
OpenAI and Claude do not bill cached context through the same accounting model. OpenAI reports cache hits as cached input tokens at the model's cached-input rate, while Claude separates the first cache write from later cache reads. That means a repeated system prompt, tool schema, file pack, or agent history should be priced as token classes, not as one generic "cache discount." Before you budget a repeated-context workflow, verify the provider usage fields that prove which tokens were full input, cached input, cache creation, cache read, or output.
Checked on May 19, 2026: OpenAI prompt caching is automatic for eligible API requests, starts at a 1,024-token prompt prefix, exposes usage.prompt_tokens_details.cached_tokens, and OpenAI's API pricing lists model-specific cached-input rows such as GPT-5.5 at $5 input, $0.50 cached input, and $30 output per 1M tokens. Claude prompt caching supports 5-minute and 1-hour cache durations; Anthropic prices 5-minute writes at 1.25x base input, 1-hour writes at 2x, and cache reads at 0.1x. Claude Code SDK cost fields are useful estimates, but authoritative billing proof lives in Claude Console or the Usage and Cost API.
Fast Answer
| Question | OpenAI | Claude |
|---|---|---|
| What is the cache hit line item? | Cached input tokens. | Cache read input tokens. |
| What happens on the first reusable prefix? | The first qualifying request is normally billed as input; later matching prefixes can be billed at the cached-input rate. | The first cached block is a cache write, billed above base input depending on TTL. |
| What field proves the hit? | usage.prompt_tokens_details.cached_tokens. | cache_creation_input_tokens and cache_read_input_tokens. |
| What can make the math wrong? | Assuming every repeated prompt is cache-eligible or that extended retention changes pricing. | Forgetting write cost, choosing 1-hour TTL without enough reads, or treating SDK estimates as invoices. |
| Best first action | Keep stable prompt prefixes identical and inspect cached_tokens. | Count writes and reads separately, then choose 5-minute or 1-hour TTL from reuse behavior. |
Use OpenAI cache pricing when your main question is "how many repeated prefix tokens were billed at the cached-input row?" Use Claude cache pricing when your main question is "how many tokens did I pay to write into cache, and how many later requests read from it?" The difference matters most for long system prompts, stable tool schemas, repeated file context, RAG preambles, and agent sessions that reuse the same instruction pack.
For broad provider price rows, use the separate Claude API vs OpenAI API pricing guide. For cache accounting, stay with the token-class ledger below.
Cache Billing Vocabulary
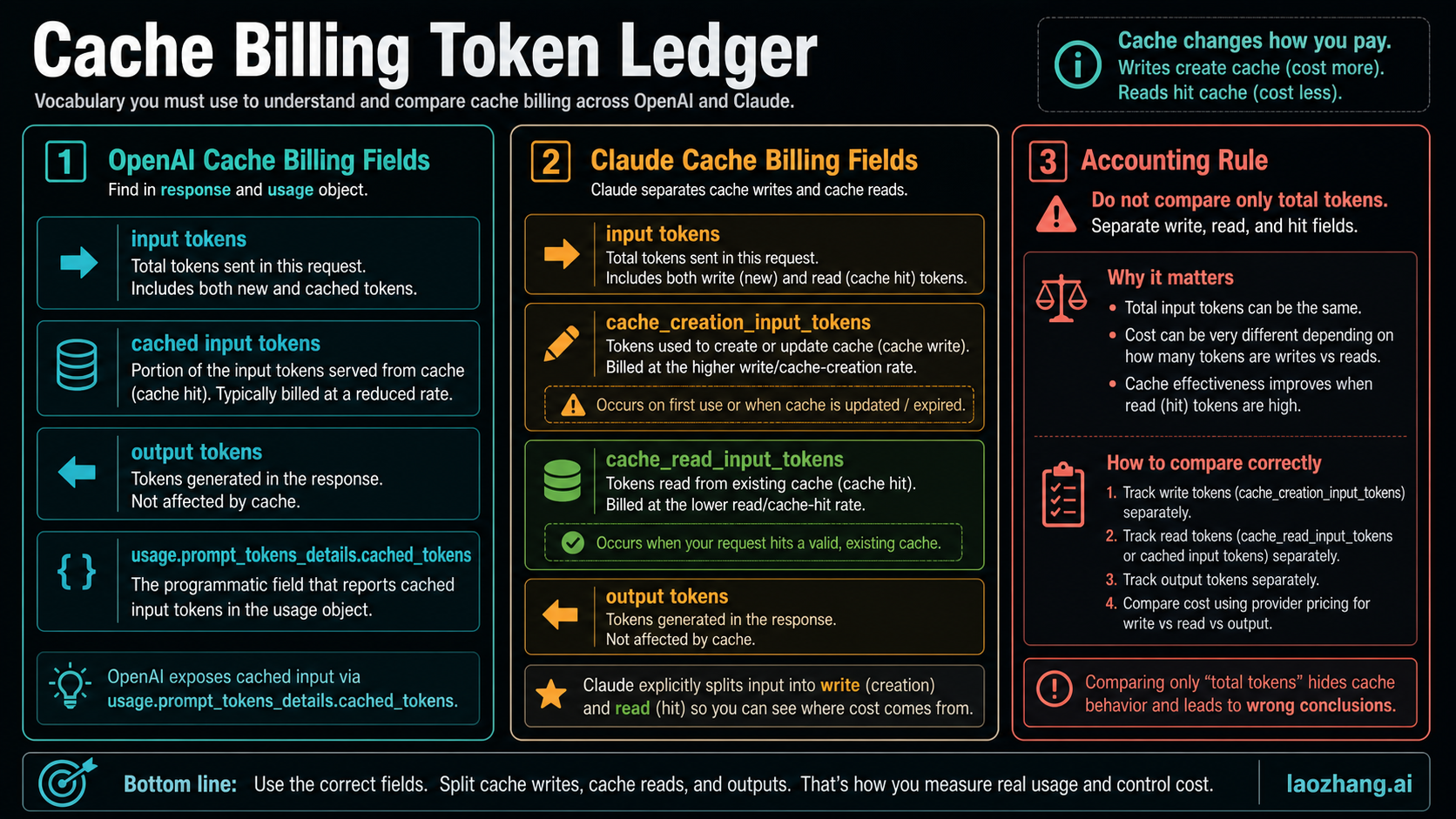
The safest vocabulary is provider-specific.
| Token class | Meaning | Why it matters |
|---|---|---|
| Full input tokens | Prompt tokens billed at the normal input price. | The first request, cache misses, dynamic suffixes, and non-cacheable content can land here. |
| OpenAI cached input tokens | Tokens from a repeated prompt prefix billed at the model's cached-input price. | They are cheaper than regular input, but still billed. |
| Claude cache creation or cache write tokens | Tokens written into Claude's prompt cache. | They can cost more than base input on the write request. |
| Claude cache read tokens | Tokens read from a previously written cache entry. | They are the cheap phase of the Claude cache model. |
| Output tokens | Generated completion tokens. | Prompt caching does not make output free. |
Do not compare OpenAI and Claude by total prompt tokens alone. A 100,000-token repeated prefix can be "100,000 prompt tokens" in both logs, but the bill depends on whether those tokens are full input, cached input, cache creation, or cache read.
OpenAI: Cached Input Is A Discounted Input Row
OpenAI's model is the simpler one to explain: eligible repeated prompt prefixes can be served from cache and billed as cached input. The prompt caching guide says caching is automatic, works best when static content appears at the beginning of the prompt and variable content appears later, and reports cache hits through usage.prompt_tokens_details.cached_tokens.
The current pricing page is model-specific. On May 19, 2026, representative standard short-context rows include:
| OpenAI model row | Input | Cached input | Output |
|---|---|---|---|
| GPT-5.5 | $5.00 / 1M tokens | $0.50 / 1M tokens | $30.00 / 1M tokens |
| GPT-5.4 | $2.50 / 1M tokens | $0.25 / 1M tokens | $15.00 / 1M tokens |
| GPT-5.4 mini | $0.75 / 1M tokens | $0.075 / 1M tokens | $4.50 / 1M tokens |
The operational rule is straightforward: keep the repeated prefix stable. Put system instructions, tool schemas, policy packs, and reusable context before the changing user request. If your application keeps moving the static content, rewriting tool schemas, or inserting variable metadata before the reusable block, you can lose cache hits and the invoice will look like normal input.
OpenAI also documents default cache retention after inactivity and extended retention for supported models, but the key billing rule is still the same: price the hit at the model's cached-input row and verify it in the usage object.
Claude: The First Cache Write And Later Reads Are Separate
Claude's cache model is more expressive and easier to misread. Anthropic documents both automatic caching and explicit cache control. The pricing rule is not "cached tokens are simply cheaper." It is:
| Claude cache action | Billing rule |
|---|---|
| 5-minute cache write | 1.25x base input price |
| 1-hour cache write | 2x base input price |
| Cache read | 0.1x base input price |
For example, Anthropic's Sonnet 4.6 row on May 19, 2026 lists $3 base input, $3.75 for a 5-minute cache write, $6 for a 1-hour cache write, $0.30 for a cache read, and $15 output per million tokens. The first cached request can therefore cost more than an uncached request. The saving appears only when later requests read enough cached tokens before the entry expires.
This is why the TTL decision belongs in the budget. A 1-hour cache write is not automatically better because it lasts longer. It is better only when your reuse window actually needs that hour and generates enough reads to justify the higher write cost.
Worked Example: A 100K-Token Repeated Prefix
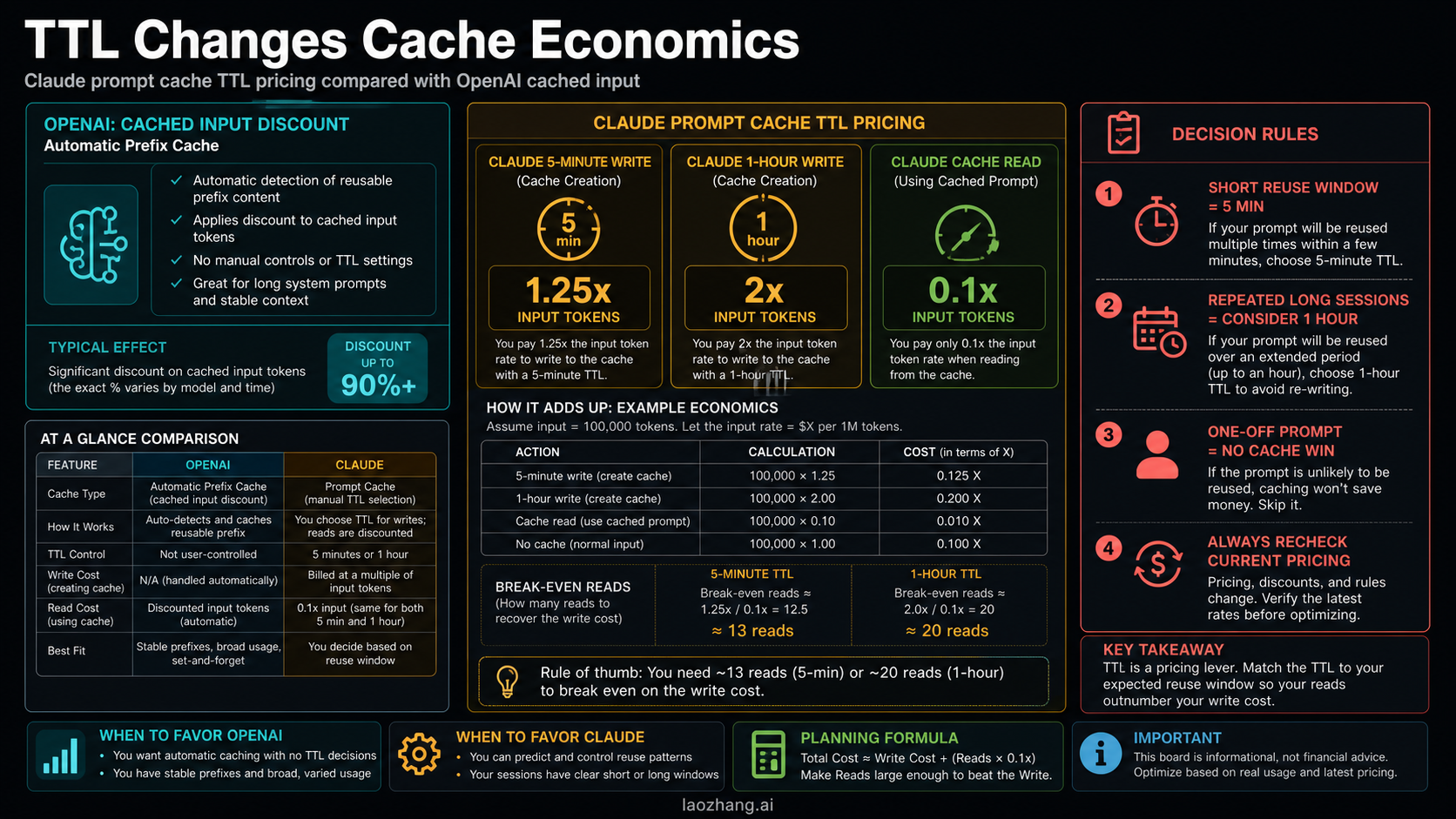
Assume the same 100,000-token static prefix is reused across five requests. Ignore output tokens and dynamic suffixes for the moment so the cache math is visible.
| Scenario | First request | Four later requests | Total input-side cache cost | Same five requests with no cache |
|---|---|---|---|---|
| OpenAI GPT-5.5 cached input | 0.1M x $5.00 = $0.50 | 4 x 0.1M x $0.50 = $0.20 | $0.70 | $2.50 |
| OpenAI GPT-5.4 cached input | 0.1M x $2.50 = $0.25 | 4 x 0.1M x $0.25 = $0.10 | $0.35 | $1.25 |
| Claude Sonnet 4.6, 5-minute cache | 0.1M x $3.75 = $0.375 | 4 x 0.1M x $0.30 = $0.12 | $0.495 | $1.50 |
| Claude Sonnet 4.6, 1-hour cache | 0.1M x $6.00 = $0.60 | 4 x 0.1M x $0.30 = $0.12 | $0.72 | $1.50 |
This example shows three practical points.
First, OpenAI cache hits are easy to explain once the hit appears in cached_tokens: repeated prefix tokens move from the regular input row to the cached-input row. Second, Claude's first cached call is a write, not a read, so the first call alone is more expensive than uncached input. Third, Claude's 1-hour cache can still be cheaper than no cache over repeated reads, but it is worse than the 5-minute cache when the shorter retention window already covers the session.
The exact answer changes with model, output length, dynamic prompt size, TTL, cache hit rate, and current provider prices. The shape of the math does not change: split the first write from later reads.
Audit Your Logs Before You Trust The Estimate

Use this checklist before you publish a budget, customer-facing price, or internal routing rule.
| Step | What to check | Acceptable proof |
|---|---|---|
| 1 | Current official price row | Provider pricing page on the deployment date. |
| 2 | OpenAI cache hits | usage.prompt_tokens_details.cached_tokens in real responses or exports. |
| 3 | Claude cache writes | cache_creation_input_tokens in usage records. |
| 4 | Claude cache reads | cache_read_input_tokens in usage records. |
| 5 | Output tokens | Provider usage fields, not a local word-count estimate. |
| 6 | Authoritative bill | OpenAI billing/usage surfaces or Claude Console / Usage and Cost API. |
| 7 | Route owner | API billing, SDK estimate, app subscription, and third-party gateway are separate contracts. |
The route owner point matters for agent workflows. Claude Code and SDK reports can expose helpful total_cost_usd or costUSD style estimates, but Anthropic's Agent SDK cost-tracking docs caution that these are client-side estimates. Use them for local monitoring; use Claude Console or the Usage and Cost API for billing proof.
If your team mixes Claude subscription use, API keys, and Console credits, keep that diagnosis separate from cache pricing. The Claude Code API key vs subscription billing guide covers the route split.
Keep Cacheable Content Stable
Prompt caching is an engineering contract as much as a pricing feature. The cache can only help when enough of the prompt stays identical and appears in the right place.
Use these design rules:
- Put stable system instructions before changing user instructions.
- Keep tool schemas, function descriptions, and policy blocks byte-stable when possible.
- Append request-specific variables after the reusable prefix.
- Avoid adding timestamps, request IDs, user names, or random metadata before the reusable block.
- Measure cache hit rate in production traffic, not only in a single local test.
- Use Claude's 1-hour TTL only when the session cadence actually needs it.
- Recheck price rows before using cached-token math in sales decks, customer invoices, or routing rules.
For OpenAI, the common failure mode is assuming a long prompt is cached just because it repeats conceptually. The prefix has to match in the way the cache system can recognize. For Claude, the common failure mode is seeing cheap cache reads and forgetting the earlier write premium.
When Cache Pricing Should Change Your Provider Choice
Cache pricing can flip a provider decision when the application sends a large, stable prefix many times: codebase maps, policy packs, long RAG context, reusable document sets, tool schemas, or agent memory. It is less important when the app sends short one-off prompts or when most of the input changes every call.
Choose the provider or route by the job:
| Workload | Cache-pricing implication |
|---|---|
| Repeated long system prompt with many short tasks | OpenAI cached input and Claude cache reads both deserve a test. |
| Multi-turn agent session with large stable context | Claude 5-minute or 1-hour TTL can matter, but only if reads are real. |
| One-off document analysis | Cache may add little or no value; price the normal input and output. |
| API gateway or reseller route | Verify the gateway's own cache policy and billing fields; do not assume first-party semantics. |
| Subscription app usage | Do not translate API token math directly into subscription limits or local estimates. |
The winning provider is not the one with the loudest cached-token discount. It is the route whose cache behavior matches your reuse pattern and whose billing evidence you can audit.
FAQ
Are cached tokens free on OpenAI or Claude?
No. OpenAI cached input tokens are billed at the model's cached-input rate. Claude cache reads are billed at 0.1x base input, and cache writes can cost 1.25x or 2x base input depending on TTL.
Does OpenAI charge a separate cache write fee?
Not in the same way Claude does. OpenAI reports cached input tokens and charges the model's cached-input row for hits. The first qualifying prompt still needs to be sent and billed as input before future matching prefixes can hit cache.
Why can a Claude cached request cost more than uncached input?
The write request can be billed at 1.25x base input for the 5-minute cache or 2x for the 1-hour cache. The saving comes from later cache reads at 0.1x, not from the first write.
When is Claude's 1-hour cache worth it?
Use 1-hour TTL when repeated requests need a reuse window longer than the default 5-minute cache and enough reads will occur before expiry. If the workload completes within five minutes, the shorter cache usually has better economics.
Which usage fields should I log?
For OpenAI, log usage.prompt_tokens_details.cached_tokens alongside total prompt and output tokens. For Claude, log cache_creation_input_tokens, cache_read_input_tokens, regular input tokens, and output tokens.
Can I use Claude Code cost estimates as the bill?
Use them as estimates, not authoritative billing. For API-route work, confirm spend in Claude Console or the Usage and Cost API. For subscription-route work, keep plan usage separate from API token pricing.
What should I do before publishing customer pricing based on cache savings?
Recheck the official provider pricing page, run a production-like test, export actual usage fields, compare them with the provider billing surface, and document which route owns the bill.