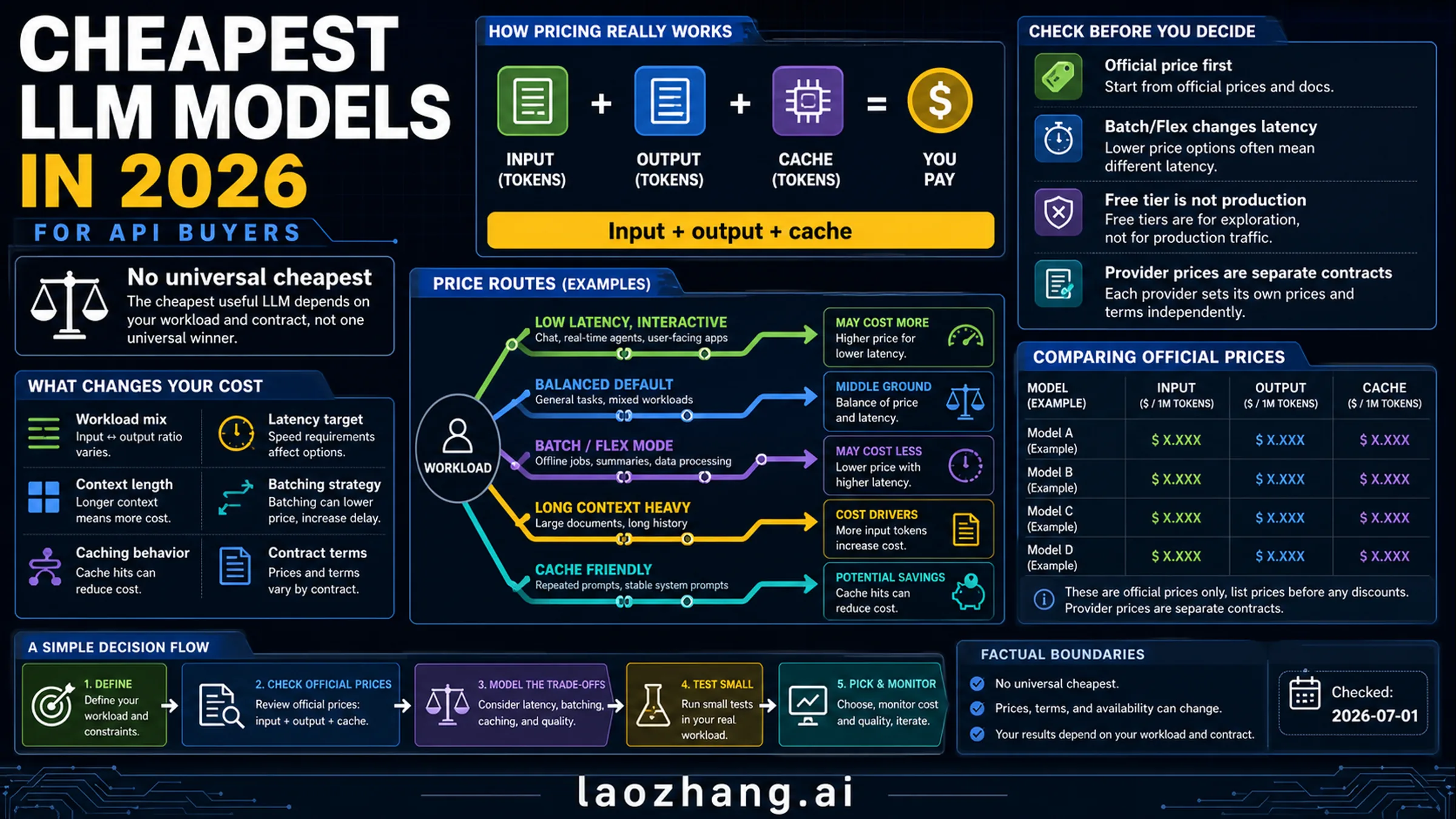
The cheapest LLM model is not one permanent winner; it is the lowest-cost model that still fits your prompt shape, output length, cache rate, privacy boundary, latency target, and quality floor. As checked on July 1, 2026, the first shortlist for API buyers starts with official model-owner prices, then adjusts for Batch/Flex terms, free-tier rules, provider contracts, retries, and accepted-output quality.
| If your workload looks like... | Start your check with... | Checked price anchor | When this row is not cheapest |
|---|---|---|---|
| cache-heavy bulk extraction or short answers | deepseek-v4-flash | $0.0028 cache-hit input, $0.14 cache-miss input, $0.28 output per 1M tokens | if quality, latency, region, or provider availability misses your bar |
| OpenAI ecosystem, cheap general API calls, or Batch/Flex work | gpt-5-nano | $0.05 input, $0.005 cached input, $0.40 output; Batch/Flex $0.025 input, $0.0025 cached input, $0.20 output per 1M tokens | if output length, tool calls, or quality reruns dominate |
| very small symmetric text jobs | ministral-3b-latest | $0.10 input and $0.10 output per 1M tokens | if the job needs stronger reasoning, coding, or long-context behavior |
| prototype exploration on Google routes | Gemini API free tier or gemini-3.1-flash-lite | paid gemini-3.1-flash-lite is $0.25 input and $1.50 output standard, with Batch/Flex $0.125 and $0.75 per 1M tokens | if free-tier data-use terms, quota, or output cost do not fit production |
| cheap models fail the quality floor | Claude Haiku 4.5 | $1 input and $5 output per MTok, with 50% Batch API discount | if acceptable output quality is already met by a lower-cost lane |
Stop rule: do not choose a model from an input-price row alone. Run your own prompt mix through input, cached input, output, tool calls, retries, latency, free-tier terms, and provider-contract checks before committing production spend.
The official price table to start from
Use official model-owner pages as the first source of truth, then recheck before spending. The rows below were checked on July 1, 2026 from OpenAI pricing, Google Gemini API pricing, DeepSeek pricing, Anthropic pricing, and Mistral pricing. Aggregators and gateways can be useful for discovery, but they are separate contracts.
| Official model-owner lane | Model row to check | Input | Cached input | Output | Discount or boundary |
|---|---|---|---|---|---|
| DeepSeek | deepseek-v4-flash | $0.14 cache miss | $0.0028 cache hit | $0.28 | Very cheap when cache hits and quality fits; DeepSeek notes users should regularly check the page |
| OpenAI | gpt-5-nano | $0.05 | $0.005 | $0.40 | Batch/Flex lowers it to $0.025 input, $0.0025 cached input, $0.20 output |
| OpenAI | gpt-5.4-nano | $0.20 | $0.02 | $1.25 | Use only if its capability or route beats the cheaper nano row for your workload |
| Mistral | ministral-3b-latest | $0.10 | not listed in this row | $0.10 | Symmetric small-model row; do not confuse classifier API pricing with general chat pricing |
gemini-3.1-flash-lite | $0.25 | route dependent | $1.50 | Batch/Flex is $0.125 input and $0.75 output; free tier is a separate prototype boundary | |
| Anthropic | Claude Haiku 4.5 | $1 | cache hit can be 0.1x base input | $5 | Batch API gives 50% off; use when quality or policy needs justify the higher token row |
Two practical facts fall out of the table. First, DeepSeek and OpenAI can be dramatically cheaper than Claude or Gemini on raw token rows for some text workloads. Second, output price, cache behavior, and quality reruns can flip the answer quickly. A model that is cheap for extraction can be expensive for long, verbose answers if it needs more retries or produces less acceptable output.
If the decision is mainly OpenAI versus Claude, keep a more detailed pairwise guide open: Claude API vs OpenAI API pricing. If caching is the main lever, compare prompt-cache economics separately with OpenAI vs Claude cache pricing.
The real cost formula
The useful price is the cost of accepted output, not the sticker price of one input token. A simple cost model should include at least:
textreal cost = input tokens + cached input tokens after actual cache-hit rate + output tokens + tool calls and route-specific add-ons + quality reruns and failed attempts + batch/flex latency tradeoff + region, tax, data residency, and contract terms

For extraction, the input side may dominate. For chat summaries or agent loops, output and retry behavior often dominate. For long-running workflows, tool calls, search add-ons, concurrency limits, and failure billing can matter more than the base model row. If you are running agents, a separate spend cap and kill switch is not optional; use the workflow in LLM agent API spend kill switch before scaling.
Normalize every candidate against the same workload sample. Use the same prompt set, the same input documents, the same max output, the same success criteria, and the same retry policy. Then calculate cost per accepted result. If Model A costs half as much per token but needs three attempts to meet the quality bar, Model B may be the cheaper production choice.
Best cheap first lane by workload
Start with one or two lanes, not ten. The table below is a first-test map, not a universal ranking.
| Workload | Cheap first lane | Why it is plausible | What to measure before you trust it |
|---|---|---|---|
| Bulk extraction from many records | deepseek-v4-flash, then gpt-5-nano | DeepSeek has the lowest checked cache-hit input row and a low output row; OpenAI nano has a very low standard input row | extraction accuracy, schema validity, retry rate, latency at volume |
| Short summarization | gpt-5-nano, deepseek-v4-flash, or ministral-3b-latest | all three have low entry rows, and output length can be controlled | summary faithfulness, max output, hallucinated facts, cache hit rate |
| Coding help and snippets | test DeepSeek, OpenAI nano, and Mistral small lanes | raw price is low enough to run same-prompt samples | compile/test pass rate, reasoning gaps, longer output cost |
| Agentic workflows | start cheap but cap spend | repeated calls magnify retries, tool calls, and output tokens | p50/p95 latency, tool-call cost, runaway-loop protection |
| Long-context analysis | check DeepSeek context and Gemini/Claude quality lanes | context length and quality may outweigh sticker price | context failures, quote fidelity, latency, data terms |
| Free or prototype exploration | Gemini API free tier, then paid route if it passes | free tier can reduce exploration cost | quota, terms, whether submitted content may be used to improve products |
| Quality-critical output | Claude Haiku 4.5 or a stronger paid model after cheap lanes fail | a higher token row can be cheaper than repeated bad cheap outputs | acceptance rate, policy fit, support owner, data residency |

The most common mistake is to treat "best cheap model" as a personality contest. Make it a workload test. For each lane, store the prompt, input size, output size, latency, retry count, and pass/fail reason. After 20 to 50 representative calls, the cheapest lane will usually become obvious. If it does not, the right answer may be routing by workload instead of picking one model for everything.
Free tier is not production pricing
Free access is valuable for learning a route, testing prompts, or building a prototype, but it is not the same as a production contract. The Google Gemini API pricing page separates free and paid tiers and notes a data-use difference: free-tier submitted content can be used to improve products, while paid-tier content is not used that way. That is not a small footnote if your prompts contain customer data, source code, logs, contracts, or private documents.
Treat free-tier testing as a proof of fit, not a cost model. Before you ship, check quota, rate limits, data-use terms, billing enablement, paid price rows, Batch/Flex availability, and support expectations. A free path that works for ten manual calls can still fail a production queue.
Provider and gateway prices are separate contracts
Provider, gateway, and aggregator rows can be useful. They can expose many models behind one API, smooth migration, add logs, offer OpenAI-compatible endpoints, or quote provider-owned prices that differ from official model-owner pages. The mistake is to relabel those rows as official OpenAI, Google, Anthropic, DeepSeek, or Mistral prices.
Use this separation:
| Price owner | What it can prove | What it cannot prove |
|---|---|---|
| Official model-owner page | official model row, billing unit, discount mode, model availability, current caveats | third-party gateway fee, gateway uptime, wrapper support, reseller refund policy |
| Gateway or aggregator | its own route, model list, price metadata, routing behavior, logs, support owner | official vendor price unless the vendor page agrees |
| Forum, Reddit, benchmark, or screenshot | reader pain, route ambiguity, possible routes to inspect | current price, production reliability, legal terms, or availability |
If a provider quote looks cheaper than the official row, verify the exact model ID, billing unit, cache behavior, failed-call billing, rate limits, refund rules, and support owner. Then run a small same-prompt test. A cheap wrapper is useful only if the accepted-output cost and operational boundary are better for your workload.
Verification checklist before spend
Use this checklist before moving production traffic:
- Verify the official model ID on the model-owner page.
- Record input, cached input, output, and Batch/Flex rows with the date checked.
- Run representative prompts, not toy prompts.
- Measure p50 and p95 latency at expected concurrency.
- Count retries, refusals, malformed outputs, and tool calls.
- Confirm free-tier terms and paid-tier data-use boundaries.
- Keep provider or gateway contract terms separate from official price rows.
- Recheck prices, model names, and availability before launch.
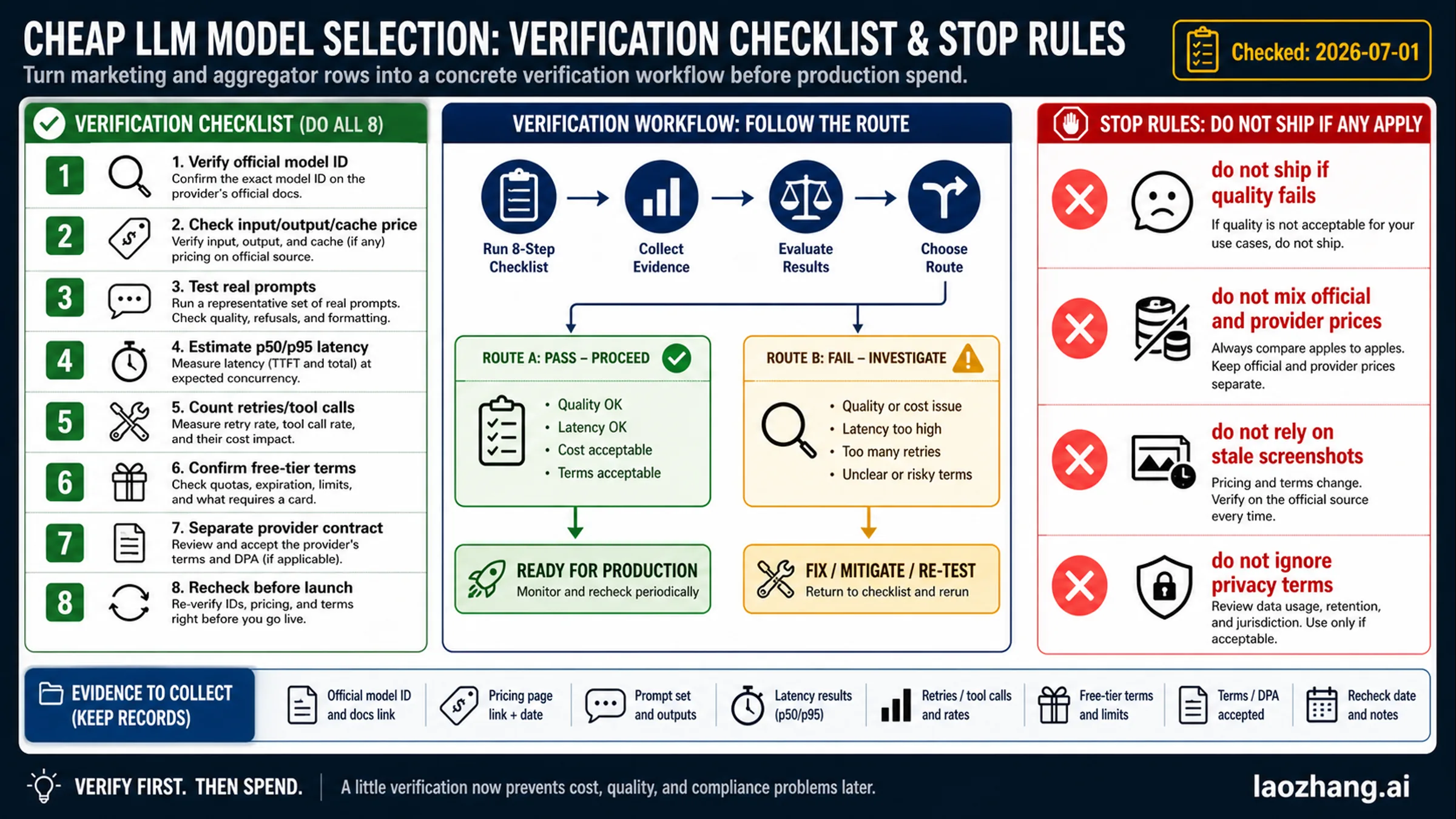
There are also hard stop rules. Do not ship if the cheap lane misses your quality bar, if you cannot separate official and provider prices, if your evidence is a stale screenshot, or if the privacy terms do not fit the data you send. Cheap but wrong output is not cheap. Cheap but unclear contract ownership is not production-ready.
Recommended starting choices
For the lowest raw official paid token floor in this run, start with deepseek-v4-flash, especially when cache hits are realistic and output is short. For a low-cost OpenAI route, start with gpt-5-nano, then check Batch/Flex if offline latency is acceptable. For very small symmetric text tasks, test ministral-3b-latest. For Google ecosystem prototyping, use the Gemini free tier carefully and move to paid terms before real data or production traffic. For quality-sensitive tasks, include Claude Haiku 4.5 even though it is not the cheapest token row.
The final pick should be the model with the lowest cost per accepted result under your real prompt mix. If the result differs from a public cheapest-model ranking, trust your measured workload.
FAQ
What is the cheapest LLM model right now?
There is no universal winner. Checked on July 1, 2026, deepseek-v4-flash has the lowest official cache-hit input row in this run, while gpt-5-nano has a very low OpenAI standard input row and useful Batch/Flex discounts. The cheapest useful choice still depends on output length, cache hit rate, quality, latency, and contract terms.
Is DeepSeek always the cheapest LLM?
No. DeepSeek can be extremely cheap for cache-heavy or short-output workloads, but a low row is not a guarantee. If quality misses, latency is unacceptable, a route is unavailable, or the workload produces long outputs and retries, another model may be cheaper per accepted result.
Are free LLM APIs good enough for production?
Usually treat them as prototype routes first. Free tiers can be useful for experiments, but production use needs quota, rate limit, data-use, support, billing, and availability checks. Google Gemini's free tier is especially important to separate from paid-tier data-use terms.
Which cheap LLM model should I use for coding?
Start with the cheapest lanes that can pass your actual tests: DeepSeek, OpenAI nano, and Mistral small rows are reasonable first checks, then compare compile/test pass rate, output length, and retry count. If cheap outputs need repeated repair, a higher-quality lane can become cheaper.
Is Claude too expensive for cheap LLM selection?
Claude Haiku 4.5 is not the cheapest token row in this comparison, but it can still be cost-effective when quality, policy fit, or lower rerun rate matters. Use it as a quality-floor lane, not as the default cheapest-token lane.
Should I trust LLM price comparison aggregators?
Use them for discovery, not final proof. Before purchase or migration, confirm model ID, price unit, cache behavior, output price, discount mode, and contract owner on the official or provider page that will bill you.