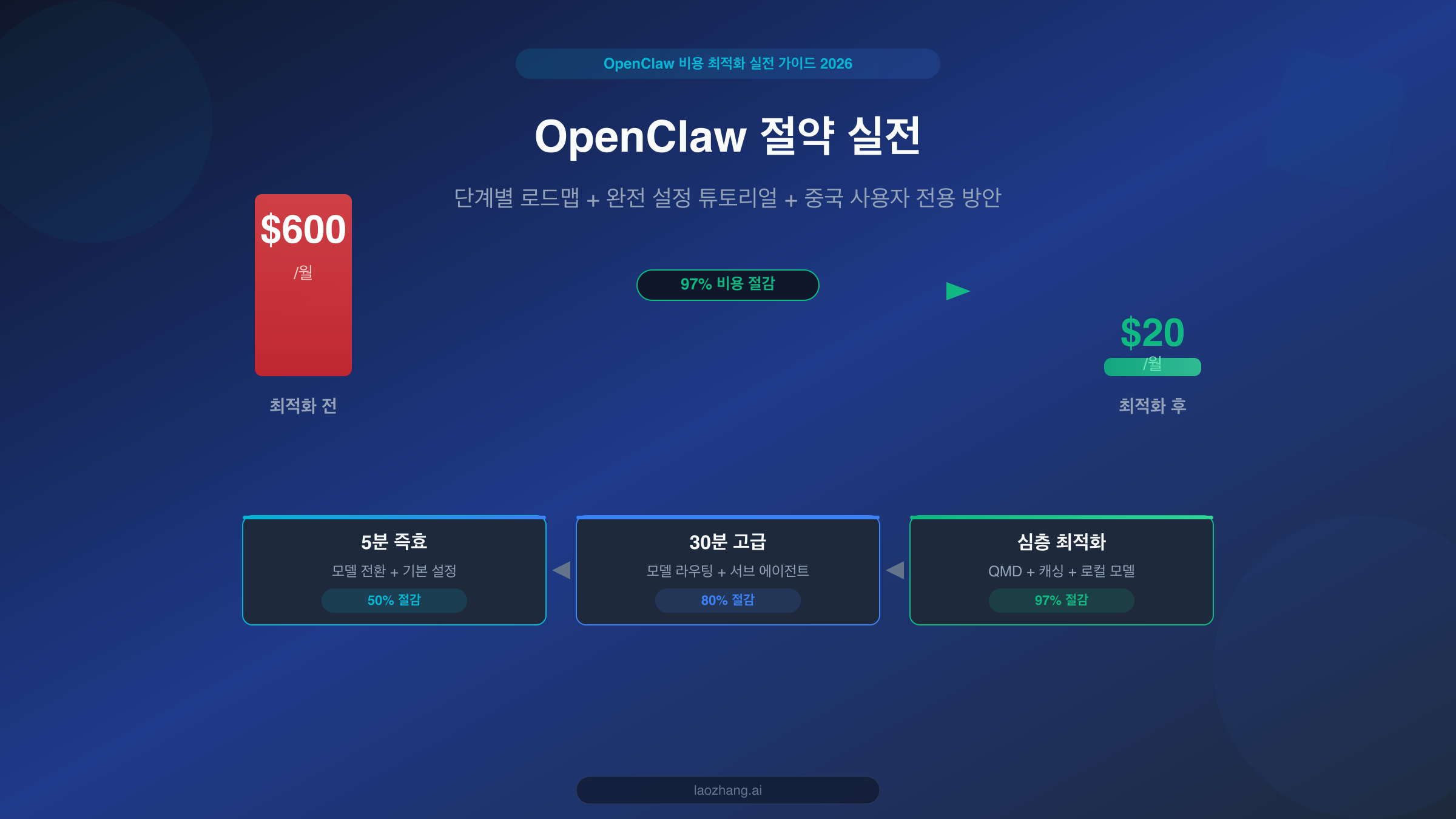
OpenClaw는 현재 가장 강력한 오픈소스 개인 AI 어시스턴트 플랫폼 중 하나이지만, 아무런 최적화 없이 사용하면 월간 API 요금이 $300-600에 달할 수 있습니다. 다행히도 이 글에서 소개하는 3단계 최적화 방법을 적용하면, 핵심 기능을 유지하면서도 월 비용을 $20 이하로 줄일 수 있습니다. 이것은 단순한 이론이 아닌 실제 검증된 방법입니다. 5분 만에 효과를 볼 수 있는 모델 전환부터 QMD 로컬 검색을 활용한 심층 최적화까지, 모든 단계에 구체적인 설정과 실제 데이터가 뒷받침됩니다.
실제 OpenClaw 요금 청구서 이야기
많은 사람들이 처음 OpenClaw를 접하면 그 강력한 기능에 깊은 인상을 받습니다. 코드 작성, 문서 분석, 일정 관리는 물론이고 Discord, Telegram 등 12개 이상의 플랫폼을 통해 대화할 수 있습니다. 문제는 신나게 일주일 정도 사용한 후 API 청구서를 열어보면 충격을 받을 수 있다는 것입니다. 일주일 사용료만 $100을 넘기는 경우가 적지 않습니다.
이것은 특별한 사례가 아닙니다. Reddit의 r/OpenClaw 커뮤니티, 각종 기술 포럼에서 "OpenClaw 비용이 너무 많이 나온다"는 질문은 가장 자주 등장하는 주제 중 하나입니다. 커뮤니티 피드백과 여러 기술 문서의 통계 데이터에 따르면, 최적화하지 않은 OpenClaw의 월간 API 비용은 보통 $300-600 사이이며, 헤비 유저의 경우 $1000을 넘기기도 합니다. 이런 수치의 원인은 사실 복잡하지 않지만, 대부분의 사용자는 처음 사용할 때 토큰 과금 메커니즘을 제대로 이해하지 못하고, 기본 설정에서 얼마나 많은 "숨겨진 비용"이 예산을 소모하고 있는지 알지 못합니다.
전형적인 시나리오 하나를 통해 문제의 심각성을 설명하겠습니다. OpenClaw의 기본 모델인 Claude Opus 4.6을 사용해 일상적인 개발 보조 업무를 수행한다고 가정해봅시다. 하루에 약 20회의 대화를 진행하고, 각 대화는 평균 5000개의 토큰 컨텍스트와 2000개의 토큰 모델 응답을 포함합니다. Anthropic 공식 가격(입력 $5/MTok, 출력 $25/MTok, 2026년 3월 기준)으로 계산하면, 하루 API 비용은 입력 비용 20 x 5000 / 1M x $5 = $0.5, 출력 비용 20 x 2000 / 1M x $25 = $1.0, 합계 $1.5/일입니다. 얼핏 보면 많지 않아 보이지만, OpenClaw의 대화는 컨텍스트가 누적된다는 것이 문제입니다. 10번째 대화에서는 이전 9번의 대화 내용을 모두 컨텍스트로 다시 전송하므로, 실제 소모되는 토큰 양이 기하급수적으로 증가합니다. 도구 호출, 시스템 프롬프트 등의 추가 비용까지 합치면, 실제 일일 비용은 이론적 수치의 5-10배에 달해 하루 $10-20을 쉽게 넘깁니다.
좋은 소식은 이 문제를 완벽하게 해결할 수 있다는 것입니다. 이 글에서는 검증된 3단계 최적화 방법을 공유합니다. 1단계는 5분 만에 비용의 50%를 절감할 수 있고, 2단계는 30분간의 모델 라우팅 설정으로 80%까지 절감하며, 3단계는 QMD 로컬 검색과 캐싱 전략을 통해 97%의 극한 비용 최적화를 달성합니다. 먼저 "돈이 도대체 어디에 쓰이는지"부터 알아보겠습니다.
비용은 어디에 쓰이는가? 토큰 소모 완전 분석
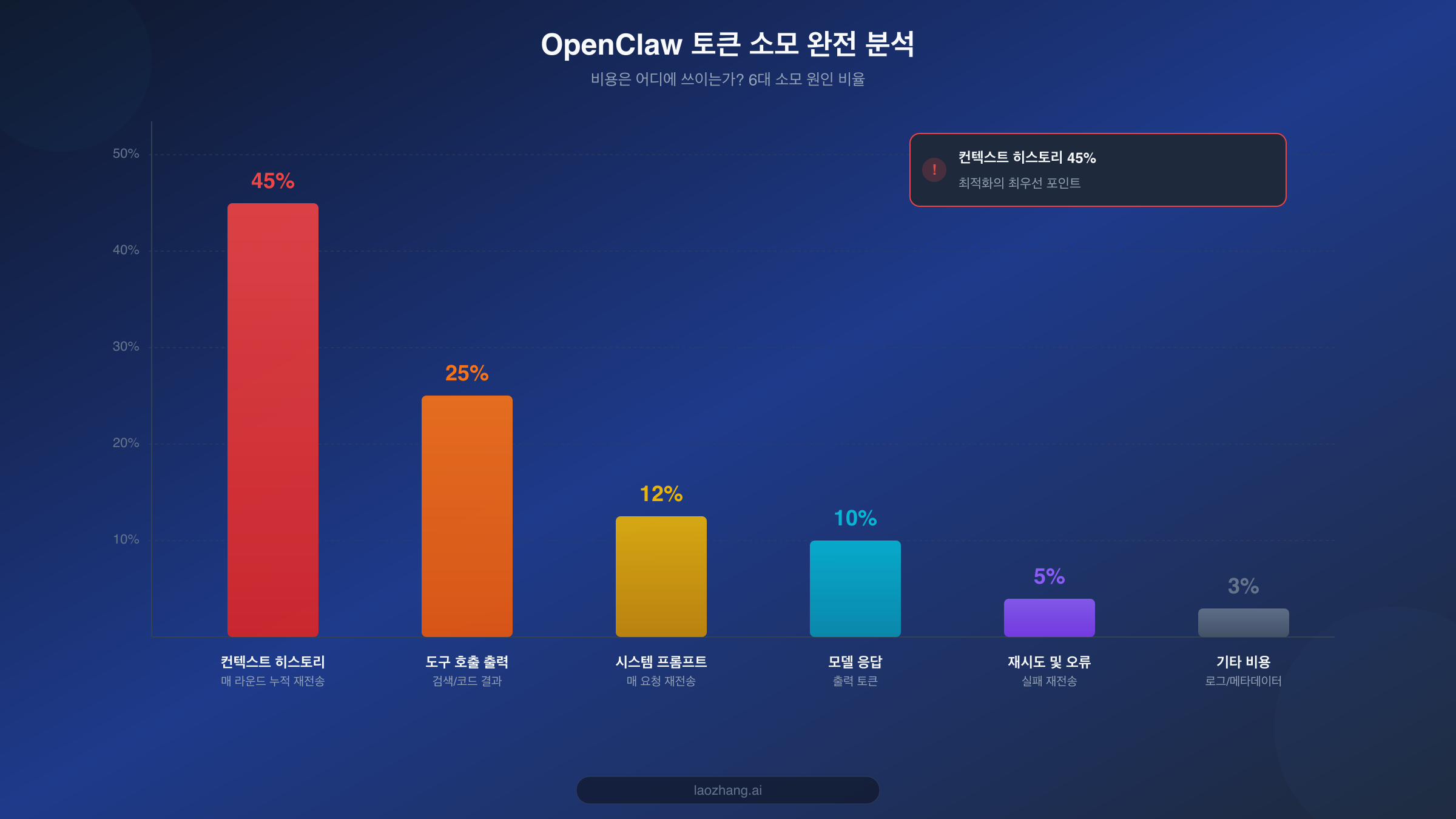
최적화에 착수하기 전에, 토큰 소모 구조를 이해하는 것이 매우 중요한 첫 번째 단계입니다. 많은 사용자들이 API 비용이 주로 모델의 응답에서 발생한다고 생각하지만, 실제로는 정반대입니다. 입력 토큰(모델에 보내는 내용)이 가장 큰 비용 요인이며, 그중에서도 가장 큰 비중을 차지하는 것은 여러분이 전혀 인식하지 못하고 있을 수 있는 "컨텍스트 히스토리"입니다.
여러 SERP 문서 분석과 커뮤니티 피드백에 따르면, OpenClaw의 토큰 소모는 크게 6가지 카테고리로 나눌 수 있습니다. 첫 번째는 컨텍스트 히스토리로, 전체 소모의 40-50%를 차지합니다. OpenClaw는 매 대화마다 이전의 모든 대화 내용을 컨텍스트로 모델에 전송합니다. 이는 20번째 대화의 입력 토큰 양이 1번째 대화의 20배라는 의미입니다. 이런 누적 효과가 비용 급등의 가장 핵심적인 원인입니다. OpenClaw가 긴 문서 처리나 복잡한 다단계 작업을 수행하도록 설정되어 있다면, 컨텍스트 길이가 100K 토큰을 쉽게 넘을 수 있으며, Claude Opus 4.6의 입력 가격 $5/MTok으로 계산하면 한 번의 요청에서 컨텍스트 비용만 $0.5 이상이 될 수 있습니다.
두 번째는 도구 호출 출력으로, 20-30%를 차지합니다. OpenClaw는 웹 검색, 코드 실행, 파일 작업 등 풍부한 도구 통합을 지원합니다. 각 도구 호출의 반환 결과는 토큰으로 대화 컨텍스트에 주입되며, 웹 검색 같은 도구는 한 번의 호출로 수천에서 수만 개의 토큰을 반환할 수 있습니다. 더 중요한 것은, 이러한 도구 출력이 한번 컨텍스트에 들어가면 이후의 모든 대화에서 반복적으로 전송되어 지속적인 비용 누적을 유발한다는 것입니다. 토큰 관리의 기술적 세부사항에 대해 더 자세히 알고 싶다면, 토큰 관리 완전 가이드를 참고하시기 바랍니다.
세 번째로 큰 소모 항목은 시스템 프롬프트로, 10-15%를 차지합니다. OpenClaw의 시스템 프롬프트는 보통 꽤 길어서(1000-3000 토큰) 페르소나 설정, 기능 설명, 사용 규칙 등의 내용을 포함합니다. 이 토큰은 매 API 요청마다 다시 전송되므로, 장기적으로 보면 상당한 비용이 됩니다. 네 번째는 모델 응답 자체로, 8-12%를 차지하며 출력 토큰에 해당합니다. 주목할 점은 대부분의 모델에서 출력 토큰 가격이 입력 가격의 3-5배라는 것입니다(예: Opus의 입력 $5/MTok vs 출력 $25/MTok). 비율은 높지 않지만 단가가 비쌉니다. 다섯 번째는 재시도와 오류 처리로 3-5%를 차지합니다. 모델 응답이 기대에 미치지 못하거나 도구 호출이 실패할 때 OpenClaw가 자동으로 재시도하며, 이 추가 요청들도 비용이 발생합니다. 마지막으로 기타 항목(로그, 메타데이터 등)이 약 3%를 차지합니다.
이 6가지 소모 원인을 이해했다면, 최적화 방향이 매우 명확해집니다. 먼저 컨텍스트 누적이라는 가장 큰 "비용 잡아먹는 괴물"을 해결하고, 모델 선택을 통해 토큰당 단가를 낮추며, 마지막으로 QMD 등의 기술 수단을 활용해 근본적으로 토큰 사용량을 줄이면 됩니다.
5분 즉효 최적화: 즉시 50% 절감
5분만 투자해서 바로 효과를 보고 싶다면, 기본 모델을 Claude Opus에서 Claude Haiku로 전환하는 것입니다. 이 한 가지 작업만으로 API 비용을 50-80% 줄일 수 있으며, 일상적인 사용 시나리오의 80%에서는 성능 차이를 거의 느낄 수 없습니다.
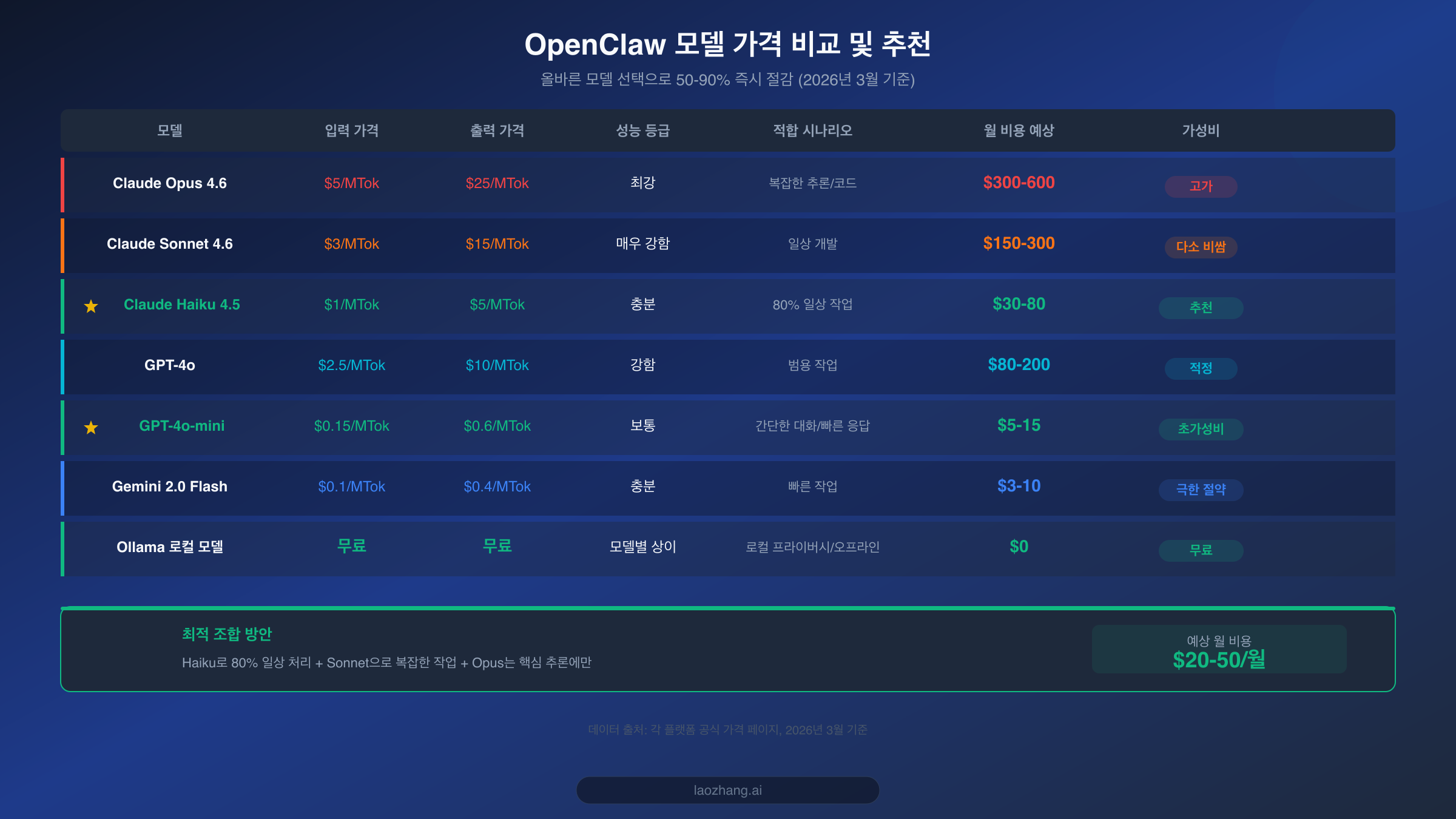
OpenClaw의 기본 설정은 보통 가장 강력한 모델(Claude Opus 4.6이나 GPT-4o 등)을 사용하지만, 대부분의 일상 작업인 간단한 질문 답변, 텍스트 포맷팅, 번역, 일정 관리 등에는 이렇게 강력한 모델이 전혀 필요하지 않습니다. Claude Haiku 4.5의 입력 가격은 $1/MTok, 출력은 $5/MTok으로, Opus 4.6의 $5/$25와 비교하면 무려 5배나 저렴합니다. OpenClaw의 설정 파일에서 기본 모델을 변경하는 것은 단 한 줄이면 됩니다.
yamlmodel: default: claude-haiku-4-5-20251001
Claude 시리즈 외에도 가성비가 뛰어난 모델들이 많습니다. GPT-4o-mini의 가격은 입력 $0.15/MTok, 출력 $0.6/MTok으로 Haiku보다 6배 이상 저렴하며, 간단한 대화와 빠른 질답 처리에 매우 적합합니다. Google의 Gemini 2.0 Flash는 입력이 $0.1/MTok으로 더욱 저렴합니다. OpenClaw를 주로 한국어 환경에서 사용한다면, MiniMax M2.5도 좋은 선택입니다. 시간당 비용은 약 $1입니다(dailydoseofds 측정, 2026년 2월 기준). 물론 충분한 로컬 하드웨어 리소스가 있다면 Ollama를 통해 로컬 모델을 실행하여 완전히 무료로 사용할 수도 있습니다. OpenClaw에서 이러한 모델을 연결하는 방법은 OpenClaw 모델 설정 완전 가이드를 참고하시기 바랍니다.
두 번째로 5분 안에 할 수 있는 최적화는 Max Token 상한 설정입니다. 기본적으로 OpenClaw는 모델 응답 길이를 제한하지 않기 때문에, 모델이 간단한 질문에 대해서도 장문의 답변을 생성할 수 있습니다. 적절한 상한을 설정하면 출력 토큰 소모를 효과적으로 제어할 수 있습니다.
yaml# config.yaml model: max_output_tokens: 2048 # 대부분의 작업에 2048이면 충분합니다
세 번째 즉효 조치는 Prompt Caching을 활성화하는 것입니다. Claude와 GPT 시리즈 모델은 모두 프롬프트 캐싱 기능을 지원하며, 시스템 프롬프트나 자주 사용하는 컨텍스트가 변경되지 않을 때 API가 자동으로 캐시된 버전을 사용하여 입력 토큰 비용을 80-90% 절감할 수 있습니다. OpenClaw에서 캐싱을 활성화하려면 API 호출 설정에서 관련 파라미터가 활성화되어 있는지 확인하면 됩니다. 구체적인 구현은 사용하는 API 제공업체에 따라 다릅니다. laozhang.ai 같은 중계 서비스를 통해 API에 접근하는 경우, 캐싱 기능은 기본적으로 활성화되어 있으며, 가격은 주요 플랫폼과 대부분 동일하면서 네트워크 가속의 추가 이점도 얻을 수 있습니다.
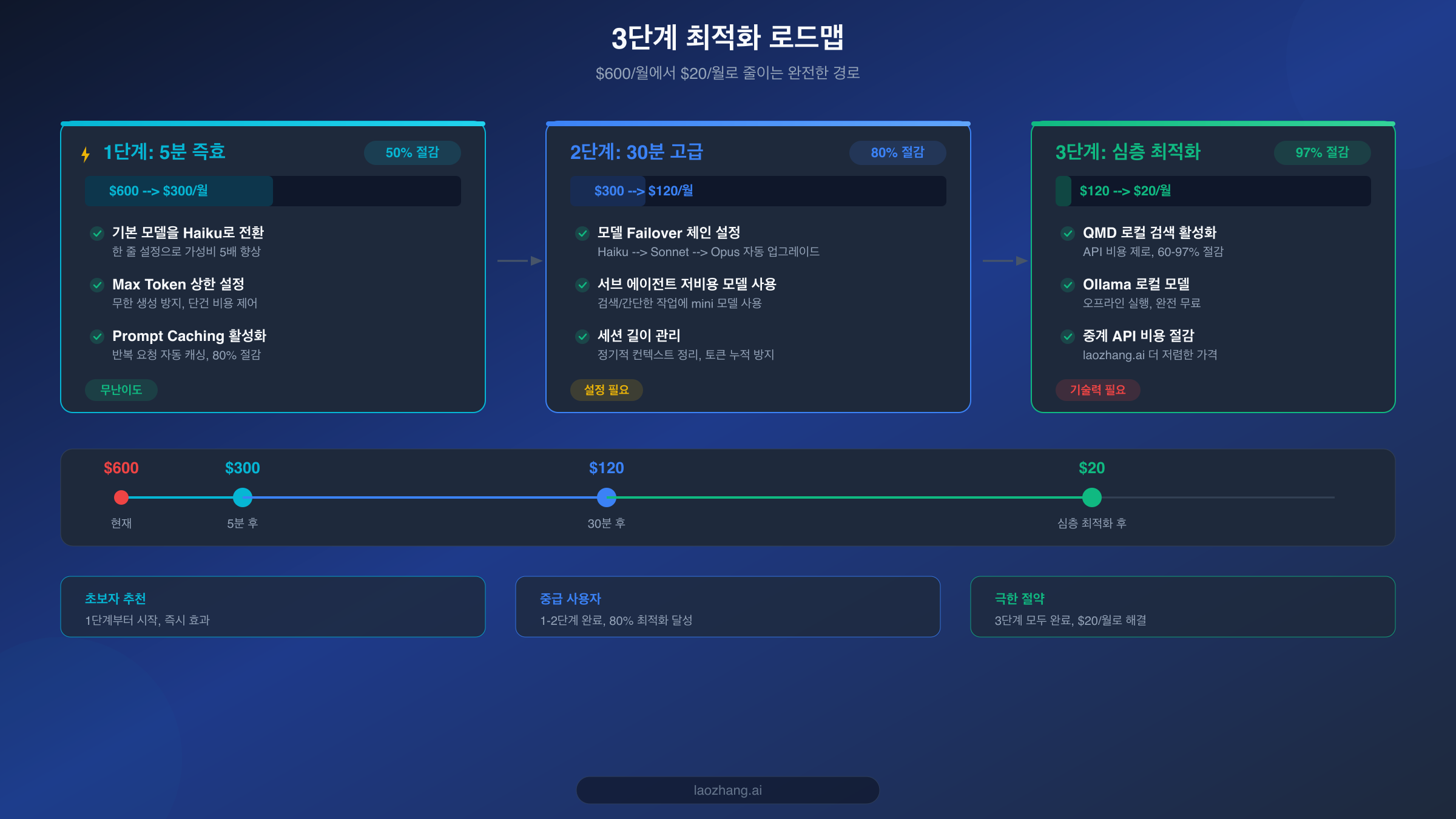
위의 세 단계 작업은 총 5분밖에 걸리지 않지만 효과는 즉각적입니다. 커뮤니티 사용자들의 실제 피드백에 따르면, 모델 전환만으로도 월 비용을 $600에서 $150-300 범위로 줄일 수 있습니다.
고급 최적화: 모델 라우팅으로 OpenClaw가 자동으로 절약
5분의 즉효 최적화로 "어떤 모델을 사용할지"의 문제는 해결했지만, 일괄적으로 가장 저렴한 모델만 사용하는 것이 최적의 해답은 아닙니다. 일부 복잡한 작업은 더 강력한 모델이 필요하기 때문입니다. 모델 라우팅의 핵심 아이디어는 "적절한 모델로 적절한 일을 하는 것"입니다. 간단한 작업은 저렴한 모델에 맡기고, 복잡한 작업에만 비싼 모델을 호출하여 OpenClaw가 자동으로 판단하고 선택하도록 합니다.
모델 라우팅을 구현하는 가장 직접적인 방법은 Failover 체인을 설정하는 것입니다. OpenClaw는 우선순위에 따라 여러 모델을 설정할 수 있으며, 하위 모델이 요구사항을 충족하지 못할 때 자동으로 상위 모델로 업그레이드합니다. 검증된 고가성비 Failover 체인 설정은 다음과 같습니다.
yaml# config.yaml - 모델 Failover 체인 model: default: claude-haiku-4-5-20251001 fallback: - model: claude-sonnet-4-6 condition: "complexity > 0.7" - model: claude-opus-4-6 condition: "complexity > 0.9"
이 설정의 로직은 간단합니다. 일상 작업의 80%는 Haiku가 처리하고($1/MTok), 더 깊은 추론이 필요한 작업은 자동으로 Sonnet으로 업그레이드하며($3/MTok), 정말 복잡한 코드 디버깅이나 장문 분석에만 Opus를 호출합니다($5/MTok). LumaDock의 실측 데이터에 따르면, 이런 계층적 방식은 95% 이상의 작업 품질을 유지하면서 80-95%의 비용을 절감할 수 있습니다.
두 번째 고급 최적화는 서브 에이전트에 독립적인 저비용 모델을 설정하는 것입니다. OpenClaw는 복잡한 작업을 처리할 때 여러 서브 에이전트를 실행하는 경우가 많습니다. 검색 에이전트, 코드 실행 에이전트, 문서 분석 에이전트 등이 그 예입니다. 기본적으로 이 서브 에이전트들은 메인 에이전트와 동일한 모델을 사용하지만, 실제로 그들의 대부분의 작업(검색 결과 요약, 간단한 포맷팅 등)은 고급 모델이 전혀 필요 없습니다. LumaDock의 데이터에 따르면, 멀티 에이전트 시나리오의 토큰 소모량은 싱글 에이전트의 3.5배이므로, 서브 에이전트에 GPT-4o-mini나 Gemini Flash 같은 저비용 모델을 설정하면 상당한 절감 효과를 얻을 수 있습니다. 커스텀 모델의 상세한 연결 방법은 커스텀 모델 연결 튜토리얼을 참고하시기 바랍니다.
yaml# config.yaml - 서브 에이전트 모델 설정 agents: search: model: gpt-4o-mini code_runner: model: claude-haiku-4-5-20251001 summarizer: model: gpt-4o-mini
세 번째 고급 최적화는 세션 길이 관리입니다. 앞서 언급했듯이 컨텍스트 히스토리가 토큰 소모의 40-50%를 차지하며, 이 문제를 해결하는 가장 직접적인 방법은 세션 길이를 제어하는 것입니다. OpenClaw는 최대 대화 라운드 수와 컨텍스트 윈도우 크기를 설정할 수 있으며, 대화가 설정된 길이를 초과하면 자동으로 초기 대화 내용을 정리합니다. 커뮤니티에서 권장하는 컨텍스트 상한은 50K-100K 토큰이며, 이 범위를 넘으면 비용이 급증할 뿐 아니라 모델의 주의력도 떨어져 오히려 답변 품질이 저하됩니다.
yaml# config.yaml - 세션 관리 conversation: max_context_tokens: 50000 auto_summarize: true # 긴 대화 자동 요약 summary_threshold: 30000 # 30K 초과 시 요약 트리거
모델 라우팅과 서브 에이전트 설정을 완료하면, OpenClaw 월 비용은 $300에서 $60-120 범위로 줄어들 것입니다. 5분 즉효 방법과 비교하면 이해하고 설정하는 데 30분이 필요하지만, "수동 절약"에서 "지능형 절약"으로 전환되는 효과를 얻을 수 있습니다. 시스템이 자동으로 성능과 비용 사이에서 최적의 균형점을 찾아줍니다.
심층 최적화: QMD + 캐싱 + 세션 관리 3대 무기
앞의 두 단계 최적화로 월 비용이 $60-120까지 줄었다면, 세 번째 심층 최적화의 목표는 이를 $20 이하로 더 압축하는 것입니다. 이 단계의 핵심 무기는 QMD(Quick Memory Database)입니다. OpenClaw v2026.2.2 버전에서 도입된 로컬 시맨틱 검색 기능으로, API 토큰을 전혀 소모하지 않으면서도 모델이 관련 정보를 가져오도록 도와줍니다.
QMD의 작동 원리는 복잡하지 않습니다. 로컬 디바이스에 벡터 데이터베이스를 구축하고, 대화 기록, 문서, 노트 등의 콘텐츠를 인덱싱합니다. 질문을 하면 QMD가 먼저 로컬에서 관련 콘텐츠를 검색하고, 전체 컨텍스트 히스토리가 아닌 가장 관련성 높은 정보 조각만 모델에 전송합니다. 이렇게 하면 컨텍스트 누적이라는 가장 큰 비용 문제를 직접적으로 해결합니다. 여러 출처의 데이터 검증(Medium, Google 검색 결과, haimaker 등, 2026년 3월 검증)에 따르면, QMD는 60-97%의 토큰 절감을 실현할 수 있으며, 구체적인 절감 비율은 사용 패턴과 데이터 양에 따라 달라집니다.
QMD를 활성화하는 기본 설정 단계는 다음과 같습니다. 먼저 OpenClaw 버전이 v2026.2.2 이상인지 확인한 후, 설정 파일에서 QMD 기능을 활성화합니다.
yaml# config.yaml - QMD 설정 qmd: enabled: true index_path: "./qmd_index" embedding_model: "local" # 로컬 임베딩 모델 사용, API 비용 제로 search_top_k: 5 # 매 검색마다 가장 관련성 높은 5개 반환 auto_index: true # 새로운 대화 자동 인덱싱
QMD는 로컬 임베딩 모델을 사용하여 벡터를 생성하므로, 인덱싱과 검색 과정에서 외부 API를 전혀 호출할 필요가 없어 진정한 의미의 제로 비용을 실현합니다. 이미 Ollama를 사용하고 있는 사용자라면 로컬의 임베딩 모델을 직접 재활용할 수 있습니다. 사용 중 컨텍스트 초과 문제를 겪는 경우, 컨텍스트 초과 해결 방법에 상세한 가이드가 있으니 참고하시기 바랍니다.
두 번째 무기는 캐싱 전략의 추가 최적화입니다. 앞서 언급한 Prompt Caching 외에도 OpenClaw 레벨에서 더 세밀한 캐시 제어를 구현할 수 있습니다. 예를 들어 반복성이 높은 작업(매일의 모닝 브리핑, 고정 형식의 이메일 생성 등)의 경우, 템플릿과 자주 사용하는 응답을 로컬에 캐싱하여 API 호출을 완전히 우회할 수 있습니다. LumaDock의 테스트 데이터에 따르면, 합리적인 캐싱 전략은 QMD를 기반으로 남은 API 호출의 70-90%를 추가로 절감할 수 있습니다.
세 번째 무기는 Ollama를 사용한 로컬 모델로 간단한 작업을 처리하는 것입니다. 최신 지식이나 복잡한 추론이 필요하지 않은 작업, 예를 들어 텍스트 포맷팅, 간단한 번역, 코드 스니펫 생성 등은 로컬에서 실행되는 오픈소스 모델에 완전히 맡길 수 있습니다. OpenClaw는 LiteLLM을 통해 Ollama와의 원활한 통합을 지원하며, Failover 체인의 최하단에 로컬 모델을 추가할 수 있습니다.
yaml# config.yaml - Ollama 로컬 모델 통합 model: default: ollama/llama3.2 # 로컬 모델을 기본으로 설정 fallback: - model: claude-haiku-4-5-20251001 condition: "local_failed or complexity > 0.5" - model: claude-sonnet-4-6 condition: "complexity > 0.8"
이 설정의 의미는 간단한 작업은 우선적으로 무료 로컬 모델을 사용하고, 로컬 모델이 처리에 실패하거나 작업 복잡도가 높으면 자동으로 Haiku로 업그레이드하며, 정말 복잡한 작업에만 Sonnet을 호출한다는 것입니다. 이렇게 하면 요청의 80%에서 API 비용이 발생하지 않고, 나머지 20%의 요청도 가성비가 가장 높은 모델을 사용합니다.
세 가지 무기를 모두 갖추면, 커뮤니티 피드백과 여러 출처의 검증 데이터에 따르면 개인 사용자의 월 비용은 보통 $6-13 사이로 제어할 수 있으며(LumaDock 데이터), 소규모 팀은 약 $25-50/월입니다. 이는 $600에서 $20으로의 97% 비용 최적화 목표를 달성했다는 의미입니다.
중국 사용자 전용: 중계 API 가속 및 비용 이중 최적화
중국 대륙 사용자에게는 OpenClaw 사용 시 추가적인 도전이 있습니다. 해외 API(Anthropic, OpenAI 등)에 직접 연결하면 속도가 느리고 지연이 높을 뿐 아니라, 연결 불안정이나 차단 문제를 자주 겪게 됩니다. 이러한 네트워크 문제는 사용 경험에 영향을 줄 뿐 아니라 간접적으로 비용도 증가시킵니다. 연결 타임아웃으로 인한 재시도, 요청 손실로 인한 중복 호출 등은 모두 숨겨진 토큰 낭비입니다.
중계 API 서비스는 이 문제를 해결하는 최적의 방안입니다. laozhang.ai를 예로 들면, 안정적인 중계 채널을 제공하여 중국 내 네트워크로도 Claude, GPT, Gemini 등 주요 모델의 API에 고속으로 접근할 수 있습니다. 비용 측면에서 laozhang.ai의 텍스트 모델 가격은 주요 AI 플랫폼과 대부분 동일하지만, 네트워크 연결이 더 안정적이기 때문에 재시도와 타임아웃으로 인한 추가 토큰 소모가 줄어 실제 사용 비용은 오히려 더 낮습니다. 최소 $5부터 충전 가능(약 35위안)하므로, 개인 개발자에게도 진입 장벽이 낮습니다.
OpenClaw에서 중계 API를 설정하는 것은 매우 간단합니다. API의 Base URL만 변경하면 됩니다. laozhang.ai를 예로 들면 다음과 같습니다.
yaml# config.yaml - 중계 API 설정 api: base_url: "https://api.laozhang.ai/v1" api_key: "your-api-key"
변경 후 모든 API 요청이 중계 서비스를 통해 전송되며, 다른 설정은 전혀 수정할 필요가 없습니다. 모델 이름, 파라미터 설정, Failover 체인 등이 모두 그대로 유지됩니다. 중계 서비스의 상세한 설정 방법과 주의사항은 laozhang.ai OpenClaw 연결 설정 튜토리얼을 참고하시기 바랍니다.
중계 방식 외에도, 중국 사용자에게는 독특한 이점이 있습니다. 바로 중국산 대형 언어 모델입니다. MiniMax M2.5, 통의천문 등의 모델은 중국어 작업에서 이미 매우 뛰어난 성능을 보여주고 있으며, 가격도 해외 모델보다 일반적으로 저렴합니다. 중국산 모델을 Failover 체인의 주력으로 사용하고, 영어 처리나 고급 추론이 필요할 때만 Claude/GPT로 전환하면, 중국어 사용 경험을 보장하면서도 비용을 추가로 절감할 수 있습니다. 이러한 "중국산 모델 주력 + 해외 모델 백업" 혼합 전략은 중국 사용자만의 고유한 비용 최적화 경로입니다.
장기 절약: 예산 모니터링 및 자동화 관리
앞서 소개한 최적화 방법들은 "어떻게 절약할 것인가"의 문제를 해결했지만, 비용을 장기적으로 통제하려면 모니터링과 예산 관리 체계를 구축해야 합니다. 모니터링 없는 최적화는 지속 가능하지 않습니다. 측정할 수 없는 것은 개선할 수도 없기 때문입니다.
첫 번째 단계는 월간 예산 상한을 설정하는 것입니다. 대부분의 API 제공업체는 소비 한도 설정을 지원하며, 소비가 사전 설정된 값에 도달하면 자동으로 API 호출을 중단하거나 알림을 전송합니다. OpenClaw 수준에서도 LiteLLM을 통해 소비 예산을 설정할 수 있습니다.
yaml# litellm_config.yaml - 예산 제어 budget: monthly_limit: 30 # 월간 예산 $30 alert_threshold: 0.8 # 80% 도달 시 알림 action_on_limit: "downgrade" # 상한 도달 시 무료 모델로 다운그레이드
두 번째 단계는 소비 모니터링 대시보드를 구축하는 것입니다. OpenClaw는 LiteLLM의 로깅 기능을 통해 매 API 호출의 토큰 소모와 비용을 기록할 수 있습니다. 이 데이터를 간단한 스프레드시트나 모니터링 도구로 내보내서 일별, 주별 소비 추이를 추적하고 비정상적인 소비 피크를 신속하게 발견할 수 있습니다. 주목해야 할 핵심 지표는 대화당 평균 토큰 소모, 일일 활성 대화 수, 모델 사용 분포 비율, QMD 캐시 적중률입니다.
세 번째 단계는 설정을 정기적으로 최적화하는 것입니다. 비용 관리는 일회성 작업이 아니라 지속적으로 반복해야 하는 과정입니다. 매달 10분을 투자해 소비 보고서를 확인하면서, 특정 시나리오의 소모가 비정상적으로 높은지, 기존 설정을 대체할 수 있는 더 저렴한 새 모델이 있는지, QMD 인덱스를 업데이트할 필요가 있는지 등을 점검하시기 바랍니다. AI 모델 시장의 빠른 발전과 함께, 신규 모델의 출시는 종종 더 낮은 가격과 더 나은 성능을 동반합니다. 예를 들어 Claude Haiku 4.5는 이전 세대 Haiku 3($0.25/$1.25 MTok)과 비교하면 가격이 조정되었지만, 성능이 크게 향상되어 가성비가 오히려 더 높아졌습니다. 시장 동향에 관심을 기울이며 모델 설정을 적시에 조정하면, 항상 가장 가성비 높은 방안을 유지할 수 있습니다.
자동화는 장기 관리의 궁극적인 목표입니다. 소비 알림, 자동 다운그레이드 전략, 정기적인 설정 검토 계획을 설정하면 비용 관리를 "수동 조작"에서 "자동 실행"으로 전환할 수 있습니다. 소비가 예산 상한에 근접하면 시스템이 자동으로 더 저렴한 모델로 전환하거나 더 적극적인 캐싱 전략을 활성화하고, 특정 서브 에이전트의 소모가 비정상적으로 감지되면 자동으로 알림을 보내 확인할 수 있도록 합니다. 이렇게 하면 OpenClaw는 진정한 의미에서 "부담 없이 사용하고 관리할 수 있는" AI 어시스턴트가 됩니다.
요약: 절약 실행 체크리스트
이 글의 핵심 내용을 실행 가능한 체크리스트로 정리하여 우선순위별로 나열합니다.
1단계: 5분 즉시 실행 (예상 효과: 50% 절감)
- 기본 모델을 Opus/Sonnet에서 Haiku 4.5로 전환
- max_output_tokens를 2048로 설정
- Prompt Caching이 활성화되어 있는지 확인
2단계: 30분 고급 설정 (예상 효과: 80% 절감)
- Haiku -> Sonnet -> Opus Failover 체인 설정
- 서브 에이전트에 독립적인 저비용 모델 설정 (GPT-4o-mini / Gemini Flash)
- 세션 자동 요약 및 컨텍스트 길이 제어 활성화
3단계: 심층 최적화 (예상 효과: 97% 절감)
- QMD 로컬 시맨틱 검색 활성화 (v2026.2.2+)
- Ollama를 통해 로컬 모델로 간단한 작업 처리
- 중계 API(예: laozhang.ai, 문서: https://docs.laozhang.ai/ )로 네트워크 및 비용 문제 해결
- 월간 예산 모니터링 및 자동 다운그레이드 메커니즘 구축
각 단계는 독립적으로 실행 가능하며, 1단계부터 시작하여 자신의 기술 수준과 시간에 맞춰 점진적으로 진행하는 것을 권장합니다. 1단계만 실행해도 요금 청구서의 뚜렷한 감소를 즉시 체감할 수 있습니다. 그리고 반나절을 투자해 세 단계를 모두 완료하면, OpenClaw 월 비용이 $600에서 $20 이하로 줄어듭니다. 이것이 바로 이 글 제목의 약속이며, 검증된 실제 수치입니다.