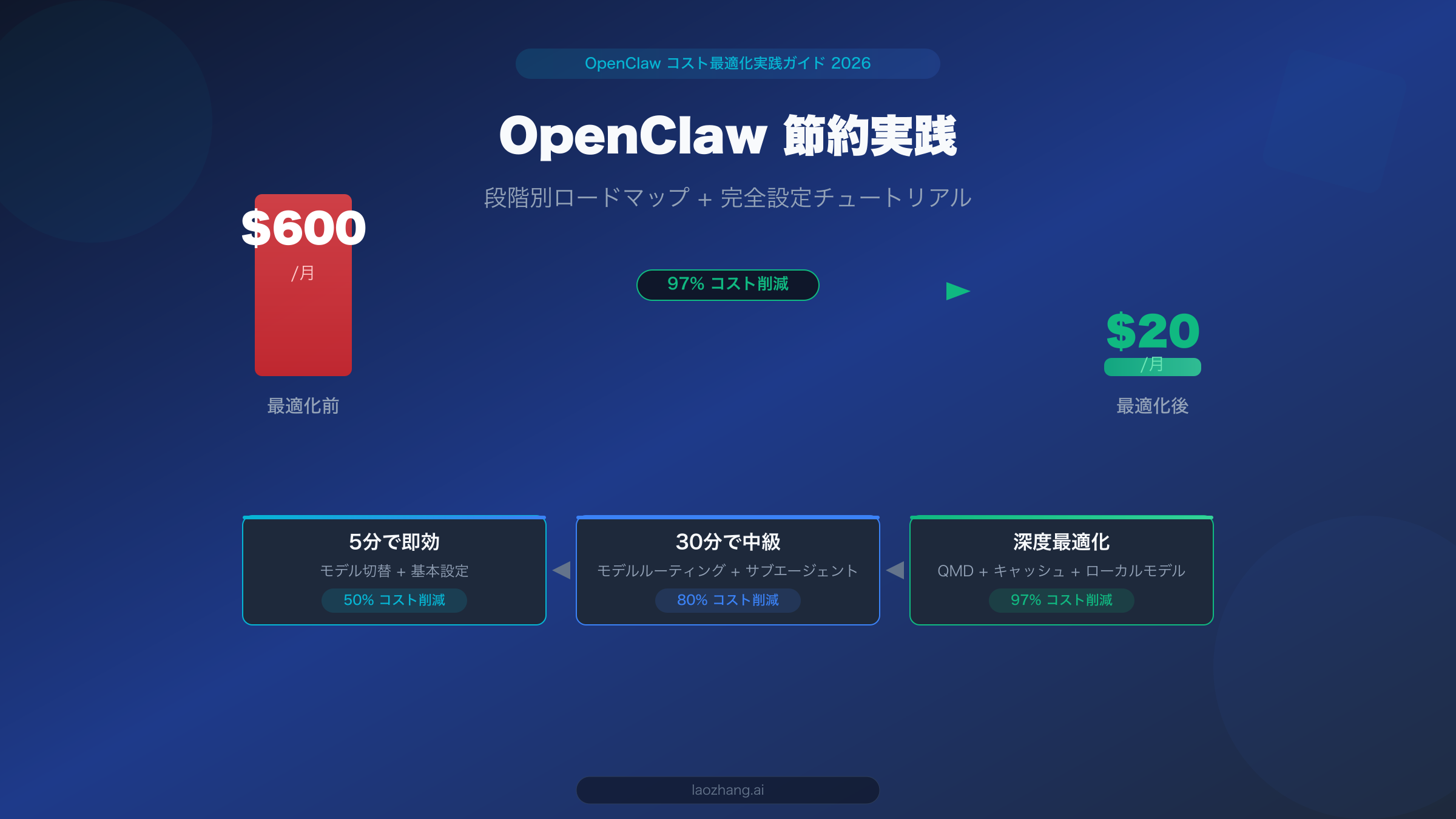
OpenClaw は現在最も強力なオープンソース個人AIアシスタントプラットフォームの一つですが、何の最適化もせずにそのまま使い続けると、月々のAPI請求額が $300〜600 に達することも珍しくありません。しかし朗報があります。本記事で紹介する3段階の最適化アプローチを実践すれば、コア機能を維持しながら月額コストを $20 以下に抑えることが可能です。これは机上の空論ではなく、実際に検証済みの実践的な手法です。5分で効果が出るモデル切替から、QMDローカル検索による深度最適化まで、すべてのステップに具体的な設定方法と実データを添えてお伝えします。
実際の OpenClaw 請求書から見えること
OpenClaw に初めて触れた多くのユーザーは、その強力な機能に感動します。コード作成の支援、ドキュメント分析、スケジュール管理、さらには Discord や Telegram など 12 以上のプラットフォームを通じた対話まで可能です。しかし問題は、1週間ほど夢中で使った後に API 請求書を開いた瞬間に訪れます。1週間の利用で $100 を超えていた、ということが珍しくないのです。
これは特殊なケースではありません。Reddit の r/OpenClaw コミュニティ、各種技術フォーラムにおいて、「OpenClaw の料金が高すぎる、どうすればいい?」は最も頻繁に投稿される質問の一つです。コミュニティのフィードバックと複数の技術記事の統計データによると、最適化を行っていない OpenClaw の月間 API 費用は通常 $300〜600、ヘビーユーザーでは $1000 を超えるケースもあります。この背景には、多くのユーザーが使い始めの段階で Token の課金メカニズムを理解しておらず、デフォルト設定でどれだけの「見えないコスト」が予算を食い潰しているか把握していないという事実があります。
典型的なシナリオで問題の深刻さを説明しましょう。OpenClaw のデフォルトモデル Claude Opus 4.6 を使って日常的な開発支援を行い、1日約 20 回の対話を行い、各対話で平均 5000 Token のコンテキストと 2000 Token のモデル応答が発生するとします。Anthropic の公式価格(入力 $5/MTok、出力 $25/MTok、2026年3月データ)で計算すると、1日の API 費用は次の通りです。入力コスト 20 x 5000 / 1M x $5 = $0.5、出力コスト 20 x 2000 / 1M x $25 = $1.0、合計 $1.5/日。一見それほど高額ではありませんが、OpenClaw の対話はコンテキストが累積される仕組みになっています。つまり第10回目の対話では、前の9回分の内容がすべてコンテキストとしてモデルに再送信されるため、実際に消費される Token 量は指数関数的に増加します。ツール呼び出しやシステムプロンプトなどの追加オーバーヘッドを加えると、実際の1日あたりのコストは理論値の 5〜10 倍に膨れ上がり、$10〜20/日を簡単に超えてしまいます。
朗報として、この問題は完全に解決可能です。本記事では実証済みの3段階最適化アプローチを紹介します。第1段階はたった5分で費用の 50% を削減できます。第2段階では30分でモデルルーティングを設定し、さらに 80% の削減を実現します。第3段階では QMD ローカル検索とキャッシュ戦略により、97% の究極的なコスト最適化を達成します。まずは「お金が実際にどこに使われているのか」を理解するところから始めましょう。
お金はどこに消えている? Token 消費の全体像
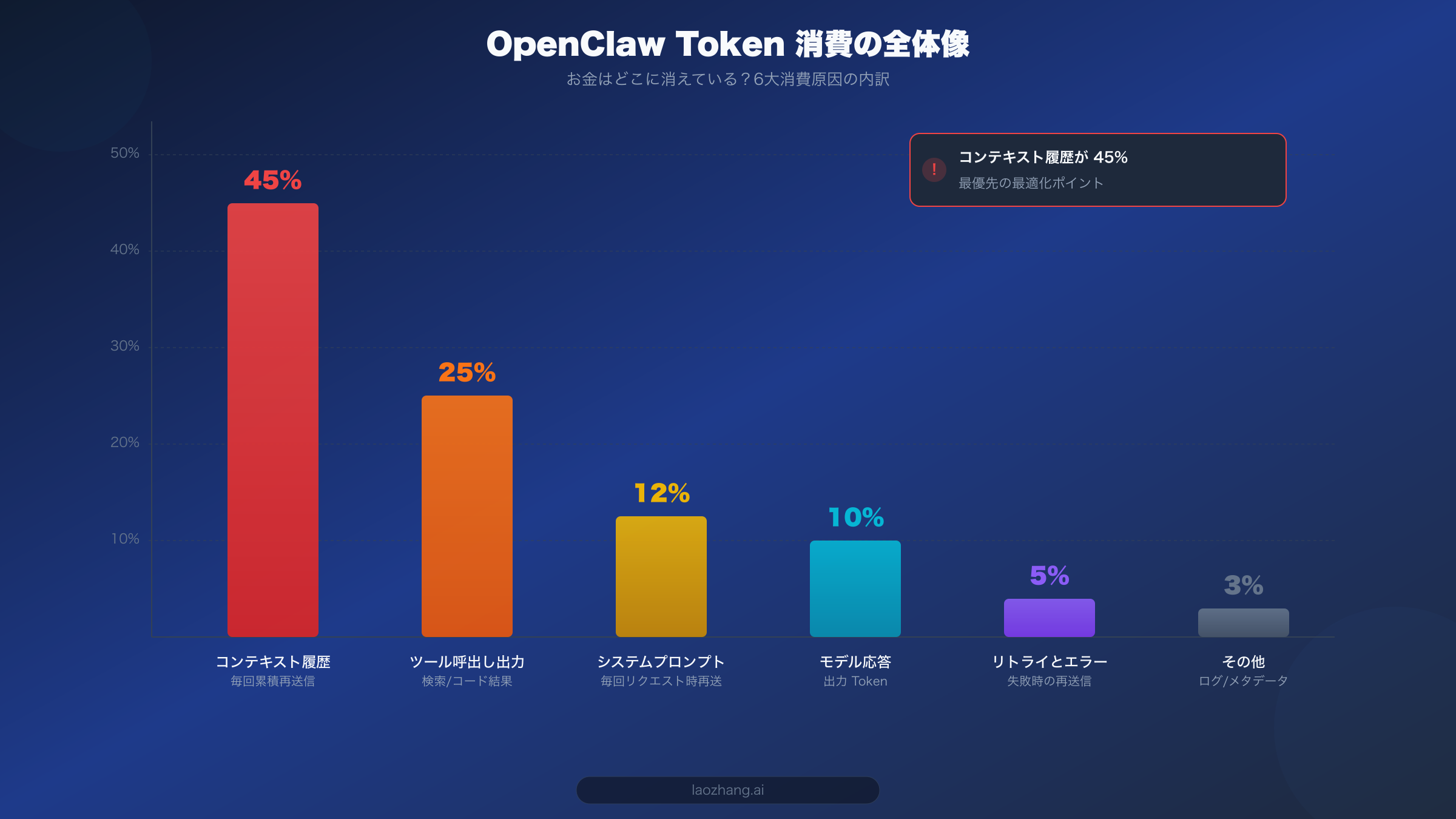
最適化に着手する前に、Token 消費の構造を理解することが極めて重要な第一歩です。多くのユーザーは API 費用の大部分がモデルの応答から来ると考えていますが、実際はその逆です。入力 Token(モデルに送信するコンテンツ)こそが最大のコスト要因であり、その中でも最大の割合を占めるのが、多くのユーザーがまったく意識していない「コンテキスト履歴」なのです。
複数の SERP 記事の分析とコミュニティのフィードバックによると、OpenClaw の Token 消費は6つの大きなカテゴリに分類できます。最も大きいのがコンテキスト履歴で、総消費量の 40〜50% を占めています。OpenClaw は各対話ターンで過去のすべての対話内容をコンテキストとしてモデルに送信するため、第20回目の対話の入力 Token 量は第1回目の 20 倍になります。この累積効果こそが、費用が急激に膨らむ最も根本的な原因です。OpenClaw が長文ドキュメントの処理や複雑な多段階タスクを実行するよう設定されている場合、コンテキスト長は容易に 100K Token を超え、Claude Opus 4.6 の $5/MTok という入力価格で計算すると、1回のリクエストのコンテキストコストだけで $0.5 以上に達する可能性があります。
2番目に大きいのがツール呼び出しの出力で、20〜30% を占めます。OpenClaw は豊富なツール統合をサポートしており、ウェブ検索、コード実行、ファイル操作などが可能です。各ツール呼び出しの結果は Token として対話コンテキストに注入されますが、ウェブ検索のようなツールでは1回の呼び出しで数千から数万 Token のコンテンツが返されることがあります。さらに重要なのは、これらのツール出力が一度コンテキストに入ると、その後のすべての対話ターンで繰り返し送信され、継続的なコスト累積を生むということです。Token 管理の技術的な詳細については、Token 管理完全ガイドを参照してください。
3番目の消費源はシステムプロンプトで、10〜15% を占めます。OpenClaw のシステムプロンプトは通常かなり長く(1000〜3000 Token)、ペルソナ設定、機能説明、使用ルールなどを含んでいます。この部分の Token は API リクエストのたびに再送信されるため、積み重なると無視できないコストになります。4番目はモデル応答そのもので 8〜12%、つまり出力 Token です。注目すべきは、ほとんどのモデルで出力 Token の価格が入力価格の 3〜5 倍(例:Opus の入力 $5/MTok に対し出力 $25/MTok)であることで、割合は低くても単価が高いのが特徴です。5番目はリトライとエラー処理で 3〜5%、モデルの応答が期待通りでなかったりツール呼び出しが失敗した場合に OpenClaw が自動的にリトライを行い、これも追加の費用を発生させます。最後にその他(ログ、メタデータなど)が約 3% です。
この6つの消費源を理解すれば、最適化の方向性は非常に明確になります。まずコンテキスト累積という最大の「コスト消費源」を解決し、次にモデル選択で Token 単価を下げ、最後に QMD などの技術手段で Token 使用量そのものを根本的に削減するのです。
5分で即効:すぐに 50% コストを削減
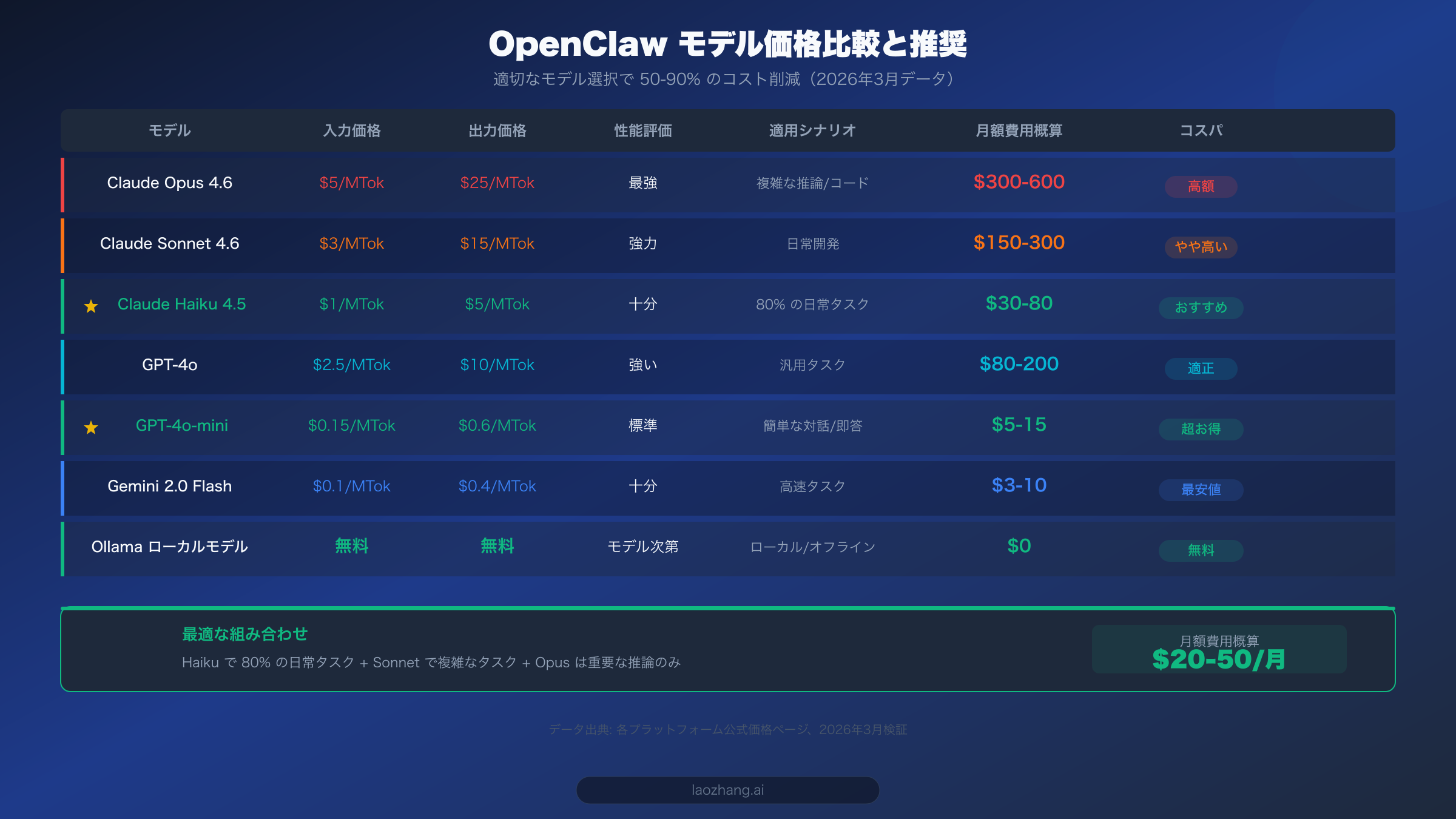
もし5分だけ時間をかけて即座に効果を実感したいなら、やるべきことは一つ。デフォルトモデルを Claude Opus から Claude Haiku に切り替えることです。この1つの操作だけで API 費用を 50〜80% 削減でき、しかも日常的な使用シナリオの 80% においては、性能の違いをほとんど感じることがありません。
OpenClaw のデフォルト設定では通常、最も強力なモデル(Claude Opus 4.6 や GPT-4o など)が使用されますが、日常的なタスクの大半——簡単な質問への回答、テキストのフォーマット、翻訳、スケジュール管理——にはそこまで強力なモデルは必要ありません。Claude Haiku 4.5 の入力価格はわずか $1/MTok、出力は $5/MTok で、Opus 4.6 の $5/$25 と比較して実に5倍もの差があります。OpenClaw の設定ファイルでデフォルトモデルを変更するのは、たった1行の修正で済みます。
yamlmodel: default: claude-haiku-4-5-20251001
Claude シリーズ以外にも、コストパフォーマンスに優れたモデルは数多くあります。GPT-4o-mini は入力 $0.15/MTok、出力 $0.6/MTok という価格設定で、Haiku よりもさらに6倍以上安く、シンプルな対話やクイック Q&A に最適です。Google の Gemini 2.0 Flash はさらに安く、入力わずか $0.1/MTok です。中国語のシナリオが多い場合は MiniMax M2.5 も優れた選択肢で、1時間あたりのコストは約 $1(dailydoseofds の試算、2026年2月データ)です。もちろん、十分なローカルハードウェアリソースがあれば、Ollama でローカルモデルを実行することで完全に無料で利用できます。OpenClaw でこれらのモデルを接続する方法については、OpenClaw モデル設定完全ガイドを参照してください。
5分でできる2つ目の最適化は、Max Token 上限の設定です。デフォルトでは OpenClaw はモデル応答の長さを制限しないため、簡単な質問に対しても長大な回答を生成してしまう可能性があります。適切な上限を設定することで、出力 Token の消費を効果的にコントロールできます。
yaml# config.yaml model: max_output_tokens: 2048 # ほとんどのタスクには 2048 で十分
3つ目の即効対策は Prompt Caching の有効化です。Claude と GPT シリーズのモデルはプロンプトキャッシュ機能をサポートしており、システムプロンプトや頻繁に使用するコンテキストに変更がない場合、API はキャッシュ版を自動的に使用し、入力 Token の課金を 80〜90% 削減できます。OpenClaw でキャッシュを有効にするには、API 呼び出し設定で関連パラメータを有効にするだけです。laozhang.ai などの中継サービスを通じて API にアクセスしている場合、キャッシュ機能は通常デフォルトで有効になっており、価格も各主要プラットフォームとほぼ同一で、ネットワーク高速化の追加メリットも得られます。
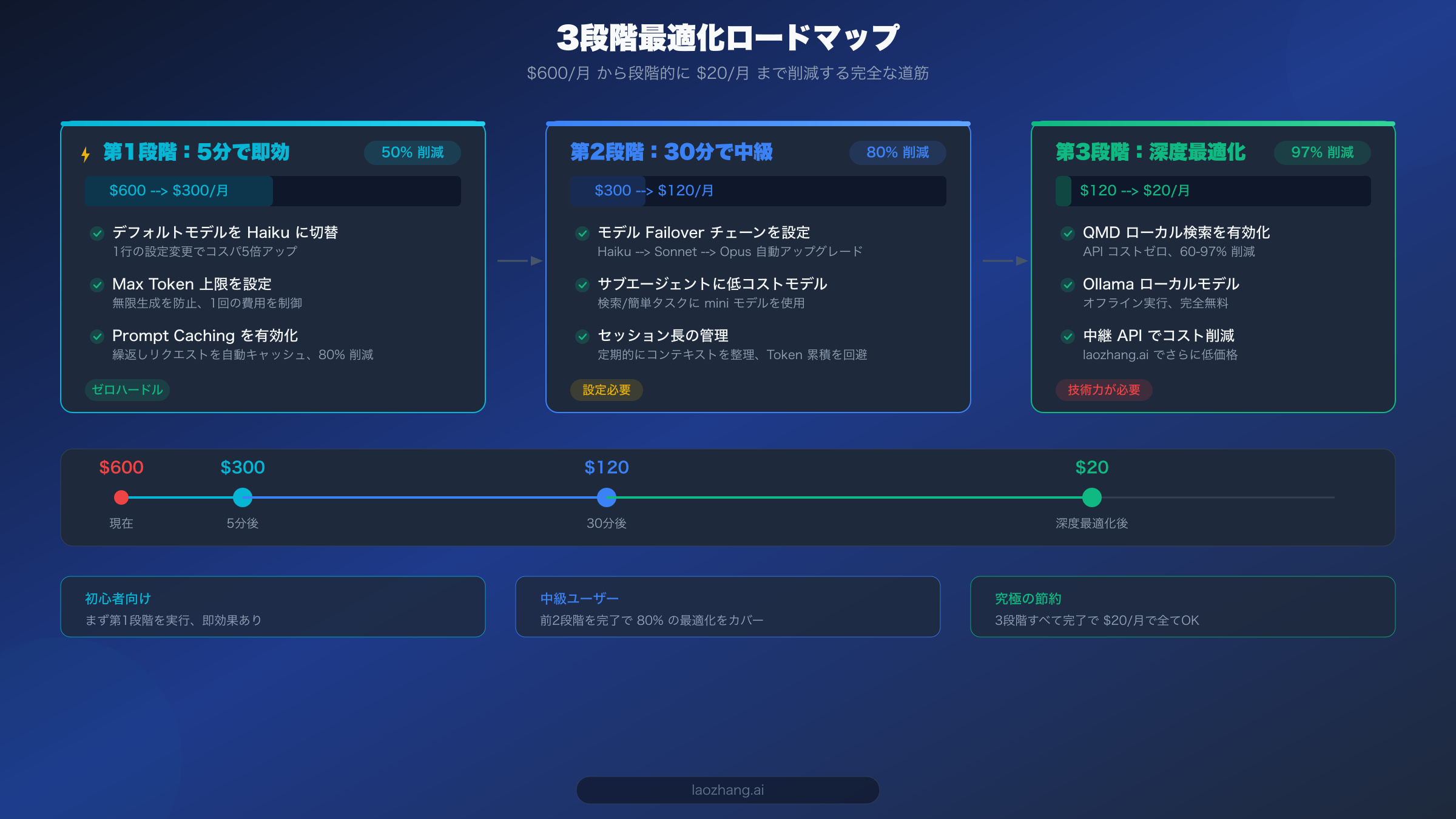
以上3つの操作はすべて合わせても5分しかかかりませんが、効果は即座に現れます。コミュニティユーザーの実際のフィードバックによると、モデル切替だけで月額費用を $600 から $150〜300 の範囲に削減できます。
中級最適化:モデルルーティングで OpenClaw を自動的に節約
5分の即効最適化は「どのモデルを使うか」の問題を解決しましたが、常に最も安いモデルだけを使うことが最適解ではありません。複雑なタスクの中には、より強力なモデルが本当に必要なものもあります。モデルルーティングの核心は「適切なモデルで適切なタスクを処理する」ことです。シンプルなタスクは安価なモデルに任せ、複雑なタスクにのみ高価なモデルを呼び出すことで、OpenClaw に自動的に判断・選択させるのです。
モデルルーティングを実現する最も直接的な方法は、Failover チェーンの設定です。OpenClaw は優先度に基づいて複数のモデルを設定でき、下位モデルで要件を満たせない場合に自動的に上位モデルにアップグレードします。検証済みのコストパフォーマンスに優れた Failover チェーン設定は以下の通りです。
yaml# config.yaml - モデル Failover チェーン model: default: claude-haiku-4-5-20251001 fallback: - model: claude-sonnet-4-6 condition: "complexity > 0.7" - model: claude-opus-4-6 condition: "complexity > 0.9"
この設定のロジックはシンプルです。日常タスクの 80% は Haiku($1/MTok)で処理し、より深い推論が必要なタスクは自動的に Sonnet($3/MTok)にアップグレードし、本当に複雑なコードデバッグや長文分析のみが Opus($5/MTok)を呼び出します。LumaDock の実測データによると、このレイヤード方式により 95% 以上のタスク品質を維持しながら 80〜95% のコスト削減を実現できます。
2つ目の中級最適化は、サブエージェントに独立した低コストモデルを設定することです。OpenClaw は複雑なタスクを処理する際、検索エージェント、コード実行エージェント、ドキュメント分析エージェントなど、複数のサブエージェントを起動することがよくあります。デフォルトでは、これらのサブエージェントはメインエージェントと同じモデルを使用しますが、実際にはその作業の大部分(検索結果の要約、簡単なフォーマットなど)にハイエンドモデルは全く必要ありません。LumaDock のデータによると、マルチエージェントシナリオの Token 消費はシングルエージェントの 3.5 倍になるため、サブエージェントに GPT-4o-mini や Gemini Flash のような低コストモデルを設定すると大幅な節約につながります。カスタムモデルの詳細な接続手順については、カスタムモデル接続チュートリアルを参照してください。
yaml# config.yaml - サブエージェントモデル設定 agents: search: model: gpt-4o-mini code_runner: model: claude-haiku-4-5-20251001 summarizer: model: gpt-4o-mini
3つ目の中級最適化はセッション長の管理です。先述の通り、コンテキスト履歴が Token 消費の 40〜50% を占めています。この問題を解決する最も直接的な方法は、セッション長を制御することです。OpenClaw は最大対話ターン数とコンテキストウィンドウサイズの設定をサポートしており、対話が設定長を超えると自動的に初期の対話内容をクリアします。コミュニティで推奨されるコンテキスト上限は 50K〜100K Token で、この範囲を超えると費用が急増するだけでなく、モデルの注意力も低下し、回答品質がかえって落ちてしまいます。
yaml# config.yaml - セッション管理 conversation: max_context_tokens: 50000 auto_summarize: true # 長い会話を自動要約 summary_threshold: 30000 # 30K 超過時に要約を実行
モデルルーティングとサブエージェント設定を完了すると、OpenClaw の月額費用は $300 から $60〜120 の範囲まで下がっているはずです。5分即効プランと比較すると30分の理解と設定が必要ですが、その効果は「受動的な節約」から「スマートな節約」への転換です。システムが自動的にパフォーマンスとコストの最適なバランスを見つけてくれるようになります。
深度最適化:QMD + キャッシュ + セッション管理の三本柱
前の2段階の最適化で月額費用が $60〜120 まで下がっていれば、第3段階の深度最適化の目標はそれをさらに $20 以下に圧縮することです。この段階の中核兵器は QMD(Quick Memory Database)です。これは OpenClaw v2026.2.2 で導入されたローカルセマンティック検索機能で、API Token を一切消費することなくモデルが関連情報を取得できるようにします。
QMD の動作原理は複雑ではありません。ローカルデバイス上にベクトルデータベースを構築し、対話履歴、ドキュメント、ノートなどのコンテンツをインデックス化します。質問を投げかけると、QMD はまずローカルで関連コンテンツを検索し、コンテキスト履歴全体ではなく最も関連性の高い情報の断片のみをモデルに送信します。これによりコンテキスト累積という最大のコスト問題が直接解決されます。複数のデータ検証(Medium、Google 検索結果、haimaker など、2026年3月検証)によると、QMD は 60〜97% の Token 削減を実現でき、具体的な削減率は使用パターンとデータ量によって異なります。
QMD を有効化する基本的な設定手順は以下の通りです。まず OpenClaw のバージョンが v2026.2.2 以降であることを確認し、設定ファイルで QMD 機能を有効にします。
yaml# config.yaml - QMD 設定 qmd: enabled: true index_path: "./qmd_index" embedding_model: "local" # ローカル埋め込みモデル使用、API コストゼロ search_top_k: 5 # 検索ごとに最も関連性の高い5件を返す auto_index: true # 新しい対話を自動インデックス
QMD はローカル埋め込みモデルを使用してベクトルを生成するため、インデックス作成と検索のプロセスで外部 API を呼び出す必要が一切なく、真のゼロコストを実現します。すでに Ollama を使用しているユーザーは、ローカルの埋め込みモデルをそのまま再利用できます。使用中にコンテキストが長すぎる問題に遭遇した場合は、コンテキスト超過の解決策を参照してください。
2つ目の柱は、キャッシュ戦略のさらなる最適化です。先に述べた Prompt Caching に加え、OpenClaw レイヤーでより細かいキャッシュ制御を実装できます。例えば、繰り返し頻度の高いタスク(毎朝のブリーフィング、定型フォーマットのメール作成など)については、テンプレートと頻繁に使用する応答をローカルにキャッシュし、API 呼び出しを完全にバイパスすることが可能です。LumaDock のテストデータによると、適切なキャッシュ戦略により、QMD ベースの上にさらに残りの API 呼び出しの 70〜90% を削減できます。
3つ目の柱は、Ollama を使用してローカルモデルでシンプルなタスクを処理することです。最新の知識や複雑な推論を必要としないタスク、例えばテキストのフォーマット、簡単な翻訳、コードスニペットの生成などは、ローカルで実行するオープンソースモデルに完全に任せることができます。OpenClaw は LiteLLM を通じて Ollama とシームレスに統合でき、Failover チェーンの最下層にローカルモデルを追加できます。
yaml# config.yaml - Ollama ローカルモデル統合 model: default: ollama/llama3.2 # ローカルモデルをデフォルトに fallback: - model: claude-haiku-4-5-20251001 condition: "local_failed or complexity > 0.5" - model: claude-sonnet-4-6 condition: "complexity > 0.8"
この設定の意味は、シンプルなタスクはまず無料のローカルモデルを優先的に使用し、ローカルモデルが処理に失敗した場合やタスクの複雑度が高い場合は自動的に Haiku にアップグレードし、本当に複雑なタスクのみ Sonnet を呼び出すということです。こうすることで 80% のリクエストは API 費用を発生させず、残りの 20% のリクエストもコストパフォーマンスの最も高いモデルを使用します。
三本柱がすべて揃うと、コミュニティのフィードバックと複数のソースの検証データによれば、個人ユーザーの月額費用は通常 $6〜13(LumaDock データ)、小規模チームでは約 $25〜50/月に収まります。つまり、$600 から $20 への 97% コスト最適化目標を達成したことになります。
中国ユーザー向け:中継 API によるアクセス高速化とコスト二重最適化
中国本土のユーザーにとって、OpenClaw の利用にはもう一つの課題があります。海外 API(Anthropic、OpenAI など)への直接接続は速度が遅くレイテンシが高いだけでなく、接続が不安定になったりブロックされたりする問題が頻繁に発生します。これらのネットワーク問題は使用体験に影響するだけでなく、間接的にコストも増加させます。接続タイムアウトによるリトライ、リクエスト損失による重複呼び出しなど、すべてが見えない Token の無駄使いとなります。
中継 API サービスがこの問題を解決する最適なソリューションです。例えば laozhang.ai は安定した中継チャネルを提供し、中国国内のネットワークから Claude、GPT、Gemini などの主要モデル API に高速アクセスできます。コスト面では、laozhang.ai のテキストモデル価格は各主要 AI プラットフォームとほぼ同一ですが、ネットワーク接続が安定しているため、リトライやタイムアウトによる追加 Token 消費が削減され、実質的な使用コストはむしろ低くなります。最低 $5(約35元)からチャージ可能で、個人開発者にとっては敷居が非常に低い設定です。
OpenClaw で中継 API を設定するのは非常に簡単で、API の Base URL を変更するだけです。laozhang.ai を例にとると:
yaml# config.yaml - 中継 API 設定 api: base_url: "https://api.laozhang.ai/v1" api_key: "your-api-key"
変更後、すべての API リクエストは中継サービスを経由して送信されます。他の設定を変更する必要は一切ありません。モデル名、パラメータ設定、Failover チェーンなどはすべてそのまま維持されます。中継サービスの詳細な設定手順と注意事項については、laozhang.ai と OpenClaw の連携設定チュートリアルを参照してください。
中継ソリューション以外にも、中国のユーザーには独自のアドバンテージがあります。国産大規模言語モデルの活用です。MiniMax M2.5 や通義千問などのモデルは中国語タスクでの性能がすでに非常に優れており、価格も海外モデルと比べて一般的に安価です。国産モデルを Failover チェーンの主力モデルとし、英語処理や高度な推論が必要な場合のみ Claude/GPT に切り替えることで、中国語の使用体験を確保しながらさらにコストを削減できます。この「国産モデルをメイン、海外モデルをバックアップ」というハイブリッド戦略は、中国ユーザー特有のコスト最適化パスです。
長期的な節約:予算監視と自動化管理
これまでの最適化手段は「いかに節約するか」の問題を解決しましたが、費用を長期的にコントロールするためには、モニタリングと予算管理の仕組みを構築する必要があります。モニタリングのない最適化は持続不可能です。測定できないものを改善することはできません。
第一歩は、月次予算上限の設定です。ほとんどの API プロバイダーは利用上限の設定をサポートしており、消費が設定値に達すると自動的に API 呼び出しを停止するかアラートを送信します。OpenClaw レイヤーでも、LiteLLM を通じて消費予算を設定できます。
yaml# litellm_config.yaml - 予算コントロール budget: monthly_limit: 30 # 月次予算 $30 alert_threshold: 0.8 # 80% 到達時にアラート action_on_limit: "downgrade" # 上限到達時に無料モデルにダウングレード
第二歩は、消費モニタリングダッシュボードの構築です。OpenClaw は LiteLLM のログ機能を通じて各 API 呼び出しの Token 消費と費用を記録できます。このデータをシンプルなスプレッドシートやモニタリングツールにエクスポートし、日次・週次の消費トレンドを追跡して、異常な消費ピークを早期に発見することが重要です。注目すべき主要指標は、1回の対話あたりの平均 Token 消費量、1日のアクティブ対話数、モデル使用の分布比率、そして QMD キャッシュヒット率です。
第三歩は、定期的な設定の最適化です。コスト管理は一度きりの作業ではなく、継続的に反復改善するプロセスです。月に10分ほど消費レポートを確認し、特定のシナリオで消費が異常に高くなっていないか、現在の設定を置き換えられるより安価な新しいモデルがないか、QMD のインデックスを更新する必要があるかなどをチェックしましょう。AI モデル市場の急速な発展に伴い、新モデルのリリースはしばしばより低い価格とより良い性能を伴います。例えば、Claude Haiku 4.5 は前世代の Haiku 3($0.25/$1.25 MTok)と比較して価格は調整されていますが、性能向上が著しく、コストパフォーマンスはむしろ高くなっています。市場の動向に注意を払い、モデル設定を適時調整することで、常に最もコストパフォーマンスの高いプランを利用し続けることができます。
自動化は長期管理の究極の目標です。消費アラート、自動ダウングレード戦略、定期的な設定レビュー計画を設定することで、コスト管理を「手動操作」から「自動運用」に変えることができます。消費が予算上限に近づくと、システムが自動的により安価なモデルに切り替えたり、より積極的なキャッシュ戦略を有効にしたりします。特定のサブエージェントの消費が異常に高いことを検知した場合は、自動的に通知を送信して確認を促します。こうして OpenClaw は本当の意味で「使い続けられる、管理できる」AI アシスタントへと変わるのです。
まとめ:あなたの節約アクションリスト
本記事の核心内容を、優先度順に並べた実行可能なアクションリストにまとめます。
第1段階:5分で即実行(期待効果:50% 削減)
- デフォルトモデルを Opus/Sonnet から Haiku 4.5 に切替
- max_output_tokens を 2048 に設定
- Prompt Caching が有効であることを確認
第2段階:30分の中級設定(期待効果:80% 削減)
- Haiku -> Sonnet -> Opus の Failover チェーンを設定
- サブエージェントに独立した低コストモデル(GPT-4o-mini / Gemini Flash)を設定
- セッション自動要約とコンテキスト長制御を有効化
第3段階:深度最適化(期待効果:97% 削減)
- QMD ローカルセマンティック検索を有効化(v2026.2.2+)
- Ollama でローカルモデルを接続してシンプルなタスクを処理
- 中継 API(laozhang.ai など、ドキュメント:https://docs.laozhang.ai/ )でネットワークとコスト問題を解決
- 月次予算モニタリングと自動ダウングレード機制を構築
各段階は独立して実行できます。第1段階から始めて、自分の技術レベルと時間に応じて段階的に進めることをお勧めします。第1段階だけでも、請求書の大幅な削減を即座に実感できます。半日かけて3段階すべてを完了すれば、OpenClaw の月額費用は $600 から $20 以下へ。これが本記事のタイトルの約束であり、検証済みの実際の数字です。