На 4 мая 2026 года это не гонка за одним победителем. GPT-5.5 стоит тестировать первым там, где рабочий процесс уже зависит от OpenAI, Codex, инструментов и структурированного вывода. Claude Opus 4.7 лучше держать как premium control для задач, где ошибка дороже модели. DeepSeek V4 Pro заслуживает пилота, когда цена, open-weight контроль или массовые long-context эксперименты важнее немедленного production-перехода.
Безопасная исходная позиция проста: выбирать нужно маршрут, который команда может проверить, а не название модели, которое выиграло публичную таблицу. GPT-5.5 входит в первый OpenAI-native пилот. Opus 4.7 остается контрольной премиальной линией. DeepSeek V4 Pro идет в ограниченный cost или self-host пилот, пока не докажет ту же задачу с теми же файлами, инструментами и критериями приемки.
| Задача маршрута | С чего начать | Почему подходит | Правило остановки |
|---|---|---|---|
| OpenAI-native coding, Codex, tool-heavy API, structured output | GPT-5.5 | Документация OpenAI сейчас перечисляет GPT-5.5, 1M контекста и 128K максимального вывода, поэтому это самый чистый первый тест внутри OpenAI-стека. | Перед production-трафиком повторно проверить доступ в аккаунте, лимиты, консоль и конфликт со старой справочной заметкой. |
| Correctness-sensitive agents, cloud/API deployment, premium control | Claude Opus 4.7 | Anthropic позиционирует Opus 4.7 для сложного coding, agents, tools, vision и облачного развертывания. | Не утверждать premium-стоимость, пока модель не снижает дефекты, время ревью или риск отката. |
| Cost-sensitive pilots, open-weight governance, high-volume long-context tests | DeepSeek V4 Pro | DeepSeek документирует скидку V4 Pro, совместимые URL, 1M контекста и 384K максимального вывода. | Держать как пилот, пока качество, latency, route fidelity и rollback не прошли. |
| Любое изменение production default | Dual-run first | Публичные бенчмарки и разница цен не измеряют ваши failure modes. | Никакого переключения без одинаковых prompts, tools, files, budgets, acceptance tests и rollback threshold. |
Начинайте с контракта, который можно вызвать
Практическое сравнение начинается с владельца маршрута. OpenAI владеет фактами о GPT-5.5 и API-контрактом. Anthropic владеет доступностью и ценой Claude Opus 4.7. DeepSeek владеет V4 Pro API, скидочным окном и open-weight маршрутом. Обзоры, видео и агрегаторы полезны для вопросов, но они не должны решать model labels, цены, endpoint behavior, context windows или discount windows.
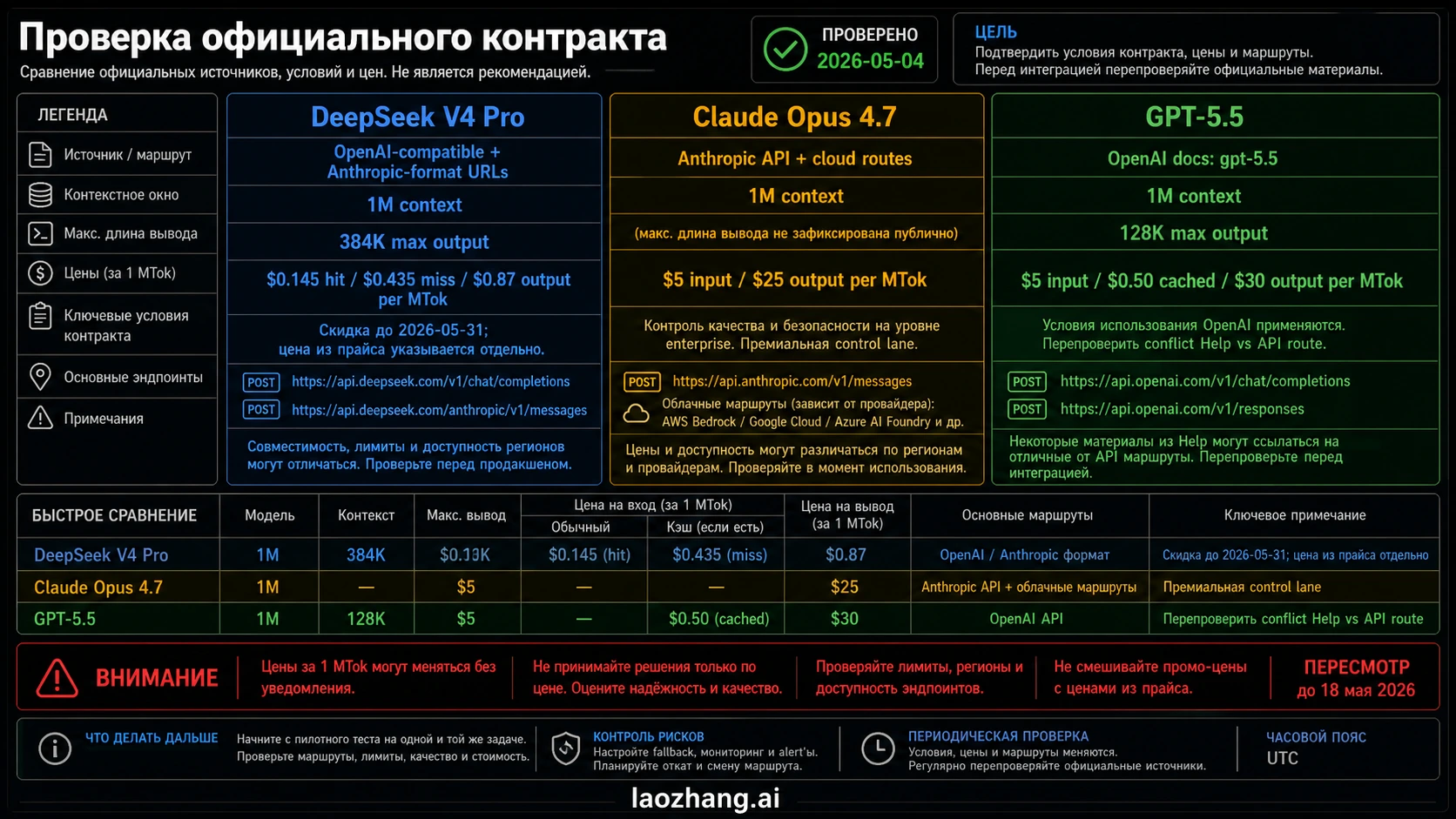
| Контрактный пункт | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 Pro |
|---|---|---|---|
| Основной владелец маршрута | OpenAI developer platform и OpenAI-native product/tool surfaces | Anthropic API, Claude products и крупные cloud partners | DeepSeek API плюс официальная open-weight model card |
| Метка модели для проверки | В документации OpenAI перечислены GPT-5.5, GPT-5.5 Chat, GPT-5.5 Thinking и dated variants | Перед деплоем проверяйте текущий model ID в Anthropic docs или консоли | DeepSeek API docs перечисляют deepseek-v4-pro |
| Контекст и вывод | OpenAI docs указывают 1M контекста и 128K max output | Anthropic ставит Opus 4.7 в long-context и demanding agent work, но лимиты зависят от маршрута | DeepSeek docs указывают 1M контекста и 384K max output |
| Владелец цены | OpenAI docs сейчас указывают $5 input, $0.50 cached input и $30 output за million tokens для standard short-context API row | Anthropic launch material указывает $5 input и $25 output за million tokens | DeepSeek docs указывают скидку до 2026-05-31: $0.145 cache-hit input, $0.435 cache-miss input, $0.87 output |
| Граница риска | Старая справочная заметка OpenAI говорила, что GPT-5.5 не запускался в API в тот rollout day, а текущие developer docs уже перечисляют GPT-5.5. Production требует текущей проверки. | Premium имеет смысл только при меньшем числе дефектов, меньшем review time или меньшем rollout risk. | Совместимый URL не доказывает поведенческий паритет с OpenAI или Anthropic routes. |
Документация моделей OpenAI и страница сравнения моделей контролируют контракт GPT-5.5. Старая help center заметка все еще важна, потому что создает датированный конфликт: она описывала ChatGPT/Codex rollout и говорила, что GPT-5.5 в тот день не выходит в API. Если планируется платный трафик, проверяйте текущие developer docs, account access, model visibility, limits и фактический вызов.
Anthropic launch page для Claude Opus 4.7 говорит о доступности в Claude products, Anthropic API, Amazon Bedrock, Google Vertex AI и Microsoft Foundry, а также о цене $5 input и $25 output за million tokens. DeepSeek pricing docs перечисляют V4 Pro price, compatible OpenAI and Anthropic-format URLs, 1M контекста, 384K max output и временную скидку. Официальная model card добавляет open-weight сторону: 1.6T total parameters, 49B activated и 1M context.
Подбирайте модель под рабочую нагрузку
Чистое сравнение DeepSeek V4 Pro, Claude Opus 4.7 и GPT-5.5 строится не вокруг короны, а вокруг работы. Модель, которая лучше всего вписывается в OpenAI-native tool loop, не обязана быть лучшим premium control для автономного агента. Дешевая строка за million tokens не обязана дать дешевую выполненную задачу, если растут retries, defects или review load.

| Workload | Первая модель для теста | Почему | Что измерять |
|---|---|---|---|
| OpenAI-native coding, Codex, Responses API tools, structured outputs | GPT-5.5 | Модель ближе всего к OpenAI tool surface и account controls. | Accepted diffs, tool recovery, format stability, review time, token cost. |
| Correctness-sensitive coding agents или multi-step orchestration | Claude Opus 4.7 | Opus является premium control, когда failure cost выше model cost. | Defect severity, tool-call reliability, rollback behavior, reviewer trust. |
| Batch exploration, fuzzing, дешевый long-context exploration | DeepSeek V4 Pro | Скидка и open-weight маршрут оправдывают cost pilot. | Task success rate, retry rate, latency under load, route fidelity. |
| Long-context documents, repos, evidence analysis | Route-specific test | Все три маршрута заявляют или поддерживают большой контекст разными способами. | Truncation, recall quality, output length, cost at full prompt size. |
| Self-host, private cloud, governance | DeepSeek V4 Pro | GPT-5.5 и Opus закрытые hosted routes, а DeepSeek дает open-weight path. | Deployment complexity, security review, inference cost, maintenance burden. |
| Existing production default | Dual-run | У текущего default уже есть известная история и known failure modes. | Regression count, total cost, human minutes, fallback success. |
Для OpenAI-native разработки GPT-5.5 получает первый тест, потому что он ближе всего к Codex, OpenAI tools, file handling, structured output и account policy. Это не делает его универсальным production default, но снижает стоимость начального наблюдения там, где стек уже построен вокруг OpenAI.
Для premium reliability Claude Opus 4.7 остается контрольной линией. Он особенно уместен в задачах multi-tool orchestration, сложного code review, визуально-документной проверки и conservative rollout. Если Opus стоит дороже, но уменьшает количество серьезных дефектов и минуты senior review, premium может быть рациональным.
Для cost pressure и open-weight governance DeepSeek V4 Pro заслуживает пилота. Его скидка заметна, совместимые endpoints полезны, а модельная карта важна для команд, которым нужна самостоятельная инфраструктура или контроль над весами. Но цена и endpoint shape не доказывают, что он одинаково восстанавливается после tool errors, сохраняет JSON, выдерживает latency и читает ваш repo лучше premium routes.
Цена является входом в маршрутизацию
DeepSeek V4 Pro имеет самый заметный price advantage. Текущие документы DeepSeek показывают скидку V4 Pro до 31 мая 2026 года 15:59 UTC: $0.145 за million cache-hit input tokens, $0.435 за cache-miss input tokens и $0.87 за output tokens. Рядом нужно держать list prices: $0.58, $1.74 и $3.48. Пилот, начатый в discount window, может выглядеть совсем иначе после окончания скидки.
GPT-5.5 по текущей OpenAI comparison table не бюджетная модель: standard short-context API row указывает $5 input, $0.50 cached input и $30 output за million tokens. Long-context pricing нужно проверять как отдельный route row, не смешивая его с этой стандартной строкой. Claude Opus 4.7 в Anthropic launch material стоит $5 input и $25 output. На raw hosted API price DeepSeek сильно дешевле, Claude является premium control, а GPT-5.5 - дорогим OpenAI-native frontier route.
Но deploy decision нельзя выводить из одной price row. Дешевая модель становится дорогой, если требует больше повторов, ломает structured output, создает review work или заставляет поддерживать отдельную serving stack. Дорогая модель может быть дешевле на уровне completed task, если сокращает human review minutes и failed generations.
| Cost variable | Почему это важно |
|---|---|
| Input и cached input | Long prompts, repeated context и cache behavior меняют ranking. |
| Output length | Output price GPT-5.5 и 384K max output DeepSeek по-разному влияют на long generation economics. |
| Retry rate | Низкая цена токена проигрывает, если модель делает несколько попыток. |
| Human review time | Самая дорогая часть coding workflow часто не token row, а senior engineer, который читает результат. |
Бюджетный расчет должен идти по representative tasks. Запускайте одинаковые prompts, файлы, tools, permissions и task budgets. Считайте input, cached input, output, retries, p95 latency и review minutes. Если DeepSeek сохраняет преимущество после полной задачи, он заслуживает расширения. Если Opus или GPT-5.5 сокращают review и rollback, их высокая цена может окупиться.
Читайте бенчмарки без лишних выводов
Публичные бенчмарки полезны, когда похожи на вашу работу. Coding-agent rows, terminal-task evaluations, browsing/research scores, long-context tests и math/security benchmarks измеряют разные вещи. Сильная строка GPT-5.5 в OpenAI-native тесте является причиной запустить GPT-5.5 в этом маршруте. Она не доказывает, что DeepSeek V4 Pro не может быть cost pilot, и не доказывает, что Opus 4.7 перестал быть premium control.
То же работает в обратную сторону. DeepSeek price/performance claim является причиной собрать pilot harness. Это не доказательство production replacement для high-risk agent. Anthropic launch claim является причиной держать Opus в control lane. Это не доказательство, что Opus всегда стоит premium, если GPT-5.5 или DeepSeek прошли ту же задачу.
Используйте лестницу доказательств:
- Official docs решают существование маршрута, model label, цену и ограничения.
- Provider or third-party benchmarks подсказывают, какие workloads заслуживают теста.
- Same-task harness решает, может ли модель стать default.
- Production rollout проверяет, survives ли улучшение при реальных permissions, latency и failures.
Эта лестница защищает от ошибок совместимости. DeepSeek предлагает OpenAI-compatible и Anthropic-format API URLs, но форма URL не равна behavior parity. Tool calling, streaming, timeouts, tokenization, output format, safety behavior, retries и SDK edge cases могут отличаться. Compatibility снижает начальную интеграцию, но не отменяет validation.
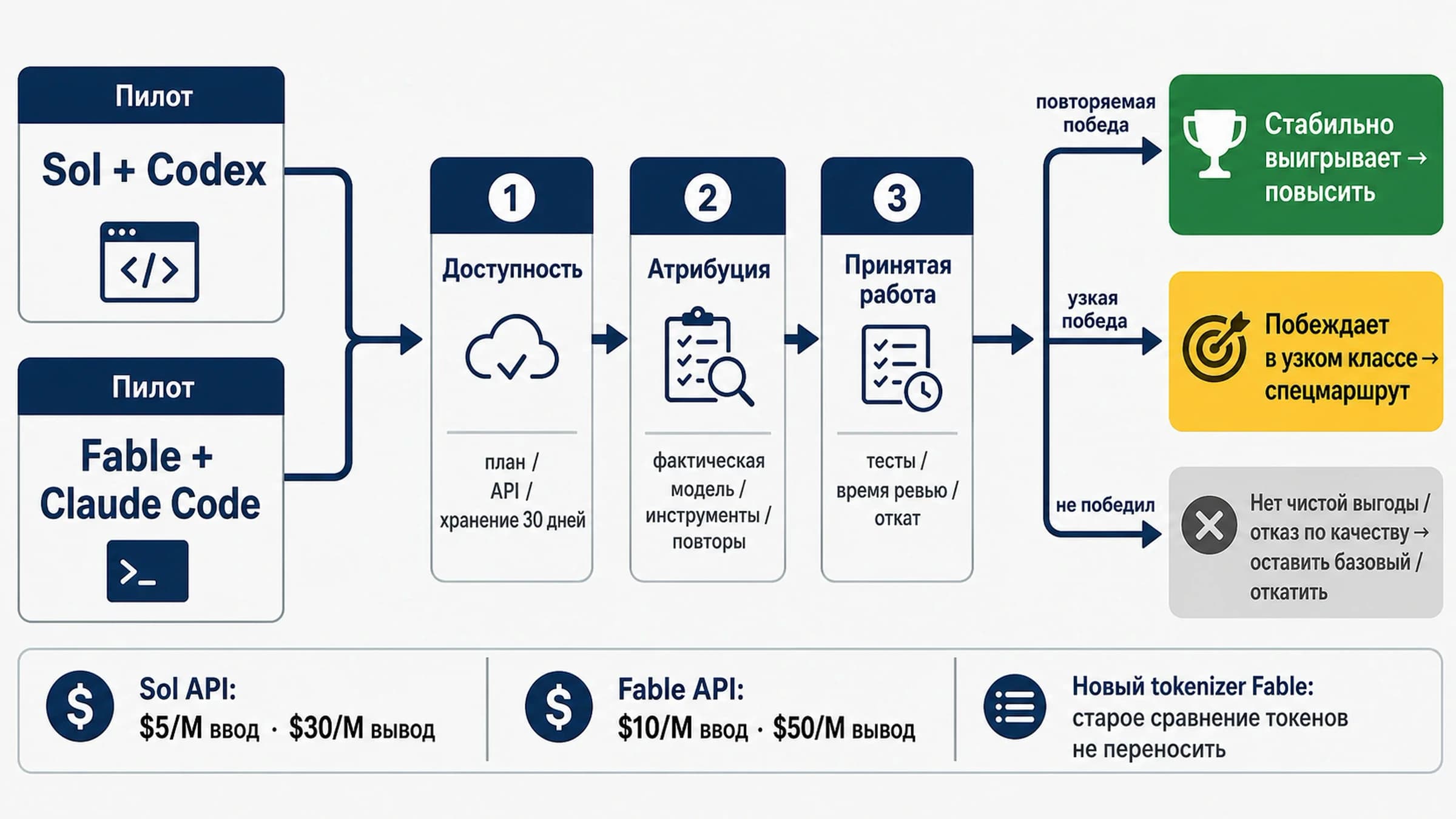
Перед переключением нужен same-task pilot
Практичный пилот может быть небольшим. Главное, чтобы результат выдержал разговор о production. Нельзя давать одной модели лучший prompt, больший budget или более легкий набор tasks, а затем объявлять победителя. Candidate должен проходить те же tasks, files, tools и acceptance criteria.

| Pilot gate | Что делать | Pass condition |
|---|---|---|
| Route check | Confirm model label, endpoint, account access, region, quota и fallback. | Команда может вызвать маршрут, который планирует deploy. |
| Same prompt and tools | Использовать одинаковые system prompt, files, tools, permissions и task budget, где surfaces позволяют. | Разница идет от model behavior, а не от лучшего harness. |
| Representative tasks | Включить easy, hard, long-context, output-format и failure-prone tasks. | Sample совпадает с работой, которая стоит денег или review time. |
| Defect scoring | Классифицировать correctness, severity, security risk и recovery effort. | Candidate уменьшает high-severity failures. |
| Review-time scoring | Считать human review minutes и accepted-result rate. | Candidate уменьшает total work. |
| Cost and latency | Измерять input, cached input, output, retries, task-level cost и p95 latency. | Savings survive full-task accounting. |
| Rollback threshold | Решить, какой failure rate, latency или cost запускает fallback. | Old route может вернуться без rebuild. |
Команда, у которой уже есть GPT-5.4, Opus 4.7 или другой стабильный default, должна ставить планку выше, чем "новая модель впечатляет". Сначала оставьте incumbent, shadow-run candidate, затем поднимайте трафик только при снижении total work, acceptable regression rate и ясном rollback path.
Команда, выбирающая первый маршрут, может начать с GPT-5.5 и Opus 4.7 на high-risk tasks, а затем добавить DeepSeek V4 Pro там, где важны cost или open weights. Если DeepSeek проходит те же tasks, он становится серьезным default candidate для workload. Если проваливается так, что требует manual repair, держите его в exploration lane.
Смежные решения
Трехстороннее сравнение DeepSeek V4 Pro, Claude Opus 4.7 и GPT-5.5 решает только задачу первого теста, control lane и production switch. Более узкие или широкие решения лучше разделять.
Если реальный выбор только между OpenAI и Anthropic, используйте GPT-5.5 vs Claude Opus 4.7. Там больше места для OpenAI-native testing и Anthropic deployability.
Если нужен более широкий дешевый route pool с Kimi, используйте Kimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7. Четырехстороннее распределение требует отдельной логики.
Если сравниваются более старые official frontier API routes, используйте Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro. Для background по DeepSeek начните с DeepSeek V4.
Часто задаваемые вопросы
GPT-5.5 лучше Claude Opus 4.7 и DeepSeek V4 Pro?
GPT-5.5 лучше первым тестировать в OpenAI-native работе, особенно coding или tool workflows. Это не универсальный winner. Claude Opus 4.7 остается premium control lane, а DeepSeek V4 Pro заслуживает cost/open-weight pilot при честной validation.
DeepSeek V4 Pro дешевле GPT-5.5 и Claude Opus 4.7?
Да, по текущей documented API discount. Но discount window имеет дату завершения и должен отделяться от list price. Completed-task cost зависит от качества, retries, latency и review time.
Стоит ли использовать Claude Opus 4.7 для coding agents?
Используйте Claude Opus 4.7 первым, когда agent correctness-sensitive, deployable through Anthropic или cloud routes, а review и rollback дороги. GPT-5.5 тестируйте первым для OpenAI-native work. DeepSeek V4 Pro добавляйте как pilot, когда cost или open weights важнее premium control.
Может ли DeepSeek V4 Pro заменить Claude Opus 4.7?
Только после same-task pilot на вашем workload. DeepSeek V4 Pro может быть серьезным кандидатом для high-volume или open-weight tasks, но price и compatible endpoints не доказывают production replacement.
GPT-5.5 доступен через API?
Текущие OpenAI developer docs перечисляют GPT-5.5 model entries и API price/context details. Старая OpenAI Help Center rollout note говорила, что GPT-5.5 не запускался в API в тот день. Перед production traffic проверяйте current docs, account access, limits и console behavior.
Что тестировать первым для long-context work?
Тестируйте маршрут, который соответствует deployment need. OpenAI и DeepSeek docs перечисляют 1M context для relevant routes, а Anthropic позиционирует Opus 4.7 для demanding long-context agent work. Измеряйте truncation, recall, output length, latency и full-task cost.
Самое безопасное правило production switch?
Не меняйте default по public benchmarks, price gap или launch excitement. Dual-run candidate на тех же prompts, tools, files, task budgets и acceptance tests. Promote только когда он уменьшает total work и имеет rollback path.
Итоговое решение - route plan: GPT-5.5 для OpenAI-native first tests, Claude Opus 4.7 для premium deployable control, DeepSeek V4 Pro для cost или open-weight pilots. Production switch должен быть заработан на тех же задачах.