
Nano Banana 2(Gemini 3.1 Flash Image,模型 ID gemini-3.1-flash-image-preview)中的 blockReason OTHER 表示你的请求被 Google 第二层策略执行系统拦截——这是一个不可配置的服务端过滤器,无法通过将安全阈值设置为 BLOCK_NONE 或 OFF 来绕过。截至 2026 年 3 月,该过滤器涵盖 8 类内容,包括受版权保护的角色、公众人物和 NSFW 内容。本指南将详细讲解 blockReason 与 finishReason 的完整映射关系、双层安全架构原理,并提供 5 种经过验证的解决方案及生产级代码。
要点速览
- blockReason OTHER 不等于 blockReason SAFETY:OTHER 来自第二层(不可配置的策略执行),而 SAFETY 来自第一层(可通过
harm_block_threshold调整)。设置BLOCK_NONE或OFF只影响第一层,永远无法修复第二层的拦截。 - 8 类内容会触发 blockReason OTHER:NSFW 内容、受版权保护的角色/知名 IP、公众人物、未成年人保护、水印移除、金融信息篡改、换装/换脸以及隐性暗示内容。2026 年 3 月的更新收紧了其中 4 类的执行力度。
- blockReason 和 finishReason 是两个不同的字段:
blockReason出现在提示词被拒绝、生成尚未开始时(不消耗 token)。finishReason出现在内容在生成过程中或生成后被拦截时(token 已被消耗)。两者都可能返回 OTHER 相关的值。 - python-genai SDK 存在 bug:在响应被拦截时访问
response.candidates[0].finish_reason会导致程序无限挂起,因为 candidates 数组为空。务必先检查len(response.candidates) > 0。 - 存在 5 种经过验证的解决方案:改写提示词、移除版权引用、拆分复杂提示词、添加超时并回退到其他模型,或使用替代图像模型(GPT Image、FLUX.2)作为回退方案。
blockReason OTHER 到底意味着什么?

当你向 Nano Banana 2 发送图像生成请求并在 API 响应中收到 blockReason: "OTHER" 时,意味着你的提示词在图像生成开始之前就被 Google 的第二层内容过滤器拦截了。这与 blockReason: "SAFETY" 有本质区别——后者来自第一层过滤器,你可以通过安全设置来控制。理解这一区别是解决问题最关键的一步,因为它直接决定了你是通过配置更改就能修复,还是需要采取完全不同的方案。
blockReason 和 finishReason 之间的混淆是开发者在使用 Gemini 图像生成 API 时第二常见的困扰来源。这两个字段出现在响应的不同位置,对计费有不同影响,排查策略也完全不同。下面的表格提供了完整的映射关系——在此之前,你可能需要阅读五篇不同的文章才能拼凑出这些信息。
blockReason 值(提示词级拦截)
blockReason 字段出现在 API 响应的 prompt_feedback 部分。当该字段存在时,表示提示词在生成开始前就被拒绝,因此不会消耗任何 token,也不存在部分生成的图像。
| blockReason 值 | 来源层 | 可配置? | 含义 |
|---|---|---|---|
SAFETY | 第一层 | 是(通过 harm_block_threshold) | 4 个危害类别之一超过了你配置的阈值。设置 BLOCK_NONE 或 OFF 即可解决。 |
OTHER | 第二层 | 否 | 服务端策略执行系统检测到提示词中包含违禁内容,无法绕过。 |
BLOCKED_REASON_UNSPECIFIED | 均有可能 | 视情况而定 | 罕见的兜底值。需要同时检查安全评级和提示词内容。 |
当你收到 blockReason OTHER 响应时,JSON 结构如下:
json{ "promptFeedback": { "blockReason": "OTHER" }, "candidates": [] }
注意 candidates 数组是完全空的。没有安全评级可供检查,没有部分内容可以恢复,也没有具体的类别告诉你到底触发了哪条规则。这是 Google 的设计意图——第二层过滤器故意不透露触发了哪条策略规则,因为这样做可能帮助恶意用户精心构造刚好绕过检测的提示词。
finishReason 值(生成级拦截)
finishReason 字段出现在每个 candidate 对象内部,表示生成停止的原因。与 blockReason 不同,这些拦截发生在生成过程中,意味着 token 已经被消耗,你可能会看到部分文本输出(但永远不会看到部分图像)。
| finishReason 值 | 来源层 | 含义 |
|---|---|---|
STOP | 不适用 | 正常完成。图像生成成功。 |
SAFETY | 第一层 | 生成的内容触发了可配置的安全过滤器。可通过设置调整。 |
IMAGE_SAFETY | 第二层 | 生成过程中检测到图像特定的安全违规。不可配置。 |
OTHER | 第二层 | 生成的内容中检测到版权、商标或知名 IP。不可配置。 |
PROHIBITED_CONTENT | 第二层 | 儿童安全或法律明令禁止的内容。最严格的执行级别,不可配置。 |
关键区别在于时机:blockReason 在生成之前触发(不消耗费用),而 finishReason 在生成过程中触发(消耗 token)。如果你看到的是 finishReason: "OTHER" 而不是 blockReason: "OTHER",说明你的提示词通过了初始过滤器,但生成的图像被第二层拦截了。这种情况通常出现在版权或商标内容只有在图像合成过程中才变得明显的场景——例如,"一只戴圆耳朵的卡通老鼠"这样的提示词可能通过了提示词过滤器,但当生成的图像开始像某个受版权保护的角色时,就会触发 finishReason: OTHER。
根据 GitHub Issue #276 的确认,Google 已声明包括儿童安全保护在内的强制性过滤器不能被禁用,第二层拦截不存在任何程序化的绕过方式。这是一个深思熟虑的架构设计决策,而不是 bug。
为什么 BLOCK_NONE 无法修复 blockReason OTHER
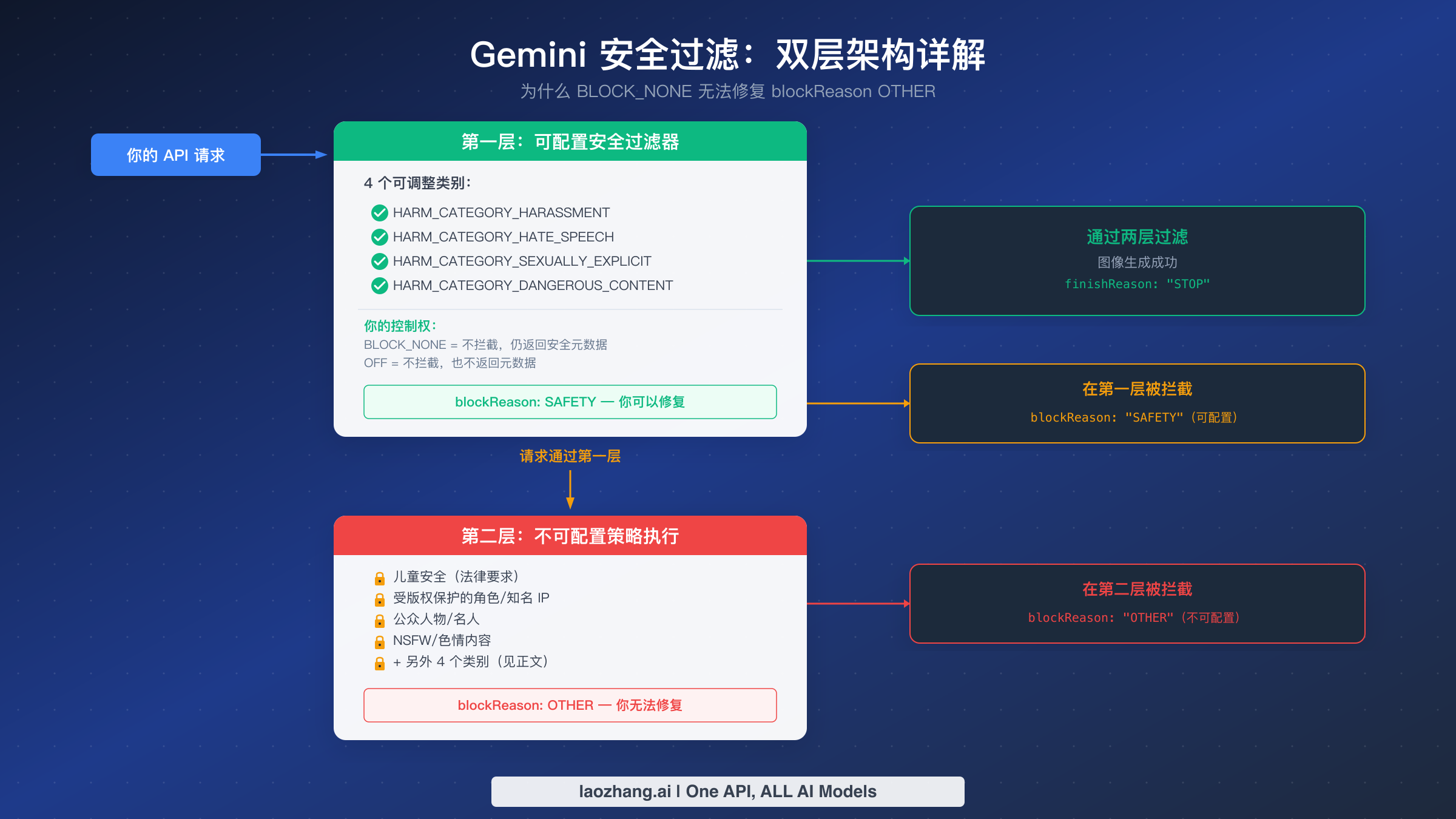
开发者在遇到 blockReason OTHER 时最常犯的错误就是立即尝试将所有安全类别设置为 BLOCK_NONE 或 OFF,期望这样就能解决问题。这种做法之所以失败,是因为它从根本上误解了 Gemini 安全过滤架构的工作方式。整个系统在两个完全独立的层级上运行,而你的安全设置只控制第一层。要深入了解所有可用的安全配置选项,请参阅我们的Gemini 安全设置详细指南。
第一层:可配置的安全过滤器
第一层根据四个危害类别评估你的提示词和生成内容,每个类别都可以单独配置:HARM_CATEGORY_HARASSMENT、HARM_CATEGORY_HATE_SPEECH、HARM_CATEGORY_SEXUALLY_EXPLICIT 和 HARM_CATEGORY_DANGEROUS_CONTENT。对于每个类别,你可以设置 harm_block_threshold 来决定过滤器的灵敏度。当第一层过滤器触发时,你会收到 blockReason: "SAFETY",并附带详细的安全评级,告诉你具体触发了哪个类别以及置信度级别。
控制第一层有两种选项。将阈值设置为 BLOCK_NONE 会禁用自动拦截,但仍然在响应中返回安全元数据,这对监控和日志记录很有用。将阈值设置为 OFF(根据 Vertex AI 文档,自 gemini-2.5-flash 及更新模型起可用,截至 2026 年 1 月)则完全禁用拦截和元数据收集。对于基于 Gemini 3.1 Flash 的 Nano Banana 2,这两个选项都可用,任何一个都能完全消除第一层的拦截。
以下是将第一层配置为最大宽松度的代码:
pythonfrom google import genai from google.genai import types client = genai.Client(api_key="YOUR_API_KEY") safety_settings_block_none = [ types.SafetySetting( category="HARM_CATEGORY_HARASSMENT", threshold="BLOCK_NONE" ), types.SafetySetting( category="HARM_CATEGORY_HATE_SPEECH", threshold="BLOCK_NONE" ), types.SafetySetting( category="HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold="BLOCK_NONE" ), types.SafetySetting( category="HARM_CATEGORY_DANGEROUS_CONTENT", threshold="BLOCK_NONE" ), ] # 选项 2:OFF - 不拦截,也不返回安全元数据 safety_settings_off = [ types.SafetySetting( category="HARM_CATEGORY_HARASSMENT", threshold="OFF" ), # ... 其他类别同理 ]
第二层:不可配置的策略执行
第二层是一个完全独立的系统,独立于你的安全设置运行。它通过服务端过滤器执行 Google 的内容政策、法律要求和服务条款,任何 API 参数、SDK 配置或账户设置都无法访问、修改或绕过。当第二层触发时,你会收到 blockReason: "OTHER",没有安全评级,没有类别信息,也无法确定具体违反了哪条策略。
第二层覆盖的内容类别超越了一般安全关切,涉及法律责任领域:儿童安全(大多数司法管辖区的法律要求)、受版权保护的角色和商标视觉标识、可识别的公众人物和名人、违反 Google 服务条款的 NSFW 内容,以及下一节详细介绍的其他几个类别。这些过滤器之所以存在,是因为如果 Google 的图像生成 API 产出了某些类型的内容,Google 将面临直接的法律责任,无论开发者的预期用途是什么。
实际含义很直白:如果你收到了 blockReason: "OTHER",无论怎么调整安全设置都不会有帮助。你已经通过将所有四个类别设置为 BLOCK_NONE 或 OFF 验证了这一点,但请求仍然被拦截。拦截并非来自你能控制的系统,而是来自它背后的另一个系统。唯一的出路是修改你的提示词或使用替代方案,我们将在下面的解决方案部分详细介绍。
分步诊断流程图
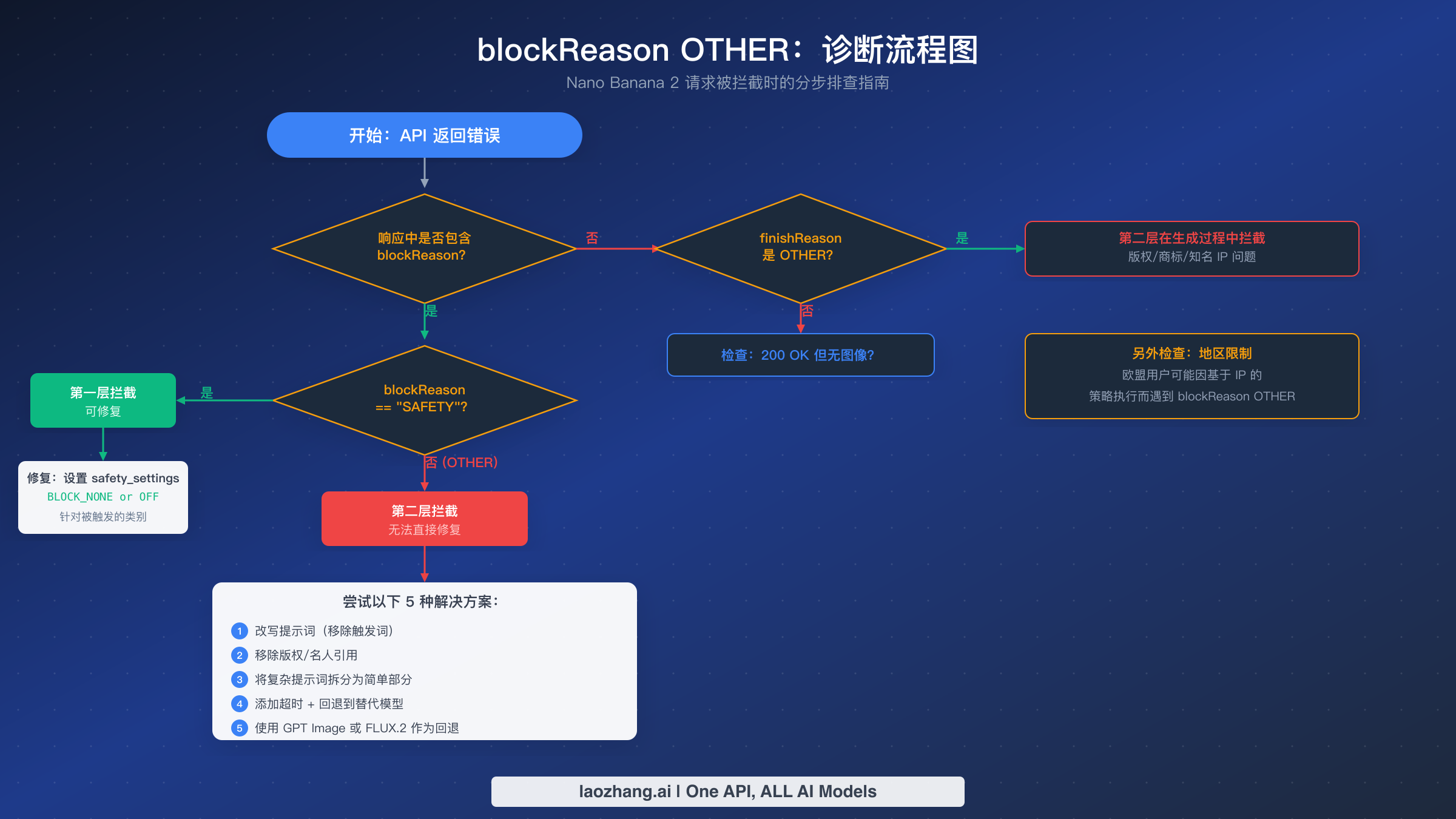
当你的 Nano Banana 2 API 调用返回错误时,第一步不是立即修改安全设置——而是精确判断你遇到的是哪种类型的错误。不同的错误类型需要完全不同的解决方案,用错方法只会浪费时间和 API 配额。这个诊断流程图提供了一种系统化方法,消除了猜测。
首先检查你的响应中 prompt_feedback 部分是否包含 blockReason 字段。如果没有 blockReason,问题可能是完全不同类型的错误。检查 candidates 数组中是否有 finishReason: "OTHER",这表示提示词通过了初始过滤,但生成的内容因版权或商标问题在生成过程中被拦截。如果 blockReason 和 finishReason OTHER 都不存在,你可能遇到的是 200 OK 但未生成图像的场景或 503 过载错误,这些问题各有其排查路径。有关其他常见的 Nano Banana 2 错误,请参阅我们的 thought signature 错误指南。
如果 blockReason 存在,检查它的值。如果值为 SAFETY,你遇到的是第一层拦截,可以通过安全设置配置来修复。检查响应中的安全评级以确定触发了哪个类别,然后将该类别的阈值设置为 BLOCK_NONE 或 OFF。如果值为 OTHER,则确认是第二层拦截,本指南中的解决方案适用。
以下是自动化此诊断过程的代码:
pythondef diagnose_block(response): """系统化诊断 Nano Banana 2 请求被拦截的原因。""" # 步骤 1:检查提示词级拦截 if hasattr(response, 'prompt_feedback') and response.prompt_feedback: block_reason = getattr(response.prompt_feedback, 'block_reason', None) if block_reason == 'SAFETY': # 第一层拦截 - 可通过安全设置修复 ratings = response.prompt_feedback.safety_ratings triggered = [r for r in ratings if r.blocked] return { 'type': 'LAYER_1_BLOCK', 'fixable': True, 'categories': [r.category for r in triggered], 'action': 'Set triggered categories to BLOCK_NONE or OFF' } elif block_reason == 'OTHER': # 第二层拦截 - 无法通过设置修复 return { 'type': 'LAYER_2_BLOCK', 'fixable': False, 'action': 'Rephrase prompt or use alternative model' } # 步骤 2:检查生成级拦截 if len(response.candidates) > 0: finish_reason = response.candidates[0].finish_reason if finish_reason == 'OTHER': return { 'type': 'LAYER_2_GENERATION_BLOCK', 'fixable': False, 'action': 'Copyright/trademark detected during generation' } if finish_reason == 'IMAGE_SAFETY': return { 'type': 'IMAGE_SAFETY_BLOCK', 'fixable': False, 'action': 'Image content violated safety policy' } # 步骤 3:无 candidates 且无 block reason if len(response.candidates) == 0: return { 'type': 'EMPTY_RESPONSE', 'fixable': False, 'action': 'Check for 200 OK no-image scenario' } return {'type': 'UNKNOWN', 'action': 'Inspect full response JSON'}
Python 开发者在使用 google-genai SDK 时需要特别注意一个关键细节:当 candidates 数组为空时尝试访问 response.candidates[0].finish_reason,SDK 不会抛出异常,而是会无限挂起。这是一个已知的 bug(截至 2026 年 3 月),SDK 尝试对 candidate 对象进行延迟求值时进入了无限等待状态。在访问任何 candidate 属性之前,务必先检查 len(response.candidates) > 0。如果你遇到了这种挂起,唯一的恢复方式是终止进程。
地区因素
欧盟地区的开发者需要注意,基于 IP 的策略执行可能导致 blockReason OTHER 被触发,即使同样的提示词在其他地区运行正常。这是因为 Google 在对 AI 生成图像有更严格法规的司法管辖区会应用更严格的内容策略。如果你怀疑是地区限制导致的拦截,可以从不同的地理区域测试同一提示词,以确认拦截是基于内容还是基于地区。
触发 blockReason OTHER 的 8 类内容
了解哪些内容会触发第二层拦截,有助于你编写避免不必要拒绝的提示词。通过交叉参考 Google 官方文档、社区报告和系统化测试,我们确定了 8 类在 Nano Banana 2 中会持续触发 blockReason OTHER 的内容类别。截至 2026 年 3 月,Google 加强了其中 4 类的执行力度,这解释了为什么之前能用的提示词现在可能被拦截。
NSFW 和色情内容是最广泛的类别,会捕获任何请求裸露、性行为或恋物内容的提示词。与你可以设置为 BLOCK_NONE 的第一层 HARM_CATEGORY_SEXUALLY_EXPLICIT 不同,第二层的 NSFW 过滤器独立运行且无法禁用。这会捕获第一层在 BLOCK_NONE 阈值下原本会放行的提示词,导致了一种令人困惑的情况:你的安全设置写着"允许一切",但请求仍然被拦截。
受版权保护的角色和知名 IP 会在你的提示词引用大型知识产权持有者拥有的角色时触发——比如标志性的动画角色、电子游戏主角或漫画超级英雄。这是你更可能看到 finishReason: OTHER 而非 blockReason: OTHER 的类别之一,因为版权检测通常发生在图像合成过程中,当生成的图像开始像某个受保护的角色时才被发现,即使你的提示词文本并没有明确提到角色名称。
公众人物和名人在 2026 年 3 月被大幅收紧。此前,在非争议性语境中引用公众人物的提示词(如"一个长得像[某名人]的人在演讲")有时能通过。2026 年 3 月的策略更新扩展了检测范围,能够捕获更多间接引用和艺术风格模仿。如果你之前能生成可辨识公众人物图像的提示词现在返回 blockReason OTHER,这次策略变更是最可能的原因。
未成年人保护是最严格的类别,实行零容忍政策。任何可能生成未成年人处于不当或剥削性场景的图像的提示词都会被立即拦截。根据 GitHub Issue #276 的确认,这是一项法律要求,Google 已声明永远不会有绕过方式。这个过滤器的误报率最高,有时会误捕关于儿童插画或家庭照片的无害提示词。
水印移除针对的是要求移除、替换或遮盖参考图像中水印的提示词。这专门适用于提供参考图像并指示模型移除品牌或版权标识的图像编辑工作流。
金融信息篡改是在 2026 年 3 月策略更新中新增的类别。请求生成或修改金融文件、货币、支票、银行对账单或官方身份证件的提示词现在会触发 blockReason OTHER。此类内容之前的处理优先级较低,经常能通过第二层。
换装和换脸在 2026 年 3 月加强了执行力度。要求交换图像之间的面部、将某人的肖像放置到不同的身体上,或以可能产生误导性图像的方式更改某人服装的提示词,现在会被更积极地拦截。当涉及的对象是可辨识的人物时,这一类别与公众人物类别有重叠。
隐性暗示内容是最微妙的类别,也是最难预测的。它会捕获那些没有明确请求不当内容,但使用了暗语、委婉表达或上下文组合,模型将其解读为暗示性的提示词。该类别在 2026 年 3 月被扩展,以捕获更多间接措辞模式,这就是为什么之前看似无害的提示词现在可能触发拦截。
实际要点是,第二层的分析维度是内容语义级别而非关键词级别。仅仅避免某些词语是不够的——模型会评估整个提示词的语义含义和可能的视觉输出。下面的解决方案部分提供了规避内容过滤的具体策略,同时仍能实现你期望的创意产出。
绕过 blockReason OTHER 的 5 种经过验证的解决方案
由于 blockReason OTHER 无法通过安全设置来解决,以下解决方案采取了不同的思路:修改输入内容、重构工作流程或路由到替代模型。这些方案按从简单到最稳健的顺序排列,在生产环境中,你很可能需要实现多种方案作为分层回退策略。
**方案 1:改写提示词以消除触发模式。**最直接的方法是识别并移除触发拦截的特定语言模式。由于第二层分析的是语义含义而非仅仅是关键词,有效的改写不能只是简单的词语替换。将角色名称替换为通用描述(用"一只友好的卡通动物"代替具体角色名),将名人引用替换为特征描述(用"一位留着深色短发正在做演讲的职业女性"代替直接点名),将复合概念拆分为更简单的独立提示词。如果复杂的场景描述触发了拦截,尝试单独生成各个元素,然后再组合。
**方案 2:移除所有版权和名人引用。**这是方案 1 的更激进版本,专门针对导致大多数 blockReason OTHER 错误的两个类别。审查你的提示词中是否包含任何品牌角色引用、商标视觉风格、与特定艺术家相关的可辨识艺术风格、名人名字或可能识别出公众人物的描述,以及任何品牌标志或产品设计。即使是间接引用,如"以[著名艺术家]的风格",如果该风格与受版权保护的作品密切相关,也可能触发拦截。
**方案 3:将复杂提示词拆分为更简单的部分。**组合多个概念的复杂提示词触发第二层拦截的概率更高,因为每增加一个概念都会增加组合语义含义越过策略边界的风险。将单个复杂提示词拆分为 2-3 个更简单的生成请求,然后组合结果,往往在组合提示词失败的地方能够成功。例如,与其用"一个穿特定服装的人在特定地标做特定动作",不如分别生成场景和人物。
**方案 4:添加超时和自动模型回退。**对于生产应用,最可靠的方法是在 Nano Banana 2 返回 blockReason OTHER 时自动回退到替代图像模型。这承认了某些提示词将始终被第二层拦截的现实,确保你的应用保持功能正常。一些 API 代理服务如 laozhang.ai 在统一端点后聚合了多个图像模型,使得在 Nano Banana 2 和替代模型之间实现回退变得非常简单,无需管理多个 API 集成。
pythonimport asyncio from google import genai async def generate_with_fallback(prompt, timeout_seconds=30): """使用 Nano Banana 2 生成图像,失败时回退到替代方案。""" client = genai.Client(api_key="YOUR_GEMINI_KEY") try: # 带超时地尝试 Nano Banana 2 response = await asyncio.wait_for( asyncio.to_thread( client.models.generate_content, model="gemini-3.1-flash-image-preview", contents=prompt, config=types.GenerateContentConfig( response_modalities=["IMAGE", "TEXT"], ) ), timeout=timeout_seconds ) # 检查 blockReason OTHER if hasattr(response, 'prompt_feedback') and response.prompt_feedback: if getattr(response.prompt_feedback, 'block_reason', None) == 'OTHER': print("检测到第二层拦截,正在回退...") return await fallback_generate(prompt) # 检查 candidates 是否为空(防止 SDK 挂起) if not response.candidates or len(response.candidates) == 0: print("candidates 为空,正在回退...") return await fallback_generate(prompt) return response except asyncio.TimeoutError: print(f"超时 {timeout_seconds} 秒,正在回退...") return await fallback_generate(prompt) async def fallback_generate(prompt): """回退到替代图像模型。""" # 示例:通过替代 API 使用 GPT Image 或 FLUX.2 # 具体实现取决于你选择的回退模型 pass
**方案 5:使用 GPT Image 或 FLUX.2 作为主要回退。**当你的内容需求本身与 Google 的第二层策略冲突时——例如,如果你需要为新闻或编辑目的生成可辨识的公众人物图像——唯一可靠的解决方案是使用具有不同内容策略的其他图像生成模型。OpenAI 的 GPT Image(DALL-E 4o)有不同的策略边界,可能接受 Nano Banana 2 拒绝的提示词,反之亦然。通过各种提供商可用的 FLUX.2 模型提供了另一套内容策略。在生产环境中,维护对 2-3 个不同图像生成 API 的访问,确保提供商之间的策略差异成为你的安全网,而不是瓶颈。
生产级错误处理
从开发调试转向生产可靠性,需要全面的错误处理来应对我们讨论过的所有失败模式。以下实现提供了一个完整的 Nano Banana 2 错误处理封装,能够防止 python-genai SDK 挂起 bug、正确区分第一层和第二层拦截、实现自动重试回退,并提供结构化日志用于监控。
pythonimport time import logging from dataclasses import dataclass from enum import Enum from typing import Optional logger = logging.getLogger(__name__) class BlockType(Enum): NONE = "none" LAYER_1_SAFETY = "layer_1_safety" LAYER_2_OTHER = "layer_2_other" LAYER_2_IMAGE_SAFETY = "layer_2_image_safety" LAYER_2_COPYRIGHT = "layer_2_copyright" LAYER_2_PROHIBITED = "layer_2_prohibited" SDK_HANG = "sdk_hang" UNKNOWN = "unknown" @dataclass class GenerationResult: success: bool block_type: BlockType image_data: Optional[bytes] = None error_message: str = "" latency_ms: int = 0 model_used: str = "" def safe_generate_image(client, prompt: str, model: str = "gemini-3.1-flash-image-preview") -> GenerationResult: """生产环境安全的图像生成,包含全面的错误处理。""" start_time = time.time() try: response = client.models.generate_content( model=model, contents=prompt, config=types.GenerateContentConfig( response_modalities=["IMAGE", "TEXT"], safety_settings=[ types.SafetySetting(category=cat, threshold="BLOCK_NONE") for cat in [ "HARM_CATEGORY_HARASSMENT", "HARM_CATEGORY_HATE_SPEECH", "HARM_CATEGORY_SEXUALLY_EXPLICIT", "HARM_CATEGORY_DANGEROUS_CONTENT", ] ], ), ) latency = int((time.time() - start_time) * 1000) # 检查 1:提示词级拦截(blockReason) if hasattr(response, 'prompt_feedback') and response.prompt_feedback: block_reason = getattr(response.prompt_feedback, 'block_reason', None) if block_reason == 'SAFETY': logger.warning(f"Layer 1 block: {prompt[:80]}...") return GenerationResult( success=False, block_type=BlockType.LAYER_1_SAFETY, error_message="Layer 1 safety filter triggered. Adjust safety_settings.", latency_ms=latency, model_used=model, ) if block_reason == 'OTHER': logger.warning(f"Layer 2 block: {prompt[:80]}...") return GenerationResult( success=False, block_type=BlockType.LAYER_2_OTHER, error_message="Layer 2 policy block. Cannot bypass via settings.", latency_ms=latency, model_used=model, ) # 检查 2:candidates 为空(防止 SDK 挂起) if not response.candidates or len(response.candidates) == 0: logger.warning(f"Empty candidates for: {prompt[:80]}...") return GenerationResult( success=False, block_type=BlockType.SDK_HANG, error_message="Empty candidates array. Likely silent Layer 2 block.", latency_ms=latency, model_used=model, ) # 检查 3:生成级拦截(finishReason) candidate = response.candidates[0] finish_reason = getattr(candidate, 'finish_reason', 'STOP') finish_reason_map = { 'SAFETY': BlockType.LAYER_1_SAFETY, 'IMAGE_SAFETY': BlockType.LAYER_2_IMAGE_SAFETY, 'OTHER': BlockType.LAYER_2_COPYRIGHT, 'PROHIBITED_CONTENT': BlockType.LAYER_2_PROHIBITED, } if finish_reason in finish_reason_map: return GenerationResult( success=False, block_type=finish_reason_map[finish_reason], error_message=f"Generation blocked: finishReason={finish_reason}", latency_ms=latency, model_used=model, ) # 检查 4:提取图像数据 for part in candidate.content.parts: if hasattr(part, 'inline_data') and part.inline_data: return GenerationResult( success=True, block_type=BlockType.NONE, image_data=part.inline_data.data, latency_ms=latency, model_used=model, ) # 响应中未找到图像 return GenerationResult( success=False, block_type=BlockType.UNKNOWN, error_message="Response contained no image data.", latency_ms=latency, model_used=model, ) except Exception as e: latency = int((time.time() - start_time) * 1000) logger.error(f"Exception during generation: {e}") return GenerationResult( success=False, block_type=BlockType.UNKNOWN, error_message=str(e), latency_ms=latency, model_used=model, )
这个实现中的几个关键防御性编程模式值得重点强调。首先,对 response.candidates 的每次访问都有长度检查保护,防止了 python-genai SDK 的挂起 bug——这个问题已经困扰了很多开发者。其次,函数返回结构化的结果对象而不是抛出异常,使其在异步管道和重试逻辑中使用更安全。第三,拦截类型分类使你的监控系统能够精确追踪正在发生的拦截类型及其频率,为你提供优化提示词所需的数据。
对于生产部署,像 laozhang.ai 这样的平台提供跨多个图像生成模型的统一 API 端点,简化了方案 4 中描述的回退策略的实现。你不需要为每个回退模型管理单独的 API 客户端,而是通过单一端点路由,让平台处理模型选择和错误恢复。
这个实现中的日志设计特意支持了监控仪表盘。通过跟踪每个请求的 block_type、latency_ms 和 model_used,你可以构建针对第二层拦截异常峰值的告警(这可能表示策略变更),追踪提示词改写工作的效果,以及识别哪些提示词需要路由到替代模型。
常见问题
能否完全禁用 Nano Banana 2 的安全过滤器?
你可以通过将所有四个危害类别(HARM_CATEGORY_HARASSMENT、HARM_CATEGORY_HATE_SPEECH、HARM_CATEGORY_SEXUALLY_EXPLICIT、HARM_CATEGORY_DANGEROUS_CONTENT)设置为 BLOCK_NONE 或 OFF 来禁用第一层安全过滤器。但是,第二层策略执行无法通过任何 API 参数、SDK 配置或账户设置来禁用。这意味着即使移除了所有可配置的安全设置,违反 Google 服务条款、版权法或儿童安全要求的内容仍然会被拦截。区别在于:第一层保护用户免受潜在有害的 AI 输出,第二层保护 Google 免受法律责任。两者都是必要的,但只有第一层是可配置的。
BLOCK_NONE 和 OFF 有什么区别?
两种设置都能阻止第一层的自动拦截,但在元数据行为上有所不同。BLOCK_NONE 禁用拦截但仍然在响应中返回安全评级,告诉你检测到了哪些类别以及置信度级别,这对监控和审计很有用。OFF 则完全禁用拦截和元数据收集,意味着你在响应中不会获得任何安全信息。对于自 gemini-2.5-flash 起的模型(根据 Vertex AI 文档,截至 2026 年 1 月),OFF 是默认设置。实际建议是在开发阶段使用 BLOCK_NONE(这样你可以看到什么触发了安全评级),在生产环境中如果不需要安全元数据则使用 OFF(可获得略快的响应速度)。
为什么之前能用的提示词现在被拦截了?
如果 2026 年 1 月或 2 月能用的提示词现在返回 blockReason OTHER,最可能的原因是 Google 的 2026 年 3 月策略更新。此次更新收紧了四个特定类别的执行力度:公众人物和名人(更广泛的间接引用检测)、金融信息篡改(之前处理优先级较低)、换装和换脸(更积极的检测),以及隐性暗示内容(扩展的模式识别)。如果你的提示词涉及这些领域中的任何一个,它们现在可能触发之前不会触发的拦截。修复方法是审查并改写受影响的提示词,特别是移除对可辨识个人或金融文件的任何间接引用。
免费套餐 API 是否支持使用 Nano Banana 2 生成图像?
Google AI Studio 的免费套餐提供 Gemini 模型的文本生成访问,但通过 API 进行图像生成需要付费方案。虽然你可以在 Google AI Studio 的网页界面上使用免费套餐体验图像生成功能,但使用 Nano Banana 2(gemini-3.1-flash-image-preview)进行程序化 API 图像生成需要在你的 Google Cloud 项目上启用计费。这与 blockReason OTHER 问题是分开的,后者在免费和付费套餐上都可能出现——区别在于免费套餐用户可能根本到不了出现 blockReason OTHER 的阶段,因为图像生成请求会在配额层面就被拒绝。
如何判断 blockReason OTHER 是否由地区限制导致?
欧盟地区的开发者可能因基于 IP 的策略执行而更频繁地遇到 blockReason OTHER,这种执行会在某些司法管辖区应用更严格的内容过滤器。要确定你的拦截是基于地区还是基于内容,可以从不同的地理区域测试完全相同的提示词(使用 VPN 或部署在不同区域的云函数)。如果同一提示词从其他区域成功但从你的区域失败,则拦截是地区性的。在这种情况下,从策略限制较宽松的区域的服务器(如美国的云基础设施)部署你的 API 调用是合规的解决方案,前提是你的使用场景符合该区域适用的服务条款。