
Kimi K2.6 is the model to test first when cost and high-volume coding-agent experiments dominate; Claude Opus 4.7 should stay first when correctness, long context, and migration risk matter more than the API bill.
Do not replace an Opus default because Kimi looks strong in a benchmark row or one passing test. Dual-run the same workflow, same spec, same tool budget, and same review path before changing production routing.
| Route | Start here when | Why it fits | Stop rule |
|---|---|---|---|
| Kimi-first | You need cheaper large-batch coding-agent experiments, open-route testing, or cost-sensitive API trials. | Kimi's first-party contract makes the cost gap large enough to justify a pilot. | Do not call it an Opus replacement until it survives the exact workflow where Opus currently earns its cost. |
| Opus-first | The work is correctness-critical, long-context, migration-heavy, or expensive to debug after a hidden failure. | Opus 4.7 is the premium mature route with Anthropic-owned API behavior and context claims. | Do not switch away just because Kimi is cheaper on paper. |
| Dual-run | A team is considering a default model switch, production routing change, or coding-agent policy update. | Replacement quality depends on reproduced failures, review load, and recovery cost, not only published scores. | No default change without a pre-set loss threshold. |
As of 2026-04-23, the official contract facts make the split sharper: Kimi lists cache-hit input at $0.16/MTok, input at $0.95/MTok, output at $4.00/MTok, and a 262,144-token context window; Anthropic lists Claude Opus 4.7 at $5/MTok input, $25/MTok output, 1M context, and 128k max output. Those facts prove the cost and context route, not a universal replacement verdict.
The Fast Answer
The useful answer is route-based, not model-prestige-based. Kimi K2.6 is the first model to evaluate when you need many coding-agent runs, low-cost iteration, or an open model route that can be tested without paying premium Opus prices on every attempt. Claude Opus 4.7 is the first model to keep when the job has high hidden-failure cost: repo migrations, security-sensitive code, long-context reasoning, difficult debugging, or any workflow where a wrong patch is more expensive than the tokens.
The middle route matters most for teams that are actually considering replacement. If Opus is already your default for coding agents, the right comparison is not "Which model has the nicer public chart?" It is "Can Kimi survive the exact work where Opus currently earns its cost?" That means same repository, same spec, same tool budget, same tests, same reviewer, and the same failure-accounting rules.
Use this quick split:
| Decision | Best first move | Why |
|---|---|---|
| You want to expand experiment volume or run cheap agent trials. | Test Kimi K2.6 first. | The official Kimi price is low enough that more attempts can be part of the strategy. |
| You need the lowest-regret default for hard coding work. | Keep Claude Opus 4.7 first. | Anthropic owns the premium coding and long-context contract, and failure cost can dominate token cost. |
| You plan to change production routing or model defaults. | Dual-run before switching. | Replacement quality is a workflow claim, not a benchmark claim. |
That is why a Kimi-first pilot can be the right move even if Opus remains the safer production default. Cost lets you test more. Correctness decides whether the cheaper route deserves the default.
The Official Contract Makes The Tradeoff Obvious

The official contract is where the comparison becomes concrete. Kimi K2.6 has the stronger cost argument; Claude Opus 4.7 has the larger official context route, mature Anthropic API contract, and premium coding positioning.
| Contract point | Kimi K2.6 | Claude Opus 4.7 |
|---|---|---|
| First-party owner | Moonshot / Kimi | Anthropic |
| Current model label | kimi-k2.6 on the Kimi platform | claude-opus-4-7 in Anthropic docs |
| Official price checked on 2026-04-23 | $0.16/MTok cache hit, $0.95/MTok input, $4.00/MTok output | $5/MTok input, $25/MTok output |
| Context / output | 262,144-token context window on Kimi's pricing page | 1M context and 128k max output in Anthropic docs |
| Availability claim | Kimi says K2.6 is available on Kimi.com, Kimi App, API, and Kimi Code, and is being open sourced | Anthropic says Opus 4.7 is available in Claude products, API, Amazon Bedrock, Vertex AI, and Microsoft Foundry |
| API behavior caveat | Provider routes may have separate latency, quota, and billing behavior | Anthropic documents API behavior changes, including removed sampling parameters and tokenizer differences |
Sources matter here because price rows travel badly in launch-week comparisons. Kimi's own K2.6 pricing page and API platform are the right owners for the Kimi contract. Anthropic's Opus 4.7 launch post and Claude 4.7 model docs are the right owners for the Opus contract.
At a simple one-million-token input plus one-million-token output shape, the list-price gap is not subtle. Kimi's non-cached input plus output would land near $4.95 before any cache-hit benefit; Opus lands at $30 for the same input/output count. That rough comparison is useful, but it is not the whole decision because output volume, caching, retries, tool calls, and review time can move the real cost.
The most important cost nuance on the Opus side is tokenization. Anthropic's migration notes say Opus 4.7 can process the same text as roughly 1.0x to 1.35x as many tokens compared with previous models depending on content type. That should not be rewritten as a universal surcharge, but it does mean teams should measure real prompts before assuming the catalog price is the final workload cost.
What The Evidence Does Not Prove
The biggest mistake in this comparison is pretending that every Kimi proof point is direct proof against Opus 4.7. It is not.
Kimi's official K2.6 release material is useful, but its benchmark table does not directly include Claude Opus 4.7 as a column. It compares Kimi K2.6 against models including GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro, and Kimi K2.5. That can support a claim that Kimi K2.6 is a serious current model, and it can support a low-cost pilot. It cannot, by itself, prove that Kimi beats Opus 4.7 on your coding-agent workflow.
Third-party tests are useful in a different way. A same-workflow comparison from Kilo, checked on 2026-04-23, found Claude Opus 4.7 stronger in that workflow after review and bug reproduction, while Kimi remained much cheaper. That is not universal proof that Opus always wins. It is a good example of the evaluation method: run the same task, inspect the diff, reproduce the bugs, and count real defects rather than trusting a passing summary.
That distinction creates the evidence boundary:
| Evidence type | What it can support | What it cannot support |
|---|---|---|
| Kimi first-party pricing and release notes | Kimi is real, current, cheaper, and worth testing for coding-agent volume. | Kimi is a drop-in Opus 4.7 replacement. |
| Anthropic Opus 4.7 docs | Opus has a mature premium API route, 1M context, and documented migration behavior. | Opus is always worth the extra spend for every task. |
| Third-party head-to-head pages | Which tests to reproduce and what failure modes to watch. | A universal production routing decision. |
| Your own dual-run pilot | Whether Kimi can replace Opus in your environment. | Whether every other team should make the same switch. |
If the evidence is weaker than the deployment consequence, slow down. For model defaults, a clean boundary is better than a confident but brittle verdict.
How To Pilot Kimi Against Opus
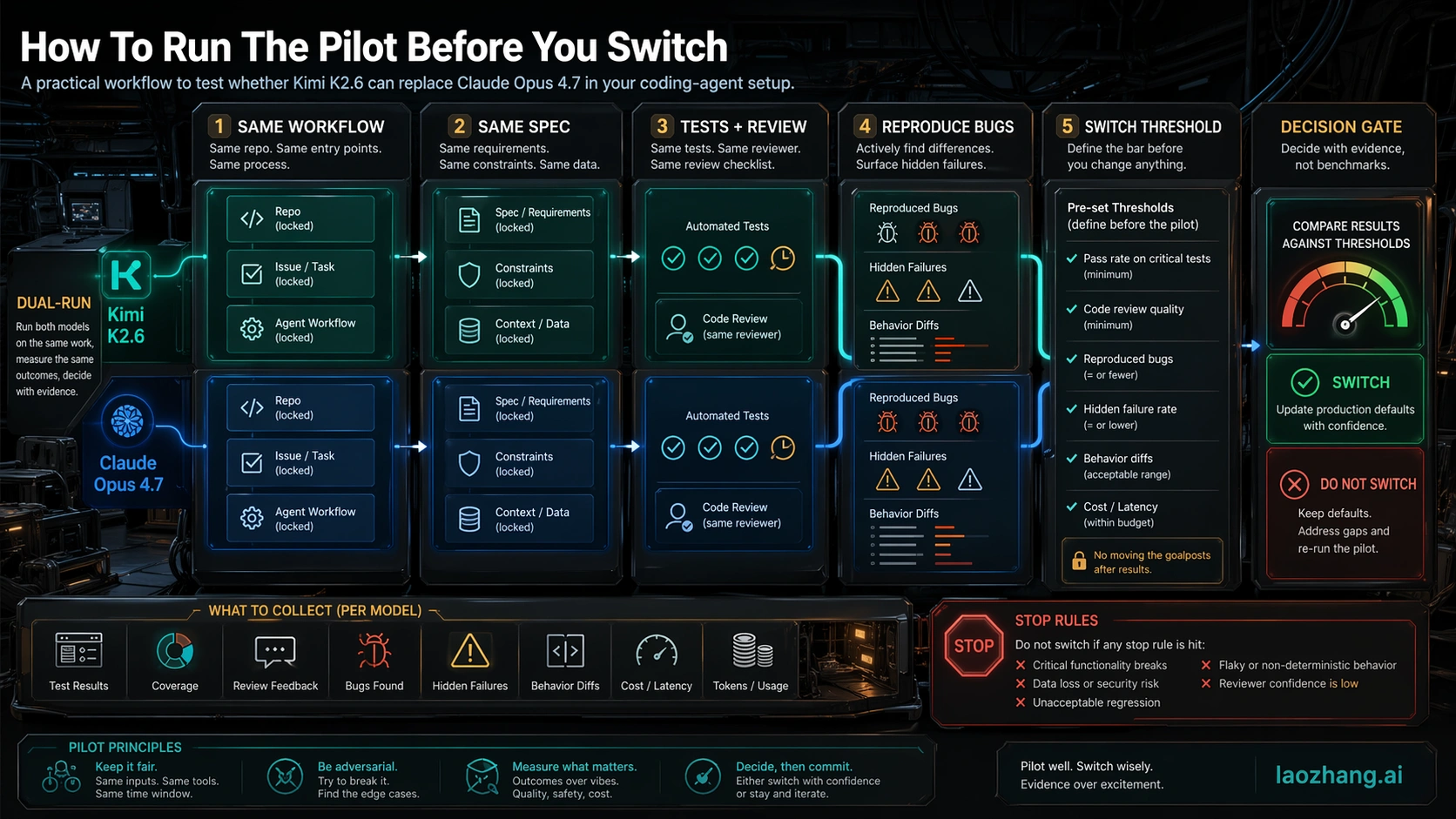
A serious pilot should be boring. The goal is not to create a dramatic leaderboard; it is to remove excuses from the comparison.
Start with a control pack of real tasks where Opus has previously been useful. Include at least one small bug fix, one medium refactor, one test-writing task, one long-context task, and one ambiguous task where the model must ask for missing information or resist a bad instruction. If your real use is agentic coding, include tool use and repo navigation. If your real use is API batch work, include the same prompt templates, timeout rules, and retry policy you use in production.
Then run both models under the same constraints:
- Use the same repository snapshot, task description, files, and success criteria.
- Give both models the same tool budget and the same stop conditions.
- Run the same unit, integration, lint, or smoke checks.
- Review the diffs manually, especially where tests pass but the code shape looks risky.
- Reproduce failures before scoring them.
- Count reviewer time, retries, tool loops, and hidden bug severity, not only token price.
The switch threshold should be decided before the pilot starts. For example, a team might say Kimi can become the default for low-risk batch edits if it keeps real defects within 10 percent of Opus while cutting run cost by more than half. The same team might require near-parity before using Kimi on migrations or security-sensitive code. That asymmetry is rational because different workflows have different failure prices.
Do not let a "passed tests" message end the evaluation. Tests are necessary, but coding agents can fail in ways tests do not see: over-broad refactors, brittle abstractions, missed migration steps, wrong assumptions about surrounding code, or a fix that works only for the visible case. If Opus avoids those failures more often, it may still be cheaper for high-risk work even when Kimi's token bill is far lower.
Workload Routes: Where Each Model Should Start
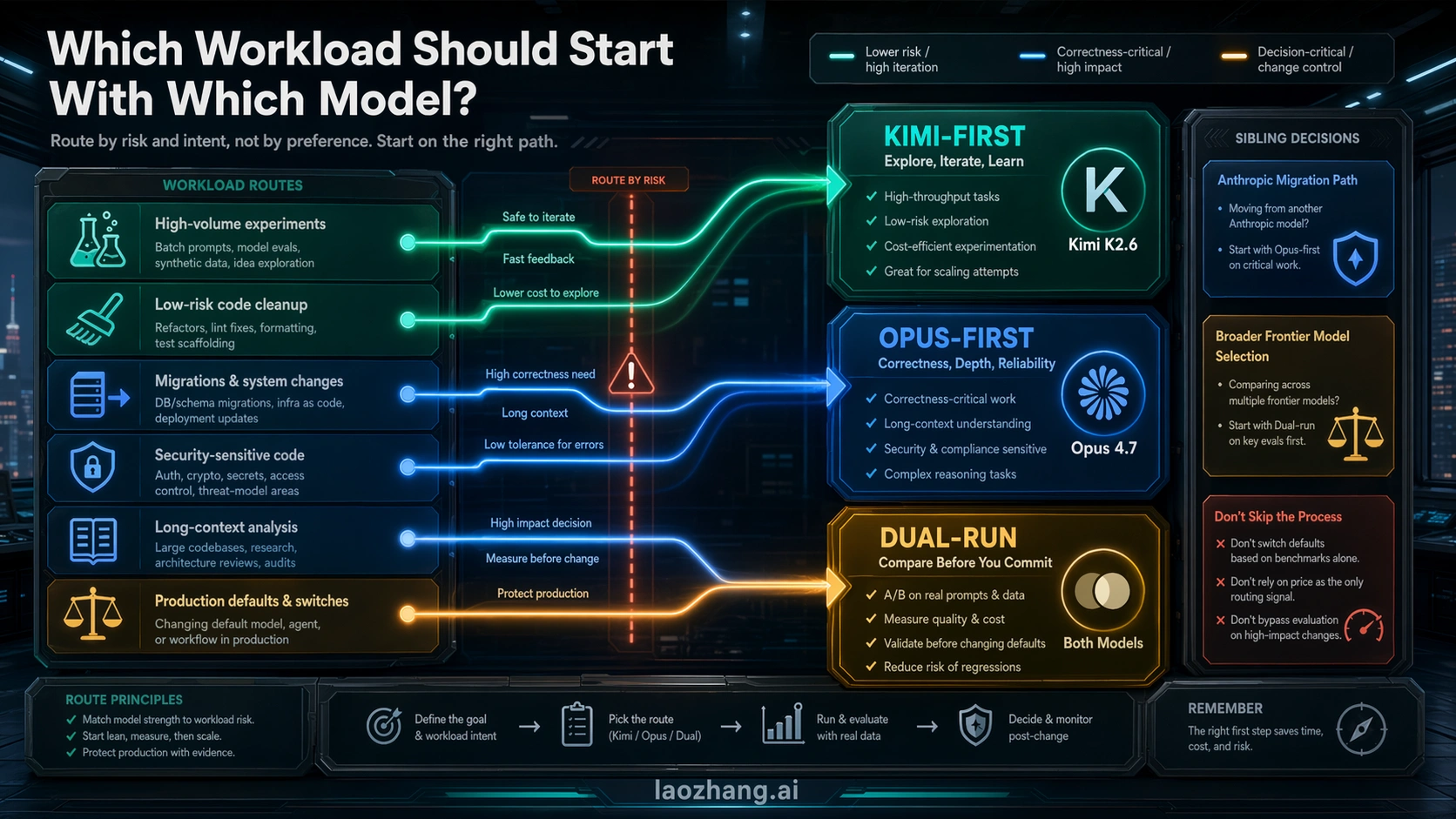
The cleanest routing rule is to choose by the failure you cannot afford, then let price decide inside that boundary.
| Workload | Start with Kimi K2.6 | Start with Claude Opus 4.7 | Dual-run before default change |
|---|---|---|---|
| High-volume agent experiments | Yes | Only as a quality control sample | Before routing important repositories |
| Low-risk code cleanup or test scaffolding | Yes | If review time becomes the bottleneck | If results will be merged automatically |
| Repo-wide migration | Only after a control run | Yes | Yes |
| Security-sensitive or payment-adjacent code | Rarely first | Yes | Yes |
| Long-context production analysis | When 262k context is enough and cost dominates | When 1M context or 128k output matters | If Kimi output will replace Opus decisions |
| Open-source or self-host evaluation | Kimi is the natural first route to investigate | Not applicable as an open model route | If self-host output competes with hosted Opus |
| Procurement or conservative enterprise routing | Maybe as a cost pilot | Usually first | Yes, with audit notes |
Existing sibling guides can take over when the decision is not really Kimi versus Opus. If your real question is whether Opus 4.7 is worth moving to from Opus 4.6, use the focused Claude Opus 4.7 vs Claude Opus 4.6 migration guide. If your real question is broader frontier routing across Anthropic, OpenAI, and Google, use the broader Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro route guide. Keep the current decision focused on whether Kimi can pilot or replace an Opus route.
For many teams, the practical steady state will not be "Kimi everywhere" or "Opus everywhere." It will be a routed stack: Kimi for high-volume exploration, first-pass batch work, and cost-sensitive experiments; Opus for high-risk coding, migrations, and long-context production tasks; and dual-run tests whenever the boundary changes.
API Notes Before You Switch Defaults
The API details are not side notes if your comparison is about coding agents. They decide how painful the switch will be.
On the Kimi side, separate first-party Kimi pricing from provider or marketplace pricing. Microsoft Foundry, OpenRouter, and other routes can be useful, but they are separate contracts. If you publish an internal cost estimate, label which route owns it. Do not mix a first-party Kimi price with a third-party provider's latency, quota, or model-routing behavior.
On the Claude side, read Opus 4.7 as a migration event, not just a model ID swap. Anthropic documents behavior changes around sampling parameters, extended thinking budgets, tokenizer behavior, high-resolution image handling, and task-budget controls. If your current harness passes non-default top_p, top_k, or temperature behavior that Opus 4.7 no longer accepts in the same way, the migration work may be in your client code rather than your prompt.
The safest API comparison plan is:
- Keep a small Opus control set pinned while Kimi is being tested.
- Log token usage, retries, tool calls, wall-clock time, and reviewer intervention for both models.
- Separate cached input, non-cached input, and output costs in reports.
- Track failures by severity, not just count.
- Make the first rollout route opt-in before it becomes default.
That gives Kimi a fair chance to win where price really matters without pretending that every lower bill is a better production decision.
FAQ
Is Kimi K2.6 cheaper than Claude Opus 4.7?
Yes, on the first-party API prices checked on 2026-04-23, Kimi K2.6 is much cheaper. Kimi lists $0.95/MTok input and $4.00/MTok output, with a $0.16/MTok cache-hit input row. Anthropic lists Claude Opus 4.7 at $5/MTok input and $25/MTok output. Keep route ownership clear because provider prices can differ.
Can Kimi K2.6 replace Claude Opus 4.7?
It can replace Opus only after it proves itself on the same workflow where Opus is currently used. The right claim is "Kimi deserves a pilot for cost-sensitive coding-agent work," not "Kimi is automatically a drop-in Opus replacement."
Which is better for coding agents?
Claude Opus 4.7 is the safer first choice for correctness-critical coding agents, migrations, and high-risk long-context work. Kimi K2.6 is the better first experiment when you need many cheaper runs and can review or discard weaker outputs.
Does Kimi's official benchmark table prove it beats Opus 4.7?
No. Kimi's official K2.6 table is useful, but it does not directly include Claude Opus 4.7 as the head-to-head column. Treat it as evidence that Kimi K2.6 is serious and current, not as direct production replacement proof.
What should I test before changing a default model?
Run the same repository, same spec, same tool budget, same tests, and same manual review through both models. Decide the acceptable quality loss and cost win before the test starts. If the failure cost is high, dual-run longer.
Should I use a third-party provider comparison page to decide?
Use third-party pages to scout benchmark categories, price rows, and test ideas, but do not let them own official facts. First-party Kimi and Anthropic pages own model IDs, pricing, context, output limits, and API behavior.
What if I need a 1M-token context window?
Start with Claude Opus 4.7 when the official 1M context route is central to the workload. Kimi K2.6's 262,144-token context is substantial, but it is not the same contract. If your work fits inside Kimi's context and cost dominates, test Kimi first.
What is the safest final recommendation?
Use Kimi-first for low-cost high-volume experiments, Opus-first for correctness-critical production, and dual-run before any default replacement. That route split is more useful than declaring one universal winner.