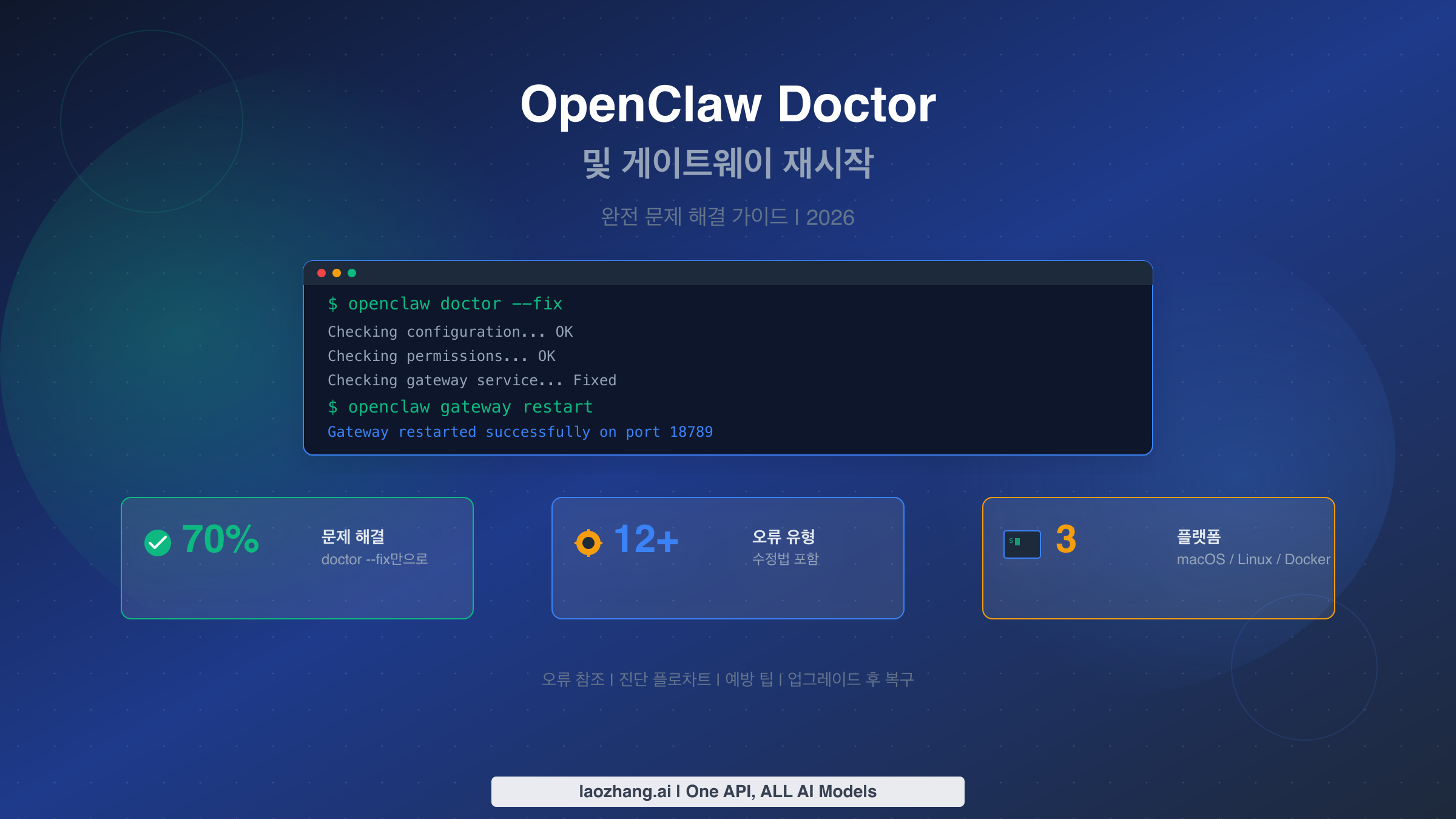
OpenClaw의 openclaw doctor --fix 명령어는 설정 드리프트를 점검하고 자동으로 복구하여 게이트웨이 문제의 약 70%를 해결합니다(ClawTank, 2026년 3월 커뮤니티 분석 기준). openclaw gateway restart와 결합하면 이 두 명령어가 OpenClaw 문제 해결의 기반을 형성합니다. 이 가이드는 발생할 수 있는 모든 오류 메시지, macOS, Linux, Docker 플랫폼별 수정법, 업그레이드 후 복구 절차, 예방적 유지보수 전략을 다루며 — 모두 2026년 3월 기준 공식 OpenClaw 문서를 기반으로 검증되었습니다.
핵심 요약
대부분의 OpenClaw 게이트웨이 문제를 해결하려면 다음 두 명령어를 실행하세요:
bashopenclaw doctor --fix openclaw gateway restart
이 조합은 게이트웨이 문제의 약 70%를 자동으로 해결합니다. 게이트웨이가 여전히 시작되지 않으면 openclaw gateway status를 실행하여 문제가 서비스 중지, RPC 프로브 실패, 설정 오류 중 어떤 것인지 확인한 후 아래 진단 플로차트를 따르세요. 가장 일반적인 근본 원인은 포트 충돌(45%), 서비스 미실행(30%), 설정 오류(15%)입니다.
게이트웨이 문제 70%를 해결하는 30초 수정법
OpenClaw 게이트웨이가 응답을 멈추면 본능적으로 로그 파일과 설정을 파헤치고 싶어집니다. 30초만 그 충동을 참으세요. 복구로 가는 가장 빠른 경로는 거의 항상 동일한 두 명령어 시퀀스이며, 이것이 왜 그렇게 잘 작동하는지 이해하면 앞으로 수 시간의 디버깅을 절약할 수 있습니다.
openclaw doctor --fix 명령어는 OpenClaw 설치의 포괄적인 점검을 수행합니다. 디렉토리 구조를 확인하고, 파일 권한을 검증하고, ~/.openclaw/openclaw.json 설정 파일의 유효성을 확인하며, 필요한 서비스가 올바르게 등록되어 있는지, 포트 바인딩이 선언된 설정과 일치하는지 확인합니다. 문제를 발견하면 — 일반적으로 실패하는 게이트웨이에는 한두 개의 잘못된 설정이 있습니다 — 자동으로 수정합니다. --fix 플래그가 이 명령어를 단순한 정보 제공이 아닌 강력한 도구로 만드는 핵심입니다. 이 플래그 없이는 doctor가 문제를 보고만 하고 해결하지 않습니다.
doctor 명령어에 이어 openclaw gateway restart를 실행하면 게이트웨이 프로세스가 방금 적용된 모든 수정 사항을 반영합니다. 재시작 시퀀스는 깔끔합니다: 기존 게이트웨이 프로세스를 정상적으로 중지하고(SIGTERM을 보낸 후 진행 중인 WebSocket 연결이 종료될 때까지 대기), 수정된 설정으로 새 인스턴스를 시작합니다. WhatsApp, Slack, Discord, Telegram 등 채널 연결은 잠시 끊어졌다가 몇 초 내에 자동으로 재연결됩니다.
이 두 명령어 접근법이 자주 효과가 있는 이유는 대부분의 게이트웨이 장애가 근본적인 시스템 문제가 아닌 설정 드리프트에서 발생하기 때문입니다. OpenClaw를 업데이트하거나, 새 플러그인을 설치하거나, 모델 설정을 변경하거나, 채널 설정을 수정할 때 작은 불일치가 누적될 수 있습니다. 권한이 강화되거나, 디렉토리가 아직 존재하지 않거나, 설정 키가 더 이상 사용되지 않는 스키마를 참조할 수 있습니다. doctor 명령어는 특히 이러한 드리프트 시나리오를 대상으로 하기 때문에 커뮤니티에서 이 접근법만으로 약 70%의 성공률을 보고합니다.
이 명령어를 실행한 후 게이트웨이가 성공적으로 시작되면 완료입니다. 시작되지 않으면 아래 진단 섹션으로 이동하여 구체적인 장애 모드를 확인하세요.
openclaw doctor와 gateway restart가 실제로 하는 일
이 명령어들의 작동 원리를 이해하면 문제 해결에서 미스터리가 사라지고, 각각을 독립적으로 사용할 시기를 판단하는 데 도움이 됩니다. 이 도구들은 상호 교환할 수 없으며 — 근본적으로 다른 목적을 수행합니다. 이 차이를 알면 불필요한 명령어를 실행하거나, 더 나쁘게는 실제로 필요한 명령어를 건너뛰는 것을 방지할 수 있습니다.
openclaw doctor 명령어는 설정 감사관으로 작동합니다. 실행하면 프로세스가 설치 디렉토리(일반적으로 ~/.openclaw/), 시스템 서비스 설정, 런타임 환경을 읽습니다. 각 구성 요소를 예상 조건 세트와 비교합니다: 설정 파일이 올바르게 파싱되는가? 참조된 모든 디렉토리가 존재하고 쓰기 가능한가? 게이트웨이 서비스가 올바른 바이너리 경로로 등록되어 있는가? 선언된 포트가 서비스 파일에서 지정한 것과 일치하는가? 각 검사는 통과, 경고 또는 실패를 생성합니다. --fix 플래그를 사용하면 실패 시 자동 수정 조치가 트리거됩니다 — 누락된 디렉토리 생성, 잘못된 서비스 파일 재작성, 파일 권한 재설정 등. --fix 없이는 수동으로 조치할 수 있는 진단 보고서를 받게 되는데, 무언가를 변경하기 전에 문제를 이해하고 싶을 때 때로는 더 나은 선택입니다.
반면에 openclaw gateway restart 명령어는 순수하게 서비스 생명주기 작업입니다. 설정을 검사하거나 복구하지 않습니다. 실행 중인 게이트웨이 프로세스에 중지 신호를 보내고, 종료될 때까지 대기하며(기본 타임아웃 60초), 새 프로세스를 시작합니다. 게이트웨이 실행 파일은 시작 시 ~/.openclaw/openclaw.json을 읽고, 설정된 포트(기본값 18789)에 바인딩하고, WebSocket 연결을 수락하기 시작합니다. 재시작 시점에 설정 파일에 오류가 있으면 새 프로세스가 시작되지 않습니다 — 이것이 바로 재시작 전에 doctor --fix를 실행하는 것이 효과적인 이유입니다.
이 맥락에서 언급할 가치가 있는 세 번째 명령어가 있습니다: openclaw gateway install --force. 이 명령어는 기존 서비스 정의를 덮어쓰면서 게이트웨이를 시스템 서비스(macOS의 LaunchAgent, Linux의 systemd 사용자 서비스)로 재등록합니다. 단순 재시작보다 더 공격적이며 서비스 등록 자체가 손상되었을 때 특히 유용합니다 — 운영체제 업데이트 후나 OpenClaw 버전 간 전환 시 가끔 발생하는 시나리오입니다. 변경된 OpenClaw API 키 설정으로 작업하는 경우 install --force 다음에 restart를 실행하면 서비스가 새 설정을 완전히 반영합니다.
한 가지 중요한 차이점: openclaw doctor는 일회성 진단 프로세스로 실행되고 종료됩니다. 반면 게이트웨이는 장기 실행 데몬입니다. doctor를 실행해도 현재 실행 중인 게이트웨이에 영향을 주지 않습니다 — 단, --fix 플래그가 게이트웨이가 의존하는 서비스 파일을 재작성한 경우에는 변경 사항을 적용하기 위해 재시작이 필요합니다.
60초 만에 문제 진단하기
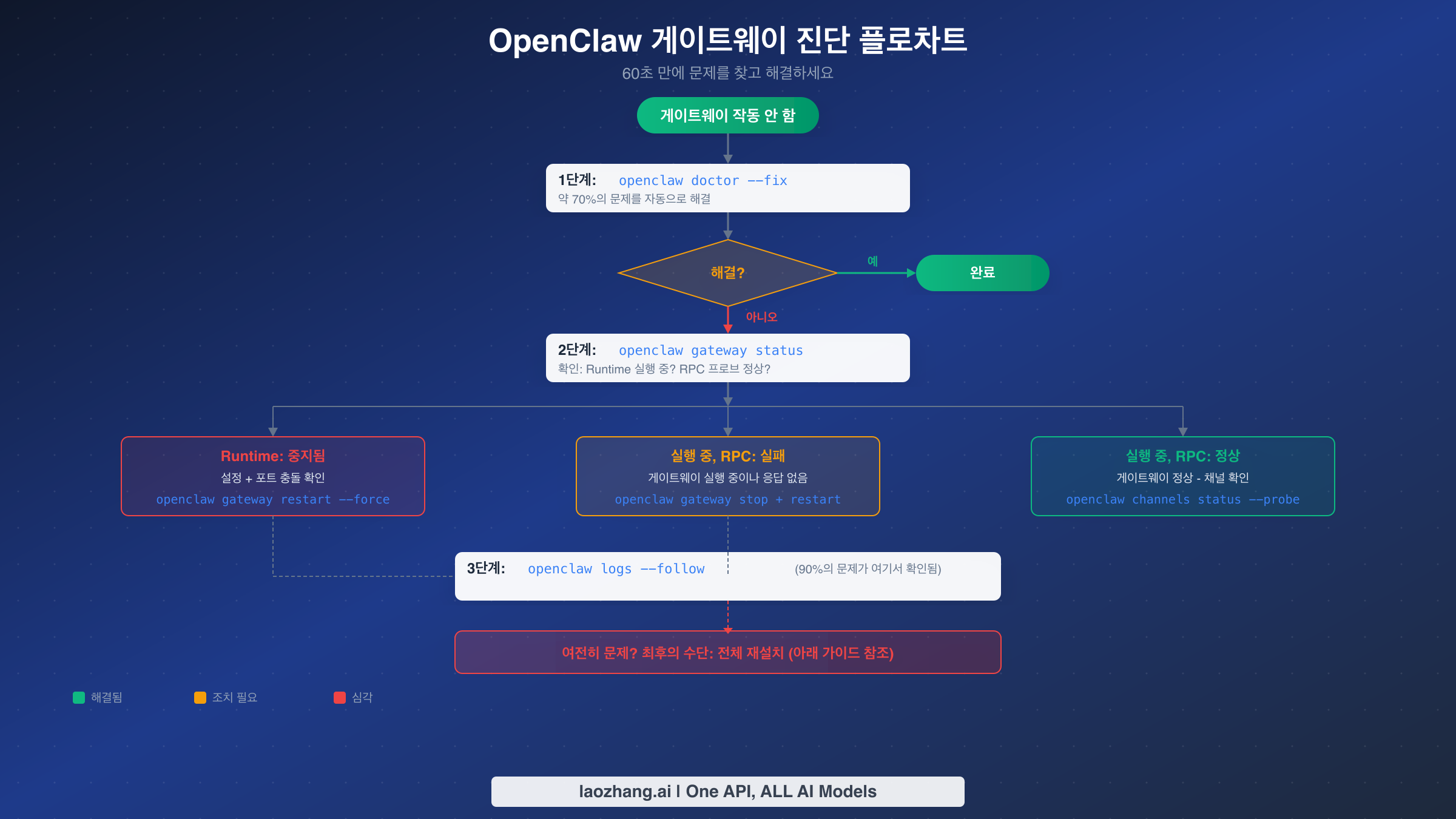
범용 수정법으로 문제가 해결되지 않는 경우 다음 단계는 실제로 무엇이 고장났는지 체계적으로 파악하는 것입니다. OpenClaw에 내장된 진단 명령어는 장애 모드를 직접 가리키는 구조화된 출력을 제공하므로 추측할 필요가 없습니다. 이 섹션에서는 정확한 명령어 시퀀스와 출력이 의미하는 바를 안내합니다.
openclaw gateway status부터 시작하세요. 이것은 문제 해결 도구 중 가장 유용한 단일 명령어입니다. 출력은 두 가지 핵심 정보를 알려줍니다: 게이트웨이 프로세스가 실행 중인지, 연결을 수락하고 있는지. 정상 게이트웨이는 Runtime: running과 RPC probe: ok를 표시합니다. 이 패턴에서 벗어나면 특정 문제 범주를 나타냅니다.
Runtime: stopped가 표시되면 게이트웨이 프로세스가 전혀 실행되고 있지 않습니다. 이는 일반적으로 서비스가 시작되지 못했거나(설정 오류 확인), 프로세스가 충돌했거나(로그에서 충돌 출력 확인), 서비스가 설치되지 않았음을 의미합니다. 가장 흔한 원인은 시작을 방해하는 설정 문제로, 로컬 전용 배포에서 gateway.mode가 local로 설정되지 않은 경우 등입니다. openclaw config get gateway.mode를 실행하여 이 설정을 확인하고, 값이 반환되지 않거나 local이 아닌 값이면 openclaw config set gateway.mode local로 설정하세요.
Runtime: running이지만 RPC probe: failed가 표시되면 게이트웨이 프로세스는 살아있지만 상태 확인에 응답하지 않는 것입니다. 이는 더 미묘한 문제로 보통 세 가지 중 하나를 나타냅니다: 게이트웨이가 아직 초기화 중이거나(60초를 기다리세요, 특히 Docker에서는 초기화에 약 40초 소요), 게이트웨이가 예상과 다른 포트에 바인딩되어 있거나(openclaw config get gateway.port 확인), 프로세스가 교착 상태에 빠져 있는 경우입니다. 마지막 시나리오의 해결책은 openclaw gateway stop --force 다음에 openclaw gateway start입니다.
게이트웨이 상태를 확인한 후 다음 진단 명령어는 openclaw logs --follow입니다. 이 명령어는 게이트웨이 로그 파일을 실시간으로 추적하며, 커뮤니티 보고에 따르면 남은 문제의 약 90%에서 근본 원인을 드러냅니다. 로그 항목은 타임스탬프가 찍히고 분류되어 있으므로 출력에서 ERROR 또는 FATAL로 표시된 항목을 찾으세요. 일반적인 패턴에는 권한 거부 오류(프로세스가 파일을 읽거나 포트에 바인딩할 수 없음), 연결 거부 오류(업스트림 서비스 또는 API 엔드포인트에 도달할 수 없음), 설정 유효성 검사 실패(필수 필드 누락 또는 잘못된 형식)가 포함됩니다.
게이트웨이가 실행 중이지만 메시지가 전달되지 않는 채널별 문제의 경우 openclaw channels status --probe를 사용하세요. 이 명령어는 설정된 각 채널의 연결을 독립적으로 테스트하고 어떤 것이 정상이고 어떤 것이 실패하는지 보고합니다. 모든 채널이 연결됨으로 표시되지만 메시지가 여전히 전달되지 않으면 게이트웨이 장애가 아닌 페어링 또는 멘션 설정 문제일 가능성이 높습니다 — DM 정책 설정과 그룹 멘션 패턴을 확인하세요.
모든 게이트웨이 오류와 해결 방법

이 섹션은 조회 테이블 역할을 합니다. 표시되는 오류 메시지를 찾고, 발생 원인을 이해하고, 대상화된 수정을 적용하세요. 각 항목에는 문제를 해결하기 위한 정확한 명령어와 성공적인 해결 후 예상되는 출력이 포함됩니다. 모든 수정법은 2026년 3월 기준 공식 OpenClaw 문서와 커뮤니티 보고를 기반으로 검증되었습니다.
"Gateway start blocked: set gateway.mode=local"
이것은 최초 설치 시 가장 흔한 오류입니다. OpenClaw의 게이트웨이는 운영 모드를 명시적으로 선언하지 않으면 시작을 거부합니다. 기본값은 잠재적으로 안전하지 않은 설정을 가정하는 대신 시작을 차단하는 것입니다. 해결하려면 openclaw config set gateway.mode local을 실행한 다음 openclaw gateway restart를 실행하세요. local 모드는 게이트웨이를 루프백 연결로만 제한하며, 단일 머신 배포에 적합합니다. 원격 접근이 필요한 경우 gateway.mode를 remote로 설정하고 openclaw config set gateway.auth.token YOUR_TOKEN으로 적절한 인증을 구성하세요.
"Timed out after 60s waiting for gateway port 18789 to become healthy"
게이트웨이 프로세스가 시작되었지만 기본 60초 창 내에 연결을 수락하기 시작하지 않았습니다. 리소스가 제한된 시스템 — 특히 소규모 VPS 인스턴스의 Docker 컨테이너 — 에서는 초기화에 실제로 60초 이상 걸릴 수 있습니다. 먼저 프로세스가 아직 시작 중인지 아니면 초기화 중에 충돌했는지 확인하세요. 이 오류를 확인한 직후 openclaw gateway status를 실행하세요. 런타임이 running으로 표시되면 30-60초를 더 기다린 후 다시 확인하세요. stopped로 표시되면 openclaw logs --follow로 구체적인 시작 실패를 확인하세요. Docker 배포에서는 컨테이너 초기화만 약 40초가 소요되어 게이트웨이 시작에 20초만 남게 됩니다 — 1-vCPU 머신에서는 빠듯합니다. VPS에 1GB 스왑 공간을 추가하면 이런 타임아웃 문제를 영구적으로 해결하는 경우가 많습니다.
"Another gateway instance is already listening on port 18789"
포트 충돌은 두 프로세스가 동일한 포트에 바인딩하려 할 때 발생합니다. 이전 Clawdbot 네이밍에서 OpenClaw로 업그레이드한 후 가장 자주 발생하며, 레거시 clawdbot-gateway 서비스가 새 openclaw-gateway 서비스와 함께 실행될 수 있습니다. 충돌하는 프로세스를 식별하려면 lsof -i :18789 (macOS/Linux) 또는 ss -tlnp | grep 18789 (Linux)를 실행하세요. 이전 프로세스를 종료한 다음 재시작하세요: openclaw gateway restart. 재발을 방지하려면 이전 서비스가 완전히 제거되었는지 확인하세요: Linux에서는 systemctl --user disable clawdbot-gateway.service && systemctl --user stop clawdbot-gateway.service, macOS에서는 ~/Library/LaunchAgents/에서 이전 LaunchAgent plist를 제거하세요.
"Refusing to bind gateway on 0.0.0.0 without auth"
OpenClaw는 무단 접근을 방지하기 위해 인증 없는 비-루프백 바인딩을 올바르게 차단합니다. 의도적으로 다른 머신에서 게이트웨이에 접근하려는 경우(대시보드 또는 모바일 클라이언트를 통한 원격 접근) 먼저 인증을 설정해야 합니다: openclaw config set gateway.auth.mode token 다음에 openclaw config set gateway.auth.token YOUR_SECURE_TOKEN. 로컬에서 실행 중이고 원격 접근이 필요하지 않은 경우 바인딩을 루프백으로만 설정하세요: openclaw config set gateway.bind loopback.
"AUTH_DEVICE_TOKEN_MISMATCH" 또는 "PAIRING_REQUIRED"
게이트웨이 재시작 후 기존 클라이언트 연결이 디바이스 페어링을 잃을 수 있습니다. 이는 GitHub Issue #22062에 문서화된 알려진 문제입니다. 해결 방법은 간단합니다: 이 오류가 표시되는 각 클라이언트에서 페어링 플로를 다시 수행하세요. CLI 클라이언트의 경우 openclaw pair를 사용하세요. 웹 대시보드의 경우 페어링 페이지로 이동하여 QR 코드를 스캔하세요. 계획된 재시작 중 페어링 중단을 최소화하려면 디바이스별 토큰 교체를 피하는 gateway.auth.mode password 옵션 사용을 고려하세요.
"HTTP 429: rate_limit_error: Extra usage is required for long context requests"
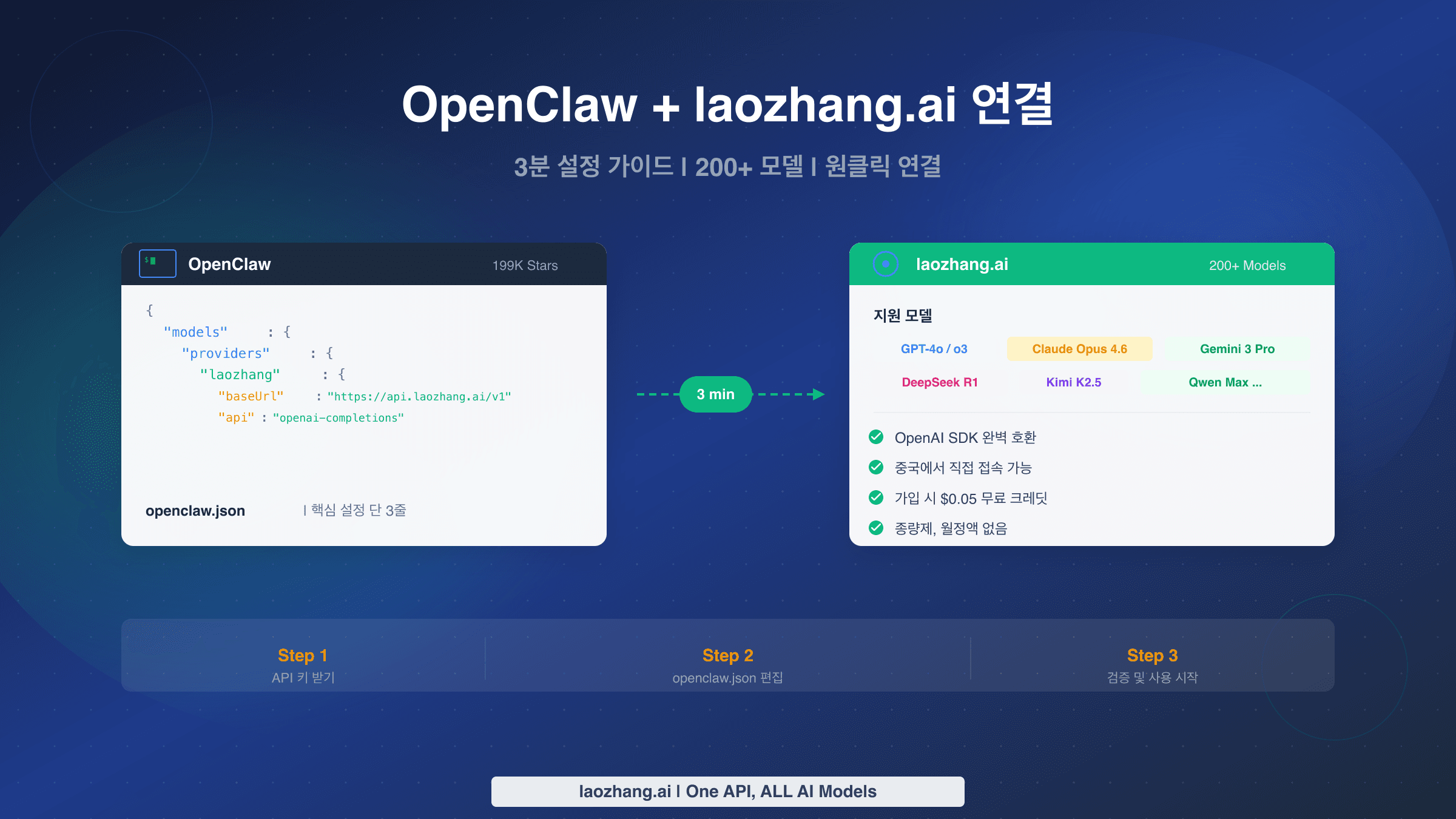
이 오류는 OpenClaw 자체가 아닌 업스트림 Anthropic API에서 발생합니다. 사용 중인 모델에서 params.context1m: true가 활성화되어 있지만 API 키가 긴 컨텍스트 접근 권한이 없을 때 나타납니다. 확장된 컨텍스트 창을 비활성화하거나(openclaw config set agents.defaults.models.context1m false) Anthropic API 키에 긴 컨텍스트 자격이 있는 활성 결제가 있는지 확인하여 해결하세요. 개별 프로바이더 키를 관리하지 않고 안정적인 API 접근이 필요한 경우, 프로바이더 로테이션을 처리하고 속도 제한 노출을 줄이는 laozhang.ai와 같은 통합 API 서비스 사용을 고려하세요 — 전체 설정 과정은 OpenClaw과 laozhang.ai 통합 가이드에서 확인할 수 있습니다. OpenClaw 429 속도 제한 오류 해결에 대한 자세한 내용은 전용 문제 해결 문서를 참조하세요.
"NODE_BACKGROUND_UNAVAILABLE" 또는 "SYSTEM_RUN_DENIED"
이러한 오류는 게이트웨이가 실행 중이지만 OpenClaw의 노드 도구(브라우저 자동화, 시스템 명령)가 실행되지 않음을 나타냅니다. openclaw nodes status로 노드 상태를 확인하세요. 노드가 오프라인이면 재시작하세요. 온라인이지만 권한이 거부되면 노드의 도구 허용 목록과 OS 수준 권한(macOS에서 카메라, 마이크, 화면 접근은 시스템 환경설정에서 명시적 허가 필요)을 검토하세요.
플랫폼별 수정법 (macOS, Linux, Docker)

핵심 문제 해결 명령어는 플랫폼 간에 동일하지만, 서비스 관리 계층은 macOS, Linux, Docker 간에 크게 다릅니다. Linux에서 완벽하게 작동하는 명령어가 macOS에서 조용히 실패할 수 있으며, Docker 배포에는 컨테이너 생명주기 관리와 관련된 고유한 제약이 있습니다. 이 섹션에서는 일반적인 문제 해결 가이드에서 종종 간과하는 플랫폼별 뉘앙스를 다룹니다.
macOS (LaunchAgent)
macOS에서 OpenClaw 게이트웨이는 LaunchAgent로 실행됩니다 — launchd가 관리하는 사용자별 백그라운드 서비스입니다. 서비스 정의는 ~/Library/LaunchAgents/com.openclaw.gateway.plist에 있습니다. macOS에서 openclaw gateway restart가 실패하는 가장 흔한 원인은 중지 단계 이후 LaunchAgent가 제대로 재등록되지 않는 것입니다. 이는 GitHub Issue #42775에 문서화된 알려진 문제로, 재시작 명령어가 게이트웨이를 성공적으로 중지하지만 launchctl이 서비스를 재부트스트랩하지 않아 다시 시작하지 못합니다.
신뢰할 수 있는 해결 방법은 실패한 재시작 후 openclaw gateway install --force를 사용하는 것입니다. 이 명령어는 plist 파일을 재생성하고 launchd에 명시적으로 로드하여 재등록 문제를 우회합니다. 이것마저 실패하면 수동으로 에이전트를 언로드하고 다시 로드하세요: launchctl bootout gui/$(id -u)/com.openclaw.gateway 다음에 launchctl bootstrap gui/$(id -u) ~/Library/LaunchAgents/com.openclaw.gateway.plist.
macOS의 게이트웨이 로그는 ~/Library/Logs/openclaw/에 기록되며 Console.app에서 "openclaw" 프로세스를 필터링하여 볼 수도 있습니다. 실시간 로그 모니터링에는 openclaw logs --follow가 가장 편리한 옵션입니다.
Linux (systemd)
Linux 배포는 systemd 사용자 서비스를 사용합니다. 서비스 파일은 일반적으로 ~/.config/systemd/user/openclaw-gateway.service에 있습니다. Linux에서 가장 중요한 고려 사항은 lingering을 활성화하는 것으로, 사용자가 로그아웃한 후에도 사용자 서비스가 지속되도록 합니다. lingering 없이는 SSH 세션이 종료될 때마다 게이트웨이가 중지됩니다. loginctl enable-linger $USER로 활성화하세요.
제한된 메모리(1GB 이하)를 가진 VPS 배포의 경우 피크 로드 시 OOM(Out of Memory) 킬러에 의해 게이트웨이가 종료될 수 있습니다. 스왑 공간을 추가하면 이를 방지합니다: sudo fallocate -l 1G /swapfile && sudo chmod 600 /swapfile && sudo mkswap /swapfile && sudo swapon /swapfile. /etc/fstab에 /swapfile none swap sw 0 0을 추가하여 스왑을 영구적으로 만드세요.
Linux에서 게이트웨이 로그를 보려면 실시간 모니터링에 journalctl --user -u openclaw-gateway -f를 사용하거나, 동일한 기본 메커니즘을 래핑하는 openclaw logs --follow를 사용하세요.
Docker
Docker 배포는 네이티브 설치에 존재하지 않는 컨테이너 생명주기 고려 사항을 도입합니다. 가장 중요한 차이점은 openclaw doctor를 호스트가 아닌 컨테이너 내부에서 실행해야 한다는 것입니다. docker exec -it CONTAINER_NAME openclaw doctor --fix를 사용하세요. 여기서 CONTAINER_NAME은 게이트웨이 컨테이너의 이름입니다(docker ps로 확인).
재시작은 openclaw gateway restart 명령어가 아닌 Docker Compose를 통해 처리됩니다: docker compose restart openclaw-gateway. 컨테이너 상태도 초기화하는 더 철저한 재시작의 경우 docker compose up -d --force-recreate openclaw-gateway를 사용하세요. 컨테이너 초기화가 게이트웨이 자체 시작 시간 위에 약 40초의 오버헤드를 추가하므로 Docker 배포에서 타임아웃이 더 흔합니다.
Docker 환경의 설정은 일반적으로 ~/.openclaw/openclaw.json이 아닌 .env 파일과 docker-compose.yml에 있습니다. 문제 해결 시 호스트 수준 Docker 설정과 컨테이너 내부 OpenClaw 설정 모두 일관성을 확인하세요.
업그레이드 후 게이트웨이 장애
OpenClaw 업그레이드는 표준 doctor --fix 시퀀스로 완전히 해결할 수 없는 게이트웨이 장애의 가장 일반적인 트리거입니다. 이는 업그레이드가 서비스 등록 경로, 설정 스키마, 인증 메커니즘을 변경할 수 있기 때문이며 — 설정 드리프트가 아닌 의도적인 설계 변경을 포함하므로 doctor 명령어가 자동 수정하지 못할 수 있습니다.
업그레이드 후 가장 자주 보고되는 문제는 이중 서비스 충돌입니다. OpenClaw가 "Clawdbot" 브랜딩에서 "OpenClaw"로 전환했을 때 설치 프로그램이 기존 서비스와 함께 새 서비스를 생성했습니다. 두 서비스가 모두 포트 18789에 바인딩을 시도하여 각각이 포트가 이미 사용 중이어서 반복적으로 실패하는 재시작 루프를 유발합니다. 해결책은 새 서비스를 시작하기 전에 이전 서비스를 완전히 제거하는 것입니다. Linux에서: systemctl --user stop clawdbot-gateway.service && systemctl --user disable clawdbot-gateway.service. macOS에서: 이전 LaunchAgent를 중지하고 ~/Library/LaunchAgents/에서 plist 파일을 삭제하세요.
업그레이드 후 또 다른 일반적인 문제는 설정 스키마 변경입니다. 새 버전의 OpenClaw는 설정 키를 더 이상 사용하지 않거나 예상 형식을 변경할 수 있습니다. 게이트웨이는 시작 시 설정의 유효성을 검사하고 알 수 없거나 잘못된 형식의 키를 만나면 실행을 거부합니다. openclaw config validate를 실행하여 더 이상 사용되지 않는 설정을 확인하세요. 출력은 각 문제가 있는 키와 권장 대체 항목을 나열합니다. 필요한 변경을 한 후 게이트웨이를 재시작하세요.
업그레이드 후 인증 변경도 기존 클라이언트 연결을 끊을 수 있습니다. 업그레이드가 인증 메커니즘을 수정한 경우(예: 단순한 gateway.token에서 새로운 gateway.auth.token 구조로 마이그레이션) 연결된 모든 클라이언트가 재인증해야 합니다. 이는 클라이언트 측에서 AUTH_TOKEN_MISMATCH 오류로 나타납니다. 원격 클라이언트를 새 토큰 형식으로 업데이트한 다음 게이트웨이를 재시작하세요.
대부분의 이러한 문제를 피하는 가장 안전한 업그레이드 절차는 업그레이드 전 체크리스트를 따르는 것입니다: 업그레이드 전에 게이트웨이를 중지하고(openclaw gateway stop), 업그레이드를 실행하고, openclaw doctor --fix를 실행하여 필요한 마이그레이션을 적용하고, 마지막으로 게이트웨이를 시작하세요(openclaw gateway start). 이 시퀀스는 게이트웨이가 설정을 파싱하기 전에 doctor 명령어가 스키마 마이그레이션을 수정할 기회를 제공합니다.
게이트웨이 문제를 사전에 예방하기
가장 효율적인 문제 해결은 결코 필요 없는 문제 해결입니다. OpenClaw 게이트웨이의 예방적 유지보수는 간단하며 주당 5분 미만이 소요되지만, 대부분의 운영자는 문제가 발생할 때만 게이트웨이 설정을 다룹니다. 간단한 모니터링 루틴을 구현하면 예상치 못한 장애의 대다수를 제거할 수 있습니다.
예방적 유지보수의 기반은 상태 확인 명령어입니다: openclaw gateway status. 이 명령어를 매일 실행하거나 — 더 좋게는 자동으로 실행되도록 스크립트를 작성하여 출력이 예상되는 Runtime: running, RPC probe: ok 패턴에서 벗어날 때 알려주도록 설정하세요. openclaw gateway status | grep -q "RPC probe: ok" || echo "Gateway unhealthy" | mail -s "OpenClaw Alert" you@example.com을 실행하는 간단한 cron 작업으로 외부 도구 없이 기본 모니터링을 제공할 수 있습니다.
설정 검증은 OpenClaw 설정을 변경할 때마다 실행해야 합니다. openclaw config validate 명령어는 런타임 장애가 발생하기 전에 문제를 잡아내며, 이는 새벽 2시에 봇이 응답을 멈출 때 오타를 발견하는 것보다 훨씬 낫습니다. 습관으로 만드세요: 설정 변경, 검증, 재시작.
디스크 공간은 게이트웨이 장애에서 종종 간과되는 원인입니다. 게이트웨이는 지속적으로 로그를 작성하며, 소규모 VPS 인스턴스에서는 로그 파일이 몇 주 내에 사용 가능한 모든 디스크 공간을 소비할 수 있습니다. 설정에서 gateway.logs.maxFiles와 gateway.logs.maxSize를 설정하여 로그 로테이션을 구성하거나, 시스템의 내장 로그 로테이션(Linux의 logrotate, macOS의 newsyslog)을 사용하세요.
OpenClaw 설치를 최신 상태로 유지하되 의도적으로 하세요. 프로덕션에서는 최신 릴리스를 추적하는 대신 특정 버전에 고정하세요. 업그레이드 시 이전 섹션의 업그레이드 전 체크리스트를 따르세요: 중지, 업그레이드, doctor, 시작. OpenClaw 릴리스 노트를 구독하면 호환성을 깨는 변경 사항이 배포에 영향을 미치기 전에 알 수 있습니다. OpenClaw 설정의 비용 효율적인 운영을 위해서는 OpenClaw 비용 최적화 가이드에서 실용적인 전략을 확인하세요.
아무것도 작동하지 않을 때 — 최후의 수단
모든 진단 단계를 거치고 관련된 모든 수정을 적용했는데도 게이트웨이가 여전히 협조하지 않으면 클린 재설치가 마지막 옵션입니다. 설정을 초기화하므로 최후의 수단이지만 알려진 정상 상태를 보장합니다. 진행하기 전에 설정을 백업하세요: cp -r ~/.openclaw ~/.openclaw.backup.
최후의 수단 절차는 다음과 같습니다:
bashopenclaw gateway stop --force # 2. 서비스 제거 openclaw gateway uninstall # 3. 설정 디렉토리 제거 rm -rf ~/.openclaw # 4. OpenClaw 재설치 (패키지 관리자 또는 공식 설치 프로그램 사용) # npm의 경우: npm install -g openclaw # brew의 경우: brew install openclaw # 5. 초기 설정 실행 openclaw init # 6. 설정 복원 (전체 디렉토리가 아닌 선택적으로) # ~/.openclaw.backup/openclaw.json에서 특정 설정을 복사 # 7. 게이트웨이 설치 및 시작 openclaw gateway install openclaw gateway start
클린 재설치 후 백업된 설정을 참조하여 채널, API 키, 모델 설정을 처음부터 다시 구성하세요. 이전 설정 파일을 새 파일 위에 단순히 복사하지 마세요 — 이전 파일에 장애를 유발한 바로 그 문제가 포함되어 있을 수 있습니다. 대신 완전한 OpenClaw 설치 가이드를 참조하여 각 구성 요소를 깔끔하게 설정하세요.
FAQ
openclaw gateway restart가 메시지 손실을 유발하나요?
재시작 창(일반적으로 3-5초) 동안 들어오는 메시지는 채널 프로바이더(WhatsApp, Slack 등)에 의해 버퍼링되고 게이트웨이가 재연결되면 전달됩니다. 메시지가 영구적으로 손실되지는 않지만 짧은 지연이 있을 수 있습니다. 계획된 재시작의 경우 트래픽이 적은 시간에 예약하는 것을 고려하세요.
openclaw restart와 openclaw gateway restart의 차이점은 무엇인가요?
openclaw restart 명령어는 모든 노드와 서비스를 포함한 전체 OpenClaw 스택을 재시작합니다. openclaw gateway restart 명령어는 게이트웨이 프로세스만 재시작합니다. 게이트웨이 관련 문제를 해결할 때는 다른 구성 요소에 대한 중단을 최소화하기 위해 openclaw gateway restart를 사용하세요.
게이트웨이가 실행 중일 때 openclaw doctor를 실행할 수 있나요?
네. doctor 명령어는 실행 중인 게이트웨이 프로세스를 수정하지 않고 설정 파일을 읽고 시스템 상태를 확인하는 진단 도구입니다. 그러나 --fix를 사용하고 doctor가 서비스 정의를 재작성한 경우 변경 사항을 적용하기 위해 게이트웨이를 재시작해야 합니다.
게이트웨이를 얼마나 자주 재시작해야 하나요?
정상 운영에서 게이트웨이는 정기적인 재시작이 필요하지 않습니다. 지속적으로 실행되도록 설계되었습니다. 설정 변경, 업데이트 또는 문제 해결 시에만 재시작하세요. 자주 재시작해야 하는 경우 재시작을 임시방편으로 취급하기보다 근본 원인을 조사하세요.
macOS에서 openclaw gateway restart가 조용히 실패하는 이유는 무엇인가요?
이는 macOS LaunchAgent가 중지 단계 이후 제대로 재등록되지 않는 알려진 문제입니다(GitHub #42775). 신뢰할 수 있는 대안으로 openclaw gateway install --force 다음에 openclaw gateway start를 사용하세요.