
Nano Banana Pro (Gemini 3 Pro Image) создаёт впечатляющие изображения с помощью ИИ, но его API может выдавать целый ряд запутанных ошибок, которые полностью останавливают ваш продакшен-конвейер. Примерно 70% всех сбоев API Nano Banana Pro приходится на ошибки 429 RESOURCE_EXHAUSTED, которые разрешаются в течение 1-5 минут, тогда как серверные ошибки 503 могут устраняться от 30 до 120 минут — и понимание того, с каким именно типом ошибки вы столкнулись, определяет, нужно ли исправлять код или просто подождать. Этот центр устранения неполадок объединяет всё, что необходимо разработчикам для диагностики, исправления и предотвращения каждой ошибки Nano Banana Pro, включая часто неправильно понимаемый механизм временных изображений, который многие разработчики ошибочно принимают за баг.
Краткое содержание
Ошибки Nano Banana Pro делятся на пять категорий, каждая из которых требует своей стратегии реагирования. Ошибки превышения лимита (429) составляют примерно 70% всех сбоев API и обычно устраняются в течение 1-5 минут — реализуйте экспоненциальную задержку, и большинство из них будут обрабатываться автоматически. Ошибки перегрузки сервера (503) не являются вашей виной; они вызваны нехваткой вычислительных ресурсов на бэкенде Google и требуют терпения: время восстановления варьируется от 30 минут до 2 часов для Gemini 3 Pro. Клиентские ошибки (400) означают, что формат вашего запроса неверен, и их можно исправить немедленно, проверив идентификатор модели, параметр разрешения и формат промпта. Если вы видите несколько изображений в ответе API, это тоже не ошибка — это черновики процесса «мышления» модели, и оплачивается только финальное изображение. Для наиболее надёжной работы сообщество разработчиков настоятельно рекомендует использовать Gemini API вместо Vertex AI, где ошибки 429 возникают значительно чаще.
Коды ошибок Nano Banana Pro: подробный разбор
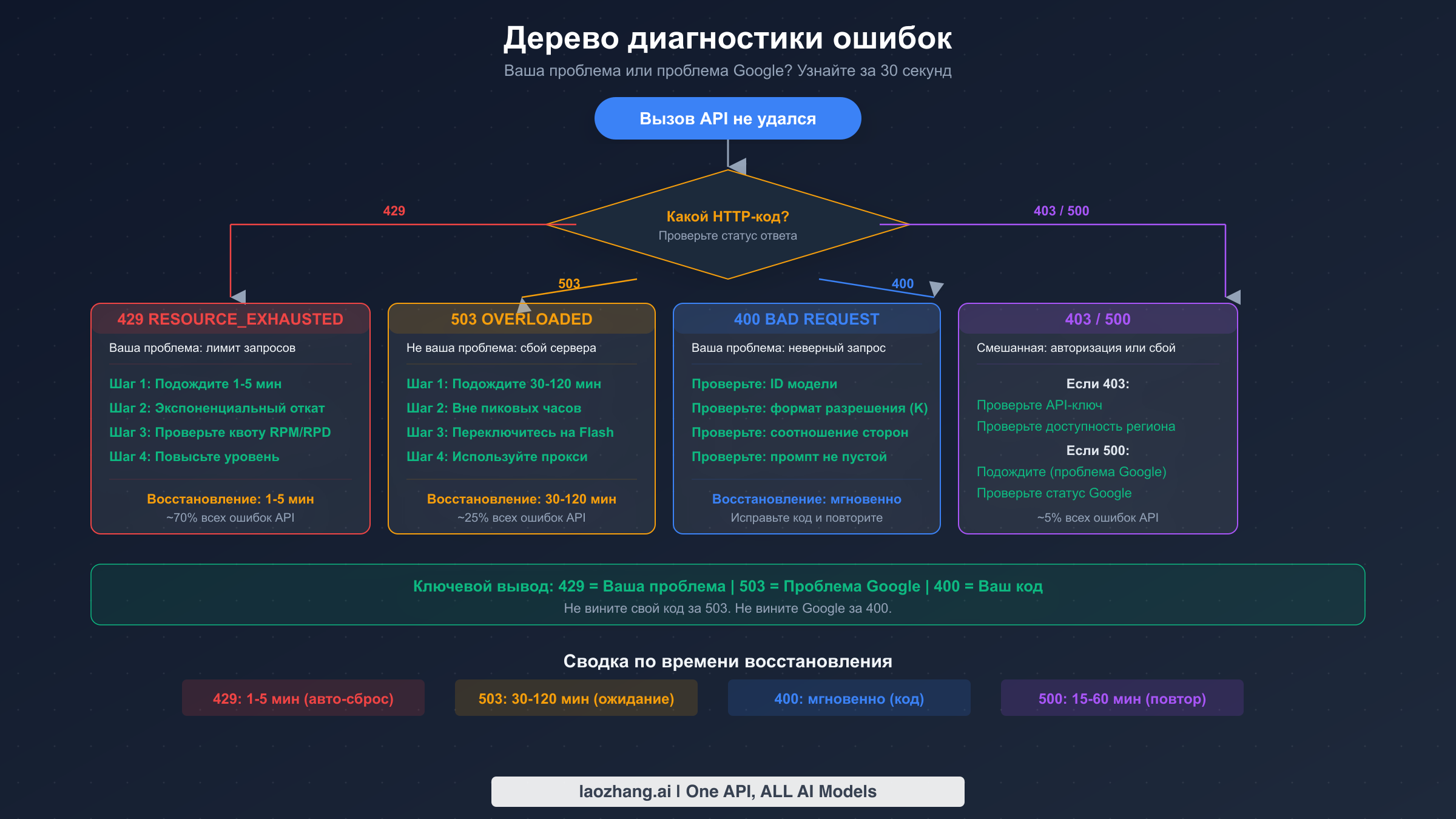
Когда ваш вызов API Nano Banana Pro завершается неудачей, HTTP-код статуса в ответе точно указывает, где находится проблема. Критически важным первым шагом является различение ошибок, которые вы можете исправить (клиентские), и ошибок, которые вы исправить не можете (серверные). Это различие экономит разработчикам часы ненужной отладки — вам не следует тратить время на рефакторинг кода, когда реальная проблема заключается в пропускной способности серверов Google, и не стоит пассивно ждать, когда исправление заключается в простой корректировке параметра в вашем запросе.
429 RESOURCE_EXHAUSTED — самая распространённая ошибка, составляющая примерно 70% всех сбоев API Nano Banana Pro согласно отчётам сообщества, проанализированным на Google AI Developer Forum и в множестве блогов разработчиков. Эта ошибка означает, что вы превысили один из нескольких параметров лимита: количество запросов в минуту (RPM), количество запросов в день (RPD) или количество токенов в минуту (TPM). Ключевая деталь, которую многие разработчики упускают: Google применяет эти лимиты одновременно по всем параметрам — превышение любого единственного показателя вызывает ошибку 429. Восстановление обычно происходит автоматически в течение 1-5 минут по мере обновления пула квоты, но постоянные ошибки 429 могут указывать на необходимость перехода на более высокий тарифный план. Если вы сейчас на бесплатном тарифе, дневной лимит генерации изображений довольно жёсткий, и переход на платный тариф существенно увеличивает вашу квоту. Вы можете проверить свои текущие лимиты и использование непосредственно в Google AI Studio. Для более глубокого погружения в механику лимитов ознакомьтесь с нашим полным руководством по лимитам.
503 SERVICE OVERLOADED принципиально отличается от ошибки 429, и понимание этого различия критически важно. Ошибка 503 указывает на то, что серверы Google не имеют достаточных вычислительных ресурсов для обработки вашего запроса, независимо от вашего индивидуального уровня использования. Это системная проблема, а не что-то, вызванное вашим кодом или аккаунтом. Время восстановления при ошибках 503 для Nano Banana Pro значительно больше, чем для других моделей: ожидайте 30-120 минут для Gemini 3 Pro по сравнению с 5-15 минутами для Gemini 2.5 Flash. В пиковые часы — которые, по данным сообщества, приходятся примерно на 00:00-02:00, 09:00-11:00 и 20:00-23:00 по пекинскому времени — частота сбоев из-за ошибок 503 может достигать 45% всех вызовов API согласно данным продакшен-мониторинга, которыми делятся разработчики. Практический ответ на ошибку 503 прост: реализуйте стратегию переключения на резервную модель, которая автоматически переходит на Gemini 2.5 Flash (стандартная модель Nano Banana), когда модель Pro недоступна, и планируйте пакетную обработку на непиковые часы, когда это возможно.
400 BAD REQUEST — это ошибки, всегда вызванные чем-то неправильным в вашем API-запросе, и их можно исправить немедленно. Наиболее распространённые причины включают использование неправильного идентификатора модели (правильный идентификатор для Nano Banana Pro — gemini-3-pro-image-preview по состоянию на февраль 2026, согласно официальной странице цен Google), указание разрешения со строчной буквой «k» вместо заглавной «K», предоставление неподдерживаемого соотношения сторон или отправку пустого или некорректного промпта. Одна неочевидная ловушка: если вы попытаетесь использовать идентификатор модели из более старой версии API, вы получите ошибку 400, а не полезное предупреждение об устаревании.
403 FORBIDDEN — ошибки, указывающие на сбой аутентификации или авторизации. Наиболее распространённые причины: недействительный или просроченный API-ключ, попытка доступа к модели из неподдерживаемого региона или использование аккаунта Google Workspace, на котором администратор установил ограничения на функции ИИ. Если вы только что создали API-ключ, подождите несколько минут для его распространения, прежде чем делать вывод о неисправности.
500 INTERNAL SERVER ERROR представляет собой сбой или необработанное исключение на серверах Google. В отличие от ошибок 503, которые указывают на известные ограничения мощности, ошибки 500 означают, что произошло что-то действительно неожиданное. Они менее распространены (примерно 5% всех ошибок) и обычно устраняются в течение 15-60 минут. Несколько пользователей на Google AI Developer Forum сообщили о постоянных ошибках 500, длившихся несколько дней в декабре 2025 года, которые команда поддержки Google признала и в конечном итоге устранила через исправление на бэкенде. Если вы сталкиваетесь с повторяющимися ошибками 500, проверьте страницу статуса Google Cloud и форум разработчиков, чтобы узнать, испытывают ли другие ту же проблему — почти наверняка дело не в вашем коде.
Механизм временных изображений: почему вы видите дополнительные картинки
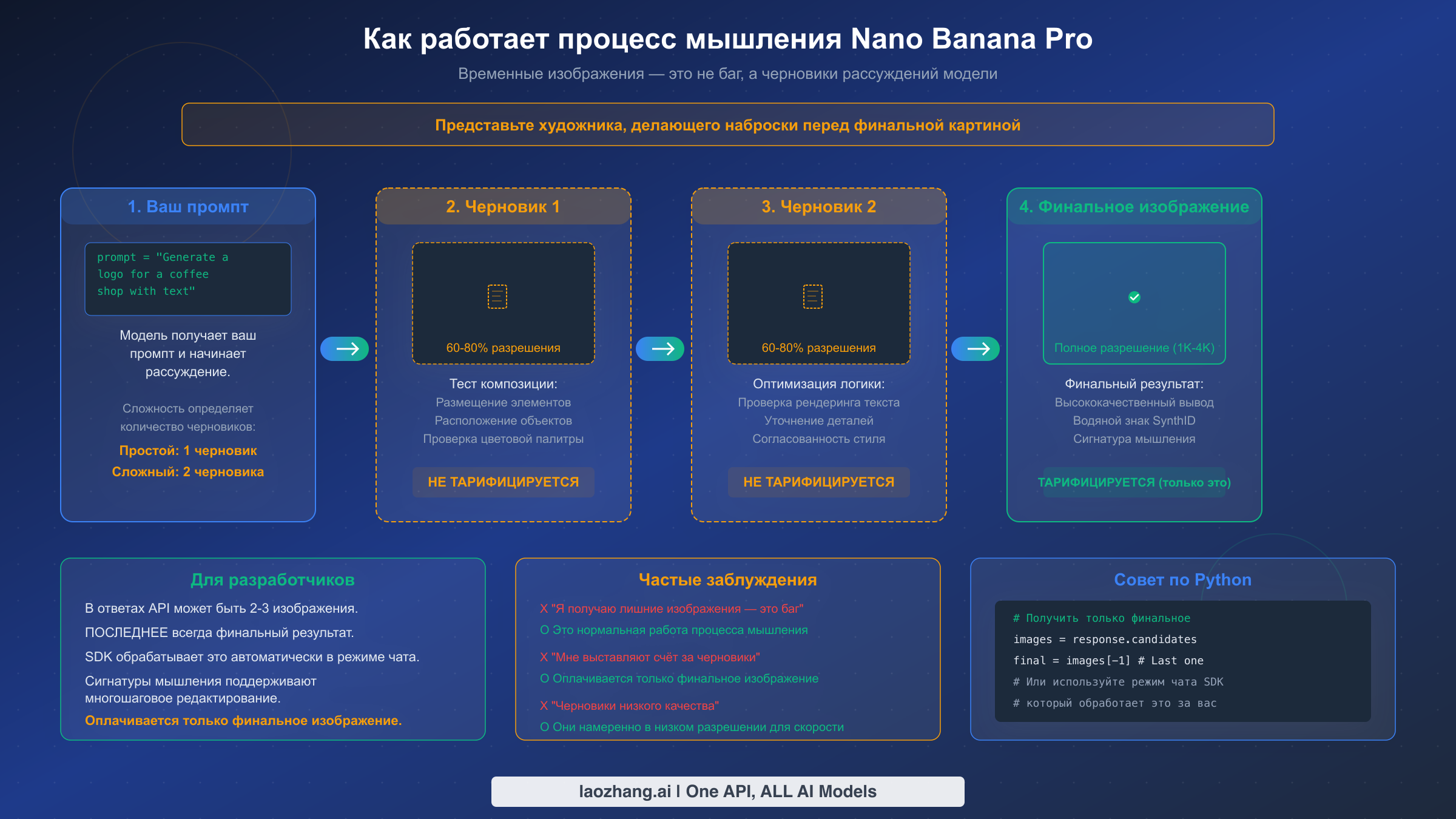
Одна из наиболее часто сообщаемых «ошибок» Nano Banana Pro на самом деле является функцией: когда вы делаете вызов API, ответ может содержать два или три изображения вместо одного запрошенного. Разработчики, впервые сталкивающиеся с таким поведением, часто предполагают, что что-то пошло не так — они создают баг-репорты, добавляют логику фильтрации для отсеивания «лишних» изображений или беспокоятся о многократной оплате. Реальность гораздо проще, и понимание этого механизма сэкономит вам значительное время на отладке и поможет выстроить более эффективные рабочие процессы генерации изображений.
Nano Banana Pro использует встроенный процесс рассуждений под названием «Thinking mode», который принципиально меняет способ генерации изображений по сравнению с более простыми моделями вроде DALL-E или Stable Diffusion. Вместо создания одного результата за один проход модель генерирует до двух промежуточных «черновых» изображений для проверки композиции и логики перед рендерингом финального результата. Представьте это как художника, создающего предварительные эскизы — черновики помогают модели оценить размещение элементов, точность отрисовки текста, расположение объектов и стилевую согласованность перед созданием финального полноразмерного изображения. Официальная документация Google на ai.google.dev подтверждает это поведение: «Модель генерирует до двух временных изображений для проверки композиции и логики. Последнее изображение в процессе мышления также является финальным отрендеренным изображением».
Количество черновых изображений зависит от сложности промпта. Простые промпты — вроде «красное яблоко на белом фоне» — могут потребовать лишь один черновик или вовсе пропустить фазу черновиков. Сложные многоэлементные композиции, особенно с рендерингом текста, логотипами или детализированными макетами, обычно проходят полный двухчерновиковый процесс. Именно поэтому сложные промпты генерируются дольше: модель действительно рассуждает о композиции, а не просто выполняет один прямой проход.
Критически важная деталь для разработчиков: временные черновые изображения не тарифицируются отдельно. Оплачивается только финальное отрендеренное изображение по стандартной ставке — примерно $0,134 за изображение 1K/2K или $0,24 за изображение 4K (ai.google.dev/pricing, февраль 2026). Черновые изображения используют 60-80% разрешения финального изображения для оптимизации скорости обработки, поэтому при прямом просмотре они могут выглядеть несколько менее качественно.
Для разработчиков, использующих официальные SDK Google Gen AI в режиме чата, подписи мышления (зашифрованные представления контекста рассуждений модели) обрабатываются автоматически, обеспечивая бесшовное многоходовое редактирование изображений. Однако если вы обрабатываете необработанные ответы API, вам необходимо явно извлечь последнее изображение из ответа как финальный результат. Вот как правильно это обрабатывать на практике — последнее изображение в массиве ответа всегда является финальным, оплачиваемым результатом, а все предшествующие изображения — это черновики процесса мышления, которые можно безопасно отбросить или записать в лог для отладки.
Готовый к продакшену код и анализ логов
Создание надёжной обработки ошибок для Nano Banana Pro требует большего, чем простые блоки try-catch. Продакшен-системам необходимы структурированное логирование, интеллектуальная логика повторных попыток, правильный парсинг ответов с учётом процесса «мышления» и корректная деградация при недоступности сервиса. Следующие примеры на Python представляют полную основу, которую вы можете адаптировать для вашего конкретного случая.
Первый паттерн, который должен реализовать каждый разработчик, — это структурированный вызов API с экспоненциальной задержкой, правильной настройкой таймаутов и всесторонним логированием. Этот единственный класс обрабатывает наиболее распространённые режимы сбоя — лимиты запросов, перегрузку серверов, таймауты и некорректные ответы — при этом обеспечивая чёткий вывод в логи, который делает отладку понятной даже в продакшен-окружении.
pythonimport google.generativeai as genai import time import logging from typing import Optional logging.basicConfig(level=logging.INFO) logger = logging.getLogger("nano_banana_pro") class NanaBananaProClient: """Production-ready Nano Banana Pro client with retry and fallback.""" def __init__(self, api_key: str, max_retries: int = 3): genai.configure(api_key=api_key) self.model = genai.GenerativeModel("gemini-3-pro-image-preview") self.fallback_model = genai.GenerativeModel("gemini-2.5-flash-image") self.max_retries = max_retries def generate_image(self, prompt: str, resolution: str = "2K") -> Optional[bytes]: """Generate image with automatic retry and fallback.""" for attempt in range(self.max_retries): try: logger.info(f"Attempt {attempt + 1}/{self.max_retries}: {prompt[:50]}...") response = self.model.generate_content( prompt, generation_config={"response_modalities": ["IMAGE", "TEXT"]}, request_options={"timeout": 300} ) return self._extract_final_image(response) except Exception as e: error_msg = str(e) if "429" in error_msg or "RESOURCE_EXHAUSTED" in error_msg: wait = min(2 ** attempt * 5, 60) logger.warning(f"Rate limited. Waiting {wait}s...") time.sleep(wait) elif "503" in error_msg or "overloaded" in error_msg.lower(): logger.warning("Server overloaded. Trying fallback model...") return self._fallback_generate(prompt) elif "400" in error_msg: logger.error(f"Bad request - fix your code: {error_msg}") return None # Don't retry client errors else: logger.error(f"Unexpected error: {error_msg}") if attempt == self.max_retries - 1: return self._fallback_generate(prompt) time.sleep(2 ** attempt) return None def _extract_final_image(self, response) -> Optional[bytes]: """Extract the final image, skipping thinking process drafts.""" images = [] for part in response.candidates[0].content.parts: if hasattr(part, "inline_data") and part.inline_data.mime_type.startswith("image/"): images.append(part.inline_data.data) if images: # The LAST image is always the final result logger.info(f"Received {len(images)} image(s). Using final image.") return images[-1] logger.warning("No image data in response") return None def _fallback_generate(self, prompt: str) -> Optional[bytes]: """Fall back to Nano Banana (Flash) when Pro is unavailable.""" try: logger.info("Using fallback: gemini-2.5-flash-image") response = self.fallback_model.generate_content( prompt, generation_config={"response_modalities": ["IMAGE", "TEXT"]}, request_options={"timeout": 120} ) return self._extract_final_image(response) except Exception as e: logger.error(f"Fallback also failed: {e}") return None
Второй критически важный паттерн — анализ логов. При отладке проблем Nano Banana Pro в продакшене ваши логи должны фиксировать конкретные данные, помогающие различать типы ошибок и выявлять закономерности. Описанный выше подход к структурированному логированию формирует записи, включающие номер попытки, тип ошибки, время ожидания и факт использования резервной модели — всё это необходимо для диагностики повторяющихся проблем. Обращайте особое внимание на соотношение ошибок 429 и 503: если вы видите преимущественно ошибки 429, вашему приложению, вероятно, нужна более тщательная ограничительная логика на вашей стороне или переход на более высокий тарифный план. Если преобладают ошибки 503, проблема на стороне инфраструктуры Google, и вам стоит рассмотреть планирование рабочей нагрузки на непиковые часы. Более подробную информацию о работе лимитов на разных тарифных планах вы найдёте в нашем детальном разборе ошибки resource exhausted.
Метод _extract_final_image в приведённом коде особенно важен, поскольку он корректно обрабатывает механизм «мышления». Всегда беря images[-1] (последнее изображение в ответе), вы автоматически получаете финальный результат наивысшего качества независимо от того, сколько черновых изображений модель сгенерировала в процессе мышления. Этот подход работает как с простыми промптами (одно изображение), так и со сложными (два черновика плюс финальное изображение).
Чтение продакшен-логов для диагностики проблем — это навык, который отличает опытных разработчиков от новичков при работе с Nano Banana Pro. Вот как выглядят реальные выходные данные продакшен-логов и как интерпретировать каждый сценарий:
INFO Attempt 1/3: "A futuristic city skyline with neon signs..."
INFO Received 3 image(s). Using final image.
→ Интерпретация: Модель создала 2 черновика + 1 финальный. Нормальное поведение.
# Сценарий 2: Превышение лимита с успешным повтором
INFO Attempt 1/3: "Product photo of a leather bag..."
WARNING Rate limited. Waiting 5s...
INFO Attempt 2/3: "Product photo of a leather bag..."
INFO Received 1 image(s). Using final image.
→ Интерпретация: Достигнут лимит RPM, восстановление после задержки. Рассмотрите увеличение интервалов между запросами.
# Сценарий 3: Перегрузка сервера с переключением на резервную модель
INFO Attempt 1/3: "Detailed architectural blueprint..."
WARNING Server overloaded. Trying fallback model...
INFO Using fallback: gemini-2.5-flash-image
INFO Received 1 image(s). Using final image.
→ Интерпретация: Модель Pro недоступна, модель Flash справилась. Качество может отличаться.
# Сценарий 4: Полный отказ
INFO Attempt 1/3: "Complex multi-element poster..."
ERROR Unexpected error: 500 Internal Server Error
INFO Attempt 2/3: "Complex multi-element poster..."
ERROR Unexpected error: 500 Internal Server Error
INFO Attempt 3/3: "Complex multi-element poster..."
ERROR Unexpected error: 500 Internal Server Error
WARNING Server overloaded. Trying fallback model...
ERROR Fallback also failed: 500 Internal Server Error
→ Интерпретация: Системный сбой. Проверьте страницу статуса Google, подождите 15-60 мин.
Паттерн, который следует отслеживать при анализе логов за период, — это соотношение ошибок 429 к 503. Если ошибки 429 преобладают (более 80% сбоев), ваше приложение отправляет запросы слишком агрессивно — реализуйте очередь запросов с ограничителем скорости, учитывающим лимит RPM вашего тарифного плана. Если преобладают ошибки 503, узким местом является инфраструктура Google, и лучшие варианты — планирование пакетных задач на непиковые часы или поддержание резервного переключения на модель Flash. Здоровая продакшен-система должна показывать менее 5% общей частоты сбоев в непиковые часы и менее 20% в пиковые — значительное превышение этих порогов требует расследования.
Для продвинутого мониторинга рассмотрите добавление простого слоя агрегации метрик, отслеживающего почасовую долю успешных запросов, среднюю задержку и распределение типов ошибок. Даже базовая реализация с использованием collections.Counter из Python и записью почасовых сводок в файл логов может обеспечить необходимую прозрачность для оптимизации ваших паттернов использования API со временем.
Настройка таймаутов и повторных попыток
Генерация изображений Nano Banana Pro по своей природе медленнее по сравнению с генерацией текста — одно изображение может занимать от 30 до 170 секунд в зависимости от разрешения и сложности промпта. Значения HTTP-таймаутов по умолчанию в большинстве библиотек программирования слишком агрессивны для такой нагрузки, и неправильно настроенные таймауты являются одним из самых распространённых источников ложных сбоев. Правильная настройка таймаутов — простая, но критически важная оптимизация, которая может радикально повысить процент успешных запросов без каких-либо изменений на стороне API-сервера.
Рекомендуемые значения таймаутов варьируются в зависимости от разрешения и основаны на наблюдаемом времени генерации плюс запас безопасности. Для изображений 1K (разрешение по умолчанию) установите таймаут чтения на 300 секунд. Фактическая генерация обычно занимает 30-90 секунд, но вариабельность сети и время ожидания в очереди сервера могут значительно увеличить это время в пиковые часы. Для изображений 2K сохраняйте 300-секундный таймаут — генерация занимает 50-120 секунд, а дополнительный запас учитывает увеличенную вычислительную нагрузку. Для изображений 4K увеличьте таймаут до 600 секунд, поскольку генерация может занимать 100-170 секунд даже в идеальных условиях, и вам нужен существенный запас для задержек в пиковые часы.
Тонкий, но важный технический момент — версия HTTP-протокола. Некоторые разработчики сообщают, что соединения HTTP/2 могут вызывать преждевременные разрывы при длительных запросах Nano Banana Pro, потому что все потоки HTTP/2 разделяют одно TCP-соединение — потеря пакета блокирует все потоки одновременно. Если вы испытываете необъяснимые таймауты, несмотря на щедрые значения таймаутов, попробуйте явно принудительно использовать HTTP/1.1 в вашем HTTP-клиенте. В библиотеке Python httpx это означает установку http2=False; в библиотеке requests HTTP/1.1 используется по умолчанию. Различие между таймаутом соединения и таймаутом чтения здесь имеет значение: установите короткий таймаут соединения (10 секунд) для установки TCP-соединения и длинный таймаут чтения (300-600 секунд) для приёма данных во время окна генерации изображения. В библиотеке Python requests используйте timeout=(10, 600) в виде кортежа для раздельной настройки.
Вот полный пример конфигурации таймаутов, учитывающий все описанные выше нюансы. Эта конфигурация разделяет таймауты соединения и чтения, принудительно использует HTTP/1.1 и включает рекомендуемые значения для каждого уровня разрешения:
pythonimport google.generativeai as genai import random # Timeout configuration by resolution TIMEOUT_CONFIG = { "1K": {"connect": 10, "read": 300}, # 30-90s typical generation "2K": {"connect": 10, "read": 300}, # 50-120s typical generation "4K": {"connect": 10, "read": 600}, # 100-170s typical generation } def generate_with_proper_timeout(prompt: str, resolution: str = "2K"): """Generate image with resolution-appropriate timeout.""" config = TIMEOUT_CONFIG.get(resolution, TIMEOUT_CONFIG["2K"]) model = genai.GenerativeModel("gemini-3-pro-image-preview") for attempt in range(3): try: response = model.generate_content( prompt, generation_config={"response_modalities": ["IMAGE", "TEXT"]}, request_options={"timeout": config["read"]} ) return response except Exception as e: if "429" in str(e): # Exponential backoff with jitter wait = min(2 ** attempt * 5, 60) + random.uniform(0, 2) time.sleep(wait) elif "timeout" in str(e).lower(): # Timeout: increase buffer and retry config["read"] = int(config["read"] * 1.5) continue else: raise return None
| Разрешение | Таймаут соединения | Таймаут чтения | Типичное время генерации | Запас безопасности |
|---|---|---|---|---|
| 1K (по умолчанию) | 10 с | 300 с | 30-90 с | 3,3-10x |
| 2K | 10 с | 300 с | 50-120 с | 2,5-6x |
| 4K | 10 с | 600 с | 100-170 с | 3,5-6x |
Для стратегии повторных попыток экспоненциальная задержка с джиттером является стандартным подходом. Начните с 5-секундной задержки, удваивайте её при каждой повторной попытке и добавляйте случайный джиттер 0-2 секунды для предотвращения эффекта «громового стада», когда несколько клиентов повторяют попытки одновременно. Ограничьте максимальную задержку 60 секундами и максимальное количество повторных попыток 3-5. Если все повторные попытки не удались, переключитесь на резервную модель Nano Banana (Flash), а не сдавайтесь полностью — Flash генерирует быстрее и имеет более короткие окна восстановления при серверных ошибках.
Одна из частых ошибок разработчиков — реализация логики повторных попыток, которая одинаково обрабатывает все ошибки. Примеры кода в этой статье различают повторяемые ошибки (429, 503, таймаут) и неповторяемые ошибки (400, 403). Повторная отправка запроса с ошибкой 400 Bad Request тратит время и квоту API, потому что один и тот же некорректный запрос всегда будет завершаться неудачей. Точно так же немедленный повтор при ошибке 503 в течение нескольких секунд вряд ли увенчается успехом, поскольку перегрузка серверов устраняется за минуты или часы — ваша логика повторных попыток должна распознавать ошибки 503 и либо немедленно переключаться на резервную модель, либо реализовать значительно более длительное ожидание (минимум 5-10 минут) перед повторной попыткой с моделью Pro.
Gemini API vs Vertex AI — сравнение платформ
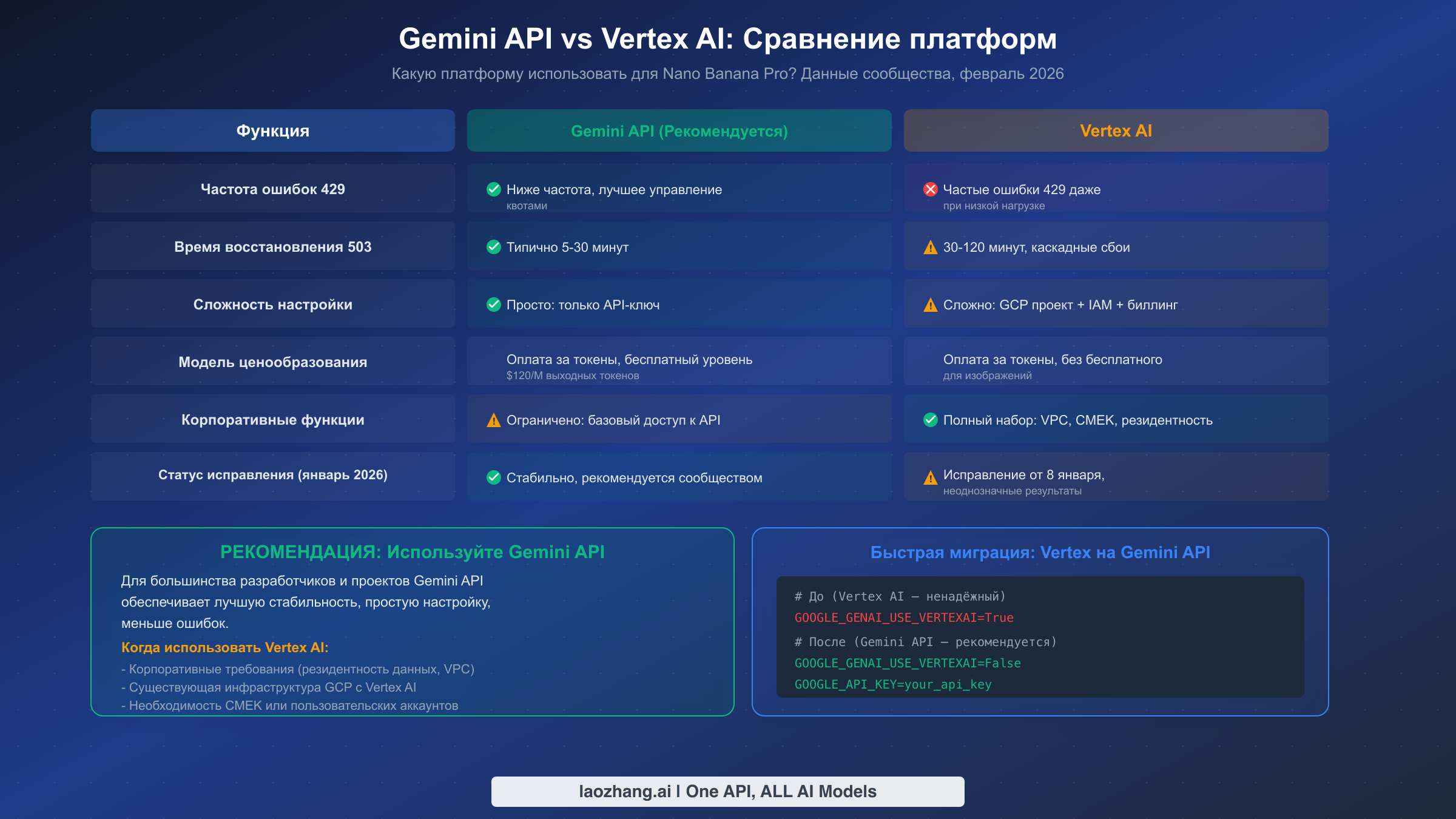
Выбор между Gemini API и Vertex AI от Google для работы с Nano Banana Pro имеет значительные последствия для надёжности, и консенсус сообщества однозначен: Gemini API в настоящее время более стабилен для задач генерации изображений. Эта оценка основана на многочисленных отчётах разработчиков на Google AI Developer Forum и подтверждена действиями команды поддержки Google — когда разработчики сообщали о постоянных ошибках 429 на Vertex AI, поддержка Google указала, что исправление было развёрнуто к 8 января 2026 года, хотя результаты по-прежнему неоднозначны.
Разница в стабильности наиболее заметна в частоте ошибок 429. Многие разработчики сообщают, что переключение с Vertex AI на Gemini API путём установки GOOGLE_GENAI_USE_VERTEXAI=False устраняет или существенно сокращает ошибки RESOURCE_EXHAUSTED даже при той же нагрузке и том же аккаунте. Один особенно показательный отчёт описывал «молниеносную скорость» в один день, за которой следовали постоянные ошибки resource exhausted на следующий день на Vertex AI, несмотря на низкое общее использование — поведение, которое не наблюдалось после перехода на Gemini API. Коренная причина, по-видимому, заключается в различиях того, как две платформы выделяют и управляют пулами квот для моделей генерации изображений.
Практические последствия выходят за рамки частоты ошибок. Vertex AI требует полной настройки GCP-проекта с конфигурацией IAM, биллинговыми аккаунтами и учётными данными сервисных аккаунтов, что добавляет сложности как к первоначальному развёртыванию, так и к отладке. Gemini API, напротив, требует только API-ключ — вы можете начать работу менее чем за минуту. По ценообразованию обе платформы используют одинаковую модель оплаты за токен ($120 за миллион выходных токенов для Nano Banana Pro), но ни одна из платформ в настоящее время не предлагает бесплатный тарифный план для генерации изображений (по состоянию на февраль 2026, согласно ai.google.dev/pricing), хотя Gemini API имеет значительно более простую настройку биллинга.
Тем не менее у Vertex AI есть обоснованные преимущества для корпоративных сценариев. Если вашей организации необходим контроль местоположения данных, интеграция с Virtual Private Cloud (VPC), управляемые клиентом ключи шифрования (CMEK) или пользовательские сервисные аккаунты, Vertex AI — единственный вариант. Крупные предприятия с существующей инфраструктурой GCP также могут предпочесть Vertex AI за его интеграцию с другими сервисами Google Cloud, даже ценой несколько сниженной надёжности для генерации изображений.
Миграция с Vertex AI на Gemini API удивительно проста для большинства разработчиков. Если вы используете официальный SDK Google Gen AI, переключение требует только изменения переменных окружения — изменения кода не нужны:
bash# Before (Vertex AI — higher 429 error rates reported) GOOGLE_GENAI_USE_VERTEXAI=True GOOGLE_CLOUD_PROJECT=your-gcp-project GOOGLE_CLOUD_REGION=us-central1 # After (Gemini API — recommended for stability) GOOGLE_GENAI_USE_VERTEXAI=False GOOGLE_API_KEY=your_gemini_api_key
Ваш код промптов, обработка ответов и логика обработки изображений остаются абсолютно такими же, потому что SDK Google Gen AI абстрагирует различия между платформами. Единственное заметное изменение в вашем приложении — снижение частоты ошибок и более простое управление учётными данными. Для проектов, которым необходимо поддерживать Vertex AI в качестве резерва для корпоративного соответствия и одновременно использовать Gemini API как основной путь, простое переключение через переменную окружения позволяет динамически переключаться между ними — вы даже можете реализовать автоматическое переключение платформ, которое сначала пробует Gemini API и переходит на Vertex AI только тогда, когда для конкретного запроса требуются корпоративные функции (например, изоляция VPC).
Важный момент при миграции: если ваша существующая настройка Vertex AI использует имперсонацию сервисных аккаунтов или федерацию идентификации рабочих нагрузок для аутентификации, эти механизмы специфичны для GCP и не переносятся на Gemini API. Вам потребуется сгенерировать стандартный API-ключ в Google AI Studio. Компромисс — простота против детального контроля доступа: API-ключами проще управлять, но они предлагают менее гранулярный контроль прав доступа по сравнению с ролями GCP IAM. Для большинства задач генерации изображений подхода с API-ключом более чем достаточно, и повышение стабильности вполне оправдывает более простую модель аутентификации. Если вы оцениваете затраты и производительность при выборе между платформами, наши результаты тестирования цен и скорости предоставляют количественные сравнения, которые могут помочь в принятии решения.
Оптимизация затрат и лучшие практики
Эксплуатация Nano Banana Pro в продакшене требует внимания к управлению затратами, поскольку повторные попытки, неудачные запросы и неоптимальное время отправки могут значительно увеличить ваши расходы на API. Одно изображение 2K стоит примерно $0,134 за генерацию через официальный API, но если ваша логика повторных попыток запускает три попытки на каждое успешное изображение из-за ошибок 429 в пиковые часы, ваши эффективные расходы утраиваются. Понимание влияния вашей стратегии обработки ошибок на затраты критически важно для сохранения экономической целесообразности генерации изображений в масштабе.
Наиболее результативная оптимизация затрат — избегание пиковых часов. По данным мониторинга продакшен-пользователей, частота ошибок 503 может достигать 45% в пиковые часы, что означает, что почти половина ваших API-вызовов завершается неудачей и должна быть повторена. Если ваш сценарий использования допускает пакетную обработку — генерация маркетинговых материалов, изображений товаров или иллюстраций к контенту — планирование этих задач на непиковые часы (примерно 03:00-08:00 и 14:00-19:00 по пекинскому времени, по данным сообщества) может снизить частоту повторных попыток с почти 50% до менее 10%, сокращая эффективные затраты на 30-40%.
Переключение на резервную модель — второй важный рычаг управления затратами. Когда Nano Banana Pro (Gemini 3 Pro Image) испытывает высокую частоту ошибок, переключение на стандартную модель Nano Banana (Gemini 2.5 Flash Image, gemini-2.5-flash-image) обеспечивает жизнеспособную альтернативу за малую часть стоимости. Хотя модель Flash лишена процесса «мышления» и создаёт несколько менее утончённые композиции, она генерирует изображения быстрее и со значительно более высокой надёжностью. Для некритичных задач генерации изображений вы можете рассмотреть использование модели Flash в качестве основной, сохраняя Pro для задач, которые конкретно требуют продвинутого рендеринга текста, сложных композиций или разрешения 4K.
Для разработчиков, обрабатывающих большие объёмы изображений, пакетный API Google предлагает 50% скидку на тарификацию выходных токенов — снижая стоимость изображения с примерно $0,134 до $0,067 для изображений 2K. Компромисс — задержка: пакетные запросы могут обрабатываться до 24 часов. Если ваш рабочий процесс допускает такую задержку, экономия существенна. Сторонние прокси-сервисы API, такие как laozhang.ai, предлагают ещё один путь оптимизации затрат, обеспечивая доступ к Nano Banana Pro по цене примерно $0,05 за изображение — примерно на 60% ниже официальных тарифов API — с дополнительным преимуществом встроенной логики повторных попыток и балансировки нагрузки между несколькими API-ключами, что может сгладить проблемы с лимитами.
Мониторинг работоспособности вашего API — это последняя лучшая практика, которая окупается со временем. Отслеживайте процент успешных запросов, среднюю задержку, распределение типов ошибок (429 vs 503 vs другие) и стоимость за успешное изображение на ежедневной и почасовой основе. Эти данные выявляют паттерны — например, конкретные часы, когда частота ошибок резко возрастает — что позволяет оптимизировать планирование, корректировать параметры повторных попыток и принимать обоснованные решения о повышении тарифного плана или переключении платформы. Пример кода в разделе «Готовый к продакшену код» выше включает основу для этого мониторинга через подход к структурированному логированию. Для более широкого понимания того, как лимиты бесплатного и Pro тарифов влияют на вашу структуру затрат, ознакомьтесь со сравнением тарифных планов, которое поможет выбрать правильный план для вашего объёма использования.
FAQ
Почему мой вызов API Nano Banana Pro возвращает несколько изображений?
Это нормальное поведение процесса «мышления», а не ошибка. Nano Banana Pro генерирует до двух черновых изображений для проверки композиции и логики перед созданием финального результата. Последнее изображение в ответе API всегда является финальным, оплачиваемым результатом. Черновые изображения генерируются в 60-80% разрешения и не тарифицируются отдельно. Если вы используете официальные SDK Google Gen AI в режиме чата, подписи мышления автоматически обрабатывают многоходовой контекст.
В чём разница между ошибкой 429 и ошибкой 503?
Ошибка 429 означает, что вы превысили свой лимит запросов — она вызвана вашим паттерном использования и разрешается за 1-5 минут. Ошибка 503 означает, что серверы Google перегружены — она не имеет отношения к вашему коду или использованию и может устраняться 30-120 минут. Никогда не отлаживайте свой код при ошибке 503, и никогда просто не ждите при ошибке 429, не изучив своё использование лимитов.
Что лучше использовать для Nano Banana Pro: Gemini API или Vertex AI?
Для большинства разработчиков рекомендуется Gemini API. Отчёты сообщества последовательно показывают более низкую частоту ошибок 429, более простую настройку (только API-ключ вместо полного проекта GCP) и эквивалентное ценообразование. Используйте Vertex AI только если вам нужны корпоративные функции, такие как интеграция с VPC, контроль местоположения данных или управляемые клиентом ключи шифрования.
Какой таймаут следует установить для API?
Для изображений 1K и 2K используйте 300 секунд. Для изображений 4K используйте 600 секунд. Эти значения учитывают время генерации (30-170 секунд в зависимости от разрешения) плюс вариабельность сети и задержки очереди сервера в пиковые часы. Всегда разделяйте таймаут соединения (10 секунд) и таймаут чтения.
Почему я постоянно получаю «An internal error has occurred» в Google AI Studio?
Как правило, это ошибка 500 Internal Server Error на бэкенде Google, а не что-то, вызванное вами. Несколько разработчиков сообщили об этой проблеме, сохранявшейся несколько дней в декабре 2025 года, пока Google не развернул исправление. Проверьте Google AI Developer Forum, чтобы узнать, испытывают ли другие ту же проблему, поскольку это обычно указывает на системную проблему, а не на проблему, специфичную для аккаунта. Очистка кэша браузера и обновление сессии иногда помогают для веб-интерфейса, но для постоянных ошибок API необходимо дождаться, пока Google устранит проблему на бэкенде.
Учитываются ли временные изображения мышления в моей квоте?
Нет. Только финальное отрендеренное изображение учитывается в вашей квоте лимита запросов и тарифицируется. Временные черновые изображения, сгенерированные в процессе мышления, являются внутренними для рассуждений модели и не расходуют вашу квоту RPM, RPD или биллинговую квоту. Это подтверждено в официальной документации Google по генерации изображений.
Как снизить расходы на API Nano Banana Pro в продакшене?
Три наиболее эффективные стратегии снижения затрат: избегание пиковых часов (планирование пакетных задач на 03:00-08:00 или 14:00-19:00 по пекинскому времени может снизить затраты, связанные с повторными попытками, на 30-40%), переключение на резервную модель (использование Gemini 2.5 Flash Image по $0,039/изображение для некритичных задач вместо Pro по $0,134/изображение) и пакетный API Google (предлагающий 50% скидку по $0,067/изображение для разрешения 2K с компромиссом в виде до 24-часовой задержки обработки). Сторонние прокси-сервисы, такие как laozhang.ai, могут дополнительно снизить затраты до примерно $0,05/изображение со встроенной логикой повторных попыток и балансировкой нагрузки. Для высоконагруженных продакшен-задач комбинирование всех трёх стратегий — пакетный API для несрочных задач, Flash для стандартного качества и Pro только для премиального результата — может снизить ваши эффективные затраты на генерацию изображений на 60-70% по сравнению с наивным вызовом модели Pro для каждого запроса.
В чём разница между Nano Banana и Nano Banana Pro?
Nano Banana — это стандартная модель, Gemini 2.5 Flash Image (gemini-2.5-flash-image), которая генерирует изображения быстро при низкой стоимости ($0,039/изображение), но без продвинутого процесса мышления. Nano Banana Pro — это Gemini 3 Pro Image (gemini-3-pro-image-preview), использующая механизм мышления с несколькими черновиками для более качественных композиций, лучшего рендеринга текста и поддержки разрешения 4K, но по более высокой цене ($0,134/изображение для 2K) и с более длительным временем генерации (30-170 секунд по сравнению с 10-30 секундами для Flash). В продакшене рекомендуемый подход — использовать Pro в качестве основной модели с Flash как автоматическим резервом — это обеспечивает наилучшее качество, когда модель Pro доступна, сохраняя при этом непрерывность обслуживания в периоды перегрузки серверов.