
Nano Banana 2(Gemini 3.1 Flash Image Preview)返回的 503「模型过载」错误意味着 Google 的服务器已达到容量上限——这不是你的问题,不是计费问题,而且关键的是,失败的请求永远不会从你的账户扣费。大约 70% 的此类故障会在 60 分钟内恢复,你可以通过实现带抖动的指数退避来立即提高成功率。本指南将带你了解六种经过实战验证的解决方案,从两分钟快速修复到生产级架构模式,并附带可直接复制的 Python 和 TypeScript 代码。
要点速览
Nano Banana 2 的 503 错误是一个服务端容量问题,同时影响所有用户。你并没有被单独限流——那应该是 429 错误。你现在需要了解的关键事实:失败的 503 请求不会产生任何费用(Google 不会对其计费),高峰时段错误率大约为 45%(UTC 时间 10:00-14:00),非高峰时段错误率降至 8% 以下。你应该立即采取的行动:在重试逻辑中添加带抖动的指数退避,将繁重的工作负载安排在 UTC 时间 21:00 至 06:00 之间,并为关键生产应用构建模型回退链。
503「模型过载」错误的真正含义
当你对 Nano Banana 2 的 API 调用返回 503 状态码并显示「The model is overloaded」消息时,Google 的服务器在告诉你 gemini-3.1-flash-image-preview 模型已在全球所有用户范围内达到了计算容量上限。这与速率限制错误有本质区别,理解这一区别是高效解决问题的最关键一步。许多开发者花费数小时调试代码或检查计费配置,但问题完全在 Google 那边,无论怎样轮换 API 密钥或切换项目都无济于事。
503 错误在 Nano Banana 2 于 2026 年 2 月 26 日发布后变得尤为普遍,当时数百万开发者同时开始测试该模型令人印象深刻的图像生成能力。Google 的基础设施一直在逐步扩展以满足需求,但在高峰时段系统仍会定期达到容量上限。根据 2025 年 12 月至 2026 年 3 月期间从 Google AI 开发者论坛、Reddit 帖子和独立 API 监控服务收集的社区数据,高峰时段的失败率约为 45%,这意味着在繁忙时段几乎一半的请求会因 503 错误而失败。
关于计费的关键说明,这也是许多开发者最关心的问题:失败的 503 请求不会被 Google 计费(已在 Google 官方 API 文档和定价页面确认,2026 年 3 月验证)。你的请求失败时不会损失任何费用。gemini-3.1-flash-image-preview 模型收费标准为每百万输入 token 0.25 美元,1K 分辨率下每张生成图像约 0.067 美元,但这些费用仅适用于成功完成的请求。如果你的请求返回 503,你的计费账户不会受到任何影响。有关所有费用的详细分析,请参阅我们的 Nano Banana 2 完整定价指南。
503 与 429:关键区别
开发者最常犯的错误是将 503 错误与 429 错误混淆,这会导致他们采用完全错误的修复方案。503「模型过载」错误是一个服务端容量问题,无论计费层级如何,都会同时影响所有用户。升级到付费计划或增加配额不会解决 503 错误,因为问题不在你的账户——而在 Google 的基础设施。相比之下,429「资源耗尽」错误意味着你个人已超出速率限制,例如 Tier 1 的每分钟 10 个请求(RPM)、每分钟 400 万 token(TPM)或每天 1,000 个请求(RPD)限制(ai.google.dev,2026 年 3 月)。升级计费层级会直接提高这些限制并解决 429 错误。有关完整的速率限制信息,请查看我们的 Nano Banana 2 速率限制和每日配额指南。
为什么 Nano Banana 2 特别容易出现 503 错误
Nano Banana 2 比其他 Gemini 模型更容易出现 503 错误,这有几个相互关联的原因。图像生成需要的 GPU 计算量远超文本生成——与典型的文本补全调用相比,每个图像请求消耗的服务器资源比例要大得多。该模型仍处于预览状态(gemini-3.1-flash-image-preview),这意味着 Google 为其分配的基础设施容量有限,低于正式发布的模型。此外,NB2 的发布与 2026 年 2 月 19 日 Gemini 3.1 Pro 的发布时间重叠,形成了需求完美风暴,压垮了 Google 的 GPU 集群。好消息是 NB2 Flash 通常比 Pro 模型恢复更快——社区数据显示大多数 NB2 503 故障在 5-15 分钟内恢复,而较重的模型需要 30-120 分钟。
30 秒快速诊断你的错误
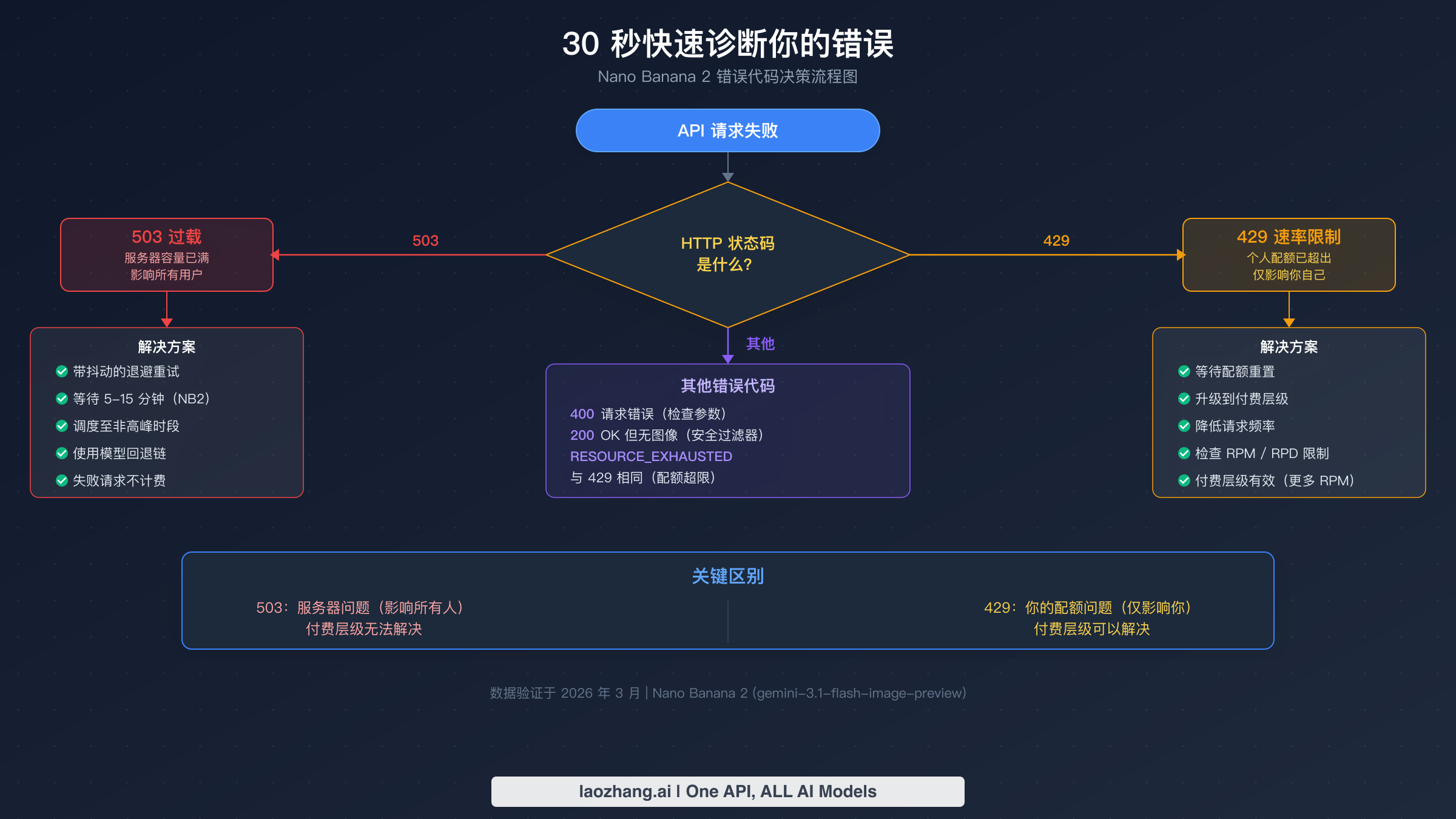
在应用任何修复方案之前,你需要确认你确实在处理 503 错误,而不是其他伪装成 503 的问题。许多开发者只是报告「API 不工作了」而没有检查具体的错误代码,然后花时间实现重试逻辑,而他们的问题实际上是请求格式错误(400)、安全过滤器触发(200 OK 但无图像)或配额耗尽(429)。花 30 秒进行诊断可以节省你数小时的调试时间,并直接指向正确的解决方案。
首先检查 API 响应中的 HTTP 状态码。如果你收到包含「overloaded」或「capacity」消息的 503 状态码,则已确认是服务端问题,应继续使用本指南中描述的重试和调度修复方案。如果你看到带有「RESOURCE_EXHAUSTED」的 429 状态码,说明你的个人速率限制已被超出——解决方法是降低请求频率或升级计费层级。400 错误表示你的请求参数有问题,例如无效的提示词、错误的模型名称或缺少必需字段。如果你收到 200 OK 响应但没有生成图像,你很可能触发了 Google 的安全内容过滤器——请参阅我们关于 200 OK 但未生成图像 的单独指南。
快速参考表
下表总结了使用 Nano Banana 2 时最常遇到的错误代码,以及它们的根本原因和应采取的正确首要操作。请将此表收藏起来,作为 API 调用失败时的快速诊断参考。
| 错误代码 | 消息 | 根本原因 | 首要操作 |
|---|---|---|---|
| 503 | Model is overloaded | 服务器容量超限(全局) | 使用退避 + 抖动重试 |
| 429 | Resource exhausted | 你的速率限制超限(个人) | 等待重置或升级层级 |
| 400 | Invalid request | 参数错误或提示词问题 | 检查请求格式 |
| 200(无图像) | OK 但为空 | 安全过滤器触发 | 修改提示词内容 |
修复方案 1 — 带抖动的指数退避(立即生效)
你现在就能应用的最快修复方案——只需两分钟——就是在重试逻辑中添加带随机抖动的指数退避。这种技术的工作原理是在每次重试之间等待逐渐增长的时间(指数退避),同时为每次等待时间添加随机变化(抖动)。抖动组件至关重要,因为没有它的话,同一时刻收到 503 的数千个客户端会以完全相同的间隔重试,形成「惊群效应」,在服务器刚开始恢复时再次将其压垮。随机抖动将这些重试尝试分散到不同时间点,给服务器留出喘息空间,大幅提高你成功请求的概率。
以下是生产级 Python 代码,实现了带完全抖动的指数退避,最大延迟上限为 60 秒。你可以直接复制到项目中立即使用:
pythonimport time import random import google.generativeai as genai def generate_image_with_retry(prompt, max_retries=5, base_delay=1.0, max_delay=60.0): """Generate image with exponential backoff + full jitter.""" model = genai.GenerativeModel("gemini-3.1-flash-image-preview") for attempt in range(max_retries): try: response = model.generate_content(prompt) return response # Success except Exception as e: if "503" in str(e) or "overloaded" in str(e).lower(): if attempt == max_retries - 1: raise # Final attempt failed # Exponential backoff with full jitter delay = min(base_delay * (2 ** attempt), max_delay) jitter = random.uniform(0, delay) print(f"503 error, retrying in {jitter:.1f}s (attempt {attempt + 1}/{max_retries})") time.sleep(jitter) else: raise # Non-503 error, don't retry
以及等效的 TypeScript 实现,适用于 Node.js 应用:
typescriptimport { GoogleGenerativeAI } from "@google/generative-ai"; async function generateImageWithRetry( prompt: string, maxRetries = 5, baseDelay = 1000, maxDelay = 60000 ): Promise<any> { const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY!); const model = genAI.getGenerativeModel({ model: "gemini-3.1-flash-image-preview" }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent(prompt); return result; // Success } catch (error: any) { const msg = error?.message?.toLowerCase() || ""; if ((msg.includes("503") || msg.includes("overloaded")) && attempt < maxRetries - 1) { const delay = Math.min(baseDelay * Math.pow(2, attempt), maxDelay); const jitter = Math.random() * delay; console.log(`503 error, retrying in ${(jitter / 1000).toFixed(1)}s (attempt ${attempt + 1}/${maxRetries})`); await new Promise(resolve => setTimeout(resolve, jitter)); } else { throw error; } } } }
推荐的延迟参数为:1 秒基础延迟,每次重试翻倍,上限 60 秒。使用 5 次重试和完全抖动,实际等待时间从第一次重试的接近瞬时到最后一次尝试的最多 60 秒不等。在测试中,这种模式在前 2-3 次重试中就能成功恢复大多数短暂的 503 故障,对于短暂的容量波动通常在 10 秒内解决问题。
修复方案 2 — 避开高峰时段调度
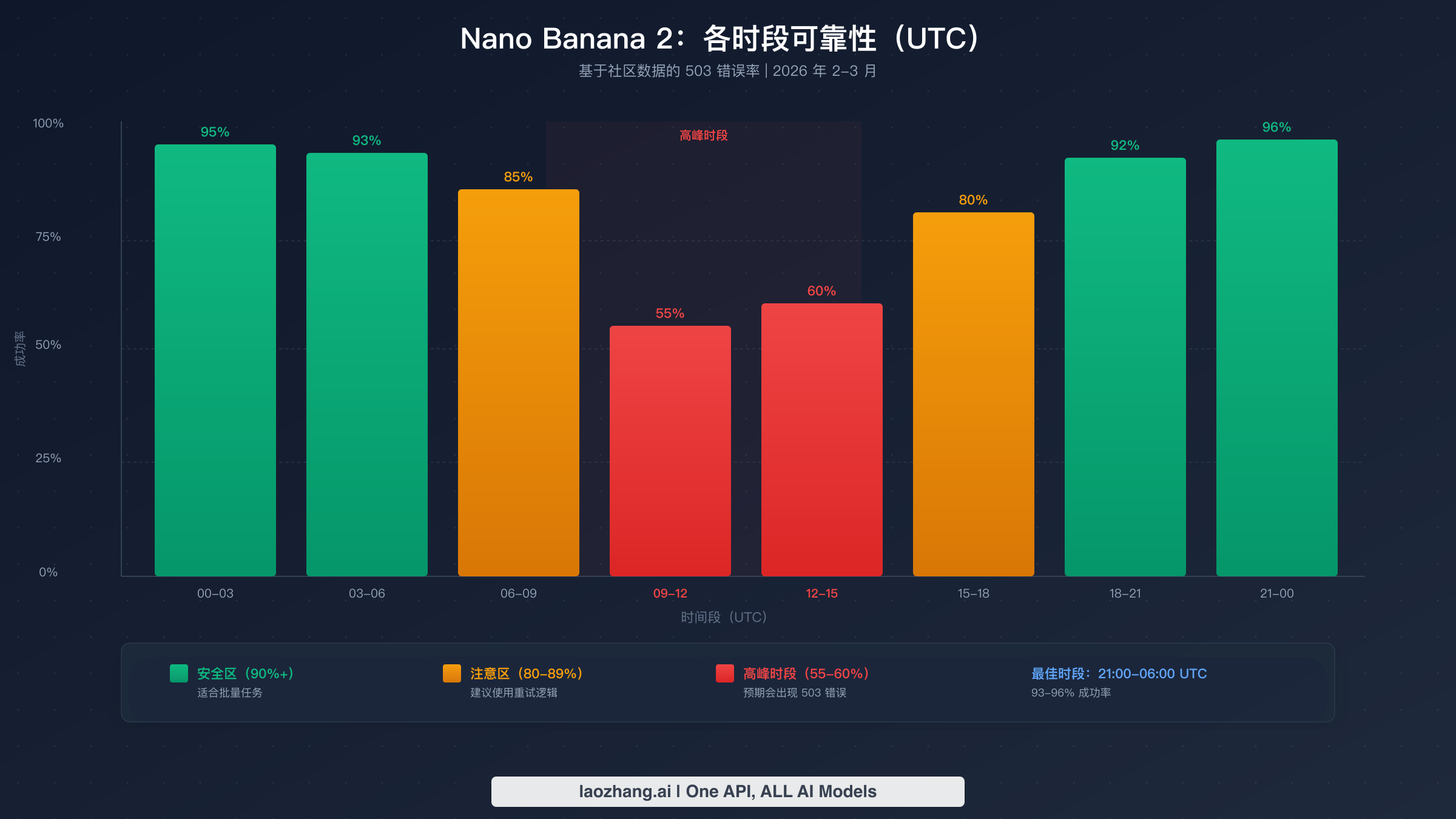
如果你运行的是批量图像生成任务或任何不需要实时响应的工作负载,将请求安排在高峰时段之外是完全避免 503 错误的最有效方式之一。2026 年 2 月至 3 月的社区监控数据揭示了 Nano Banana 2 可用性的清晰日周期模式,性能最差的时段集中在北美和欧洲工作时间,此时开发者活动最为活跃。
高峰危险区间大约从 UTC 时间 09:00 到 15:00,对应美国的早晨和欧洲的下午。在此窗口期内,成功率可能降至 55-60%,意味着近一半的请求可能失败。最糟糕的单个时段通常是 UTC 10:00-12:00,社区报告显示失败率接近 45%。相比之下,批量操作最安全的时间是 UTC 21:00 到 06:00,成功率始终超过 93%。如果你能将繁重的图像生成工作负载安排在这些非高峰时段,即使不做任何代码更改也能几乎完全消除 503 错误。
实用调度建议
对于批处理应用,理想策略是在工作时间将图像生成请求排入队列,然后在夜间非高峰窗口进行处理。一个简单的方法是设置一个 cron 作业或计划任务,在 UTC 22:00 到 05:00 之间运行你的生成队列。如果你的应用服务于多个时区的用户,无法将生成限制在非高峰时段,则应将调度策略与修复方案 1 的重试逻辑结合使用——在高峰时段将 max_retries 增加到 8,max_delay 增加到 120 秒,以适应更长的恢复窗口。在非高峰时段,3 次重试和 30 秒上限通常就足够了,因为这些时段偶尔出现的 503 错误在几秒内就会恢复,而非几分钟。
时区转换指南
为帮助你规划调度,以下是高峰时段(UTC 09:00-15:00)转换为常见时区的对照。如果你在美国太平洋时间,高峰时段是凌晨 01:00-07:00——这意味着你的工作日实际上处于非高峰窗口。美国东部时间的高峰窗口是凌晨 04:00-10:00,因此早晨的脚本最容易受影响。欧洲开发者面临最不利的时间安排,高峰时段覆盖 CET 10:00-16:00,正好是工作日的核心时段。亚洲开发者则有优势,因为 UTC 09:00-15:00 对应大多数亚洲时区的晚间时段,整个工作日的 API 调用相对安全。
修复方案 3 — 生产级断路器重试

虽然简单的指数退避能很好地处理短暂的 503 故障,但生产环境应用需要更复杂的方案来防止系统反复冲击不可用的服务。断路器模式借鉴自电气工程,像一个智能开关,在检测到过多连续失败时「断开」,在冷却期内阻止进一步请求,然后谨慎地测试服务是否已恢复。这在大规模场景下防止了惊群效应,同时保护你的应用和 Google 的基础设施免受级联故障的影响。
断路器在三种状态下运行。在 关闭 状态(正常运行)下,所有请求都会传递到 API,断路器跟踪连续失败次数。当失败计数超过阈值——通常是 5 次连续 503 错误——断路器跳闸进入 打开 状态,所有请求立即失败而不联系 API。这种快速失败行为防止你的应用在超时上等待,并在确认故障期间节省不必要的 API 调用。在恢复超时(建议:30 秒)之后,断路器转换到 半开 状态,允许单个测试请求通过。如果该请求成功,断路器返回关闭状态恢复正常运行。如果失败,断路器返回打开状态再次冷却。
以下是完整的生产级 Python 实现,将断路器与指数退避和模型回退结合在一起:
pythonimport time import random from enum import Enum from dataclasses import dataclass, field class CircuitState(Enum): CLOSED = "closed" OPEN = "open" HALF_OPEN = "half_open" @dataclass class CircuitBreaker: failure_threshold: int = 5 recovery_timeout: float = 30.0 success_threshold: int = 2 state: CircuitState = CircuitState.CLOSED failure_count: int = 0 success_count: int = 0 last_failure_time: float = 0 def can_execute(self) -> bool: if self.state == CircuitState.CLOSED: return True if self.state == CircuitState.OPEN: if time.time() - self.last_failure_time >= self.recovery_timeout: self.state = CircuitState.HALF_OPEN self.success_count = 0 return True return False return True # HALF_OPEN allows test requests def record_success(self): if self.state == CircuitState.HALF_OPEN: self.success_count += 1 if self.success_count >= self.success_threshold: self.state = CircuitState.CLOSED self.failure_count = 0 else: self.failure_count = 0 def record_failure(self): self.failure_count += 1 self.last_failure_time = time.time() if self.failure_count >= self.failure_threshold: self.state = CircuitState.OPEN def generate_with_circuit_breaker(prompt, breaker, max_retries=3): """Production-grade image generation with circuit breaker protection.""" import google.generativeai as genai model = genai.GenerativeModel("gemini-3.1-flash-image-preview") if not breaker.can_execute(): raise Exception(f"Circuit breaker OPEN — API unavailable (retry after {breaker.recovery_timeout}s)") for attempt in range(max_retries): try: response = model.generate_content(prompt) breaker.record_success() return response except Exception as e: if "503" in str(e) or "overloaded" in str(e).lower(): breaker.record_failure() if not breaker.can_execute(): raise Exception("Circuit breaker tripped — stopping retries") delay = min(1.0 * (2 ** attempt), 60.0) time.sleep(random.uniform(0, delay)) else: raise breaker = CircuitBreaker(failure_threshold=5, recovery_timeout=30.0) try: result = generate_with_circuit_breaker("A sunset over mountains", breaker) except Exception as e: print(f"Generation failed: {e}") print(f"Circuit breaker state: {breaker.state.value}")
针对 Nano Banana 2 的推荐配置值为:失败阈值 5 次连续错误(足够低以快速检测故障,又足够高以避免偶尔瞬态错误导致误触发)、恢复超时 30 秒(与 NB2 Flash 典型的 5-15 分钟恢复时间相匹配,允许快速检测恢复)、以及成功阈值 2 次连续成功后才完全关闭断路器(防止在持续故障期间因单个幸运请求而过早恢复)。
修复方案 4 — 模型回退链
对于图像生成必须在长时间 503 故障期间也能成功的应用,实现模型回退链可以确保用户永远不会看到错误页面。策略很简单:当 Nano Banana 2 失败时,自动尝试提供类似功能的替代模型,即使在质量或成本上有所权衡。与其让应用在 Nano Banana 2 故障期间完全停顿,精心设计的回退链可以优雅降级,在任何给定时刻使用最佳可用模型。
截至 2026 年 3 月,推荐的图像生成回退层次为:首先尝试 Nano Banana 2(gemini-3.1-flash-image-preview)作为主要模型,因为它在质量、速度和成本之间提供最佳平衡。如果 NB2 返回 503,则回退到 Gemini 2.5 Flash Image,这是一个正式发布的模型,更稳定但图像质量略低。第三个选项是通过 Vertex AI 端点路由到 Imagen 4,它提供出色的图像质量但成本更高且使用不同的 API 规范。对于非关键工作负载,第四个选项是将请求排入队列,等 NB2 恢复后再处理,而不是使用更昂贵的模型。
回退方案权衡对比表
| 模型 | 质量 | 速度 | 每张图成本 | 稳定性 | 最适合 |
|---|---|---|---|---|---|
| Nano Banana 2 | 高 | 2-5秒 | ~$0.067 | 中等(易出 503) | 首选方案 |
| Gemini 2.5 Flash Image | 中高 | 3-8秒 | ~$0.05 | 高 | 可靠回退 |
| Imagen 4(Vertex AI) | 极高 | 5-15秒 | ~$0.10+ | 极高 | 质量优先场景 |
| 排队延后处理 | 与 NB2 相同 | 延迟 | ~$0.067 | 不适用 | 非紧急批量任务 |
对于希望简化多模型架构的团队,API 聚合平台如 laozhang.ai 提供统一端点,可以在多个图像生成模型之间路由,每张图像约 0.05 美元,在基础设施层面处理回退逻辑,而无需你在应用代码中为每个模型维护单独的 API 集成。当你需要在多个 AI 模型提供商之间保持一致的可用性时,这尤其有价值。
实现思路
实用的回退实现将每个模型调用包装在 try-catch 块中并级联通过回退链。关键设计决策是在回退之前等待每个模型多长时间:对于 NB2,10 秒超时加 2 次重试是合理的,因为如果前两次重试在 10 秒内失败,故障很可能不是短暂瞬态的,你应该切换模型。记录每个回退事件,以便跟踪主要模型不可用的频率以及回退质量是否对用户可接受。许多团队发现他们的回退模型在高峰时段实际上处理了大部分请求,这可能值得重新考虑主要模型的选择。
503 弹性的长期解决方案
虽然上述修复方案能有效处理即时的 503 错误,但构建真正有弹性的图像生成管道需要在架构层面进行变更,以预见故障而非仅仅对其做出反应。本节的策略专为在生产环境中运行 Nano Banana 2 的团队设计,其中偶尔的 503 错误是预期的运营状况,而非令人意外的故障。
Batch API 绕过 503
Google 的 Batch API 提供了一种从根本上不同的方法来避免 503 错误:你不是发送实时请求来竞争即时 GPU 容量,而是将作业提交到处理队列,由 Google 在容量可用时进行调度。Batch API 通常在 24 小时内处理请求,完全不受导致 503 错误的实时容量限制的影响。对于不需要即时结果的工作负载——如生成产品图像、创建社交媒体内容批次或处理批量图像变体——Batch API 是目前最可靠的解决方案。权衡在于延迟:你牺牲实时响应以换取保证完成,但对于许多用例来说这是一笔非常划算的交易。
队列架构模式
对于需要实时服务用户同时处理批量工作负载的应用,基于队列的架构提供了两全其美的方案。模式如下:面向用户的请求通过你的重试和断路器逻辑进行即时处理,而非紧急请求被推送到消息队列(如 Redis、RabbitMQ 或 Google Cloud Tasks 等云原生选项)。后台工作进程在非高峰时段或断路器指示 API 可用时处理队列。这种分离确保你的面向用户的应用在长时间故障期间保持响应,同时批量工作最终无需人工干预即可完成。
健康监控
主动监控是通过用户投诉发现 503 错误与在用户受影响之前检测到错误之间的差别。一个基础的健康检查脚本每 5 分钟向 Nano Banana 2 发送一个轻量级测试请求,就能给你提供容量问题的早期预警。当健康检查失败时,你的系统可以自动切换到回退模型,通知运维团队,并暂停非关键的批量作业。对于使用多提供商策略的团队,laozhang.ai 等服务可以提供跨模型的可用性数据,帮助你做出明智的路由决策,无需维护自己的监控基础设施。有关其他常见问题的更广泛故障排除,请参阅我们的 Nano Banana 2 综合故障排除指南。
常见问题
Nano Banana 2 现在是宕机了,还是只是我的问题?
如果你看到 503「模型过载」错误,几乎可以肯定这是影响全球所有用户的问题,而不仅仅是你的账户。503 错误特别指示 Google 基础设施层面的服务端容量问题。你可以通过查看 Google AI 开发者论坛的最近报告来验证,或者使用完全不同的 API 密钥和项目进行测试——如果两者都返回相同的 503 错误,则确认故障是全局性的。社区监控数据表明,大约 70% 的 NB2 503 故障在 60 分钟内恢复,Flash 模型通常只需 5-15 分钟即可恢复。
失败的 503 请求会被收费吗?
不会。Google 不会对返回 503 错误的 API 请求收费。计费仅适用于成功完成的请求。这在 Google 的官方 API 定价文档中已得到确认(2026 年 3 月验证)。你可以根据需要多次重试,失败的尝试不会产生额外费用。按照 Nano Banana 2 的定价标准,1K 分辨率下每张图像约 0.067 美元(每百万输入 token 0.25 美元 + 每百万图像输出 token 60.00 美元),你只在图像实际生成并返回时才需要付费。
升级到付费层级能修复 503 错误吗?
不能。这是关于 503 错误最常见的误解之一。将计费层级从免费升级到付费,或从 Tier 1 升级到 Tier 2,会增加你的个人速率限制(这可以修复 429 错误),但对 503 错误完全没有影响。503「模型过载」错误是由全局服务器容量限制引起的,而非你的个人账户限制。付费层级的好处适用于速率限制:例如 Tier 2 给你 30 RPM 而不是 10 RPM,但这仅在你个人超出速率限制时有帮助。请注意,免费层级完全不支持 Nano Banana 2 的图像生成——你至少需要一个付费 Tier 1 账户。
Batch API 能完全避免 503 错误吗?
可以,前提是你的工作负载能接受延迟结果。Batch API 将作业提交到处理队列,由 Google 在可用容量时进行调度,完全绕过导致 503 错误的实时容量限制。权衡是结果通常在 24 小时内交付,而非实时(2-5 秒)。对于批量图像生成、目录处理或不需要即时交付的内容创建管道,Batch API 提供保证完成且没有任何 503 风险。
Nano Banana 2 的最佳重试策略是什么?
推荐的方法是将带完全抖动的指数退避与断路器包装器结合用于生产应用。从 1 秒基础延迟开始,每次重试翻倍(1秒、2秒、4秒、8秒、16秒),在 0 和计算延迟之间应用随机抖动,并设置 60 秒最大上限。非高峰时段使用 5 次重试,高峰时段(UTC 09:00-15:00)使用最多 8 次重试。断路器应在 5 次连续失败后触发,并在 30 秒后测试恢复。这种组合能优雅地处理短暂瞬态错误和长时间故障。