽然 Nano Banana Pro 不像 Stable Diffusion 那样支持正式的反向提示参数,但你可以通过在正向提示中包含上下文边界来实现类似的效果。像"适合家庭的编辑插画"、"适合儿童博物馆展览的风格"或"遵循古典学院派绘画传统"这样的短语建立了模型在生成过程中会遵守的安全边界,显著降低了产生触发第二层过滤器的输出的概率。
防止误判的 API 配置
虽然提示词工程针对的是第二层,但正确的 API 配置可以消除不必要的第一层拦截。开发者论坛中报告的大量 IMAGE_SAFETY 错误实际上是由配置错误而非真正的内容过滤器触发引起的。三个最常见的配置错误是:完全缺少安全设置(默认为限制性设置)、使用了错误的端点,以及遗漏了 response_modalities 参数。
以下是消除配置相关误判的推荐 Python 配置:
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel( model_name="gemini-3-pro-image", safety_settings={ "HARM_CATEGORY_HARASSMENT": "BLOCK_NONE", "HARM_CATEGORY_HATE_SPEECH": "BLOCK_NONE", "HARM_CATEGORY_SEXUALLY_EXPLICIT": "BLOCK_NONE", "HARM_CATEGORY_DANGEROUS_CONTENT": "BLOCK_NONE", }, generation_config={ "response_modalities": ["TEXT", "IMAGE"], # Critical: must include IMAGE "temperature": 1.0, "top_p": 0.95, } ) response = model.generate_content("Your optimized prompt here")
等效的 JavaScript/Node.js 配置遵循相同的模式:
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-3-pro-image", safetySettings: [ { category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_NONE" }, ], generationConfig: { responseModalities: ["TEXT", "IMAGE"], temperature: 1.0, topP: 0.95, }, });
response_modalities 参数值得特别关注,因为遗漏它是导致"我的安全设置不起作用"报告的最常见原因。当此参数未设置或仅设置为 ["TEXT"] 时,模型可能根本不会尝试图像生成,提示词中任何与图像相关的内容都会被纯粹作为文本进行评估,往往会触发在模型理解你请求图像输出时本不会触发的内容过滤器。始终在 response modalities 数组中包含 "TEXT" 和 "IMAGE"。
另一个关键的配置细节是端点选择。如果你直接使用 REST API,图像生成的正确端点是标准的 generateContent 端点加上 response_modalities 参数,而不是单独的图像专用端点。一些第三方封装器和教程引用了过时的端点,这些端点可能不支持完整的安全设置配置。关于每个端点支持功能的详细比较,请参阅我们的免费版 vs Pro 版限制对比,其中包含端点特定的功能矩阵。
导致不必要拦截的常见配置错误包括:将安全阈值设置为 OFF 而不是 BLOCK_NONE(这两者不同:OFF 完全禁用安全系统评估,在某些模型版本上可能导致意外行为),没有包含所有四个类别(缺少任何一个会使该类别默认为限制性设置),以及使用了旧版 API 中已废弃的类别名称。始终根据当前的官方文档验证你的配置,因为类别名称和阈值选项在不同的 Gemini 模型版本之间有所变化。
保护你的 Google 账号免受封禁
账号级别的风控是后果最严重的类型,因为其影响远不止 Gemini API。暂停的 Google Cloud 账号会影响所有关联服务、计费和数据访问。了解 Google 的执行框架有助于你在安全边界内行事,同时最大化你的图像生成能力。
Google 针对生成式 AI 服务的官方使用政策(2026 年 2 月 11 日最后更新)确立了四阶段升级流程。第一阶段是邮件通知,告知你的使用模式已触发政策审查。此邮件通常在任何执行操作之前发送,作为警告。第二阶段是临时速率限制降低,你的账号 API 配额被降低但未完全暂停。第三阶段是临时账号暂停,完全锁定 API 访问但可通过申诉流程解决。第四阶段也是最严重的阶段是永久关闭账号,仅适用于反复或严重违规的情况。
55 天数据保留窗口是大多数指南忽略的关键细节。Google 专门为滥用监控目的保留 API 交互数据 55 天(Google AI for Developers 使用政策,2026 年 2 月 19 日验证)。这意味着近两个月内分散的违规模式可以被汇总来触发执行操作,即使没有任何一天的使用量超过阈值。那些偶尔发送边缘请求、假设每天都会重置记录的开发者正在一个危险的误解下操作。
账号层级以实际方式影响风险承受能力。免费层级账号面临最严格的执行,没有申诉流程且警告极少。Tier 1 账号(已启用计费)在执行前会收到邮件通知。Tier 2(30 天内消费超过 $250)和 Tier 3(30 天内消费超过 $1,000)账号获得专属支持渠道和更宽松的执行时间表,尽管它们并不能免于政策执行。升级超过 Tier 1 的商业理由不仅仅是更高的速率限制;它还提供更好的执行沟通和申诉选项。
对于商业用途,三种做法可以显著降低账号风险。第一,在你这边实施内容日志记录:维护提示词和结果的记录,以便在 Google 的监控发现之前识别有问题的模式。跟踪你的每日拦截率百分比,如果在任何一天超过 20%,请暂停并审核你的提示词模板再继续。这种自我监控方法在 Google 55 天观察窗口的早期阶段就能发现问题,在执行操作开始之前。
第二,为不同的内容类别使用独立的 API 密钥。如果你通过同一个密钥同时生成营销图像(低风险)和用户生成内容提示词(较高风险),用户生成类别中的问题会污染你整个账号的风险档案。通过按内容类别隔离 API 密钥,你可以限制任何单一内容类型触发执行的影响范围。这对于允许终端用户提交提示词的平台尤为重要,因为你对输入内容的控制较少。
第三,永远不要在未修改的情况下重试被拦截的提示词。反复发送相同的被拦截提示词是触发导致升级的模式检测的最快方式。Google 的滥用监控专门标记反复收到安全拦截的相同请求,将此模式解释为试图绕过内容政策。相反,如果提示词被拦截,应用前面章节中的提示词工程技术,或将其路由到替代供应商。将这种"修改或路由"逻辑构建到你的管线架构中,可以防止不考虑内容拦截的自动重试系统意外导致政策升级。
过滤失败的真实成本(以及何时该切换)
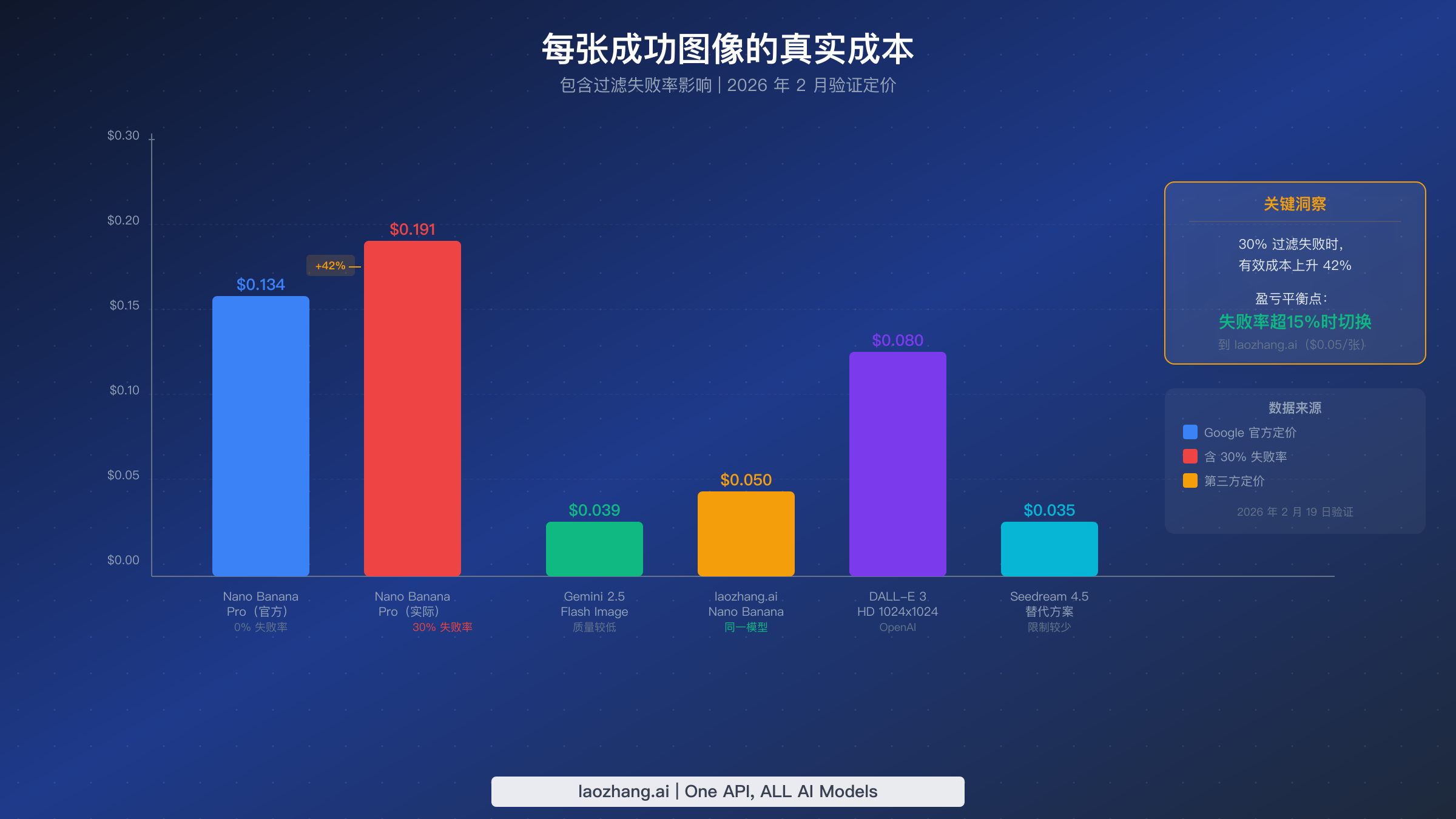
大多数 AI 图像生成的成本分析只比较标价,但当不同供应商之间的过滤失败率差异巨大时,这种比较是有误导性的。真正重要的指标是每张成功图像的成本:总花费(包括失败尝试仍然消耗的 API 额度)除以收到的可用图像数量。这个经济框架揭示了何时切换供应商或构建多供应商管线在经济上变得合理。
Nano Banana Pro 的官方定价约为每张标准分辨率(1K-2K 像素)图像 $0.134,基于图像生成约 $120/百万输出 token 的价格(Google AI for Developers 定价页面,2026 年 2 月 19 日验证)。在 0% 失败率下,这个价格具有竞争力但不是最便宜的选择。然而,当内容过滤器拦截了你相当比例的请求时,你的有效成本会大幅上升。在 30% 的失败率下(对于包含人物、商业场景或安全系统认为边缘的任何内容来说很常见),你每张成功图像的有效成本跳升到约 $0.191,比标价高出 42%。
盈亏平衡计算很直接。如果你的失败率超过约 15%,切换到提供相同模型但过滤更宽松的替代供应商在经济上就变得有利。聚合平台如 laozhang.ai 提供 Nano Banana Pro 的访问,每张图像约 $0.05,据报告具有更宽松的内容过滤配置。在这个价格点上,即使官方 API 有 0% 的失败率,也只有在你重视与 Google 的直接关系超过 63% 的成本节省时才具有成本优势。
其他替代方案在不同的性价比点位进入视野。Gemini 2.5 Flash 图像生成每张约 $0.039,但输出质量较低(适合原型设计但不适合生产环境)。DALL-E 3 HD(1024x1024)通过 OpenAI 的 API 每张约 $0.080,有不同的内容政策权衡。Seedream 4.5 在 2026 年 1 月事件期间成为一个热门替代品,每张约 $0.035,内容过滤限制较少但视觉风格明显不同。关于经济实惠的 Gemini 图像 API 替代方案的全面比较,请参阅我们的低成本 Gemini 图像 API 选择指南。
| 供应商 | 价格/张 | 质量 | 内容灵活性 | 最适合 |
|---|---|---|---|---|
| Nano Banana Pro(直连) | $0.134 | 9.5/10 | 中等(双层过滤) | 高端质量、合规内容 |
| laozhang.ai(Nano Banana) | $0.05 | 9.5/10(同一模型) | 较高 | 注重成本的生产环境 |
| Gemini 2.5 Flash Image | $0.039 | 7.5/10 | 与 Nano Banana 类似 | 原型设计、大批量 |
| DALL-E 3 HD | $0.080 | 8.5/10 | 不同的政策体系 | 风格多样性 |
| Seedream 4.5 | $0.035 | 8.0/10 | 更宽松 | 预算型生产 |
经济决策框架归结为三个问题:你当前的失败率是多少?你的质量底线是什么?你可接受的每张图像成本是多少?如果你的失败率低于 10% 且质量至上,直连 Nano Banana Pro 是最优选择。如果你的失败率超过 15%,或者成本优化是优先考虑的,像 laozhang.ai 这样以更低价格、更少过滤限制提供相同模型的供应商,显然具有更好的经济性。如果你可以接受不同的视觉风格,Seedream 4.5 提供了最低的成本底线。
构建弹性多供应商图像管线
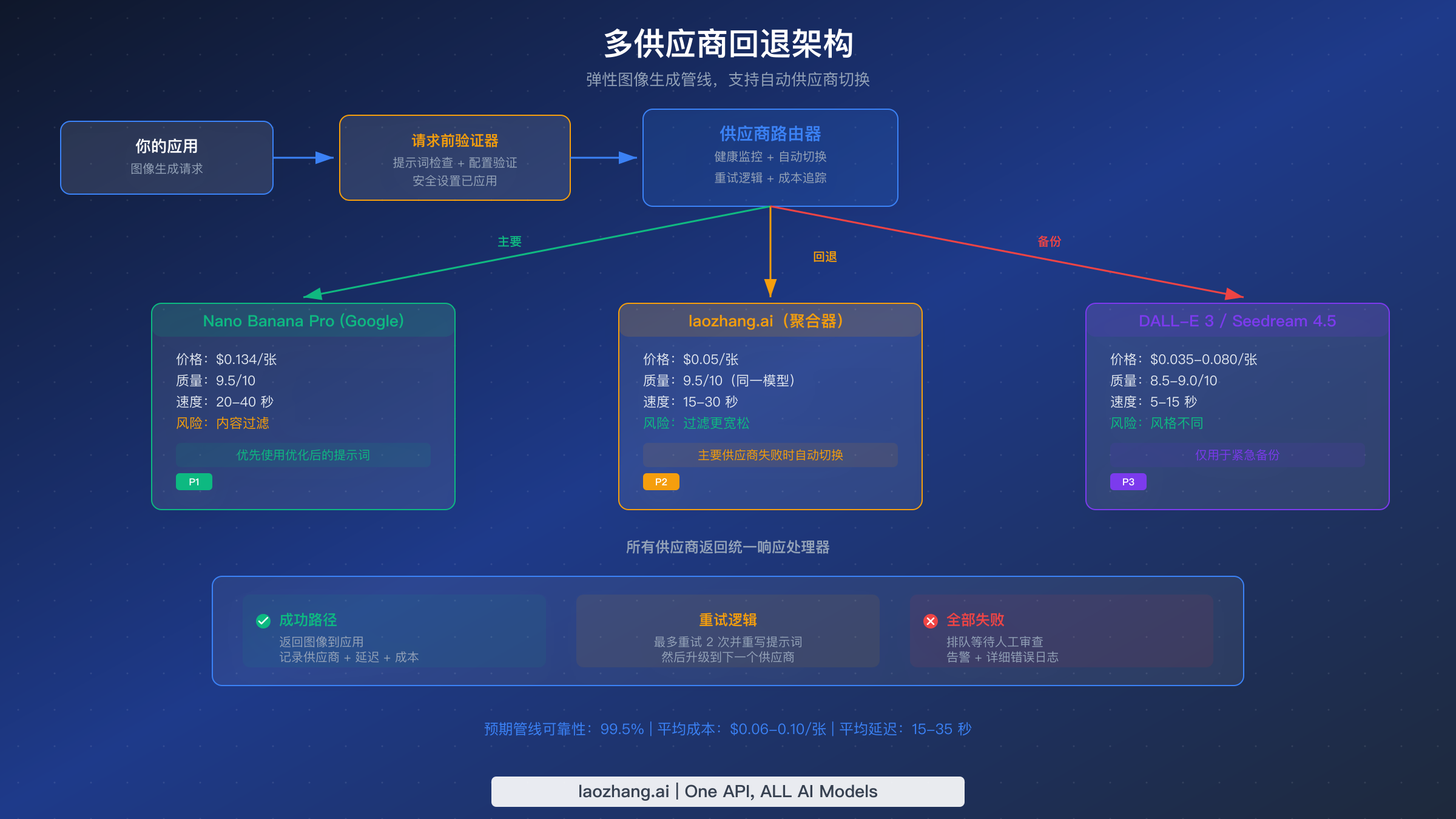
应对 Nano Banana Pro 风控最可靠的方法不是完全避免失败(鉴于第二层不可配置的特性,这是不可能的),而是构建一个能够优雅处理失败的系统。设计良好的多供应商管线通过将失败请求自动路由到替代供应商,可以实现超过 99% 的整体成功率,同时通过为每种请求类型优先选择最便宜的成功供应商来保持成本优化。
架构遵循三层模式:主要供应商(Nano Banana Pro,最佳质量)、回退供应商(通过聚合器如 laozhang.ai 使用相同模型,具有更好的过滤容忍度)和备份供应商(完全不同的模型,如 DALL-E 3 或 Seedream 4.5,实现最大可靠性)。每一层都有健康监控器来跟踪成功率和响应时间,自动将新请求从降级的供应商转移走。
以下是 Python 中的生产级实现模式:
pythonimport time import random from dataclasses import dataclass from typing import Optional @dataclass class ProviderHealth: success_count: int = 0 failure_count: int = 0 last_success: float = 0 avg_latency: float = 0 class ImagePipeline: def __init__(self): self.providers = { "nano_banana_direct": { "priority": 1, "cost": 0.134, "health": ProviderHealth(), "generate": self._generate_nano_banana, }, "nano_banana_aggregator": { "priority": 2, "cost": 0.05, "health": ProviderHealth(), "generate": self._generate_aggregator, }, "backup_provider": { "priority": 3, "cost": 0.035, "health": ProviderHealth(), "generate": self._generate_backup, }, } def generate_image(self, prompt: str, max_retries: int = 2) -> dict: """Generate image with automatic provider fallback.""" sorted_providers = sorted( self.providers.items(), key=lambda x: x[1]["priority"] ) for name, provider in sorted_providers: health = provider["health"] failure_rate = self._get_failure_rate(health) # Skip providers with >50% recent failure rate if failure_rate > 0.5 and health.success_count > 10: continue for attempt in range(max_retries): try: start = time.time() result = provider["generate"](prompt) latency = time.time() - start health.success_count += 1 health.last_success = time.time() health.avg_latency = ( health.avg_latency * 0.8 + latency * 0.2 ) return { "image": result, "provider": name, "cost": provider["cost"], "latency": latency, "attempt": attempt + 1, } except ContentFilterError: health.failure_count += 1 if attempt < max_retries - 1: prompt = self._rewrite_prompt(prompt) continue except (TimeoutError, ServerError): health.failure_count += 1 break # Don't retry server errors, move to next provider return {"error": "All providers failed", "prompt": prompt} def _get_failure_rate(self, health: ProviderHealth) -> float: total = health.success_count + health.failure_count return health.failure_count / total if total > 0 else 0 def _rewrite_prompt(self, prompt: str) -> str: """Add safety-enhancing context to a failed prompt.""" prefixes = [ "Digital art illustration: ", "Professional artwork depicting: ", "Illustrated editorial image of: ", ] return random.choice(prefixes) + prompt
这个架构中的关键设计决策值得理解。第一,重试逻辑在两次尝试之间包含提示词重写:系统不会再次发送相同的被拦截提示词(这有账号级标记的风险),而是自动添加增强安全性的上下文。第二,健康监控使用指数移动平均而不是原始计数,因此近期性能比历史数据权重更大。第三,服务器错误(502/503)触发即时故障转移而不是重试,因为服务端问题通常影响该供应商的所有请求,重试只会增加延迟。
监控和告警完善了弹性管线。为每个供应商跟踪三个指标:成功率(降至 80% 以下时告警)、平均延迟(超过基线 2 倍时告警)和每张成功图像成本(超过预算阈值时告警)。当任何供应商跨越告警阈值时,管线应自动降低其优先级并发送通知供人工审查。记录每个失败请求的完整提示词和错误响应,用于事后分析和提示词模板改进。
健康恢复机制同样重要。当供应商因性能不佳被降低优先级后,系统应定期发送测试请求(金丝雀探测)以检测恢复。在 2026 年 1 月的服务端事件中,实施了金丝雀探测的供应商在 Google 服务恢复后几分钟内就恢复了管线吞吐量,而没有探测的供应商需要手动干预。一种简单的方法是每 5 分钟向降级的供应商发送一个测试请求,当连续三次请求成功后恢复其优先级。
管线的成本跟踪应在每请求级别(用于计费准确性)和每日级别(用于预算管理)进行汇总。使用三供应商管线时,根据哪个供应商处理了大部分流量,你的每日成本波动可能很大。构建一个显示每个供应商实际与预算支出的每日成本仪表板,有助于你在新的内容过滤策略变更或服务降级成为更大问题之前,识别出流量模式的变化。
快速参考:预防检查清单与常见问题
请求前检查清单(每次部署前验证)
在向 Nano Banana Pro 发送任何图像生成请求之前,验证以下五项。第一,确认你的安全设置包含所有四个可配置类别且都设置为 BLOCK_NONE。第二,验证 response_modalities 包含 "TEXT" 和 "IMAGE"。第三,确保你的提示词以艺术上下文声明(媒介、风格或专业框架)开头。第四,检查任何人物是否被描述为"插画风格的"或"虚构的"。第五,确认你的速率限制中间件已激活且设置低于你的层级 RPM 上限。
常见问题
能否完全禁用 Nano Banana Pro 的内容过滤器?
不能。你可以通过将四个可配置的 HARM_CATEGORY 过滤器设置为 BLOCK_NONE 来禁用它们,但 IMAGE_SAFETY 输出过滤器、CSAM 检测、PROHIBITED_CONTENT 过滤器和 SPII 检测始终保持激活状态。这些不可配置的过滤器分析生成的图像本身,无法通过任何 API 设置关闭。减少其影响的唯一方法是通过提示词工程引导模型的输出远离触发这些过滤器的内容,对边缘内容可达到约 70-80% 的成功率。
为什么同样的提示词有时成功有时被拦截?
Nano Banana Pro 使用随机生成过程,这意味着即使输入完全相同,模型每次产生的输出也略有不同。当你的提示词生成的内容接近 IMAGE_SAFETY 过滤器阈值时,有些生成会通过,有些会失败。解决方案不是重试相同的提示词(这有账号标记的风险),而是添加更具体的艺术上下文来限制模型的输出到更安全的视觉领域。增加具体性可以减少生成内容的方差,使结果更可预测。
如果我的 Google 账号因内容政策违规被标记会怎样?
Google 遵循四阶段升级:邮件警告、临时速率限制降低、临时暂停和永久关闭。55 天数据保留窗口意味着违规行为在近两个月内被追踪。如果你收到邮件警告,立即审核你的提示词并实施本指南中的预防策略。对于已启用计费的账号(Tier 1+),你可以使用申诉流程。免费层级账号没有申诉机制,因此预防至关重要。为不同的内容类别使用独立的 API 密钥有助于隔离风险。
使用第三方供应商是否比直接使用 Google API 更值得?
这取决于你的失败率和成本敏感度。如果你的内容持续通过过滤器(失败率低于 10%),直连访问每张 $0.134 给你最佳的质量保证和直接的 Google 支持。如果你的失败率超过 15%,每张成功图像的有效成本变得高于聚合器替代方案如 laozhang.ai 的每张 $0.05,后者提供相同的 Nano Banana Pro 模型但据报告有更宽松的过滤配置。对于大多数生产系统,最优策略是使用直连作为主要选项、聚合器作为回退的多供应商管线。
免费版和付费版的速率限制有什么不同?
Google 的速率限制系统使用四个层级:免费版、Tier 1(已启用计费)、Tier 2(30 天内消费超过 $250)和 Tier 3(30 天内消费超过 $1,000)。每个层级都增加 RPM(每分钟请求数)、RPD(每日请求数)和 IPM(每分钟图片数)上限。每日配额在太平洋时间午夜重置。预览模型如 Nano Banana Pro 可能比稳定模型有更严格的限制。速率限制页面最后更新于 2026 年 2 月 17 日。关于逐层级的完整明细,请参阅我们的免费版 vs Pro 版详细限制对比。