
As of May 7, 2026, test GLM-5.1 first if your coding-agent workload needs long-horizon autonomous execution on the Z.AI route, test Kimi K2.6 first for cheap broad pilots and many attempts, and test Qwen3.6 first only after you choose the branch: Qwen3.6-35B-A3B for open-weight control or a hosted Plus, Flash, or Max Preview route for Alibaba experiments.
The catch is that Qwen3.6 is not one contract row. In this comparison it is a branch label, while kimi-k2.6 and glm-5.1 are the owner model IDs to verify against Moonshot/Kimi and Z.AI docs.
| First test route | Use it when | Verify before switching |
|---|---|---|
| GLM-5.1 | You need long-horizon autonomous coding, sustained context, and Z.AI route compatibility. | Confirm glm-5.1, context/output limits, tool behavior, and current pricing in Z.AI docs. |
| Kimi K2.6 | You need cheap broad pilots, many attempts, and Moonshot/Kimi or open-source optionality. | Confirm kimi-k2.6, pricing rows, hosted route, and whether open-weight terms fit your stack. |
| Qwen3.6 | You need Qwen-family control, local/open-weight experiments, or Alibaba-hosted branch tests. | Name the branch first: Qwen3.6-35B-A3B is not the same contract as Plus, Flash, or Max Preview. |
Stop rule: do not replace your current default until the same repo snapshot, prompt, tools, tests, and review rubric show equal or better task completion, retry cost, reviewer time, and hidden-defect rate.
The Fast Answer
GLM-5.1 is the first model to test when the job is a long autonomous coding loop: multi-step repository work, memory-heavy debugging, long context carryover, and tool use that must stay coherent for hours. Its official Z.AI route gives you a clear model ID, documented context/output boundaries, and a migration surface to measure.
Kimi K2.6 is the first model to test when you need broad, cheap exploration. It is the right early pilot for many candidate patches, UI variants, refactor attempts, or codebase-scanning tasks where one failed attempt is not costly and fast iteration matters.
Qwen3.6 is the first model to test only after you say which Qwen3.6 you mean. Qwen3.6-35B-A3B is the open-weight/control lane. Hosted Qwen3.6 Plus, Flash, or Max Preview are Alibaba-route experiments with different contracts. Mixing those rows makes the comparison look cleaner than it is.
What Qwen3.6 Means Here
Treat Qwen3.6 as a family label until the branch is named. The owner-supported Qwen3.6-35B-A3B material frames it as an open-source MoE coding-agent model, with 35B total parameters and 3B active parameters. The Hugging Face model card records an Apache-2.0 license and serving examples with a 262,144-token context setting. Those facts are useful for teams that care about local control, reproducible deployment, or branch-level experiments.
That does not mean every public Qwen3.6 comparison row is about Qwen3.6-35B-A3B. Some public comparisons discuss Qwen3.6 Plus, Flash, or Max Preview. Those hosted branches may be exactly what an Alibaba-route user needs, but they should not be silently merged into the open-weight row. If you are comparing against Kimi K2.6 and GLM-5.1 for coding-agent work, your first Qwen question is not "is Qwen better?" It is "which Qwen3.6 route are we testing?"
Official Contract Lanes
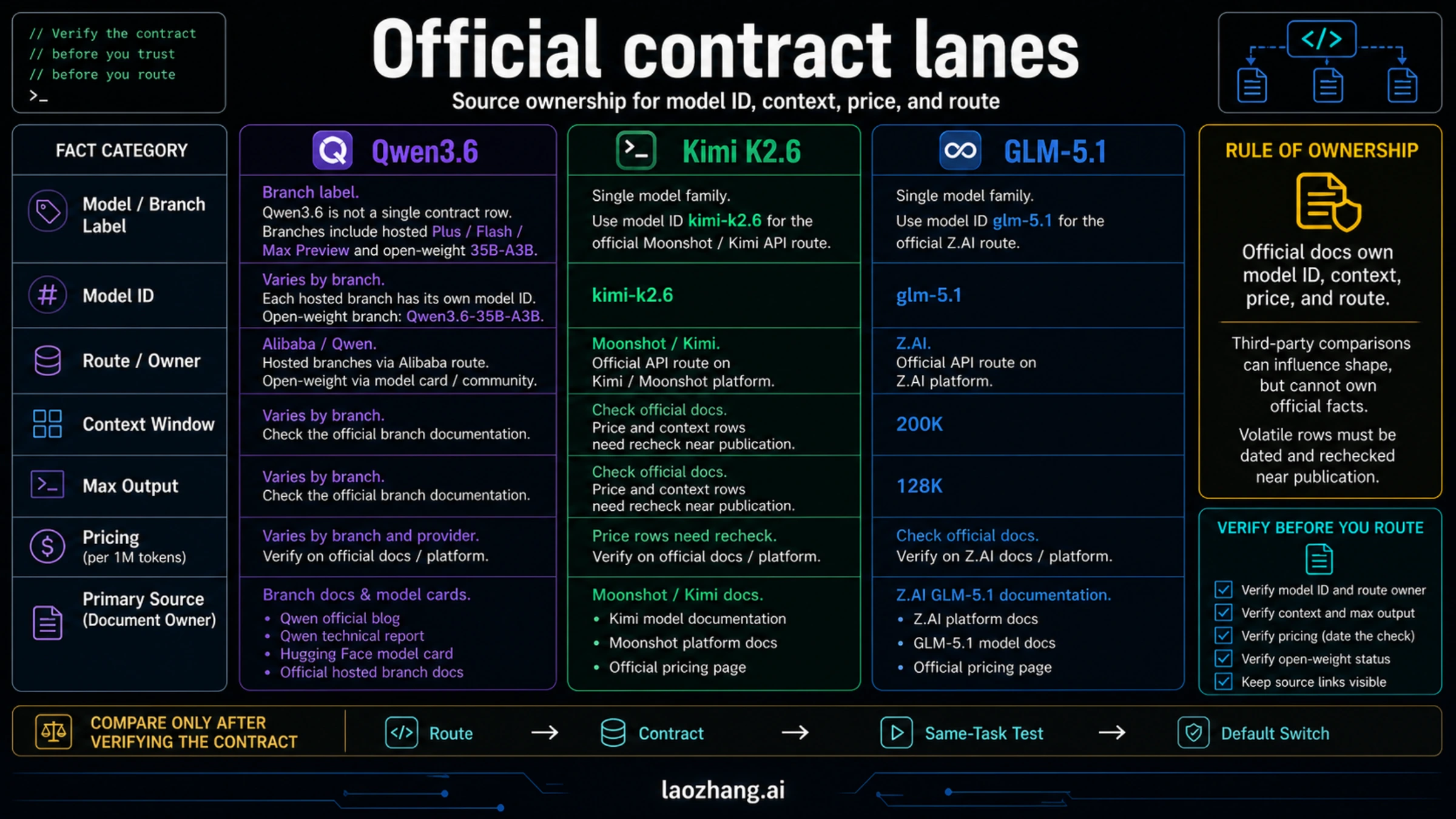
Official contracts keep the decision usable after the launch week. Checked on May 7, 2026, the owner rows were:
| Contract item | Qwen3.6 | Kimi K2.6 | GLM-5.1 |
|---|---|---|---|
| First owner to verify | Qwen official blog, Qwen model card, Alibaba-hosted branch docs | Moonshot/Kimi platform and Kimi model documentation | Z.AI GLM-5.1 docs, migration docs, and pricing docs |
| Deploy label | Qwen3.6-35B-A3B for the open-weight branch; hosted branch names must be named separately | kimi-k2.6 | glm-5.1 |
| Best first-test route | Local/open-weight control or Alibaba branch experiment | Cheap broad pilot through Moonshot/Kimi and Kimi surfaces | Long-horizon agent work through Z.AI route |
| Context/output boundary | Branch-dependent; Qwen3.6-35B-A3B model card includes 262,144-token serving examples | Verify current context and route behavior in Moonshot/Kimi docs | Z.AI docs list 200K context and 128K max output |
| Pricing owner | Hosted branch pricing is branch/provider-dependent; open-weight cost is your infrastructure cost | Platform row checked May 7: cache hit $0.16/MTok, input $0.95/MTok, output $4.00/MTok | Pricing row checked May 7: input $1.4, cached input $0.26, output $4.4 per 1M tokens |
| Open-weight boundary | Qwen3.6-35B-A3B is the open-weight lane | Kimi documentation claims open-source availability, but route, license, and self-host terms still need verification | Z.AI hosted route is the contract row here |
Use the official Qwen post and Hugging Face card for Qwen3.6-35B-A3B facts, the Kimi platform and Kimi model documentation for Kimi route facts, and Z.AI GLM-5.1 docs, migration docs, and pricing docs for GLM rows. Recheck pricing and availability before using any of these as a production default.
Coding-Agent Workload Fit

The workload split is clearer than a single benchmark score.
Use GLM-5.1 first for long-horizon autonomous coding. The route is strongest when the agent must keep a plan alive, retain context, recover from intermediate errors, and carry a large task across many steps. If your evaluation task is a multi-file migration, a large bug hunt, or a long context refactor, GLM-5.1 is the route to put against your current default early.
Use Kimi K2.6 first for broad pilot volume. It is useful when the team needs many attempts: front-end alternatives, scaffolding, routine implementation passes, A/B solution sketches, and low-risk code cleanup. The lower token row is a pilot advantage only if the accepted-task cost stays low after retries and review.
Use Qwen3.6 first for branch-specific control. Qwen3.6-35B-A3B belongs in tests where local deployment, open-weight access, reproducibility, or custom orchestration is the point. Hosted Qwen3.6 branches belong in Alibaba-route tests where the managed surface is part of the decision. Those are different first-test reasons.
The Same-Task Pilot

A model comparison becomes useful only when it turns into a repeatable test. Pick five to ten real tasks before you change defaults:
| Test task | Why it matters | What to record |
|---|---|---|
| Small bug fix | catches basic repo navigation and patch quality | accepted diff, test pass, reviewer edits |
| Multi-file refactor | tests context retention and dependency awareness | missed references, regression count, rollback risk |
| Test-writing task | exposes shallow implementation and assertion quality | useful tests, brittle tests, false confidence |
| Frontend/UI task | measures instruction following, structure, and visual judgment | layout defects, accessibility misses, manual cleanup |
| Ambiguous requirement | tests refusal to over-assume | questions asked, assumptions made, wrong turns avoided |
Run every route against the same repo snapshot, same prompt, same tools, same time budget, same tests, and same review rubric. Do not let a cheaper route win because it got easier tasks or looser review.
Set stop rules before the pilot starts. One blocker defect should prevent default promotion. Repeated tool-call drift should keep the route in experiment mode. Reviewer time above twice the current default usually means the model moved cost from tokens to people. A route that needs three retries for each accepted patch may still be useful, but it is not the new default.
When Each Route Should Not Be First
Do not start with GLM-5.1 if the task is a small cheap experiment and your team has no Z.AI route ready. Its long-horizon strengths are less important when the evaluation is a dozen tiny variants.
Do not start with Kimi K2.6 if the task is high-risk production migration where one hidden defect costs more than the entire model bill. Kimi can still enter the pilot pool, but it should not replace a trusted control from one good demo.
Do not start with Qwen3.6 if nobody can name the branch. A Qwen3.6 Flash result, a Qwen3.6 Max Preview result, and a Qwen3.6-35B-A3B local run are not interchangeable. The most important Qwen rule is simple: branch first, comparison second.
How This Fits Existing Comparison Pages
This tri-route decision is about Qwen3.6 family branch versus Kimi K2.6 versus GLM-5.1.
If your real question is whether Kimi K2.6 can replace a premium Claude default, use the existing Kimi K2.6 vs Claude Opus 4.7 guide. If your route set also includes DeepSeek V4, GPT-5.5, and Claude Opus 4.7, use the broader Kimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7 guide. Keeping those boundaries separate prevents the Qwen/Kimi/GLM decision from becoming another general-purpose leaderboard.
FAQ
Is Qwen3.6 one model?
No. In practical comparison work, Qwen3.6 is a branch label until you name the route. Qwen3.6-35B-A3B is the open-weight branch discussed in Qwen and Hugging Face materials. Hosted Plus, Flash, and Max Preview branches need their own route and pricing checks.
Is Kimi K2.6 cheaper than GLM-5.1?
The May 7, 2026 owner rows made Kimi K2.6 cheaper on listed input/output token price than GLM-5.1. That is a pilot advantage, not a default-switch verdict. Accepted-task cost still depends on retries, reviewer time, hidden defects, tool behavior, and wrapper billing.
Is GLM-5.1 better for coding agents?
GLM-5.1 is the first route to test when the coding-agent job is long-horizon, context-heavy, and aligned with Z.AI's route. It is not automatically the first route for cheap exploration, local control, or small routine tasks.
When should Qwen3.6 be tested first?
Test Qwen3.6 first when local control, open-weight deployment, Alibaba-route compatibility, or Qwen-family behavior is the decision. Name the branch before interpreting the result.
Can any of these replace my current default model?
Only after a same-task pilot. A replacement candidate must match or beat the current default on accepted diffs, test pass rate, hidden-defect severity, reviewer time, retry cost, tool reliability, and rollback risk.