There is no single cheaper answer for Claude API vs OpenAI API pricing. If your workload is high-volume, short-context, and can use OpenAI's cheaper GPT-5.4 mini row, OpenAI usually starts lower. If the job needs long-context reasoning, agentic coding, high cache reuse, or Claude-specific tool behavior, Claude can be the better total-cost route even when one row looks more expensive.
Checked on May 2, 2026: OpenAI's pricing page lists GPT-5.5 at $5 input, $0.50 cached input, and $30 output per 1M tokens, GPT-5.4 at $2.50 / $0.25 / $15, and GPT-5.4 mini at $0.75 / $0.075 / $4.50. OpenAI's GPT-5.5 launch note was updated on April 24, 2026 to say GPT-5.5 and GPT-5.5 Pro are now available in the API, but production comparisons should still verify whether the model is enabled in the account before using it as the default row. Anthropic's pricing page lists Claude Opus 4.7 at $5 input and $25 output, Claude Sonnet 4.6 at $3 and $15, and Claude Haiku 4.5 at $1 and $5 per 1M tokens, with separate cache, batch, data-residency, long-context, and tool-use mechanics.
Fast Answer: Pick The Workload Before The Provider
| Workload | Cheaper first model to test | Why |
|---|---|---|
| Simple chat, classification, extraction, short summaries | OpenAI GPT-5.4 mini | The base row is lower than Claude Haiku 4.5, and cached input is also low. |
| Complex coding or professional reasoning where GPT-5.5 is enabled | Test GPT-5.5 and Claude Opus 4.7 side by side | GPT-5.5 has higher output price than Opus 4.7, but model efficiency and retries can flip the result. |
| Long-context analysis with hundreds of thousands of tokens | Claude Opus 4.7 or Sonnet 4.6 deserves a serious test | Anthropic documents full 1M context for Opus 4.7, Opus 4.6, and Sonnet 4.6 at standard pricing. |
| Large offline summarization or evaluation | Either provider through batch mode | OpenAI and Anthropic both expose 50% batch-style savings, so latency tolerance matters. |
| Heavy system prompts, stable tools, repeated RAG context | Compare cache hit rate, not only list price | Anthropic cache hits are 0.1x base input after the write; OpenAI cached input rows are also discounted. |
| Tool chains, image work, code execution, web search | Price the tool surface separately | Tool calls add tokens or usage charges that can dominate the base model row. |
Current Price Rows To Anchor The Math

Use the official rows as anchors, not as the final answer. A simple row comparison says OpenAI GPT-5.4 mini is cheaper than Claude Haiku 4.5 for both input and output. The Sonnet 4.6 versus GPT-5.4 comparison is closer: OpenAI is lower on input and equal on output. The Opus 4.7 versus GPT-5.5 comparison is not a one-way OpenAI win: the listed input price is the same, while Claude Opus 4.7 output is lower than the GPT-5.5 row.
That does not mean Claude is always cheaper for frontier work. It means you should run scenario math. GPT-5.5 may need fewer attempts for some OpenAI-native jobs; Claude may handle long context or coding-agent flows with fewer retries in other jobs. The cost that matters is successful output per task, not price per million tokens in isolation.
OpenAI's pricing page also states that the flagship standard rows are for context under 270K. Anthropic's pricing page says Opus 4.7, Opus 4.6, and Sonnet 4.6 include the full 1M token context window at standard pricing, while Opus 4.7's tokenizer may use up to 35% more tokens for the same fixed text. That tokenizer note is exactly why direct "same document length equals same input cost" comparisons can be wrong.
Cache And Batch Change The Winner
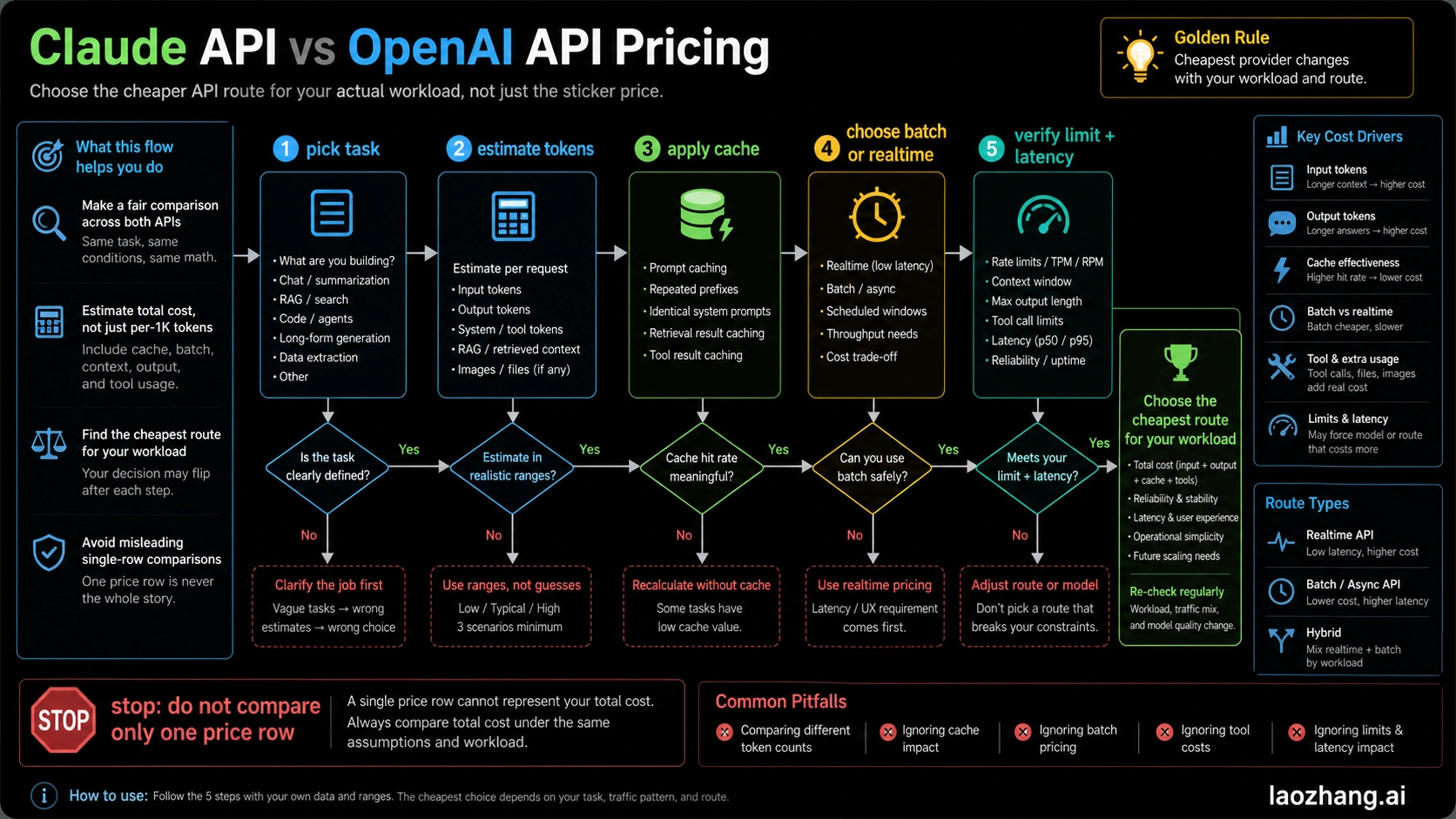
Caching can turn an expensive-looking model into a cheaper route when most of the input is stable. Anthropic prices 5-minute cache writes at 1.25x base input, 1-hour cache writes at 2x, and cache hits at 0.1x base input. OpenAI publishes cached-input rows for its current flagship models. If your system prompt, tool schema, policy pack, or RAG context repeats, estimate the first request and the cache-hit requests separately.
Batch is the other major lever. OpenAI says the Batch API saves 50% on inputs and outputs for asynchronous jobs over 24 hours. Anthropic's pricing page lists a 50% batch discount on both input and output tokens. For non-urgent summarization, evaluation, classification, migration QA, and data cleanup, the correct question is not only "Claude or OpenAI?" It is "Can this run asynchronously?"
When OpenAI Is The Cheaper Default
OpenAI is the default cost test when the work is high-volume, short-context, and tolerant of a smaller model. Classification, extraction, short customer-support drafts, title generation, simple summarization, and structured transformations should start with GPT-5.4 mini before a frontier model enters the spreadsheet.
OpenAI also becomes attractive when cached input rows and Batch API discounts line up with the workload. If the app sends short prompts, produces short outputs, and rarely needs long context, the lower mini row is hard to beat. If GPT-5.5 is not enabled in your API account yet, do not force it into production math; compare the available GPT-5.4 family against Claude's current rows.
When Claude Can Be The Better Spend
Claude becomes more compelling when context, tool behavior, or completion quality reduces total attempts. Long codebases, long research packets, contract review, multi-file refactors, agent loops, and large document analysis can make "cheapest per token" a weak proxy.
Anthropic's current pricing page also makes cache and long-context math explicit. If a workflow reuses a large context many times, cache-hit economics can matter more than the base input row. If the workflow is near 1M tokens, Claude's standard long-context note is part of the decision. If the same fixed text tokenizes differently on Opus 4.7, measure with the real tokenizer before trusting a word-count estimate.
Build A Fair Scenario Calculator
Use this formula for each candidate route:
| Cost unit | What to measure |
|---|---|
| Input tokens | Prompt, system text, RAG chunks, tool schemas, files, images represented as tokens |
| Output tokens | Final answer, JSON, code, reasoning-heavy reply, intermediate summaries |
| Cached input | How many tokens are written once and then read repeatedly |
| Batch discount | Whether the job can wait and whether the endpoint supports the required feature |
| Tool charges | Web search, code execution, image generation, file tools, or server-side tools |
| Retry rate | Failed calls, low-quality attempts, truncation, or manual reruns |
| Route premium | Data residency, regional endpoint, priority, or fast mode multipliers |
Run three cases: low, typical, and high output length. Then rerun after enabling cache. Then rerun after batch. The provider that wins all three is a safe default. If the winner flips, route by workload instead of forcing one vendor into every request.
Verification Checklist Before You Deploy
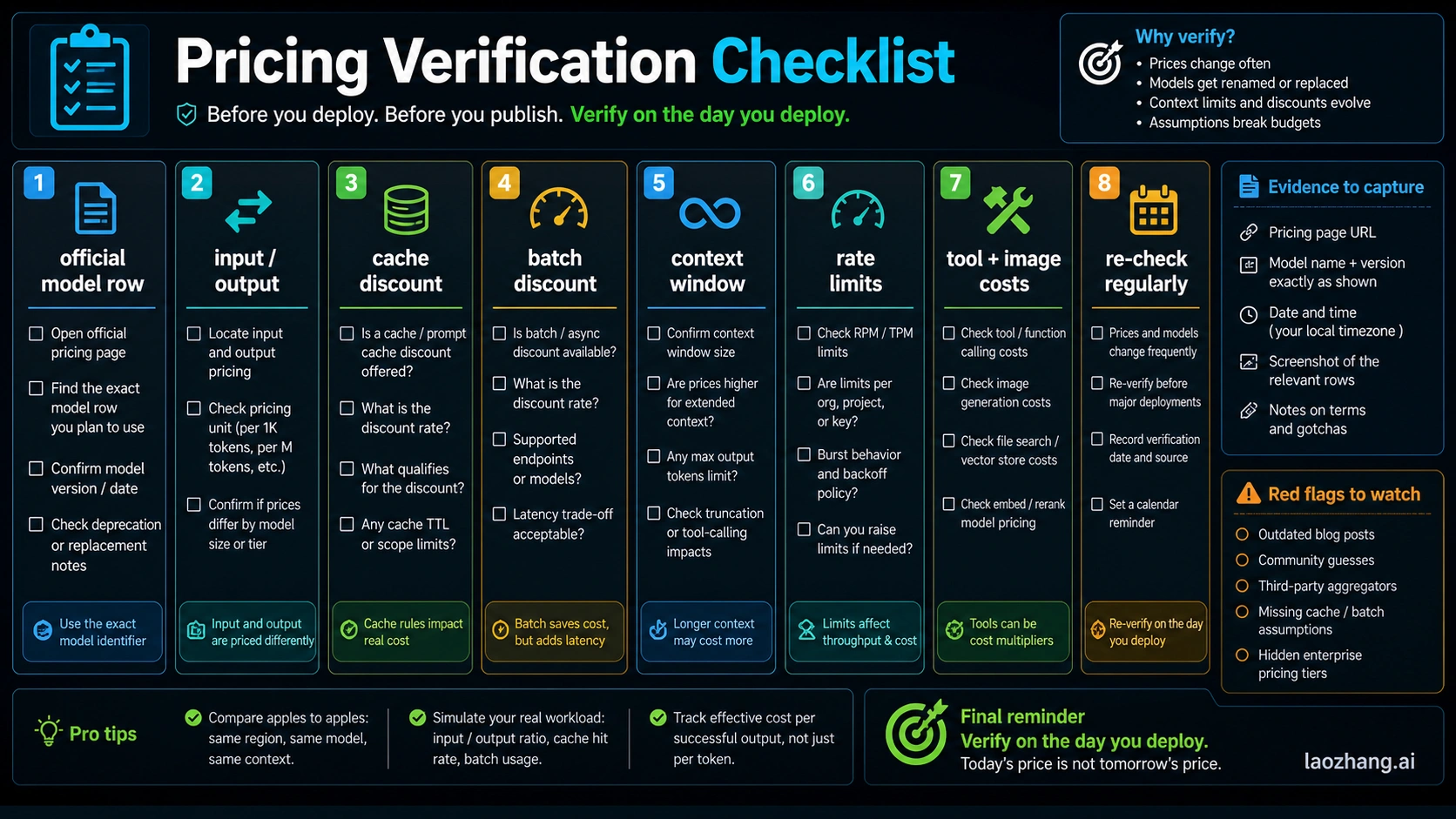
Before shipping, verify the exact official model row, model access in your account, input and output prices, cache rules, batch support, context limits, rate limits, data-residency or regional premiums, and tool-specific charges. Do this on the day you deploy because pricing pages, model names, availability, and account limits change faster than old comparison posts.
Use OpenAI API pricing, OpenAI GPT-5.5 availability notes, and Anthropic Claude pricing as the first-party anchors. Treat Reddit, calculators, and FinOps blogs as useful scenario inspiration, not as pricing authority.
FAQ
Is Claude API or OpenAI API cheaper?
OpenAI is usually cheaper for simple high-volume workloads that fit GPT-5.4 mini. Claude can be cheaper or better value for long-context, agentic, cache-heavy, or fewer-retry workflows. The answer changes with model access, cache hit rate, output length, batch mode, and tools.
Should I compare GPT-5.5 directly with Claude Opus 4.7?
Yes, but date-bound it. OpenAI lists GPT-5.5 pricing and the April 24 launch-note update says GPT-5.5 is now available in the API, while Anthropic lists Opus 4.7 as a current Claude API row. If your OpenAI account does not expose GPT-5.5 yet, compare GPT-5.4 or GPT-5.4 mini instead.
Does batch pricing make both APIs half price?
For the documented batch paths, both providers advertise 50% savings on input and output tokens. Batch only helps when the workload can wait and the needed features are supported in that batch route.
Does cache always save money?
No. Cache saves money when the same large content is reused. A one-off prompt can become more expensive if it pays a cache write and never gets a read. Calculate first write and repeated reads separately.
What is the safest rule for a production team?
Start with the cheapest model that passes quality, measure real input and output, add cache and batch where valid, and keep a second provider tested for workloads where the first provider's cost or quality fails.