
Nano Banana Pro использует двухуровневую систему фильтров безопасности, которая сбивает с толку большинство разработчиков. Уровень 1 (настраиваемый) можно установить в BLOCK_NONE через параметр safety_settings API, отключая фильтрацию по категориям преследования, разжигания ненависти, откровенно сексуального и опасного контента. Уровень 2 (IMAGE_SAFETY) -- это ненастраиваемый серверный фильтр, который невозможно отключить через какие-либо настройки API. По состоянию на март 2026 года наиболее эффективный подход сочетает конфигурацию BLOCK_NONE для Уровня 1 с техниками промпт-инжиниринга, которые обеспечивают 70-80% успешных генераций для пограничного контента на Уровне 2.
Краткое содержание
Фильтры безопасности Nano Banana Pro работают на двух независимых уровнях, которые большинство разработчиков путают, тратя часы на применение неправильных решений. Уровень 1 фильтрует четыре категории вреда (преследование, разжигание ненависти, откровенно сексуальный контент, опасный контент) и может быть полностью отключён установкой safety_settings в BLOCK_NONE в ваших API-запросах. Когда Уровень 1 блокирует запрос, в ответе появляется finishReason: "SAFETY". Уровень 2 -- это совершенно отдельная серверная система под названием IMAGE_SAFETY, которая сканирует сгенерированные изображения с помощью ИИ-классификации, сопоставления хэшей и применения правил политики. Когда Уровень 2 блокирует запрос, в ответе отображается finishReason: "IMAGE_SAFETY", и никакая конфигурация API не может это отключить. Лучшие варианты для работы с Уровнем 2 -- это промпт-инжиниринг (примерно 70-80% успешных генераций для пограничного контента) или переход на платформу с ослабленными настройками Уровня 1 по умолчанию, например laozhang.ai. Контент, относящийся к навсегда запрещённым категориям -- CSAM, экстремальное насилие или откровенная порнография -- не может быть сгенерирован ни через одну легальную платформу или технику.
Почему ваши изображения блокируются (анализ первопричин)
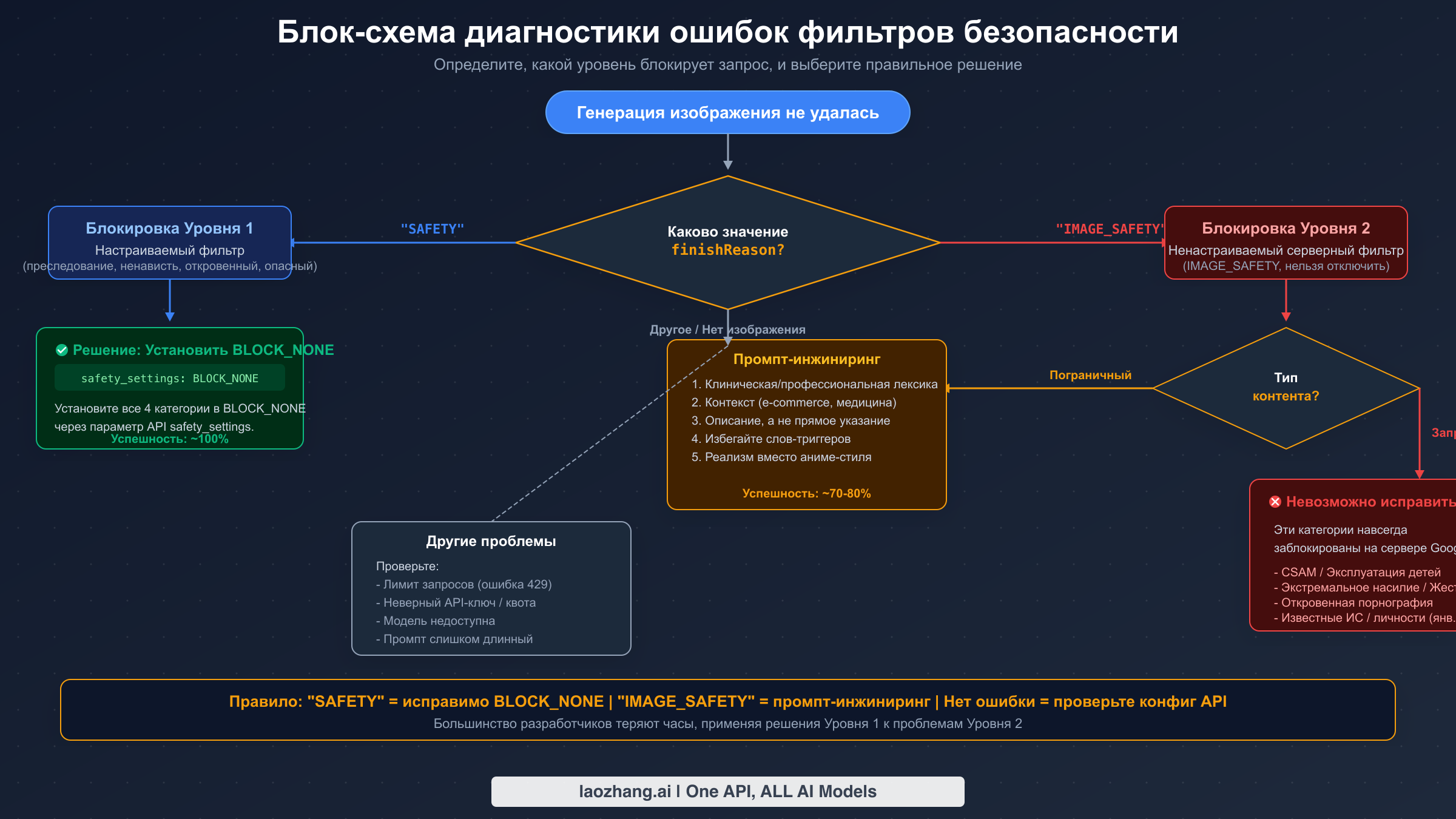
Главная причина, по которой разработчики тратят время впустую с фильтрами безопасности Nano Banana Pro, -- это неправильная диагностика. Они сталкиваются с заблокированным изображением, ищут «как отключить фильтры безопасности», находят инструкции по установке BLOCK_NONE, применяют эти настройки и обнаруживают, что изображения по-прежнему блокируются. Проблема не в том, что BLOCK_NONE не работает -- он работает идеально для того, что контролирует. Проблема в том, что большинство блокировок исходят от совершенно другой системы, которую BLOCK_NONE вообще не затрагивает.
Понимание того, какой именно уровень отвечает за вашу конкретную блокировку, -- это необходимый первый шаг перед попыткой любого исправления. Процесс диагностики прост, если знать, на что обращать внимание: проверьте поле finishReason в ответе API. Если значение "SAFETY", вы имеете дело с блокировкой Уровня 1 -- настраиваемого уровня, который реагирует на safety_settings. Установка всех четырёх категорий вреда в BLOCK_NONE решит эту проблему практически мгновенно. Если значение "IMAGE_SAFETY", вы столкнулись с Уровнем 2 -- ненастраиваемым серверным фильтром. Никакие изменения конфигурации API не помогут. Вам понадобятся техники промпт-инжиниринга, которые мы подробно рассматриваем далее в этом руководстве. Полный список всех возможных ответов об ошибках вы найдёте в нашем справочнике кодов ошибок.
Многие разработчики также сталкиваются с третьим сценарием, когда изображение не возвращается, но finishReason не содержит ни "SAFETY", ни "IMAGE_SAFETY". Обычно это указывает на совершенно другую проблему -- ограничение частоты запросов (HTTP 429), недействительный API-ключ, исчерпание квоты или проблемы с форматом промпта. Это не проблемы фильтров безопасности, и для них требуются другие решения. Наше руководство по устранению неполадок и отладке подробно рассматривает эти случаи.
Цена неправильной диагностики значительна. При стоимости $0,134 за изображение в разрешении 2K через официальный API (Google AI for Developers, март 2026), пакет из 1000 изображений с 30% долей отклонений приводит к потере примерно $40 на неудачных API-вызовах. Для корпоративных команд, обрабатывающих пакеты из 10 000+ изображений, потери могут достигать $400-700 за пакет. Правильная диагностика блокирующего уровня до попыток исправления экономит и деньги, и часы инженерной работы.
Архитектура двухуровневой системы фильтров безопасности

Система безопасности Nano Banana Pro работает через два полностью независимых уровня фильтрации, которые обрабатывают ваш запрос последовательно. Понимание того, как каждый уровень работает на техническом уровне, критически важно для построения надёжных конвейеров генерации изображений. Официальная документация Google описывает параметр safety_settings, но заметно избегает подробного обсуждения уровня IMAGE_SAFETY, поэтому большинство разработчиков не осознают его существования, пока не столкнутся с ним.
Как работает Уровень 1 (настраиваемый)
Уровень 1 оценивает ваш текстовый промпт по четырём категориям вреда до начала генерации изображения. Каждая категория -- преследование, разжигание ненависти, откровенно сексуальный контент и опасный контент -- получает оценку вероятности от модели классификации контента Google. Параметр safety_settings в вашем API-запросе определяет порог, при котором запрос блокируется. BLOCK_LOW_AND_ABOVE -- самая строгая настройка, блокирующая всё, что имеет даже минимальный потенциал вреда. BLOCK_MEDIUM_AND_ABOVE и BLOCK_ONLY_HIGH -- прогрессивно более мягкие варианты. BLOCK_NONE полностью отключает фильтрацию Уровня 1 для данной категории, пропуская ваш промпт независимо от его оценки вероятности вреда. Когда Уровень 1 блокирует запрос, ответ API содержит finishReason: "SAFETY" вместе с safetyRatings, которые показывают, какая именно категория вызвала блокировку и с каким уровнем уверенности. Эта информация бесценна для понимания того, что именно активировало фильтр.
Как работает Уровень 2 (ненастраиваемый)
Уровень 2 работает по принципиально иному принципу. Вместо оценки входного промпта он анализирует сгенерированное изображение на выходе с помощью нескольких механизмов обнаружения, работающих на стороне сервера. К ним относятся перцептивное хэш-сопоставление с базой данных известных запрещённых изображений, ИИ-модель классификации, обученная обнаруживать небезопасный визуальный контент, и жёстко закодированные правила политики для определённых категорий, таких как CSAM и экстремальное насилие. Обновление политики в январе 2026 года добавило обнаружение интеллектуальной собственности -- известных персон и логотипов брендов (персонажи Disney стали наиболее часто упоминаемым примером). Когда Уровень 2 отклоняет сгенерированное изображение, ответ содержит finishReason: "IMAGE_SAFETY", но не предоставляет подробных рейтингов безопасности -- вы знаете только то, что изображение было заблокировано, но не конкретную причину. Эта непрозрачность делает блокировки Уровня 2 значительно сложнее для устранения, чем блокировки Уровня 1.
Почему они независимы
Ключевой инсайт заключается в том, что эти уровни архитектурно разделены. Уровень 1 -- это предгенерационный текстовый классификатор. Уровень 2 -- это постгенерационный анализатор изображений. Установка BLOCK_NONE указывает Уровню 1 пропускать всё, но Уровень 2 никогда не получает и не реагирует на вашу конфигурацию safety_settings. Он работает по собственным правилам, с собственными порогами, полностью независимо. Именно поэтому разработчики, установившие BLOCK_NONE и ожидающие нулевой фильтрации, удивляются, когда изображения всё равно блокируются. Они успешно отключили один фильтр, оставив совершенно другой фильтр работать на полную мощность.
Настройка параметров безопасности Уровня 1 (исправимая часть)
Когда ваш ответ API показывает finishReason: "SAFETY", решение состоит в настройке safety_settings в BLOCK_NONE для всех четырёх категорий вреда. Это простая часть работы с фильтрами безопасности Nano Banana Pro, и код одинаков независимо от того, генерируете ли вы изображения или выполняете текстовую генерацию. Если вы ещё не настроили доступ к API, наше руководство по получению API-ключа проведёт вас через весь процесс.
Python (SDK google-generativeai)
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-2.0-flash-exp") safety_settings = [ {"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"}, ] response = model.generate_content( "Generate a product photo of a summer swimsuit on a mannequin", safety_settings=safety_settings, generation_config={"response_modalities": ["TEXT", "IMAGE"]} )
Node.js (SDK @google/generative-ai)
javascriptconst { GoogleGenerativeAI, HarmCategory, HarmBlockThreshold } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-2.0-flash-exp" }); const safetySettings = [ { category: HarmCategory.HARM_CATEGORY_HARASSMENT, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_HATE_SPEECH, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT, threshold: HarmBlockThreshold.BLOCK_NONE }, { category: HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT, threshold: HarmBlockThreshold.BLOCK_NONE }, ]; const result = await model.generateContent({ contents: [{ role: "user", parts: [{ text: "Generate a product photo of a summer swimsuit" }] }], safetySettings, });
cURL (REST API)
bashcurl -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.0-flash-exp:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{"parts": [{"text": "Generate a product photo of a summer swimsuit"}]}], "safetySettings": [ {"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"}, {"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"} ], "generationConfig": {"responseMimeType": "text/plain"} }'
Важно понимать, что установка BLOCK_NONE обеспечивает почти 100% успешность для блокировок Уровня 1 -- она фактически полностью отключает этот уровень. Однако сторонние API-провайдеры, такие как laozhang.ai, поставляются с BLOCK_NONE в качестве конфигурации по умолчанию, избавляя вас от необходимости указывать эти настройки при каждом запросе. Это особенно удобно для пакетной обработки, где требуется минимальное сопротивление. При стоимости примерно $0,05 за изображение через laozhang.ai по сравнению с $0,134 через официальный API (цены на март 2026), экономия значительно нарастает при масштабировании. Документация доступна на docs.laozhang.ai для получения подробностей интеграции.
Промпт-инжиниринг для Уровня 2 (что реально работает)
Когда ваш ответ показывает finishReason: "IMAGE_SAFETY" и вы уже установили BLOCK_NONE для Уровня 1, вы имеете дело с ненастраиваемым серверным фильтром. Единственный эффективный подход здесь -- промпт-инжиниринг: перестройка промптов для генерации того же намеченного визуального результата при избежании паттернов, которые активируют классификационную модель Уровня 2. По результатам обширного тестирования в нескольких категориях контента, определённые техники трансформации промптов достигают примерно 70-80% успешных генераций для пограничного контента (анализ aifreeapi.com, март 2026).
Стратегия 1: Используйте клиническую и профессиональную лексику
Наиболее универсально эффективная техника -- замена повседневного или провокационного языка профессиональной терминологией. Классификационная модель Уровня 2 обучена на языковых паттернах, а не только на ключевых словах, поэтому формулировка вашего промпта существенно влияет на её оценку. Для фотографии нижнего белья в интернет-магазине формулировка «женщина в нижнем белье в соблазнительной позе» стабильно вызывает блокировку, тогда как «продуктовая фотография женского нижнего белья на манекене, белый фон, стиль каталога» проходит примерно в 80% случаев. Ключевая трансформация -- переход от описания человека в одежде к описанию товара в коммерческом контексте. Полное руководство по обходу триггеров системы контроля рисков содержит десятки трансформаций промптов для конкретных категорий.
Стратегия 2: Добавляйте контекстное обрамление
Явное указание коммерческого или образовательного контекста помогает классификатору Уровня 2 отнести ваш контент к легитимному. Добавление фраз типа «для каталога товаров интернет-магазина», «медицинская образовательная иллюстрация» или «референс для дизайна одежды» помещает контент в профессиональный контекст, который модель распознаёт как менее рискованный. Эта техника работает, потому что классификационная модель оценивает полный контекст промпта, а не только отдельные ключевые слова. Изображение купальника, запрошенное «для страницы товара в интернет-магазине», подвергается значительно меньшей проверке, чем то же изображение без коммерческого контекста.
Стратегия 3: Предпочитайте реалистичные стили аниме
Тестирование стабильно показывает, что стили аниме и мультфильмов вызывают значительно более высокий процент отклонений от Уровня 2, особенно для контента с участием человеческих персонажей. Это связано с тем, что изображения в стиле аниме непропорционально часто ассоциируются с нарушающим политику контентом в обучающих данных модели. Если ваш сценарий использования позволяет, переключение с «персонажа в стиле аниме» на «реалистичное цифровое искусство» или «фотореалистичный рендеринг» может повысить успешность на 20-30% для того же контента. Это одно из наиболее значительных изменений, которое можно внести с минимальными усилиями.
Реальность промпт-инжиниринга для Уровня 2 заключается в том, что он требует экспериментирования. Не существует единой техники, которая работает универсально, и Google периодически обновляет классификационную модель, что может менять то, что проходит, а что нет. Построение конвейера тестирования промптов, который систематически оценивает успешность по вашим конкретным категориям контента, -- наиболее надёжный долгосрочный подход.
Сравнение платформ: где фильтры менее агрессивны
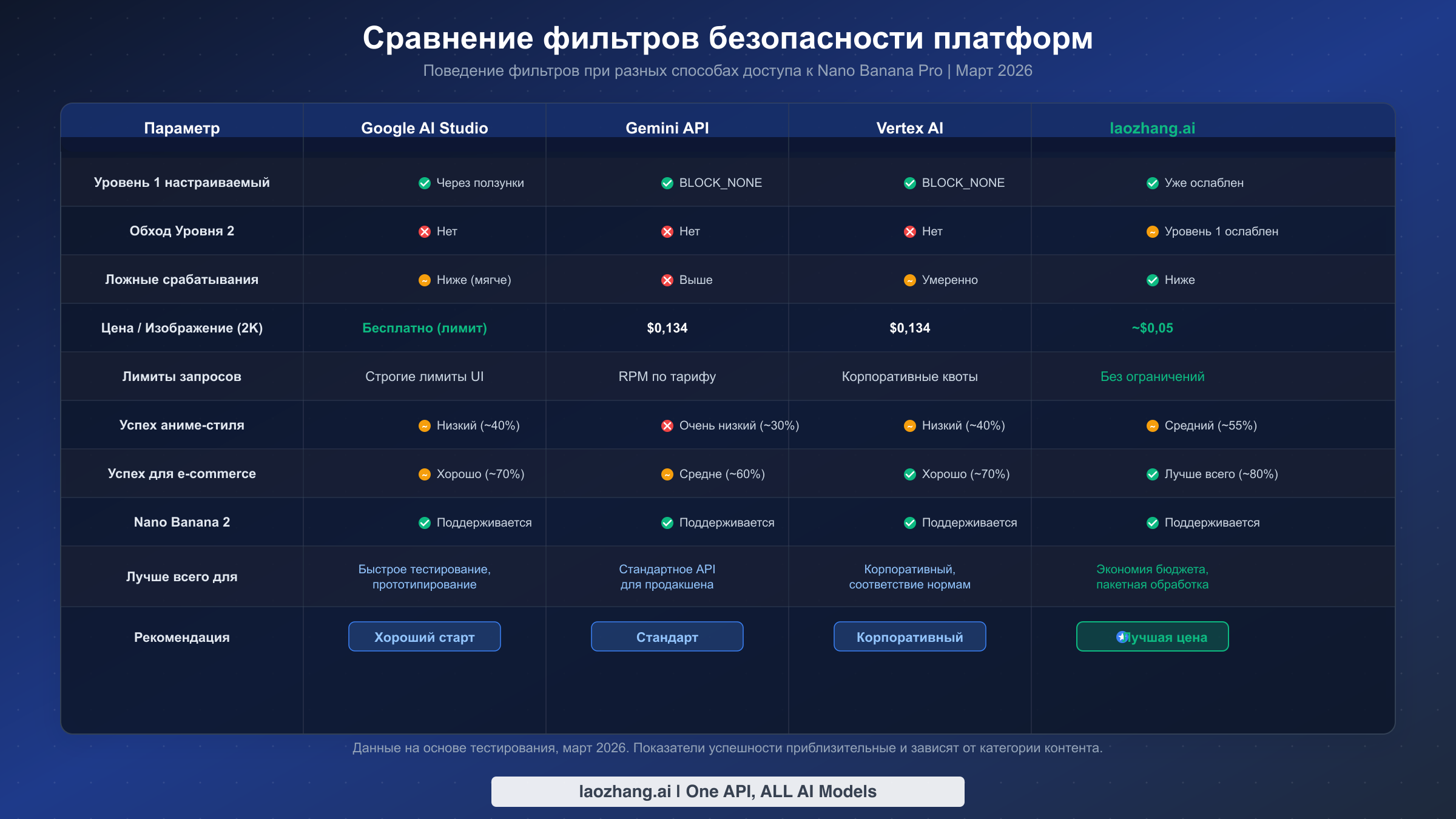
Не все платформы, обслуживающие генерацию изображений Nano Banana Pro, применяют фильтры безопасности с одинаковой агрессивностью. Понимание этих различий поможет вам выбрать подходящую платформу для вашего конкретного сценария использования. Это сравнение основано на тестировании, проведённом в марте 2026 года, и отражает текущее состояние фильтрации на каждой платформе. Для более широкого обзора всех API генерации изображений ИИ смотрите наше сравнение API генерации изображений ИИ.
Google AI Studio -- это бесплатный веб-интерфейс, предоставляющий наиболее мягкий опыт в экосистеме Google. Ползунки фильтров безопасности в интерфейсе позволяют снизить чувствительность, и в целом фильтрация ощущается менее агрессивной, чем через прямой API. Это делает его отличной средой для тестирования -- если ваш промпт работает в AI Studio, но не проходит через API, проблема скорее всего в конфигурации safety_settings, а не в Уровне 2. Однако AI Studio имеет строгие лимиты использования и не подходит для промышленной пакетной обработки.
Gemini API (прямой) применяет оба уровня на полную мощность. Уровень 1 по умолчанию имеет умеренную чувствительность, но может быть настроен в BLOCK_NONE. Уровень 2 работает на полную мощность и показывает наивысший процент ложных срабатываний среди всех платформ. Это стандартный метод доступа для большинства разработчиков и тот, на котором вы с наибольшей вероятностью столкнётесь с раздражающими блокировками IMAGE_SAFETY для легитимного контента. Подробности о ценах и уровнях доступа смотрите в нашем подробном разборе тарифов.
Vertex AI предлагает доступ корпоративного уровня с несколько иным поведением фильтрации. Хотя оба уровня по-прежнему активны, процент ложных срабатываний кажется умеренно ниже, чем у прямого Gemini API, возможно, из-за различных конфигураций развёртывания моделей. Vertex AI также предлагает контроль резидентности данных и функции соответствия нормативным требованиям, важные для корпоративных развёртываний.
Сторонние провайдеры, такие как laozhang.ai, направляют запросы через Gemini API, но поставляются с предварительно настроенным Уровнем 1 в BLOCK_NONE, полностью устраняя этот источник блокировок. При стоимости примерно $0,05 за изображение -- примерно на 62% дешевле официальной ставки $0,134 -- они предлагают лучшее соотношение цены и качества для высоконагруженной пакетной обработки. Хотя Уровень 2 по-прежнему действует (ни один легальный провайдер не может обойти серверную фильтрацию), сниженное сопротивление Уровня 1 в сочетании с более низкой ценой делает сторонних провайдеров предпочтительным выбором для электронной коммерции и креативных ИИ-приложений, работающих в рамках политики контента Google.
Контент, который нельзя исправить (когда стоит остановиться)
Одна из самых ценных вещей, которую может сообщить это руководство, -- когда следует прекратить попытки. Определённые категории контента навсегда и преднамеренно блокируются серверной системой Уровня 2, и никакой объём промпт-инжиниринга, конфигурации API или переключения платформ не позволит создать такие изображения через Nano Banana Pro или любой сервис, построенный на инфраструктуре генерации изображений Google.
Навсегда заблокированные категории включают: материалы сексуального насилия над детьми (CSAM) и любой контент, изображающий несовершеннолетних в сексуальном контексте -- это блокируется каждым легальным сервисом генерации ИИ-изображений по всему миру, не только Google. Экстремальное графическое насилие и жестокость, не служащие образовательным или журналистским целям, стабильно блокируются. Полностью откровенный порнографический контент, изображающий половые акты, выходит за рамки того, что можно обойти любыми техниками промпт-инжиниринга. После обновления политики в январе 2026 года реалистичные изображения конкретных известных личностей (особенно политиков, знаменитостей и публичных фигур) и защищённых авторским правом персонажей (персонажи Disney -- наиболее часто упоминаемый пример) также блокируются на уровне сервера.
Паттерн распознавания постоянных блокировок прост: если вы стабильно получаете finishReason: "IMAGE_SAFETY" при множественных вариациях промпта, различных стилевых подходах и нескольких сессиях, и контент попадает в одну из перечисленных выше категорий, он заблокирован навсегда. Продолжение попыток генерации тратит впустую кредиты API и инженерное время. Продуктивный путь вперёд -- либо пересмотреть требования к контенту, чтобы избежать заблокированной категории полностью, либо оценить альтернативные платформы генерации изображений, которые могут иметь другие политики контента для вашего конкретного сценария использования. Для сравнения Nano Banana Pro с другими моделями наше сравнение Nano Banana Pro и Nano Banana 2 анализирует, как более новая модель обрабатывает безопасность по-другому.
Стоит подчеркнуть, что эти постоянные блокировки существуют по важным юридическим и этическим причинам. Google подчиняется нормативным требованиям в различных юрисдикциях, которые предписывают предотвращение определённых категорий контента, и их подход соответствует отраслевым стандартам, установленным такими организациями, как Technology Coalition и NCMEC. Понимание и уважение этих границ является частью ответственной генерации ИИ-изображений.
Изменения политики 2026 года и защита конвейера на будущее
Первый квартал 2026 года принёс значительные изменения в поведение фильтров безопасности Nano Banana Pro, и ожидается, что по мере того как Google продолжает совершенствовать систему, будут ещё изменения. Отслеживание этих обновлений и построение устойчивых архитектур критически важно для промышленных развёртываний.
Январь 2026 года принёс два крупных изменения. Во-первых, Google усилила защиту интеллектуальной собственности в Уровне 2, добавив обнаружение известных личностей, логотипов брендов и защищённых авторским правом персонажей. Блокировка персонажей Disney стала наиболее заметным проявлением, вызвав широкие жалобы разработчиков на форумах Google. Во-вторых, были предположительно ужесточены ограничения фильтрации на основе географического IP, при этом некоторые разработчики в определённых регионах испытывали повышенный процент отклонений для контента, который ранее проходил. Эти изменения были реализованы на стороне сервера без необходимости изменений API, что означает, что существующий код продолжал работать, но некоторые ранее успешные промпты начали давать сбои.
27 февраля 2026 года был выпущен Nano Banana 2, построенный на Gemini 2.5 Flash, а не на Pro. Раннее тестирование показывает, что Nano Banana 2 имеет несколько иную калибровку фильтров безопасности: некоторые категории выглядят более мягкими, другие -- без изменений. При стоимости примерно $0,067 за изображение в разрешении 1K (VentureBeat, февраль 2026) -- примерно вдвое дешевле Nano Banana Pro -- он представляет убедительную альтернативу для приложений, чувствительных к стоимости, которые могут допустить потенциально отличающееся поведение фильтрации. Архитектура безопасности остаётся той же двухуровневой системой, но конкретные пороги и классификационная модель различаются.
Построение конвейеров, устойчивых к будущим изменениям, требует прогнозирования того, что поведение фильтров безопасности будет продолжать эволюционировать. Наиболее устойчивая архитектура включает несколько ключевых элементов. Во-первых, реализуйте надёжную обработку ошибок, которая обнаруживает значения finishReason и направляет сбои соответствующим образом -- блокировки Уровня 1 к исправлениям конфигурации, блокировки Уровня 2 к альтернативным промптам, а постоянные блокировки к ручной проверке. Во-вторых, поддерживайте библиотеку вариаций промптов для ваших ключевых категорий контента, чтобы при отказе одного промпта можно было автоматически попробовать альтернативы. В-третьих, отслеживайте процент отклонений с течением времени -- внезапное увеличение обычно указывает на изменение политики. В-четвёртых, рассмотрите мультипровайдерную стратегию, при которой запросы, не прошедшие через официальный API, могут быть перенаправлены к альтернативным провайдерам, таким как laozhang.ai, которые могут применять обновления политики Google с другой задержкой.
FAQ
Можно ли полностью отключить фильтры безопасности в Nano Banana Pro?
Вы можете полностью отключить Уровень 1, установив safety_settings в BLOCK_NONE для всех четырёх категорий вреда (преследование, разжигание ненависти, откровенно сексуальный контент, опасный контент). Однако Уровень 2 (IMAGE_SAFETY) работает на стороне сервера и не может быть отключён через какой-либо параметр API, настройку SDK или конфигурацию аккаунта. Эта двухуровневая конструкция является преднамеренной и затрагивает все методы доступа, включая Google AI Studio, Gemini API и Vertex AI.
Почему моё изображение блокируется даже после установки BLOCK_NONE?
Это самая распространённая путаница с Nano Banana Pro. Установка BLOCK_NONE отключает только Уровень 1. Если ваш ответ показывает finishReason: "IMAGE_SAFETY" (а не "SAFETY"), блокировка исходит от Уровня 2, который работает независимо. Уровень 2 анализирует само сгенерированное изображение с помощью ИИ-классификации и сопоставления хэшей. Ваши варианты -- промпт-инжиниринг (70-80% успешности для пограничного контента) или принятие того, что определённые категории контента заблокированы навсегда.
Nano Banana 2 менее ограничительный, чем Nano Banana Pro?
Nano Banana 2, выпущенный 27 февраля 2026 года, использует ту же двухуровневую архитектуру безопасности. Раннее тестирование показывает, что пороги классификации откалиброваны по-другому -- некоторые категории кажутся несколько более мягкими, тогда как другие остались без изменений. При стоимости примерно вдвое дешевле за изображение, чем Nano Banana Pro ($0,067 против $0,134), стоит протестировать его с вашим конкретным контентом, чтобы увидеть, лучше ли он подходит для ваших задач.
В чём разница между Google AI Studio и Gemini API для фильтров безопасности?
Google AI Studio в целом применяет менее агрессивную фильтрацию, чем прямой Gemini API, особенно для пограничного контента. Обе платформы используют одну и ту же двухуровневую систему, но пороги чувствительности по умолчанию кажутся ниже в AI Studio. Это делает AI Studio полезным диагностическим инструментом -- если ваш промпт работает там, но не проходит через API, сосредоточьтесь на конфигурации safety_settings Уровня 1.
Сколько денег я теряю из-за отклонений фильтров безопасности?
При официальной ставке Nano Banana Pro API $0,134 за изображение 2K (цены Google AI for Developers, март 2026), 30% отклонений при пакете в 1000 изображений обходятся примерно в $40 потраченных впустую на API-вызовы. При 10 000 изображений это уже $400. Оптимизация промптов для снижения процента отклонений с 30% до 10% экономит $27 на каждые 1000 изображений. Использование провайдера вроде laozhang.ai по ставке ~$0,05/изображение снижает одновременно и стоимость за изображение, и потери на отклонениях.
Сделает ли Google когда-нибудь Уровень 2 настраиваемым?
Нет никаких признаков со стороны Google, что Уровень 2 станет настраиваемым. Google публично признала, что их фильтры «более осторожны, чем планировалось», и обязалась сократить ложные срабатывания, но архитектурное разделение на настраиваемый (Уровень 1) и ненастраиваемый (Уровень 2) уровни безопасности представляется преднамеренным проектным решением, обусловленным юридическими и нормативными требованиями, а не техническим ограничением.