
As of May 22, 2026, Qwen3-30B-A3B should not be treated as one deployment choice. Pick the branch first: Instruct-2507 for fast instruction work, Thinking-2507 for deliberate reasoning, Coder-30B-A3B for repo-scale coding, and the original card only when reproducing the April 2025 hybrid model.
A3B tells you the model is a sparse MoE route with a smaller active-parameter slice; it does not tell you which current branch, runtime tag, context length, or hardware profile fits your job.
| If your job is... | Start with this branch | Verify before switching |
|---|---|---|
| Fast local instruction, summaries, chat, and ordinary agent prompts | Qwen/Qwen3-30B-A3B-Instruct-2507 | It is the non-thinking branch, so do not expect <think> traces. |
| Hard reasoning where longer deliberation is acceptable | Qwen/Qwen3-30B-A3B-Thinking-2507 | Measure latency, verbosity, and answer quality on your own hard tasks. |
| Repo-scale coding, tool loops, and long-context code work | Qwen/Qwen3-Coder-30B-A3B-Instruct | Treat it as the Coder branch, not the generic original card. |
| April 2025 hybrid-mode reproduction or old eval comparison | Qwen/Qwen3-30B-A3B | Use the original owner card and its 32K native context boundary. |
| Newer Qwen local or coding exploration | Check Qwen3.6-35B-A3B separately | Keep Qwen3.6 as a successor boundary, not the same model row. |
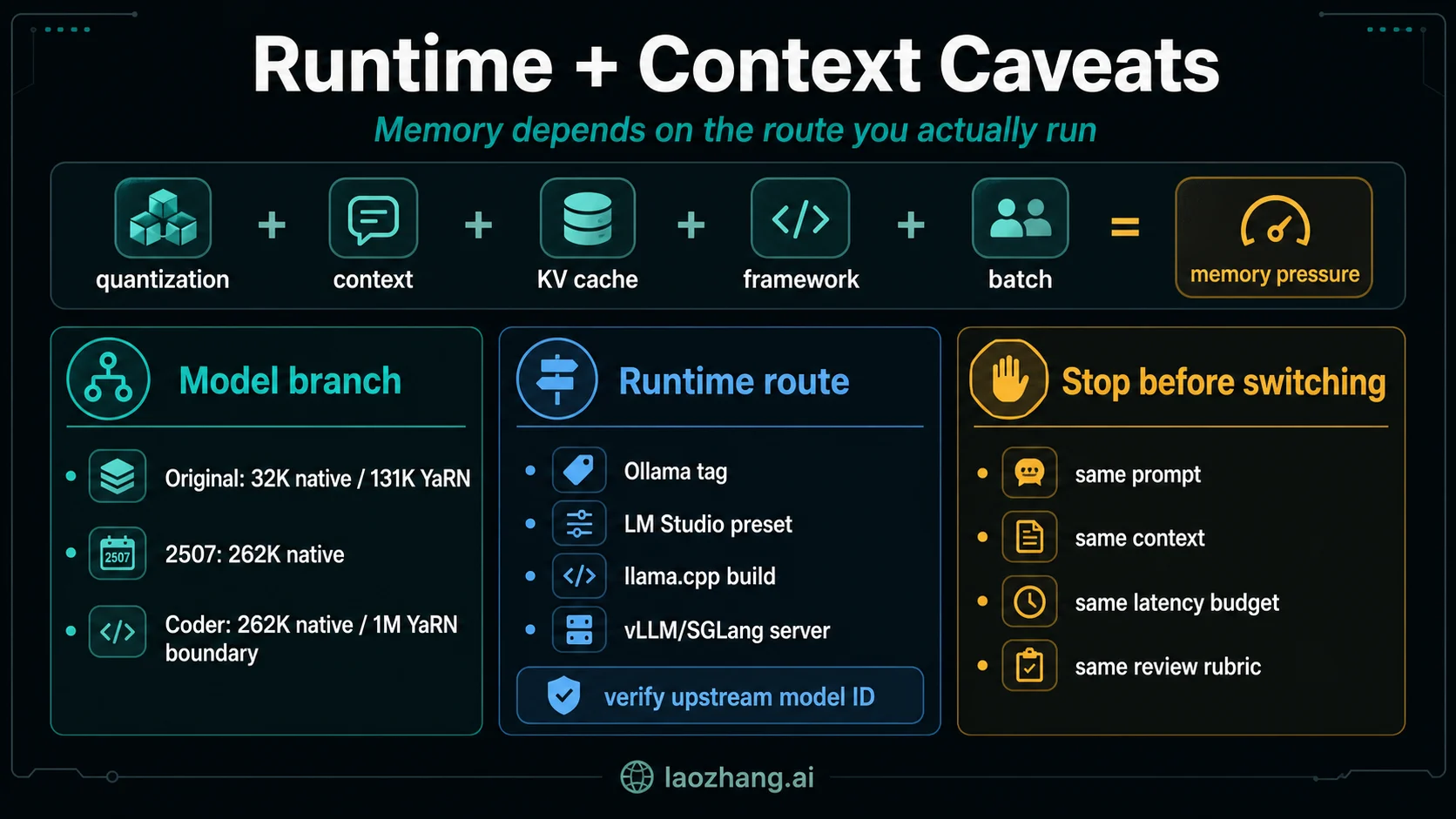
Stop rule: do not replace your current local default until the same prompt, same files, same tools, same context budget, same tests, same latency budget, and same review rubric pass on the candidate branch.
The Fast Answer
Use Qwen/Qwen3-30B-A3B-Instruct-2507 when you want a compact local model for normal instruction following, summaries, light agents, and chat-style work without visible thinking output. The branch is easier to reason about as a default because its Hugging Face card positions it as non-thinking and records a 262,144-token native context.
Use Qwen/Qwen3-30B-A3B-Thinking-2507 when the task rewards deliberate reasoning and you can tolerate longer outputs, slower review, and more verbose traces. It is not the low-friction default for every local conversation. It is the branch to test when the extra reasoning behavior is the point.
Use Qwen/Qwen3-Coder-30B-A3B-Instruct when the job is code. The Coder branch is the better first test for repository-scale work, tool calls, refactors, and long-context coding tasks because its owner materials frame it around agentic coding rather than general chat.
Use the original Qwen/Qwen3-30B-A3B when you need the April 2025 hybrid thinking/non-thinking model, old evaluation parity, or a baseline against earlier Qwen3 coverage. It is still a useful owner card, but it should not silently become your 2026 local default.
What A3B Means
The original Qwen3 announcement and the Qwen/Qwen3-30B-A3B model card describe a sparse mixture-of-experts model. The owner card records 30.5B total parameters, 3.3B activated parameters, 48 layers, 128 experts, and 8 active experts. That active-parameter shape is why the label looks attractive for local experiments: you get a larger total model footprint while only a smaller expert slice is active per token.
The label does not remove deployment tradeoffs. A sparse MoE can still be memory-heavy once you include the loaded weights, quantization choice, context length, KV cache, framework overhead, and batch size. That is why one universal RAM or VRAM number is the wrong mental model. A short 4-bit local chat and a long-context tool loop are not the same deployment.
The original card also records a different context boundary from the later branches: 32,768 native context and 131,072 with YaRN. The 2507 Instruct and Thinking cards record 262,144 native context, while the Coder card records 262,144 native context and a 1M-with-YaRN boundary. Put those rows in different buckets before you compare speed or quality.

Which Branch Should You Run?
Start with the branch that matches the cost of being wrong.
For everyday local instruction work, start with Instruct-2507. It is the cleanest default when the task is helpfully answering, summarizing, classifying, drafting, or following ordinary tool instructions. The key boundary is that it is not the thinking branch. If your evaluation prompt expects visible reasoning traces, you are testing the wrong lane.
For hard reasoning, test Thinking-2507 separately. It belongs in tasks where intermediate deliberation can improve the answer: multi-step math, puzzle-like reasoning, planning, adversarial review, or long document synthesis. The tradeoff is reviewer time and latency. A thinking model that produces better answers but doubles the review burden may still be a bad default for routine work.
For code, test Coder-30B-A3B before you treat the generic branch as a coding model. The Coder card and Qwen3-Coder materials are explicitly about coding and tool use. That does not guarantee your repository will pass more tests, but it gives you the right first branch to measure for repo search, refactor quality, edit locality, and tool-call discipline.
For old benchmarks or reproducibility, keep the original card. It is the right reference when you are comparing against April 2025 Qwen3 writeups, reproducing hybrid thinking/non-thinking behavior, or checking older quantized builds. It is not automatically the best branch for a fresh local setup.
For the newest Qwen route, keep the exact-model decision narrow. Qwen3.6-35B-A3B is a newer Qwen local/coding boundary with its own contract. If your real question is whether to test Qwen3.6 against Kimi or GLM, use the broader Qwen3.6 vs Kimi K2.6 vs GLM-5.1 route guide instead of stretching Qwen3-30B-A3B into a cross-model comparison.
Runtime Routes Are Not Fact Owners
Ollama, LM Studio, llama.cpp, vLLM, and SGLang are useful because they turn a model decision into a runnable local setup. They are not interchangeable with the upstream model cards. A runtime tag can hide quantization choices, defaults, prompt templates, context settings, or branch mapping. Before you compare quality, verify the upstream model ID and branch.
Ollama's qwen3:30b-a3b page is a good example of a convenience route: it gives local users a fast install path and a runtime label. Use it to get moving. Do not use it as the source of record for parameter counts, branch behavior, or context promises. Those facts belong to Qwen and Hugging Face owner pages.
The same rule applies to quantized builds and community packages. They can be exactly what you need for a given GPU, but once you change quantization, context, server, or prompt template, you are no longer evaluating only the model card. You are evaluating a deployment stack.
Hardware And Context Caveats
The useful hardware answer is conditional: memory pressure is a function of quantization, loaded weights, context length, KV cache, framework overhead, batch size, and concurrency. If someone gives you a single fixed VRAM number for every Qwen3-30B-A3B scenario, ask which branch, quantization, context, and runtime they tested.
For a quick local chat, you may care most about model load, short context speed, and whether the responses are good enough for your daily prompts. For a code agent, the bottleneck may be long context, repository files, tool-call loops, and repeated retries. For a reasoning task, the output length and review burden can matter as much as raw tokens per second.
A safe local pilot starts small. Use the same prompt and a realistic context budget before expanding context. Track memory pressure, latency, crash behavior, and whether the model degrades when the context becomes real. A model that looks excellent at short context can become the wrong default once your repository, logs, or tool outputs enter the window.
The Same-Task Pilot
Do not compare branches with different tasks. Choose five to ten real tasks you already understand, then run the same work through your current default and the candidate Qwen branch.

| Test row | Keep identical | What to record |
|---|---|---|
| Prompt | User task, system rules, output format | Whether the answer solves the task without extra repair |
| Context | Files, snippets, logs, token budget | Whether quality survives realistic context length |
| Tools | Same commands, tool permissions, retry policy | Tool-call accuracy and unnecessary action rate |
| Tests | Same unit tests, eval set, manual checks | Accepted diff, failed checks, hidden defects |
| Operations | Same hardware, runtime, quantization, batch | Latency, memory pressure, crashes, and recovery time |
Only switch defaults when the candidate branch beats or matches the current default on task completion, reviewer time, retry count, and operating cost. A faster model that needs more human correction is not faster. A smarter model that fails your runtime budget is not a better default.
Official Sources To Keep Open
Keep these source lanes separate when you maintain the article or your own internal model notes:
- Qwen's Qwen3 announcement explains the original family framing, open-weight MoE release, Apache 2.0 context, and model table.
- The
Qwen/Qwen3-30B-A3BHugging Face card owns the original model facts: parameters, experts, active experts, hybrid behavior, and original context boundary. - The Instruct-2507 and Thinking-2507 cards own the updated branch behavior and 262K native context rows.
- The Qwen3-Coder-30B-A3B card and Qwen3-Coder blog own the coding-agent branch framing.
- Ollama and other local runtimes own install convenience, not upstream model identity.
- Qwen3.6 material owns the successor boundary, not the exact Qwen3-30B-A3B decision.
That separation keeps the branch map useful after the next model release. When Qwen ships a new branch or a runtime changes a tag, update the affected row instead of rewriting the decision around hype.
FAQ
Is Qwen3-30B-A3B still worth running?
Yes, if the branch fits the job. Instruct-2507 is worth testing for compact local instruction work, Thinking-2507 for reasoning-heavy tasks, and Coder-30B-A3B for coding loops. The original branch is mainly for April 2025 reproduction and older comparisons.
Is A3B the same as a 3B model?
No. A3B refers to the activated-parameter slice in a sparse MoE design. The original owner card records 30.5B total parameters and 3.3B activated parameters. Deployment memory still depends on the full stack, not only the active-parameter label.
Should I use Instruct-2507 or Thinking-2507?
Use Instruct-2507 when you want fast, clean answers without thinking traces. Use Thinking-2507 when the problem is hard enough that deliberate reasoning is worth extra latency and review time.
Is Qwen3-Coder-30B-A3B the same model?
No. It is a related Coder branch. Test it first for repository-scale coding, tool use, and long-context code work, but do not cite it as if it were the original Qwen/Qwen3-30B-A3B card.
Can Ollama tell me which branch I am running?
Ollama can give you a practical local route, but you should still verify the upstream model ID, quantization, context setting, and prompt template. Runtime convenience is not the same thing as official source ownership.
How much VRAM do I need?
There is no honest single number for every setup. Quantization, context length, KV cache, framework overhead, batch size, and concurrency all change memory pressure. Start with the smallest realistic context and record memory behavior before you widen the window.
When should I look at Qwen3.6 instead?
Look at Qwen3.6-35B-A3B when your real job is the newer Qwen local/coding route rather than the exact Qwen3-30B-A3B branch decision. Keep that as a successor comparison, not as a silent replacement for this model ID.