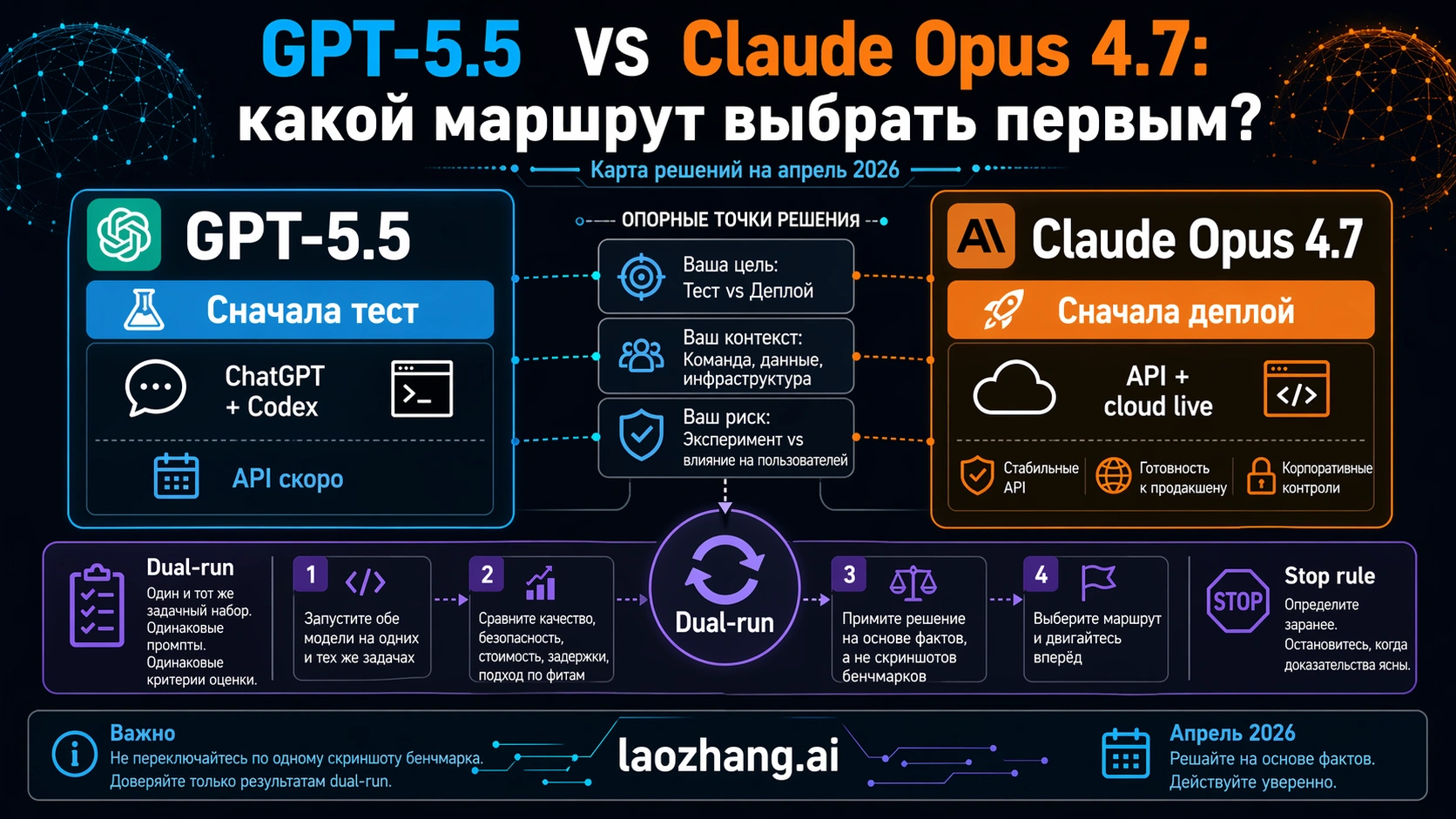
GPT-5.5 и Claude Opus 4.7 пока не являются симметричным API-выбором. На 24 апреля 2026 года GPT-5.5 доступна в ChatGPT и Codex для платных OpenAI-поверхностей, а API-доступ к ней обозначен как coming soon. Claude Opus 4.7 уже доступна через Anthropic API, Amazon Bedrock, Google Vertex AI и Microsoft Foundry.
Поэтому вопрос не в том, какая модель "победила" в день релиза. Правильный первый вопрос: где именно будет выполняться ваша работа. Если это ChatGPT, Codex, OpenAI-native анализ или coding review, первой стоит тестировать GPT-5.5. Если нужен production API, cloud endpoint, журналирование, rollout и бюджетная дисциплина уже сегодня, первой в оценку должна идти Claude Opus 4.7. Если вы меняете рабочий default, обе модели должны пройти один и тот же набор задач.
| Маршрут | Первый шаг | Почему это подходит | Stop rule |
|---|---|---|---|
| ChatGPT или Codex testing | Начать с GPT-5.5 | Это новый OpenAI route для professional work и agentic coding внутри уже доступных OpenAI-поверхностей. | Не планировать production API migration, пока официальный API не открыт для вашего аккаунта. |
| Production API или cloud deployment | Начать с Claude Opus 4.7 | Модель уже доступна в Claude API, Bedrock, Vertex AI и Microsoft Foundry. | Не заменять premium default по одной launch-week таблице. |
| Output-heavy или budget-sensitive задачи | Посчитать обе модели на реальных промптах | GPT-5.5 указана как coming soon по $5 input и $30 output за миллион tokens; Opus 4.7 live по $5 input и $25 output. | Не утверждать бюджет без проверки cache, batch, region, tokenizer и retries. |
| Замена текущего default | Запустить dual-run | Ценность замены определяется failures, review minutes и rollback cost, а не заголовком в новостях. | Без same repo, same prompts, same tool budget и same tests default не менять. |
Быстрый ответ
Если нужен практический ответ, выбирайте по маршруту, а не по имени модели.
| Ситуация | Что пробовать первым | Почему | Что перепроверить |
|---|---|---|---|
| Основная работа идет в ChatGPT, Codex или OpenAI-native coding flow | GPT-5.5 | OpenAI позиционирует GPT-5.5 как новый frontier route для professional и agentic work, а эти поверхности уже доступны. | API status, model ID, account limits, production constraints. |
| Нужен production API или cloud endpoint сегодня | Claude Opus 4.7 | Anthropic уже вывела Opus 4.7 в Claude API и крупные облачные платформы. | Latency, region, rate limits, token usage, deployment policy. |
| Работа output-heavy или бюджет утверждается строго | Opus 4.7 как live baseline | У Anthropic ясная текущая цена: $5 input и $25 output. У GPT-5.5 цена опубликована для coming-soon API и требует повторной проверки при запуске. | Cached input, batch discounts, regional multipliers, tokenizer effects. |
| Нужно подготовить GPT-5.5 API pilot | Подождать официальный callable route | Цена coming soon полезна для планирования, но она не равна endpoint, который можно поставить в production. | OpenAI docs и pricing page в день старта пилота. |
| Нужно заменить работающий default | Dual-run обе модели | Launch-week comparisons не измеряют ваши failure modes, review load и recovery cost. | Same task set, same tools, same acceptance tests, same cost accounting. |

Итог: это не простая формула "GPT-5.5 выигрывает" или "Claude выигрывает". GPT-5.5 надо первой проверять там, где работа уже находится внутри live OpenAI-поверхностей. Claude Opus 4.7 надо первой проверять там, где нужен API route, облачный endpoint и управляемый rollout прямо сейчас. Любая миграция с деньгами, SLA или customer-facing automation должна проходить один и тот же набор задач на обеих моделях.
Доступность и цена являются первым разделением
Сравнение цены начинается с доступности. Если одна модель уже запускается в нужном API route, а другая только заявлена как coming soon, первое решение не является benchmark decision.
| Контракт | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| User surface сейчас | OpenAI сообщает о rollout в ChatGPT и Codex для платных пользователей. | Anthropic показывает Opus 4.7 как доступную в Claude products. |
| API status на 24 апреля 2026 | API access coming soon. Не считать цену доказательством live endpoint. | Live в Anthropic API и major cloud platforms. |
| API model ID | Перепроверить OpenAI docs после запуска API; не придумывать имя модели. | claude-opus-4-7 в Anthropic model overview. |
| Standard API price | Coming-soon price: $5 input, $0.50 cached input, $30 output за миллион tokens. | $5 input и $25 output за миллион tokens, с cache и batch options. |
| Context и output | Перепроверить, когда API доступен вашему account. | 1M context и 128k max output в Messages API. |
| High-end variant | GPT-5.5 Pro является будущим expensive high-accuracy route, не базовым API-сравнением сегодня. | Opus 4.7 уже является premium Opus route. |
Эта таблица меняет default action. Developer, которому нужен production integration сегодня, может сразу добавить Opus 4.7 в live evaluation path. Команда, которая хочет GPT-5.5 через API, должна подготовить evaluation harness и дождаться официального callable route, а не строить deployment на слухах, screenshots или unofficial IDs.
Output price тоже важен. Если GPT-5.5 выйдет в API по указанной сейчас цене, ее output side выше live output price Opus 4.7. Это не значит, что Opus всегда дешевле: cache, batch, prompt length, tokenizer behavior, retries и manual edits могут изменить invoice. Но output-heavy задачи не должны автоматически считать новую OpenAI-модель budget default.
Как читать бенчмарки

Benchmark table помогает только тогда, когда вы привязываете ее к workload. Provider-published launch rows являются evidence, но не являются нейтральной universal crown. В launch-week обсуждениях легко увидеть формулировки "обошла Claude" или "все еще лучше пишет код"; инженерное решение должно разделять coding agent, terminal workflow, browsing, long-context review и production API.
| Benchmark | GPT-5.5 public result | Claude Opus 4.7 comparator | Практическое чтение |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | Сильный повод первой тестировать GPT-5.5 в Codex и terminal-style OpenAI workflows. |
| GDPval-agentic | 84.9% | 80.3% | Полезно для professional task quality, но требует domain-specific review loop. |
| OSWorld-Verified | 78.7% | 78.0% | Почти parity: deploy route и test harness важнее одной строки. |
| BrowseComp | 84.4% | Смотреть source table | Сигнал для browsing/research, не самостоятельное API решение. |
| FrontierMath Tier 4 | 35.4% | Смотреть source table | Hard-reasoning rows должны входить в pilot, а не заменять workload tests. |
| CyberGym | 81.8% | Смотреть source table | Важен только для задач, похожих на benchmark. |
Этого достаточно, чтобы серьезно тестировать GPT-5.5 для agentic coding и professional tasks. Этого недостаточно, чтобы одобрить blanket replacement. OpenAI владеет контекстом benchmark table, Anthropic владеет live API contract, а ваша workload владеет итоговым решением.
Главная ошибка: сравнивать live API model и not-yet-live API model так, будто обе одинаково deployable. Если вы выбираете, что пробовать в ChatGPT или Codex, GPT-5.5 rows важны. Если вы выбираете, что ставить за API route сегодня, availability остается первым фильтром, и Opus 4.7 имеет более чистый deployability contract.
Какая модель подходит для coding и agents
Используйте GPT-5.5 первой, если фактический route OpenAI-native: ChatGPT для analysis, Codex для repo work, terminal tasks, code review или workflow, где operator experience важен не меньше API. В этой ситуации вопрос звучит так: уменьшает ли GPT-5.5 review load и закрывает ли более сложные задачи внутри tools, которыми вы уже пользуетесь? На него можно отвечать сразу, потому что surface live.
Используйте Claude Opus 4.7 первой, если фактический route API-first, Claude-native или cloud-provider-first. Anthropic materials подчеркивают coding, agents, long context, high-resolution images и higher-effort control. Но важнее другое: route already deployable. Если вам нужен model behind server workflow, scheduled jobs, logs, permissions, rollout и rollback, этот contract важнее launch-day excitement вокруг coming-soon API.
Честный инженерный тест прост. Выберите десять задач, которые уже стоят вам review time. Запустите GPT-5.5 в OpenAI surface, где она live. Запустите Opus 4.7 через тот API или cloud route, который вы реально deploy. Оценивайте first-pass correctness, tool recovery, format stability, token use, latency, human review minutes и failure severity. Победитель должен снижать total work, а не просто выглядеть сильнее в demo.
Если тест состоит из repo edits, terminal tasks и OpenAI-native coding, GPT-5.5 заслуживает first seat. Если это production agent с explicit API budgets, cloud routing, long context и controlled rollout, Opus 4.7 заслуживает first seat.
Context, output и migration risk
Context и output limits становятся критичными, когда задача больше short chat. Claude Opus 4.7 имеет ясный live contract: 1M context window и 128k max output в Messages API. Anthropic pricing docs также указывают full 1M context at standard pricing, что важно, потому что secondary pages могут смешивать older long-context premium assumptions.
GPT-5.5 API context, rate limits, model ID, tool availability и billing behavior нужно перепроверять в момент, когда API доступен вашему account. До этого честная формулировка: planned API route или coming-soon API pricing, не deploy it today. Это не pedantry. Именно model IDs, context windows, rate limits, tools и billing behavior ломают production migrations.
У Opus 4.7 тоже есть migration hazards. Anthropic current docs говорят, что non-default sampling parameters such as temperature, top_p и top_k возвращают 400; old extended-thinking budget fields removed; newer tokenizer может использовать до примерно 35% more tokens for fixed text depending on content. Это не причины избегать Opus. Это причины тестировать настоящий harness, а не менять одну model string.
Для long-form coding agents, document review и production workflows решающий вопрос не "у кого больше context". Вопрос такой: какой route удерживает нужный context, генерирует нужный output, остается внутри cost limits и fails in ways your system can recover from.
Если вы уже используете GPT-5.4 или Opus 4.7
Если вы уже используете GPT-5.4 through API, не вырывайте ее только потому, что GPT-5.5 launched. GPT-5.5 является правильным OpenAI-native pilot, но GPT-5.4 остается deployable OpenAI API baseline, пока GPT-5.5 API route не live for your account. Если ваш выбор шире - OpenAI, Anthropic или Google route - соседнее сравнение Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro лучше покрывает tri-model decision.
Если вы уже используете Claude Opus 4.7, релиз GPT-5.5 должен запускать pilot, а не automatic replacement. Держите Opus 4.7 как deployable route, если API contract был причиной выбора. Затем сравните GPT-5.5 inside OpenAI live surfaces и решите, достаточно ли gains, чтобы вернуться к production route once API access is official.
Если реальный вопрос касается Anthropic-side migration, а не OpenAI-vs-Anthropic route selection, используйте более узкий guide Claude Opus 4.7 vs Claude Opus 4.6. Он лучше отвечает на same-family upgrade, prompt behavior и cost drift.
Практический план переключения
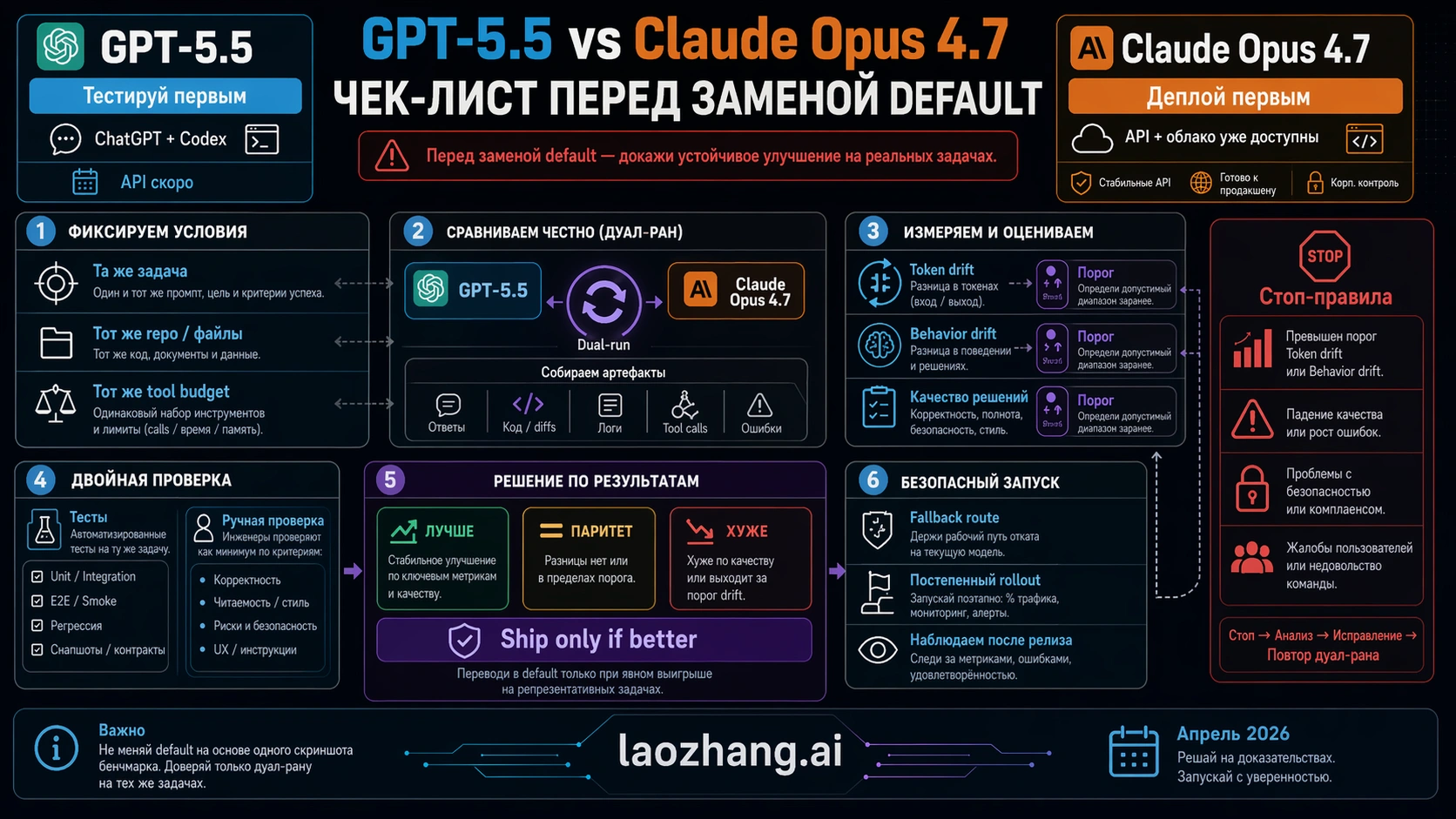
Model switch должен иметь release plan. Минимальный полезный план состоит из шести проверок.
| Проверка | Что делать | Pass condition |
|---|---|---|
| Route check | Подтвердить, live ли модель в нужной surface: ChatGPT, Codex, API или cloud. | Production plan не зависит от coming-soon endpoint. |
| Task set | Выбрать representative tasks, а не cherry-picked demos. | Есть easy, hard, long-context, output-format и failure-prone tasks. |
| Harness parity | Запустить обе модели с same prompts, tools, files и task budgets, где surface позволяет. | Difference comes from model behavior, not a better setup for one side. |
| Quality score | Track correctness, recovery, formatting и human review minutes. | Winner reduces total work, not just first-impression quality. |
| Cost score | Measure input, cached input, output, retries и task-level cost. | Chosen route affordable under real workload. |
| Rollback route | Keep old model или fallback route during rollout. | Failed migration can be reversed without rebuilding the pipeline. |
Для небольшой команды это может быть один день disciplined testing. Для enterprise workflow это лучше сделать staged rollout: private pilot, shadow run, limited production route, затем default switch. Порог одинаковый: не переключайтесь потому, что модель новая; переключайтесь только если она уменьшает failure, time или cost на работе, которую вы реально запускаете.
FAQ
GPT-5.5 лучше Claude Opus 4.7?
Это зависит от route и workload. GPT-5.5 лучше первой тестировать для OpenAI-native ChatGPT и Codex work. Claude Opus 4.7 лучше первой разворачивать, если нужен live API или cloud endpoint сегодня.
GPT-5.5 доступна в API?
На 24 апреля 2026 года OpenAI описывает GPT-5.5 API access как coming soon. Pricing page полезна для planning, но не является доказательством callable production endpoint today.
Какая модель дешевле?
Для live API deployment today более ясная цена у Opus 4.7: $5 input и $25 output за миллион tokens до cache, batch и regional adjustments. GPT-5.5 указана как coming soon по $5 input и $30 output, поэтому output-heavy jobs нужно пересчитать на реальных prompts после запуска API.
Какая модель лучше для coding agents?
GPT-5.5 стоит первой тестировать для Codex и OpenAI-native coding workflows. Opus 4.7 стоит первой тестировать для Claude API agents, cloud deployment, long-context agent loops и teams that need production endpoint now.
У Opus 4.7 все еще есть сильные стороны?
Да. Сегодня он выигрывает вопрос deployability для API и cloud routes, а также имеет ясный live contract вокруг 1M context, 128k output и availability across multiple platforms.
Стоит ли ждать GPT-5.5 API?
Ждите, если цель именно OpenAI API migration to GPT-5.5. Не ждите, если immediate need is production API route and Opus 4.7 already fits the job. Держите GPT-5.5 in pilot plan и перепроверяйте OpenAI docs when API goes live.
Что насчет GPT-5.5 Pro?
GPT-5.5 Pro - будущий higher-accuracy route с much higher listed API pricing. Для большинства команд это не default comparison today. Сначала докажите, что обычный GPT-5.5 или Opus 4.7 не закрывает задачу.
Используйте GPT-5.5 первой, когда работа живет внутри OpenAI live surfaces. Используйте Claude Opus 4.7 первой, когда нужен deployable API или cloud route прямо сейчас. Если на кону money или reliability, заставьте обе модели заслужить switch на одних и тех же задачах.