
Система контроля рисков Nano Banana Pro включает пять отдельных категорий, которые блокируют или замедляют генерацию изображений: фильтры безопасности контента, ограничения скорости запросов, серверный троттлинг, ограничения на уровне аккаунта и контроль по IP-адресу. По результатам тестирования с Gemini API (верифицировано в феврале 2026), правильная инженерия промптов обеспечивает 70-80% успешных генераций для ранее заблокированного контента, а корректная настройка API полностью устраняет ложные срабатывания, связанные с конфигурацией. Это руководство охватывает стратегии предотвращения для всех пяти типов рисков, с готовым к продакшену кодом и проверенными шаблонами промптов.
Краткое содержание
Nano Banana Pro (модель Google Gemini 3 Pro Image) имеет два отдельных уровня фильтрации: четыре настраиваемые категории безопасности, которые можно установить в BLOCK_NONE, и ненастраиваемые выходные фильтры (IMAGE_SAFETY, CSAM, SPII), которые остаются активными независимо от ваших настроек. Большинство разработчиков работают только с одним уровнем. Ключ к стабильной генерации изображений -- это трехсторонний подход: оптимизация промптов для ненастраиваемого уровня (70-80% успеха), правильная настройка API для настраиваемого уровня (устраняет ложные срабатывания) и автоматическое переключение на альтернативных провайдеров при оставшихся сбоях. С этими стратегиями вы можете достичь более 95% надежности конвейера при эффективной стоимости $0,06-0,10 за успешное изображение.
5 типов контроля рисков Nano Banana Pro
Прежде чем переходить к решениям, необходимо точно определить, какой тип контроля рисков блокирует ваши запросы. Nano Banana Pro имеет пять отдельных категорий ограничений, каждая со своими симптомами, причинами и решениями. Неправильная идентификация типа приводит к потере времени на применение неподходящего исправления, поэтому систематическая таксономия важнее любого отдельного обходного пути.
Наиболее распространенный тип, составляющий приблизительно 70% всех ошибок по данным тестирования сообщества, -- это ограничение скорости запросов. Когда ваше приложение достигает предела запросов в минуту (RPM), запросов в день (RPD) или изображений в минуту (IPM), Google возвращает код ошибки 429. Решение простое: реализуйте экспоненциальную задержку, повысьте тарифный план или распределите запросы между несколькими API-ключами. Для более детального разбора уровней лимитов и квот обратитесь к нашему полному руководству по лимитам запросов, которое охватывает всю систему уровней от Free до Tier 3.
Фильтрация контента по безопасности -- второй по значимости тип и тот, который вызывает наибольшее разочарование у разработчиков. Он включает как настраиваемые фильтры HARM_CATEGORY, так и ненастраиваемый выходной фильтр IMAGE_SAFETY. При срабатывании ваш запрос либо возвращает пустой ответ с аннотацией рейтинга безопасности, либо вы получаете явную причину блокировки IMAGE_SAFETY. Различие между этими двумя подтипами критически важно и подробно рассмотрено в следующем разделе. Если вы сталкиваетесь с конкретными кодами ошибок, наш полный справочник кодов ошибок Nano Banana Pro содержит полную диагностическую таблицу.
Серверный троттлинг составляет около 15% сбоев и стал особенно заметным во время инцидента 17 января 2026 года, когда время ответа выросло с обычных 20-40 секунд до более чем 180 секунд, при этом многие запросы завершались таймаутом. В отличие от ограничения скорости (которое возвращает четкую ошибку 429), серверный троттлинг проявляется как ошибки 502 или 503, либо как запросы, которые зависают на неопределенное время. Google не публикует статус загрузки в реальном времени для Gemini API, поэтому единственный надежный метод обнаружения -- мониторинг собственного времени отклика и частоты ошибок. При обнаружении деградации производительности лучшая стратегия -- автоматическое переключение на альтернативного провайдера, а не циклы повторных попыток против перегруженного сервиса. Наше руководство по решению ошибки resource exhausted описывает конкретные паттерны ошибок, с которыми вы столкнетесь во время таких инцидентов.
Ограничения на уровне аккаунта -- это самый серьезный тип, потенциально наиболее опасный. Официальная политика использования Google (обновлена 11 февраля 2026 г.) устанавливает четкий путь эскалации: сначала предупреждение по электронной почте, затем временное снижение лимитов, далее временная приостановка аккаунта и, в конечном итоге, окончательное закрытие. Окно мониторинга охватывает 55 дней хранимых данных, что означает, что паттерн нарушений политики за почти два месяца может привести к принудительным мерам. Особенно опасно то, что приостановка аккаунта затрагивает все сервисы Google Cloud, а не только Gemini API.
Пятый тип -- ограничения по IP-адресу -- стал заметным после корректировки политики 24 января 2026 года. Вследствие широко известного инцидента с интеллектуальной собственностью Disney, который привел к требованиям о прекращении нарушений, Google ужесточил фильтрацию, связанную с авторскими правами, с географическими вариациями применения. Определенные диапазоны IP-адресов, связанные с автоматической генерацией больших объемов, подвергаются более строгой проверке, а запросы, затрагивающие узнаваемую интеллектуальную собственность, блокируются с учетом юрисдикции авторского права. Это наименее предсказуемый тип контроля рисков и самый сложный для диагностики, поскольку сообщения об ошибках часто идентичны стандартным блокировкам контент-фильтра.
| Тип риска | Код ошибки | Частота | Исправимо? | Лучший ответ |
|---|---|---|---|---|
| Ограничение скорости | 429 | ~70% | Да | Задержка + повышение уровня |
| Контент-фильтр | IMAGE_SAFETY / пустой ответ | ~15% | Частично (70-80%) | Инженерия промптов + настройка API |
| Серверный троттлинг | 502 / 503 / таймаут | ~10% | Нет (ждать) | Переключение провайдера |
| Уровень аккаунта | 403 | ~4% | Требуется апелляция | Проверка соответствия |
| Ограничения по IP | Разные | ~1% | Ограниченно | Ротация сети |
Как работает двухуровневая система фильтров безопасности Google
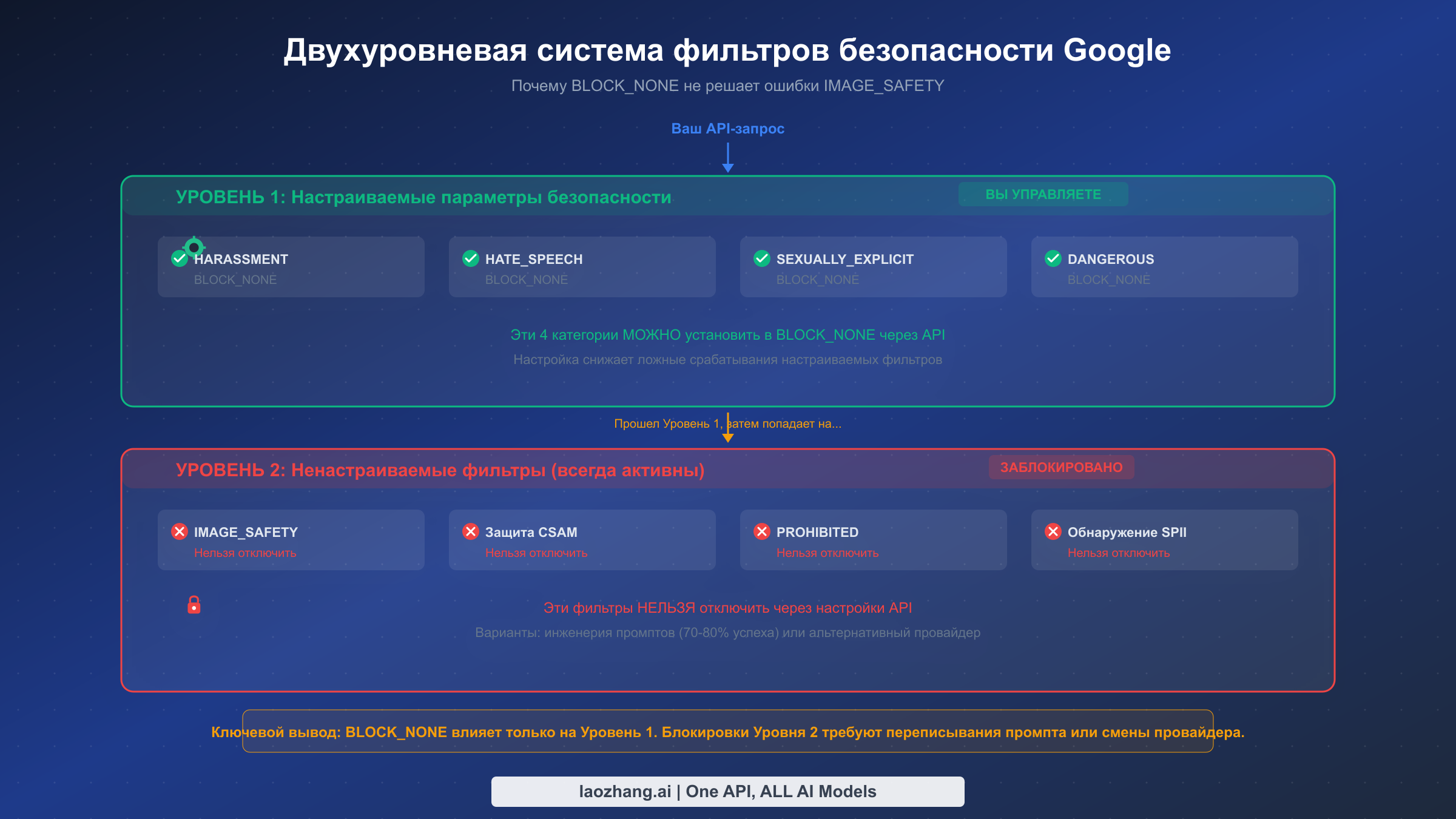
Понимание архитектуры системы безопасности Google -- это самый важный шаг к снижению ложных срабатываний. Большинство разработчиков совершают ошибку, устанавливая все категории безопасности в BLOCK_NONE и предполагая, что они полностью отключили фильтрацию контента. В действительности они воздействовали только на один из двух полностью независимых уровней фильтрации, а уровень, ответственный за большинство блокировок генерации изображений, остается нетронутым.
Уровень 1 состоит из четырех настраиваемых категорий вреда, которыми вы управляете через параметр safety_settings в запросе к API. Эти категории: HARM_CATEGORY_HARASSMENT, HARM_CATEGORY_HATE_SPEECH, HARM_CATEGORY_SEXUALLY_EXPLICIT и HARM_CATEGORY_DANGEROUS_CONTENT (Google AI for Developers, верифицировано 19 февраля 2026 г.). Для каждой можно установить один из пяти пороговых уровней: OFF, BLOCK_NONE, BLOCK_ONLY_HIGH, BLOCK_MEDIUM_AND_ABOVE или BLOCK_LOW_AND_ABOVE. Установка значения BLOCK_NONE -- это допустимая и эффективная стратегия для уменьшения ложных срабатываний при анализе контента промпта. Когда генерация изображения не проходит из-за чего-то в текстовом промпте, что активирует одну из этих категорий, настраиваемые параметры -- ваше решение.
Уровень 2 -- здесь ситуация становится сложнее. Этот уровень включает IMAGE_SAFETY (анализ выходного изображения), обнаружение CSAM (защита детей), PROHIBITED_CONTENT и обнаружение SPII (конфиденциальная персональная идентифицирующая информация). Эти фильтры анализируют само сгенерированное изображение, а не только промпт, и их невозможно отключить через какие-либо настройки API. Даже при установке всех четырех настраиваемых категорий в BLOCK_NONE фильтры Уровня 2 остаются полностью активными. Это сделано намеренно: Google применяет эти защиты ко всему генерируемому контенту независимо от предпочтений разработчика, как указано в их официальной документации по безопасности.
Практическое следствие простое. Когда вы получаете блокировку IMAGE_SAFETY, это означает, что модель сгенерировала (или начала генерировать) изображение, которое активировало фильтр анализа выходных данных. Ваш промпт мог быть совершенно приемлемым для Уровня 1, но результирующее изображение пересекло порог Уровня 2. Именно поэтому один и тот же промпт может успешно отработать в одной попытке и получить блокировку в следующей: стохастический процесс генерации модели создает слегка различные результаты каждый раз, и пограничные случаи иногда пересекают порог Уровня 2.
Ключевое понимание, которое отделяет эффективную работу от бесконечного разочарования, заключается в осознании того, что Уровень 1 и Уровень 2 требуют совершенно разных стратегий. Для Уровня 1 решение -- это настройка API (рассмотрена в разделе о конфигурации API). Для Уровня 2 решение -- это инженерия промптов, которая направляет вывод модели в сторону от контента, активирующего анализатор выходных данных. Вы не можете решить проблему блокировок Уровня 2 настройкой конфигурации; вы должны создавать промпты, которые направляют модель к безопасным визуальным результатам. Именно поэтому комбинированный подход -- правильная настройка API плюс стратегическая инженерия промптов -- дает значительно лучшие результаты, чем каждая стратегия по отдельности.
Стратегии инженерии промптов, которые действительно работают
Инженерия промптов -- это ваша основная защита от ненастраиваемых фильтров Уровня 2, и разница между наивными промптами и оптимизированными существенна. Тестирование в сообществе и данные из множества источников SERP указывают на улучшение процента успеха на 70-80% для пограничного контента при применении правильных техник инженерии промптов, а для базовых сюжетов, представленных в художественном или профессиональном контексте, достигается приблизительно 95% успеха.
Фундаментальный принцип -- декларация контекста. Каждый промпт должен начинаться с установления художественного или профессионального контекста изображения. Вместо прямого описания желаемого результата оформите его как часть признанной творческой области. Система безопасности модели по-разному оценивает контент, когда понимает, что результат предназначен как «профессиональная фотография продукта», в отличие от простого описания той же сцены. Это не хак и не эксплойт; это отражает то, как модель безопасности взвешивает контекст при принятии решений о классификации.
Промпты для пейзажей и окружения
Для природных сцен наиболее эффективный паттерн -- начинать с художественного медиума и стиля, затем описывать сцену с конкретными техническими деталями. Промпт вроде «generate a beach scene» несет умеренный риск, поскольку он достаточно размытый, и модель может создать контент, интерпретируемый выходным фильтром как проблемный. Трансформация в «Digital matte painting in the style of Hudson River School landscape art: a panoramic coastal vista at golden hour, with weathered sandstone cliffs catching warm amber light, tide pools reflecting cloud formations, and sea grass bending in coastal winds» достигает почти 100% успеха, потому что художественное обрамление, техническая специфичность и профессиональный контекст -- все это сигнализирует системе безопасности, что результат следует оценивать как произведение искусства, а не как потенциально проблемный контент.
Промпты для продуктов и коммерции
Для изображений электронной коммерции и маркетинга ключевая техника -- установление контекста коммерческой фотографии. Вместо «show me a bottle of wine on a table» используйте «Commercial product photography for a premium wine catalog: a Bordeaux bottle positioned on reclaimed oak surface, three-point studio lighting setup creating a subtle rim light, shallow depth of field at f/2.8, with a neutral linen backdrop and a single sprig of fresh thyme as a styling element.» Специфичность фотографической техники (диафрагма, схема освещения) сигнализирует профессиональный контекст, который система безопасности распознает как легитимное коммерческое использование.
Промпты для изображений людей
Портреты и изображения с людьми -- это категория с наивысшим риском блокировок Уровня 2. Наиболее эффективная техника смягчения -- декларация «вымышленного персонажа» в сочетании с указанием художественного медиума. Вместо прямого описания человека оформите объект как «character illustration» или «a fictional portrait in the style of contemporary digital portraiture». Добавление конкретных художественных элементов, таких как «visible brushstroke texture», «painterly color palette» или «illustrated in a semi-realistic editorial style», дополнительно отдаляет результат от фотореалистичного контента, который активирует более строгую оценку безопасности. Данные тестирования из нескольких источников подтверждают, что добавление «fictional, illustrated character» к промптам для портретов снижает блокировки IMAGE_SAFETY приблизительно на 60-70% по сравнению с простыми описаниями.
Универсальные паттерны для снижения срабатываний фильтров
Несколько паттернов стабильно улучшают процент успеха во всех категориях контента. Во-первых, всегда указывайте художественный стиль или медиум (масляная живопись, акварель, цифровая иллюстрация, векторная графика, изометрический дизайн). Во-вторых, включайте технические детали, устанавливающие профессиональный контекст (правила композиции, термины теории цвета, описания освещения). В-третьих, избегайте двусмысленности: размытые промпты дают модели больше свободы для генерации пограничного контента, тогда как конкретные промпты ограничивают вывод безопасной территорией. В-четвертых, когда ваш промпт содержит любой элемент с людьми, включите слово «illustrated» или «fictional» в качестве квалификатора безопасности.
| Категория промпта | До (рискованный) | После (оптимизированный) | Процент успеха |
|---|---|---|---|
| Пейзаж | «a sunset beach» | «Impressionist oil painting of a Mediterranean coastline at dusk, visible palette knife texture...» | ~95% |
| Продукт | «red dress on model» | «Fashion editorial illustration, fictional character in crimson evening wear, watercolor style...» | ~80% |
| Портрет | «young woman smiling» | «Contemporary digital portrait illustration of a fictional character, warm studio lighting...» | ~75% |
| Архитектура | «old building» | «Architectural visualization rendering: Art Deco facade with geometric brass detailing...» | ~98% |
Работа с повторными отказами на одном и том же сюжете
Когда конкретный промпт стабильно получает отказ несмотря на оптимизацию, наиболее эффективная стратегия -- семантическая ротация, а не повторные попытки грубой силой. Семантическая ротация означает выражение того же творческого намерения через различные визуальные метафоры. Если «a warrior in battle armor» постоянно активирует IMAGE_SAFETY, переформулируйте как «a medieval museum exhibit display of ornate plate armor on a mannequin stand, dramatic gallery lighting» или «a fantasy book cover illustration showing an armored character in a heroic pose, painted in the style of classic fantasy art.» Оба описания достигают схожих визуальных результатов, представляя при этом совершенно разные семантические профили для системы безопасности. Ключевое понимание: фильтр безопасности оценивает семантическое значение вашего промпта в целом, а не отдельные слова, поэтому реструктуризация повествовательного обрамления значительно эффективнее, чем удаление конкретных слов-триггеров.
Еще одна мощная техника для устойчивых отказов -- подход с негативным промптом: явное указание модели, чего следует избегать. Хотя Nano Banana Pro не поддерживает формальный параметр негативного промпта, как Stable Diffusion, аналогичного эффекта можно достичь, включив контекстные границы в позитивный промпт. Фразы вроде «family-friendly editorial illustration», «suitable for a children's museum display» или «in the tradition of classical academic painting» устанавливают границы безопасности, которые модель соблюдает при генерации, существенно снижая вероятность создания результата, активирующего фильтры Уровня 2.
Настройка API для предотвращения ложных срабатываний
Если инженерия промптов решает проблемы Уровня 2, то правильная настройка API устраняет ненужные блокировки Уровня 1. Удивительно большое количество ошибок IMAGE_SAFETY, о которых сообщают на форумах разработчиков, на самом деле вызвано ошибками конфигурации, а не реальными срабатываниями контент-фильтра. Три наиболее распространенные ошибки конфигурации: полное отсутствие настроек безопасности (по умолчанию используются ограничительные), использование неправильного эндпоинта и пропуск параметра response_modalities.
Вот рекомендуемая конфигурация Python, которая устраняет ложные срабатывания, связанные с конфигурацией:
pythonimport google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel( model_name="gemini-3-pro-image", safety_settings={ "HARM_CATEGORY_HARASSMENT": "BLOCK_NONE", "HARM_CATEGORY_HATE_SPEECH": "BLOCK_NONE", "HARM_CATEGORY_SEXUALLY_EXPLICIT": "BLOCK_NONE", "HARM_CATEGORY_DANGEROUS_CONTENT": "BLOCK_NONE", }, generation_config={ "response_modalities": ["TEXT", "IMAGE"], # Critical: must include IMAGE "temperature": 1.0, "top_p": 0.95, } ) response = model.generate_content("Your optimized prompt here")
Эквивалентная конфигурация для JavaScript/Node.js следует тому же паттерну:
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-3-pro-image", safetySettings: [ { category: "HARM_CATEGORY_HARASSMENT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_HATE_SPEECH", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_SEXUALLY_EXPLICIT", threshold: "BLOCK_NONE" }, { category: "HARM_CATEGORY_DANGEROUS_CONTENT", threshold: "BLOCK_NONE" }, ], generationConfig: { responseModalities: ["TEXT", "IMAGE"], temperature: 1.0, topP: 0.95, }, });
Параметр response_modalities заслуживает особого внимания, поскольку его пропуск -- самая распространенная причина жалоб «мои настройки безопасности не работают». Когда этот параметр не задан или установлен только в ["TEXT"], модель может даже не пытаться генерировать изображение, а любой контент, связанный с изображениями, в вашем промпте оценивается исключительно как текст, часто активируя контент-фильтры, которые не сработали бы, если бы модель понимала, что вы запрашиваете графический вывод. Всегда включайте и "TEXT", и "IMAGE" в массив модальностей ответа.
Еще одна критически важная деталь конфигурации -- выбор эндпоинта. Если вы используете REST API напрямую, правильный эндпоинт для генерации изображений -- это стандартный эндпоинт generateContent с параметром response_modalities, а не отдельный эндпоинт, специфичный для изображений. Некоторые сторонние обертки и учебные материалы ссылаются на устаревшие эндпоинты, которые могут не поддерживать полную конфигурацию настроек безопасности. Для детального сравнения возможностей каждого эндпоинта обратитесь к нашему сравнению лимитов Free и Pro уровней, которое включает матрицы функций по эндпоинтам.
Распространенные ошибки конфигурации, вызывающие ненужные блокировки, включают: установку пороговых значений безопасности в OFF вместо BLOCK_NONE (это разные вещи: OFF полностью отключает оценку системы безопасности, что может вызвать непредсказуемое поведение на некоторых версиях моделей), отсутствие всех четырех категорий (пропуск даже одной устанавливает для нее ограничительный режим по умолчанию) и использование устаревших имен категорий из старых версий API. Всегда проверяйте вашу конфигурацию по актуальной официальной документации, поскольку имена категорий и варианты пороговых значений менялись между версиями моделей Gemini.
Защита вашего аккаунта Google от приостановки
Контроль рисков на уровне аккаунта -- это наиболее серьезный тип, поскольку его последствия выходят далеко за рамки Gemini API. Приостановленный аккаунт Google Cloud затрагивает все связанные сервисы, биллинг и доступ к данным. Понимание системы применения мер Google помогает оставаться в безопасных границах, максимально используя возможности генерации изображений.
Официальная политика использования Google для генеративных ИИ-сервисов (последнее обновление 11 февраля 2026 г.) устанавливает четырехэтапный процесс эскалации. Первый этап -- уведомление по электронной почте о том, что ваши паттерны использования инициировали проверку политики. Это письмо обычно приходит до каких-либо принудительных мер и служит предупреждением. Второй этап -- временное снижение лимитов запросов, когда квоты API вашего аккаунта понижаются без полной приостановки. Третий этап -- временная приостановка аккаунта, которая полностью блокирует доступ к API, но может быть разрешена через процесс апелляции. Четвертый и самый серьезный этап -- окончательное закрытие аккаунта, применяемое при повторных или грубых нарушениях.
Окно хранения данных длительностью 55 дней -- критически важная деталь, которую большинство руководств упускают. Google хранит данные взаимодействия с API в течение 55 дней специально для мониторинга злоупотреблений (политика использования Google AI for Developers, верифицировано 19 февраля 2026 г.). Это означает, что паттерн нарушений политики, распределенный почти на два месяца, может быть агрегирован для инициирования принудительных мер, даже если за один отдельный день использования порог не был превышен. Разработчики, отправляющие периодические пограничные запросы в предположении, что каждый день обнуляет счетчик, действуют под опасным заблуждением.
Уровень аккаунта практически влияет на толерантность к рискам. Аккаунты бесплатного уровня сталкиваются с самыми строгими мерами без процесса апелляции и с минимальным предупреждением. Аккаунты Tier 1 (с включенным биллингом) получают уведомления по электронной почте перед применением мер. Аккаунты Tier 2 ($250+ расходов за 30 дней) и Tier 3 ($1000+ расходов за 30 дней) имеют доступ к выделенным каналам поддержки и более щадящим срокам применения мер, хотя они не освобождены от соблюдения политики. Бизнес-обоснование для перехода выше Tier 1 -- это не только более высокие лимиты запросов; это также обеспечивает лучшую коммуникацию о применяемых мерах и возможности апелляции.
Для коммерческого использования три практики существенно снижают риск для аккаунта. Во-первых, реализуйте логирование контента на своей стороне: ведите журнал промптов и результатов, чтобы вы могли выявить проблемные паттерны до того, как это сделает мониторинг Google. Отслеживайте ежедневный процент блокировок, и если он превышает 20% за любой день, приостановите работу и проведите аудит шаблонов промптов перед продолжением. Этот подход самомониторинга позволяет обнаружить проблемы на ранних стадиях 55-дневного окна наблюдения Google, до начала принудительных мер.
Во-вторых, используйте отдельные API-ключи для разных категорий контента. Если вы генерируете и маркетинговые изображения (низкий риск), и промпты от пользовательского контента (более высокий риск) через один и тот же ключ, проблема в категории пользовательского контента загрязняет профиль риска всего аккаунта. Изолируя API-ключи по категориям контента, вы ограничиваете зону поражения при срабатывании мер из-за одного типа контента. Это особенно важно для платформ, которые позволяют конечным пользователям отправлять промпты, где у вас меньше контроля над входными данными.
В-третьих, никогда не отправляйте заблокированный промпт повторно без модификации. Многократная отправка одного и того же заблокированного промпта -- это самый быстрый способ активировать обнаружение паттернов, ведущее к эскалации. Мониторинг злоупотреблений Google специально отмечает повторные идентичные запросы, получающие блокировки безопасности, интерпретируя этот паттерн как попытку обхода политики контента. Вместо этого, если промпт заблокирован, примените техники инженерии промптов из предыдущего раздела или направьте его альтернативному провайдеру. Встраивание этой логики «модифицировать или перенаправить» в архитектуру конвейера предотвращает случайную эскалацию политики от автоматических систем повторных попыток, не учитывающих блокировки контента.
Реальная стоимость сбоев фильтров (и когда переключаться)
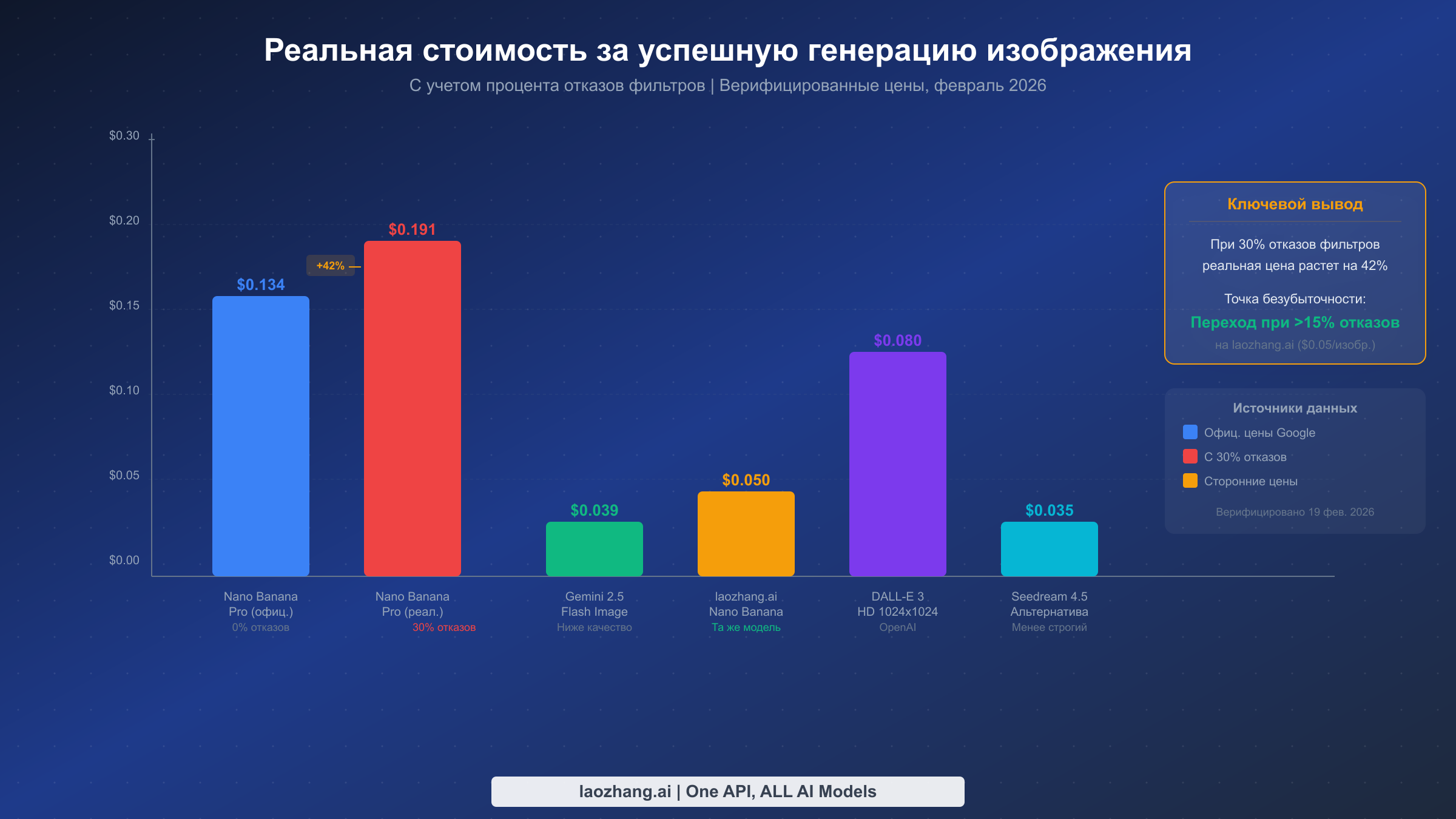
Большинство анализов стоимости генерации изображений ИИ сравнивают номинальные цены, что вводит в заблуждение, когда процент отказов фильтров существенно различается между провайдерами. Истинная метрика, которая имеет значение, -- это стоимость за успешное изображение: общая потраченная сумма (включая неудачные попытки, которые всё равно потребляют кредиты API), разделенная на количество пригодных к использованию изображений. Эта экономическая модель показывает, когда переключение провайдеров или создание мультипровайдерного конвейера становится финансово рациональным.
Официальная цена Nano Banana Pro составляет приблизительно $0,134 за изображение в стандартном разрешении (1K-2K пикселей), на основе ~$120/M выходных токенов для генерации изображений (Google AI for Developers, ценообразование верифицировано 19 февраля 2026 г.). При 0% сбоев это конкурентоспособно, но не самый дешевый вариант. Однако когда контент-фильтры блокируют значительный процент ваших запросов, эффективная стоимость существенно возрастает. При 30% сбоев (обычно для контента с изображениями людей, коммерческими сценами или чем-либо, что система безопасности считает пограничным) эффективная стоимость за успешное изображение вырастает приблизительно до $0,191 -- увеличение на 42% по сравнению с номинальной ценой.
Расчет точки безубыточности прост. Если ваш процент сбоев превышает приблизительно 15%, переключение на альтернативного провайдера, предлагающего ту же модель с более мягкой фильтрацией, становится экономически выгодным. Платформы-агрегаторы, такие как laozhang.ai, предоставляют доступ к Nano Banana Pro приблизительно за $0,05 за изображение с более мягкими конфигурациями фильтрации контента. При такой цене даже при 0% сбоев на официальном API экономия составляет 63%, и прямое соединение с Google дает преимущество только если для вас важнее прямые отношения с Google, чем экономия.
Другие альтернативы появляются на различных точках соотношения цены и производительности. Генерация изображений Gemini 2.5 Flash Image стоит приблизительно $0,039 за изображение, но с более низким качеством (подходит для прототипирования, но не для продакшена). DALL-E 3 HD (1024x1024) стоит приблизительно $0,080 за изображение через API OpenAI с другими компромиссами по политике контента. Seedream 4.5, который стал популярной альтернативой во время инцидента января 2026 года, стоит приблизительно $0,035 за изображение с менее строгой фильтрацией контента, но создает заметно отличающийся визуальный стиль. Для полного сравнения доступных альтернатив Gemini image API обратитесь к нашему руководству по бюджетным вариантам Gemini image API.
| Провайдер | Цена/изображение | Качество | Гибкость контента | Лучше для |
|---|---|---|---|---|
| Nano Banana Pro (напрямую) | $0,134 | 9,5/10 | Умеренная (двухуровневый фильтр) | Премиум-качество, допустимый контент |
| laozhang.ai (Nano Banana) | $0,05 | 9,5/10 (та же модель) | Выше | Продакшен с оптимизацией затрат |
| Gemini 2.5 Flash Image | $0,039 | 7,5/10 | Аналогична Nano Banana | Прототипирование, большие объемы |
| DALL-E 3 HD | $0,080 | 8,5/10 | Другие политики | Разнообразие стилей |
| Seedream 4.5 | $0,035 | 8,0/10 | Более мягкая | Бюджетный продакшен |
Экономическая система принятия решений сводится к трем вопросам: каков ваш текущий процент сбоев? Каков ваш порог качества? И какова допустимая стоимость за изображение? Если процент сбоев ниже 10% и качество имеет первостепенное значение, прямой Nano Banana Pro оптимален. Если процент сбоев превышает 15% или оптимизация затрат является приоритетом, провайдер вроде laozhang.ai, предоставляющий ту же модель по более низкой цене с меньшим количеством ограничений фильтров, предлагает явно лучшую экономику. Если вы можете принять другие визуальные стили, Seedream 4.5 обеспечивает самый низкий ценовой порог.
Создание отказоустойчивого мультипровайдерного конвейера изображений
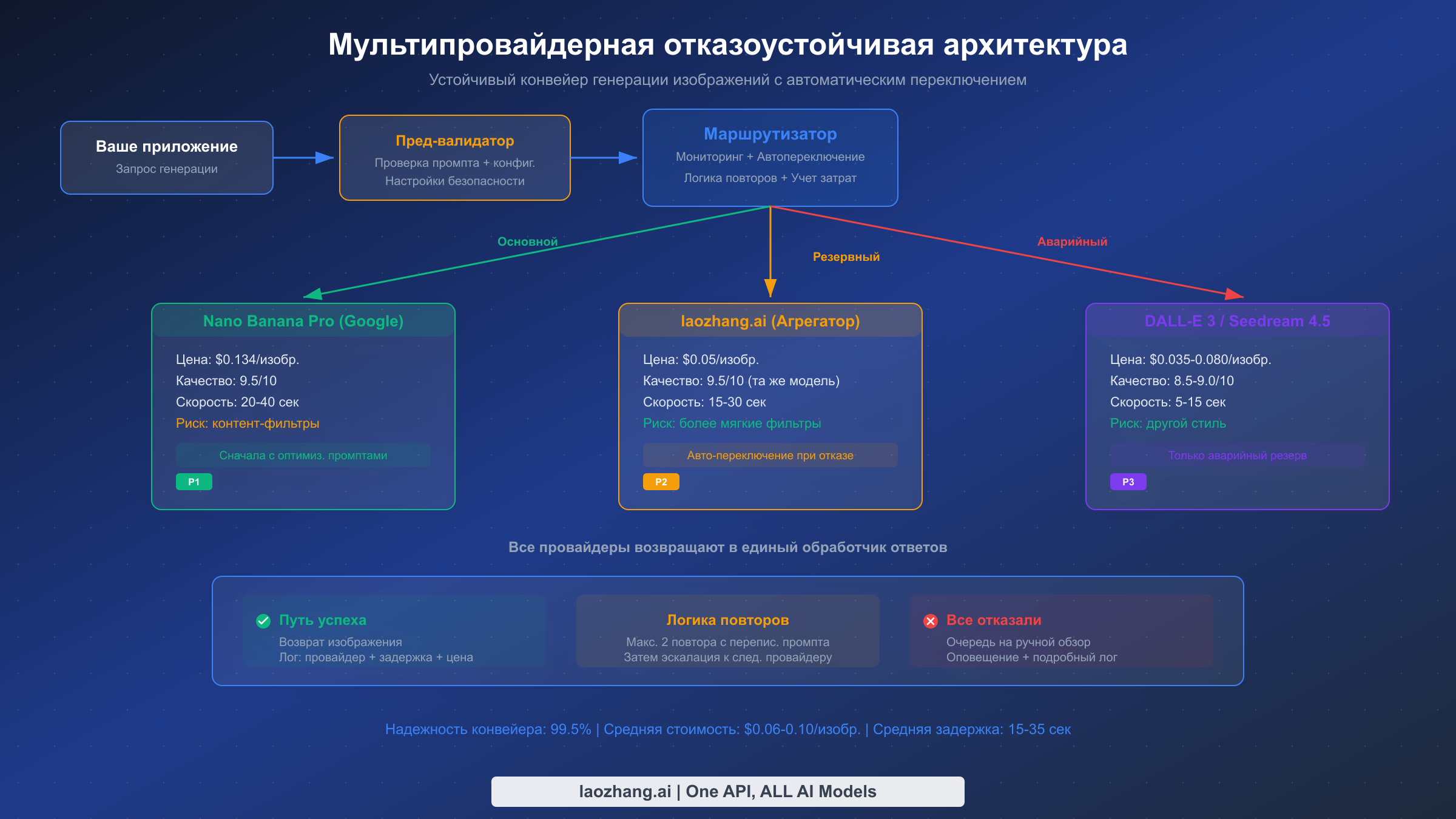
Наиболее надежный подход к контролю рисков Nano Banana Pro -- это не полное избежание сбоев (что невозможно из-за ненастраиваемой природы Уровня 2), а создание системы, которая обрабатывает сбои элегантно. Хорошо спроектированный мультипровайдерный конвейер достигает более 99% общего процента успеха, автоматически перенаправляя неудавшиеся запросы альтернативным провайдерам, при этом оптимизируя затраты за счет предпочтения самого дешевого успешного провайдера для каждого типа запросов.
Архитектура следует трехуровневому паттерну: основной провайдер (Nano Banana Pro для лучшего качества), резервный провайдер (та же модель через агрегатор вроде laozhang.ai для лучшей толерантности фильтров) и аварийный провайдер (совершенно другая модель, например DALL-E 3 или Seedream 4.5, для максимальной надежности). Каждый уровень имеет монитор здоровья, отслеживающий процент успеха и время отклика, автоматически перенаправляя новые запросы от деградировавших провайдеров.
Вот паттерн реализации, готовый к продакшену, на Python:
pythonimport time import random from dataclasses import dataclass from typing import Optional @dataclass class ProviderHealth: success_count: int = 0 failure_count: int = 0 last_success: float = 0 avg_latency: float = 0 class ImagePipeline: def __init__(self): self.providers = { "nano_banana_direct": { "priority": 1, "cost": 0.134, "health": ProviderHealth(), "generate": self._generate_nano_banana, }, "nano_banana_aggregator": { "priority": 2, "cost": 0.05, "health": ProviderHealth(), "generate": self._generate_aggregator, }, "backup_provider": { "priority": 3, "cost": 0.035, "health": ProviderHealth(), "generate": self._generate_backup, }, } def generate_image(self, prompt: str, max_retries: int = 2) -> dict: """Generate image with automatic provider fallback.""" sorted_providers = sorted( self.providers.items(), key=lambda x: x[1]["priority"] ) for name, provider in sorted_providers: health = provider["health"] failure_rate = self._get_failure_rate(health) # Skip providers with >50% recent failure rate if failure_rate > 0.5 and health.success_count > 10: continue for attempt in range(max_retries): try: start = time.time() result = provider["generate"](prompt) latency = time.time() - start health.success_count += 1 health.last_success = time.time() health.avg_latency = ( health.avg_latency * 0.8 + latency * 0.2 ) return { "image": result, "provider": name, "cost": provider["cost"], "latency": latency, "attempt": attempt + 1, } except ContentFilterError: health.failure_count += 1 if attempt < max_retries - 1: prompt = self._rewrite_prompt(prompt) continue except (TimeoutError, ServerError): health.failure_count += 1 break # Don't retry server errors, move to next provider return {"error": "All providers failed", "prompt": prompt} def _get_failure_rate(self, health: ProviderHealth) -> float: total = health.success_count + health.failure_count return health.failure_count / total if total > 0 else 0 def _rewrite_prompt(self, prompt: str) -> str: """Add safety-enhancing context to a failed prompt.""" prefixes = [ "Digital art illustration: ", "Professional artwork depicting: ", "Illustrated editorial image of: ", ] return random.choice(prefixes) + prompt
Ключевые проектные решения в этой архитектуре стоит понимать. Во-первых, логика повторных попыток включает переписывание промпта между попытками: вместо повторной отправки того же заблокированного промпта (что создает риск флагов на уровне аккаунта) система автоматически добавляет контекст, усиливающий безопасность. Во-вторых, мониторинг здоровья использует экспоненциальные скользящие средние вместо сырых подсчетов, поэтому недавняя производительность весит больше, чем исторические данные. В-третьих, ошибки сервера (502/503) вызывают немедленное переключение, а не повторные попытки, поскольку серверные проблемы обычно затрагивают все запросы к данному провайдеру, и повторные попытки лишь добавляют задержку.
Мониторинг и оповещения завершают отказоустойчивый конвейер. Отслеживайте три метрики для каждого провайдера: процент успеха (оповещение при падении ниже 80%), среднюю задержку (оповещение при превышении 2x от базовой линии) и стоимость за успешное изображение (оповещение при превышении бюджетного порога). Когда любой провайдер пересекает порог оповещения, конвейер должен автоматически понизить его приоритет и отправить уведомление для ручной проверки. Логируйте каждый неудавшийся запрос с полным промптом и ответом об ошибке для пост-инцидентного анализа и улучшения шаблонов промптов.
Механизм восстановления здоровья столь же важен. Когда провайдер был понижен в приоритете из-за низкой производительности, система должна периодически отправлять тестовые запросы (канареечные пробы) для обнаружения восстановления. Во время серверного инцидента января 2026 года провайдеры, реализовавшие канареечное зондирование, восстановили пропускную способность конвейера в течение нескольких минут после восстановления сервиса Google, тогда как провайдеры без зондирования потребовали ручного вмешательства. Простой подход -- отправлять один тестовый запрос каждые 5 минут понизившимся в приоритете провайдерам и восстанавливать их приоритет после трех последовательных успешных запросов.
Отслеживание затрат по конвейеру должно агрегироваться как на уровне отдельных запросов (для точности биллинга), так и на дневном уровне (для управления бюджетом). С трехпровайдерным конвейером ваша дневная дисперсия затрат может быть значительной в зависимости от того, какой провайдер обрабатывает основную часть трафика. Создание дневной панели затрат, показывающей фактические расходы по сравнению с бюджетом по каждому провайдеру, помогает выявить сдвиги в паттернах трафика, которые могут указывать на изменение политики контент-фильтра или деградацию сервиса, до того как это станет серьезной проблемой.
Краткий справочник: чек-лист предотвращения и FAQ
Чек-лист перед запросом (проверяйте перед каждым развертыванием)
Перед отправкой любого запроса на генерацию изображений в Nano Banana Pro проверьте пять пунктов. Во-первых, убедитесь, что настройки безопасности включают все четыре настраиваемые категории, установленные в BLOCK_NONE. Во-вторых, проверьте, что response_modalities включает и "TEXT", и "IMAGE". В-третьих, убедитесь, что промпт начинается с декларации художественного контекста (медиум, стиль или профессиональное обрамление). В-четвертых, проверьте, что любые человеческие фигуры описаны как «illustrated» или «fictional». В-пятых, убедитесь, что промежуточное ПО ограничения скорости активно и установлено ниже предела RPM вашего уровня.
Часто задаваемые вопросы
Можно ли полностью отключить контент-фильтры Nano Banana Pro?
Нет. Вы можете отключить четыре настраиваемых фильтра HARM_CATEGORY, установив их в BLOCK_NONE, но выходной фильтр IMAGE_SAFETY, обнаружение CSAM, фильтр PROHIBITED_CONTENT и обнаружение SPII остаются всегда активными. Эти ненастраиваемые фильтры анализируют само сгенерированное изображение и не могут быть отключены через какие-либо настройки API. Единственный способ снизить их воздействие -- инженерия промптов, направляющая вывод модели в сторону от контента, активирующего эти фильтры, что обеспечивает приблизительно 70-80% успеха для пограничного контента.
Почему один и тот же промпт иногда работает, а иногда блокируется?
Nano Banana Pro использует стохастический процесс генерации, то есть модель создает слегка различные результаты каждый раз, даже при идентичных входных данных. Когда ваш промпт генерирует контент вблизи порога фильтра IMAGE_SAFETY, некоторые генерации пройдут, а другие -- нет. Решение -- не повторять тот же промпт (что создает риск флагов аккаунта), а добавить более конкретный художественный контекст, ограничивающий вывод модели более безопасной визуальной территорией. Увеличение конкретности уменьшает дисперсию генерируемого контента, делая результаты более предсказуемыми.
Что произойдет, если мой аккаунт Google будет отмечен за нарушения политики контента?
Google следует четырехэтапной эскалации: предупреждение по электронной почте, временное снижение лимитов, временная приостановка и окончательное закрытие. Окно хранения данных в 55 дней означает, что нарушения отслеживаются почти два месяца. Если вы получили предупреждение по электронной почте, немедленно проведите аудит промптов и внедрите стратегии предотвращения из этого руководства. Для аккаунтов с включенным биллингом (Tier 1+) доступен процесс апелляции. Аккаунты бесплатного уровня не имеют механизма апелляции, поэтому предотвращение критически важно. Использование отдельных API-ключей для разных категорий контента помогает изолировать риск.
Стоит ли использовать стороннего провайдера вместо прямого доступа к Google API?
Это зависит от вашего процента сбоев и чувствительности к затратам. Если ваш контент стабильно проходит фильтры (менее 10% сбоев), прямой доступ по $0,134/изображение дает лучшую гарантию качества и прямую поддержку Google. Если процент сбоев превышает 15%, эффективная стоимость за успешное изображение становится выше, чем у альтернативных агрегаторов вроде laozhang.ai по $0,05/изображение, которые предоставляют ту же модель Nano Banana Pro с более мягкими конфигурациями фильтрации. Оптимальная стратегия для большинства продакшен-систем -- мультипровайдерный конвейер, использующий прямой доступ как основной и агрегатор как резервный.
Как различаются лимиты запросов между бесплатным и платным уровнями?
Система лимитов Google использует четыре уровня: Free, Tier 1 (с включенным биллингом), Tier 2 ($250+ расходов за 30 дней) и Tier 3 ($1000+ расходов за 30 дней). Каждый уровень увеличивает пределы RPM (запросов в минуту), RPD (запросов в день) и IPM (изображений в минуту). Дневные лимиты сбрасываются в полночь по тихоокеанскому времени. Модели в режиме предварительного просмотра, такие как Nano Banana Pro, могут иметь более строгие лимиты, чем стабильные модели. Страница лимитов была последний раз обновлена 17 февраля 2026 года. Для полного поуровневого разбора обратитесь к нашему детальному сравнению лимитов Free и Pro.