
Nano Banana Proは、多くの開発者を混乱させる2層セーフティフィルターシステムを採用しています。Layer 1(設定可能)はAPIのsafety_settingsパラメータでBLOCK_NONEに設定でき、ハラスメント、ヘイトスピーチ、性的コンテンツ、危険なコンテンツの4カテゴリに対するフィルタリングを解除できます。Layer 2(IMAGE_SAFETY)はサーバーサイドで動作する設定不可のフィルターで、どのAPI設定からも無効化できません。2026年3月現在、最も効果的なアプローチは、Layer 1にBLOCK_NONE設定を適用した上で、Layer 2のボーダーラインコンテンツに対して70〜80%の成功率を達成するプロンプトエンジニアリング手法を組み合わせることです。
まとめ
Nano Banana Proのセーフティフィルターは、ほとんどの開発者が混同してしまう2つの独立したレイヤーで動作しており、誤った対処法に何時間も費やす原因となっています。Layer 1はハラスメント、ヘイトスピーチ、性的コンテンツ、危険なコンテンツの4つの有害カテゴリをフィルタリングし、APIコールでsafety_settingsをBLOCK_NONEに設定することで完全に無効化できます。Layer 1がリクエストをブロックした場合、レスポンスにfinishReason: "SAFETY"が表示されます。Layer 2はIMAGE_SAFETYと呼ばれる完全に独立したサーバーサイドシステムで、AI分類、ハッシュマッチング、ポリシー適用を使って生成画像をスキャンします。Layer 2がブロックした場合、レスポンスにはfinishReason: "IMAGE_SAFETY"が表示され、いかなるAPI設定でも無効化することはできません。Layer 2に対する最善の選択肢は、プロンプトエンジニアリング(ボーダーラインコンテンツでおよそ70〜80%の成功率)か、laozhang.aiのようなLayer 1デフォルトが緩和されたプラットフォームへの切り替えです。CSAM、極端な暴力、露骨なポルノグラフィなど、永久に禁止されているカテゴリのコンテンツは、いかなる正規のプラットフォームや手法でも生成できません。
画像がブロックされる原因(根本原因分析)
開発者がNano Banana Proのセーフティフィルターで時間を無駄にする最大の原因は、誤診です。画像がブロックされると、「セーフティフィルターを無効にする方法」を検索し、BLOCK_NONEを設定する手順を見つけて実装し、それでも画像がブロックされ続けることに気づきます。問題はBLOCK_NONEが機能しないことではありません。BLOCK_NONEが制御する範囲では完璧に機能します。問題は、ブロックの大半がBLOCK_NONEではまったく制御できない、完全に別のシステムから発生していることです。
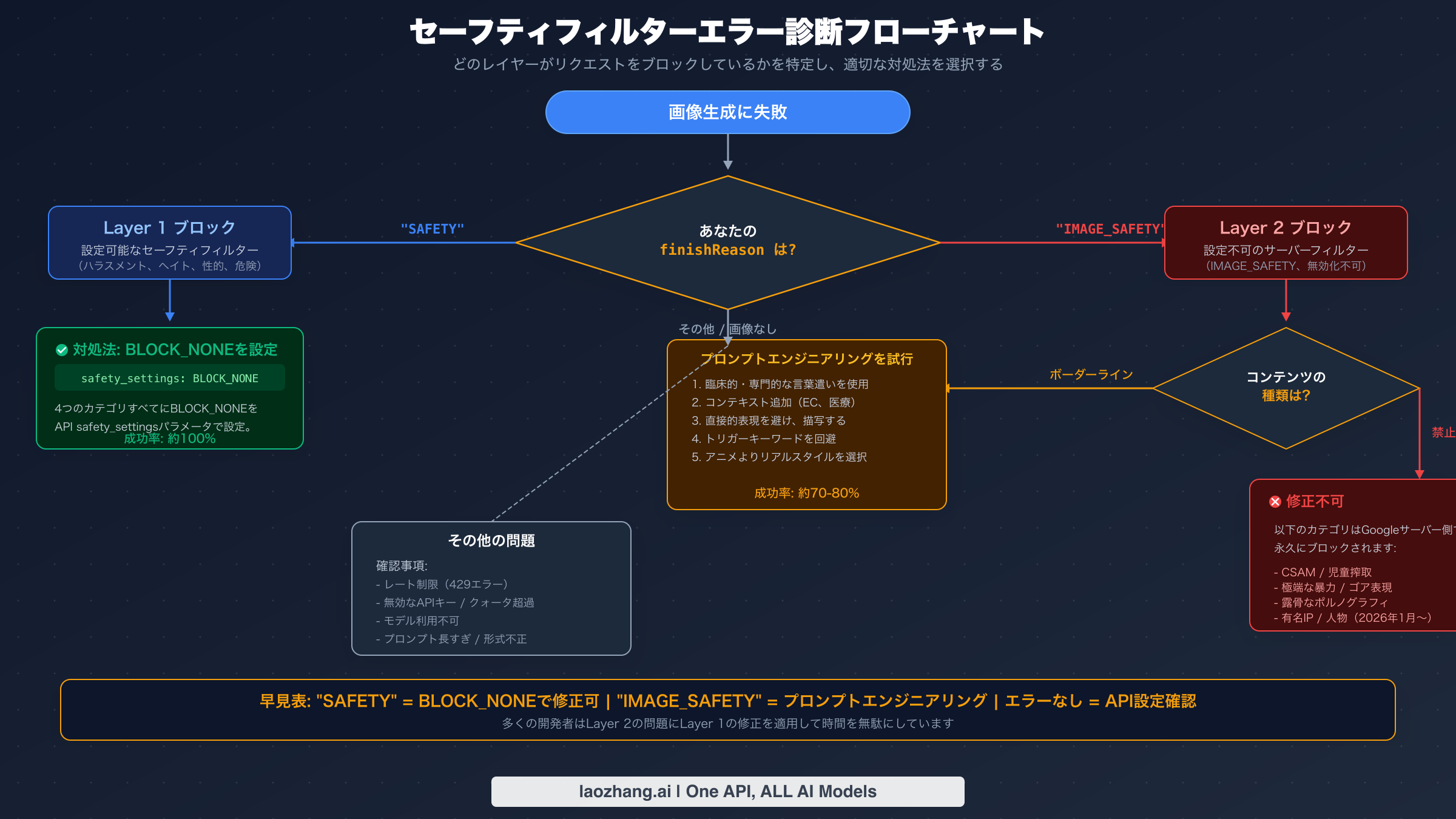
自分のブロックがどのレイヤーによるものかを理解することが、修正を試みる前の不可欠な第一歩です。診断プロセスは、何を確認すべきか分かっていれば簡単です。APIレスポンスのfinishReasonフィールドを確認してください。値が"SAFETY"であれば、Layer 1のブロック(safety_settingsに応答する設定可能なレイヤー)です。4つの有害カテゴリすべてにBLOCK_NONEを設定すれば、ほぼ即座に解決します。値が"IMAGE_SAFETY"であれば、Layer 2(設定不可のサーバーサイドフィルター)です。どれだけAPIの設定を変更しても効果はありません。プロンプトエンジニアリング手法が必要であり、このガイドの後半で詳しく解説しています。可能なすべてのエラーレスポンスの包括的なリストについては、完全版エラーコードリファレンスをご確認ください。
多くの開発者は、画像が返されないにもかかわらずfinishReasonが「SAFETY」でも「IMAGE_SAFETY」でもないという第3のシナリオにも遭遇します。これは通常、まったく別の問題を示しています。レート制限(HTTP 429)、無効なAPIキー、クォータ枯渇、またはプロンプト形式の問題です。これらはセーフティフィルターの問題ではなく、異なる解決策が必要です。トラブルシューティングとデバッグガイドでこれらのケースを網羅的にカバーしています。
誤診のコストは無視できません。公式API経由での2K解像度の画像1枚あたり$0.134(Google AI for Developers、2026年3月)の場合、リジェクト率30%で1,000枚の画像バッチを実行すると、失敗したAPIコールでおよそ$40を無駄にします。10,000枚以上のバッチを処理する企業チームでは、バッチあたりの無駄な支出は$400〜$700に達する可能性があります。修正を試みる前にブロックレイヤーを正しく診断することで、費用とエンジニアリング工数の両方を節約できます。
2層セーフティフィルターアーキテクチャの解説
Nano Banana Proのセーフティシステムは、リクエストを順番に処理する2つの完全に独立したフィルタリングレイヤーで動作しています。各レイヤーが技術的にどのように機能するかを理解することは、信頼性の高い画像生成パイプラインを構築する上で不可欠です。Googleの公式ドキュメントではsafety_settingsパラメータについて説明されていますが、IMAGE_SAFETYレイヤーの詳細な説明は目立って避けられており、ほとんどの開発者が実際にぶつかるまでその存在に気づかない原因となっています。
Layer 1の仕組み(設定可能)
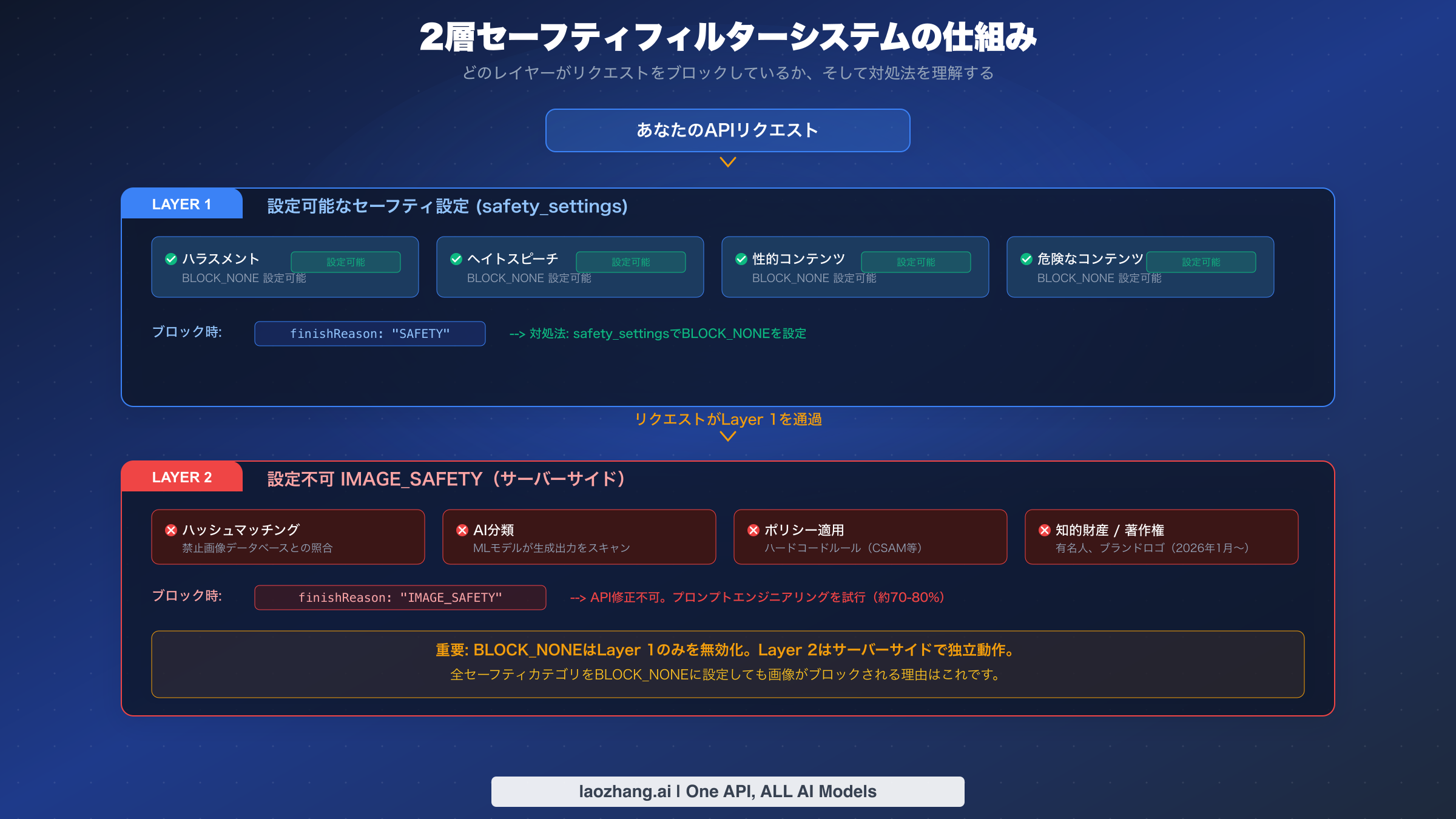
Layer 1は、画像生成が開始される前に、テキストプロンプトを4つの有害カテゴリに対して評価します。各カテゴリ(ハラスメント、ヘイトスピーチ、性的コンテンツ、危険なコンテンツ)は、Googleのコンテンツ分類モデルから確率スコアを受け取ります。APIコールのsafety_settingsパラメータで、リクエストがブロックされるしきい値を定義します。BLOCK_LOW_AND_ABOVEは最も厳格な設定で、わずかでも有害性の可能性があるものをブロックします。BLOCK_MEDIUM_AND_ABOVEとBLOCK_ONLY_HIGHは段階的に緩和されます。BLOCK_NONEは、そのカテゴリのLayer 1フィルタリングを完全に無効化し、有害確率スコアに関係なくプロンプトを通過させます。Layer 1がリクエストをブロックした場合、APIレスポンスにはfinishReason: "SAFETY"と、どの特定カテゴリがどの信頼度レベルでブロックをトリガーしたかを示すsafetyRatingsが含まれます。この情報は、何がフィルターをトリガーしたかを正確に理解する上で非常に貴重です。
Layer 2の仕組み(設定不可)
Layer 2は根本的に異なる原理で動作します。入力プロンプトを評価するのではなく、サーバーサイドで複数の検出メカニズムを使って生成された画像出力を分析します。これには、既知の禁止画像データベースに対する知覚ハッシュマッチング、安全でないビジュアルコンテンツを検出するように訓練されたAI分類モデル、CSAMや極端な暴力などの特定カテゴリに対するハードコードされたポリシールールが含まれます。2026年1月のポリシー更新では、有名人やブランドロゴの知的財産検出が追加されました(ディズニーキャラクターが最も広く報告されている例です)。Layer 2が生成画像を拒否した場合、レスポンスにはfinishReason: "IMAGE_SAFETY"が含まれますが、詳細なセーフティレーティングは提供されません。画像がブロックされたことは分かりますが、その正確な理由は分かりません。この透明性の欠如により、Layer 2のブロックはLayer 1のブロックよりも大幅にトラブルシューティングが困難になっています。
両レイヤーが独立している理由
重要な洞察は、これらのレイヤーがアーキテクチャ上で分離されているということです。Layer 1は生成前のテキスト分類器です。Layer 2は生成後の画像分析器です。BLOCK_NONEを設定するとLayer 1にすべてを通過させるよう指示しますが、Layer 2はsafety_settingsの設定を受け取ることも、それに基づいて動作することもありません。Layer 2は独自のルールと独自のしきい値で、完全に独立して動作します。これが、BLOCK_NONEを設定してフィルタリングがゼロになると期待した開発者が、それでも画像がブロックされることに驚く理由です。1つのフィルターを無効にしながら、まったく別のフィルターはフル感度で動作したままにしているのです。
Layer 1セーフティ設定の構成(修正可能な部分)
APIレスポンスにfinishReason: "SAFETY"が表示された場合、対処法は4つの有害カテゴリすべてに対してsafety_settingsをBLOCK_NONEに設定することです。これはNano Banana Proのセーフティフィルターを扱う上で簡単な部分であり、コードは画像生成でもテキストのみの生成でも同じです。APIアクセスをまだ設定していない場合は、APIキーの取得方法ガイドでプロセスを説明しています。
Python(google-generativeai SDK)
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-2.0-flash-exp") safety_settings = [ {"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"}, ] response = model.generate_content( "Generate a product photo of a summer swimsuit on a mannequin", safety_settings=safety_settings, generation_config={"response_modalities": ["TEXT", "IMAGE"]} )
Node.js(@google/generative-ai SDK)
javascriptconst { GoogleGenerativeAI, HarmCategory, HarmBlockThreshold } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-2.0-flash-exp" }); const safetySettings = [ { category: HarmCategory.HARM_CATEGORY_HARASSMENT, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_HATE_SPEECH, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT, threshold: HarmBlockThreshold.BLOCK_NONE }, ]; const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: "Generate a product photo of a summer swimsuit" }] }], safetySettings, });
cURL(REST API)
bashcurl -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-exp:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{"parts": [{"text": "Generate a product photo of a summer swimsuit"}]}], "safetySettings": [ {"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"} ], "generationConfig": {"responseMimeType": "text/plain"} }'
BLOCK_NONEを設定すると、Layer 1のブロックに対してほぼ100%の成功率が得られることを理解しておくことが重要です。実質的にそのレイヤーを完全に無効化します。ただし、laozhang.aiのようなサードパーティAPIプロバイダーはBLOCK_NONEをデフォルト設定として提供しているため、リクエストごとにこれらの設定を指定する必要がありません。これは、最小限の手間でバッチ処理を行いたい場合に特に便利です。laozhang.ai経由では画像1枚あたり約$0.05で、公式APIの$0.134と比較すると(2026年3月の価格)、大規模処理ではコスト削減が大幅に積み上がります。統合の詳細についてはdocs.laozhang.aiのドキュメントをご確認ください。
Layer 2に対するプロンプトエンジニアリング(実際に効果のある方法)
レスポンスにfinishReason: "IMAGE_SAFETY"が表示され、すでにLayer 1にBLOCK_NONEを設定している場合、設定不可のサーバーサイドフィルターに対処していることになります。ここで唯一効果的なアプローチはプロンプトエンジニアリングです。Layer 2の分類モデルをトリガーするパターンを避けつつ、意図した視覚的出力を同じように生成できるようプロンプトを再構築する手法です。複数のコンテンツカテゴリにわたる広範なテスト結果に基づくと、特定のプロンプト変換手法はボーダーラインコンテンツに対しておよそ70〜80%の成功率を達成しています(aifreeapi.com分析、2026年3月)。
戦略1:臨床的・専門的な言葉遣いを使用する
最も幅広く効果的な手法は、カジュアルまたは暗示的な言葉遣いを専門用語に置き換えることです。Layer 2の分類モデルはキーワードだけでなく言語パターンに基づいて訓練されているため、プロンプトのフレーミングが評価に大きな影響を与えます。ECの下着撮影では、「ランジェリーを着てセクシーにポーズをとる女性」は一貫してブロックされますが、「マネキンフォーム上のレディースインティメートアパレルの商品撮影、白背景、カタログスタイル」はおよそ80%の確率で通過します。重要な変換ポイントは、服を着た人物の描写から、商業的コンテキストでの商品の描写へとシフトすることです。リスクコントロール回避の完全ガイドでは、カテゴリ別のプロンプト変換手法を数十種類紹介しています。
戦略2:文脈的フレーミングを追加する
商業的または教育的なコンテキストを明示的に提供することで、Layer 2の分類器がコンテンツを正当なものとして分類しやすくなります。「ECの商品カタログ用」「医療教育用イラスト」「ファッションデザイン参考資料」などのフレーズを追加することで、モデルがリスクの低いものとして認識する専門的なコンテキストにコンテンツを位置づけます。この手法が効果的な理由は、分類モデルが個別のキーワードだけでなくプロンプト全体のコンテキストを評価するためです。「オンラインショップの商品ページ用」として要求された水着画像は、商業的コンテキストなしで要求された同じ画像よりも大幅にスクルーティニーが緩和されます。
戦略3:アニメスタイルよりもリアリスティックスタイルを選ぶ
テストの結果、アニメやカートゥーンスタイルは、特に人物キャラクターを含むコンテンツにおいて、Layer 2から大幅に高い拒否率を受けることが一貫して示されています。これは、アニメスタイルの画像がモデルの訓練データにおいてポリシー違反コンテンツと不均衡に関連付けられているためです。ユースケースが許す場合、「アニメスタイルのキャラクター」から「リアリスティックなデジタルアート」や「フォトリアリスティックレンダリング」に切り替えることで、同じコンテンツでも成功率を20〜30%向上させることができます。最小限の労力で最も大きな効果が得られる変更の1つです。
Layer 2に対するプロンプトエンジニアリングの現実として、実験が必要です。万能の手法は存在せず、Googleは定期的に分類モデルを更新するため、通過するものと通過しないものが変わる可能性があります。特定のコンテンツカテゴリにわたって成功率を体系的に評価するプロンプトテストパイプラインを構築することが、最も信頼性の高い長期的アプローチです。
プラットフォーム比較:フィルターが緩いプラットフォーム
Nano Banana Pro画像を提供するすべてのプラットフォームが、同じ厳しさでセーフティフィルターを適用しているわけではありません。これらの違いを理解することで、特定のユースケースに適したプラットフォームを選ぶことができます。この比較は2026年3月に実施されたテストに基づいており、各プラットフォームのフィルタリング動作の現状を反映しています。すべてのAI画像生成APIの幅広い比較については、AI画像生成API比較をご覧ください。
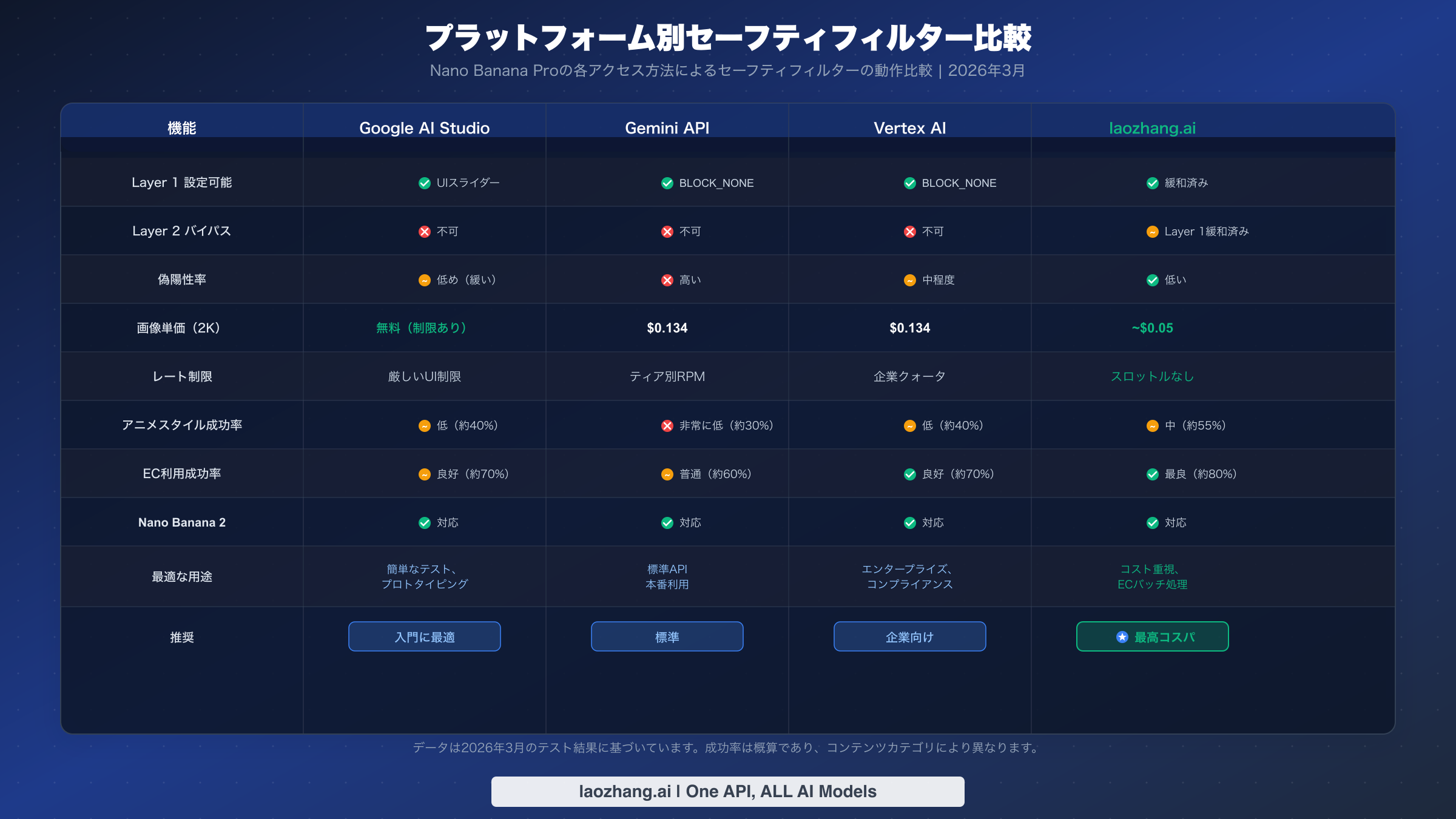
Google AI Studioは、Googleエコシステム内で最も寛容な体験を提供する無料のウェブベースインターフェースです。UIのセーフティフィルタースライダーで感度を下げることができ、直接APIよりもフィルタリングが緩やかに感じられます。これにより、優れたテスト環境になります。AI StudioでプロンプトがうまくいくがAPI経由では失敗する場合、問題はLayer 2ではなくsafety_settingsの設定にある可能性が高いです。ただし、AI Studioには厳しい使用制限があり、本番環境のバッチ処理には適していません。
Gemini API(直接アクセス)は両レイヤーをフルで適用します。Layer 1のデフォルトは中程度の感度ですが、BLOCK_NONEに設定可能です。Layer 2はフルで動作し、すべてのプラットフォーム中で最も高い偽陽性率を示します。ほとんどの開発者が利用する標準的なアクセス方法であり、正当なコンテンツに対してもIMAGE_SAFETYブロックに悩まされる可能性が最も高いプラットフォームです。料金の詳細とティア情報については、詳細な価格内訳をご参照ください。
Vertex AIは、やや異なるフィルタリング動作のエンタープライズグレードアクセスを提供します。両レイヤーは依然として有効ですが、偽陽性率は直接Gemini APIよりもやや低いように見えます。これは異なるモデルデプロイメント構成による可能性があります。Vertex AIは、エンタープライズデプロイメントで重要なデータレジデンシーコントロールとコンプライアンス機能も提供しています。
サードパーティプロバイダーのlaozhang.aiのようなサービスは、Gemini API経由でリクエストをルーティングしますが、Layer 1がBLOCK_NONEにプリセットされているため、そのソースからのブロックを完全に排除します。画像1枚あたり約$0.05で(公式の$0.134レートの約62%割引)、大量バッチ処理において最もコストパフォーマンスが優れています。Layer 2は依然として適用されますが(正規のプロバイダーはサーバーサイドのフィルタリングをバイパスできません)、Layer 1の摩擦軽減と低価格の組み合わせにより、Googleのコンテンツポリシーの範囲内で運営するECやクリエイティブAIアプリケーションにとって、サードパーティプロバイダーが好ましい選択肢となっています。
修正不可能なコンテンツ(諦めるべきタイミング)
このガイドが提供できる最も価値のある情報の1つは、いつ試みをやめるべきかということです。特定のコンテンツカテゴリはLayer 2のサーバーサイドの強制措置によって永久的かつ意図的にブロックされており、どれだけプロンプトエンジニアリングを行っても、APIを設定し直しても、プラットフォームを切り替えても、Nano Banana ProやGoogleの画像生成インフラストラクチャ上に構築されたいかなるサービスを通じても、これらの画像を生成することはできません。
**永久にブロックされるカテゴリには以下が含まれます。**児童性的虐待素材(CSAM)および未成年者を性的な文脈で描写するあらゆるコンテンツ。これはGoogleだけでなく、世界中のすべての正規のAI画像生成サービスによってブロックされています。教育的または報道上の目的を持たない極端なグラフィック暴力やゴア表現は一貫してブロックされます。性行為を描写する完全に露骨なポルノグラフィックコンテンツは、いかなるプロンプトエンジニアリング手法でも回避できない範囲を超えています。2026年1月のポリシー更新以降、特定の有名人(特に政治家、著名人、公人)や著作権のあるキャラクター(ディズニーキャラクターが最も広く報告されている例)のリアルな描写もサーバーレベルでブロックされています。
永久ブロックの認識パターンは簡単です。複数のプロンプトバリエーション、複数のスタイルアプローチ、複数のセッションにわたって一貫してfinishReason: "IMAGE_SAFETY"を受信し、コンテンツが上記のカテゴリのいずれかに該当する場合、それは永久にブロックされています。生成を試み続けることはAPIクレジットとエンジニアリング時間の無駄です。前に進む生産的な道は、コンテンツ要件をブロックカテゴリを完全に回避するように再構成するか、特定のユースケースに対して異なるコンテンツポリシーを持つ可能性のある代替画像生成プラットフォームを評価することです。Nano Banana Proと他のモデルの比較については、Nano Banana Pro vs Nano Banana 2の比較で新しいモデルがセーフティをどのように異なる方法で処理しているかを分析しています。
これらの永久ブロックが重要な法的・倫理的理由で存在していることを強調しておく価値があります。Googleは複数の法域で特定カテゴリのコンテンツ防止を義務付ける規制要件に直面しており、そのアプローチはTechnology CoalitionやNCMECなどの組織によって確立された業界標準に沿っています。これらの境界線を理解し尊重することは、責任あるAI画像生成の一部です。
2026年のポリシー変更とパイプラインの将来対応
2026年第1四半期はNano Banana Proのセーフティフィルター動作に重要な変更をもたらしており、Googleがシステムの改良を続ける中、さらなる変更が予想されます。これらの動向を把握し、レジリエントなアーキテクチャを構築することは、本番環境のデプロイメントにとって不可欠です。
**2026年1月に2つの大きな変更がありました。**まず、GoogleはLayer 2の知的財産保護を強化し、有名人、ブランドロゴ、著作権のあるキャラクターの検出を追加しました。ディズニーキャラクターのブロックは最も目に見える形で現れ、Googleの開発者フォーラムで広範な開発者からの苦情を生みました。次に、地域IPベースのフィルタリング制限が厳格化されたと報告されており、一部の地域の開発者が以前は通過していたコンテンツに対してより高い拒否率を経験しています。これらの変更はAPI変更なしにサーバーサイドで実装されたため、既存のコードは引き続き動作しますが、以前成功していた一部のプロンプトが失敗し始めました。
2026年2月27日にはNano Banana 2がリリースされ、ProではなくGemini 2.5 Flashをベースに構築されています。初期テストでは、Nano Banana 2はセーフティフィルターのキャリブレーションがやや異なり、一部のカテゴリはより寛容に、他のカテゴリは変わらないように見えます。1K画像あたり約$0.067(VentureBeat、2026年2月)で、Nano Banana Proのおよそ半額であり、異なるフィルタリング動作を許容できるコスト重視のアプリケーションにとって魅力的な代替案となっています。セーフティアーキテクチャは同じ2層システムのままですが、具体的なしきい値と分類モデルが異なります。
将来対応パイプラインの構築には、セーフティフィルターの動作が進化し続けることを予測する必要があります。最もレジリエントなアーキテクチャには、いくつかの重要な要素が含まれます。まず、finishReasonの値を検出して適切にルーティングする堅牢なエラーハンドリングを実装します。Layer 1の失敗は設定修正へ、Layer 2の失敗はプロンプト代替案へ、永久ブロックは人間によるレビューへルーティングします。次に、主要なコンテンツカテゴリのプロンプトバリエーションライブラリを維持し、1つのプロンプトが失敗し始めた時に自動的に代替を試せるようにします。第三に、拒否率を経時的に監視します。急激な増加は通常、ポリシー変更を示しています。第四に、公式APIで失敗したリクエストをlaozhang.aiのような代替プロバイダーにルーティングできるマルチプロバイダー戦略を検討します。これらのプロバイダーは、Googleのポリシー更新の適用タイミングが異なる場合があります。
FAQ
Nano Banana Proのセーフティフィルターを完全にオフにすることはできますか?
Layer 1は、4つの有害カテゴリ(ハラスメント、ヘイトスピーチ、性的コンテンツ、危険なコンテンツ)すべてに対してsafety_settingsをBLOCK_NONEに設定することで完全に無効化できます。ただし、Layer 2(IMAGE_SAFETY)はサーバーサイドで動作しており、いかなるAPIパラメータ、SDK設定、アカウント構成でも無効化できません。この2層設計は意図的なものであり、Google AI Studio、Gemini API、Vertex AIを含むすべてのアクセス方法に影響します。
BLOCK_NONEを設定しても画像がブロックされるのはなぜですか?
これはNano Banana Proで最も一般的な混乱です。BLOCK_NONEの設定はLayer 1のみを無効化します。レスポンスにfinishReason: "IMAGE_SAFETY"(「SAFETY」ではなく)が表示されている場合、ブロックはLayer 2から発生しており、Layer 2は独立して動作しています。Layer 2はAI分類とハッシュマッチングを使用して生成画像そのものを分析します。選択肢はプロンプトエンジニアリング(ボーダーラインコンテンツで70〜80%の成功率)か、特定のコンテンツカテゴリが永久にブロックされていることを受け入れることです。
Nano Banana 2はNano Banana Proよりも制限が緩いですか?
2026年2月27日にリリースされたNano Banana 2は、同じ2層セーフティアーキテクチャを使用しています。初期テストでは、分類しきい値のキャリブレーションが異なり、一部のカテゴリはやや寛容に、他は変わらないように見えます。Nano Banana Proの約半額の画像単価($0.067 vs $0.134)であるため、自分のコンテンツでテストして、ニーズに合うかどうか確認する価値があります。
Google AI StudioとGemini APIでセーフティフィルターにどのような違いがありますか?
Google AI Studioは一般的に、特にボーダーラインコンテンツに対して、直接Gemini APIよりも緩やかなフィルタリングを適用します。両プラットフォームとも同じ2層システムを使用していますが、デフォルトの感度しきい値はAI Studioの方が低いように見えます。これにより、AI Studioは診断ツールとして有用です。AI StudioでプロンプトがうまくいくがAPI経由では失敗する場合は、Layer 1のsafety_settings設定に焦点を当ててください。
セーフティフィルターのリジェクションでどれくらいの費用を損失していますか?
公式Nano Banana Pro APIレートの2K画像あたり$0.134(Google AI for Developers価格、2026年3月)で、1,000枚の画像バッチに対して30%のリジェクト率の場合、無駄なAPIコールでおよそ$40のコストが発生します。10,000枚では$400です。プロンプトの最適化でリジェクト率を30%から10%に削減すると、1,000枚あたり$27の節約になります。laozhang.aiのようなプロバイダーを利用して画像あたり約$0.05にすれば、画像単価と無駄なリジェクションコストの両方を同時に削減できます。
GoogleはいずれLayer 2を設定可能にしますか?
GoogleがLayer 2を設定可能にするという兆候は現在のところありません。Googleはフィルターが「意図したよりも慎重である」ことを公に認め、偽陽性の削減にコミットしていますが、設定可能(Layer 1)と設定不可(Layer 2)のセーフティのアーキテクチャ上の分離は、技術的な制限ではなく法的・規制上の要件に基づく意図的な設計判断であると考えられます。