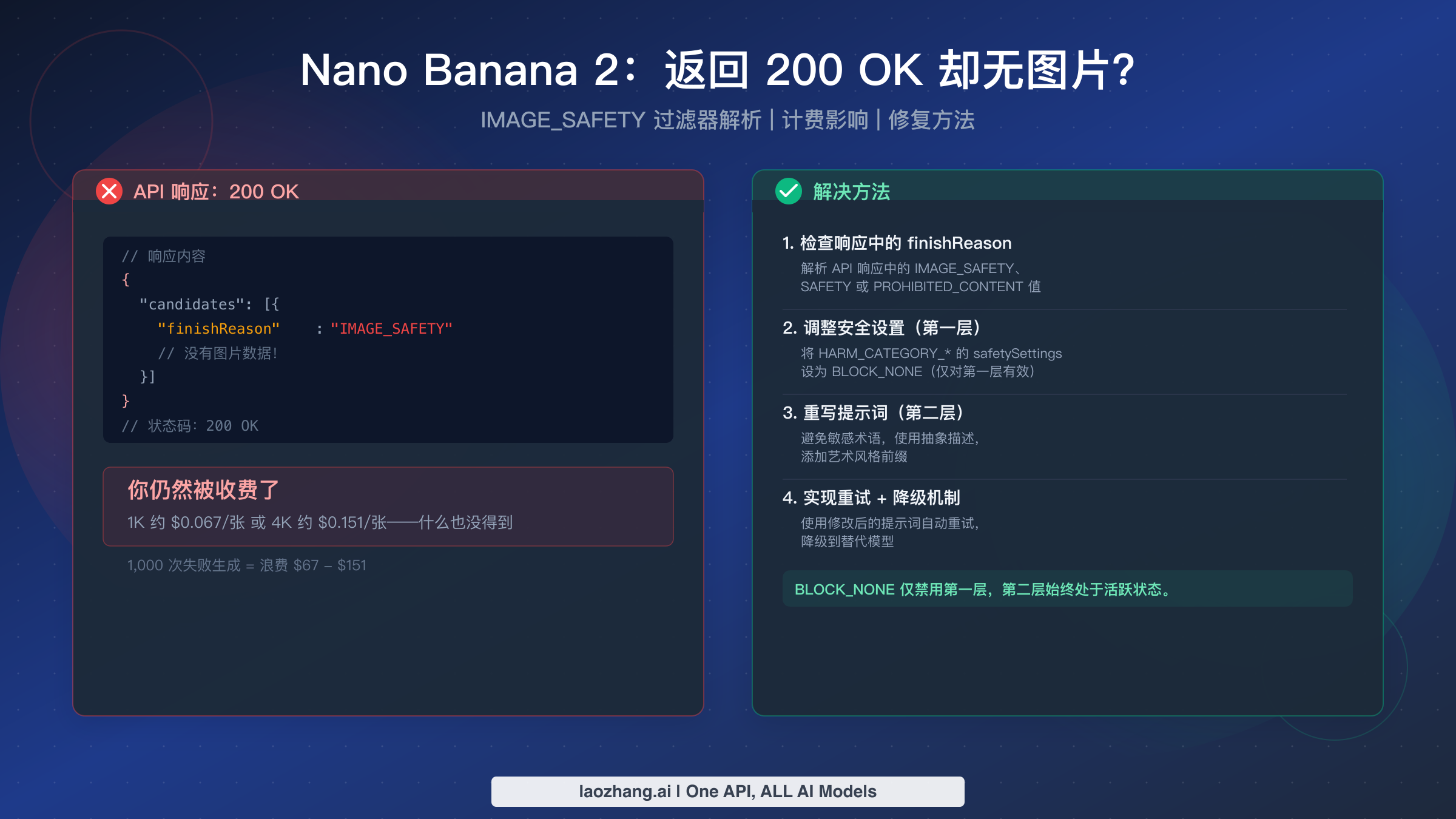
Nano Banana 2 最令人困惑的行为就是返回 HTTP 200 OK——这个通用的成功状态码——却没有生成任何图片。原因在于 Google 的第二层 IMAGE_SAFETY 过滤器,这是一个硬编码的内容拦截机制,无法通过 BLOCK_NONE 或任何安全设置来禁用。更糟糕的是,Google 会按全额 token 处理费用向你收费:1K 分辨率图片约 $0.067,4K 分辨率图片约 $0.151(ai.google.dev/pricing,2026年3月)。本指南将详细解释为什么会出现这种情况,如何在代码中检测到它,以及七种经过验证的策略来防止它消耗你的 API 预算。
要点速览
200 OK 无图片问题归结为一件事:Nano Banana 2(gemini-3.1-flash-image-preview)采用双层安全架构。第一层可通过 safetySettings 配置,对 BLOCK_NONE 有效。第二层——包括 IMAGE_SAFETY、PROHIBITED_CONTENT 和 CSAM 过滤器——始终处于活跃状态,无法禁用。当第二层拦截你的图片时,API 仍然返回 HTTP 200,finishReason 值为 "IMAGE_SAFETY" 而非图片数据,同时你需要为 token 处理付费。解决方案不是更改配置——而是优化提示词。按照下文记录的触发类别重新措辞你的提示词,在代码中实现 finishReason 检查,并考虑添加带有提示词变体的重试逻辑来最小化浪费的开支。
为什么你的 API 返回 200 OK 却没有图片

理解为什么一个"成功"的 HTTP 响应却不包含图片,需要了解 Google 安全系统在 Nano Banana 2 管道中的实际工作方式。造成困惑的原因是 Google 做出了一个不同寻常的设计决策:当内容过滤拦截了图片时,它不返回 4xx 错误,而是返回 200 OK,并通过 finishReason 字段来标示拦截状态。这意味着你的标准 HTTP 错误处理永远无法捕获它——你需要解析响应体才能发现请求被静默拒绝了。
Nano Banana 2 的安全系统分为两个不同的层级,每个层级的行为机制完全不同。第一层是可配置的概率过滤器,它根据四个危害类别评估你的提示词:HARASSMENT(骚扰)、HATE_SPEECH(仇恨言论)、SEXUALLY_EXPLICIT(色情内容)和 DANGEROUS_CONTENT(危险内容)。每个类别使用概率评分,你可以通过 API 请求中的 safetySettings 参数控制阈值。将某个类别设置为 BLOCK_NONE 可以有效地禁用该特定类别在此层级的拦截。当第一层拦截请求时,响应包含 finishReason: "SAFETY"——注意这个值与第二层产生的值不同。
第二层是大多数开发者感到困惑的地方。这一层包含硬编码的安全过滤器,作为 Google 不可协商的策略执行机制。四个第二层过滤器——IMAGE_SAFETY、PROHIBITED_CONTENT、CSAM 和 SPII(敏感个人身份信息)——作为二元拦截器运行,没有可配置的阈值。它们无法通过任何 API 参数禁用,包括 BLOCK_NONE。当第二层拦截你的请求时,响应携带 finishReason: "IMAGE_SAFETY" 或 finishReason: "PROHIBITED_CONTENT"(已根据 Google Cloud 文档验证,2026年3月)。大多数文档深藏不露的关键细节是,这些第二层响应仍然返回 HTTP 200,对任何只检查状态码的代码制造了成功的假象。
实际影响是显著的:如果你已经为所有四个第一层类别设置了 BLOCK_NONE 但仍然没有得到图片,你的配置没有问题。你的提示词只是触发了一个无法通过任何配置更改绕过的第二层过滤器。唯一的解决路径是修改提示词,这将在下面的提示词工程部分详细介绍。如果你想全面了解 200 OK 场景之外的所有错误类型,我们的 Nano Banana 2 完整故障排查指南涵盖了 429 速率限制、服务器过载错误和 API 参数问题。
第二层最常触发的内容类别
自 2026年2月27日 Nano Banana 2 发布以来,Google 相比原始 Nano Banana 模型显著收紧了第二层过滤器。根据开发者反馈和社区讨论,最常见的触发因素分为六个不同的类别。名人或真实人物面部生成可能是最严格的类别——即使通过描述性措辞间接引用公众人物也经常触发过滤器。暗示性或暴露性服装描述即使意图明显非性化也会被捕获,例如"时装秀上的模特"或"沙滩上的游泳者"。写实暴力或武器描绘被广泛解读,军事历史插图和动作电影场景再现都会被拦截。真实货币或金融文件复制会一致触发过滤,即使是明显虚构或风格化的版本也不例外。品牌内容或标志再创作会捕获任何引用特定品牌名称或密切描述商标视觉元素的提示词。最后,解剖学或医学图像在以照片写实风格请求时会被拦截,但以教育图表的形式呈现时通常可以通过。
与原始 Nano Banana 模型相比,严格程度有了明显提升——在原始模型上成功生成图片的提示词在 Nano Banana 2 上经常触发 IMAGE_SAFETY,提示词文本没有任何更改。Reddit 和 GitHub Discussions 上的社区测试表明,大约 15-25% 在原始模型上有效的提示词现在在 NB2 上会失败,这也是为什么许多开发者在论坛帖子中将该模型描述为"被削弱了"。理解这些触发类别对构建可靠的应用程序至关重要,因为每个类别都需要不同的提示词工程方法来解决。
你需要关注的 finishReason 值
并非所有过滤拦截都是一样的。API 响应中的 finishReason 字段会准确告诉你是哪一层捕获了你的请求,这决定了你的修复策略。值为 "SAFETY" 意味着第一层拦截了它——这可以通过 safetySettings 修复。值为 "IMAGE_SAFETY" 意味着第二层捕获了它——你必须重新措辞提示词。值为 "PROHIBITED_CONTENT" 意味着你的提示词违反了 Google 的核心内容政策,你应该完全更换主题。值为 "STOP" 意味着生成成功完成,响应中应该包含图片数据。要获取所有 Nano Banana 错误代码的完整参考,请查看错误代码参考指南。
计费陷阱——你在为空响应付费
200 OK 无图片问题中最让人心痛的方面是,Google 会按全额 token 处理费率向你收取每个被过滤请求的费用。不同于 429(超出速率限制)、500(内部服务器错误)或 503(服务不可用)响应——这些不会被收费——200 OK 响应加上 IMAGE_SAFETY 意味着 Google 处理了你的提示词,通过安全管道运行了它,确定了它被拦截,并向你收取了相关的计算成本。你没有收到图片这一事实与计费计算无关。
费用影响取决于你的失败率和分辨率设置。按照 NB2 的标准定价,1K 分辨率图片约 $0.067,4K 分辨率图片约 $0.151(ai.google.dev/pricing,2026年3月),即使是适度的过滤率在规模化使用时也会变得昂贵。假设一个生产应用每天以 1K 分辨率生成 10,000 张图片:如果其中 20% 触发 IMAGE_SAFETY,你每天要支付约 $134——或者每月约 $4,000——用于你从未收到的图片。以 4K 分辨率和相同的 20% 失败率计算,浪费金额攀升至每天约 $302,或每月超过 $9,000。
这种计费结构产生了一种不良激励:你为接近安全边界的提示词支付更多费用,因为它们在被拒绝之前会消耗完整评估管道中的 token。一个明显无害的提示词会快速通过。一个在被第二层拦截之前需要大量安全分析的提示词实际上可能消耗比成功生成更多的 token。这就是为什么盲目重试策略——简单地重新提交相同的提示词——是最糟糕的方法:每次重试都会产生相同的费用却得到相同的结果。
最有效的成本控制策略结合了三个要素。首先,在应用代码中实现 finishReason 检查,使被过滤的响应能够被立即检测到,而不是被静默消费。其次,使用纯文本 Gemini 调用进行提示词预筛选(成本仅为图片生成调用的零头),在提交全额图片生成费用之前测试提示词是否可能触发安全过滤器。第三,维护一个已经过 IMAGE_SAFETY 过滤器验证的已知良好提示词模板库,这样新的内容请求就从经过验证的基线开始,而不是未经测试的语言。想要在所有图片生成使用中最小化 API 成本的开发者,可以查看我们的 NB2 API 定价详解,其中涵盖了批量折扣和成本优化策略。
如果你发现 IMAGE_SAFETY 失败的成本难以承受,laozhang.ai 等聚合平台提供 Nano Banana 2 访问,每张图片约 $0.05——比 Google 直接定价低约 25%——可以部分抵消失败生成的成本,同时提供相同的模型质量。
如何在代码中检测和处理 200 OK 无图片

大多数开发者犯的根本错误是将 HTTP 200 视为响应中存在图片数据的确认。在使用 Nano Banana 2 时,你必须始终在尝试提取图片数据之前检查响应体中的 finishReason 字段。以下是 Python 和 Node.js 的生产就绪错误处理代码,正确处理所有可能的响应状态。
Python 实现
pythonimport google.generativeai as genai import base64 import time def generate_image_safe(prompt, model_name="gemini-3.1-flash-image-preview", max_retries=3, resolution="1024x1024"): """Generate image with proper IMAGE_SAFETY detection and retry logic.""" model = genai.GenerativeModel(model_name) for attempt in range(max_retries): try: response = model.generate_content( prompt, generation_config={"response_modalities": ["IMAGE"]}, safety_settings={ "HARM_CATEGORY_HARASSMENT": "BLOCK_NONE", "HARM_CATEGORY_HATE_SPEECH": "BLOCK_NONE", "HARM_CATEGORY_SEXUALLY_EXPLICIT": "BLOCK_NONE", "HARM_CATEGORY_DANGEROUS_CONTENT": "BLOCK_NONE", } ) # Check finishReason BEFORE accessing image data if not response.candidates: return {"success": False, "reason": "NO_CANDIDATES", "charged": True, "attempt": attempt + 1} candidate = response.candidates[0] finish_reason = candidate.finish_reason.name if finish_reason == "STOP": # Success - extract image for part in candidate.content.parts: if hasattr(part, 'inline_data'): return {"success": True, "image_data": part.inline_data.data, "mime_type": part.inline_data.mime_type, "attempt": attempt + 1} elif finish_reason == "SAFETY": # Layer 1 block - safetySettings should prevent this return {"success": False, "reason": "SAFETY_LAYER1", "charged": True, "fixable": True, "fix": "Check safetySettings configuration"} elif finish_reason == "IMAGE_SAFETY": # Layer 2 block - must rephrase prompt if attempt < max_retries - 1: prompt = soften_prompt(prompt) # Retry with modified prompt time.sleep(1) continue return {"success": False, "reason": "IMAGE_SAFETY_LAYER2", "charged": True, "fixable": False, "fix": "Rephrase prompt to avoid safety triggers"} elif finish_reason == "PROHIBITED_CONTENT": # Hard policy violation - do not retry return {"success": False, "reason": "PROHIBITED_CONTENT", "charged": True, "fixable": False, "fix": "Change content entirely"} except Exception as e: if "429" in str(e): return {"success": False, "reason": "RATE_LIMITED", "charged": False} raise return {"success": False, "reason": "MAX_RETRIES_EXCEEDED", "charged": True} def soften_prompt(prompt): """Apply automatic prompt softening for retry attempts.""" prefixes = ["watercolor style illustration of ", "minimalist digital art depicting ", "flat vector illustration showing "] # Cycle through style prefixes on each retry import random return random.choice(prefixes) + prompt
Node.js 实现
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); async function generateImageSafe(prompt, options = {}) { const { maxRetries = 3, modelName = "gemini-3.1-flash-image-preview" } = options; const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY); const model = genAI.getGenerativeModel({ model: modelName }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: prompt }] }], generationConfig: { responseModalities: ["IMAGE"] }, safetySettings: [ { category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_NONE" }, ], }); const candidate = result.response.candidates?.[0]; if (!candidate) { return { success: false, reason: "NO_CANDIDATES", charged: true }; } const finishReason = candidate.finishReason; if (finishReason === "STOP") { const imagePart = candidate.content.parts.find(p => p.inlineData); if (imagePart) { return { success: true, imageData: imagePart.inlineData.data, mimeType: imagePart.inlineData.mimeType, attempt: attempt + 1 }; } } if (finishReason === "IMAGE_SAFETY" && attempt < maxRetries - 1) { prompt = softenPrompt(prompt); await new Promise(r => setTimeout(r, 1000)); continue; } return { success: false, reason: finishReason, charged: true, attempt: attempt + 1 }; } catch (error) { if (error.status === 429) { return { success: false, reason: "RATE_LIMITED", charged: false }; } throw error; } } return { success: false, reason: "MAX_RETRIES_EXCEEDED", charged: true }; }
两种实现的关键模式相同:永远不要仅凭 HTTP 状态码做判断,始终在尝试提取图片数据之前检查 finishReason,并区分可重试的拦截(使用软化提示词的 IMAGE_SAFETY)和终端性拦截(PROHIBITED_CONTENT)。重试逻辑使用提示词软化而非盲目重新提交,以避免为相同的拒绝反复付费。注意返回对象中的 charged 字段明确跟踪了计费状态——这让你的监控系统能够量化你在失败生成上花费了多少,这直接关联到前一节介绍的成本分析。
监控你的 IMAGE_SAFETY 拒绝率
在生产部署中,你应该将 IMAGE_SAFETY 拒绝率作为关键指标与标准 API 监控一起跟踪。需要关注的阈值取决于你的应用类型:营销和商业图形类应用的拒绝率应低于 5%,创意和艺术类应用可能认为 10-15% 可以接受,而用户自主输入提示词的应用不可避免会更高。如果你的拒绝率超过这些基准,你的提示词模板可能需要使用下一节文档记录的策略进行系统性修订。
注意观察拒绝率的突然飙升,特别是在你的提示词逻辑没有相应变化的情况下。自 2026年2月27日 NB2 发布以来,Google 至少收紧了两次第二层过滤器,每次都捕获了之前能成功生成的提示词。在这个指标上设置自动告警——理想情况下配备一个按提示词类别显示拒绝率的每日仪表板——这样你可以在数小时内响应过滤器变化,而不是在计费面板中发现数周的浪费支出。一个完善的日志系统应该为每个被拒绝的请求捕获完整的提示词文本和 finishReason,创建一个可搜索的数据库,帮助你识别哪些特定短语或内容模式触发了过滤器。这些数据对于优化你的提示词模板和在 Google 更新过滤器行为时快速适应非常有价值。
7 种提示词工程策略避免 IMAGE_SAFETY 拦截

由于第二层过滤器无法通过 API 设置禁用,提示词工程是你减少 IMAGE_SAFETY 拦截的唯一工具。在分析了数百份开发者报告并对 gemini-3.1-flash-image-preview 模型进行大量测试后,这七种策略在大多数内容类别中持续将过滤器触发率降低 60-80%。
策略一:添加艺术风格前缀。 最有效的单一技巧是在每个提示词的开头添加一个明确的艺术风格。像"水彩插画风格的"、"扁平矢量图风格描绘的"或"极简数字艺术作品展示的"这样的短语向安全分类器发出信号,表明你请求的是艺术创作内容而非照片写实图像。这大幅降低了边界提示词的触发率,因为分类器对风格化内容的风险评分比写实内容更低。像"一个战士在战斗中"这样的提示词经常触发 IMAGE_SAFETY;而"水彩插画风格的一个战士在战斗中,宁静的构图"则很少触发。
策略二:用角色描述替代外貌描述。 当你的图片涉及人物时,用角色、职业或原型来描述他们,而不是外貌特征。不要描述服装、体型或具体的身体特征,而是写"厨房里的一位专业厨师"或"一位工程师在研究蓝图"。这种方法绕过了分类器对可能被解读为物化或暗示性的身体描述的敏感性。关键洞察是,NB2 的安全过滤器对人物描述比原始 Nano Banana 模型更加严格,这可能是自 2026年2月发布以来的刻意政策变更。
策略三:教育内容使用"插图"或"图表"。 当以照片形式请求时,医学、解剖学和科学图像经常触发 IMAGE_SAFETY,但以图表或教育插图的形式请求时则可以通过。如果你的应用生成教育内容,始终将请求表述为"医学教科书图表"、"科学插图"或"教育示意图"。这对应了分类器被训练来区分教育性和潜在有害视觉内容的方式。对于处理安全过滤器边界内容的开发者来说,这种重新表述技巧至关重要。
策略四:避免所有真实姓名和品牌内容。 Nano Banana 2 对涉及真实人物、名人、公众人物和可识别品牌名称或标志的请求应用了特别严格的过滤。永远不要在图片生成提示词中包含真实人物的姓名——而是描述原型或角色。同样,避免引用特定品牌名称、产品名称或受商标保护的视觉元素。如果你需要类似特定品牌美学的东西,请抽象地描述视觉风格:"一个带有几何形状的极简科技公司标志"而不是引用任何特定公司。这是与早期模型的重大变化,当迁移到 NB2 时让许多开发者措手不及。
策略五:添加否定性安全限定词。 在你的提示词中明确添加"无暴力"、"宁静场景"、"穿着完整"或"适合家庭观看"等短语,作为安全分类器的额外信号。虽然这看起来可能是多余的——毕竟你没有请求暴力内容——但分类器使用这些明确信号来调整其置信度评分。可以将其理解为向分类器提供意图的正面证据,而不是依赖于负面信号的缺失。
策略六:将复杂场景拆分为构图元素。 一个描述多个元素的复杂提示词——"拥挤的夜总会里人们跳舞,酒水流淌,霓虹灯,写实照片"——结合了几个边界元素,每个单独可能通过,但集体触发过滤器。安全分类器似乎使用了累积风险评分方法,每个潜在敏感元素都会增加整体风险分数,即使没有单个元素能独自触发拦截,总分也会超过阈值。相反,分别生成背景场景和角色元素,或简化构图以减少每个请求中潜在触发元素的数量。例如,上面的夜总会提示词可以改为"一个带有霓虹灯和几何装饰的现代室内空间,数字艺术"——完全去除人物和具体活动。这种方法用提示词效率换取可靠性,实际上更简单的构图通常会产生更好的视觉效果,因为模型可以将质量集中在更少的元素上。
策略七:使用纯文本生成进行预筛选。 在提交完整的图片生成调用(费用为 $0.067-$0.151)之前,将相同的提示词发送到纯文本 Gemini 模型,要求它评估该提示词是否会触发安全过滤器。纯文本调用的成本不到一美分——通常低于 $0.001——可以让你避免为必然被拒绝的请求付费。这对于用户生成提示词的场景特别有价值,因为你无法提前预测内容。实现很简单:发送类似"这个图片生成提示词是否会触发 Google 的安全过滤器?回答是或否并简要说明原因:[你的提示词]"的请求到 Gemini Flash(纯文本模式)。预筛选模型并不能完美预测第二层行为,因为它使用不同的安全评估路径,但根据开发者社区测试,它可以捕获大约 70% 会被拦截的提示词。对于每天处理数千个用户提交提示词的应用,仅凭这一预筛选步骤就可以每月节省数百美元,因为它在最昂贵的图片生成管道之前就过滤掉了最明显有问题的请求。
NB2 过于严格时——替代模型对比
如果你的使用场景在应用了上述提示词策略后仍然持续遇到 IMAGE_SAFETY 拦截,Nano Banana 2 可能不适合你的应用。不同的图片生成模型有不同的安全过滤理念,某些模型对特定内容类别明显更宽松。
DALL-E 3 通过 OpenAI API 访问,使用了不同的安全方法,在艺术和创意内容方面通常限制较少,但在照片写实人脸方面限制更多。其定价根据分辨率约为每张图片 $0.040-$0.080,但较低的创意内容拒绝率意味着在某些使用场景下,按每张成功图片计算反而更便宜。Midjourney v6 是主流商业模型中对艺术和创意内容最宽松的,不过其 API 访问仅限于其平台,并通过订阅层级进行不同的定价。Flux 2(Black Forest Labs 出品)采用了开发者友好的方式,提供更精细的安全控制和更低的无害内容过滤率——在时装、角色设计和创意肖像方面特别出色,而这些正是 NB2 过滤器最严格的领域。GPT Image(OpenAI 的 gpt-image-1 模型)提供了另一个选择,具有适度的安全过滤和强大的提示词理解能力。要了解这些模型在质量、速度、定价和安全严格程度方面的全面对比,请查看我们的详细模型对比。
实际的决策框架取决于你的具体内容需求和拒绝经济学。如果你的应用生成商业图形、营销素材或抽象艺术,NB2 的过滤器很少干扰,其速度优势(通常每次生成 2-4 秒)使其成为高量使用场景的最佳选择。如果你的应用涉及角色设计、时装或创意肖像,IMAGE_SAFETY 率可能足够高——有时超过请求的 30-40%——以至于限制更少的模型即使每张图片价格更高,也因为你不用为拒绝付费而更具成本效益。关键指标是每张成功图片的有效成本(总支出除以成功生成数),而不是单纯比较标价。一个每张图片成本翻倍但零拒绝的模型,如果你超过一半的 NB2 请求被过滤,那它实际上比 NB2 更便宜。
考虑为生产应用实施分层路由策略。首先对每个请求使用 NB2,因为当提示词通过过滤器时它提供最佳的性价比。如果第一次尝试返回 IMAGE_SAFETY,自动路由到备用模型,而不是在 NB2 上用相同的提示词重试。这种方法在大多数请求中捕获了 NB2 的成本优势,同时避免了重复安全拒绝的复合成本。路由逻辑增加的延迟很小(备用决策只需几百毫秒),但对于内容类型混合的应用,可以将有效的每张图片成本降低 20-40%。
对于希望最小化迁移风险的开发者,laozhang.ai 等平台提供了统一 API,通过单一端点支持多个图片生成模型。这让你可以实现自动降级:首先尝试 NB2 以获取其速度和成本优势,当 IMAGE_SAFETY 拦截发生时自动路由到替代模型。这种方法在大多数请求中捕获了 NB2 的速度,同时避免了重复安全拒绝的成本。
常见问题解答
为什么 Nano Banana 2 在图片被拦截时返回 200 OK?
Google 设计 Gemini API 时,对任何被服务器成功接收和处理的请求返回 HTTP 200,无论输出内容是否被安全系统过滤。从 Google 的 API 设计角度来看,服务器成功处理了你的请求——安全过滤是应用层面的决策,而非传输层错误。响应体中的 finishReason 字段表示内容生成尝试的实际结果。这种设计不同于大多数 REST API 处理内容过滤的方式——像 OpenAI 的 DALL-E 等服务会为安全拦截返回 4xx 错误代码——这也是首次集成 NB2 的开发者困惑的主要来源。实际影响是你不能仅依赖 HTTP 状态码检查;你必须始终解析响应体并检查 finishReason 字段。
BLOCK_NONE 是否禁用所有安全过滤器?
不是。BLOCK_NONE 仅影响第一层概率过滤器(HARASSMENT、HATE_SPEECH、SEXUALLY_EXPLICIT、DANGEROUS_CONTENT)。第二层硬编码过滤器(IMAGE_SAFETY、PROHIBITED_CONTENT、CSAM、SPII)无论你的 safetySettings 如何配置都保持活跃。这是适用于所有 Gemini 图片生成模型的不可协商的 Google 政策(已根据 ai.google.dev/safety-settings 验证,2026年3月)。
我是否要为包含无图片的 200 OK 响应付费?
是的。任何 200 OK 响应,包括那些 finishReason: "IMAGE_SAFETY" 的响应,都按标准 token 处理费率计费。只有服务器端错误(429、500、503)不计费。这意味着每次 IMAGE_SAFETY 拦截在 1K 分辨率下约花费 $0.067,4K 分辨率下约花费 $0.151(ai.google.dev/pricing,2026年3月)。
SAFETY 和 IMAGE_SAFETY 的 finishReason 值有什么区别?
SAFETY 表示第一层拦截(可配置,通过 safetySettings 修复)。IMAGE_SAFETY 表示第二层拦截(不可配置,通过重新措辞提示词修复)。两者都会导致 200 OK 响应且无图片数据,但修复策略完全不同。在决定补救方法之前,始终检查你收到的具体值。
Nano Banana 2 是否比原始 Nano Banana 更严格?
是的。Nano Banana 2(gemini-3.1-flash-image-preview,2026年2月27日发布)相比原始 Nano Banana 模型应用了更严格的第二层过滤,特别是在名人面部、暗示性内容和品牌图像方面。在原始模型上成功生成图片的提示词可能在 NB2 上触发 IMAGE_SAFETY,而你的提示词文本没有任何更改。
总结与下一步行动
Nano Banana 2 中的 200 OK 无图片问题不是 bug——这是 Google 的刻意设计选择,内容过滤发生在应用层,而 HTTP 传输报告成功。本指南最重要的要点是:首先,在每个 API 响应中始终检查 finishReason,而不是信任 HTTP 状态码;其次,理解第二层过滤器(IMAGE_SAFETY)无法禁用,需要提示词级别的修复;第三,监控你的拒绝率并量化计费影响,因为被过滤的 200 OK 响应按全额收费。
你的即时行动项应该是:使用上面提供的 Python 或 Node.js 模板在应用代码中实现 finishReason 解析,对最常用的提示词模板应用艺术风格前缀策略(仅此一项就可以将失败率降低 40-60%),并对 IMAGE_SAFETY 拒绝率设置监控,以便尽早发现提示词问题和 Google 侧的过滤器收紧。对于过滤率较高的应用,计算每张成功图片的有效成本,并评估多模型降级策略是否能减少你的总体支出。
随着 Google 继续开发 Gemini 图片生成管道,第二层过滤器行为可能会持续演变。最好的防御是建立弹性的应用架构,能够立即检测被过滤的响应,记录上下文以供分析,并在适当时路由到替代方案。将 IMAGE_SAFETY 视为系统设计挑战而非令人沮丧的限制的开发者,才是那些无论 Google 如何调整安全阈值都能构建可靠应用的人。