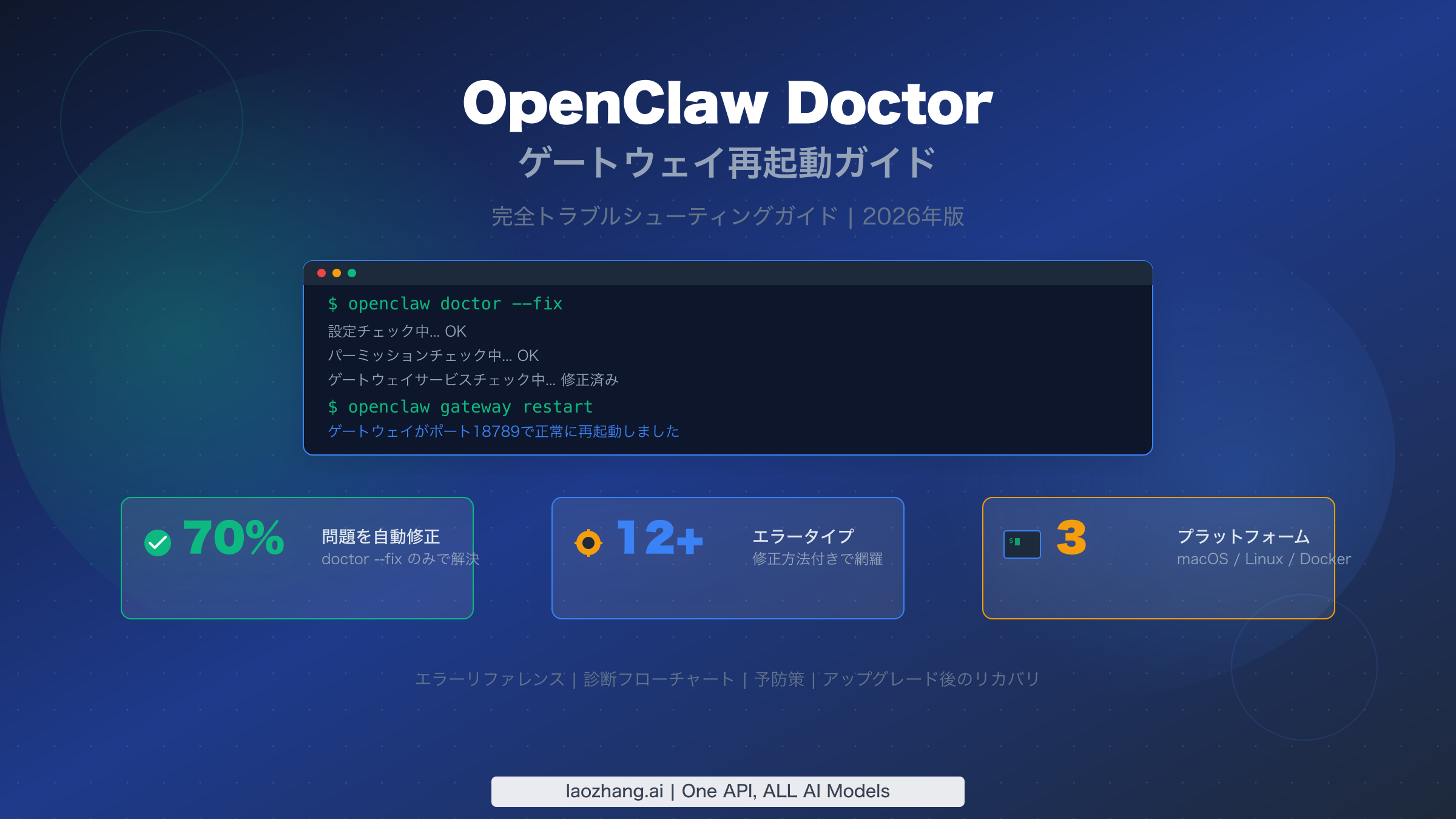
OpenClawのopenclaw doctor --fixコマンドは、設定のドリフトを監査して自動修復し、コミュニティ分析(ClawTank、2026年3月)によると約70%のゲートウェイ問題を解決します。openclaw gateway restartと組み合わせることで、この2つのコマンドがOpenClawトラブルシューティングの基盤となります。本ガイドでは、遭遇する可能性のあるすべてのエラーメッセージ、macOS・Linux・Docker各プラットフォーム固有の修正方法、アップグレード後のリカバリ手順、そして予防的メンテナンス戦略を、2026年3月時点の公式OpenClawドキュメントに基づいて網羅しています。
まとめ
以下の2つのコマンドを実行すれば、ほとんどのOpenClawゲートウェイの問題を修正できます:
bashopenclaw doctor --fix openclaw gateway restart
この組み合わせで、ゲートウェイの問題の約70%が自動的に解決されます。それでもゲートウェイが起動しない場合は、openclaw gateway statusを実行して、サービスの停止、RPCプローブの失敗、設定エラーのいずれが原因かを特定し、以下の診断フローチャートに従ってください。最も一般的な根本原因は、ポート競合(45%)、サービス未起動(30%)、設定エラー(15%)です。
ゲートウェイ問題の70%を解決する30秒修正
OpenClawのゲートウェイが応答しなくなったとき、ログファイルや設定を調べたくなるのは自然なことです。しかし、その衝動を30秒だけ抑えてください。最も速い回復方法は、ほぼ常に同じ2つのコマンドのシーケンスであり、なぜこれが効果的なのかを理解すれば、将来のデバッグで何時間もの時間を節約できます。
openclaw doctor --fixコマンドは、OpenClawインストールの包括的な監査を実行します。ディレクトリ構造をチェックし、ファイルパーミッションを検証し、~/.openclaw/openclaw.jsonの設定ファイルを検証し、必要なサービスが正しく登録されているか確認し、ポートバインディングが宣言された設定と一致するかを確認します。問題が見つかると(典型的な障害のあるゲートウェイでは通常1〜2個の設定ミスがあります)、自動的に修正します。--fixフラグこそが、このコマンドを単なる情報提供ではなく強力なものにする要素です。--fixなしでは、doctorは問題を報告するだけで解決はしません。
doctorコマンドに続いてopenclaw gateway restartを実行すると、ゲートウェイプロセスが適用されたすべての修正を確実に読み込みます。再起動シーケンスはクリーンです:既存のゲートウェイプロセスを正常に停止し(SIGTERMを送信してから、処理中のWebSocket接続がドレインされるのを待機)、修正された設定で新しいインスタンスを起動します。WhatsApp、Slack、Discord、Telegramなどのチャンネル接続は一時的に切断されますが、数秒以内に自動的に再接続されます。
この2コマンドアプローチがこれほど頻繁に機能する理由は、ほとんどのゲートウェイ障害が根本的なシステム問題ではなく、設定のドリフトに起因するからです。OpenClawの更新、新しいプラグインのインストール、モデル設定の変更、チャンネル設定の修正を行うと、小さな不整合が蓄積される可能性があります。パーミッションが厳しくなったり、ディレクトリがまだ存在しなかったり、設定キーが廃止されたスキーマを参照していたりすることがあります。doctorコマンドはこれらのドリフトシナリオを特に対象としており、このアプローチだけでコミュニティが約70%の成功率を報告している理由です。
これらのコマンドを実行した後にゲートウェイが正常に起動すれば、完了です。起動しない場合は、以下の診断セクションに進んで、具体的な障害モードを特定してください。
openclaw doctorとgateway restartが実際に行うこと
これらのコマンドの仕組みを理解すれば、トラブルシューティングの謎が解け、それぞれを独立して使用するタイミングを判断できるようになります。これらは互換性のあるツールではなく、根本的に異なる目的を果たすものであり、その違いを知ることで不要なコマンドの実行を防ぎ、さらに悪いことに、実際に必要なコマンドをスキップすることを防げます。
openclaw doctorコマンドは設定監査ツールとして動作します。実行すると、プロセスはインストールディレクトリ(通常は~/.openclaw/)、システムサービス設定、ランタイム環境を読み取ります。各コンポーネントを期待される条件セットに対してチェックします:設定ファイルは正しくパースされるか?参照されるすべてのディレクトリが存在し書き込み可能か?ゲートウェイサービスは正しいバイナリパスで登録されているか?宣言されたポートはサービスファイルの指定と一致するか?各チェックはパス、警告、または失敗を生成します。--fixフラグを使用すると、失敗は自動修正アクションをトリガーします — 不足しているディレクトリの作成、不正なサービスファイルの書き換え、ファイルパーミッションのリセットなどです。--fixなしでは、手動で対処できる診断レポートが得られます。これは何かを変更する前に問題を理解したい場合に適しています。
openclaw gateway restartコマンドは、対照的に、純粋なサービスライフサイクル操作です。設定の検査や修復は行いません。実行中のゲートウェイプロセスに停止シグナルを送信し、終了を待機し(デフォルトタイムアウト60秒)、新しいプロセスを起動します。ゲートウェイ実行ファイルは起動時に~/.openclaw/openclaw.jsonを読み取り、設定されたポート(デフォルト18789)にバインドし、WebSocket接続の受け入れを開始します。再起動時に設定ファイルにエラーが含まれていると、新しいプロセスは起動に失敗します — これこそが、再起動前にdoctor --fixを実行することが非常に効果的な理由です。
このコンテキストで言及する価値のある3番目のコマンドがあります:openclaw gateway install --force。このコマンドはゲートウェイをシステムサービスとして再登録し(macOSではLaunchAgent、Linuxではsystemdユーザーサービス)、既存のサービス定義を上書きします。単純な再起動よりも積極的で、サービス登録自体が破損した場合に特に有用です — これはOSの更新後やOpenClawバージョンの切り替え時に時折発生するシナリオです。変更されたOpenClaw APIキーの設定を扱っている場合、install --forceの後にrestartを実行すれば、サービスが新しい設定を完全に読み込むことが保証されます。
重要な違いの1つ:openclaw doctorはワンショットの診断プロセスとして実行されて終了します。一方、ゲートウェイは長時間実行されるデーモンです。doctorの実行は、--fixフラグがゲートウェイが依存するサービスファイルを書き換えない限り、現在実行中のゲートウェイに影響を与えません。サービスファイルが書き換えられた場合は、変更を適用するために再起動が必要です。
60秒で問題を診断する
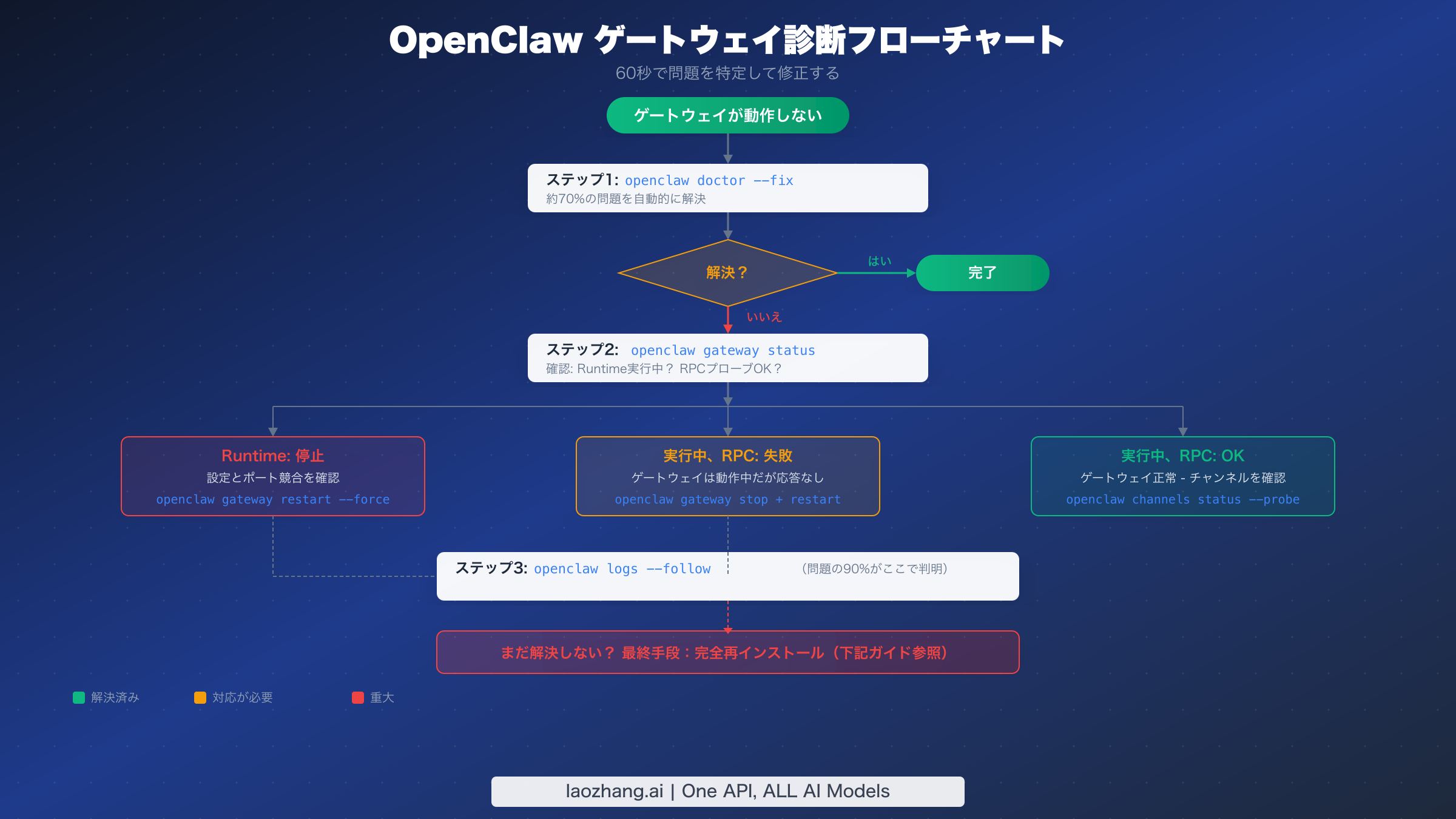
ユニバーサル修正で問題が解決しない場合、次のステップは実際に何が壊れているかを体系的に特定することです。OpenClawに組み込まれた診断コマンドは、障害モードを直接指し示す構造化された出力を提供するため、推測する必要がありません。このセクションでは、コマンドの正確なシーケンスとその出力が示す内容を解説します。
まずopenclaw gateway statusから始めましょう。これはトラブルシューティングツールキットで最も情報量の多いコマンドです。その出力は2つの重要なことを教えてくれます:ゲートウェイプロセスが実行中かどうか、そして接続を受け入れているかどうかです。正常なゲートウェイはRuntime: runningとRPC probe: okを表示します。このパターンからの逸脱は、特定の問題カテゴリを示します。
Runtime: stoppedと表示される場合、ゲートウェイプロセスがまったく実行されていません。これは通常、サービスの起動失敗(設定エラーを確認)、プロセスのクラッシュ(ログでクラッシュ出力を確認)、またはサービスがインストールされていないことを意味します。最も一般的な原因は、起動を妨げる設定の問題です。例えば、ローカル専用デプロイメントでgateway.modeがlocalに設定されていない場合などです。openclaw config get gateway.modeを実行してこの設定を確認し、何も返されないかlocal以外の値が返された場合は、openclaw config set gateway.mode localで設定してください。
Runtime: runningだがRPC probe: failedと表示される場合、ゲートウェイプロセスは生きていますがヘルスチェックに応答していません。これはより微妙な問題で、通常は3つのことのいずれかを示します:ゲートウェイがまだ初期化中(特にDockerでは初期化に約40秒かかるため、60秒待ってください)、ゲートウェイが予想とは異なるポートにバインドされている(openclaw config get gateway.portを確認)、またはプロセスがデッドロック状態でスタックしている場合です。最後のシナリオには、openclaw gateway stop --forceの後にopenclaw gateway startを実行するのが対処法です。
ゲートウェイステータスの確認後、次の診断コマンドはopenclaw logs --followです。このコマンドはゲートウェイのログファイルをリアルタイムでテールし、コミュニティレポートによると、残りの問題の約90%の根本原因を明らかにします。ログエントリにはタイムスタンプとカテゴリが付けられているため、出力でERRORまたはFATALとマークされたエントリを探してください。一般的なパターンには、パーミッション拒否エラー(プロセスがファイルを読み取れないかポートをバインドできない)、接続拒否エラー(アップストリームサービスやAPIエンドポイントに到達できない)、設定検証の失敗(必須フィールドが欠落しているか不正な形式)が含まれます。
ゲートウェイは動作しているがメッセージが配信されないチャンネル固有の問題については、openclaw channels status --probeを使用してください。このコマンドは設定された各チャンネルの接続を個別にテストし、正常なものと障害のあるものを報告します。すべてのチャンネルが接続済みと表示されるがメッセージがまだ流れていない場合、問題はゲートウェイの障害ではなく、ペアリングまたはメンション設定の問題である可能性が高いです — DMポリシー設定とグループメンションパターンを確認してください。
すべてのゲートウェイエラーとその修正方法

このセクションはルックアップテーブルとして機能します。表示されているエラーメッセージを見つけ、なぜ発生するかを理解し、対象を絞った修正を適用してください。各エントリには、問題を解決する正確なコマンドと、修正成功後の期待される出力が含まれています。すべての修正は、2026年3月時点の公式OpenClawドキュメントとコミュニティレポートに対して検証されています。
「Gateway start blocked: set gateway.mode=local」
これは初回インストールで最も一般的なエラーです。OpenClawのゲートウェイは、動作モードを明示的に宣言しない限り起動を拒否します。デフォルトでは、潜在的に安全でない設定を想定するのではなく、起動をブロックします。解決するには、openclaw config set gateway.mode localを実行してからopenclaw gateway restartを実行してください。localモードはゲートウェイをループバック接続のみに制限し、シングルマシンデプロイメントに適しています。リモートアクセスが必要な場合は、gateway.modeをremoteに設定し、openclaw config set gateway.auth.token YOUR_TOKENで適切な認証を設定してください。
「Timed out after 60s waiting for gateway port 18789 to become healthy」
ゲートウェイプロセスは起動しましたが、デフォルトの60秒ウィンドウ内に接続の受け入れを開始しませんでした。リソースが制限されたシステム — 特に小さなVPSインスタンス上のDockerコンテナ — では、初期化に60秒以上かかることが実際にあります。最初に確認すべきは、プロセスがまだ起動中なのか、初期化中にクラッシュしたのかです。このエラーの直後にopenclaw gateway statusを実行してください。ランタイムが実行中と表示される場合は、さらに30〜60秒待ってから再度確認してください。停止と表示される場合は、openclaw logs --followでログを確認して具体的な起動失敗を調べてください。Dockerデプロイメントでは、コンテナの初期化だけで約40秒かかり、ゲートウェイの起動に残されるのは20秒のみです — 1 vCPUのマシンではタイトです。VPSに1GBのスワップスペースを追加すると、これらのタイムアウト問題が恒久的に解決されることが多いです。
「Another gateway instance is already listening on port 18789」
ポート競合は、2つのプロセスが同じポートにバインドしようとするときに発生します。これは、古いClawdbot命名からOpenClawにアップグレードした後に最も頻繁に発生し、レガシーのclawdbot-gatewayサービスが新しいopenclaw-gatewayサービスと並行して実行されている可能性があります。競合するプロセスを特定するには、lsof -i :18789(macOS/Linux)またはss -tlnp | grep 18789(Linux)を実行してください。古いプロセスを終了してから再起動します:openclaw gateway restart。再発を防ぐために、古いサービスを完全にアンインストールしてください:Linuxではsystemctl --user disable clawdbot-gateway.service && systemctl --user stop clawdbot-gateway.service、macOSでは古いLaunchAgent plistを~/Library/LaunchAgents/から削除してください。
「Refusing to bind gateway on 0.0.0.0 without auth」
OpenClawは、不正アクセスを防ぐために、認証なしの非ループバックバインディングを正しくブロックします。ゲートウェイを他のマシンからアクセス可能にしたい場合(ダッシュボードやモバイルクライアント経由のリモートアクセス用)、まず認証を設定する必要があります:openclaw config set gateway.auth.mode tokenの後にopenclaw config set gateway.auth.token YOUR_SECURE_TOKENを実行してください。ローカルで実行していてリモートアクセスが不要な場合は、ループバックのみにバインドを設定してください:openclaw config set gateway.bind loopback。
「AUTH_DEVICE_TOKEN_MISMATCH」または「PAIRING_REQUIRED」
ゲートウェイの再起動後、既存のクライアント接続がデバイスペアリングを失う場合があります。これはGitHub Issue #22062に記載された既知の問題です。修正は簡単です:このエラーが表示される各クライアントで、ペアリングフローを再度実行してください。CLIクライアントの場合はopenclaw pairを使用します。ウェブダッシュボードの場合はペアリングページに移動してQRコードをスキャンしてください。計画的な再起動時のペアリング中断を最小限に抑えるために、デバイスごとのトークンローテーションを回避するgateway.auth.mode passwordオプションの使用を検討してください。
「HTTP 429: rate_limit_error: Extra usage is required for long context requests」
このエラーはOpenClaw自体からではなく、アップストリームのAnthropic APIから発生します。使用しているモデルでparams.context1m: trueが有効になっているが、APIキーにロングコンテキストアクセスがない場合に表示されます。拡張コンテキストウィンドウを無効にするか(openclaw config set agents.defaults.models.context1m false)、Anthropic APIキーにロングコンテキスト対応のアクティブな課金があることを確認して解決してください。個々のプロバイダーキーを管理せずに信頼性の高いAPIアクセスが必要な場合は、プロバイダーローテーションを処理しレート制限の影響を軽減するlaozhang.aiのようなAPIアグリゲーションサービスの利用を検討してください — 完全なセットアップ手順はOpenClawとlaozhang.aiの連携ガイドをご覧ください。OpenClaw 429レート制限エラーの修正の詳細については、専用のトラブルシューティング記事をご参照ください。
「NODE_BACKGROUND_UNAVAILABLE」または「SYSTEM_RUN_DENIED」
これらのエラーは、ゲートウェイは動作しているがOpenClawのノードツール(ブラウザ自動化、システムコマンド)が実行できないことを示します。openclaw nodes statusでノードのステータスを確認してください。ノードがオフラインの場合は再起動してください。オンラインだがパーミッションが拒否される場合は、ノードのツール許可リストとOS レベルのパーミッション(macOSではカメラ、マイク、画面アクセスにシステム環境設定での明示的な許可が必要)を確認してください。
プラットフォーム別の修正方法(macOS、Linux、Docker)

コアとなるトラブルシューティングコマンドはプラットフォーム間で同じですが、サービス管理レイヤーはmacOS、Linux、Dockerで大きく異なります。Linuxで完璧に動作するコマンドがmacOSではサイレントに失敗する場合があり、Dockerデプロイメントにはコンテナライフサイクル管理に関する独自の制約があります。このセクションでは、一般的なトラブルシューティングガイドではしばしば見落とされるプラットフォーム固有のニュアンスについて説明します。
macOS(LaunchAgent)
macOSでは、OpenClawゲートウェイはLaunchAgent — launchdによって管理されるユーザーごとのバックグラウンドサービス — として実行されます。サービス定義は~/Library/LaunchAgents/com.openclaw.gateway.plistにあります。macOSでopenclaw gateway restartが失敗する場合、最も一般的な原因は、停止フェーズ後にLaunchAgentが適切に再登録されなかったことです。これはGitHub Issue #42775に記載された既知の問題で、restartコマンドはゲートウェイの停止には成功しますが、launchctlがサービスを再ブートストラップしないため起動に失敗します。
信頼性の高い回避策は、失敗した再起動の後にopenclaw gateway install --forceを使用することです。このコマンドはplistファイルを再生成し、launchdに明示的にロードすることで、再登録の問題をバイパスします。これでも失敗する場合は、エージェントを手動でアンロードしてリロードしてください:launchctl bootout gui/$(id -u)/com.openclaw.gatewayの後にlaunchctl bootstrap gui/$(id -u) ~/Library/LaunchAgents/com.openclaw.gateway.plistを実行します。
macOSのゲートウェイログは~/Library/Logs/openclaw/に書き込まれ、Console.appで「openclaw」プロセスをフィルタリングして表示することもできます。リアルタイムのログ監視には、openclaw logs --followが最も便利なオプションです。
Linux(systemd)
Linuxデプロイメントではsystemdユーザーサービスを使用します。サービスファイルは通常~/.config/systemd/user/openclaw-gateway.serviceにあります。Linux固有の最も重要な考慮事項は、リンガリングの有効化です。これにより、ユーザーがログアウトした後もユーザーサービスが持続できます。リンガリングがないと、SSHセッションが終了するたびにゲートウェイが停止します。loginctl enable-linger $USERで有効化してください。
メモリが限られたVPSデプロイメント(1GB以下)では、ピーク負荷時にOOM(Out of Memory)キラーによってゲートウェイが強制終了される場合があります。スワップスペースを追加することでこれを防げます:sudo fallocate -l 1G /swapfile && sudo chmod 600 /swapfile && sudo mkswap /swapfile && sudo swapon /swapfile。スワップを永続的にするには、/swapfile none swap sw 0 0を/etc/fstabに追加してください。
Linuxでゲートウェイログを表示するには、リアルタイム監視にjournalctl --user -u openclaw-gateway -fを使用するか、同じ基盤メカニズムをラップするopenclaw logs --followを使用してください。
Docker
Dockerデプロイメントでは、ネイティブインストールには存在しないコンテナライフサイクルの考慮事項が発生します。最も重要な違いは、openclaw doctorはホストではなくコンテナ内で実行する必要があるということです。docker exec -it CONTAINER_NAME openclaw doctor --fixを使用してください。CONTAINER_NAMEはゲートウェイコンテナの名前です(docker psで確認できます)。
再起動はopenclaw gateway restartコマンドではなく、Docker Composeを通じて処理されます:docker compose restart openclaw-gateway。コンテナの状態もリセットするより徹底的な再起動には、docker compose up -d --force-recreate openclaw-gatewayを使用してください。コンテナの初期化はゲートウェイ自体の起動時間に加えて約40秒のオーバーヘッドを追加するため、Dockerデプロイメントではタイムアウトがより一般的であることに注意してください。
Docker環境での設定は通常、~/.openclaw/openclaw.jsonではなく.envファイルとdocker-compose.ymlにあります。トラブルシューティングの際は、ホストレベルのDocker設定とコンテナ内のOpenClaw設定の両方が一貫しているか確認してください。
アップグレード後のゲートウェイ障害
OpenClawのアップグレードは、標準的なdoctor --fixシーケンスでは完全に解決できないゲートウェイ障害の最も一般的なトリガーです。アップグレードはサービス登録パス、設定スキーマ、認証メカニズムを変更する可能性があるためです — これらは設定のドリフトではなく意図的な設計変更を含むため、doctorコマンドが自動修正できない場合があります。
アップグレード後に最も頻繁に報告される問題は、デュアルサービスの競合です。OpenClawが「Clawdbot」ブランディングから「OpenClaw」に移行した際、インストーラーが古いサービスと並行して新しいサービスを作成しました。両方のサービスがポート18789にバインドしようとするため、ポートがすでに占有されているため各サービスが繰り返し失敗する再起動ループが発生します。解決策は、新しいサービスを起動する前に古いサービスを完全に削除することです。Linuxの場合:systemctl --user stop clawdbot-gateway.service && systemctl --user disable clawdbot-gateway.service。macOSの場合:古いLaunchAgentを停止し、~/Library/LaunchAgents/からそのplistファイルを削除してください。
アップグレード後のもう1つの一般的な問題は、設定スキーマの変更に関するものです。新しいバージョンのOpenClawは設定キーを廃止したり、その期待される形式を変更したりする場合があります。ゲートウェイは起動時に設定を検証し、未知または不正な形式のキーに遭遇すると起動を拒否します。openclaw config validateを実行して廃止された設定を特定してください。出力には各問題のあるキーと推奨される置き換えがリストされます。必要な変更を行った後、ゲートウェイを再起動してください。
アップグレード後の認証変更も既存のクライアント接続を壊す可能性があります。アップグレードが認証メカニズムを変更した場合(例えば、単純なgateway.tokenから新しいgateway.auth.token構造への移行)、すべての接続されたクライアントが再認証する必要があります。これはクライアント側でAUTH_TOKEN_MISMATCHエラーとして現れます。リモートクライアントを新しいトークン形式を使用するように更新してから、ゲートウェイを再起動してください。
これらの問題のほとんどを回避する最も安全なアップグレード手順は、アップグレード前のチェックリストに従うことです:アップグレード前にゲートウェイを停止し(openclaw gateway stop)、アップグレードを実行し、openclaw doctor --fixを実行して必要なマイグレーションを適用し、最後にゲートウェイを起動します(openclaw gateway start)。このシーケンスにより、ゲートウェイが設定をパースする前にdoctorコマンドがスキーママイグレーションを修正する機会が得られます。
ゲートウェイ問題を未然に防ぐ
最も効率的なトラブルシューティングは、そもそも必要のないトラブルシューティングです。OpenClawゲートウェイの予防的メンテナンスは簡単で、週に5分未満しかかかりませんが、ほとんどのオペレーターは何かが壊れたときにのみゲートウェイ設定にアクセスします。シンプルな監視ルーチンを実装すれば、予期しない障害の大部分を排除できます。
予防的メンテナンスの基盤はヘルスチェックコマンドです:openclaw gateway status。このコマンドを毎日実行してください — あるいはさらに良いのは、自動的に実行されるようスクリプト化し、出力が期待されるRuntime: running, RPC probe: okパターンから逸脱したときにアラートを出すことです。openclaw gateway status | grep -q "RPC probe: ok" || echo "Gateway unhealthy" | mail -s "OpenClaw Alert" you@example.comを実行するシンプルなcronジョブで、外部ツールなしの基本的な監視が実現できます。
設定の検証は、OpenClaw設定に変更を加えるたびに実行すべきです。openclaw config validateコマンドは、ランタイム障害の原因になる前に問題を検出します。これは、午前2時にボットが応答しなくなってタイプミスを発見するよりもはるかに望ましいことです。習慣にしてください:設定を変更し、検証し、再起動する。
ディスクスペースは、ゲートウェイ障害の見落とされがちな原因です。ゲートウェイは継続的にログを書き込み、小さなVPSインスタンスでは数週間以内にログファイルが利用可能なディスクスペースをすべて消費する可能性があります。設定でgateway.logs.maxFilesとgateway.logs.maxSizeを設定してログローテーションを構成するか、システム内蔵のログローテーション(Linuxではlogrotate、macOSではnewsyslog)を使用してください。
OpenClawのインストールを最新に保ちつつも、計画的に行ってください。本番環境では最新リリースを追跡するのではなく、特定のバージョンに固定してください。アップグレードする際は、前のセクションのアップグレード前チェックリストに従ってください:停止、アップグレード、doctor、起動。OpenClawのリリースノートを購読しておけば、破壊的変更がデプロイメントに影響する前に把握できます。OpenClawセットアップのコスト効率的な運用については、OpenClawのコスト最適化ガイドで実践的な戦略を紹介しています。
どうしても解決しない場合 — 最終手段
すべての診断ステップを実行し、すべての関連する修正を適用してもゲートウェイが協力しない場合、クリーンな再インストールが最終オプションです。設定がリセットされるため最終手段ですが、既知の正常な状態が保証されます。続行する前に、設定をバックアップしてください:cp -r ~/.openclaw ~/.openclaw.backup。
最終手段の手順は以下の通りです:
bashopenclaw gateway stop --force # 2. サービスのアンインストール openclaw gateway uninstall # 3. 設定ディレクトリの削除 rm -rf ~/.openclaw # 4. OpenClawの再インストール(パッケージマネージャーまたは公式インストーラーを使用) # npmの場合: npm install -g openclaw # brewの場合: brew install openclaw # 5. 初期セットアップの実行 openclaw init # 6. 設定の復元(ディレクトリ全体ではなく、選択的に) # ~/.openclaw.backup/openclaw.json から特定の設定をコピー # 7. ゲートウェイのインストールと起動 openclaw gateway install openclaw gateway start
クリーンな再インストール後、バックアップした設定を参照にしてチャンネル、APIキー、モデル設定をゼロから再設定してください。古い設定ファイルを新しいものにそのままコピーしないでください — 古いファイルに障害の原因となった問題が含まれている可能性があります。代わりに、OpenClawの完全なインストールガイドを参照して、各コンポーネントをクリーンにセットアップしてください。
FAQ
openclaw gateway restartでメッセージが失われますか?
再起動ウィンドウ(通常3〜5秒)の間、受信メッセージはチャンネルプロバイダー(WhatsApp、Slackなど)によってバッファリングされ、ゲートウェイが再接続すると配信されます。メッセージが永久に失われることはありませんが、わずかな遅延が生じる場合があります。計画的な再起動の場合は、トラフィックの少ない時間帯にスケジューリングすることを検討してください。
openclaw restartとopenclaw gateway restartの違いは何ですか?
openclaw restartコマンドは、すべてのノードとサービスを含むOpenClawスタック全体を再起動します。openclaw gateway restartコマンドは、ゲートウェイプロセスのみを再起動します。ゲートウェイ固有の問題のトラブルシューティングには、他のコンポーネントへの影響を最小限に抑えるためにopenclaw gateway restartを使用してください。
ゲートウェイの実行中にopenclaw doctorを実行できますか?
はい。doctorコマンドは設定ファイルを読み取り、実行中のゲートウェイプロセスを変更せずにシステム状態をチェックする診断ツールです。ただし、--fixを使用してdoctorがサービス定義を書き換えた場合は、変更を適用するためにゲートウェイの再起動が必要です。
ゲートウェイをどのくらいの頻度で再起動すべきですか?
通常の運用では、ゲートウェイは定期的な再起動を必要としません。継続的に実行されるように設計されています。設定変更、アップデート、または問題のトラブルシューティング後にのみ再起動してください。頻繁に再起動する必要がある場合は、再起動をワークアラウンドとして扱うのではなく、根本原因を調査してください。
macOSでopenclaw gateway restartがサイレントに失敗するのはなぜですか?
これは既知の問題(GitHub #42775)で、macOSのLaunchAgentが停止フェーズ後に適切に再登録されません。信頼性の高い代替方法として、openclaw gateway install --forceの後にopenclaw gateway startを使用してください。