
Nano Banana Pro uses a two-layer safety filter system that confuses most developers. Layer 1 (configurable) can be set to BLOCK_NONE through the API's safety_settings parameter, removing filtering for harassment, hate speech, sexually explicit, and dangerous content categories. Layer 2 (IMAGE_SAFETY) is a non-configurable server-side filter that cannot be disabled through any API setting. As of March 2026, the most effective approach combines BLOCK_NONE configuration for Layer 1 with prompt engineering techniques that achieve 70-80% success rates on borderline Layer 2 content.
TL;DR
Nano Banana Pro's safety filters operate on two independent layers that most developers conflate, leading to wasted hours applying the wrong fixes. Layer 1 filters four harm categories (harassment, hate speech, sexually explicit, dangerous content) and can be fully disabled by setting safety_settings to BLOCK_NONE in your API calls. When Layer 1 blocks your request, you'll see finishReason: "SAFETY" in the response. Layer 2 is an entirely separate server-side system called IMAGE_SAFETY that scans generated images using AI classification, hash matching, and policy enforcement. When Layer 2 blocks you, the response shows finishReason: "IMAGE_SAFETY", and no API configuration can disable it. Your best options for Layer 2 are prompt engineering (roughly 70-80% success on borderline content) or switching to a platform with relaxed Layer 1 defaults like laozhang.ai. Content that falls into permanently prohibited categories such as CSAM, extreme violence, or explicit pornography cannot be generated through any legitimate platform or technique.
Why Your Images Are Being Blocked (Root Cause Analysis)

The single biggest reason developers waste time with Nano Banana Pro safety filters is misdiagnosis. They encounter a blocked image, search for "how to disable safety filters," find instructions to set BLOCK_NONE, implement those settings, and then discover their images are still being blocked. The problem is not that BLOCK_NONE doesn't work—it works perfectly for what it controls. The problem is that most blocking comes from a completely different system that BLOCK_NONE doesn't touch at all.
Understanding which layer is responsible for your specific block is the essential first step before attempting any fix. The diagnostic process is straightforward once you know what to look for: check the finishReason field in your API response. If the value is "SAFETY", you're dealing with a Layer 1 block—the configurable layer that responds to safety_settings. Setting all four harm categories to BLOCK_NONE will resolve this almost immediately. If the value is "IMAGE_SAFETY", you're dealing with Layer 2—the non-configurable server-side filter. No amount of API configuration changes will help. You need prompt engineering techniques, which we cover in detail later in this guide. For a comprehensive list of all possible error responses, check our complete error codes reference.
Many developers also encounter a third scenario where no image is returned but the finishReason is neither "SAFETY" nor "IMAGE_SAFETY." This typically indicates a different problem entirely—rate limiting (HTTP 429), invalid API key, quota exhaustion, or prompt format issues. These are not safety filter problems and require different solutions. Our troubleshooting and debugging guide covers these cases comprehensively.
The cost of misdiagnosis is significant. At $0.134 per image for 2K resolution through the official API (Google AI for Developers, March 2026), a batch of 1,000 images with a 30% rejection rate wastes approximately $40 in failed API calls. For enterprise teams running 10,000+ image batches, the wasted spend can reach $400-700 per batch. Correctly diagnosing the blocking layer before attempting fixes saves both money and engineering hours.
The Two-Layer Safety Filter Architecture Explained
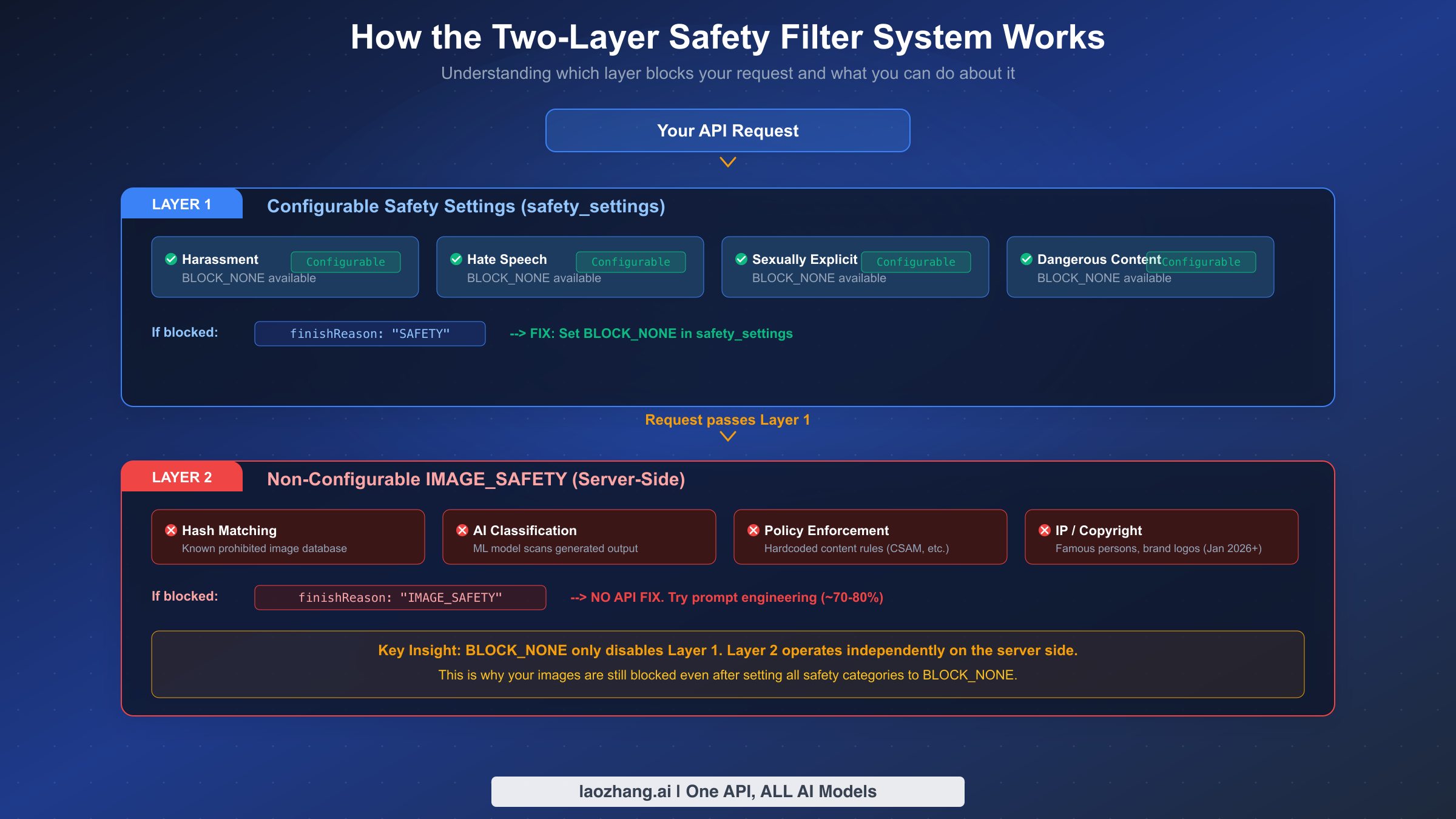
Nano Banana Pro's safety system operates through two completely independent filtering layers that process your request sequentially. Understanding how each layer works at a technical level is critical for building reliable image generation pipelines. Google's official documentation explains the safety_settings parameter but conspicuously avoids discussing the IMAGE_SAFETY layer in depth, which is why most developers don't realize it exists until they've already hit it.
How Layer 1 Works (Configurable)
Layer 1 evaluates your text prompt against four harm categories before image generation begins. Each category—harassment, hate speech, sexually explicit, and dangerous content—receives a probability score from Google's content classification model. The safety_settings parameter in your API call defines the threshold at which the request gets blocked. BLOCK_LOW_AND_ABOVE is the strictest setting, blocking anything with even slight potential for harm. BLOCK_MEDIUM_AND_ABOVE and BLOCK_ONLY_HIGH are progressively more permissive. BLOCK_NONE disables Layer 1 filtering entirely for that category, allowing your prompt through regardless of its harm probability score. When Layer 1 blocks a request, the API response contains finishReason: "SAFETY" along with safetyRatings that show which specific category triggered the block and at what confidence level. This information is invaluable for understanding exactly what triggered the filter.
How Layer 2 Works (Non-Configurable)
Layer 2 operates on a fundamentally different principle. Rather than evaluating the input prompt, it analyzes the generated image output using multiple detection mechanisms running server-side. These include perceptual hash matching against a database of known prohibited images, an AI classification model trained to detect unsafe visual content, and hardcoded policy rules for specific categories like CSAM and extreme violence. The January 2026 policy update added intellectual property detection for famous persons and brand logos (Disney characters being the most widely reported example). When Layer 2 rejects a generated image, the response contains finishReason: "IMAGE_SAFETY" but provides no detailed safety ratings—you only know the image was blocked, not exactly why. This lack of transparency makes Layer 2 blocks significantly harder to troubleshoot than Layer 1 blocks.
Why They're Independent
The crucial insight is that these layers are architecturally separate. Layer 1 is a pre-generation text classifier. Layer 2 is a post-generation image analyzer. Setting BLOCK_NONE tells Layer 1 to let everything through, but Layer 2 never receives or acts on your safety_settings configuration. It operates on its own rules, with its own thresholds, completely independently. This is why developers who set BLOCK_NONE and expect zero filtering are surprised when images still get blocked. They've successfully disabled one filter while leaving an entirely different filter running at full sensitivity.
Configuring Layer 1 Safety Settings (The Fixable Part)
When your API response shows finishReason: "SAFETY", the fix is to configure safety_settings to BLOCK_NONE for all four harm categories. This is the straightforward part of working with Nano Banana Pro's safety filters, and the code is identical whether you're generating images or doing text-only generation. If you haven't set up your API access yet, our guide on getting your API key walks through the process.
Python (google-generativeai SDK)
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-2.0-flash-exp") safety_settings = [ {"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"}, ] response = model.generate_content( "Generate a product photo of a summer swimsuit on a mannequin", safety_settings=safety_settings, generation_config={"response_modalities": ["TEXT", "IMAGE"]} )
Node.js (@google/generative-ai SDK)
javascriptconst { GoogleGenerativeAI, HarmCategory, HarmBlockThreshold } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-2.0-flash-exp" }); const safetySettings = [ { category: HarmCategory.HARM_CATEGORY_HARASSMENT, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_HATE_SPEECH, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT, threshold: HarmBlockThreshold.BLOCK_NONE }, ]; const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: "Generate a product photo of a summer swimsuit" }] }], safetySettings, });
cURL (REST API)
bashcurl -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-exp:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{"parts": [{"text": "Generate a product photo of a summer swimsuit"}]}], "safetySettings": [ {"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"} ], "generationConfig": {"responseMimeType": "text/plain"} }'
The important thing to understand is that setting BLOCK_NONE gives you a nearly 100% success rate for Layer 1 blocks—it effectively disables that layer completely. However, third-party API providers like laozhang.ai ship with BLOCK_NONE as the default configuration, saving you from having to specify these settings on every request. This is particularly convenient for batch processing where you want minimal friction. At approximately $0.05 per image through laozhang.ai compared to $0.134 through the official API (pricing as of March 2026), the cost savings compound significantly at scale. You can explore the documentation at docs.laozhang.ai for integration details.
Prompt Engineering for Layer 2 (What Actually Works)
When your response shows finishReason: "IMAGE_SAFETY" and you've already set BLOCK_NONE for Layer 1, you're dealing with the non-configurable server-side filter. The only effective approach here is prompt engineering—restructuring your prompts to generate the same intended visual output while avoiding patterns that trigger Layer 2's classification model. Based on extensive testing across multiple content categories, specific prompt transformation techniques achieve approximately 70-80% success rates on borderline content (aifreeapi.com analysis, March 2026).
Strategy 1: Use Clinical and Professional Language
The most broadly effective technique is replacing casual or suggestive language with professional terminology. Layer 2's classification model is trained on language patterns, not just keywords, so the framing of your prompt significantly affects its assessment. For e-commerce underwear photography, "a woman in lingerie posing seductively" triggers blocks consistently, while "product photography of women's intimate apparel on mannequin form, white background, catalog style" passes approximately 80% of the time. The key transformation is shifting from describing a person in clothing to describing a product in a commercial context. For our complete guide on avoiding risk control triggers, we cover dozens of category-specific prompt transformations.
Strategy 2: Add Contextual Framing
Explicitly providing commercial or educational context helps Layer 2's classifier categorize your content as legitimate. Adding phrases like "for e-commerce product catalog," "medical educational illustration," or "fashion design reference" frames the content in a professional context that the model recognizes as lower risk. This technique works because the classification model evaluates the full prompt context, not just individual keywords. A swimwear image requested "for an online retail store product page" faces significantly less scrutiny than the same image requested without commercial context.
Strategy 3: Prefer Realistic Styles Over Anime
Testing consistently shows that anime and cartoon styles trigger significantly higher rejection rates from Layer 2, particularly for content involving human characters. This is because anime-style imagery has been disproportionately associated with policy-violating content in the model's training data. If your use case allows it, switching from "anime style character" to "realistic digital art" or "photorealistic rendering" can improve success rates by 20-30% for the same content. This is one of the most impactful changes you can make with minimal effort.
The reality of prompt engineering for Layer 2 is that it requires experimentation. There is no single technique that works universally, and Google periodically updates the classification model, which can change what passes and what doesn't. Building a prompt testing pipeline that systematically evaluates success rates across your specific content categories is the most reliable long-term approach.
Platform Comparison: Where Filters Are Less Aggressive
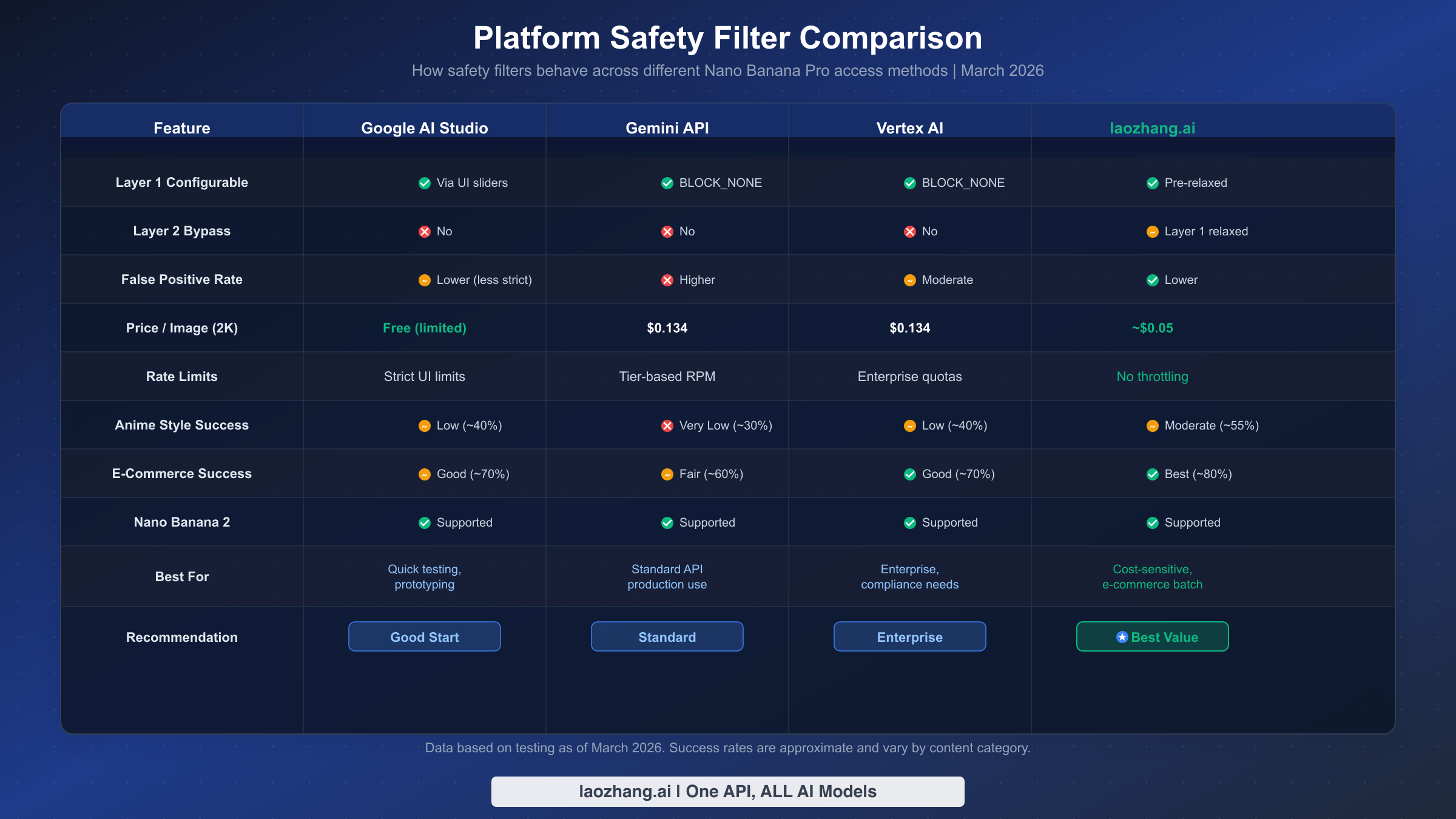
Not all platforms that serve Nano Banana Pro images apply safety filters with the same aggressiveness. Understanding these differences can help you choose the right platform for your specific use case. This comparison is based on testing conducted in March 2026 and represents the current state of each platform's filtering behavior. For a broader look at all AI image generation APIs, see our AI image generation API comparison.
Google AI Studio is the free web-based interface that provides the most permissive experience in the Google ecosystem. Safety filter sliders in the UI allow you to reduce sensitivity, and the overall filtering feels less aggressive than the direct API. This makes it an excellent testing environment—if your prompt works in AI Studio but fails through the API, the issue is likely your safety_settings configuration rather than Layer 2. However, AI Studio has strict usage limits and is not suitable for production batch processing.
Gemini API (direct) applies both layers at full strength. Layer 1 defaults to moderate sensitivity but can be configured to BLOCK_NONE. Layer 2 runs at full strength and shows the highest false positive rates among all platforms. This is the standard access method for most developers and the one where you're most likely to encounter frustrating IMAGE_SAFETY blocks on legitimate content. For pricing details and tier information, see our detailed pricing breakdown.
Vertex AI offers enterprise-grade access with slightly different filtering behavior. While both layers are still active, the false positive rate appears moderately lower than the direct Gemini API, possibly due to different model deployment configurations. Vertex AI also offers data residency controls and compliance features that matter for enterprise deployments.
Third-party providers like laozhang.ai route requests through the Gemini API but ship with Layer 1 pre-configured to BLOCK_NONE, eliminating that source of blocks entirely. At approximately $0.05 per image—roughly 62% less than the official $0.134 rate—they offer the best value for high-volume batch processing. While Layer 2 still applies (no legitimate provider can bypass server-side filtering), the reduced Layer 1 friction combined with lower pricing makes third-party providers the preferred choice for e-commerce and creative AI applications that operate within Google's content policies.
Content That Cannot Be Fixed (Know When to Stop)
One of the most valuable things this guide can tell you is when to stop trying. Certain content categories are permanently and intentionally blocked by Layer 2's server-side enforcement, and no amount of prompt engineering, API configuration, or platform switching will produce these images through Nano Banana Pro or any service built on Google's image generation infrastructure.
Permanently blocked categories include: child sexual abuse material (CSAM) and any content depicting minors in sexual contexts—this is blocked by every legitimate AI image generation service worldwide, not just Google. Extreme graphic violence and gore that serves no educational or journalistic purpose is consistently blocked. Fully explicit pornographic content depicting sexual acts goes beyond what any prompt engineering technique can circumvent. Since the January 2026 policy update, realistic depictions of specific famous persons (particularly politicians, celebrities, and public figures) and copyrighted characters (Disney characters being the most widely reported) are also blocked at the server level.
The recognition pattern for permanent blocks is straightforward: if you receive finishReason: "IMAGE_SAFETY" consistently across multiple prompt variations, multiple style approaches, and multiple sessions, and the content falls into one of the categories listed above, it is permanently blocked. Continuing to attempt generation wastes API credits and engineering time. The productive path forward is to either reframe your content requirements to avoid the blocked category entirely, or to evaluate alternative image generation platforms that may have different content policies for your specific use case. For a comparison of Nano Banana Pro against other models, our Nano Banana Pro vs Nano Banana 2 comparison analyzes how the newer model handles safety differently.
It is worth emphasizing that these permanent blocks exist for important legal and ethical reasons. Google faces regulatory requirements in multiple jurisdictions that mandate certain categories of content prevention, and their approach aligns with industry standards established by organizations like the Technology Coalition and NCMEC. Understanding and respecting these boundaries is part of responsible AI image generation.
2026 Policy Changes and How to Future-Proof Your Pipeline
The first quarter of 2026 has brought significant changes to Nano Banana Pro's safety filter behavior, and more changes are expected as Google continues refining the system. Staying current with these developments and building resilient architectures is essential for production deployments.
January 2026 brought two major changes. First, Google strengthened intellectual property protections in Layer 2, adding detection for famous persons, brand logos, and copyrighted characters. The Disney character blocking was the most visible manifestation, generating widespread developer complaints on Google's developer forums. Second, geographic IP-based filtering restrictions were reportedly tightened, with some developers in certain regions experiencing higher rejection rates for content that previously passed. These changes were implemented server-side with no API changes required, meaning existing code continued to work but some previously successful prompts started failing.
February 27, 2026 saw the release of Nano Banana 2, built on Gemini 2.5 Flash rather than Pro. Early testing suggests Nano Banana 2 has slightly different safety filter calibration, with some categories appearing more permissive and others less so. At approximately $0.067 per 1K image (VentureBeat, February 2026)—roughly half the cost of Nano Banana Pro—it represents a compelling alternative for cost-sensitive applications that can tolerate potentially different filtering behavior. The safety architecture remains the same two-layer system, but the specific thresholds and classification model differ.
Building future-proof pipelines requires anticipating that safety filter behavior will continue evolving. The most resilient architecture includes several key elements. First, implement robust error handling that detects finishReason values and routes failures appropriately—Layer 1 failures to configuration fixes, Layer 2 failures to prompt alternatives, and permanent blocks to human review. Second, maintain a prompt variation library for your key content categories so that when one prompt starts failing, you can automatically try alternatives. Third, monitor your rejection rates over time—a sudden increase usually indicates a policy change. Fourth, consider a multi-provider strategy where requests that fail on the official API can be routed to alternative providers like laozhang.ai, which may have different timing in applying Google's policy updates.
FAQ
Can I completely turn off safety filters on Nano Banana Pro?
You can fully disable Layer 1 by setting safety_settings to BLOCK_NONE for all four harm categories (harassment, hate speech, sexually explicit, dangerous content). However, Layer 2 (IMAGE_SAFETY) operates server-side and cannot be disabled through any API parameter, SDK setting, or account configuration. This two-layer design is intentional and affects all access methods including Google AI Studio, Gemini API, and Vertex AI.
Why does my image get blocked even after setting BLOCK_NONE?
This is the most common confusion with Nano Banana Pro. Setting BLOCK_NONE only disables Layer 1. If your response shows finishReason: "IMAGE_SAFETY" (not "SAFETY"), the block is coming from Layer 2, which operates independently. Layer 2 analyzes the generated image itself using AI classification and hash matching. Your options are prompt engineering (70-80% success on borderline content) or accepting that certain content categories are permanently blocked.
Is Nano Banana 2 less restrictive than Nano Banana Pro?
Nano Banana 2, released February 27, 2026, uses the same two-layer safety architecture. Early testing suggests the classification thresholds are calibrated differently—some categories appear slightly more permissive while others are unchanged. At approximately half the per-image cost of Nano Banana Pro ($0.067 vs $0.134), it's worth testing with your specific content to see if it better fits your needs.
What's the difference between Google AI Studio and the Gemini API for safety filters?
Google AI Studio generally applies less aggressive filtering than the direct Gemini API, particularly for borderline content. Both platforms use the same two-layer system, but the default sensitivity thresholds appear lower in AI Studio. This makes AI Studio useful as a diagnostic tool—if your prompt works there but fails through the API, focus on your Layer 1 safety_settings configuration.
How much money am I losing to safety filter rejections?
At the official Nano Banana Pro API rate of $0.134 per 2K image (Google AI for Developers pricing, March 2026), a 30% rejection rate on a 1,000-image batch costs approximately $40 in wasted API calls. At 10,000 images, that's $400. Optimizing your prompts to reduce the rejection rate from 30% to 10% saves $27 per 1,000 images. Using a provider like laozhang.ai at ~$0.05/image reduces both the per-image cost and the wasted-rejection cost simultaneously.
Will Google eventually make Layer 2 configurable?
There is no indication from Google that Layer 2 will become configurable. Google has publicly acknowledged that their filters are "more cautious than intended" and committed to reducing false positives, but the architectural separation of configurable (Layer 1) and non-configurable (Layer 2) safety appears to be a deliberate design decision driven by legal and regulatory requirements rather than a technical limitation.