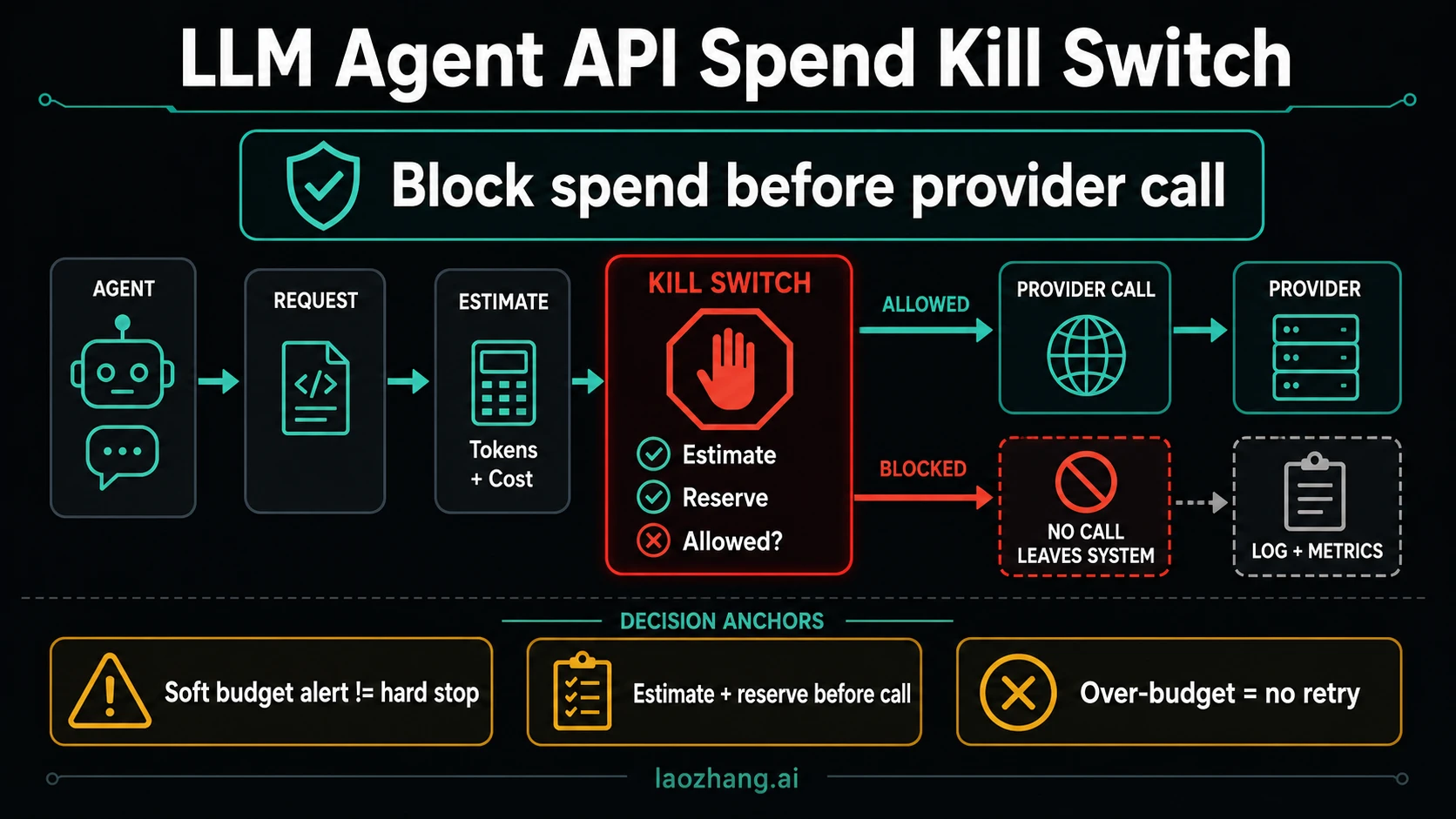
An LLM agent API spend kill switch has to run before the provider call leaves your system. If the agent can retry, spawn sub-agents, or trigger tool calls that make model requests, the budget check must sit in that request path, not only in a monthly dashboard alert.
The minimum useful design is: estimate the worst-case cost, reserve that amount atomically, call the provider only when the reservation succeeds, reconcile actual usage after the response, and return a terminal over-budget error when the cap would break. Provider and platform limits still matter, but they are backstops.
| Control | What it stops | Spend-stop role |
|---|---|---|
| Dashboard budget alert | Human misses the burn rate | Soft warning; requests may continue |
| Provider or project cap | Account-level overspend after provider enforcement | Useful backstop, not your first gate |
| Gateway budget | Calls routed through one proxy or gateway | Can be a hard stop when every paid path uses it |
| Pre-provider agent gate | The next model call before it is sent | Primary kill switch for autonomous agents |
Stop rule: once the gate returns over_budget, the agent must not retry, spawn a helper, or switch to another paid route unless a human changes the cap or policy and records that override.
What a real spend kill switch is
A spend kill switch is not the same thing as a usage dashboard, an email alert, or a rate-limit response. A real LLM agent API spend kill switch is an enforcement point that can say no before another paid request is sent. The enforcement point can live in your agent runtime, a shared internal proxy, a gateway, or a provider-facing wrapper, but it has to control the credential path the agent uses.
The most common failure is architectural: the team adds a budget warning after the agent worker already has direct access to provider keys. That protects the finance inbox, not the next API call. If a long-running agent has its own retry loop, planner loop, tool loop, and sub-agent queue, each of those paths needs to spend through the same gate.
If the agent is already repeating a tool, use the AI agent tool-loop troubleshooting guide to classify the loop and stop the next unsafe call before treating cost as the only failure.
Use four separate words in the runbook:
| Term | Use it for | Do not use it for |
|---|---|---|
| Spend limit | A cost ceiling in dollars or account currency | Token throughput |
| Rate limit | Requests or tokens per time window | Total monthly cost |
| Soft budget | Alerting, reporting, or thresholds that may allow more calls | Pre-call blocking |
| Hard stop | A request that is rejected before more paid work begins | A later email or dashboard warning |
That vocabulary matters because operators reach for the wrong control when the words blur. If the incident is a runaway agent, the first question is not "which dashboard has a budget field?" It is "which component is allowed to send the next paid request?"
Choose the control layer
The safest production design is layered. Put the primary block in the request path, then keep provider and platform controls as backstops.
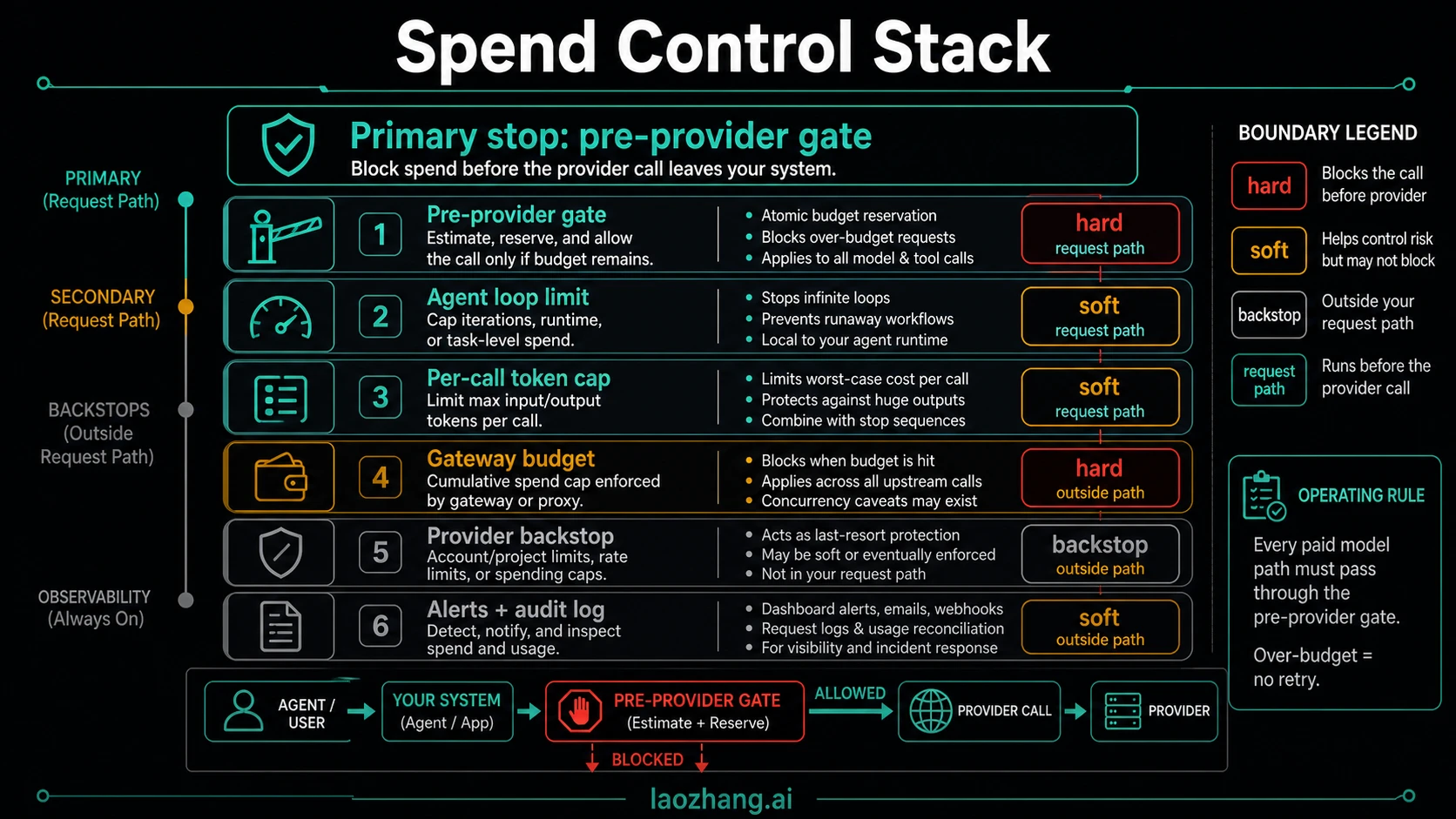
| Layer | Good at | Weakness | Use it as |
|---|---|---|---|
| Agent loop limit | Stopping infinite loops, too many tool steps, or too much wall-clock time | Does not know final provider bill unless connected to spend data | Local safety rail |
| Per-call token cap | Limiting worst-case cost for one request | Cannot stop many small calls from accumulating | Call-shape guardrail |
| Pre-provider spend gate | Blocking the next paid request before it leaves your system | Requires shared ledger and reliable routing | Primary kill switch |
| Gateway budget | Enforcing budget across keys, teams, providers, or models when all traffic is routed through it | Can miss traffic that bypasses the gateway; concurrency behavior must be understood | Shared control plane |
| Provider or project cap | Account-level ceiling and policy enforcement by the provider | May be soft, delayed, or outside your agent's retry semantics | Backstop |
| Alerts and audit logs | Detection, notification, and after-action review | They do not necessarily stop the next call | Observability |
If you already use an OpenAI-compatible proxy, put the budget check there. If your agent runtime is the only place that sees every model and tool call, put it there first and route all sub-agents through it. If you use several providers, a gateway or internal proxy usually gives a cleaner control point than copying budget checks into every worker.
The wrong design is a partial gate. If the main planner uses the gate but the retrieval tool, evaluator, image generator, or "emergency fallback" key bypasses it, the agent still has a paid route around the stop sign.
Implement reserve, call, reconcile
The buildable pattern is a ledger with conservative pre-flight reservation. You do not know the exact cost before the response arrives, so the gate reserves the worst reasonable case, then reconciles after usage is known.
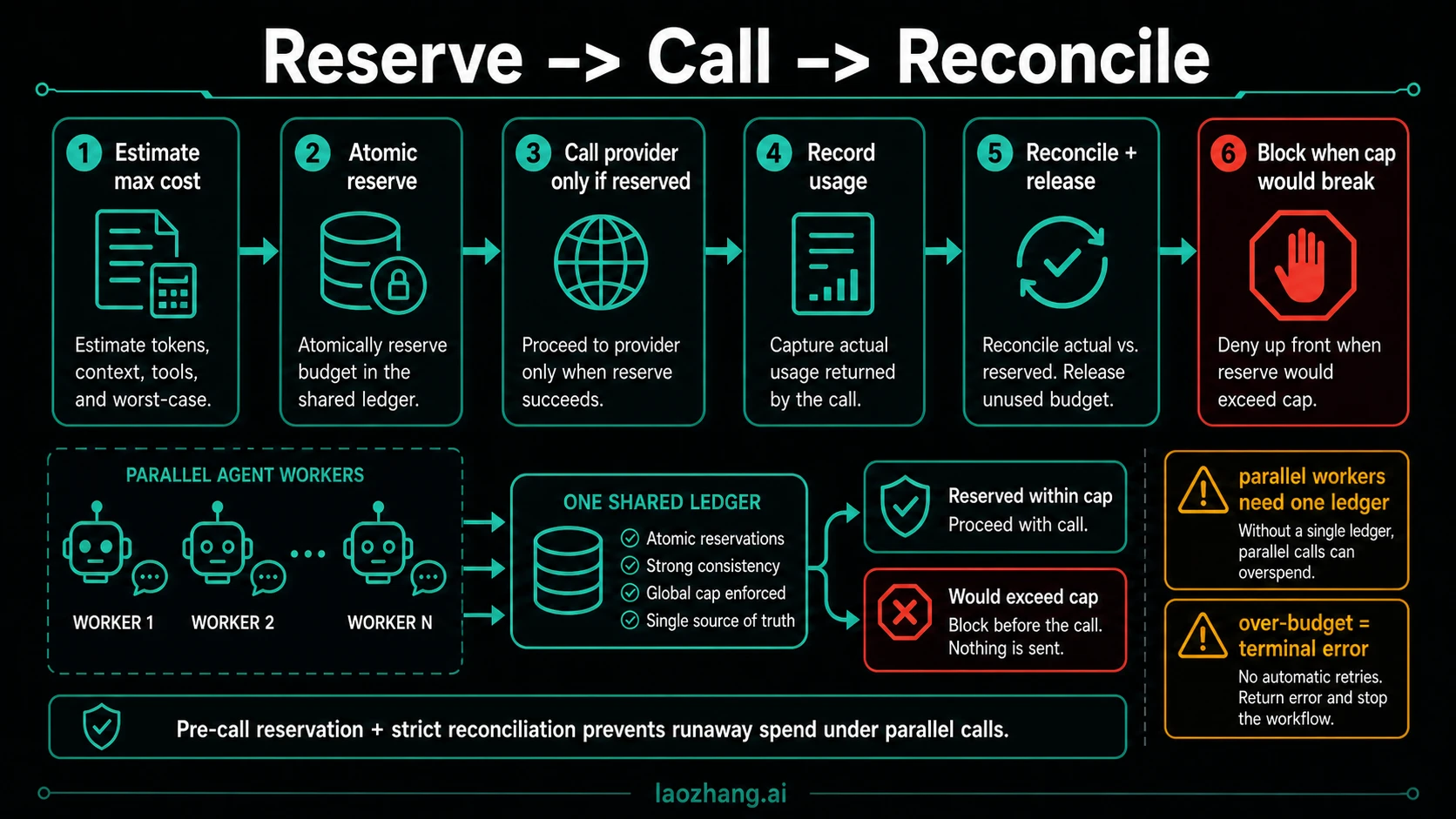
At minimum, the ledger needs these fields:
| Field | Why it exists |
|---|---|
budget_id | The team, user, project, agent, or run that owns the cap |
limit_amount | The maximum allowed spend for the period or run |
reserved_amount | Spend already reserved by in-flight calls |
actual_amount | Spend reconciled from completed calls |
period_start / period_end | Reset window for daily, monthly, or per-run budgets |
request_id | Correlates the decision with provider logs |
agent_run_id | Groups planner, worker, sub-agent, and tool-triggered calls |
decision | allowed, blocked, reconciled, or released |
reason | Cap reached, missing estimate, unknown model, override, or policy block |
The pre-call flow is short:
tsasync function guardedModelCall(request) { const estimate = estimateWorstCaseCost(request); const reservation = await ledger.reserveAtomically({ budgetId: request.budgetId, requestId: request.requestId, agentRunId: request.agentRunId, amount: estimate, }); if (!reservation.allowed) { return { error: "over_budget", retryable: false, message: "Budget cap would be exceeded before provider call.", }; } try { const response = await provider.responses.create(request.payload); await ledger.reconcile({ reservationId: reservation.id, actualAmount: costFromUsage(response.usage), usage: response.usage, }); return response; } catch (error) { await ledger.releaseOrMarkUnknown({ reservationId: reservation.id, errorClass: classifyProviderError(error), }); throw error; } }
The important word is reserveAtomically. If five workers read the same remaining budget and then all call the provider, final usage logs arrive too late. The reservation must be a single database transaction, Redis script, durable workflow step, or gateway operation that cannot be interleaved with another reservation for the same budget.
For streaming, treat the initial reservation as the maximum possible response you allowed. If your provider exposes usage only at the end, reconcile when the stream closes. If the stream fails before usage is known, keep a conservative charge, mark it unknown, or run a later reconciliation job from provider logs. Do not release the whole reservation just because the client disconnected.
Make the agent stop instead of retrying
The budget response must be part of agent semantics, not only a thrown exception. A normal timeout, 429, or provider error can be retryable. An over-budget decision should be terminal for that budget scope.
Give the agent a structured error:
json{ "error": "over_budget", "retryable": false, "budget_id": "team-alpha-agent-run", "cap": "configured", "reserved": "current ledger state", "next_allowed_action": "ask for human budget override" }
Then enforce three propagation rules:
| Rule | Reason |
|---|---|
| Planner stops scheduling paid work | Otherwise the root loop can keep creating blocked jobs |
| Sub-agents inherit the same budget scope | Otherwise helpers can spend after the parent stops |
| Tool calls that trigger model calls use the same gate | Otherwise tools become hidden model spend |
Retries need their own ceiling. A retry policy that ignores retryable: false can turn a good kill switch into a noisy incident. Treat over_budget, policy_blocked, and missing_budget_scope as no-retry errors. Log them, surface them to the operator, and stop the run.
Provider and gateway boundaries to verify
Provider controls are still useful. They are just not all the same kind of kill switch. Recheck these details before publishing internal runbooks, because spend controls and dashboard behavior change.
| Surface | Current evidence to verify | Practical boundary |
|---|---|---|
| OpenAI project budgets | OpenAI's Help Center currently describes project monthly budgets as soft thresholds where API requests continue after the budget is exceeded. The OpenAI rate limits guide also separates throughput limits from usage/spend limits. | Do not rely on project budgets alone as the request-path kill switch. Use them as alerting and account governance. |
| OpenAI Responses usage | Responses include usage fields that can support reconciliation after the call. | Useful for actual-cost logging, not enough by itself to stop the call before it starts. |
| Anthropic Console limits | Anthropic's rate-limit documentation distinguishes spend limits and rate limits. | Good backstop and provider governance; still route direct agent calls through your gate. |
| LiteLLM proxy | LiteLLM documents budgets and rate limits plus spend tracking. | Useful if every paid route goes through the proxy and your team accepts its budget semantics. |
| Cloudflare AI Gateway | Cloudflare documents AI Gateway spend limits that can block further requests when the configured cost limit is reached, with an eventual-consistency caveat. | Strong gateway option, but test concurrent bursts and bypass routes. |
| Vercel Spend Management | Vercel Spend Management can notify, trigger webhooks, and pause production deployments when configured. | Platform-level spend brake, not a substitute for per-agent request gating. |
For OpenAI-specific quota and rate-limit symptoms, keep separate incident paths. A rate-limit guide helps when the next request is blocked by throughput; a spend kill switch guide helps when the next request should be blocked by your own budget policy. If you need the provider-error branch, use OpenAI API rate limit or OpenAI API quota exceeded error. For provider-comparison cost planning, use Claude API vs OpenAI API pricing, but recheck current pricing before turning an example into a budget rule.
Test it with zero provider calls
A spend kill switch is not production-ready until you can prove that blocked requests never reach the paid provider. Run the proof before connecting expensive models or long-running agent jobs.

Use this test ladder:
| Test | Setup | Pass condition |
|---|---|---|
| Fake provider | Replace the provider endpoint with a local counter service | Counter stays at zero after budget is exhausted |
| Cap below request | Set the remaining budget lower than the estimate | Gate returns over_budget before network call |
| Parallel workers | Fire enough concurrent requests to exceed the cap if reservations race | At most the reserved budget is allowed; blocked requests do not hit provider |
| Streaming abort | Start a streaming call and force a mid-stream stop | Ledger keeps a conservative reservation until usage is reconciled |
| Retry policy | Simulate timeout, 429, and over-budget responses | Only retryable errors retry; over_budget stops |
| Audit packet | Inspect ledger, request id, agent run id, and reason code | Operator can explain why the call was blocked |
Run the tests whenever you change pricing metadata, model routing, retry policy, the gateway, or the ledger storage. If the fake provider sees a request after the cap, the kill switch is not a kill switch yet.
Production runbook
The runbook should be boring enough to use during an incident.
- Freeze direct provider credentials. Confirm agent workers cannot bypass the gate.
- Check the budget scope: user, team, project, agent run, or monthly account cap.
- Inspect ledger state: actual spend, reserved spend, in-flight calls, unknown reconciliation items.
- Confirm the agent received a terminal
over_budgeterror. - Stop retries and sub-agent scheduling.
- Reconcile provider logs against ledger records.
- Decide whether to raise the cap, narrow the task, or close the run.
- If a human override is needed, record who approved it, the new cap, the expiration, and the reason.
The highest-risk override is "try another route." That can hide the original budget scope and create a new billable path. If you must switch provider, model, gateway, or key, treat it as a new budget decision, not a retry.
FAQ
Is an OpenAI project budget enough for an LLM agent API spend kill switch?
No. Current OpenAI Help Center wording describes project budgets as soft thresholds, so they are useful for governance and alerts but should not be your only stop mechanism for a runaway agent. Put a request-path gate before the provider call.
Should the kill switch return HTTP 402, 429, or something else?
Use whatever status your clients handle consistently, but the agent-facing payload matters more than the number. The response should say the budget cap would be exceeded and retryable should be false. Some gateways use 429 for limit-style blocks; internal agent runtimes often use a domain error such as over_budget.
How do I estimate cost before the response exists?
Use the maximum input, output, tool, image, or streaming cost the request is allowed to create. That estimate can be conservative. Reconcile it after the call with provider usage fields or gateway cost logs, then release unused reservation.
What if final provider usage arrives late?
Keep the reservation until reconciliation finishes, or mark it as unknown with a conservative charge. Releasing everything immediately after an interrupted stream can reopen the budget before the real usage is known.
Do sub-agents need their own budgets?
They can have child budgets, but they also need to inherit the parent run's cap. A helper agent should not be able to continue spending after the parent budget has stopped.
Where should I start if I already use a gateway?
First confirm every paid model path uses the gateway. Then test gateway behavior with a fake provider, a low cap, and parallel calls. A gateway budget is only the primary kill switch if bypass routes are closed and the blocked request never reaches the provider.