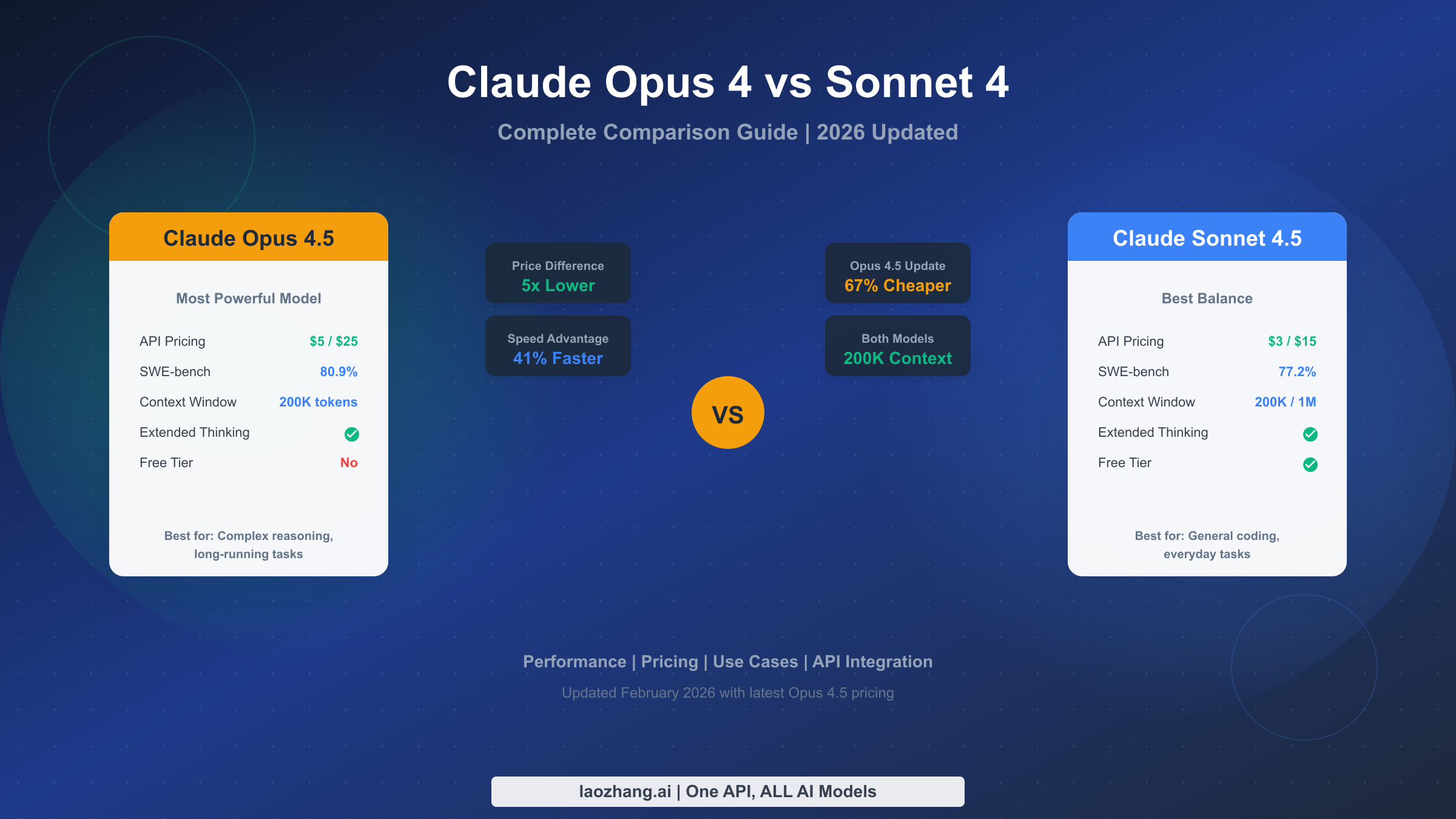
Claude Opus 4 and Sonnet 4 differ primarily in performance, pricing, and use cases. Opus 4.5 (February 2026) costs $5/$25 per million tokens—a significant 67% reduction from the original $15/$75—while Sonnet 4.5 maintains its $3/$15 pricing. For most developers, Sonnet 4.5 offers the best balance of speed (54.84 tokens/sec vs Opus's 38.93), cost, and capability, while Opus 4.5 excels in complex, long-running tasks requiring sustained reasoning over hours.
TL;DR - Quick Comparison Summary

Choosing between Claude Opus 4.5 and Sonnet 4.5 comes down to three factors: how complex your tasks are, how much you're willing to spend, and how fast you need responses. The table above captures the essential differences, but understanding what these numbers mean in practice requires deeper context.
Opus 4.5 represents Anthropic's flagship model, designed for extended autonomous operation and complex multi-step reasoning. When Anthropic talks about "multi-hour agentic tasks," they mean Opus—it's the model that powers Claude Code's most sophisticated features and handles research tasks that require sustained focus across thousands of lines of code or documents. The 80.9% SWE-bench Verified score reflects its capability to solve real-world GitHub issues with minimal human intervention.
Sonnet 4.5, by contrast, optimizes for the 90% of use cases where you need capable AI assistance without the premium price tag. Its 77.2% SWE-bench score is only 3.7 percentage points behind Opus, but the 40% cost savings and 41% speed improvement make it the practical choice for most development workflows. The free tier access through claude.ai makes it accessible for experimentation and personal projects.
| Feature | Opus 4.5 | Sonnet 4.5 | Winner |
|---|---|---|---|
| API Input Price | $5/M tokens | $3/M tokens | Sonnet |
| API Output Price | $25/M tokens | $15/M tokens | Sonnet |
| SWE-bench Verified | 80.9% | 77.2% | Opus |
| Output Speed | 38.93 tok/s | 54.84 tok/s | Sonnet |
| Time to First Token | 1.82s | 1.27s | Sonnet |
| Context Window | 200K | 200K (1M beta) | Sonnet |
| Extended Thinking | Yes | Yes | Tie |
| Free Tier | No | Yes | Sonnet |
| Best For | Complex reasoning | General tasks | Depends |
The practical recommendation is straightforward: start with Sonnet 4.5. If you find yourself hitting its limits—tasks that require extended reasoning, multi-file refactoring, or autonomous agent work—then upgrade to Opus. Most developers never need to make that switch.
Model Pricing Breakdown

The February 2026 pricing landscape for Claude models represents a significant shift from Anthropic's original pricing strategy. Most notably, Opus 4.5 received a dramatic 67% price reduction, making premium AI capabilities accessible to a much broader audience. This section breaks down exactly what you'll pay across different usage scenarios.
The headline change is Opus 4.5's new pricing: $5 per million input tokens and $25 per million output tokens. Compare this to the original Opus 4 launch pricing of $15/$75, and you're looking at substantial savings for high-volume users. For a typical coding session that processes 100,000 tokens of context and generates 50,000 tokens of output, the cost dropped from $5.25 to $1.75—a 67% reduction that fundamentally changes the economics of using Anthropic's most powerful model.
Sonnet 4.5 maintains its position as the value leader at $3 per million input tokens and $15 per million output tokens. While these prices haven't changed since launch, the model itself has received capability improvements that make it increasingly competitive with Opus for everyday tasks. The 40% cost difference between Sonnet and Opus is meaningful at scale: a developer processing 10 million tokens monthly saves $200 by choosing Sonnet over Opus.
Subscription Tiers and Their Value
Anthropic offers three subscription tiers for claude.ai that provide different levels of access:
The free tier provides access to Sonnet 4.5 with usage limits that work for casual exploration and personal projects. You'll hit rate limits during heavy usage, but for learning and experimentation, it's genuinely useful. Opus 4.5 is not available on the free tier—this is one of the key differentiators pushing power users toward paid plans.
Claude Pro at $20 per month unlocks higher rate limits and priority access during peak times. You get access to both Sonnet 4.5 and Opus 4.5 through the web interface, though API access requires separate billing. For developers who primarily work through claude.ai rather than the API, this represents excellent value—especially if you need occasional Opus access for complex tasks.
Claude Max at $100+ per month targets enterprise users who need guaranteed availability and the highest rate limits. At this tier, you're essentially paying for SLA-backed access and support rather than raw capability differences.
Cost Calculation Examples
Understanding real-world costs requires context about how tokens translate to actual work:
A typical code review session might process 50,000 input tokens (the code being reviewed plus context) and generate 10,000 output tokens (the review comments and suggestions). With Sonnet 4.5, this costs $0.30. With Opus 4.5, the same session costs $0.50. Over 100 such sessions per month, that's a $20 difference—not trivial, but not prohibitive either.
For autonomous coding agents that run for extended periods, the calculus changes. A 4-hour Opus session processing 2 million tokens of context and generating 500,000 tokens of output would cost approximately $22.50. The same task with Sonnet would cost $13.50, but might require more human intervention or produce lower-quality results for truly complex reasoning tasks.
Performance Benchmarks Explained
Performance benchmarks for large language models can feel like alphabet soup—SWE-bench, AIME, GPQA, MMLU—but each measures something specific and meaningful. Understanding what these numbers actually represent helps you make informed decisions rather than simply chasing the highest score.
SWE-bench Verified has emerged as the gold standard for evaluating coding ability in real-world conditions. The benchmark presents models with actual GitHub issues from popular open-source projects and measures whether they can produce patches that pass the project's test suite. Opus 4.5's 80.9% score means it successfully resolves about 4 out of 5 issues it attempts—a remarkable achievement considering these are real bugs that stumped human developers enough to file an issue. Sonnet 4.5's 77.2% puts it in the same tier, just slightly behind.
The practical difference between 80.9% and 77.2% is subtle. For straightforward bug fixes and feature implementations, both models perform comparably. Opus pulls ahead on multi-file refactoring, understanding complex project architectures, and maintaining consistency across extended coding sessions. If you're asking the model to make changes spanning 10+ files with intricate dependencies, that 3.7 percentage point gap becomes more noticeable.
Mathematics and Reasoning Benchmarks
AIME (American Invitational Mathematics Examination) problems test sophisticated mathematical reasoning. Opus 4.5's strong performance here reflects its ability to chain logical steps across complex problems—the same capability that makes it effective for extended reasoning tasks in non-mathematical domains.
GPQA Diamond focuses on graduate-level science questions requiring expert knowledge. High scores indicate the model can reason about specialized technical content, not just regurgitate facts. This matters for developers working in scientific computing, bioinformatics, or other domains requiring deep technical understanding.
MMLU (Massive Multitask Language Understanding) covers 57 subjects from elementary math to professional law. While useful as a general capability indicator, it's less predictive of coding performance than SWE-bench. A model can excel at MMLU while still struggling with practical software development tasks.
Speed Metrics That Matter
Two speed metrics deserve attention: Time to First Token (TTFT) and throughput (tokens per second).
TTFT measures the delay before you see any response. Sonnet 4.5's 1.27 seconds versus Opus 4.5's 1.82 seconds might seem negligible, but in interactive development environments, that half-second compounds. When you're rapidly iterating on prompts or using AI assistance in your IDE, faster TTFT creates a more responsive experience.
Throughput affects how quickly you receive complete responses. Sonnet's 54.84 tokens per second versus Opus's 38.93 means Sonnet completes a 1,000-token response in about 18 seconds while Opus takes 26 seconds. For long-form content generation or extensive code explanations, this 41% speed advantage makes Sonnet feel noticeably snappier.
Context Window Capabilities
Both models support 200,000 token context windows—enough to process entire codebases, lengthy documents, or extended conversation histories. Sonnet 4.5 additionally offers a 1 million token beta context window, useful for processing extremely large documents or maintaining longer conversation histories.
In practice, most interactions stay well under 100,000 tokens. The larger context windows matter most for specialized use cases: analyzing entire repositories, processing book-length documents, or maintaining context across multi-day autonomous agent sessions.
The output token limit of 16,384 tokens (with extended output of 64,000+ for Opus with Extended Thinking) determines the maximum length of a single response. For most coding tasks, this is more than sufficient. Extended Thinking mode, available on both models, allows for longer reasoning chains when complex problems require them.
Claude 4 vs 4.5 - Which Version to Choose
The version numbering for Claude models creates genuine confusion. Opus 4, Opus 4.5, Sonnet 4, Sonnet 4.5—which should you use, and when? This section clarifies the distinction and provides concrete guidance for making the right choice.
The fundamental difference is simple: 4.5 versions represent the current state-of-the-art, while 4.0 versions are older snapshots with different price-performance trade-offs. Anthropic has progressively improved the 4.5 models since their initial release, incorporating feedback and expanded capabilities. The 4.0 versions exist primarily for backward compatibility and cost optimization in specific scenarios.
When 4.0 Versions Make Sense
Claude Sonnet 4 (not 4.5) may still be available at reduced pricing for certain use cases. If your application has been tested and validated against a specific model version, switching to 4.5 introduces the risk of behavior changes—however minor. Production systems with tight regression testing requirements sometimes prefer version stability over incremental capability improvements.
However, for new projects, there's rarely a reason to start with 4.0. The capability improvements in 4.5 versions come without significant cost increases for Sonnet, and Opus 4.5's pricing is actually lower than Opus 4 was at launch. Unless you have specific backward compatibility requirements, default to 4.5.
Capability Differences That Matter
Sonnet 4.5 introduced several improvements over Sonnet 4:
Extended Thinking support enables the model to reason through complex problems step-by-step, showing its work and catching errors before committing to final answers. This capability, previously Opus-exclusive, significantly improves performance on multi-step reasoning tasks.
Improved instruction following means Sonnet 4.5 more reliably adheres to specified output formats, coding styles, and behavioral constraints. Developers who struggled with earlier models ignoring specific instructions often find 4.5 more cooperative.
Better code generation reflects improved training on programming tasks. The gap between Sonnet and Opus narrowed with 4.5, making Sonnet increasingly viable for complex development work.
Opus 4.5 similarly improved over Opus 4, but the most significant change was the pricing reduction. The model's core capability—sustained autonomous reasoning over extended periods—was already strong. The 4.5 update refined rather than revolutionized its capabilities.
Migration Recommendations
For existing Sonnet 4 users: migrate to 4.5 unless you have tested, validated behavior that you cannot risk changing. The capability improvements are meaningful, and pricing remains constant.
For existing Opus 4 users: migrate to 4.5 immediately. You're paying more for less capability if you stay on 4.0.
For new projects: start with Sonnet 4.5. Only move to Opus 4.5 if you encounter specific tasks where Sonnet's performance is insufficient. Most developers find Sonnet 4.5 handles their needs effectively, making the cost savings worthwhile.
| Aspect | 4.0 Versions | 4.5 Versions |
|---|---|---|
| Current Status | Legacy | Active development |
| Extended Thinking | Opus only | Both models |
| Instruction Following | Good | Improved |
| Pricing | Similar (Opus lower) | Current rates |
| Recommendation | Existing systems only | All new projects |
API Integration Guide
Integrating Claude models into your application requires understanding the authentication flow, request structure, and error handling patterns. This section provides working code examples in Python and Node.js that you can adapt to your specific needs.
Python Integration
The anthropic Python package provides the cleanest integration path. Install it via pip and configure your API key:
pythonimport anthropic import os # Initialize the client with your API key client = anthropic.Anthropic( api_key=os.environ.get("ANTHROPIC_API_KEY") ) # Basic completion request def get_completion(prompt: str, model: str = "claude-sonnet-4-5-20250929") -> str: """ Get a completion from Claude. Args: prompt: The user's message model: Model ID (claude-opus-4-5-20251101 or claude-sonnet-4-5-20250929) Returns: The model's response text """ message = client.messages.create( model=model, max_tokens=4096, messages=[ {"role": "user", "content": prompt} ] ) return message.content[0].text # Streaming for real-time responses def get_streaming_completion(prompt: str, model: str = "claude-sonnet-4-5-20250929"): """Stream a completion for real-time display.""" with client.messages.stream( model=model, max_tokens=4096, messages=[{"role": "user", "content": prompt}] ) as stream: for text in stream.text_stream: print(text, end="", flush=True)
The model IDs follow the pattern claude-{model}-{version}-{date}. Use claude-opus-4-5-20251101 for Opus 4.5 and claude-sonnet-4-5-20250929 for Sonnet 4.5.
Node.js Integration
For JavaScript/TypeScript projects, the @anthropic-ai/sdk package provides equivalent functionality:
javascriptimport Anthropic from "@anthropic-ai/sdk"; const client = new Anthropic({ apiKey: process.env.ANTHROPIC_API_KEY, }); async function getCompletion(prompt, model = "claude-sonnet-4-5-20250929") { const message = await client.messages.create({ model: model, max_tokens: 4096, messages: [{ role: "user", content: prompt }], }); return message.content[0].text; } // Streaming example async function streamCompletion(prompt, model = "claude-sonnet-4-5-20250929") { const stream = await client.messages.stream({ model: model, max_tokens: 4096, messages: [{ role: "user", content: prompt }], }); for await (const event of stream) { if (event.type === "content_block_delta" && event.delta.type === "text_delta") { process.stdout.write(event.delta.text); } } }
Error Handling Best Practices
Claude's API can return several error types that require different handling strategies. Proper error handling prevents cascading failures and provides meaningful feedback to users.
Rate limiting (HTTP 429) occurs when you exceed your API tier's request limits. Implement exponential backoff with jitter to handle these gracefully. For information about managing rate limits for AI APIs, understanding the general patterns helps across providers.
pythonimport time import random def retry_with_backoff(func, max_retries=5): """Retry a function with exponential backoff.""" for attempt in range(max_retries): try: return func() except anthropic.RateLimitError: if attempt == max_retries - 1: raise wait_time = (2 ** attempt) + random.uniform(0, 1) time.sleep(wait_time)
Context length errors occur when your input exceeds the model's context window. Track token usage and implement truncation strategies for large inputs. The tiktoken library provides accurate token counting for planning purposes.
Authentication errors indicate API key issues—verify your key is correctly set in environment variables and hasn't expired. Never hardcode API keys in source code.
When to Choose Opus vs Sonnet

The decision between Opus and Sonnet isn't about which model is "better"—it's about matching capabilities to requirements. This framework helps you make that decision based on your specific situation rather than abstract benchmarks.
Choose Opus 4.5 When:
Your tasks require sustained reasoning over extended periods. Multi-hour autonomous agent sessions, comprehensive codebase refactoring, or research tasks that need to maintain context and consistency across many files—these are Opus territory. The model's architecture specifically optimizes for these extended operations.
The quality ceiling matters more than cost efficiency. If you're building a product where AI-generated content directly reaches end users and quality differences are immediately visible, Opus's slightly higher benchmark scores may justify the premium. Legal document drafting, medical information summarization, and financial analysis often fall into this category.
You're pushing the boundaries of what current AI can do. Experimental applications, novel problem domains, and tasks that frequently fail with other models—Opus gives you the best chance of success even if it costs more per attempt.
Your volume is low enough that the cost difference is negligible. If you're processing fewer than a million tokens per month, the dollar difference between Opus and Sonnet is minimal. At that scale, defaulting to Opus ensures you're never limited by model capability.
Choose Sonnet 4.5 When:
You're building applications that need to scale. The 40% cost savings between Sonnet and Opus compounds quickly at scale. A million-token-per-day application saves $6,000 annually by using Sonnet instead of Opus.
Speed matters for user experience. Sonnet's faster TTFT and higher throughput create more responsive applications. Interactive coding assistants, chatbots, and real-time analysis tools benefit from the snappier feel.
Your tasks are well-defined with clear success criteria. Standard code generation, documentation, debugging assistance, and structured data processing—Sonnet handles these competently. The small quality gap versus Opus rarely affects outcomes for typical development tasks.
You're operating on a limited budget or just getting started. Sonnet's free tier access makes it accessible for learning and experimentation. There's no reason to spend money on Opus while you're still figuring out how to integrate AI effectively into your workflow.
The Hybrid Approach
Many successful implementations use both models strategically. Route simple queries to Sonnet for cost efficiency, escalate complex tasks to Opus when needed. The anthropic client makes model switching straightforward—just change the model parameter.
pythondef smart_route(task_complexity: str, prompt: str) -> str: """Route to appropriate model based on task complexity.""" model = ( "claude-opus-4-5-20251101" if task_complexity == "high" else "claude-sonnet-4-5-20250929" ) return get_completion(prompt, model)
This pattern optimizes both cost and quality by using premium resources only where they provide meaningful benefits.
Cost Optimization Strategies
Managing AI API costs requires understanding not just pricing but also the various mechanisms for reducing spend without sacrificing quality. Anthropic provides several built-in cost reduction features that many developers underutilize.
Prompt Caching Benefits
Prompt caching reduces costs when you repeatedly send the same context (system prompts, few-shot examples, or large documents) across multiple requests. Rather than processing the same tokens repeatedly, cached prefixes are stored and reused. For applications with consistent system prompts or reference documentation, caching can reduce input token costs by up to 90% for the cached portion.
To use caching effectively, structure your prompts so that the reusable content appears first. Put your system prompt and any consistent context at the beginning, followed by the variable user input. The cache hit rate directly correlates with how consistently you structure your requests.
Batch Processing Discounts
Anthropic offers batch processing for non-real-time workloads at 50% reduced costs. If your application can tolerate processing delays of hours rather than seconds—bulk content analysis, overnight report generation, or asynchronous data processing—batching provides significant savings.
The trade-off is latency: batch jobs complete within 24 hours rather than immediately. For development workflows requiring instant feedback, batching isn't appropriate. For background processing, it's essentially half-price AI.
Token Optimization Techniques
Reducing token usage directly reduces costs. Several strategies help without compromising quality:
Compress verbose prompts. Remove redundant instructions, eliminate excessive examples, and use concise language. A 40% reduction in prompt length yields a 40% reduction in input costs.
Stream responses and implement early stopping. If you're looking for a specific answer that appears early in a response, stop generation once you have what you need rather than waiting for the complete output.
Use appropriate max_tokens limits. Setting lower limits when you expect short responses prevents paying for tokens you'll discard. A Q&A application expecting one-paragraph answers shouldn't request 4,096 tokens.
When processing millions of tokens daily, even small per-token savings compound significantly—worth evaluating for production workloads where the official API costs become substantial.
Comparing Costs Across AI Providers
Understanding Claude's pricing in context helps budget planning. If you're evaluating alternatives like Gemini API's free tier comparison, the per-token math differs but the optimization principles remain similar.
| Strategy | Potential Savings | Best For |
|---|---|---|
| Prompt Caching | Up to 90% on cached portion | Consistent system prompts |
| Batch Processing | 50% | Non-real-time workloads |
| Token Optimization | 20-40% | All applications |
| Model Routing | 40% (Sonnet vs Opus) | Variable complexity tasks |
| Third-party Gateways | Variable | High-volume production |
The most effective cost optimization combines multiple strategies. A well-structured application using prompt caching, smart model routing, and optimized token usage can reduce costs by 60-70% compared to naive implementations—the difference between an affordable AI-powered feature and one that blows through your budget.
Conclusion and Recommendations
The choice between Claude Opus 4.5 and Sonnet 4.5 is clearer now than it has ever been. Opus 4.5's 67% price reduction brings premium AI capabilities within reach of more developers, while Sonnet 4.5 remains the practical choice for most everyday development work.
If you're starting fresh, begin with Sonnet 4.5. Its combination of speed, cost efficiency, and capability handles the vast majority of development tasks effectively. The free tier access through claude.ai means you can experiment without commitment. Only when you encounter specific limitations—tasks that truly require extended autonomous reasoning or the highest possible quality ceiling—should you consider switching to Opus.
For production applications, the hybrid approach often works best. Route routine queries to Sonnet for cost efficiency, escalate complex tasks to Opus when the additional capability justifies the premium. Implement prompt caching, consider batch processing for background workloads, and optimize token usage to minimize costs across both models.
The benchmark numbers tell one story, but practical usage tells another. Sonnet 4.5's 77.2% SWE-bench score versus Opus 4.5's 80.9% represents a meaningful gap in controlled tests. In day-to-day development, that 3.7 percentage point difference rarely determines success or failure. The 41% speed improvement and 40% cost savings with Sonnet provide tangible, immediate benefits that most developers notice more than the capability difference.
As Anthropic continues developing both model lines, expect the gap to continue narrowing. Today's Sonnet matches or exceeds last year's Opus in many respects. The march of progress benefits users who keep their implementations flexible and avoid over-optimizing for any single model version.
Whatever you choose, the fundamentals of effective AI integration remain constant: write clear prompts, handle errors gracefully, optimize token usage, and match model capabilities to task requirements. The best model is the one that solves your specific problem within your budget—and with February 2026's pricing landscape, both Opus and Sonnet offer compelling value propositions.


