
要点速览
Nano Banana Pro 的错误分为三大类:服务器错误(503/500 — Google 端的问题,使用指数退避重试)、客户端错误(400/403 — 修复你的请求载荷或权限设置)以及速率限制(429 — 在 Google AI Studio 中检查你的配额)。截至 2026 年 2 月,最常见的错误是高峰时段(UTC 10:00-14:00)的 503 UNAVAILABLE,最高可影响 45% 的 API 调用。第二个最令人困惑的问题是响应中出现的临时图片 — 这是设计行为而非 bug,不会产生计费。本指南涵盖每一种错误代码的真实 API 响应示例、Python 和 JavaScript 代码修复方案,以及一套完整的生产级重试实现方案,你可以直接复制粘贴到你的项目中使用。
快速诊断 — 30 秒内识别你的错误

每一个 Nano Banana Pro 错误都会准确地告诉你问题的责任方是谁。API 响应中的 HTTP 状态码是你最首要也是最重要的诊断信号。理解这一个信息就能帮你节省数小时的调试时间,因为修复方案完全取决于错误是源自 Google 的服务器还是你的请求。
基本规则很简单:5xx 错误意味着 Google 的基础设施正在承受压力,你应该等待并重试。4xx 错误意味着你的请求有问题,重试相同的请求必定会再次失败。 这个区别非常重要,因为开发者经常在服务器过载的情况下浪费时间"修复"自己的代码,或者不断重试永远不会成功的错误请求。
以下是快速参考诊断表,涵盖了使用 Nano Banana Pro API(模型 ID:gemini-3-pro-image-preview,见 ai.google.dev/pricing,2026 年 2 月)时最常见的八种错误:
| HTTP 状态码 | gRPC 状态 | 快速含义 | 你的操作 | 可重试? |
|---|---|---|---|---|
| 503 | UNAVAILABLE | Google 服务器过载 | 等待 30-60 秒,使用退避重试 | 是 |
| 500 | INTERNAL | 服务器端故障 | 简化提示词,60 秒后重试 | 是(有限次) |
| 502 | — | 网关/代理错误 | 检查端点 URL,重试 | 是 |
| 429 | RESOURCE_EXHAUSTED | 超出速率限制 | 检查配额,等待重置 | 是(等待后) |
| 400 | INVALID_ARGUMENT | 请求格式错误 | 修复载荷,检查 thought_signature | 否 |
| 400 | FAILED_PRECONDITION | 地区/计费问题 | 启用计费,检查地区设置 | 否 |
| 403 | PERMISSION_DENIED | API 密钥缺少权限 | 验证 API 密钥和项目设置 | 否 |
| 404 | NOT_FOUND | 资源缺失 | 检查媒体文件引用 | 否 |
收到错误后,你的第一步操作应该始终是检查 HTTP 状态码。如果以 5 开头,停止调试你的代码 — 问题出在 Google 那边。如果以 4 开头,问题出在你的请求中,你需要检查错误消息的详细信息来了解需要修复什么。JSON 响应中的 details 数组通常包含具体的字段名和验证错误信息,直接指向问题所在。
完整的 Nano Banana Pro 错误代码参考
除了快速诊断表之外,理解完整的错误响应结构对于构建可靠的应用程序至关重要。Gemini API 返回的每个错误都包含一个结构化 JSON 响应,其中包含 HTTP 状态码、gRPC 状态字符串、人类可读的消息,有时还包含一个 details 数组提供具体的错误信息。以下是当你的 API 调用命中过载服务器时,一个真实的 503 错误响应示例:
json{ "error": { "code": 503, "message": "The model is overloaded. Please try again later.", "status": "UNAVAILABLE", "details": [ { "@type": "type.googleapis.com/google.rpc.DebugInfo", "detail": "backend_error" } ] } }
429 速率限制错误看起来有所不同,并提供了更具操作性的信息,包括你具体触及了哪个限制:
json{ "error": { "code": 429, "message": "Resource has been exhausted (e.g. check quota).", "status": "RESOURCE_EXHAUSTED", "details": [ { "@type": "type.googleapis.com/google.rpc.RetryInfo", "retryDelay": "36s" } ] } }
请注意 429 响应中包含了 retryDelay 字段 — 这会告诉你在下一次尝试前需要等待多长时间。请始终遵循这个值,而不是自行猜测。400 INVALID_ARGUMENT 错误是变化最多的,因为它涵盖了多种类型的请求验证失败,从缺少必需字段到格式错误的图片数据,再到多轮对话中越来越常见的 thought_signature 问题。
错误严重性分类对你的错误处理代码非常重要。 关键错误(503、500)需要带退避的即时重试逻辑。警告错误(429)需要配额管理,可能还需要升级层级。信息性错误(400、403)需要代码修改,绝不应在未修改的情况下重试。围绕这三个类别构建你的错误处理器 — 而不是逐个处理每个错误码 — 可以产出更简洁、更易维护的代码。
完整的错误代码参考还包括两种图片生成特有的错误类型,这些在标准 Gemini 文本 API 调用中不会出现。IMAGE_SAFETY 在安全过滤器阻止你的提示词或生成的输出时返回。PROHIBITED_CONTENT 是更严格的阻止,表明你的提示词被标记为违反政策。这两者都作为响应 candidates 数组中带有 finishReason 字段的一部分返回,而不是作为 HTTP 错误码返回,这意味着它们在你的代码中需要不同的处理方式。
以下是许多开发者在生成肖像照片或任何过滤器认为可能敏感的内容时遇到的真实 IMAGE_SAFETY 响应:
json{ "candidates": [ { "finishReason": "IMAGE_SAFETY", "safetyRatings": [ { "category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "probability": "MEDIUM", "blocked": true } ] } ] }
重要的区别在于 IMAGE_SAFETY 不会返回 HTTP 错误状态 — HTTP 响应仍然是 200 OK。你的代码必须检查每个 candidate 上的 finishReason 字段来检测这些阻止。如果你只检查 HTTP 错误,安全过滤器的阻止将会悄无声息地通过你的错误处理器,在下游产生空的或意外的结果。一个健壮的错误处理器需要对每个响应同时检查 HTTP 状态码和 finishReason 字段,将 IMAGE_SAFETY 和 PROHIBITED_CONTENT 视为与标准 HTTP 错误不同的独立错误类别进行处理。
504 DEADLINE_EXCEEDED 错误值得特别提及,因为它经常与 503 混淆。504 错误意味着你的请求已被服务器接受但处理时间过长 — 生成超时了。这通常发生在需要多次思考迭代的极其复杂的提示词中,或者在中等负载期间的超高分辨率(4K)图片请求中。与 503 中服务器立即拒绝你的请求不同,504 意味着服务器在处理你的请求但未能在规定时间内完成。修复方法通常是简化你的提示词或降低请求的分辨率,然后重试。
服务器错误(503、500、502)— 当 Google 基础设施出现故障时
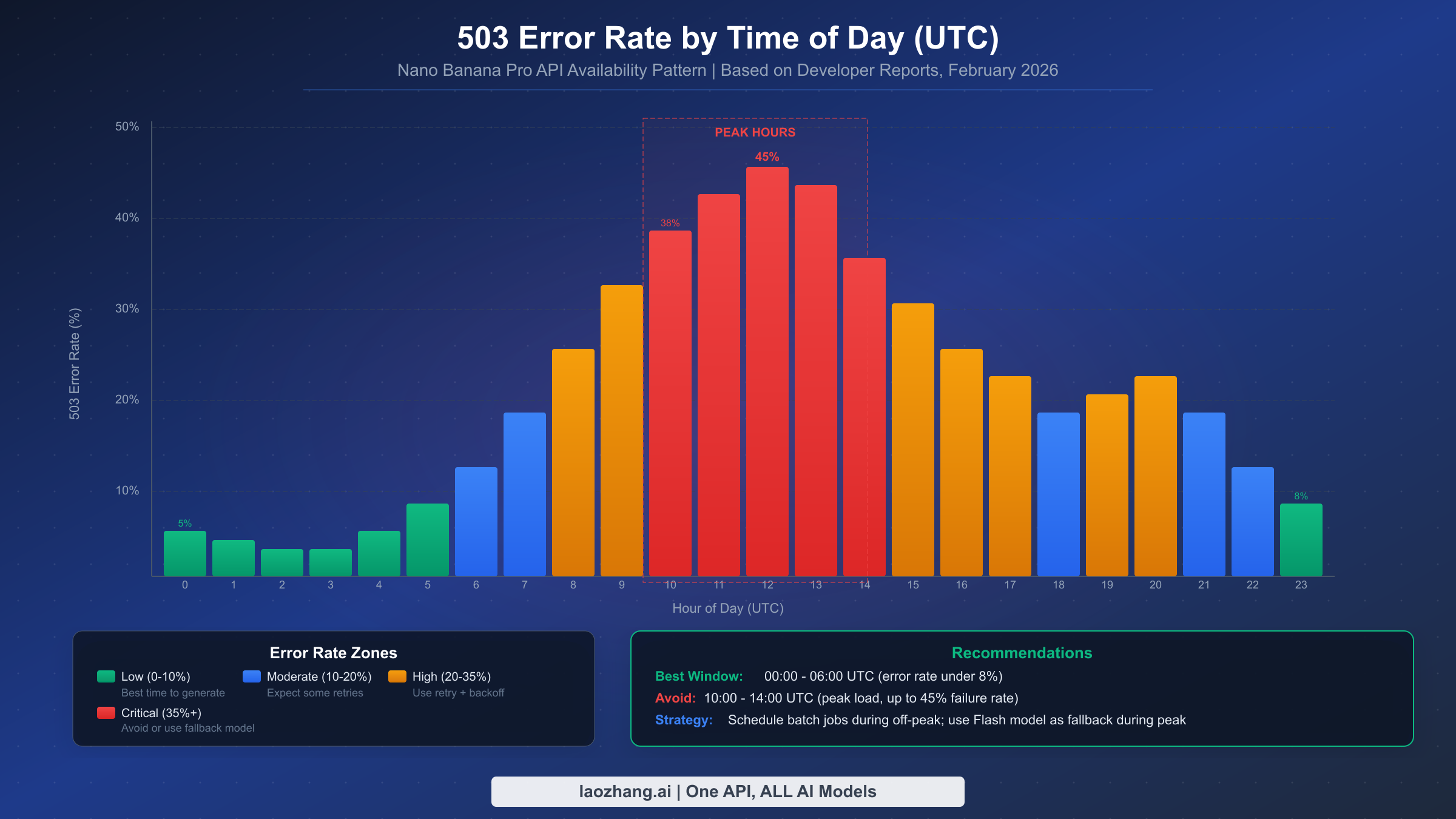
503 UNAVAILABLE 错误是目前开发者在使用 Nano Banana Pro 时遇到的最常见错误,而且它完全不在你的控制范围内。当 Google 的 Gemini 基础设施过载时 — 这在高峰使用时段经常发生 — API 会对相当比例的请求返回 503 错误。根据 Google AI 开发者论坛(discuss.ai.google.dev)汇总的开发者社区报告,高峰时段(大约 UTC 10:00 至 14:00)的错误率可达所有 API 调用的 45%,这使得可靠的错误处理不仅仅是锦上添花,而是任何生产级应用的绝对必要条件。
关于 503 错误的关键洞察是它们本质上是暂时性的。 现在因 503 失败的同一个请求在 30-60 秒后很可能会成功。这就是指数退避是正确策略的原因 — 你不是在修复任何东西,你只是在等待服务器容量释放。Google 工作人员已在开发者论坛上确认,预览模型在高峰时段出现 503 错误是预期行为,基础设施扩容正在持续进行中。
500 INTERNAL 错误不太常见,但更值得关注,因为它有时表明你的特定请求存在问题,而不是一般性的服务器过载。如果你收到 500 错误,先尝试简化你的提示词 — 过长或过于复杂的提示词可能触发内部处理故障。如果简化后错误仍然存在,将其视为 503 并使用退避进行重试。502 BAD_GATEWAY 错误通常在使用代理服务或 API 中转时出现,表示中间服务器无法访问 Google 的后端。在重试前检查你的端点 URL 配置和代理设置。
服务器错误的重试时机遵循一个经过验证的模式。 从首次失败后等待 30 秒开始,然后每次后续失败将等待时间加倍(30 秒 -> 60 秒 -> 120 秒 -> 240 秒)。最大等待时间上限为 5 分钟,总重试次数限制为 5 次。添加随机抖动(等待时间的 +-20%)可以防止"惊群效应",即多个客户端同时重试导致服务器再次过载。
避免 503 错误最有效的策略是将批量图片生成任务安排在非高峰时段。UTC 00:00 至 06:00 的时间窗口错误率持续低于 8%,非常适合批量处理。对于无法控制时间的实时应用程序,实现到 Nano Banana(Flash 模型,gemini-2.5-flash-image)的模型降级回退提供了可靠的备选方案 — Flash 模型由于计算需求较低,503 错误显著减少,但代价是图片质量较低,最大分辨率为 1024x1024 像素(ai.google.dev/pricing,2026 年 2 月)。
在调试代码之前,如何确认问题是否在 Google 那边: 访问 Google Cloud 状态仪表板或查看 Google AI 开发者论坛的当前事件报告。Google 在确认大范围故障时也会在 Gemini API 状态页面发布信息。如果其他开发者在论坛上同时报告了和你一样的 503 错误,你可以确信问题与基础设施相关而不是你的代码导致的。在重大事件期间,Google 工作人员通常会在 30-60 分钟内在论坛上回应,确认问题并给出预计解决时间。
503 错误的模式也因地区而异。通过美国数据中心路由的开发者往往在北美工作时间(UTC 15:00-22:00)看到最高的错误率,而使用亚洲数据中心的开发者报告整体错误率较低,但在亚洲工作时间(UTC 01:00-09:00)会出现峰值。如果你的应用服务于全球用户群,可以考虑将图片生成请求分布到多个地区,或使用能自动路由到负载最低地区的中转服务。
客户端错误(400、403、404)— 修复你的请求
客户端错误是你的责任,与服务器错误不同,重试相同的请求将始终产生相同的失败。400 INVALID_ARGUMENT 错误有多个子原因,对于 Nano Banana Pro 开发者来说最重要的是多轮图片编辑对话中的 thought_signature 处理。随着越来越多的开发者构建基于聊天的图片编辑功能,这个错误变得越来越常见,但现有文档几乎没有充分涵盖这个问题。
当你在对话中生成了一张图片,然后在后续轮次中要求 Nano Banana Pro 修改它时,API 要求你包含来自前一次响应的 thought_signature 值。如果你没有保存并回传这个值,该对话中第二次及所有后续的图片生成请求都会以 400 错误失败。签名位于 response.candidates[0].content.thought_signature,必须包含在你发送的下一次请求的对话历史中。这不是可选的 — 这是多轮图片生成的硬性要求。
pythonresponse_1 = model.generate_content("Create a landscape painting") # CRITICAL: Save the thought_signature thought_sig = response_1.candidates[0].content.thought_signature # For the next turn, include it in conversation history response_2 = model.generate_content( contents=[ {"role": "user", "parts": [{"text": "Create a landscape painting"}]}, {"role": "model", "parts": response_1.candidates[0].content.parts, "thought_signature": thought_sig}, {"role": "user", "parts": [{"text": "Add a sunset to the painting"}]} ] )
400 FAILED_PRECONDITION 错误是一个独立的问题,通常表明你的 Google Cloud 项目不满足 Gemini API 的要求。最常见的原因是使用未启用计费的免费层项目,或从免费层不可用的地区访问 API。请检查你的 Google Cloud 项目是否已启用计费,以及你的地区是否支持你所需的使用层级(ai.google.dev/rate-limits,2026 年 2 月)。
403 PERMISSION_DENIED 错误意味着你的 API 密钥没有必要的权限。有几个常见原因值得系统性地检查。首先,验证你的 API 密钥是否在启用了 Generative Language API(或 Vertex AI API,如果使用 Vertex)的同一个 Google Cloud 项目中生成 — 来自不同项目的密钥将无法工作。其次,确保 API 密钥没有被限制为排除了 Generative Language API 的特定 API。第三,检查你的项目是否有可能阻止访问 AI 服务的组织策略约束。
地区限制是 403 错误中特别令人沮丧的来源,因为错误消息通常没有明确指出问题是地理性的。某些国家的开发者 — 包括中国、伊朗、俄罗斯和其他一些国家 — 即使拥有有效的 API 密钥和计费账户,也无法直接访问 Gemini API。API 只会返回 403 PERMISSION_DENIED 而不解释这是基于地区的封锁。如果你怀疑遇到了地区封锁,尝试从不同的网络访问 API 或查看 Gemini API 支持地区文档。对于需要从受限地区可靠访问的开发者,laozhang.ai 等 API 中转服务通过将你的请求路由到支持的地区来提供不受地区限制的访问,无需配置 VPN 即可保持相同的 API 接口。
404 NOT_FOUND 错误不太常见,但当你的请求引用了 Google 服务器上不再存在的媒体文件(例如上传用于编辑的图片)时会出现。上传的媒体文件有过期窗口,如果你引用了已过期的文件 URI,就会收到 404。解决方案是在引用媒体文件之前重新上传它,并在你的应用程序中缓存已上传文件的 URI 及其过期时间戳。
速率限制与 429 RESOURCE_EXHAUSTED — 掌控你的配额
429 RESOURCE_EXHAUSTED 错误意味着你触及了几种速率限制维度之一。与问题在于服务器容量的 503 错误不同,429 错误关乎你的项目的特定配额分配。理解不同的限制类型至关重要,因为每种限制在不同的时间表上重置,需要不同的缓解策略。
Nano Banana Pro 的速率限制按 Google Cloud 项目(而非按 API 密钥)应用,在四个维度上衡量:RPM(每分钟请求数)、TPM(每分钟输入 token 数)、RPD(每日请求数)和 IPM(每分钟图片数)。IPM 限制是图片生成模型特有的,通常也是让开发者措手不及的限制,因为即使你还有 RPM 余量,你可能已经用完了图片专用的配额分配(ai.google.dev/rate-limits,2026 年 2 月)。
确切的数值限制因层级而异,且不作为固定数字公布 — Google 会根据系统负载和模型版本进行调整。你可以在 Google AI Studio 的项目设置中查看你当前的限制。不过,决定你总体配额级别的层级结构是有详细文档说明的:
| 层级 | 资格条件 | 速率限制级别 | 费用 |
|---|---|---|---|
| 免费 | 符合条件的国家,无需计费 | 最受限制 | $0 |
| 第 1 层 | 已启用付费计费账户 | 中等 | 按使用量付费 |
| 第 2 层 | 总消费 > $250 且满 30 天 | 较高 | 按使用量付费 |
| 第 3 层 | 总消费 > $1,000 且满 30 天 | 最高 | 按使用量付费 |
(来源:ai.google.dev/rate-limits,2026 年 2 月)
RPD 限制在太平洋时间午夜重置,这是许多开发者忽略的重要细节。如果你在太平洋时间下午 3 点触及每日限制,你必须等到午夜 — 而不是从触及限制起 24 小时。RPM 限制从你在该窗口内首次请求的时间起每 60 秒重置。围绕这些重置边界规划你的请求分布可以显著提高你的有效吞吐量。
一个常见的混淆来源是速率限制错误和配额耗尽错误之间的区别。速率限制错误(带有 retryDelay 的 429)意味着你在分配的窗口内发送请求过快 — 降低速度就能解决。配额耗尽错误(没有重试信息的 429)意味着你已经触及了绝对的每日或每月上限 — 在当前周期内再怎么等待也无济于事。对于每日配额耗尽,你唯一的选择是等待太平洋时间午夜重置或升级你的层级。对于每月配额问题,请联系 Google Cloud 支持讨论增加你的配额分配。
像 Nano Banana Pro(gemini-3-pro-image-preview)这样的预览模型比稳定模型有更严格的速率限制(ai.google.dev/rate-limits,2026 年 2 月)。这意味着你在 AI Studio 中看到的预览模型的限制是有意低于稳定版本的。随着模型接近正式发布,Google 会调整这些限制,因此你今天看到的具体数字将来可能会增加。定期在 AI Studio 中检查更新后的限制是值得的,尤其是在 Google 宣布模型更新或版本变更之后。
实用的配额优化策略可以在不升级层级的情况下大幅减少 429 错误。 最有效的技术是请求批处理 — 不要为每张图片单独进行 API 调用,而是将你的提示词批量处理并均匀分布在你的 RPM 配额内。如果你的 RPM 限制是 10,那么每 6 秒调度一次请求,而不是同时发送 10 个请求然后等待 60 秒。这可以平滑你的使用曲线并防止触发速率限制的突发流量。另一个强大的策略是实现一个模拟 Google 速率限制行为的客户端令牌桶 — 这让你能够在 429 错误发生之前预测和防止它们,而不是事后被动应对。
对于专门触及 IPM(每分钟图片数)限制的开发者,请考虑是否所有的图片生成调用都真正需要 Pro 模型。许多用例 — 缩略图、预览、低分辨率草稿 — 使用 Nano Banana(Flash)完全可以胜任,而 Flash 有独立的且通常更宽裕的速率限制。根据质量要求在模型之间分配工作负载可以有效地将你的总图片生成容量翻倍,而无需更改你的层级。
有关速率限制策略的全面分析以及如何在不同层级之间优化配额使用,请参阅我们的 429 resource exhausted 错误解决详细指南。你还可以查看全面的速率限制指南了解具体的优化技巧,以及免费层与付费层功能对比来判断升级你的层级对你的用例是否值得。
图片生成问题 — 安全过滤器、临时图片与思考模式
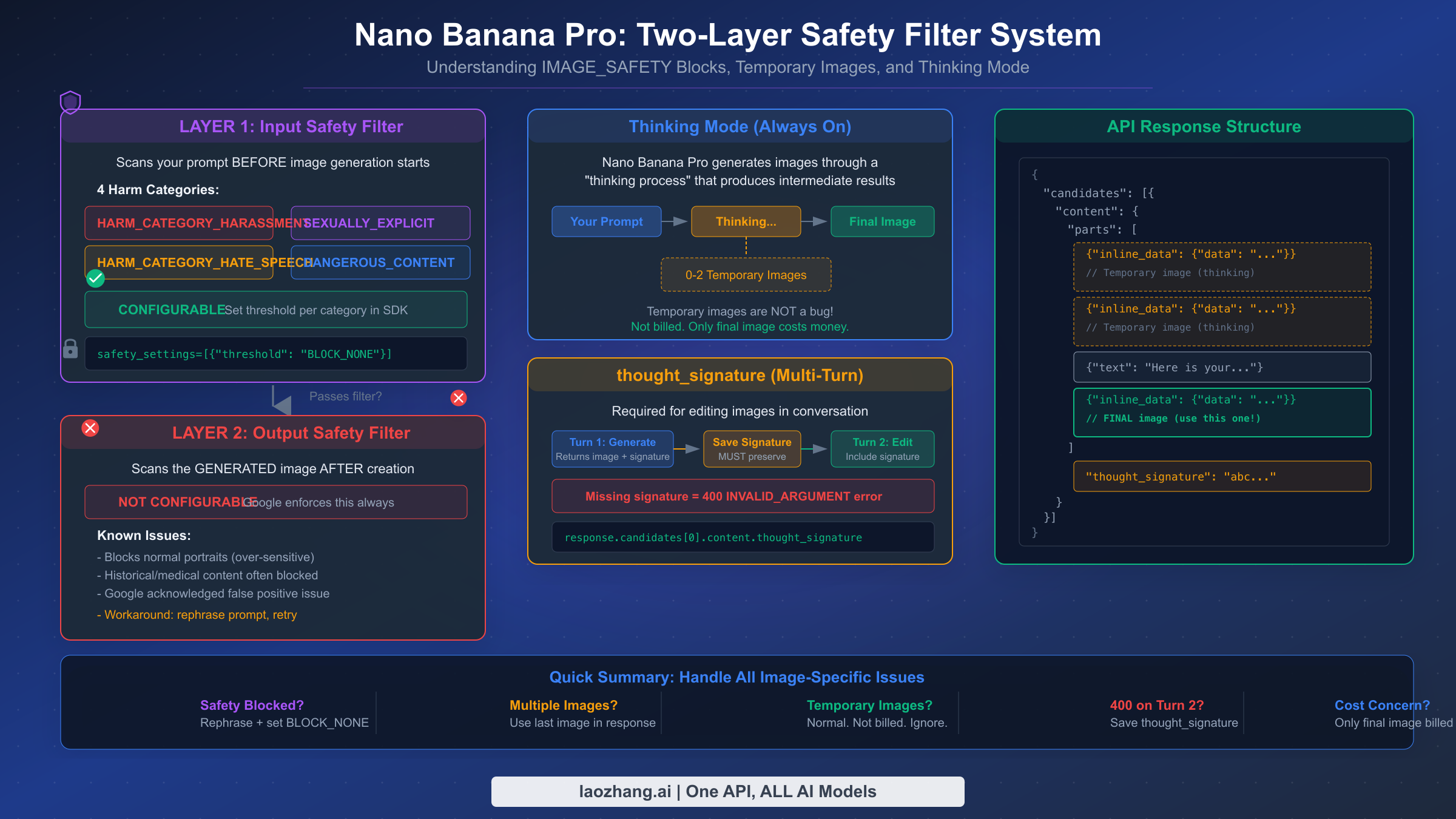
使用 Nano Banana Pro 进行图片生成会引入一组标准文本生成中不存在的错误条件。这些问题 — 安全过滤器阻止、响应中的临时图片以及思考模式行为 — 是该 API 最常被误解的方面。开发者经常将这些视为 bug,但实际上它们是 Google 有意为之的设计决策,理解其预期行为是正确处理它们的关键。
IMAGE_SAFETY 过滤器在两个层面运行,这个区别很重要,因为只有第一层是可配置的。 输入安全过滤器在图片生成开始前扫描你的提示词,针对四个伤害类别进行检查:HARM_CATEGORY_HARASSMENT、HARM_CATEGORY_HATE_SPEECH、HARM_CATEGORY_SEXUALLY_EXPLICIT 和 HARM_CATEGORY_DANGEROUS_CONTENT。你可以将每个类别的阈值设置为 BLOCK_NONE、BLOCK_LOW_AND_ABOVE、BLOCK_MEDIUM_AND_ABOVE 或 BLOCK_ONLY_HIGH。将所有四个都设置为 BLOCK_NONE 可以获得最宽松的输入过滤:
pythonfrom google.generativeai.types import HarmCategory, HarmBlockThreshold safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE, } response = model.generate_content( "A portrait photograph of a person smiling", safety_settings=safety_settings )
然而,输出安全过滤器 — 在创建后扫描生成的图片 — 是不可配置的。Google 始终强制执行这一层,而且已知它会产生误报,特别是在处理肖像照片和历史图像时。Google 已在开发者论坛上承认了这种过度敏感性。对于输出过滤器阻止的唯一变通方法是重新措辞你的提示词以产生略有不同的、不会触发过滤器的图片,或者重试相同的提示词,因为模型的随机性可能在后续尝试中产生通过过滤的图片。
你 API 响应中的临时图片不是 bug — 它们是 Nano Banana Pro 思考过程的预期组成部分。 当模型生成图片时,它可能在得到最终结果之前产生多达两张中间"思考"图片。这些临时图片作为额外的 inline_data 部分出现在响应的 parts 数组中,位于最终图片之前。大多数开发者忽略的关键细节是临时图片不计费 — 只有响应中的最终图片会产生费用(1K-2K 分辨率每张 $0.134,4K 分辨率每张 $0.24,经 ai.google.dev/pricing 验证,2026 年 2 月)。有关临时图片出现的原因以及如何在代码中处理它们的完整解释,请参阅我们的临时图片行为完整解析。
要从包含临时图片的响应中提取最终图片,始终使用响应中的最后一个图片部分而不是第一个。以下是一个可靠的代码模式,无论思考过程产生了多少张临时图片都能正常工作:
pythondef extract_final_image(response): """Always returns the final (last) image, skipping temporary images.""" parts = response.candidates[0].content.parts images = [p for p in parts if hasattr(p, 'inline_data') and p.inline_data] if not images: raise ValueError("No images in response — check finishReason") # The last image is always the final result final_image = images[-1] return base64.b64decode(final_image.inline_data.data)
Nano Banana Pro 中的思考模式默认启用且无法禁用 — 它是该模型相较于标准 Nano Banana(Flash)模型实现更高质量图片生成的基础。这个思考过程将复杂提示词的成功率从大约 60-70% 提升到了 85-90%,这一数据来自开发者社区测试。代价是响应时间更长(通常 10-30 秒,而 Flash 为 3-8 秒),并且由于包含的临时图片导致响应载荷更大,这可能影响对延迟要求严格或带宽受限的应用。
开发者常犯的一个错误是将临时图片计为单独的计费输出。包含两张临时图片和一张最终图片的响应不会收取 3 倍费用 — 它的成本与单次图片生成相同。临时图片包含在响应中是为了让思考过程透明化,一些高级应用会利用它们向用户展示模型的创作演进过程,但它们不会产生额外费用。定价仍然是 1K-2K 分辨率每张最终图片 $0.134 或 4K 分辨率每张 $0.24(ai.google.dev/pricing,2026 年 2 月)。
构建弹性图片生成流水线
在生产环境中处理 Nano Banana Pro 错误最有效的方式是将每种可能的错误分为三类 — 可重试、可修复和致命错误 — 然后围绕这个分类构建你的错误处理器。可重试错误(503、500、502 以及等待后的 429)应触发带指数退避的自动重试。可修复错误(400、403)应被记录以供调查。致命错误(PROHIBITED_CONTENT)应立即向用户展示。
以下是一个完整的 Python 实现,实现了弹性图片生成包装器,处理所有错误类型,实现带抖动的指数退避,并在主模型持续不可用时包含从 Nano Banana Pro 到 Nano Banana(Flash)的模型降级回退:
pythonimport google.generativeai as genai import time import random import base64 class ResilientImageGenerator: def __init__(self, api_key): genai.configure(api_key=api_key) self.primary_model = genai.GenerativeModel("gemini-3-pro-image-preview") self.fallback_model = genai.GenerativeModel("gemini-2.5-flash-image") def generate_image(self, prompt, max_retries=5, use_fallback=True): """Generate image with automatic retry and model fallback.""" last_error = None # Try primary model with retries for attempt in range(max_retries): try: response = self.primary_model.generate_content(prompt) return self._extract_final_image(response) except Exception as e: last_error = e error_code = getattr(e, 'code', None) or self._parse_error_code(e) if error_code in (503, 500, 502): # Retryable: wait with exponential backoff + jitter wait = min(30 * (2 ** attempt), 300) jitter = wait * random.uniform(-0.2, 0.2) time.sleep(wait + jitter) elif error_code == 429: # Rate limited: honor retry delay if provided retry_delay = self._get_retry_delay(e) or 60 time.sleep(retry_delay) elif error_code in (400, 403, 404): # Not retryable: raise immediately raise else: raise # Fallback to Flash model if primary exhausted retries if use_fallback: try: response = self.fallback_model.generate_content(prompt) return self._extract_final_image(response) except Exception: pass raise last_error def _extract_final_image(self, response): """Extract the LAST image from response (skip temporary images).""" if not response.candidates: raise ValueError("No candidates in response") parts = response.candidates[0].content.parts # Find the last image part (final image, not temporary) for part in reversed(parts): if hasattr(part, 'inline_data') and part.inline_data: return base64.b64decode(part.inline_data.data) raise ValueError("No image found in response") def _parse_error_code(self, error): error_str = str(error) for code in [503, 500, 502, 429, 400, 403, 404]: if str(code) in error_str: return code return None def _get_retry_delay(self, error): # Parse retryDelay from error details if available try: error_str = str(error) if 'retryDelay' in error_str: import re match = re.search(r'"retryDelay":\s*"(\d+)s"', error_str) if match: return int(match.group(1)) except Exception: pass return None
等效的 JavaScript/Node.js 实现遵循相同的模式,但使用 async/await 处理重试循环:
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); class ResilientImageGenerator { constructor(apiKey) { const genAI = new GoogleGenerativeAI(apiKey); this.primaryModel = genAI.getGenerativeModel({ model: "gemini-3-pro-image-preview" }); this.fallbackModel = genAI.getGenerativeModel({ model: "gemini-2.5-flash-image" }); } async generateImage(prompt, maxRetries = 5) { let lastError; for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await this.primaryModel.generateContent(prompt); return this.extractFinalImage(result.response); } catch (error) { lastError = error; const code = error.status || this.parseErrorCode(error); if ([503, 500, 502].includes(code)) { const wait = Math.min(30000 * Math.pow(2, attempt), 300000); const jitter = wait * (Math.random() * 0.4 - 0.2); await this.sleep(wait + jitter); } else if (code === 429) { await this.sleep(60000); } else { throw error; // 400, 403, 404: don't retry } } } // Fallback to Flash model try { const result = await this.fallbackModel.generateContent(prompt); return this.extractFinalImage(result.response); } catch (e) { throw lastError; } } extractFinalImage(response) { const parts = response.candidates[0].content.parts; for (let i = parts.length - 1; i >= 0; i--) { if (parts[i].inlineData) { return Buffer.from(parts[i].inlineData.data, "base64"); } } throw new Error("No image in response"); } parseErrorCode(error) { const match = String(error).match(/(\d{3})/); return match ? parseInt(match[1]) : null; } sleep(ms) { return new Promise(r => setTimeout(r, ms)); } }
对于生产环境部署,两种实现都应扩展监控和告警功能。跟踪三个关键指标:按类型分的错误率(用于检测 503 率何时超过正常水平)、每次成功请求的平均重试次数(用于检测性能下降)以及降级模型使用率(用于检测主模型何时变得持续不可用)。当你的 503 错误率超过 30% 并持续 5 分钟以上时设置告警,可以让你的团队在用户体验到大范围故障之前主动切换到降级模式(仅使用 Flash 生成)。
用于监控目的的错误分类应遵循以下分类方式:
| 类别 | 错误代码 | 操作 | 告警级别 |
|---|---|---|---|
| 可重试 | 503、500、502 | 使用退避自动重试 | 当比率 >30% 时告警 |
| 速率限制 | 429 | 队列化 + 延迟 | 信息 |
| 客户端修复 | 400、403、404 | 记录 + 通知开发者 | 错误 |
| 安全阻止 | IMAGE_SAFETY | 改述或跳过 | 信息 |
| 政策阻止 | PROHIBITED_CONTENT | 跳过 + 记录 | 警告 |
在构建多模型降级回退链时,laozhang.ai 等 API 中转服务可以通过提供路由到多个模型的单一端点来简化架构 — 请参阅其文档了解多模型 API 配置。这种方式无需为回退链中的每个模型管理单独的 API 密钥和客户端配置。
常见问题
失败的请求会收费吗?
不会。返回错误代码(503、429、400、403 等)的失败 API 请求不会计费。你只为返回生成内容的成功响应付费。这包括思考过程中的临时图片 — 它们是成功响应的一部分但不会单独计费。只有响应中的最终图片会计入你的使用量和账单。
Nano Banana Pro 的可靠性足以用于生产环境吗?
Nano Banana Pro(gemini-3-pro-image-preview)仍然是一个预览模型,这意味着 Google 不保证生产级 SLA。在非高峰时段,可靠性通常较好(成功率 >90%),但高峰时段的失败率可达 45%。对于生产使用,实现本指南中描述的重试 + 降级回退模式至关重要。如果你需要最大可靠性,可以考虑使用 Nano Banana(Flash,gemini-2.5-flash-image)作为你的主模型 — 它的质量较低但可用性显著更高。有关详细的定价和性能对比,请参阅我们的 Gemini 3 Pro Image API 定价与性能分析。
我应该使用 Vertex AI 还是 Gemini API?
两者访问的是相同的底层模型。Gemini API(通过 Google AI Studio)设置更简单且有免费层。Vertex AI 提供企业级功能,如 VPC 网络、自定义端点和更高的速率限制,但需要一个已启用计费的 Google Cloud 项目。两个 API 的错误代码完全相同,不过 Vertex AI 原生使用 gRPC,而 Gemini API 将错误包装在 REST JSON 响应中。
如何联系 Google 支持解决持续性错误?
对于免费层用户,主要支持渠道是 Google AI 开发者论坛 discuss.ai.google.dev。Google 工作人员定期监控并回复有关 API 错误的帖子。对于已启用计费的第 1 层及以上用户,你可以通过 Google Cloud 控制台提交支持工单。提交报告时请包含你的项目 ID、具体的错误代码和完整的响应 JSON 以及错误的时间戳。
生成图片的最佳时间是什么?
根据社区报告的错误模式,最低错误率出现在 UTC 00:00-06:00(美洲的傍晚到凌晨,亚太地区的白天)。最差的时间窗口是 UTC 10:00-14:00(美洲的上午到下午早些时候,美国开发者活动高峰期)。如果你的应用允许调度,请将批量图片生成任务安排在非高峰时间窗口。有关可能具有不同可用性模式的经济替代方案,请参阅我们的 Gemini 图片生成经济替代方案指南。
如何检查我当前的速率限制使用情况?
你可以在 Google AI Studio 的项目设置中查看当前使用量和剩余配额。API 本身不会在响应头中返回剩余配额信息(与某些其他 API 不同),因此你需要在客户端自行跟踪使用量或查看 AI Studio 仪表板。对于编程式配额监控,你可以使用 Google Cloud Monitoring API 配合你的项目 ID 来设置使用量接近限制时的告警。
为什么同一个提示词会得到不同的错误?
模型的随机性意味着同一个提示词在每次调用时可能产生不同的结果,包括不同的错误结果。一个在某次尝试中触发 IMAGE_SAFETY 的提示词可能在下一次就成功了,因为每次生成的图片略有不同,可能触及也可能不触及安全过滤器的阈值。对于 503 错误,可变性是由于波动的服务器负载造成的 — 在高峰时刻失败的相同请求可能在几秒钟后服务器容量释放时就成功了。这就是重试逻辑如此重要的原因:它考虑了模型行为和服务器可用性中的固有可变性。
Nano Banana Pro 和 Nano Banana(Flash)有什么区别?
Nano Banana Pro(gemini-3-pro-image-preview)优先考虑图片质量,支持最高 4K 分辨率,每张图片成本 $0.134 到 $0.24。它使用思考过程来产出更高质量的结果,但耗时更长(10-30 秒),并且可能生成临时中间图片。Nano Banana(gemini-2.5-flash-image)优先考虑速度和成本效率,每张图片 $0.039,最大分辨率 1024x1024,通常在 3-8 秒内响应。Flash 模型通常具有更高的可用性和更少的 503 错误,因为其计算需求更低。对于需要同时兼顾质量和可靠性的生产系统,推荐的方式是使用 Pro 作为主模型,Flash 作为 Pro 返回持续错误时的自动降级回退。