
Краткое содержание
Ошибки Nano Banana Pro делятся на три категории: серверные ошибки (503/500 — проблема на стороне Google, повторяйте запрос с экспоненциальной задержкой), клиентские ошибки (400/403 — исправьте тело запроса или разрешения) и превышение лимитов (429 — проверьте квоту в Google AI Studio). По состоянию на февраль 2026 года наиболее распространённая ошибка — 503 UNAVAILABLE в часы пиковой нагрузки (10:00–14:00 UTC), которая затрагивает до 45% вызовов API. Вторая наиболее запутанная проблема — временные изображения, появляющиеся в ответах: это предусмотренное поведение, а не баг, и они не тарифицируются. В этом руководстве рассмотрены все коды ошибок с реальными примерами ответов API, исправлениями на Python и JavaScript, а также полная реализация механизма повторных попыток, которую можно скопировать в ваш проект.
Быстрая диагностика — определите ошибку за 30 секунд

Каждая ошибка Nano Banana Pro чётко указывает, кто именно является причиной проблемы. HTTP-код статуса в ответе API — это ваш первый и самый важный диагностический сигнал. Понимание этой единственной информации сэкономит вам часы отладки, потому что способ исправления полностью зависит от того, возникла ошибка на серверах Google или в вашем запросе.
Основное правило простое: ошибки 5xx означают, что инфраструктура Google испытывает нагрузку, и вам следует подождать и повторить запрос. Ошибки 4xx означают, что проблема в вашем запросе, и повторная отправка того же запроса всегда завершится неудачей. Это различие важно, потому что разработчики часто тратят время на «исправление» своего кода, когда реальная проблема — перегрузка сервера, или продолжают повторять некорректные запросы, которые никогда не будут выполнены.
Вот краткая диагностическая таблица, охватывающая восемь наиболее распространённых ошибок при работе с API Nano Banana Pro (ID модели: gemini-3-pro-image-preview, согласно ai.google.dev/pricing, февраль 2026):
| HTTP-код | gRPC-статус | Значение | Ваше действие | Можно повторить? |
|---|---|---|---|---|
| 503 | UNAVAILABLE | Серверы Google перегружены | Подождите 30–60 с, повторите с задержкой | Да |
| 500 | INTERNAL | Ошибка на стороне сервера | Упростите промпт, повторите через 60 с | Да (ограниченно) |
| 502 | — | Ошибка шлюза/прокси | Проверьте URL эндпоинта, повторите | Да |
| 429 | RESOURCE_EXHAUSTED | Превышен лимит запросов | Проверьте квоту, дождитесь сброса | Да (после ожидания) |
| 400 | INVALID_ARGUMENT | Неверный формат запроса | Исправьте тело запроса, проверьте thought_signature | Нет |
| 400 | FAILED_PRECONDITION | Проблема с регионом/биллингом | Включите биллинг, проверьте регион | Нет |
| 403 | PERMISSION_DENIED | API-ключ не имеет прав | Проверьте API-ключ и настройки проекта | Нет |
| 404 | NOT_FOUND | Ресурс не найден | Проверьте ссылки на медиафайлы | Нет |
Получив ошибку, первым делом всегда проверяйте HTTP-код статуса. Если он начинается с 5 — прекратите отладку кода: проблема на стороне Google. Если он начинается с 4 — проблема в вашем запросе, и вам нужно изучить детали сообщения об ошибке, чтобы понять, что исправить. Массив details в JSON-ответе часто содержит конкретные имена полей и ошибки валидации, которые указывают непосредственно на проблему.
Полный справочник кодов ошибок Nano Banana Pro
Помимо быстрой диагностической таблицы, понимание полной структуры ответа об ошибке необходимо для создания надёжных приложений. Каждая ошибка от Gemini API возвращает структурированный JSON-ответ, содержащий HTTP-код статуса, строку gRPC-статуса, понятное сообщение и иногда массив details с дополнительной информацией об ошибке. Вот как выглядит реальный ответ об ошибке 503, когда ваш вызов API попадает на перегруженный сервер:
json{ "error": { "code": 503, "message": "The model is overloaded. Please try again later.", "status": "UNAVAILABLE", "details": [ { "@type": "type.googleapis.com/google.rpc.DebugInfo", "detail": "backend_error" } ] } }
Ошибка 429 о превышении лимита выглядит иначе и предоставляет более практичную информацию, включая указание конкретного лимита, который вы превысили:
json{ "error": { "code": 429, "message": "Resource has been exhausted (e.g. check quota).", "status": "RESOURCE_EXHAUSTED", "details": [ { "@type": "type.googleapis.com/google.rpc.RetryInfo", "retryDelay": "36s" } ] } }
Обратите внимание, что ответ 429 содержит поле retryDelay — оно указывает точное время ожидания до следующей попытки. Всегда следуйте этому значению, а не гадайте. Ошибка 400 INVALID_ARGUMENT — самая разнообразная, потому что она охватывает множество типов ошибок валидации запроса: от отсутствующих обязательных полей до некорректных данных изображения и всё более частой проблемы с thought_signature в многоходовых диалогах.
Классификация ошибок по степени серьёзности важна для кода обработки ошибок. Критические ошибки (503, 500) требуют немедленной логики повторных попыток с задержкой. Предупреждающие ошибки (429) требуют управления квотой и, возможно, повышения тарифного плана. Информационные ошибки (400, 403) требуют изменений в коде и никогда не должны повторяться без модификации. Построение обработчика ошибок на основе этих трёх категорий — а не обработка каждого кода отдельно — приводит к более чистому и поддерживаемому коду.
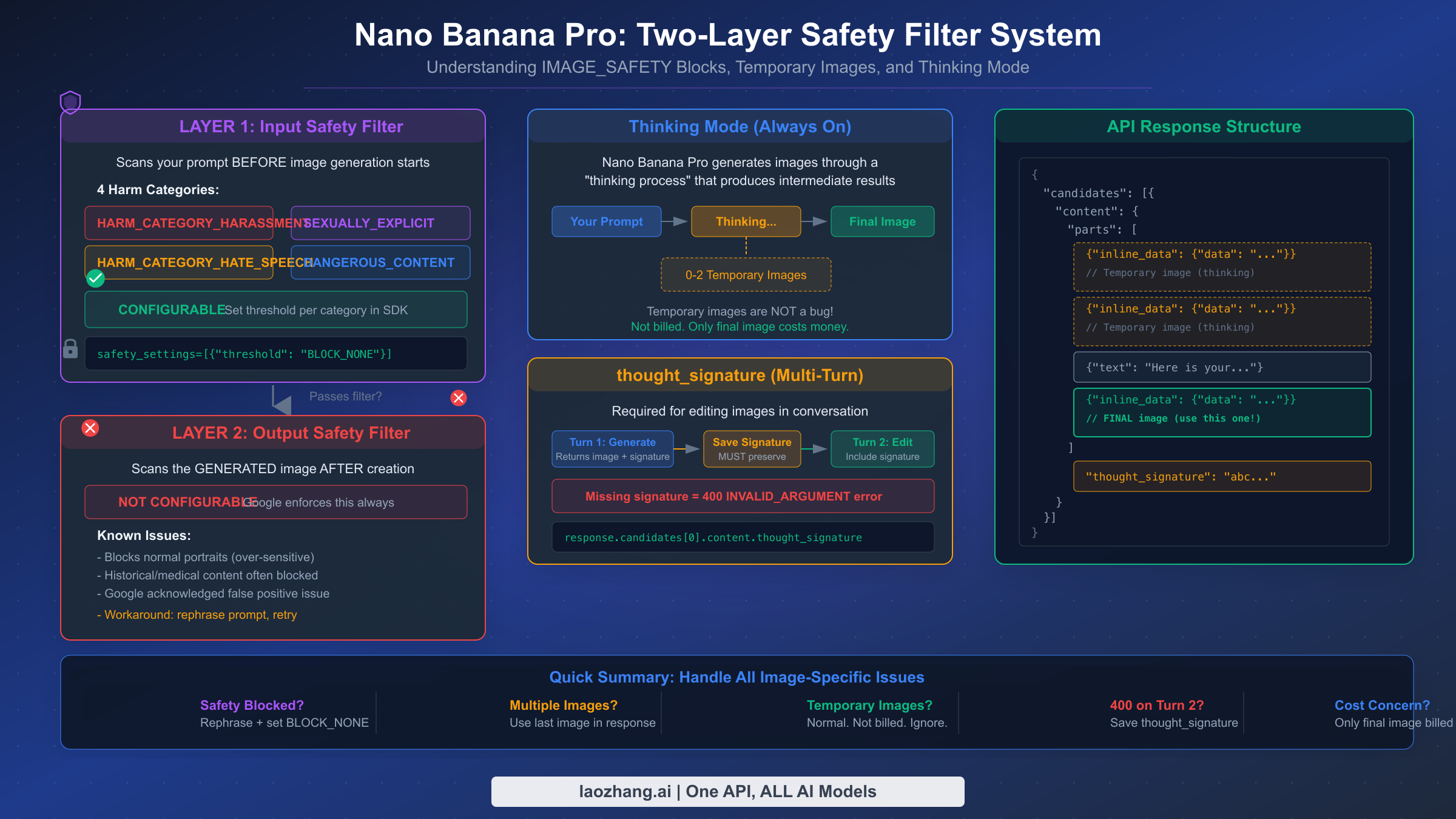
Полный справочник кодов ошибок включает два дополнительных типа, специфичных для генерации изображений, которые не встречаются в стандартных вызовах текстового Gemini API. IMAGE_SAFETY возвращается, когда фильтр безопасности блокирует ваш промпт или сгенерированный результат. PROHIBITED_CONTENT — более строгая блокировка, указывающая, что ваш промпт отмечен за нарушение политики. Оба типа возвращаются как часть массива candidates ответа с полем finishReason, а не как HTTP-коды ошибок, что означает необходимость иной обработки в вашем коде.
Вот реальный ответ IMAGE_SAFETY, с которым многие разработчики сталкиваются при генерации портретов или любого контента, который фильтр считает потенциально чувствительным:
json{ "candidates": [ { "finishReason": "IMAGE_SAFETY", "safetyRatings": [ { "category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "probability": "MEDIUM", "blocked": true } ] } ] }
Важное отличие в том, что IMAGE_SAFETY не возвращает HTTP-статус ошибки — HTTP-ответ по-прежнему имеет код 200 OK. Ваш код должен проверять поле finishReason в каждом кандидате для обнаружения таких блокировок. Если вы проверяете только HTTP-ошибки, блокировки фильтра безопасности тихо пройдут через ваш обработчик ошибок и приведут к пустым или непредвиденным результатам. Надёжный обработчик ошибок проверяет как HTTP-код статуса, так и поле finishReason в каждом ответе, обрабатывая IMAGE_SAFETY и PROHIBITED_CONTENT как отдельные категории ошибок, требующие иной обработки, чем стандартные HTTP-ошибки.
Ошибка 504 DEADLINE_EXCEEDED заслуживает особого внимания, потому что её часто путают с 503. Ошибка 504 означает, что ваш запрос был принят сервером, но обработка заняла слишком много времени — генерация превысила таймаут. Это обычно происходит со сложными промптами, требующими множества итераций обработки, или с запросами на изображения очень высокого разрешения (4K) в периоды умеренной нагрузки. В отличие от 503, где сервер отклоняет ваш запрос немедленно, ошибка 504 означает, что сервер работал над вашим запросом, но не смог завершить его вовремя. Обычно решение — упростить промпт или снизить запрашиваемое разрешение, а затем повторить попытку.
Серверные ошибки (503, 500, 502) — когда инфраструктура Google не справляется
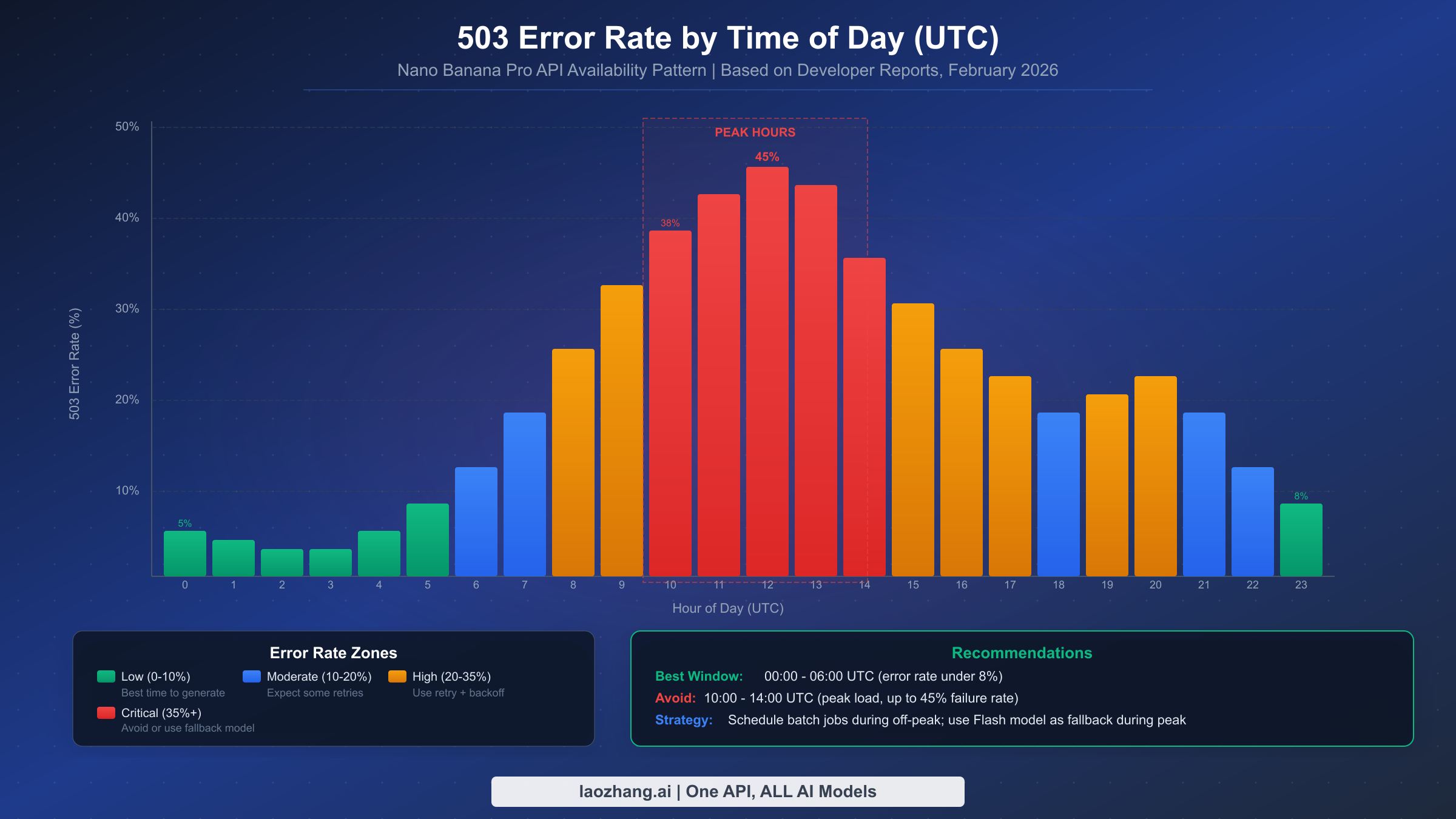
Ошибка 503 UNAVAILABLE — безусловно самая частая ошибка, с которой сталкиваются разработчики при работе с Nano Banana Pro, и она полностью находится вне вашего контроля. Когда инфраструктура Gemini от Google становится перегруженной — а это происходит регулярно в часы пиковой нагрузки — API возвращает ошибки 503 для значительной части запросов. Согласно отчётам из сообщества разработчиков на Google AI Developer Forum (discuss.ai.google.dev), частота ошибок в часы пик (приблизительно с 10:00 до 14:00 UTC) может достигать 45% всех вызовов API, что делает надёжную обработку ошибок не просто приятным дополнением, а абсолютной необходимостью для любого продакшен-приложения.
Ключевое понимание ошибок 503 заключается в том, что они временные по своей природе. Тот же запрос, который сейчас завершился с ошибкой 503, скорее всего, успешно выполнится через 30–60 секунд. Именно поэтому экспоненциальная задержка — правильная стратегия: вы ничего не исправляете, а просто ждёте, пока освободится серверная мощность. Сотрудники Google подтвердили на форуме разработчиков, что ошибки 503 в часы пик — ожидаемое поведение для превью-модели, и что масштабирование инфраструктуры продолжается.
Ошибка 500 INTERNAL встречается реже, но вызывает больше беспокойства, поскольку иногда указывает на проблему с вашим конкретным запросом, а не на общую перегрузку серверов. Если вы получили ошибку 500, сначала попробуйте упростить промпт — чрезмерно длинные или сложные промпты могут вызывать внутренние сбои обработки. Если ошибка сохраняется после упрощения, обрабатывайте её как 503 и повторяйте с задержкой. Ошибка 502 BAD_GATEWAY обычно возникает при использовании прокси-сервисов или API-ретрансляторов и указывает на то, что промежуточный сервер не смог связаться с бэкендом Google. Проверьте конфигурацию URL эндпоинта и настройки прокси перед повторной попыткой.
Тайминг повторных попыток для серверных ошибок следует проверенной схеме. Начните с 30-секундной задержки после первого сбоя, затем удваивайте время ожидания при каждом последующем сбое (30 с → 60 с → 120 с → 240 с). Ограничьте максимальное ожидание 5 минутами и общее число попыток — 5. Добавление случайного отклонения (±20% от времени ожидания) предотвращает проблему «стадного эффекта», когда множество клиентов повторяют запросы одновременно и снова перегружают сервер.
Наиболее эффективная стратегия для избежания ошибок 503 — планировать пакетные задания по генерации изображений на непиковые часы. Окно с 00:00 до 06:00 UTC стабильно показывает частоту ошибок ниже 8%, что делает его идеальным для массовой обработки. Для приложений реального времени, которые не могут контролировать время выполнения, реализация резервного переключения на модель Nano Banana (Flash, gemini-2.5-flash-image) обеспечивает надёжный запасной вариант — модель Flash значительно реже сталкивается с ошибками 503 благодаря более низким вычислительным требованиям, хотя и ценой более низкого качества изображений и максимального разрешения 1024×1024 пикселей (ai.google.dev/pricing, февраль 2026).
Как проверить, что проблема на стороне Google, прежде чем отлаживать свой код: посетите Google Cloud Status Dashboard или проверьте Google AI Developer Forum на наличие текущих инцидентов. Google также публикует информацию на странице статуса Gemini API при подтверждённых масштабных сбоях. Если другие разработчики сообщают о тех же ошибках 503 на форуме одновременно с вами, вы можете быть уверены, что проблема связана с инфраструктурой, а не с вашим кодом. Во время крупных инцидентов сотрудники Google обычно отвечают на форуме в течение 30–60 минут с подтверждением и предполагаемым временем устранения.
Характер ошибок 503 также варьируется по регионам. Разработчики, маршрутизирующие через центры обработки данных в США, обычно наблюдают наибольшую частоту ошибок в рабочие часы Северной Америки (15:00–22:00 UTC), в то время как использующие азиатские дата-центры сообщают о более низкой общей частоте ошибок, но с пиками в азиатские рабочие часы (01:00–09:00 UTC). Если ваше приложение обслуживает глобальную аудиторию, рассмотрите распределение запросов на генерацию изображений по нескольким регионам или использование сервиса-ретранслятора, который автоматически направляет запросы в наименее загруженный регион.
Клиентские ошибки (400, 403, 404) — исправьте свой запрос
Клиентские ошибки — ваша ответственность, и в отличие от серверных ошибок, повторная отправка того же запроса всегда приведёт к тому же сбою. Ошибка 400 INVALID_ARGUMENT имеет множество подпричин, и наиболее важная из них для разработчиков Nano Banana Pro — обработка thought_signature в многоходовых диалогах редактирования изображений. Эта ошибка становится всё более частой по мере того, как всё больше разработчиков создают функции чат-редактирования изображений, однако практически ни одна существующая документация не освещает её должным образом.
Когда вы генерируете изображение в диалоге и затем просите Nano Banana Pro модифицировать его в следующем ходе, API требует включить значение thought_signature из предыдущего ответа. Если вы не сохраните и не отправите обратно это значение, второй и все последующие запросы на генерацию изображений в этом диалоге завершатся ошибкой 400. Подпись находится в response.candidates[0].content.thought_signature и должна быть включена в историю диалога, отправляемую со следующим запросом. Это не опционально — это обязательное требование для многоходовой генерации изображений.
pythonresponse_1 = model.generate_content("Create a landscape painting") # CRITICAL: Save the thought_signature thought_sig = response_1.candidates[0].content.thought_signature # For the next turn, include it in conversation history response_2 = model.generate_content( contents=[ {"role": "user", "parts": [{"text": "Create a landscape painting"}]}, {"role": "model", "parts": response_1.candidates[0].content.parts, "thought_signature": thought_sig}, {"role": "user", "parts": [{"text": "Add a sunset to the painting"}]} ] )
Ошибка 400 FAILED_PRECONDITION — отдельная проблема, которая обычно указывает на то, что ваш проект Google Cloud не соответствует требованиям для Gemini API. Наиболее частая причина — использование проекта бесплатного уровня без включённого биллинга или доступ к API из региона, где бесплатный уровень недоступен. Проверьте, что биллинг включён в вашем проекте Google Cloud и что ваш регион поддерживается для нужного вам тарифного уровня (ai.google.dev/rate-limits, февраль 2026).
Ошибка 403 PERMISSION_DENIED означает, что ваш API-ключ не имеет необходимых разрешений. Есть несколько распространённых причин, которые стоит проверять систематически. Во-первых, убедитесь, что ваш API-ключ был сгенерирован в том же проекте Google Cloud, где включён Generative Language API (или Vertex AI API, если используете Vertex) — ключи из других проектов работать не будут. Во-вторых, убедитесь, что API-ключ не ограничен конкретными API, исключающими Generative Language API. В-третьих, проверьте, нет ли в вашем проекте организационных политик, которые могут блокировать доступ к ИИ-сервисам.
Региональные ограничения — особенно неприятный источник ошибок 403, потому что сообщение об ошибке часто не указывает явно, что проблема географическая. Разработчики в некоторых странах — включая Китай, Иран, Россию и ряд других — не могут обращаться к Gemini API напрямую, даже имея действующий API-ключ и платёжный аккаунт. API просто возвращает 403 PERMISSION_DENIED без объяснения, что блокировка региональная. Если вы подозреваете региональную блокировку, попробуйте обратиться к API из другой сети или проверьте документацию по поддерживаемым регионам Gemini API. Для разработчиков, которым нужен надёжный доступ из ограниченных регионов, сервисы API-ретрансляции, такие как laozhang.ai, обеспечивают доступ независимо от региона, маршрутизируя запросы через поддерживаемые регионы и устраняя необходимость настройки VPN при сохранении того же интерфейса API.
Ошибка 404 NOT_FOUND менее распространена, но возникает, когда ваш запрос ссылается на медиафайлы (например, загруженные для редактирования изображения), которых больше нет на серверах Google. Загруженные медиафайлы имеют срок действия, и если вы ссылаетесь на URI файла с истёкшим сроком, вы получите ошибку 404. Решение — повторно загрузить медиафайл перед обращением к нему в запросе и кешировать URI загруженных файлов вместе с их временными метками истечения в вашем приложении.
Лимиты запросов и 429 RESOURCE_EXHAUSTED — управление квотой
Ошибка 429 RESOURCE_EXHAUSTED означает, что вы превысили один из нескольких типов лимитов запросов. В отличие от ошибок 503, где проблема — в мощности сервера, ошибки 429 связаны с конкретной квотой вашего проекта. Понимание различных типов лимитов необходимо, поскольку каждый из них сбрасывается по своему расписанию и требует своей стратегии смягчения.
Лимиты Nano Banana Pro применяются к каждому проекту Google Cloud (а не к каждому API-ключу) и измеряются по четырём параметрам: RPM (запросов в минуту), TPM (токенов в минуту для входных данных), RPD (запросов в день) и IPM (изображений в минуту). Лимит IPM специфичен для моделей генерации изображений и часто оказывается неожиданным для разработчиков, потому что даже при наличии запаса по RPM вы могли исчерпать квоту на изображения (ai.google.dev/rate-limits, февраль 2026).
Точные числовые лимиты зависят от уровня и не публикуются как фиксированные значения — Google корректирует их в зависимости от нагрузки системы и версии модели. Вы можете просмотреть свои текущие лимиты в Google AI Studio в настройках проекта. Однако структура уровней, определяющая ваш общий объём выделения, хорошо задокументирована:
| Уровень | Требования | Объём лимитов | Стоимость |
|---|---|---|---|
| Бесплатный | Поддерживаемые страны, без биллинга | Самый ограниченный | $0 |
| Уровень 1 | Подключён платёжный аккаунт | Умеренный | По факту использования |
| Уровень 2 | Общие расходы > $250 + 30 дней | Повышенный | По факту использования |
| Уровень 3 | Общие расходы > $1 000 + 30 дней | Максимальный | По факту использования |
(Источник: ai.google.dev/rate-limits, февраль 2026)
Дневные лимиты (RPD) сбрасываются в полночь по тихоокеанскому времени — важная деталь, которую многие разработчики упускают. Если вы достигли дневного лимита в 15:00 по тихоокеанскому времени, придётся ждать до полуночи, а не 24 часа с момента достижения лимита. Минутные лимиты (RPM) сбрасываются каждые 60 секунд с момента первого запроса в этом окне. Планирование распределения запросов с учётом этих границ сброса может значительно повысить вашу эффективную пропускную способность.
Распространённый источник путаницы — разница между ошибками лимита запросов и исчерпания квоты. Ошибка лимита запросов (429 с retryDelay) означает, что вы отправляете запросы слишком быстро в пределах выделенного окна — замедление решит проблему. Ошибка исчерпания квоты (429 без информации о повторной попытке) означает, что вы достигли абсолютного дневного или месячного лимита — никакое ожидание в текущем периоде не поможет. При исчерпании дневной квоты ваши единственные варианты — дождаться сброса в полночь по тихоокеанскому времени или повысить уровень. При проблемах с месячной квотой обратитесь в поддержку Google Cloud для обсуждения увеличения выделения.
Превью-модели, такие как Nano Banana Pro (gemini-3-pro-image-preview), имеют более строгие лимиты, чем стабильные модели (ai.google.dev/rate-limits, февраль 2026). Это означает, что лимиты, которые вы видите в AI Studio для превью-модели, намеренно ниже тех, что были бы у стабильного релиза. Google корректирует эти лимиты по мере приближения модели к общей доступности, поэтому конкретные цифры сегодня могут увеличиться со временем. Регулярная проверка AI Studio на предмет обновлённых лимитов имеет смысл, особенно после объявлений Google об обновлениях моделей или изменениях версий.
Практические стратегии оптимизации квоты могут значительно сократить ошибки 429 без повышения уровня. Наиболее эффективный метод — группировка запросов: вместо индивидуальных вызовов API для каждого изображения группируйте промпты и равномерно распределяйте их по вашему лимиту RPM. Если ваш лимит RPM — 10, планируйте один запрос каждые 6 секунд вместо отправки 10 запросов одновременно с последующим 60-секундным ожиданием. Это сглаживает кривую использования и предотвращает всплески, вызывающие ограничение. Другая мощная стратегия — реализация клиентского token bucket, повторяющего поведение лимитирования Google — это позволяет предсказывать и предотвращать ошибки 429 до их появления, а не реагировать на них постфактум.
Для разработчиков, которые конкретно упираются в лимиты IPM (изображений в минуту), стоит подумать, действительно ли все вызовы генерации изображений требуют модели Pro. Многие задачи — миниатюры, превью, черновики низкого разрешения — прекрасно решаются с помощью Nano Banana (Flash), у которой отдельные и обычно более щедрые лимиты. Разделение нагрузки между моделями в зависимости от требований к качеству может фактически удвоить вашу общую мощность генерации изображений без изменения уровня.
Для подробного разбора стратегий работы с лимитами и оптимизации использования квоты по различным уровням см. наше подробное руководство по устранению ошибок 429 resource exhausted. Вы также можете ознакомиться с полным руководством по лимитам запросов, где описаны конкретные техники оптимизации, и сравнением возможностей бесплатного и платного уровней, чтобы определить, стоит ли повышать уровень для вашего варианта использования.
Проблемы генерации изображений — фильтры безопасности, временные изображения и режим мышления
Генерация изображений с помощью Nano Banana Pro создаёт набор ошибочных условий, которых не существует в стандартной текстовой генерации. Эти проблемы — блокировки фильтром безопасности, временные изображения в ответах и поведение режима мышления — наиболее часто неправильно понимаемые аспекты API. Разработчики часто считают их багами, тогда как на самом деле это намеренные проектные решения Google, и понимание предусмотренного поведения — ключ к их правильной обработке.
Фильтр IMAGE_SAFETY работает на двух уровнях, и это различие важно, потому что только первый уровень настраивается. Входной фильтр безопасности сканирует ваш промпт до начала генерации, проверяя по четырём категориям вреда: HARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT и HARM_CATEGORY_DANGEROUS_CONTENT. Вы можете установить порог для каждой категории: BLOCK_NONE, BLOCK_LOW_AND_ABOVE, BLOCK_MEDIUM_AND_ABOVE или BLOCK_ONLY_HIGH. Установка всех четырёх на BLOCK_NONE даёт наиболее мягкую входную фильтрацию:
pythonfrom google.generativeai.types import HarmCategory, HarmBlockThreshold safety_settings = { HarmCategory.HARM_CATEGORY_HARASSMENT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_HATE_SPEECH: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: HarmBlockThreshold.BLOCK_NONE, HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: HarmBlockThreshold.BLOCK_NONE, } response = model.generate_content( "A portrait photograph of a person smiling", safety_settings=safety_settings )
Однако выходной фильтр безопасности — который сканирует сгенерированное изображение после создания — не настраивается. Google применяет этот уровень постоянно, и он известен ложными срабатываниями, особенно с портретными фотографиями и историческими изображениями. Google признал эту чрезмерную чувствительность на форуме разработчиков. Единственный обходной путь для блокировок выходного фильтра — перефразировать промпт, чтобы получить немного другое изображение, не вызывающее срабатывание фильтра, или повторить тот же промпт, поскольку стохастическая природа модели может дать прошедшее фильтр изображение при последующих попытках.
Временные изображения в ответе API — не баг, а ожидаемая часть процесса мышления Nano Banana Pro. Когда модель генерирует изображение, она может создать до двух промежуточных «мысленных» изображений перед получением финального результата. Эти временные изображения появляются как дополнительные части inline_data в массиве parts ответа, предшествуя финальному изображению. Критически важная деталь, которую большинство разработчиков упускает: временные изображения не тарифицируются — оплачивается только финальное изображение в ответе ($0,134 за изображение при разрешении 1K–2K, $0,24 за изображение при разрешении 4K, согласно ai.google.dev/pricing, февраль 2026). Для полного объяснения, почему временные изображения появляются и как обрабатывать их в коде, см. наше полное объяснение поведения временных изображений.
Чтобы извлечь финальное изображение из ответа, содержащего временные изображения, всегда используйте последнюю часть изображения в ответе, а не первую. Вот надёжный паттерн кода, который работает независимо от количества временных изображений в процессе мышления:
pythondef extract_final_image(response): """Always returns the final (last) image, skipping temporary images.""" parts = response.candidates[0].content.parts images = [p for p in parts if hasattr(p, 'inline_data') and p.inline_data] if not images: raise ValueError("No images in response — check finishReason") # The last image is always the final result final_image = images[-1] return base64.b64decode(final_image.inline_data.data)
Режим мышления в Nano Banana Pro включён по умолчанию и не может быть отключён — он является фундаментальным для того, как модель достигает более высокого качества генерации изображений по сравнению со стандартной моделью Nano Banana (Flash). Именно этот процесс мышления повысил успешность выполнения сложных промптов с примерно 60–70% до 85–90%, согласно тестированию сообщества разработчиков. Компромисс в том, что ответы занимают больше времени (обычно 10–30 секунд против 3–8 секунд для Flash), а размер полезной нагрузки ответа больше из-за включённых временных изображений, что может влиять на приложения со строгими требованиями к задержке или пропускной способности.
Распространённая ошибка разработчиков — подсчёт временных изображений как отдельных тарифицируемых результатов. Ответ, содержащий два временных изображения и одно финальное, не стоит в 3 раза дороже — стоимость такая же, как за одну генерацию изображения. Временные изображения включены в ответ для прозрачности процесса мышления, и некоторые продвинутые приложения используют их, чтобы показать пользователям творческую прогрессию модели, но они не несут дополнительных затрат. Стоимость остаётся $0,134 за финальное изображение при разрешении 1K–2K или $0,24 при разрешении 4K (ai.google.dev/pricing, февраль 2026).
Создание устойчивого конвейера генерации изображений
Наиболее эффективный способ обработки ошибок Nano Banana Pro в продакшене — классифицировать каждую возможную ошибку в одну из трёх категорий: повторяемые, исправимые и критические — и строить обработчик ошибок на основе этой классификации. Повторяемые ошибки (503, 500, 502 и 429 после ожидания) должны вызывать автоматический повтор с экспоненциальной задержкой. Исправимые ошибки (400, 403) должны логироваться для расследования. Критические ошибки (PROHIBITED_CONTENT) должны немедленно сообщаться пользователю.
Вот полная реализация на Python устойчивой обёртки для генерации изображений, которая обрабатывает все типы ошибок, реализует экспоненциальную задержку со случайным отклонением и включает резервное переключение с Nano Banana Pro на Nano Banana (Flash), когда основная модель стабильно недоступна:
pythonimport google.generativeai as genai import time import random import base64 class ResilientImageGenerator: def __init__(self, api_key): genai.configure(api_key=api_key) self.primary_model = genai.GenerativeModel("gemini-3-pro-image-preview") self.fallback_model = genai.GenerativeModel("gemini-2.5-flash-image") def generate_image(self, prompt, max_retries=5, use_fallback=True): """Generate image with automatic retry and model fallback.""" last_error = None # Try primary model with retries for attempt in range(max_retries): try: response = self.primary_model.generate_content(prompt) return self._extract_final_image(response) except Exception as e: last_error = e error_code = getattr(e, 'code', None) or self._parse_error_code(e) if error_code in (503, 500, 502): # Retryable: wait with exponential backoff + jitter wait = min(30 * (2 ** attempt), 300) jitter = wait * random.uniform(-0.2, 0.2) time.sleep(wait + jitter) elif error_code == 429: # Rate limited: honor retry delay if provided retry_delay = self._get_retry_delay(e) or 60 time.sleep(retry_delay) elif error_code in (400, 403, 404): # Not retryable: raise immediately raise else: raise # Fallback to Flash model if primary exhausted retries if use_fallback: try: response = self.fallback_model.generate_content(prompt) return self._extract_final_image(response) except Exception: pass raise last_error def _extract_final_image(self, response): """Extract the LAST image from response (skip temporary images).""" if not response.candidates: raise ValueError("No candidates in response") parts = response.candidates[0].content.parts # Find the last image part (final image, not temporary) for part in reversed(parts): if hasattr(part, 'inline_data') and part.inline_data: return base64.b64decode(part.inline_data.data) raise ValueError("No image found in response") def _parse_error_code(self, error): error_str = str(error) for code in [503, 500, 502, 429, 400, 403, 404]: if str(code) in error_str: return code return None def _get_retry_delay(self, error): # Parse retryDelay from error details if available try: error_str = str(error) if 'retryDelay' in error_str: import re match = re.search(r'"retryDelay":\s*"(\d+)s"', error_str) if match: return int(match.group(1)) except Exception: pass return None
Эквивалентная реализация на JavaScript/Node.js следует тому же паттерну, но использует async/await для цикла повторных попыток:
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); class ResilientImageGenerator { constructor(apiKey) { const genAI = new GoogleGenerativeAI(apiKey); this.primaryModel = genAI.getGenerativeModel({ model: "gemini-3-pro-image-preview" }); this.fallbackModel = genAI.getGenerativeModel({ model: "gemini-2.5-flash-image" }); } async generateImage(prompt, maxRetries = 5) { let lastError; for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await this.primaryModel.generateContent(prompt); return this.extractFinalImage(result.response); } catch (error) { lastError = error; const code = error.status || this.parseErrorCode(error); if ([503, 500, 502].includes(code)) { const wait = Math.min(30000 * Math.pow(2, attempt), 300000); const jitter = wait * (Math.random() * 0.4 - 0.2); await this.sleep(wait + jitter); } else if (code === 429) { await this.sleep(60000); } else { throw error; // 400, 403, 404: don't retry } } } // Fallback to Flash model try { const result = await this.fallbackModel.generateContent(prompt); return this.extractFinalImage(result.response); } catch (e) { throw lastError; } } extractFinalImage(response) { const parts = response.candidates[0].content.parts; for (let i = parts.length - 1; i >= 0; i--) { if (parts[i].inlineData) { return Buffer.from(parts[i].inlineData.data, "base64"); } } throw new Error("No image in response"); } parseErrorCode(error) { const match = String(error).match(/(\d{3})/); return match ? parseInt(match[1]) : null; } sleep(ms) { return new Promise(r => setTimeout(r, ms)); } }
Для продакшен-развёртываний обе реализации следует дополнить мониторингом и оповещениями. Отслеживайте три ключевые метрики: частоту ошибок по типу (для обнаружения скачков частоты 503 выше нормы), среднее количество повторных попыток на успешный запрос (для обнаружения деградации производительности) и частоту использования резервной модели (для обнаружения ситуации, когда основная модель становится стабильно недоступной). Настройка оповещений при превышении частоты ошибок 503 отметки 30% на протяжении более 5 минут позволяет вашей команде проактивно переключиться в режим деградации (генерация только на Flash) до того, как пользователи столкнутся с массовыми сбоями.
Категоризация ошибок для мониторинга должна следовать этой классификации:
| Категория | Коды ошибок | Действие | Уровень оповещения |
|---|---|---|---|
| Повторяемые | 503, 500, 502 | Автоповтор с задержкой | Предупреждение при >30% |
| Лимит запросов | 429 | Очередь + задержка | Информация |
| Исправление клиента | 400, 403, 404 | Лог + уведомление разработчика | Ошибка |
| Блокировка безопасности | IMAGE_SAFETY | Перефразировать или пропустить | Информация |
| Блокировка политики | PROHIBITED_CONTENT | Пропустить + лог | Предупреждение |
При построении многомодельных цепочек резервного переключения API-ретрансляторы, такие как laozhang.ai, могут упростить архитектуру, предоставляя единый эндпоинт для маршрутизации к нескольким моделям — см. их документацию по настройке мультимодельного API. Такой подход устраняет необходимость управлять отдельными API-ключами и клиентскими конфигурациями для каждой модели в цепочке резервного переключения.
Часто задаваемые вопросы
Тарифицируются ли неудачные запросы?
Нет. Неудачные запросы API, возвращающие коды ошибок (503, 429, 400, 403 и т.д.), не тарифицируются. Вы платите только за успешные ответы с сгенерированным контентом. Это включает временные изображения в процессе мышления — они являются частью успешного ответа, но не тарифицируются отдельно. Только финальное изображение в ответе учитывается в вашем потреблении и биллинге.
Достаточно ли Nano Banana Pro надёжен для продакшена?
Nano Banana Pro (gemini-3-pro-image-preview) по-прежнему является превью-моделью, что означает, что Google не гарантирует SLA продакшен-уровня. В непиковые часы надёжность в целом хорошая (>90% успешных запросов), но в пиковые часы частота сбоев может достигать 45%. Для продакшен-использования реализация паттерна повтор + резервное переключение, описанного в этом руководстве, является обязательной. Если вам нужна максимальная надёжность, рассмотрите использование Nano Banana (Flash, gemini-2.5-flash-image) в качестве основной модели — качество ниже, но доступность значительно выше. Для подробного сравнения цен и производительности см. наш анализ стоимости и производительности Gemini 3 Pro Image API.
Что лучше — Vertex AI или Gemini API?
Оба предоставляют доступ к тем же базовым моделям. Gemini API (через Google AI Studio) проще в настройке и имеет бесплатный уровень. Vertex AI предоставляет корпоративные функции: VPC-сети, пользовательские эндпоинты и повышенные лимиты запросов, но требует проект Google Cloud с биллингом. Коды ошибок одинаковы в обоих API, хотя Vertex AI нативно использует gRPC, а Gemini API оборачивает ошибки в REST JSON-ответы.
Как обратиться в поддержку Google по поводу постоянных ошибок?
Для пользователей бесплатного уровня основной канал поддержки — Google AI Developer Forum по адресу discuss.ai.google.dev. Сотрудники Google регулярно отслеживают и отвечают на сообщения об ошибках API. Для пользователей уровня 1 и выше с включённым биллингом можно подать заявку в поддержку через Google Cloud Console. При подаче отчётов указывайте ID проекта, конкретный код ошибки и полный JSON ответа, а также временную метку ошибки.
В какое время лучше всего генерировать изображения?
Согласно данным сообщества о паттернах ошибок, наименьшая частота ошибок наблюдается в период 00:00–06:00 UTC (поздний вечер и раннее утро в обеих Америках, дневное время в Азиатско-Тихоокеанском регионе). Наихудшее окно — 10:00–14:00 UTC (утро и раннее время суток в обеих Америках, когда активность разработчиков из США достигает пика). Если ваше приложение позволяет планирование, группируйте задания на генерацию изображений в непиковое окно. О бюджетных альтернативах с другими паттернами доступности см. наше руководство по экономичным альтернативам для генерации изображений Gemini.
Как проверить текущее использование лимита запросов?
Вы можете просмотреть текущее использование и оставшуюся квоту в Google AI Studio в настройках проекта. Сам API не возвращает информацию об оставшейся квоте в заголовках ответа (в отличие от некоторых других API), поэтому вам нужно отслеживать использование на стороне клиента или проверять панель мониторинга AI Studio. Для программного мониторинга квоты можно использовать Google Cloud Monitoring API с ID вашего проекта для настройки оповещений при приближении использования к лимитам.
Почему я получаю разные ошибки для одного и того же промпта?
Стохастическая природа модели означает, что один и тот же промпт может давать разные результаты при каждом вызове, включая различные исходы ошибок. Промпт, который вызывает IMAGE_SAFETY при одной попытке, может успешно выполниться при следующей, потому что сгенерированное изображение каждый раз немного отличается и может пересечь или не пересечь порог фильтра безопасности. Для ошибок 503 вариативность обусловлена колеблющейся нагрузкой на сервер — тот же запрос, который завершился неудачей в момент пика, может успешно выполниться через несколько секунд, когда мощность освободится. Именно поэтому логика повторных попыток так важна: она учитывает неотъемлемую изменчивость как поведения модели, так и доступности сервера.
В чём разница между Nano Banana Pro и Nano Banana (Flash)?
Nano Banana Pro (gemini-3-pro-image-preview) приоритезирует качество изображений и поддерживает разрешение до 4K, со стоимостью $0,134–$0,24 за изображение. Он использует процесс мышления, который обеспечивает более качественные результаты, но занимает больше времени (10–30 секунд) и может генерировать временные промежуточные изображения. Nano Banana (gemini-2.5-flash-image) приоритезирует скорость и экономичность по $0,039 за изображение, с максимальным разрешением 1024×1024 и типичным временем ответа 3–8 секунд. Модель Flash обычно имеет более высокую доступность и менее частые ошибки 503, поскольку её вычислительные требования ниже. Для продакшен-систем, которым нужны и качество, и надёжность, рекомендуемый подход — использовать Pro как основную модель с Flash в качестве автоматического резервного варианта при постоянных ошибках Pro.