Claude Fable 5 and GLM-5.2 are not equal live choices right now. As of June 14, 2026, Anthropic says Fable/Mythos access has been disabled, so Fable 5 is a wait-and-recheck branch; Z.AI documents GLM-5.2 inside its GLM Coding Plan, so GLM-5.2 is the branch to verify with a controlled coding-agent smoke test.
That does not make GLM-5.2 a Fable replacement. Do not change a production default because one side is unavailable or because one model looks cheaper on paper; lock the same repo, same issue, same prompt, same tools, and same acceptance test before naming a winner.
| Route | Use this branch when | First action | Stop rule |
|---|---|---|---|
| Wait for Fable 5 | You need Anthropic-owned Fable behavior, policy, fallback, or billing before making the decision. | Recheck Anthropic's access statement and model/pricing docs before planning a test. | Do not rank Fable 5 on live tasks you cannot currently run. |
| Smoke-test GLM-5.2 | You need a coding-agent route you can verify now through Z.AI's documented GLM Coding Plan. | Configure the Z.AI provider path, select glm-5.2[1m] where available, and run one bounded task. | Do not call it a replacement until the task passes with acceptable latency, retries, quota use, and rollback cost. |
| Dual-run later | You are considering a default-model switch, team policy change, or production routing update. | Preserve the same task packet and run Fable again only if access returns. | No winner without observable same-task evidence from both runnable branches. |
Evidence note: Anthropic's Fable launch, access, model, and pricing pages and Z.AI's GLM Coding Plan documentation were checked on June 14, 2026. Availability, quota rules, and model routing are volatile, so recheck the official docs before publishing a new recommendation or changing a default route.
The Fast Answer
The practical answer is route-based. Fable 5 is not the model to start a live coding-agent evaluation with today because Anthropic's access statement says Fable 5 and Mythos 5 access has been disabled for all customers. Its launch page, pricing row, model ID, context, and output limits still matter, but they are not a runnable route while access is unavailable.
GLM-5.2 is the route to test first if your immediate job is "what can I run now?" Z.AI's latest-model documentation lists GLM-5.2 support in the GLM Coding Plan and shows coding-tool mappings that include glm-5.2[1m]. That is enough to justify a smoke test. It is not enough to publish a universal replacement verdict.
Use this split:
| Decision | Best first move | Why |
|---|---|---|
| You need Anthropic Fable behavior specifically. | Wait and recheck Fable access. | Current official access status blocks a fair live run. |
| You need a coding-agent route to test today. | Smoke-test GLM-5.2 through the documented Z.AI Coding Plan route. | The route is documented, selectable in the relevant tool path, and designed for coding-plan usage. |
| You are deciding a team default model. | Keep the current default, then dual-run when both branches are runnable. | Default switches need accepted-task evidence, not launch-week chatter. |
The important word is "first." GLM-5.2 can be the first runnable test route without being the final answer for every workload.
What Changed This Week
The comparison changed because the live status changed. Anthropic announced Claude Fable 5 on June 9, 2026, then updated the story after access was suspended. The separate Anthropic access statement says the company must disable Fable 5 and Mythos 5 for all customers under a U.S. government directive. That makes any static "Fable vs GLM" table incomplete unless it leads with availability.
Z.AI's side is different. The GLM-5.2 evidence is not an Anthropic-style launch page for a universal API product. It is a documented coding-plan route: the latest-model page says GLM Coding Plan supports GLM-5.2, and the tool-integration docs show an OpenAI-compatible coding provider path with base URL https://api.z.ai/api/coding/paas/v4, model glm-5.2, and a 1,000,000-context setting. Read that as a route contract, not as proof that every wrapper, catalog, or old GLM-5 comparison row applies to GLM-5.2.
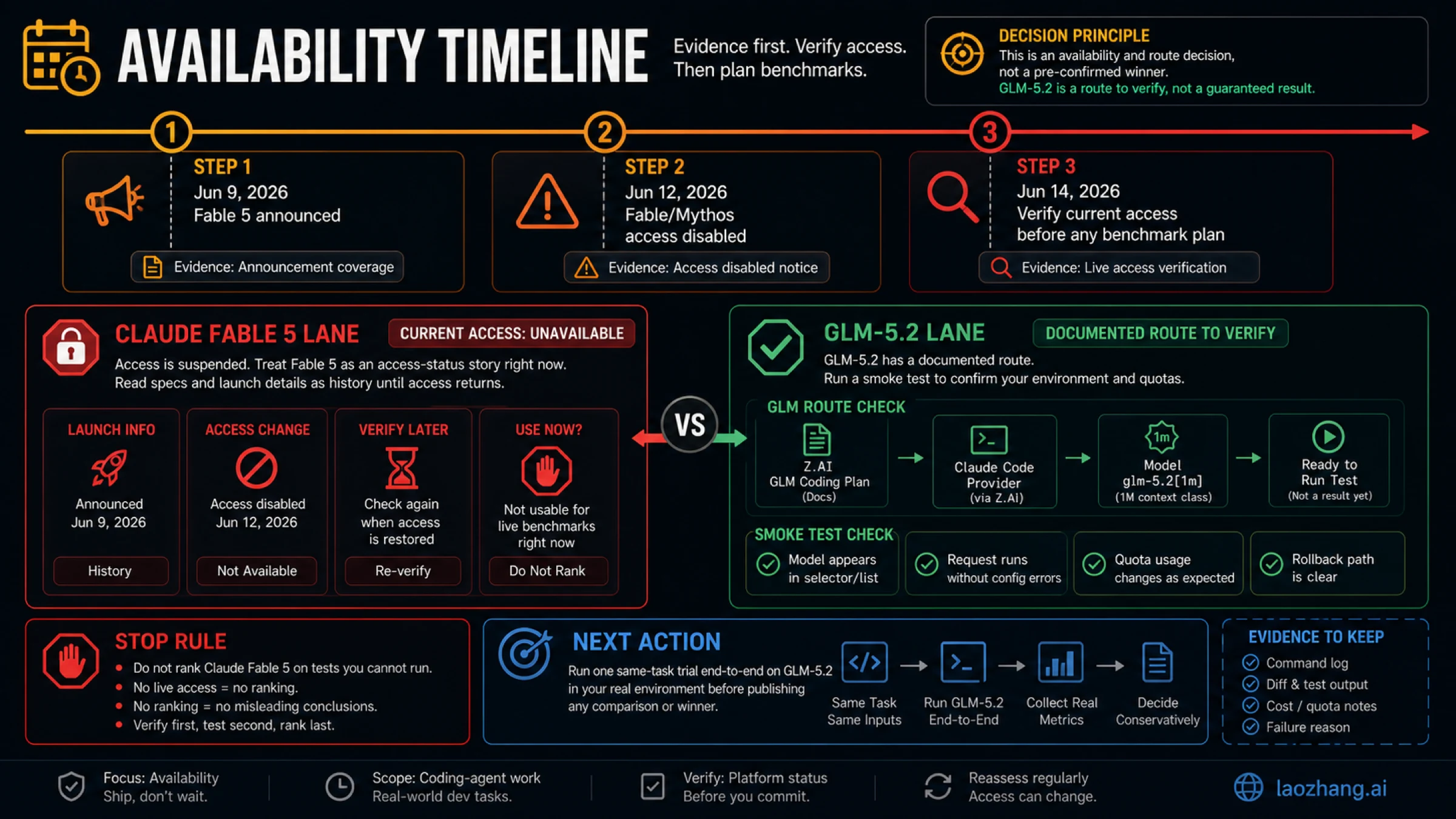
The safe order is therefore simple: verify Fable access, verify the GLM-5.2 route, then compare work. If you cannot run Fable, do not score Fable on the same task. If you can run GLM-5.2, do not promote it until the task, logs, quota use, and rollback path are visible.
Official Contract Table
This table is intentionally not a benchmark table. It shows who owns each claim and what the claim lets you do.
| Contract point | Claude Fable 5 | GLM-5.2 |
|---|---|---|
| First owner to verify | Anthropic | Z.AI |
| Current status checked on 2026-06-14 | Officially unavailable after the Fable/Mythos access change. | Documented inside GLM Coding Plan. |
| Model label to watch | claude-fable-5 in Anthropic model documentation and release notes. | glm-5.2 and glm-5.2[1m] in Z.AI coding-tool documentation. |
| Context and output boundary | Anthropic docs list 1M context and 128k max output for Fable 5. | Z.AI's coding route documents a 1M-context class for the glm-5.2[1m] route. |
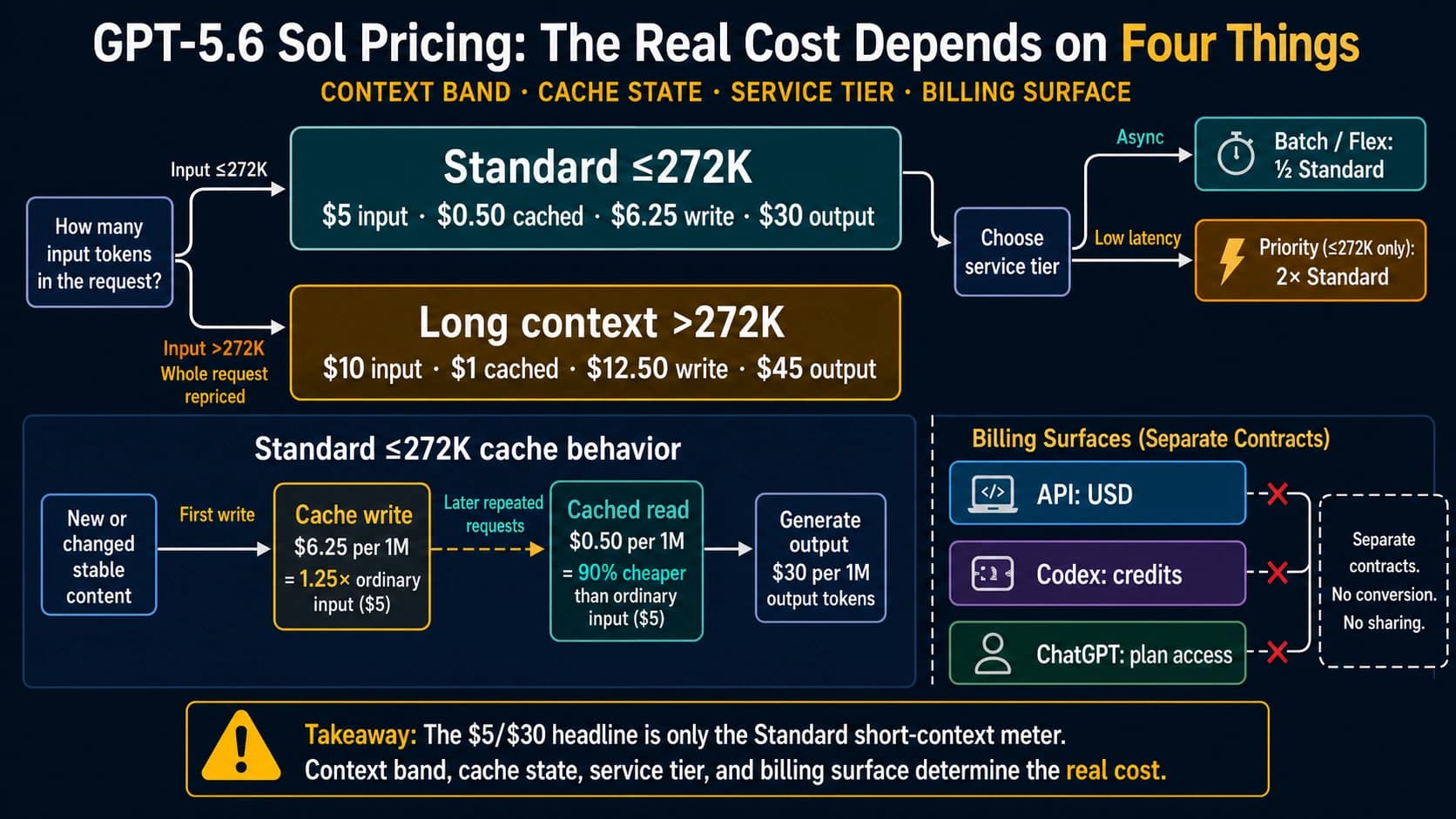
| Cost unit | Anthropic lists token pricing for Fable 5, including $10 input and $50 output per million tokens before cache, batch, and route details. | Z.AI Coding Plan uses subscription quota units and multipliers, not a directly comparable per-million-token row. |
| Coding-agent implication | Strong spec, but wait-and-recheck while access is disabled. | Runnable test candidate if your Z.AI route exposes the model and your task can tolerate route risk. |
| What this does not prove | That Fable can be tested today. | That GLM-5.2 is better than Fable, Opus, Kimi, or your existing default. |
Fable's implementation contract is still worth understanding. Anthropic's model and release docs describe Fable 5 with a large context window, high output ceiling, adaptive thinking behavior, fallback/refusal categories, and retention requirements. Those details matter if access returns, because they affect how you would run a fair coding-agent trial.
GLM-5.2's implementation contract is more practical today but narrower. It matters when you are already using, or can use, the Z.AI coding route. If your real setup is Claude Code, keep route ownership clear: configuring a provider path is a different problem from comparing model quality. The broader Claude Code routing basics are covered in Claude Code API configuration, and billing ownership differences are covered in Claude Code API key vs subscription billing.
Normalize Cost Before You Compare
The Fable row and the GLM row use different units. Fable has an official token-price row. GLM-5.2, in the evidence used here, is primarily a Coding Plan route with quota multipliers. A direct "which is cheaper?" answer is misleading unless you first choose the same task and watch what the route consumes.
Z.AI's overview and FAQ describe GLM-5.2 and GLM-5-Turbo as advanced models with quota deduction multipliers, including different peak and off-peak behavior. That is not the same kind of number as "$10 input / $50 output per MTok." It is a plan-consumption rule. A task with many tool calls, retries, or long outputs may consume quota differently from a clean single-turn answer even when the model label is the same.
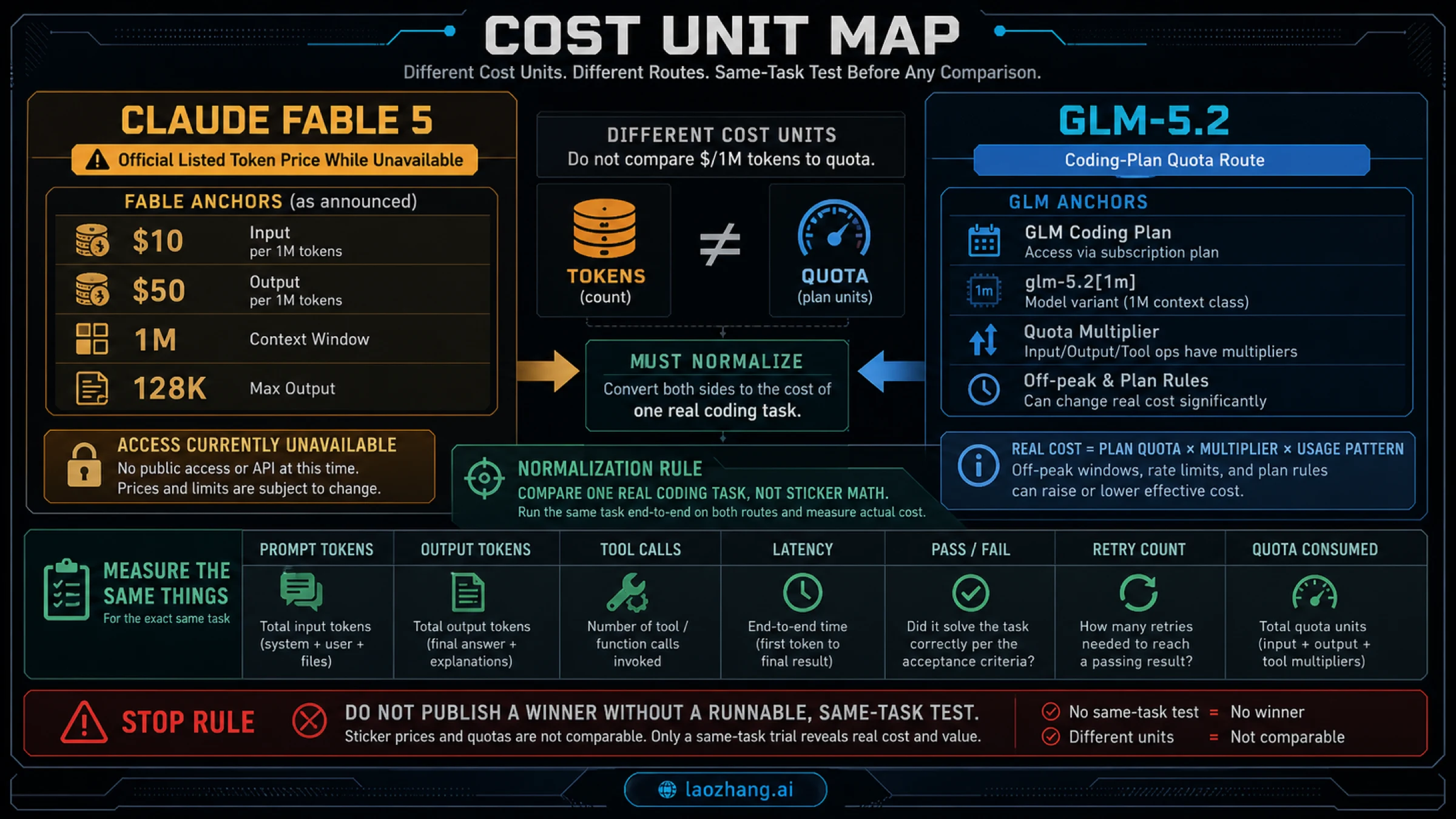
Use this measurement row before making a cost claim:
| Measure | Why it matters |
|---|---|
| Prompt tokens | Long repos and copied context can dominate input cost or quota consumption. |
| Output tokens | Agent explanations, patches, and logs can make output the real expense. |
| Tool calls | Coding-agent routes can charge or throttle around tool-use patterns. |
| Latency | A cheaper run that blocks review or CI can lose in practice. |
| Pass/fail result | Failed cheap attempts are not cheaper if they require repeated human recovery. |
| Retry count | Quota burn and review load usually rise with retries. |
| Rollback effort | The real cost of a bad patch is often outside the billing table. |
If you cannot collect that row, say "the units are not comparable yet." That is more useful than a confident but false price winner.
When GLM-5.2 Is Worth Testing First
GLM-5.2 is worth testing first when the question is operational: "What can I put through a coding-agent task this week while Fable is unavailable?" Good candidates are bounded repository fixes, repeatable test failures, migration chores with clear acceptance tests, and tasks where a failed patch is cheap to revert.
It is also a reasonable first test when you want to see whether a Z.AI route can cover work that you previously expected to try on a premium Claude-like model. In that case, the useful comparison is not "Is GLM more intelligent?" It is "Can GLM-5.2 finish this task to our review standard with acceptable latency, quota use, and rollback risk?"
Do not start with GLM-5.2 if your real need is Anthropic-specific policy behavior, Anthropic billing, Anthropic fallback semantics, or an apples-to-apples Fable evaluation. It also should not be your only branch if the task is safety-sensitive, compliance-heavy, or expensive to debug after a subtle wrong patch.
For adjacent model-routing decisions, the existing Kimi K2.6 vs Claude Opus 4.7 guide is a better route when cost-versus-correctness is the core question, and Qwen3.6 vs Kimi K2.6 vs GLM-5.1 is the better sibling when the GLM route itself is part of a broader Chinese-model comparison. Keep this decision focused on Fable access asymmetry versus GLM-5.2 testability.
Do Not Switch A Default Yet
The strongest stop rule is also the easiest to ignore: do not replace a production default just because Fable is unavailable and GLM-5.2 is visible. Availability can decide what you test first. It cannot decide what you trust by default.
Before changing a default route, require all of these:
| Requirement | Pass condition |
|---|---|
| Same task packet | Same repo, issue, prompt, file set, time budget, and allowed tools. |
| Same acceptance bar | The same tests, review checklist, and failure budget apply to every branch. |
| Same evidence packet | Keep command logs, diffs, test output, latency, quota/cost notes, and failure reason. |
| Same rollback plan | Know how to revert, isolate, or rerun when a patch is plausible but wrong. |
| Same decision threshold | Decide in advance what counts as "good enough" and what forces fallback. |
If Fable access returns, rerun the preserved task packet rather than comparing a new GLM task against an old Fable impression. If Fable remains unavailable, say so plainly and evaluate GLM-5.2 against your existing runnable baseline instead.
Same-Task Evaluation Checklist
The cleanest test is deliberately small. Pick one repo, one issue, and one acceptance test. The task should be meaningful enough to expose agent behavior but small enough that you can review it without guessing.

Use this packet:
- Lock the input: prompt, branch, files, issue description, allowed tools, and time budget.
- Run GLM-5.2 through the documented Z.AI coding route.
- Save the command log, model label, provider route, diff, tests, latency, quota note, and failure reason.
- Judge only observable outcomes: patch quality, tests pass, retry count, review load, and rollback effort.
- If Fable access returns, run the same packet without changing the task.
- If both branches are runnable, compare accepted-task cost and failure mode, not just catalog price or social proof.
That packet gives you a decision you can defend. "GLM-5.2 passed our bounded migration task with one retry and manageable quota burn" is useful. "GLM-5.2 beats Fable because Fable was suspended" is not.
FAQ
Is Claude Fable 5 available right now?
Not according to the Anthropic access statement checked on June 14, 2026. Anthropic says Fable 5 and Mythos 5 access has been disabled for all customers. Recheck Anthropic's current access and model pages before planning any Fable test.
Is GLM-5.2 better than Claude Fable 5?
That is not a fair live claim while Fable access is unavailable. GLM-5.2 is the branch to test first if you need a runnable coding-agent route today, but "better" requires the same task, same inputs, and observable outcomes from both branches.
What model string should I look for?
For Fable, watch Anthropic documentation for claude-fable-5 and the current access status. For GLM, Z.AI's coding docs use glm-5.2 and show a glm-5.2[1m] coding route where the 1M-context class matters.
Is GLM-5.2 cheaper than Fable 5?
Not in a simple row-to-row way. Fable has official per-million-token pricing; GLM-5.2 in this route uses Coding Plan quota rules and multipliers. Compare cost only after measuring the same task's tokens, tool calls, retries, latency, and quota consumption.
Should I use GLM-5.2 as a Fable replacement?
Use GLM-5.2 as a live test route, not as an automatic replacement. It can be the right first branch when you need a bounded coding-agent experiment now. Keep Fable as a wait-and-recheck branch, and change defaults only after same-task evidence shows the new route clears your quality and risk bar.
Bottom Line
The useful comparison is not "which name sounds stronger?" It is "which route can I test without lying to myself?"
On June 14, 2026, the honest route split is: Fable 5 has an official contract but is unavailable, while GLM-5.2 has a documented Z.AI Coding Plan route that can be smoke-tested. Start there. Recheck Fable before ranking it, normalize cost units before declaring a price winner, and require one same-task evidence packet before any default-model switch.