
Nano Banana Pro(Gemini 3 Pro Image)能够生成令人惊叹的 AI 图片,但其 API 可能抛出一系列令人困惑的错误,导致你的生产流水线完全停滞。大约 70% 的 Nano Banana Pro API 故障是 429 RESOURCE_EXHAUSTED 错误,通常在 1-5 分钟内自行恢复,而服务端 503 错误可能需要 30-120 分钟才能消除——判断清楚你遇到的是哪种类型,决定了你应该修复代码还是耐心等待。本故障排除中心汇总了开发者诊断、修复和预防所有 Nano Banana Pro 错误所需的全部信息,包括许多开发者误认为是 bug 的临时图片机制。
要点速览
Nano Banana Pro 的错误分为五大类,每一类需要不同的应对策略。速率限制错误(429)约占所有 API 故障的 70%,通常在 1-5 分钟内自行恢复——实现指数退避重试就能自动处理其中大部分。服务器过载错误(503)不是你的问题,而是 Google 后端计算资源不足导致的,需要耐心等待,Gemini 3 Pro 的恢复时间通常在 30 分钟到 2 小时之间。客户端错误(400)意味着你的请求格式有误,可以通过检查模型 ID、分辨率参数和提示词格式立即修复。如果你在 API 响应中看到多张图片,那也不是错误——而是模型思考过程中的草稿图,只有最终图片会被计费。为了获得最可靠的体验,社区普遍推荐使用 Gemini API 而非 Vertex AI,后者的 429 错误明显更加频繁。
理解 Nano Banana Pro 错误代码
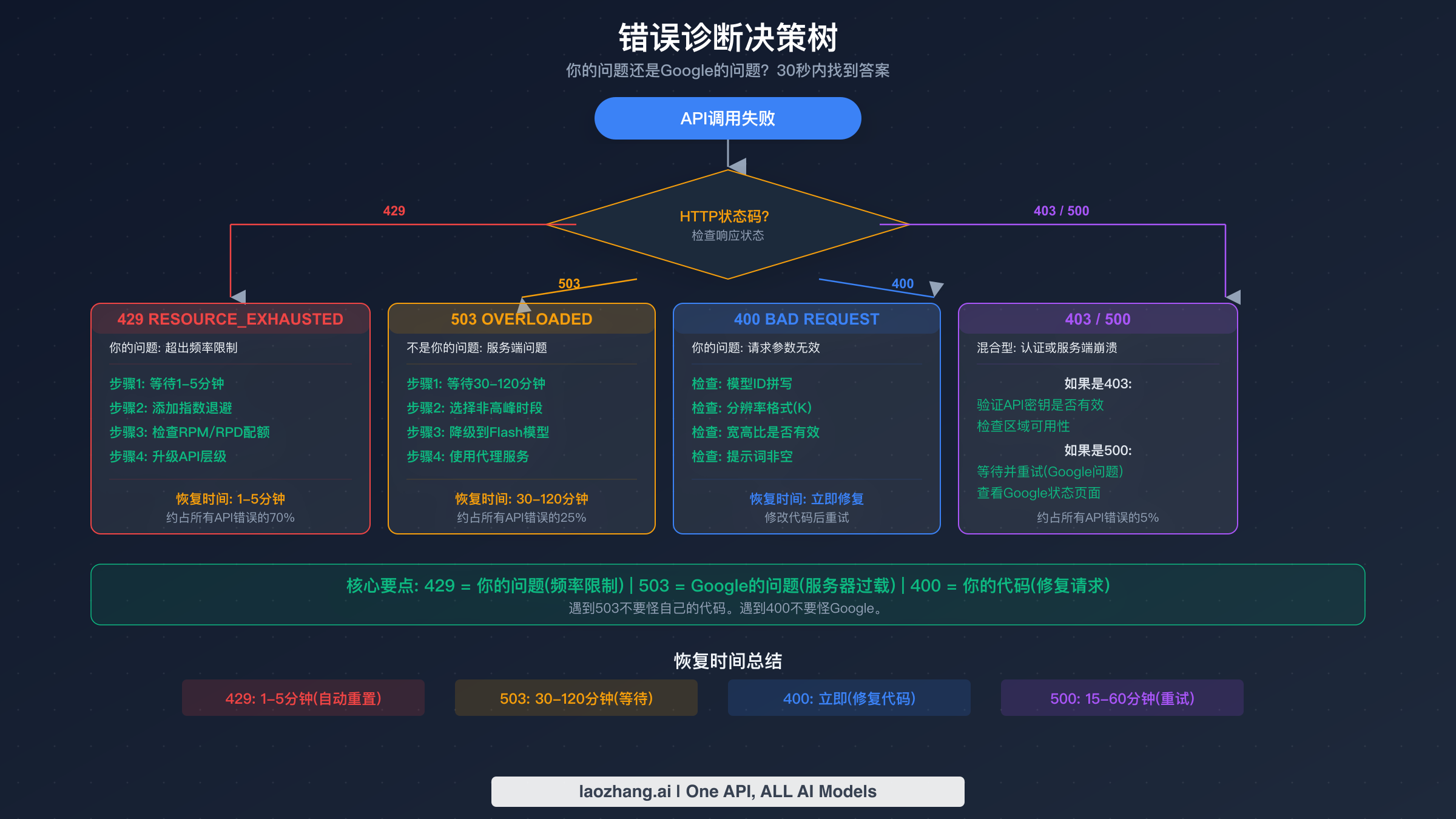
当你的 Nano Banana Pro API 调用失败时,响应中的 HTTP 状态码能精确告诉你问题出在哪里。关键的第一步是区分你能修复的错误(客户端)和你无法修复的错误(服务端)。这个判断能为开发者节省数小时的无效调试——当真正的问题是 Google 的服务器容量时,你不应该花时间重构代码;当修复只需要简单调整请求参数时,你也不应该被动等待。
429 RESOURCE_EXHAUSTED 是目前最常见的错误,根据 Google AI 开发者论坛和多个开发者博客的社区报告分析,约占所有 Nano Banana Pro API 故障的 70%。这个错误意味着你超出了多个速率限制维度中的某一个:每分钟请求数(RPM)、每日请求数(RPD)或每分钟令牌数(TPM)。许多开发者忽略的关键细节是,Google 在所有维度上同时执行这些限制——超过任何单一指标都会触发 429 错误。恢复通常在 1-5 分钟内自动完成(配额池重置),但持续出现的 429 错误可能意味着你需要升级 API 等级。如果你目前使用免费版,每日图片生成限制相当严格,升级到付费版将大幅增加配额。你可以在 Google AI Studio 中直接查看当前的速率限制和使用情况。关于速率限制机制的深入分析,请参阅我们的速率限制完全指南。
503 SERVICE OVERLOADED 与 429 错误有本质区别,理解这个差异至关重要。503 错误表示 Google 的后端服务器缺乏足够的计算资源来处理你的请求,与你的个人使用量无关。这是系统性问题,不是你的代码或账户造成的。Nano Banana Pro 503 错误的恢复时间明显长于其他模型:Gemini 3 Pro 预计需要 30-120 分钟,而 Gemini 2.5 Flash 仅需 5-15 分钟。在高峰时段——根据社区报告大约对应北京时间 00:00-02:00、09:00-11:00 和 20:00-23:00——根据开发者分享的生产环境监控数据,503 错误导致的故障率可达所有 API 调用的 45%。应对 503 的实际策略很直接:实现模型降级策略,当 Pro 模型不可用时自动切换到 Gemini 2.5 Flash(标准 Nano Banana 模型),并尽可能将批量处理安排在非高峰时段。
400 BAD REQUEST 错误始终是由 API 请求中的某些问题引起的,可以立即修复。最常见的触发原因包括使用错误的模型 ID(截至 2026 年 2 月,Nano Banana Pro 的正确标识符是 gemini-3-pro-image-preview,参见 Google 官方定价页面)、分辨率参数中使用小写 'k' 而非大写 'K'、提供不支持的宽高比,或发送空的或格式错误的提示词。一个容易忽略的细节是:如果你尝试使用旧版 API 的模型 ID,你会收到 400 错误而非有用的弃用警告。
403 FORBIDDEN 错误表示认证或授权失败。最常见的原因是 API 密钥无效或已过期、从不支持的区域访问模型,或使用了管理员限制了 AI 功能的 Google Workspace 账户。如果你刚刚创建了 API 密钥,在断定密钥有问题之前请等待几分钟让它完成传播。
500 INTERNAL SERVER ERROR 表示 Google 服务器上发生了崩溃或未处理的异常。与表示已知容量限制的 503 错误不同,500 错误暗示确实发生了意外状况。这类错误不太常见(约占所有错误的 5%),通常在 15-60 分钟内恢复。Google AI 开发者论坛上多位用户报告在 2025 年 12 月出现持续数天的 500 错误,Google 支持团队确认了该问题并最终通过后端修复解决。如果你遇到反复出现的 500 错误,请查看 Google Cloud 状态页面和开发者论坛,看看其他人是否遇到了同样的问题——这几乎可以肯定不是你的代码问题。
临时图片机制——为什么你会看到多余的图片
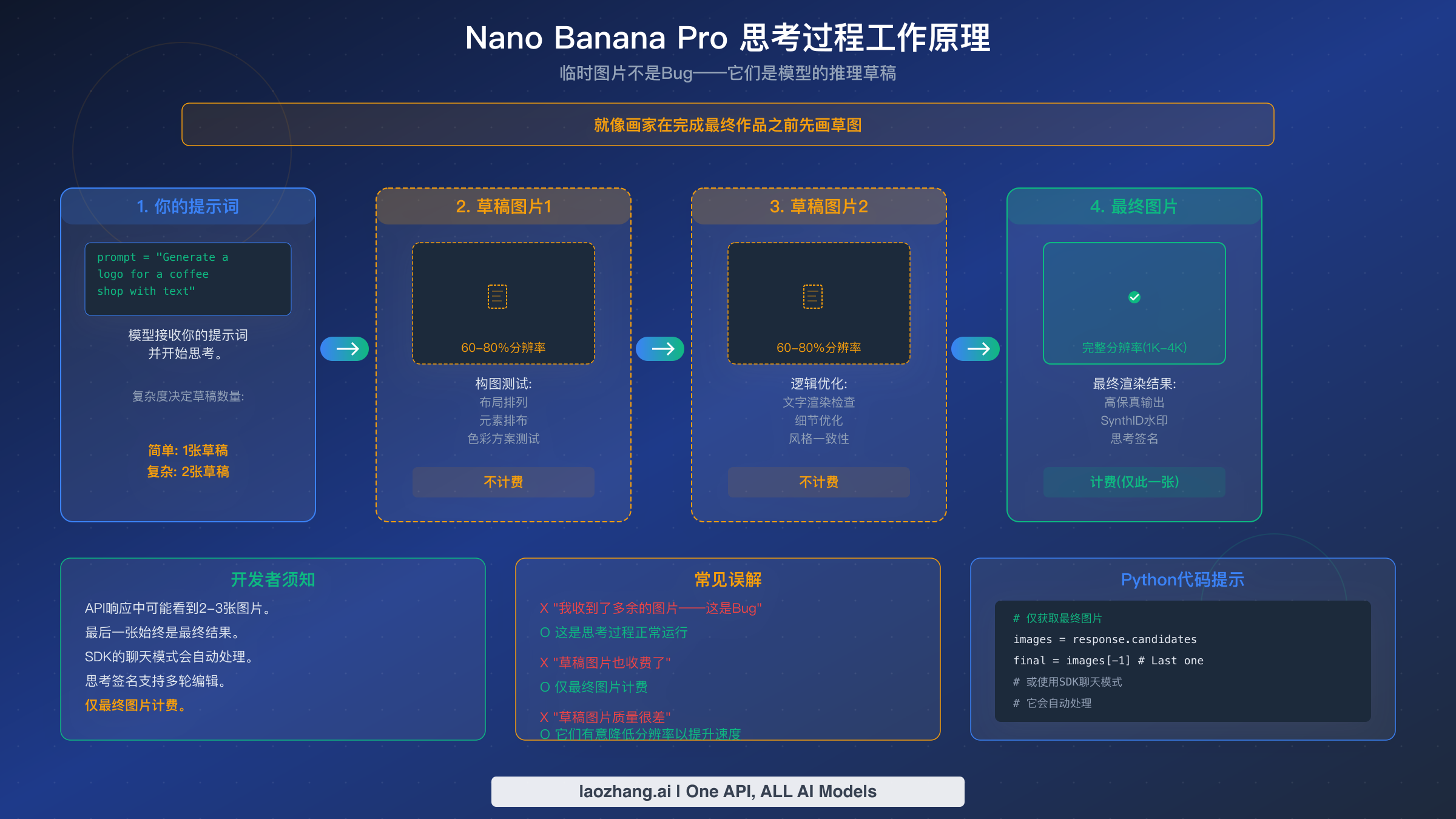
Nano Banana Pro 最常被报告的"bug"实际上是一个特性:当你发起 API 调用时,响应中可能包含两到三张图片,而不是你请求的单张图片。首次遇到这种行为的开发者通常会认为出了问题——他们提交 bug 报告、添加过滤逻辑来丢弃"多余的"图片,或者担心被多次收费。真相要简单得多,理解这个机制将为你节省大量调试时间,并帮助你构建更好的图片生成工作流。
Nano Banana Pro 使用一种名为"思考模式"(Thinking mode)的内置推理过程,这从根本上改变了模型生成图片的方式,与 DALL-E 或 Stable Diffusion 等简单模型截然不同。模型不会一次性生成单个输出,而是生成最多两张中间"草稿"图片来测试构图和逻辑,然后再渲染最终结果。可以把它想象成画家创作草图——草稿帮助模型评估布局位置、文字渲染准确性、元素排列和风格一致性,然后再提交完整分辨率的最终图片。ai.google.dev 上的 Google 官方文档确认了这一行为:"模型将生成最多两张临时图片来测试构图和逻辑。思考过程中的最后一张图片也是最终渲染的图片。"
草稿图片的数量取决于提示词的复杂度。简单的提示词——如"白色背景上的一个红苹果"——可能只需要一张草稿,甚至完全跳过草稿阶段。复杂的多元素组合,尤其是涉及文字渲染、logo 或详细布局的场景,通常会经历完整的两次草稿过程。这就是为什么复杂提示词生成时间更长:模型在真正地推理构图,而不仅仅是运行一次前向传播。
每位开发者都应该知道的关键计费细节:临时草稿图片不单独收费。只有最终渲染的图片按标准费率计费,1K/2K 图片约 $0.134,4K 图片约 $0.24(ai.google.dev/pricing,2026 年 2 月)。草稿图片使用最终图片 60-80% 的分辨率以优化处理速度,这就是为什么直接检查它们时可能会发现质量略低。
对于使用官方 Google Gen AI SDK 聊天模式的开发者,思考签名(模型推理上下文的加密表示)会自动处理,实现无缝的多轮图片编辑。但如果你直接处理原始 API 响应,则需要显式提取响应中的最后一张图片作为最终结果。以下是正确的实践处理方式——响应数组中的最后一张图片始终是最终的、已计费的输出,前面的任何图片都是思考过程的草稿,你可以安全地丢弃它们或将其记录到日志中用于调试。
生产级代码示例与日志分析
为 Nano Banana Pro 构建健壮的错误处理需要的不仅仅是简单的 try-catch 块。生产系统需要结构化日志、智能重试逻辑、正确处理思考过程的响应解析,以及在服务不可用时的优雅降级。以下 Python 示例提供了一个完整的基础框架,你可以根据具体用例进行调整。
每位开发者首先应该实现的模式是带有指数退避、合理超时配置和全面日志记录的结构化 API 调用器。这个单独的类处理了最常见的故障模式——速率限制、服务器过载、超时和格式错误的响应——同时提供清晰的日志输出,即使在生产环境中也能让调试变得简单明了。
pythonimport google.generativeai as genai import time import logging from typing import Optional logging.basicConfig(level=logging.INFO) logger = logging.getLogger("nano_banana_pro") class NanaBananaProClient: """Production-ready Nano Banana Pro client with retry and fallback.""" def __init__(self, api_key: str, max_retries: int = 3): genai.configure(api_key=api_key) self.model = genai.GenerativeModel("gemini-3-pro-image-preview") self.fallback_model = genai.GenerativeModel("gemini-2.5-flash-image") self.max_retries = max_retries def generate_image(self, prompt: str, resolution: str = "2K") -> Optional[bytes]: """Generate image with automatic retry and fallback.""" for attempt in range(self.max_retries): try: logger.info(f"Attempt {attempt + 1}/{self.max_retries}: {prompt[:50]}...") response = self.model.generate_content( prompt, generation_config={"response_modalities": ["IMAGE", "TEXT"]}, request_options={"timeout": 300} ) return self._extract_final_image(response) except Exception as e: error_msg = str(e) if "429" in error_msg or "RESOURCE_EXHAUSTED" in error_msg: wait = min(2 ** attempt * 5, 60) logger.warning(f"Rate limited. Waiting {wait}s...") time.sleep(wait) elif "503" in error_msg or "overloaded" in error_msg.lower(): logger.warning("Server overloaded. Trying fallback model...") return self._fallback_generate(prompt) elif "400" in error_msg: logger.error(f"Bad request - fix your code: {error_msg}") return None # Don't retry client errors else: logger.error(f"Unexpected error: {error_msg}") if attempt == self.max_retries - 1: return self._fallback_generate(prompt) time.sleep(2 ** attempt) return None def _extract_final_image(self, response) -> Optional[bytes]: """Extract the final image, skipping thinking process drafts.""" images = [] for part in response.candidates[0].content.parts: if hasattr(part, "inline_data") and part.inline_data.mime_type.startswith("image/"): images.append(part.inline_data.data) if images: # The LAST image is always the final result logger.info(f"Received {len(images)} image(s). Using final image.") return images[-1] logger.warning("No image data in response") return None def _fallback_generate(self, prompt: str) -> Optional[bytes]: """Fall back to Nano Banana (Flash) when Pro is unavailable.""" try: logger.info("Using fallback: gemini-2.5-flash-image") response = self.fallback_model.generate_content( prompt, generation_config={"response_modalities": ["IMAGE", "TEXT"]}, request_options={"timeout": 120} ) return self._extract_final_image(response) except Exception as e: logger.error(f"Fallback also failed: {e}") return None
第二个关键模式是日志分析。在生产环境中调试 Nano Banana Pro 问题时,你的日志需要捕获特定的数据点,帮助你区分不同的错误类型并识别规律。上面的结构化日志方法输出的条目包括尝试次数、错误类型、等待时间以及是否使用了降级模型——所有这些信息对于诊断反复出现的问题都至关重要。特别注意 429 与 503 错误的比例:如果主要是 429 错误,说明你的应用发送请求过于频繁——需要在你这一侧实现更好的速率限制,或升级等级。如果主要是 503 错误,问题出在 Google 的基础设施上,最好的选择是将批量作业安排在非高峰时段,或者维持 Flash 模型作为降级方案。更多关于不同等级速率限制如何运作的内容,请参阅我们的 RESOURCE_EXHAUSTED 错误深度解析。
上面代码中的 _extract_final_image 方法尤为重要,因为它正确处理了思考过程机制。通过始终取 images[-1](响应中的最后一张图片),你自动获得最终的、最高质量的结果,无论模型在思考过程中生成了多少张草稿图片。这种方法适用于简单提示词(一张图片)和复杂提示词(两张草稿加最终图片)两种情况。
阅读生产日志来诊断问题是一项区分经验丰富的开发者和新手的技能。以下是真实的生产日志输出示例以及如何解读每种场景:
INFO Attempt 1/3: "A futuristic city skyline with neon signs..."
INFO Received 3 image(s). Using final image.
→ 解读:模型生成了 2 张草稿 + 1 张最终图片。正常行为。
# 场景 2:速率限制后重试成功
INFO Attempt 1/3: "Product photo of a leather bag..."
WARNING Rate limited. Waiting 5s...
INFO Attempt 2/3: "Product photo of a leather bag..."
INFO Received 1 image(s). Using final image.
→ 解读:触发了 RPM 限制,退避后恢复。考虑增大请求间隔。
# 场景 3:服务器过载触发降级
INFO Attempt 1/3: "Detailed architectural blueprint..."
WARNING Server overloaded. Trying fallback model...
INFO Using fallback: gemini-2.5-flash-image
INFO Received 1 image(s). Using final image.
→ 解读:Pro 模型不可用,Flash 模型成功。画质可能有差异。
# 场景 4:完全失败
INFO Attempt 1/3: "Complex multi-element poster..."
ERROR Unexpected error: 500 Internal Server Error
INFO Attempt 2/3: "Complex multi-element poster..."
ERROR Unexpected error: 500 Internal Server Error
INFO Attempt 3/3: "Complex multi-element poster..."
ERROR Unexpected error: 500 Internal Server Error
WARNING Server overloaded. Trying fallback model...
ERROR Fallback also failed: 500 Internal Server Error
→ 解读:系统性宕机。检查 Google 状态页面,等待 15-60 分钟。
分析日志时应关注的模式是 429 与 503 错误的比例。如果 429 错误占主导(>80% 的故障),说明你的应用发送请求过于频繁——实现带有速率限制器的请求队列,使其遵守你所在等级的 RPM 限制。如果 503 错误占主导,则 Google 的基础设施是瓶颈,最好的选择是将批量作业安排在非高峰时段或维持 Flash 模型作为降级方案。一个健康的生产系统在非高峰时段的总故障率应低于 5%,高峰时段低于 20%——任何明显高于这些阈值的情况都值得深入调查。
对于高级监控,可以考虑添加一个简单的指标聚合层,跟踪每小时的成功率、平均延迟和错误类型分布。即使是使用 Python 的 collections.Counter 并将每小时摘要写入日志文件的基础实现,也能提供你优化 API 使用模式所需的可见性。
超时与重试配置指南
Nano Banana Pro 图片生成本质上比文本生成慢得多——单张图片可能需要 30-170 秒,取决于分辨率和提示词复杂度。大多数编程库中的默认 HTTP 超时值对于此类工作负载来说过于激进,而超时配置不当是最常见的误判故障来源之一。正确设置超时配置是一个简单但关键的优化,可以显著提高成功率,而无需对 API 服务器做任何更改。
推荐的超时值因分辨率而异,基于实际观测到的生成时间加上安全裕度。对于 1K 图片(默认分辨率),将读取超时设置为 300 秒。实际生成通常需要 30-90 秒,但网络波动和高峰时段的服务器排队时间可能会显著延长这个过程。对于 2K 图片,保持 300 秒超时——生成需要 50-120 秒,额外的缓冲可以应对增加的计算负载。对于 4K 图片,将超时延长到 600 秒,因为即使在理想条件下生成也可能需要 100-170 秒,而你需要充足的缓冲来应对高峰时段的延迟。
一个微妙但重要的技术考量是 HTTP 协议版本。一些开发者报告说 HTTP/2 连接在长时间运行的 Nano Banana Pro 请求期间可能导致过早断开,因为所有 HTTP/2 流共享一个 TCP 连接——一个丢失的数据包会同时阻塞所有流。如果你在设置了充裕的超时值后仍然遇到无法解释的超时,请尝试在 HTTP 客户端中显式强制使用 HTTP/1.1。在 Python 的 httpx 库中,这意味着设置 http2=False;在 requests 库中,HTTP/1.1 是默认值。连接超时和读取超时的区别在这里很重要:为 TCP 建立设置短的连接超时(10 秒),为图片生成期间的数据接收设置长的读取超时(300-600 秒)。在 Python 的 requests 库中,使用 timeout=(10, 600) 元组来分别设置。
以下是一个处理上述所有细节的完整超时配置示例。此配置分离了连接超时和读取超时,强制使用 HTTP/1.1,并包含每个分辨率级别的推荐值:
pythonimport google.generativeai as genai import random # Timeout configuration by resolution TIMEOUT_CONFIG = { "1K": {"connect": 10, "read": 300}, # 30-90s typical generation "2K": {"connect": 10, "read": 300}, # 50-120s typical generation "4K": {"connect": 10, "read": 600}, # 100-170s typical generation } def generate_with_proper_timeout(prompt: str, resolution: str = "2K"): """Generate image with resolution-appropriate timeout.""" config = TIMEOUT_CONFIG.get(resolution, TIMEOUT_CONFIG["2K"]) model = genai.GenerativeModel("gemini-3-pro-image-preview") for attempt in range(3): try: response = model.generate_content( prompt, generation_config={"response_modalities": ["IMAGE", "TEXT"]}, request_options={"timeout": config["read"]} ) return response except Exception as e: if "429" in str(e): # Exponential backoff with jitter wait = min(2 ** attempt * 5, 60) + random.uniform(0, 2) time.sleep(wait) elif "timeout" in str(e).lower(): # Timeout: increase buffer and retry config["read"] = int(config["read"] * 1.5) continue else: raise return None
| 分辨率 | 连接超时 | 读取超时 | 典型生成时间 | 安全裕度 |
|---|---|---|---|---|
| 1K(默认) | 10s | 300s | 30-90s | 3.3-10x |
| 2K | 10s | 300s | 50-120s | 2.5-6x |
| 4K | 10s | 600s | 100-170s | 3.5-6x |
重试策略方面,带抖动的指数退避是标准方法。从 5 秒延迟开始,每次重试延迟加倍,并添加 0-2 秒的随机抖动以防止多个客户端同时重试时产生惊群效应。将最大延迟上限设为 60 秒,最大重试次数设为 3-5 次。如果所有重试都失败,触发降级到 Nano Banana(Flash)模型,而不是完全放弃——Flash 生成速度更快,服务端错误的恢复窗口也更短。
开发者常犯的一个错误是实现将所有错误同等对待的重试逻辑。本文中的代码示例区分了可重试错误(429、503、超时)和不可重试错误(400、403)。重试 400 Bad Request 会浪费时间和 API 配额,因为同样格式错误的请求永远会失败。同样,在几秒内立即重试 503 错误也不太可能成功,因为服务器过载需要几分钟到几小时才能消除——你的重试逻辑应该识别 503 错误并立即切换到降级模型,或者实现更长的等待时间(至少 5-10 分钟)后再重试 Pro 模型。
Gemini API 与 Vertex AI——平台对比
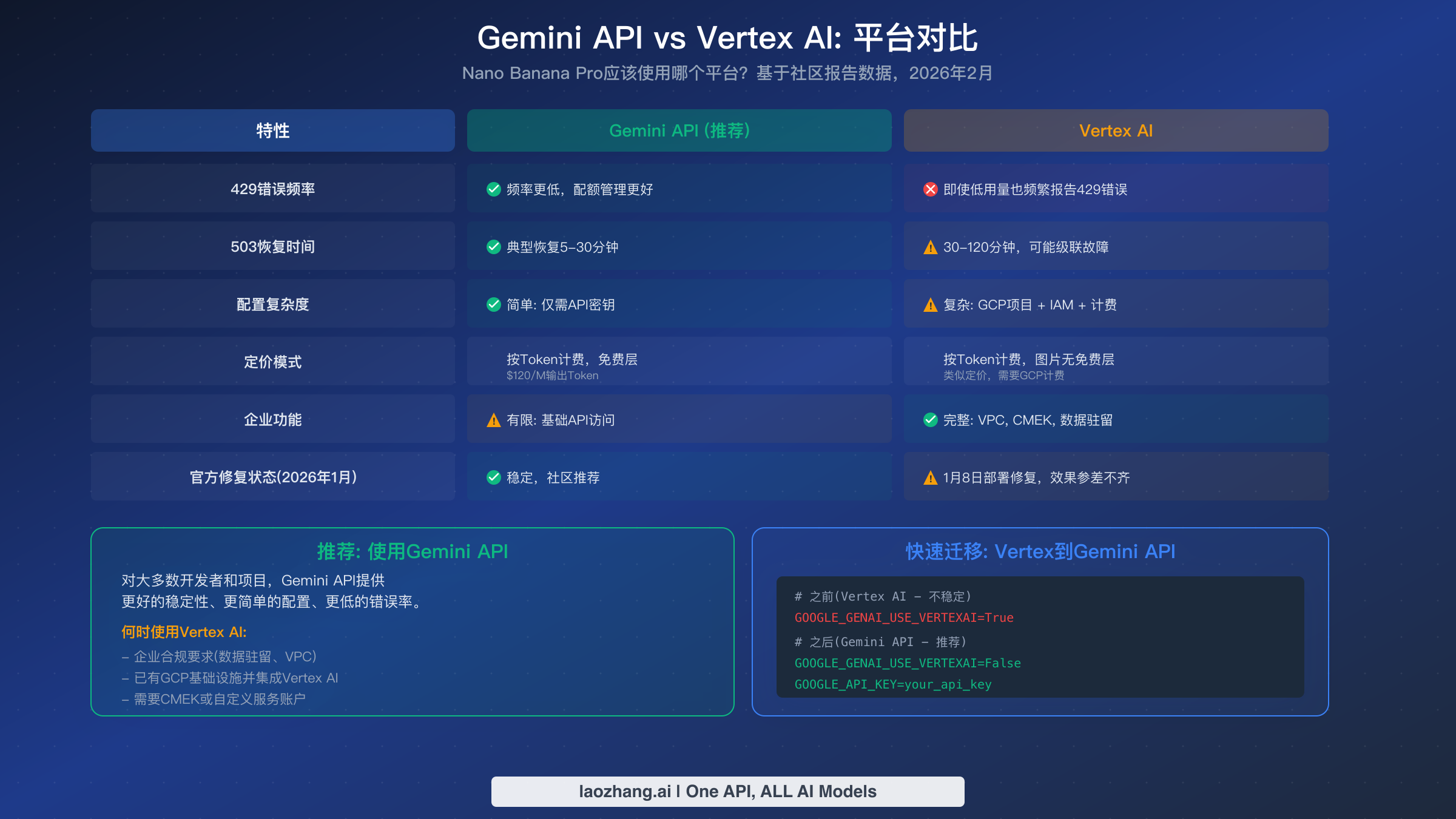
选择使用 Google 的 Gemini API 还是 Vertex AI 来运行 Nano Banana Pro 对可靠性有重大影响,而社区的共识很明确:Gemini API 目前对图片生成工作负载更稳定。这一评估基于 Google AI 开发者论坛上广泛的开发者报告,并得到了 Google 自身支持团队行动的佐证——当开发者报告 Vertex AI 上持续出现 429 错误时,Google 支持团队表示修复已于 2026 年 1 月 8 日部署,但效果仍不一致。
稳定性差异在 429 错误频率上最为明显。多位开发者报告说,通过设置 GOOGLE_GENAI_USE_VERTEXAI=False 从 Vertex AI 切换到 Gemini API 后,即使工作负载和账户完全相同,RESOURCE_EXHAUSTED 错误也被消除或大幅减少。一个特别典型的报告描述了在 Vertex AI 上"某天速度快如闪电"但第二天就不断遇到资源耗尽错误的情况,尽管整体使用量很低——而切换到 Gemini API 后这种行为不再出现。根本原因似乎在于两个平台对图片生成模型的配额池分配和管理方式不同。
实际影响不仅限于错误频率。Vertex AI 需要完整的 GCP 项目设置,包括 IAM 配置、计费账户和服务账户凭据,这增加了初始部署和调试的复杂性。相比之下,Gemini API 只需要一个 API 密钥——你可以在一分钟内完成设置并开始使用。在定价方面,两个平台使用相同的按令牌计费模型(Nano Banana Pro 每百万输出令牌 $120),但截至 2026 年 2 月(参见 ai.google.dev/pricing),两个平台目前都没有为图片生成提供免费层级,不过 Gemini API 的计费设置要简单得多。
然而,Vertex AI 对企业用例有其合理的优势。如果你的组织需要数据驻留控制、虚拟私有云(VPC)集成、客户管理的加密密钥(CMEK)或自定义服务账户,Vertex AI 是唯一的选择。拥有现有 GCP 基础设施的大型企业可能也更倾向于选择 Vertex AI,因为它与其他 Google Cloud 服务的集成更好,即使这意味着图片生成的可靠性会有所降低。
对大多数开发者来说,从 Vertex AI 迁移到 Gemini API 非常简单。如果你使用的是官方 Google Gen AI SDK,切换只需要更改环境变量——不需要修改任何代码:
bash# Before (Vertex AI — higher 429 error rates reported) GOOGLE_GENAI_USE_VERTEXAI=True GOOGLE_CLOUD_PROJECT=your-gcp-project GOOGLE_CLOUD_REGION=us-central1 # After (Gemini API — recommended for stability) GOOGLE_GENAI_USE_VERTEXAI=False GOOGLE_API_KEY=your_gemini_api_key
你的提示词代码、响应处理和图片处理逻辑保持完全不变,因为 Google Gen AI SDK 封装了平台差异。你的应用程序中唯一可见的变化将是错误率降低和凭据管理简化。对于需要将 Vertex AI 作为企业合规降级方案同时使用 Gemini API 作为主要路径的项目,一个简单的环境变量切换就能在两者之间动态切换——你甚至可以实现自动平台切换,先尝试 Gemini API,只有在特定请求需要企业级功能(如 VPC 隔离)时才降级到 Vertex AI。
迁移时需要注意的一点:如果你现有的 Vertex AI 设置使用服务账户模拟或工作负载身份联合进行认证,这些机制是 GCP 特有的,不会迁移到 Gemini API。你需要从 Google AI Studio 生成一个标准 API 密钥。这里的权衡是简单性与细粒度访问控制——API 密钥更容易管理,但相比 GCP IAM 角色提供的权限控制更为粗放。对于大多数图片生成工作负载,API 密钥方式已经足够,而稳定性的提升完全值得采用这种更简单的认证模型。如果你正在评估平台之间的成本和性能,我们的定价与速度测试结果提供了可以为你决策提供参考的量化对比。
成本优化与最佳实践
在生产环境中运行 Nano Banana Pro 需要关注成本管理,因为重试、失败请求和不当的时间安排会显著增加你的 API 支出。通过官方 API 生成一张 2K 图片约花费 $0.134,但如果你的重试逻辑在高峰时段因 429 错误而每次成功生成都触发三次尝试,你的实际成本就会翻三倍。理解错误处理策略的成本影响,对于在规模化运营中保持图片生成的经济可行性至关重要。
最具影响力的成本优化是避开高峰时段。根据生产用户分享的监控数据,高峰时段的 503 错误率可达 45%,这意味着近一半的 API 调用会失败并需要重试。如果你的使用场景允许批量处理——生成营销素材、产品图片或内容配图——将这些作业安排在非高峰时段(根据社区报告,大约在北京时间 03:00-08:00 和 14:00-19:00)可以将重试率从近 50% 降低到 10% 以下,有效降低 30-40% 的成本。
模型降级是第二个主要的成本杠杆。当 Nano Banana Pro(Gemini 3 Pro Image)遇到高错误率时,降级到标准 Nano Banana 模型(Gemini 2.5 Flash Image,gemini-2.5-flash-image)可以提供成本大幅降低的可行替代方案。虽然 Flash 模型缺少"思考"过程,生成的构图也相对简单,但它生成速度更快,可靠性也明显更高。对于非关键的图片生成任务,你甚至可以考虑将 Flash 模型作为主要选择,仅在特别需要高级文字渲染、复杂构图或 4K 分辨率功能时才使用 Pro。
对于处理大量图片的开发者,Google 的 Batch API 提供输出令牌定价 50% 的折扣——将 2K 图片的每张成本从约 $0.134 降至 $0.067。代价是延迟:批量请求可能需要长达 24 小时才能完成。如果你的工作流可以容忍这种延迟,成本节省是非常可观的。第三方 API 代理服务如 laozhang.ai 提供了另一条成本优化路径,以约 $0.05 每张的价格提供 Nano Banana Pro 的访问——大约比官方 API 定价低 60%——还内置了重试逻辑和跨多个 API 密钥的负载均衡,可以平滑速率限制问题。
监控 API 健康状况是最后一个长期受益的最佳实践。按日和按小时跟踪你的成功率、平均延迟、错误类型分布(429 vs 503 vs 其他)和每张成功图片的成本。这些数据揭示了规律——比如特定时段错误率飙升——让你可以优化调度、调整重试参数,并做出关于等级升级或平台切换的明智决策。上面生产代码部分的代码示例通过其结构化日志方法为这种监控提供了基础。要更全面地了解免费版与专业版限制如何影响你的成本结构,查看等级对比可以帮助你为使用量选择合适的方案。
常见问题
为什么我的 Nano Banana Pro API 调用返回了多张图片?
这是正常的"思考"过程行为,不是错误。Nano Banana Pro 会生成最多两张草稿图片来测试构图和逻辑,然后再生成最终结果。API 响应中的最后一张图片始终是最终的、已计费的输出。草稿图片以 60-80% 的分辨率生成,不单独收费。如果你使用官方 Google Gen AI SDK 的聊天模式,思考签名会自动处理多轮上下文。
429 错误和 503 错误有什么区别?
429 错误意味着你超出了速率限制——由你的使用模式导致,通常在 1-5 分钟内恢复。503 错误意味着 Google 的服务器过载——与你的代码或使用量无关,可能需要 30-120 分钟才能恢复。遇到 503 错误时不要调试你的代码,遇到 429 错误时也不要只是干等,而应该检查你的速率限制使用情况。
Nano Banana Pro 应该使用 Gemini API 还是 Vertex AI?
对于大多数开发者,推荐使用 Gemini API。社区报告一致显示 429 错误率更低、设置更简单(只需 API 密钥,无需完整 GCP 项目),定价也相同。只有在需要 VPC 集成、数据驻留控制或客户管理加密密钥等企业功能时才使用 Vertex AI。
API 超时应该设置多长?
对于 1K 和 2K 图片,使用 300 秒。对于 4K 图片,使用 600 秒。这些值考虑了生成时间(30-170 秒,取决于分辨率)加上高峰时段的网络波动和服务器排队延迟。始终将连接超时(10 秒)和读取超时分开设置。
为什么在 Google AI Studio 中一直看到"An internal error has occurred"?
这通常是 Google 后端的 500 Internal Server Error,不是你造成的。多位开发者报告此问题在 2025 年 12 月持续了数天,之后 Google 部署了修复。查看 Google AI 开发者论坛看看其他人是否遇到同样的问题,这通常表示系统性问题而非账户特定的问题。清除浏览器缓存并刷新会话有时对 Web 界面有帮助,但对于持续的 API 错误,你需要等待 Google 解决后端问题。
临时思考图片会计入我的配额吗?
不会。只有最终渲染的图片计入你的速率限制配额并被计费。思考过程中生成的临时草稿图片是模型推理的内部产物,不消耗你的 RPM、RPD 或计费配额。Google 官方图片生成文档已确认这一点。
如何降低生产环境中的 Nano Banana Pro API 成本?
三种最有效的成本降低策略是:避开高峰时段(将批量作业安排在北京时间 03:00-08:00 或 14:00-19:00 可以减少 30-40% 的重试驱动成本)、模型降级(对非关键任务使用 Gemini 2.5 Flash Image,每张 $0.039,而非 Pro 的每张 $0.134),以及 Google 的 Batch API(2K 分辨率每张 $0.067 的 50% 折扣,代价是最长 24 小时的处理延迟)。第三方代理服务如 laozhang.ai 可以进一步将成本降至约每张 $0.05,并内置重试逻辑和负载均衡。对于大批量生产工作负载,结合三种策略——Batch API 处理不紧急的任务、Flash 用于标准质量、Pro 仅用于高端输出——与对每个请求都直接调用 Pro 模型相比,可以将有效图片生成成本降低 60-70%。
Nano Banana 和 Nano Banana Pro 有什么区别?
Nano Banana 指的是标准模型 Gemini 2.5 Flash Image(gemini-2.5-flash-image),它生成速度快、成本低(每张 $0.039),但没有高级思考过程。Nano Banana Pro 指的是 Gemini 3 Pro Image(gemini-3-pro-image-preview),它使用多草稿思考机制来实现更高质量的构图、更好的文字渲染和 4K 分辨率支持,但成本更高(2K 每张 $0.134)且生成时间更长(30-170 秒 vs Flash 的 10-30 秒)。在生产环境中,推荐的方式是将 Pro 作为主要模型,Flash 作为自动降级方案——这样在 Pro 模型可用时能获得最佳质量,同时在服务器过载期间保持服务连续性。