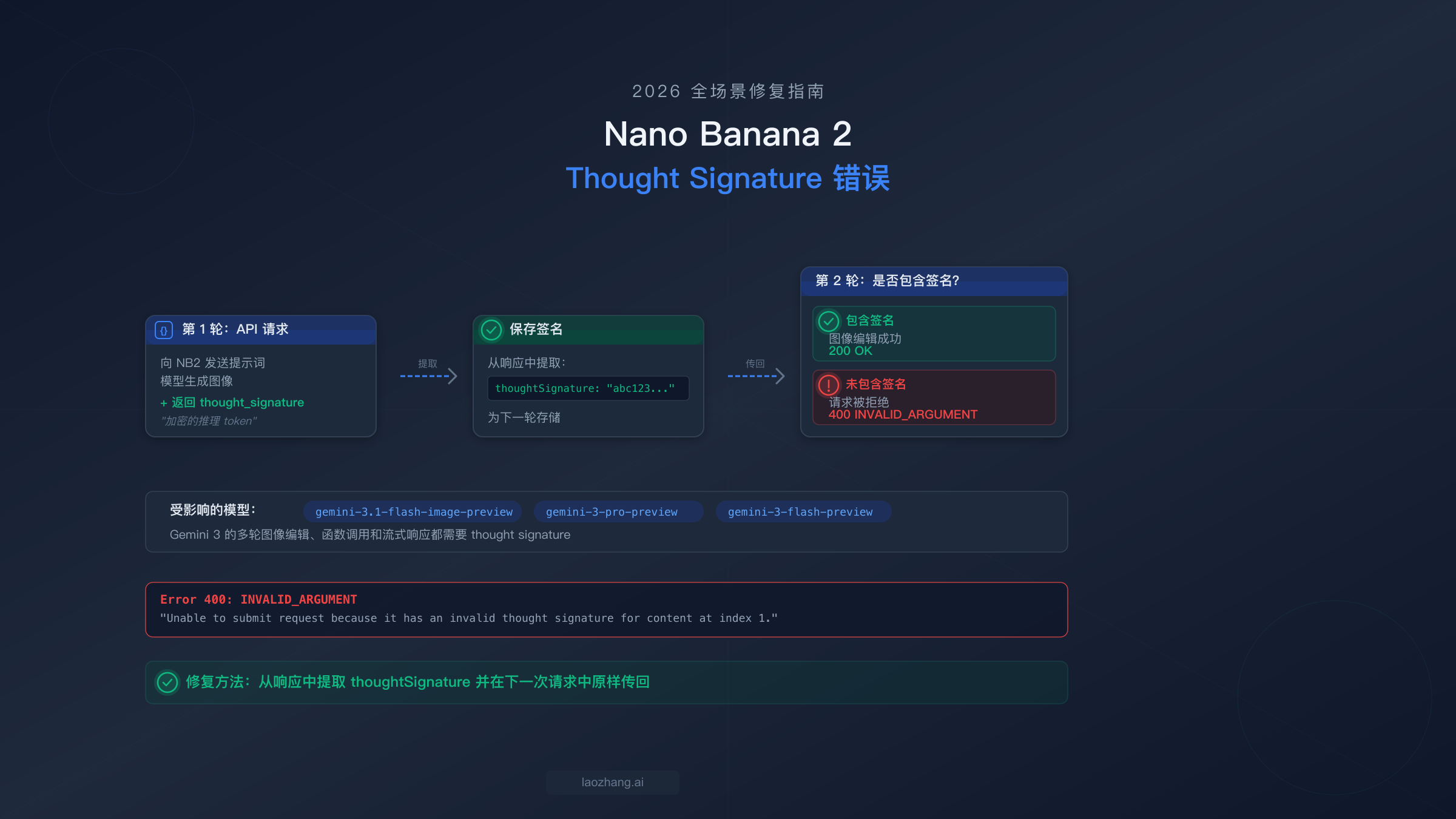
Nano Banana 2 的 thought_signature 错误(400 INVALID_ARGUMENT)发生在多轮 API 请求遗漏了模型上一次响应中返回的 thought_signature 字段时。Nano Banana 2(gemini-3.1-flash-image-preview)使用扩展思考功能生成加密的推理 token,同一对话中的每个后续请求都必须原样包含这些签名。修复方法很直接:从每次 API 响应中提取 thoughtSignature 字段,并在下一次请求的对话历史中传回。如果你使用的是官方 Google Gen AI SDK 的聊天功能,这一切会自动处理——但如果你直接调用 REST API、使用 OpenAI 兼容端点,或通过 Dify、n8n 等平台操作,就需要手动处理。
Thought Signature 错误是什么?为什么 Nano Banana 2 需要它?
当你向 Nano Banana 2 发送多轮请求时,如果 API 返回 400 INVALID_ARGUMENT: Unable to submit request because it has an invalid thought signature for content at index N,说明你遇到了 Gemini 3 模型系列中最常见也最令人抓狂的错误之一。这个错误并不意味着你的 API 密钥有误或请求格式有传统意义上的问题,而是表示模型的内部推理链断裂了——因为对话历史中缺少了一段必要的上下文信息。
要理解为什么会发生这个错误,需要了解 Gemini 3 模型如何处理"思考"过程。当 Nano Banana 2(模型 ID:gemini-3.1-flash-image-preview,Google AI 文档,2026年3月)处理你的请求时,它会执行扩展思考——一个内部推理步骤,帮助模型在生成输出之前规划其响应。这个思考步骤会产生一个名为 thought_signature 的加密字符串,本质上是模型推理过程的压缩表示。可以把它类比为游戏中的存档点:模型需要这个存档才能在下一轮中连贯地继续对话。没有它,模型就无法验证收到的对话历史是否与它实际生成的内容一致,因此会以 400 错误拒绝请求。
让大多数开发者踩坑的关键细节在于:即使你明确设置了 thinkingConfig: { thinkingBudget: 0 } 或将思考设为"关闭",签名仍然会生成。思考过程仍在底层运行,签名仍会产生且必须传回。Google 官方文档确认,无论你的思考配置如何,思考 token 始终会计费(ai.google.dev/thought-signatures,2026年3月)。这让很多开发者措手不及——他们以为关闭思考就意味着可以忽略签名字段,结果在第二轮请求时就遇到了 400 错误。如果你在构建对话式图像编辑工作流时一直被这个错误困扰,你并不孤单:Dify(#2262)、CherryStudio(#11391)、n8n、OpenClaw(#5001)和 Pipecat(#3557)的 GitHub Issues 都指向了同一个根本原因。关于 NB2 思考签名之外的其他错误,请参阅我们的Nano Banana 2 综合故障排除指南。
Thought Signature 什么时候是必须的,什么时候是可选的?
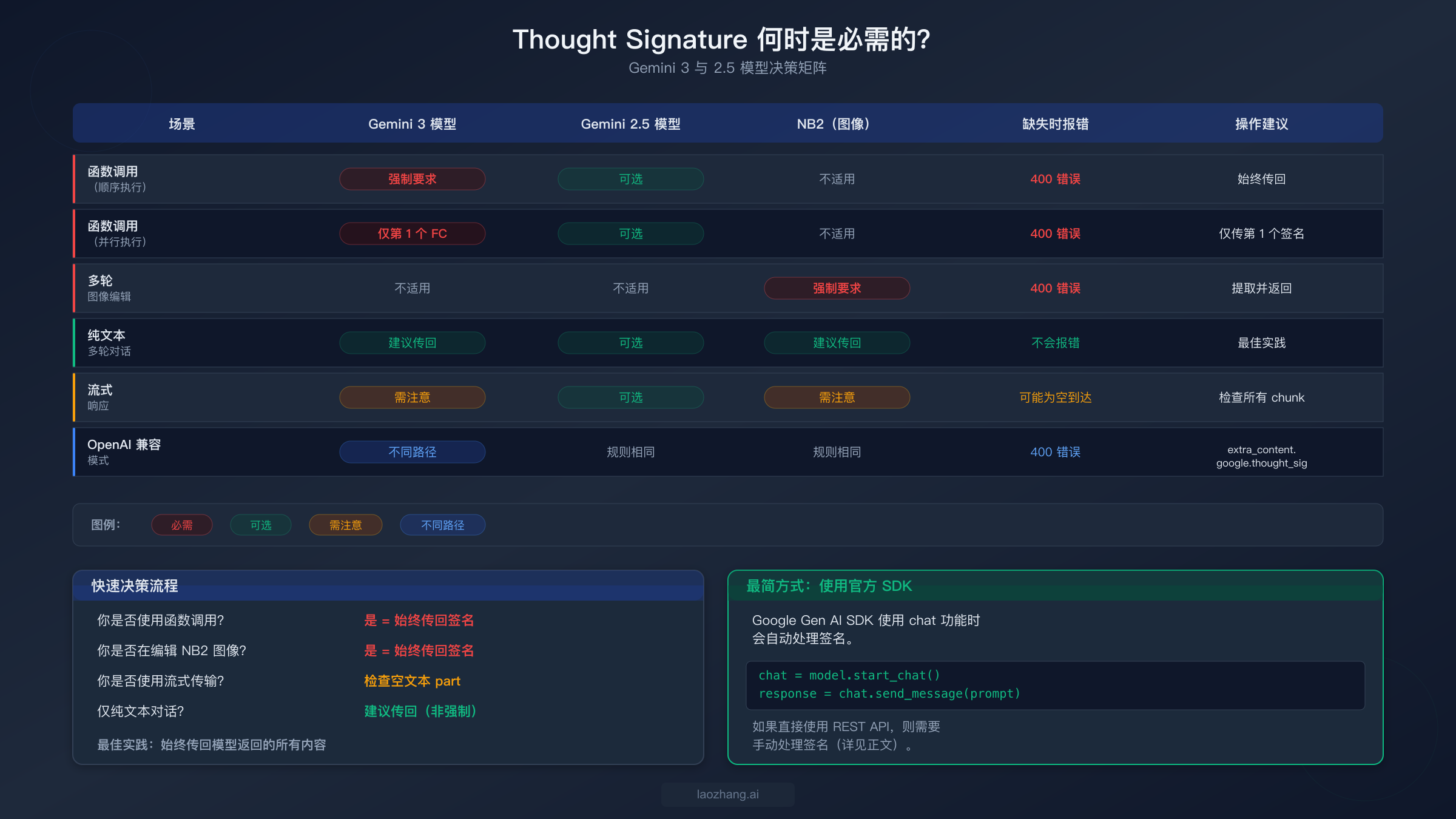
理解什么时候必须传回 thought signature、什么时候可以安全忽略,是在整个代码库中预防此错误的关键。规则在 Gemini 3 和 Gemini 2.5 模型之间有所不同,而 Nano Banana 2 的图像生成用例又有自己的特殊规则。判断失误意味着要么代码中增加了不必要的复杂性,要么在生产环境中遭遇意外的 400 错误。
对于 Gemini 3 模型(gemini-3-flash-preview、gemini-3-pro-preview),在所有函数调用场景中 thought signature 都是强制的。这意味着如果你的应用程序使用了工具调用或函数调用,每次后续轮次都必须提取并返回 thought signature——没有例外。顺序函数调用尤其棘手,因为序列中的每个步骤都会生成自己的签名,当你发送函数结果时,所有签名都必须包含在内。并行函数调用则有不同的模式:响应中只有第一个 functionCall 部分携带签名,因此你只需捕获并返回那一个。对于不涉及函数调用的纯文本多轮对话,签名在 Gemini 3 中是推荐但非强制的——这意味着省略它们不会触发 400 错误,但 Google 建议包含以获得最佳响应质量。
对于 Gemini 2.5 模型,规则更为宽松。Thought signature 在所有场景中都是可选的——函数调用、文本对话等都是如此。模型会接受带或不带签名的请求。不过,如果你正在构建需要同时兼容 Gemini 2.5 和 Gemini 3 模型的代码,最安全的做法是始终传回模型返回的所有内容,包括签名。
Nano Banana 2(gemini-3.1-flash-image-preview)属于特殊类别,因为它主要用于多轮图像生成和编辑。当你生成一张图像然后在后续轮次中要求模型编辑它时,thought signature 是强制的。这是导致大多数开发者遇到此错误的主要用例,而且相比函数调用场景,文档覆盖更少。实际规则很简单:如果你正在用 NB2 构建任何多轮工作流——无论是生成图像后进行优化、围绕视觉内容进行对话,还是链式图像编辑——你都必须处理 thought signature。关于 NB2 功能与其他模型的详细对比,请参阅我们的 Nano Banana Pro 与 Nano Banana 2 对比。
在多轮图像生成中修复此错误
多轮图像编辑是 Nano Banana 2 的主要用例,也是大多数开发者首次遇到 thought signature 错误的地方。工作流很直接——生成一张图像,然后要求模型修改它——但签名处理增加了一个容易遗漏的关键步骤。以下是完整的流程,每个步骤都标注了签名提取方法。
使用 Google Gen AI SDK 的 Python 实现:
pythonimport google.generativeai as genai import base64 genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash-image-preview") response = model.generate_content( "Generate a photo of a golden retriever playing in a park", generation_config=genai.GenerationConfig( response_modalities=["TEXT", "IMAGE"] ) ) # 步骤 2:从响应中提取 thought signature 和图像 thought_signature = None image_data = None text_response = "" for part in response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: thought_signature = part.thought_signature if hasattr(part, "inline_data") and part.inline_data: image_data = part.inline_data if hasattr(part, "text") and part.text: text_response += part.text print(f"Signature captured: {thought_signature[:30]}...") # 步骤 3:构建包含签名的多轮历史 history = [ # 你的原始请求 {"role": "user", "parts": [{"text": "Generate a photo of a golden retriever playing in a park"}]}, # 模型的响应——必须包含 thought_signature {"role": "model", "parts": []} ] # 重建包含签名的模型响应部分 for part in response.candidates[0].content.parts: part_dict = {} if hasattr(part, "text"): part_dict["text"] = part.text if hasattr(part, "inline_data") and part.inline_data: part_dict["inline_data"] = { "mime_type": part.inline_data.mime_type, "data": part.inline_data.data } if hasattr(part, "thought_signature") and part.thought_signature: part_dict["thought_signature"] = part.thought_signature history[-1]["parts"].append(part_dict) # 步骤 4:带完整历史发送编辑请求 edit_response = model.generate_content( contents=history + [ {"role": "user", "parts": [{"text": "Now add a red frisbee in the dog's mouth"}]} ], generation_config=genai.GenerationConfig( response_modalities=["TEXT", "IMAGE"] ) ) # 步骤 5:提取新签名以供后续编辑使用 new_signature = None for part in edit_response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: new_signature = part.thought_signature print(f"Edit successful! New signature: {new_signature[:30]}...")
关键步骤在步骤 3:当你重建对话历史时,模型的上一次响应必须包含原样返回的 thought_signature 字段。如果你把它剥离了,或者只保留了文本和图像数据,或者没有遍历所有 parts,下一轮请求就会触发 400 错误。NB2 的每个图像生成响应都会在其 parts 中某处包含一个 thought signature——你的任务就是忠实地保留它。
TypeScript 实现:
typescriptimport { GoogleGenerativeAI } from "@google/generative-ai"; const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-3.1-flash-image-preview" }); // 最简单的方式:使用 chat 接口 const chat = model.startChat({ generationConfig: { responseModalities: ["TEXT", "IMAGE"] } }); // 第 1 轮:生成图像(SDK 自动处理签名) const result1 = await chat.sendMessage("Generate a photo of a sunset over mountains"); // 第 2 轮:编辑图像(SDK 自动传递签名) const result2 = await chat.sendMessage("Add a silhouette of a person hiking"); // 第 3 轮:进一步优化 const result3 = await chat.sendMessage("Make the colors more vibrant and add lens flare");
TypeScript 示例使用了 SDK 的 chat 接口,它会自动处理签名管理。如果你能使用这种方式,就完全消除了 thought signature 错误这一类问题。SDK 会在内部追踪所有签名并在后续请求中自动包含,无需任何手动干预。对于大多数应用来说,这是最推荐的方式。关于 NB2 图像生成的定价详情,请参阅我们的 Nano Banana 2 API 定价详解。
处理流式传输、并行调用和 OpenAI 兼容模式
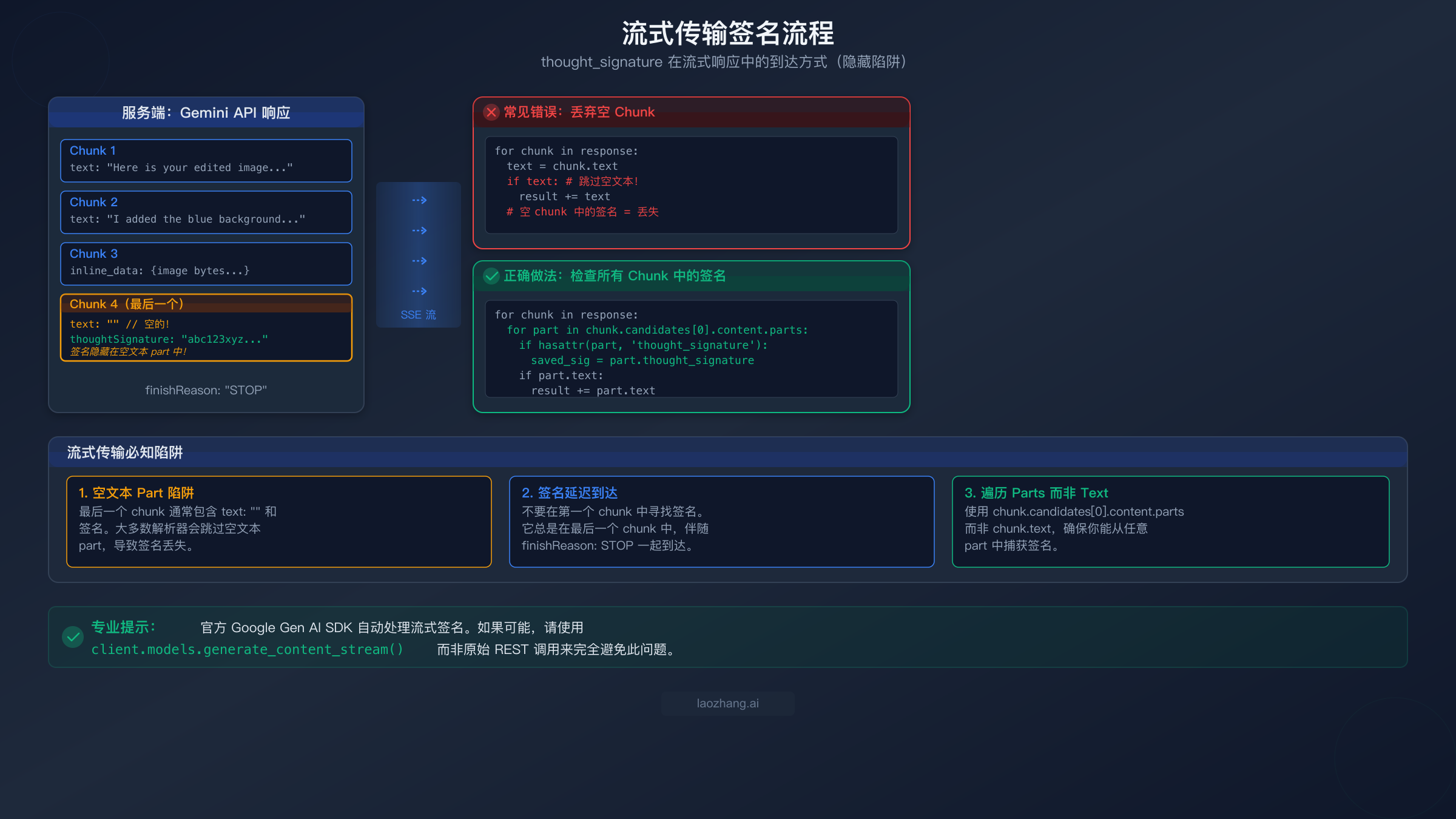
流式响应、并行函数调用和 OpenAI 兼容模式各自引入了独特的 thought signature 边界情况,可能会悄无声息地破坏你的应用。流式传输的情况尤其隐蔽,因为它涉及流解析器的工作方式与签名在响应流中实际出现位置之间的微妙交互。
流式传输:空文本 Part 陷阱
使用 NB2 或任何 Gemini 3 模型进行流式传输时,thought signature 不会出现在第一个 chunk 中,甚至也不会出现在可预测的中间 chunk 中。它出现在流的最后一个 chunk 中,而陷阱在于:最后一个 chunk 通常包含一个带有空文本字符串(text: "")和 thought_signature 字段的 part。大多数流解析器通过检查 if chunk.text: 来决定是否处理某个 chunk,而空字符串在大多数语言中求值为 false。这意味着你的解析器会悄悄跳过包含签名的那个 chunk,然后下一轮请求就会触发 400 错误。
修复方法是显式遍历 parts,而不是依赖便捷属性:
python# 错误:丢失空文本 chunk 中的签名 signature = None for chunk in response: if chunk.text: # 空字符串 = False = 签名丢失! result += chunk.text # 正确:检查每个 chunk 中的所有 parts signature = None full_text = "" for chunk in response: for part in chunk.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: signature = part.thought_signature if hasattr(part, "text") and part.text: full_text += part.text
这种模式确保你能捕获签名,无论它出现在哪个 chunk 中,也无论伴随的文本 part 是否为空。性能影响可以忽略不计——你只是在遍历本来就要处理的 parts——但可靠性的提升非常显著。
并行函数调用
当 Gemini 3 在单个响应中返回多个函数调用(并行函数调用)时,只有第一个 functionCall part 携带 thought signature。同一响应中的后续函数调用 parts 没有自己的签名。当你返回函数结果时,需要在响应中包含第一个函数调用 part 的签名。这在 Google 官方文档中有记载,但当你专注于处理函数调用本身时很容易遗漏。如果你在循环中处理函数调用并从每个调用中提取签名,你会发现只有第一个有值——而这个唯一的签名就是你需要传回的。
OpenAI 兼容模式
如果你通过 OpenAI 兼容端点访问 Gemini 模型(在从 OpenAI 迁移或使用网关服务时很常见),thought signature 位于响应中完全不同的位置。它不是 part 级别的 thought_signature,而是嵌套在消息对象的 extra_content.google.thought_signature 下。这让许多正在将 OpenAI 代码迁移到 Gemini 的开发者措手不及——他们基于原生 Gemini API 文档实现了签名处理,但 OpenAI 兼容层以不同方式组织了响应。修复方法是在使用兼容模式时检查替代字段路径:
python# 原生 Gemini API signature = part.thought_signature # OpenAI 兼容模式 signature = message.get("extra_content", {}).get("google", {}).get("thought_signature")
如果你的应用支持多种 API 模式,两种路径都需要处理。对于需要同时支持原生和兼容端点的生产应用,我们建议将签名提取抽象为一个辅助函数,同时检查两个位置。
高级变通方案——Dummy Signature 和模型迁移
Google 官方文档中隐藏着一个其他文章都没有重点介绍的变通方案:dummy thought signature。当你的对话历史不是由 Gemini 3 生成的——例如,你正在从其他模型迁移、注入合成的对话上下文,或者从未存储签名的数据库中恢复历史——你可以使用特殊的占位符字符串来代替真实签名。
Google 提供了两个官方的 dummy signature 字符串,可以绕过签名验证器(ai.google.dev/thought-signatures FAQ,2026年3月):
python# 选项 1:推荐的 dummy signature dummy_signature = "context_engineering_is_the_way_to_go" # 选项 2:备选 dummy signature dummy_signature = "skip_thought_signature_validator"
当你在对话历史中的模型轮次中将这些字符串作为 thought_signature 值时,API 将接受它而不进行验证。这在多种场景中非常有用:将现有的 GPT-4 或 Claude 对话历史迁移到 Gemini 3、从未设计存储 thought signature 的数据库中恢复对话、注入从未经过模型处理的系统级上下文轮次,以及在不需要真实签名的情况下测试多轮工作流。
但是,在生产环境中依赖 dummy signature 之前,有一些重要的注意事项需要了解。Dummy signature 告诉模型该轮次的思考上下文不可用,这意味着模型无法验证该轮次推理的连贯性。对于 Gemini 3 中的函数调用工作流,这可能导致响应质量略有下降,因为模型无法引用其原始推理链。对于 NB2 的图像编辑场景,在图像生成轮次使用 dummy signature 意味着模型可能无法完美"记住"它做出的创意决策,这可能影响后续编辑的质量。Dummy signature 方案最适合作为迁移工具或后备方案,而不是替代正确签名管理的永久方案。
实际的决策树很清晰:如果你能提取并存储真实签名,就始终这样做。如果你有没有签名的历史数据,使用 dummy signature 来解除迁移阻塞,而不是从头重建所有对话历史。如果你在原型开发或测试阶段,dummy signature 让你可以专注于业务逻辑,而不用担心签名的管道处理。
特定平台修复方案:Dify、CherryStudio、n8n 等
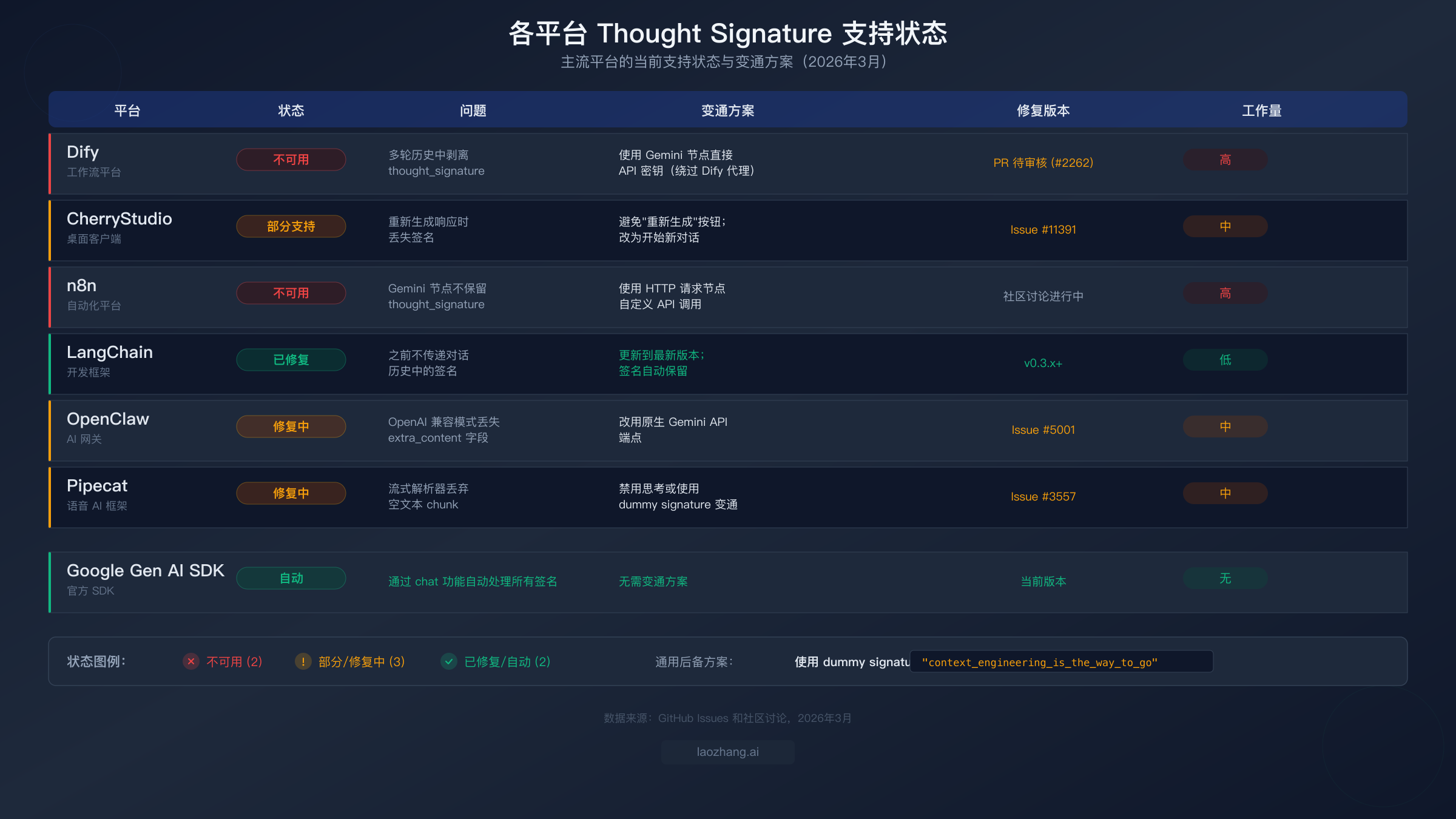
Thought signature 错误不仅仅是一个原始 API 问题——它也是 AI 开发平台和工具中普遍存在的问题。当你通过 Dify、CherryStudio、n8n 或类似平台使用 Gemini 3 模型时,平台内部的消息处理通常会在对话轮次管理过程中剥离或丢失 thought signature。这意味着你可能有完全正确的 API 凭据和模型配置,却仍然遇到 400 错误,因为平台悄悄丢掉了一个它不认识的字段。
Dify 是目前受影响最严重的平台。Dify 的消息历史管理在存储前会从模型响应中剥离非标准字段,而 thought_signature 被视为非标准字段。这意味着使用 Gemini 3 模型的多轮对话在第一轮之后总是会失败。这个问题在 GitHub Issue #2262 中被追踪,修复它的 Pull Request 正在等待审核。在此期间,变通方案是绕过 Dify 内置的 Gemini 集成,使用 HTTP 请求节点直接调用 Gemini API,并自行管理对话历史。这需要更多的设置工作,但能让你完全控制请求和响应的负载。
CherryStudio 有一个更细微的问题。桌面客户端在正常对话流程中确实会保留 thought signature,但在你使用"重新生成"按钮时会丢失它们。当 CherryStudio 重新生成响应时,它会重建对话历史但不包含被重新生成轮次的原始签名,从而触发 400 错误。变通方案很简单:避免使用重新生成功能,改为开始新对话或将你的消息重新表述为新轮次。这个问题在 GitHub Issue #11391 中被追踪。
n8n 面临与 Dify 相同的根本问题——其 Gemini 节点在工作流执行之间不保留对话状态中的 thought signature 字段。对于 n8n 用户,推荐的方式是使用 HTTP 请求节点而非 Gemini 专用节点,让你可以直接控制 API 负载。你可以在 n8n 的工作流数据中存储完整的响应(包括签名),并在后续轮次中手动重建对话历史。
LangChain 已在 0.3.x 及更高版本中修复了此问题。如果你使用的是旧版本,更新到最新版本即可自动解决 thought signature 的处理问题。LangChain 的 ChatGoogleGenerativeAI 类现在在构建对话历史时会保留所有响应元数据,包括 thought signature。
OpenClaw 和其他提供 Gemini 模型 OpenAI 兼容端点的 API 网关服务有另一个问题:它们可能不会从 OpenAI 兼容响应中转发 extra_content.google.thought_signature 字段。变通方案是通过网关使用原生 Gemini API 端点而非 OpenAI 兼容端点,或者配置网关保留所有响应字段。
对于所有平台,通用的后备方案就是上一节描述的 dummy signature 变通方法。如果某个平台剥离了你的真实签名,你可以在对话历史中注入 "context_engineering_is_the_way_to_go" 作为签名值来维持对话流程,当然要注意前面提到的质量影响。
生产级 Thought Signature 处理器
对于需要在所有场景——图像编辑、函数调用、流式传输和多种 API 模式——中实现健壮 thought signature 处理的生产应用,这里提供一个可复用的处理器类,封装了本指南中涵盖的所有边界情况。
pythonclass ThoughtSignatureHandler: """管理 Gemini 多轮对话中的 thought signature。""" DUMMY_SIGNATURES = [ "context_engineering_is_the_way_to_go", "skip_thought_signature_validator" ] def __init__(self): self.signatures = {} # turn_index -> signature def extract_from_response(self, response, turn_index: int) -> str | None: """从 Gemini API 响应中提取 thought signature。""" sig = None if hasattr(response, "candidates") and response.candidates: for part in response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: sig = part.thought_signature break if sig: self.signatures[turn_index] = sig return sig def extract_from_stream(self, stream, turn_index: int): """从流式响应中提取签名,同时逐步 yield chunk。""" sig = None for chunk in stream: if hasattr(chunk, "candidates") and chunk.candidates: for part in chunk.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: sig = part.thought_signature yield chunk if sig: self.signatures[turn_index] = sig def extract_from_openai_compat(self, message: dict, turn_index: int) -> str | None: """从 OpenAI 兼容响应格式中提取签名。""" sig = (message.get("extra_content", {}) .get("google", {}) .get("thought_signature")) if sig: self.signatures[turn_index] = sig return sig def get_signature(self, turn_index: int, fallback_dummy: bool = False) -> str | None: """获取某一轮的已存储签名,可选 dummy 后备。""" sig = self.signatures.get(turn_index) if sig is None and fallback_dummy: return self.DUMMY_SIGNATURES[0] return sig def build_history_part(self, part_data: dict, turn_index: int) -> dict: """确保模型响应 part 包含其 thought signature。""" sig = self.signatures.get(turn_index) if sig and "thought_signature" not in part_data: part_data["thought_signature"] = sig return part_data
这个处理器覆盖了三种主要的提取场景(标准响应、流式传输和 OpenAI 兼容模式),按轮次索引存储签名,并在真实签名不可用时提供 dummy signature 后备。extract_from_stream 方法是一个生成器,它透明地 yield chunk 同时从包含签名的那个 chunk 中捕获签名——你可以将其直接放入现有的流式处理代码中而无需改变处理逻辑。
对于 TypeScript 应用,等效模式更为简单,因为你可以使用 SDK 的 chat 接口自动处理一切。如果你必须在 TypeScript 中使用原始 REST 调用,可以使用可选链来应用相同的提取逻辑:
typescriptconst extractSignature = (response: any): string | undefined => { return response?.candidates?.[0]?.content?.parts ?.find((p: any) => p.thoughtSignature)?.thoughtSignature; };
构建生产系统时,建议同时实现速率限制处理和签名管理,因为 NB2 有严格的速率限制,与签名错误叠加可能导致令人困惑的失败模式。详情请参阅我们的Nano Banana 2 速率限制完整指南。对于需要更高吞吐量或更宽松速率限制的 NB2 图像生成团队,laozhang.ai 等服务提供有竞争力的替代 API 访问(每张图 $0.05,而标准价格约为 $0.067/张,按 1K token 计算)。
FAQ——常见 Thought Signature 问题
Nano Banana 2 是否总会在响应中返回 thought_signature?
是的。NB2 和其他 Gemini 3 模型的每个响应都包含 thought signature,即使思考设置为"关闭"或 thinkingBudget 为 0。思考过程始终在内部运行,签名始终会生成。你无法选择不生成签名——你只能选择是否将其传回(你应该始终这样做)。
如果我使用了错误的签名或来自不同对话的签名会怎样?
API 会以相同的 400 INVALID_ARGUMENT 错误拒绝请求。签名与生成它们的特定对话轮次进行了加密绑定。你不能在对话之间或同一对话的不同轮次之间交换签名。每个轮次的签名必须恰好使用一次,且恰好在生成它的位置使用。
官方 Google Gen AI SDK 会自动处理 thought signature 吗?
是的,当你使用 SDK 的 chat 接口时(TypeScript 中的 model.startChat() 或 Python 中的 model.start_chat())。SDK 会在内部管理整个对话历史,包括 thought signature。如果你直接使用 model.generate_content() 并手动构建对话历史,签名管理就需要你自己负责。
我可以将 thought signature 存储在数据库中供以后使用吗?
可以,如果你的应用需要跨会话恢复对话,你也应该这样做。为每个轮次存储包含 thought signature 的完整模型响应。恢复时,用所有存储的签名重建对话历史。如果有些轮次没有存储签名(历史数据),使用 dummy signature "context_engineering_is_the_way_to_go" 作为占位符。
thought_signature 字段会计费吗?它算入 token 用量吗?
生成签名的思考 token 始终会计费,无论你的 thinkingBudget 设置如何(ai.google.dev,2026年3月)。但是,签名字符串本身是紧凑的加密表示,传回时不会显著增加请求大小。计费影响在于初始的思考计算,而非传输签名本身。
为什么错误消息说"invalid thought signature"而不是"missing thought signature"?
错误消息 Unable to submit request because it has an invalid thought signature for content at index N 涵盖了两种情况:缺少签名(字段完全不存在)和损坏的签名(字段存在但包含错误数据)。"at index N"告诉你对话历史中哪个轮次有问题——检查该索引处的模型响应以确保它包含原始的 thought signature。