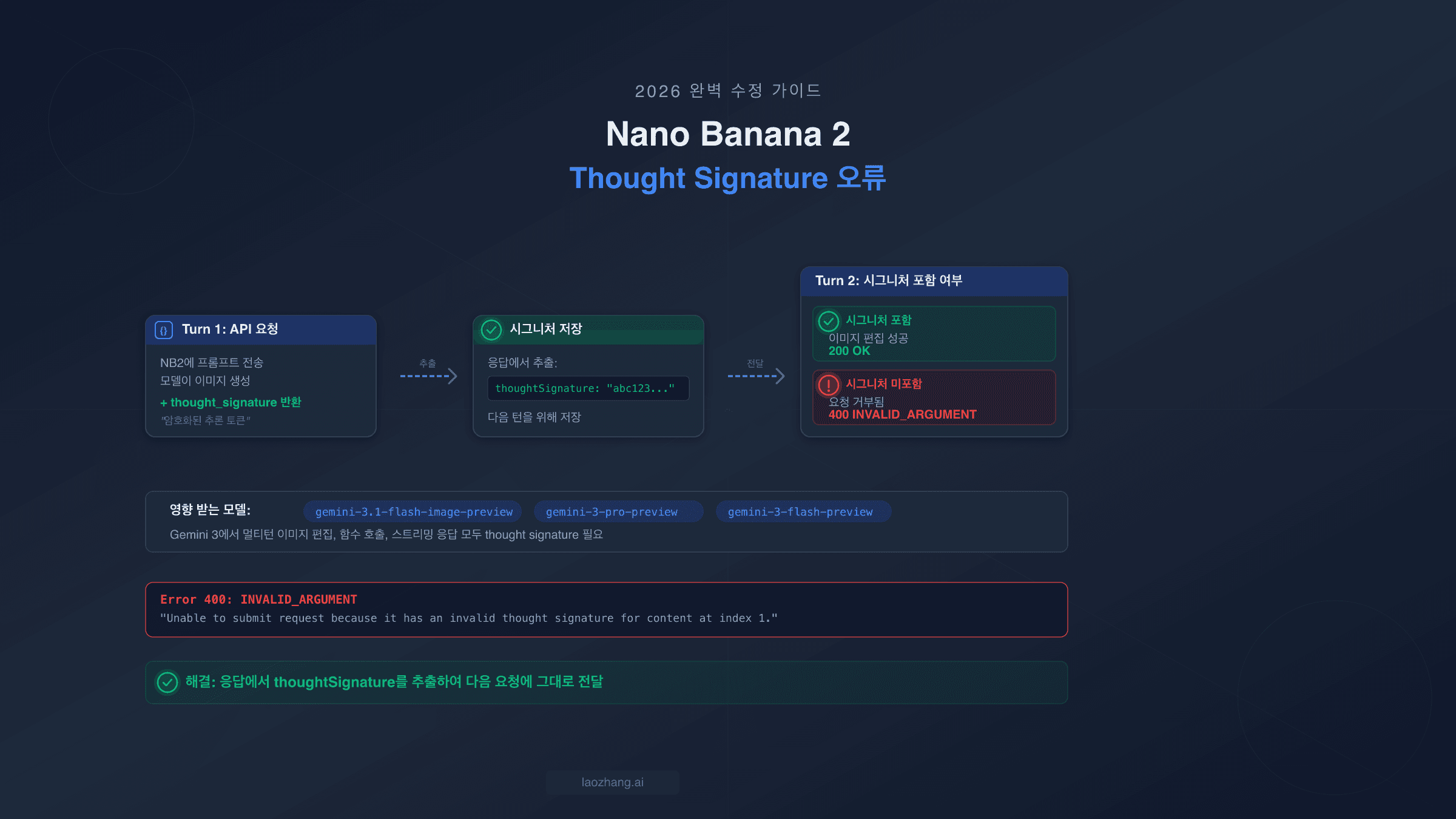
Gemini 이미지 API 오류는 세 가지 유형으로 분류됩니다: 429 속도 제한 (청구 한도 0, IPM 초과, Ghost Bug, 또는 Dynamic Shared Quota로 인한), 무응답 실패 (잘못된 엔드포인트, responseModalities 설정 오류, 또는 청구 미설정), 파라미터 문제 (imageConfig 무시, 대소문자 구분하는 image_size, responseModalities에서 TEXT 누락). GCP 콘솔 할당량 대시보드를 먼저 확인하고, 청구가 활성화되어 있는지 확인하세요 — 무료 요금제 IPM은 2025년 12월 7일부터 0이 되었습니다. 올바른 /v1beta/ 엔드포인트와 responseModalities: ["TEXT", "IMAGE"]를 사용하세요.
핵심 요약
세 가지 오류 유형, 세 가지 진단 경로. 429 오류는 각각 다른 해결 방법이 필요한 네 가지 근본 원인이 있습니다 — 어떤 유형인지 파악하지 않고 "기다리고 재시도"하지 마세요. 무응답 실패 (이미지 없는 HTTP 200)는 거의 항상 responseModalities 설정 오류입니다. 파라미터 실패 (수락되지만 무시되는 설정)는 보통 image_size의 대소문자 구분 문제이거나 미들웨어에 의해 imageConfig가 제거되는 문제입니다. 청구를 먼저 확인하고, 엔드포인트, 파라미터 순으로 확인하세요.
Gemini 이미지 API 오류 이해: 진단 맵
Gemini 이미지 생성이 실패할 때, 개발자는 일반적으로 세 가지 실패 유형 중 하나를 경험하며, 각각 완전히 다른 진단 접근 방식이 필요합니다. 첫 번째 실패 유형은 하드 오류로, API 호출이 HTTP 429 또는 HTTP 400을 반환하고 요청이 생성 시작 전에 거부됩니다. 두 번째는 무응답 실패로, 호출이 HTTP 200으로 성공하지만 응답에 이미지 데이터가 없습니다. 세 번째는 설정 실패로, 이미지가 성공적으로 생성되지만 지정한 내용과 출력이 일치하지 않습니다 — 잘못된 해상도, 잘못된 화면 비율, 또는 지정한 것과 완전히 다른 설정.
어떤 실패 유형인지 이해하는 것이 중요한 첫 번째 단계입니다. 잘못 파악하면 개발자가 잘못된 진단 경로를 택하여 시간을 낭비하게 됩니다. 아래 표는 각 오류 유형을 HTTP 상태, gRPC 상태 코드, 이 가이드에서 다루는 챕터에 매핑합니다.
| 오류 유형 | HTTP 상태 | gRPC 상태 | 일반 증상 | 해결 챕터 |
|---|---|---|---|---|
| 청구 한도 = 0 | 429 | RESOURCE_EXHAUSTED | 무료 요금제, 이미지 없음 | 챕터 2 |
| IPM 속도 제한 | 429 | RESOURCE_EXHAUSTED | 생성 후 실패 | 챕터 2 |
| Ghost 429 버그 | 429 | RESOURCE_EXHAUSTED | 청구 업그레이드 후 | 챕터 2 |
| Dynamic Shared Quota | 429 | RESOURCE_EXHAUSTED | 프리뷰 모델 트래픽 | 챕터 2 |
| 잘못된 responseModalities | 200 | — | 빈 parts[] 배열 | 챕터 3 |
| 잘못된 엔드포인트 | 404/400 | NOT_FOUND | 지원되지 않는 작업 | 챕터 3 |
| 잘못된 모델 이름 | 400 | INVALID_ARGUMENT | 모델 없음 | 챕터 3 |
| 청구 미설정 | 400 | FAILED_PRECONDITION | 명시적 오류 메시지 | 챕터 3 |
| image_size 대소문자 오류 | 200 | — | 잘못된 해상도 출력 | 챕터 4 |
| imageConfig 제거 | 200 | — | 설정 무시 | 챕터 4 |
| TEXT 모달리티 누락 | 200 | — | 빈 응답 | 챕터 4 |
이미지 관련이 아닌 일반 Gemini API 오류는 일반 Gemini API 오류 해결 가이드에서 다루고 있습니다. 이 글은 이미지 생성에 고유한 세 가지 오류 유형에만 집중합니다 — 일반 Gemini API 가이드에서 다루지 않는 오류들입니다. 이미지 API는 자체적인 할당량 차원(IPM — Images Per Minute), 필수 파라미터, 그리고 텍스트 생성에 적용되지 않는 자체 모델 엔드포인트가 있습니다.
가장 중요한 진단 원칙은 이것입니다: 429 오류를 단순히 "속도 제한"으로 기다리지 마세요. 네 가지 완전히 다른 근본 원인이 동일한 429 응답을 만들어내며, 기다리는 것은 그 중 하나에만 올바른 대응입니다. 마찬가지로, 성공적인 HTTP 200 응답이 이미지가 생성되었다는 의미라고 가정하지 마세요 — 200은 빈 응답을 만드는 설정 오류를 숨길 수 있습니다.
429 오류: 4가지 근본 원인, 4가지 다른 해결 방법
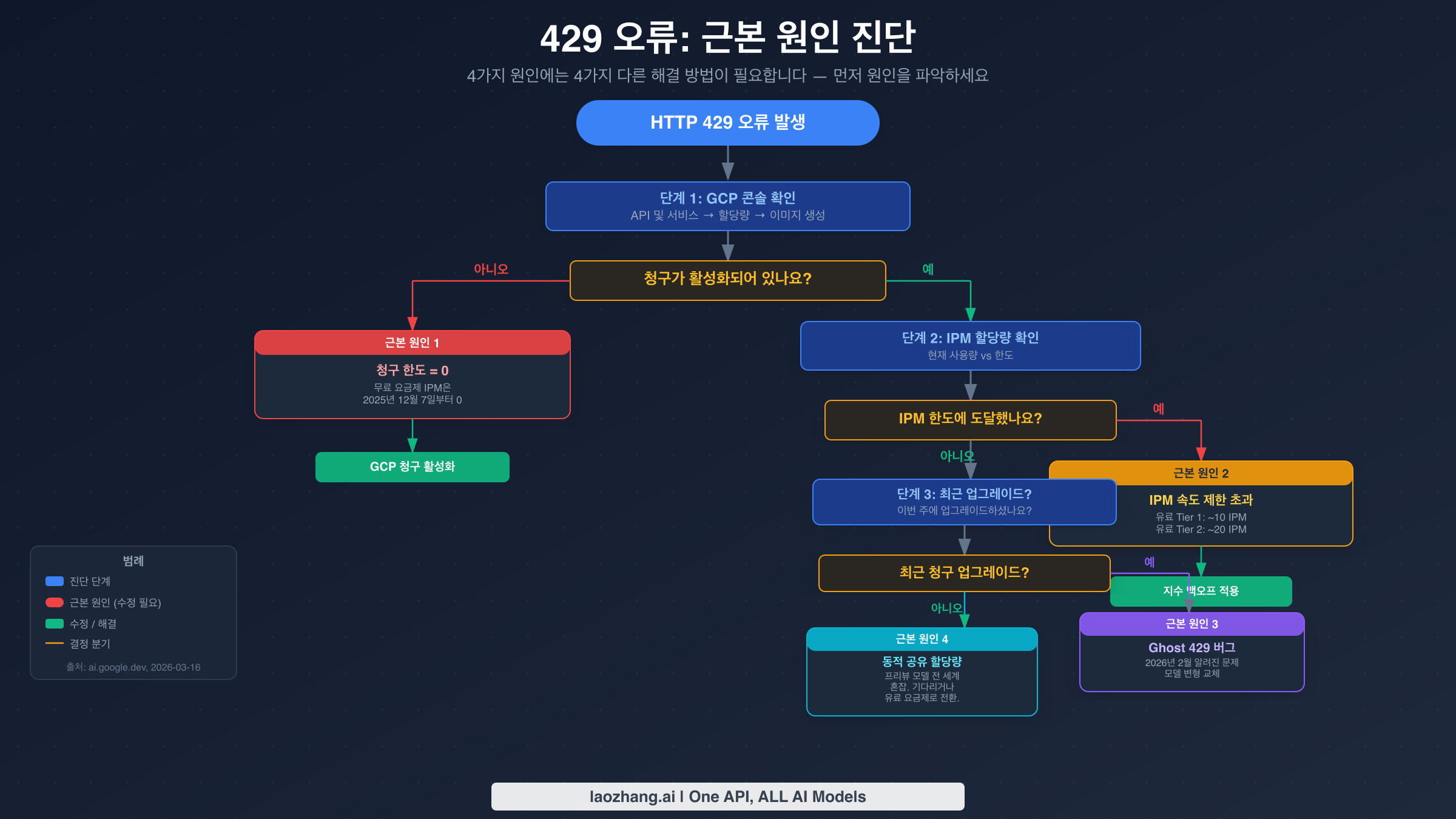
429 RESOURCE_EXHAUSTED 오류는 가장 흔한 Gemini 이미지 API 오류이지만, 네 가지 완전히 다른 문제가 트리거되더라도 동일하게 보이기 때문에 오해하기 쉽습니다. 모든 Gemini 이미지 개발자가 이를 경험하며, 온라인의 거의 모든 리소스는 이를 단일 문제 — "속도 제한을 초과했다" — 로 처리합니다. 네 가지 근본 원인에는 네 가지 완전히 다른 해결 방법이 있으며 잘못된 수정을 적용하면 도움이 되지 않기 때문에 이 접근 방식은 시간 낭비로 이어집니다.
근본 원인 1: 청구 한도 = 0 (무료 요금제)
신규 개발자에게 429의 가장 일반적인 원인은 가장 간단한 것입니다: 무료 요금제는 2025년 12월 7일부터 이미지당 할당량(IPM)이 정확히 0이 되었습니다 (Firebase AI Logic 문서 기준, 2026-03-16 검증). 즉, 무료 요금제 계정은 API를 통해 이미지를 전혀 생성할 수 없습니다 — 낮은 제한이 아니라 0입니다. 이 문제에 부딪히면, 429는 "한도를 초과했다"고 알리는 것이 아니라 한도가 이미 0임을 알려주는 것입니다.
이것이 문제인지 확인하려면, GCP 콘솔 → API 및 서비스 → Generative Language API → 할당량 및 한도로 이동하세요. "image"로 필터링하고 IPM(Images Per Minute) 할당량을 확인하세요. 0이 표시되면 근본 원인 1에 해당합니다. 해결 방법은 Google Cloud 프로젝트에서 청구를 활성화하고 최소 유료 Tier 1으로 업그레이드하는 것입니다. 청구를 활성화한다고 해서 즉시 할당량이 복구되지 않을 수 있으니 주의하세요 — 15-30분의 전파 지연이 있을 수 있습니다.
근본 원인 2: IPM 속도 제한 초과 (유료 요금제)
청구가 활성화되면 분당 이미지 생성 할당량이 생깁니다. 상세 Gemini 이미지 429 속도 제한 가이드의 검증된 데이터에 따르면, 유료 Tier 1은 약 10 IPM(Images Per Minute), 유료 Tier 2는 약 20 IPM을 지원합니다. 이는 RPM(Requests Per Minute)과 별개입니다 — 이미지 모델은 이미지 생성 호출에 특별히 적용되는 자체 IPM 할당량이 있습니다.
근본 원인 2의 진단 신호는 패턴입니다: 애플리케이션이 처음에는 잘 작동하다가 여러 이미지를 빠르게 연속 생성한 후 429 오류가 발생하기 시작합니다. GCP 콘솔 할당량 대시보드에 현재 사용량이 IPM 한도에 접근하거나 달성하는 것이 표시됩니다. 해결 방법은 지수 백오프 — 첫 번째 429 이후 2초 지연으로 시작하여 재시도마다 두 배로 늘리기 (2초, 4초, 8초, 16초)입니다. 일괄 처리 작업은 한도에 도달하여 반응적으로 물러나는 것보다 IPM 한도 내에 머물기 위한 지연을 사전에 계산해야 합니다.
근본 원인 3: Ghost 429 버그 (2026년 2월)
이 버그는 최근 청구 등급을 업그레이드한 계정에 영향을 미칩니다. 증상은 성공적인 청구 업그레이드 후에도 429 오류가 지속되는 것입니다 — GCP 콘솔에는 0이 아닌 IPM 할당량이 표시되고 청구가 활성화되어 있지만, 이미지 생성이 계속 429를 반환합니다. Google은 2026년 2월 AI 개발자 포럼에서 이것을 알려진 문제로 확인했습니다. 이 버그는 계정 수준의 할당량 적용 레이어에 영향을 미치며, 새 할당량 할당이 올바르게 전파되지 않습니다.
임시 해결 방법은 다른 모델 변형으로 전환하는 것입니다. gemini-3.1-flash-image-preview를 사용 중이라면 gemini-2.5-flash-image로 전환하거나 그 반대로 해보세요. 많은 경우 이렇게 하면 영향받은 할당량 적용 경로를 우회할 수 있습니다. 또한, 24-48시간 기다리면 할당량 전파가 완료되면서 종종 해결됩니다. 버그가 지속되면 Google Cloud 지원 티켓을 제출하면서 2026년 2월 Ghost 429 문제를 명시적으로 참조하면 해결이 가속화됩니다.
비슷해 보일 수 있는 503 과부하 오류에 대해서는 503 과부하 오류 수정 가이드를 참조하세요.
근본 원인 4: Dynamic Shared Quota (프리뷰 모델)
프리뷰 모델 — gemini-3.1-flash-image-preview와 gemini-3-pro-image-preview — 은 프로덕션 모델처럼 프로젝트별 할당량을 사용하지 않습니다. 대신 Google이 Dynamic Shared Quota라고 부르는 것을 사용하는데, 가용 용량이 전 세계의 프리뷰 모델 사용자 모두와 공유되며, 개인 사용량 수준에 관계없이 전 세계 시스템 혼잡이 높을 때 429 오류가 발생합니다. Google은 2026년 1월 29일 support.google.com의 지원 스레드에서 이 동작을 확인했습니다.
이것은 기다리는 것이 진정한 올바른 대응인 유일한 근본 원인입니다. 429는 당신이 잘못한 것 때문이 아닙니다 — 전 세계 프리뷰 모델 용량이 일시적으로 제한되어 있기 때문입니다. 더 긴 지연의 지수 백오프 (2초 대신 5초로 시작)가 여기서 작동합니다. 신뢰성 요구 사항이 있는 프로덕션 애플리케이션의 경우, 올바른 아키텍처적 대응은 gemini-2.5-flash-image와 같은 프로덕션 모델을 사용하거나 전용 용량을 제공하는 Vertex AI with Provisioned Throughput을 사용하는 것입니다.
다음은 어떤 유형의 429를 보고 있는지 식별하는 완전한 지수 백오프 구현입니다:
pythonimport time import google.generativeai as genai def generate_image_with_backoff(prompt: str, max_retries: int = 5) -> dict: """Generate image with exponential backoff for 429 errors.""" client = genai.GenerativeModel("gemini-3.1-flash-image-preview") for attempt in range(max_retries): try: response = client.generate_content( contents=prompt, generation_config={ "responseModalities": ["TEXT", "IMAGE"], } ) return response except Exception as e: error_str = str(e) if "429" not in error_str and "RESOURCE_EXHAUSTED" not in error_str: raise # Not a rate limit error if attempt == max_retries - 1: raise # Exhausted retries # Exponential backoff: 2s, 4s, 8s, 16s, 32s delay = 2 ** (attempt + 1) print(f"429 on attempt {attempt + 1}, waiting {delay}s...") time.sleep(delay) raise Exception("Max retries exceeded")
이미지 생성이 아무것도 반환하지 않음: 무응답 실패 해결
무응답 실패는 어떤 실행 가능한 피드백도 제공하지 않기 때문에 가장 답답한 Gemini 이미지 오류 유형입니다. API 호출이 HTTP 200(성공)을 반환하고, 응답은 유효한 JSON이지만, 이미지 데이터를 찾아보면 parts 배열이 비어있거나 텍스트만 포함되어 있습니다. 예외도 발생하지 않고, 무엇이 잘못되었는지 설명하는 오류 메시지도 없습니다. 이 실패 유형에는 네 가지 뚜렷한 원인이 있으며, 각각 다른 조사가 필요합니다.
가장 일반적인 원인: responseModalities 설정 오류
가장 빈번한 무응답 실패는 설정에서 단 하나의 누락된 단어에서 비롯됩니다. Gemini 이미지 API는 responseModalities에 "TEXT"와 "IMAGE" 모두를 포함해야 합니다 — ["IMAGE"]만 포함하면 빈 parts 배열이 있는 성공적인 HTTP 200 응답이 생성됩니다. 오류가 발생하지 않습니다. API는 요청을 수락하고 처리하지만 이유를 알려주지 않고 아무것도 유용한 것을 반환하지 않습니다.
이 요구 사항은 공식 Gemini 이미지 생성 문서(ai.google.dev/gemini-api/docs/image-generation, 2026-03-16 검증)에 문서화되어 있지만, 비공식 소스의 예시가 ["IMAGE"]만 표시하거나 원하는 것이 이미지이므로 "IMAGE" 모달리티를 지정하는 것으로 충분하다고 가정하기 때문에 많은 개발자가 이 문제를 경험합니다. 올바른 설정:
pythongeneration_config = { "responseModalities": ["TEXT", "IMAGE"], # Both required "imageConfig": { "image_size": "1K" # Note: uppercase K } }
왜 TEXT가 필요한가요? Gemini 이미지 모델은 설계상 멀티모달입니다 — 이미지와 함께 텍스트 응답(일반적으로 설명 또는 캡션)을 생성합니다. API는 이 이중 출력 모델을 중심으로 구축되어 있으며, responseModalities에서 TEXT를 생략하여 텍스트 출력을 억제하려고 하면 이미지 전용 출력을 반환하는 대신 전체 응답이 실패합니다. 현재 모달리티 목록에 TEXT도 포함하지 않고 이미지 전용 출력을 얻는 방법은 없습니다.
잘못된 API 엔드포인트
일부 개발자는 OpenAI 호환 클라이언트를 통해 Gemini 이미지 생성을 통합하거나 /v1beta/ 대신 /v1/ 엔드포인트를 사용합니다. Gemini 이미지 생성 API는 /v1beta/ 엔드포인트 경로가 필요합니다. OpenAI 호환 엔드포인트(/v1/images/generations) 또는 안정적인 /v1/ 경로에 대한 요청은 404 오류 또는 명시적인 "지원되지 않는 작업" 메시지를 반환합니다.
올바른 엔드포인트 구조는 다음과 같습니다:
POST https://generativelanguage.googleapis.com/v1beta/models/{model-name}:generateContent
Gemini와 함께 OpenAI 호환 라이브러리를 사용하는 경우, base URL이 올바르게 설정되었는지 확인하세요. Gemini에서 openai Python 라이브러리를 사용하는 많은 개발자가 base_url을 Gemini 서버를 가리키도록 변경하지만, /v1/ 경로를 가리키는 경우 이미지 모델에 도달하지 못합니다.
잘못된 모델 이름
현재 세 가지 Gemini 이미지 모델은 문서화된 대로 정확히 사용해야 하는 특정 이름이 있습니다. 작성 시점(ai.google.dev 기준, 2026-03-16 검증), 현재 모델 이름은 다음과 같습니다:
gemini-3.1-flash-image-preview— 빠른 생성, 프리뷰 모델gemini-3-pro-image-preview— 고품질, 프리뷰 모델gemini-2.5-flash-image— 효율적인 안정 모델
일반적인 실수에는 gemini-2.5-flash-preview-image(잘못된 접미사 순서), gemini-flash-image(버전 누락), 또는 더 이상 사용되지 않는 이전 모델 이름이 포함됩니다. 모델 이름 오류는 일반적으로 400 INVALID_ARGUMENT 또는 404 NOT_FOUND를 반환합니다 — 보통 무응답 200 응답을 생성하지는 않습니다. 하지만 속도 제한과는 다른 오류 서명으로 생성 실패를 유발합니다.
청구 미설정: 설정 오류로 착각할 수 있는 400
청구가 활성화되지 않고 무료 요금제의 0 할당량 한도를 넘어섰을 때, 명확한 오류를 예상할 수 있습니다. Gemini 이미지 API는 실제로 HTTP 400과 gRPC 상태 FAILED_PRECONDITION, 그리고 "billing"을 포함하는 메시지를 반환합니다. 이는 청구가 활성화되어 있지만 할당량이 소진된 경우 발생하는 429와 구별됩니다. FAILED_PRECONDITION 상태는 작업을 위한 사전 조건이 충족되지 않았음을 의미합니다 — 이 경우 사전 조건은 이미지 생성 API를 사용하려면 청구가 활성화되어야 한다는 것입니다.
오류 응답에서 FAILED_PRECONDITION이 보이면, 해결 방법은 항상 GCP 콘솔에서 청구를 활성화하는 것이며, API 파라미터를 조정하는 것이 아닙니다. 이 오류는 responseModalities 또는 imageConfig를 변경해도 해결되지 않습니다.
무음으로 실패하는 파라미터: imageConfig & responseModalities

파라미터 실패는 API가 불만 없이 요청을 수락하고, 이미지를 생성하여 반환하지만 — 이미지가 사양과 일치하지 않기 때문에 Gemini 이미지 API에서 특별히 답답한 카테고리입니다. 2K 해상도를 요청했는데 512px가 나옵니다. 화면 비율을 설정했는데 1:1이 나옵니다. imageConfig를 설정했는데 효과가 없습니다. API는 파라미터를 거부하지 않았습니다; 단지 무시했을 뿐입니다.
image_size 대소문자 구분 함정
imageConfig 내의 image_size 파라미터는 명확하지 않은 방식으로 대소문자를 구분합니다. 유효한 값은 대문자 "K"를 사용합니다 — "512", "1K", "2K", "4K". 소문자 "1k"를 사용해도 오류가 발생하지 않습니다; 기본 해상도(512px)로 자동으로 폴백합니다. 즉, 올바른 코드처럼 보이는 것을 작성하고 테스트하면서 해상도 설정이 무시되고 있다는 것을 알지 못할 수 있습니다.
이 특정 문제는 공식 Gemini API 문서(ai.google.dev, 2026-03-16)에 대해 검증되었습니다. 함정은 소문자 관례 언어나 문자열 값이 대소문자를 구분하지 않는 API에서 오는 개발자에게 특히 교묘합니다. 응답에서 "1k"가 유효하지 않다는 경고가 없습니다 — 이미지가 예상보다 작게 나올 뿐입니다.
유효한 image_size 값의 전체 목록은: "512", "1K", "2K", "4K". 화면 비율 파라미터(aspect_ratio)는 "1:1", "3:4", "4:3", "9:16", "16:9"를 허용합니다 — 이것들은 대소문자를 구분하지 않으며 콜론 표기법을 사용합니다.
responseModalities에 TEXT가 포함되어야 하는 이유
무응답 실패 섹션에서 언급했듯이, responseModalities에는 "TEXT"와 "IMAGE" 모두를 포함해야 합니다. 하지만 파라미터 순서에 대한 추가적인 뉘앙스가 있습니다. responseModalities 배열은 "TEXT"를 먼저, "IMAGE"를 두 번째로 나열해야 합니다 — API는 현재 어느 순서든 허용하지만, 문서화된 순서는 ["TEXT", "IMAGE"]이며, 이로부터 벗어나면 미래 API 버전에서 문제가 발생할 수 있습니다. 작은 것이지만, 프로덕션 코드는 문서화된 관례를 따라야 합니다.
python"responseModalities": ["TEXT", "IMAGE"] # Accepted but not recommended "responseModalities": ["IMAGE", "TEXT"] # WRONG - silently returns empty response "responseModalities": ["IMAGE"] # WRONG - no images even requested "responseModalities": ["TEXT"]
미들웨어에 의한 imageConfig 제거
이것은 가장 미묘한 파라미터 실패 모드입니다. LiteLLM과 같은 미들웨어 레이어를 사용하여 Gemini API 호출을 프록시할 때, imageConfig 파라미터는 종종 Gemini API에 도달하기 전에 요청에서 제거됩니다. LiteLLM GitHub 이슈 #18656이 이 동작을 문서화합니다 — LiteLLM은 파라미터를 내부 형식으로 정규화하고, imageConfig는 이 정규화에서 살아남지 못합니다.
증상: 이미지가 생성되지만 해상도와 화면 비율 설정에 효과가 없습니다. 해결 방법은 Gemini 이미지 생성을 위해 미들웨어를 우회하고 네이티브 HTTP API를 직접 사용하는 것입니다. LiteLLM이나 유사한 도구를 인프라에 사용해야 하는 경우, 텍스트 생성은 미들웨어를 통해 라우팅하면서 이미지 생성 요청은 직접 라우팅해야 합니다.
다음은 미들웨어를 우회하여 API를 직접 호출하는 방법입니다:
pythonimport requests import base64 def generate_image_direct(prompt: str, api_key: str, size: str = "1K") -> bytes: """Direct HTTP call to Gemini Image API — bypasses middleware.""" url = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" headers = {"Content-Type": "application/json"} params = {"key": api_key} payload = { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], "imageConfig": { "image_size": size, # Must be "512", "1K", "2K", or "4K" "aspect_ratio": "16:9" # Optional } } } response = requests.post(url, json=payload, headers=headers, params=params) response.raise_for_status() data = response.json() for part in data["candidates"][0]["content"]["parts"]: if "inlineData" in part: return base64.b64decode(part["inlineData"]["data"]) raise ValueError("No image data in response — check responseModalities config")
직접 HTTP 페이로드에서 generationConfig가 imageConfig를 감싸고 있음에 주의하세요. 일부 SDK 버전은 플랫 generation_config 딕셔너리를 사용하지만, 네이티브 REST API는 위에 표시된 중첩 구조를 사용합니다. 이것도 파라미터 혼란의 또 다른 원인입니다 — SDK 인터페이스가 항상 기본 HTTP 요청 구조와 일치하지는 않습니다.
할당량 확인: GCP 콘솔 진단 가이드
할당량 상황을 이해하는 것은 429 오류를 진단하는 데 필수적이지만, 많은 개발자가 정확한 할당량 정보를 어디서 찾을 수 있는지 또는 숫자가 무엇을 의미하는지 모릅니다. GCP 콘솔은 신뢰할 수 있는 데이터를 가지고 있지만, 탐색하기가 명확하지 않습니다.
이미지 생성 할당량 찾기
GCP 콘솔의 정확한 탐색 경로 (2026-03-16 검증):
- console.cloud.google.com으로 이동
- 상단의 드롭다운에서 프로젝트를 선택
- API 및 서비스 → Generative Language API로 이동
- 왼쪽 사이드바에서 할당량 및 시스템 한도를 클릭
- 필터 바에서 "image"를 입력하여 이미지 관련 할당량 필터링
할당량 보기는 여러 차원을 표시합니다. 이미지 생성의 경우 중요한 것은 IPM (Images Per Minute) 입니다 — Gemini 이미지 생성이 제한되는 차원입니다. 텍스트 생성 호출을 관장하고 이미지 API 호출의 구속 제약이 아닌 RPM (Requests Per Minute)과 혼동하지 마세요.
할당량 차원 이해
Gemini 이미지 모델에는 세 가지 할당량 차원이 있습니다:
| 차원 | 제한 대상 | 일반 범위 |
|---|---|---|
| RPM (Requests Per Minute) | 분당 API 호출 | 텍스트 모델과 공유 |
| RPD (Requests Per Day) | 일당 API 호출 | 프리뷰 모델: 1,500/일 |
| IPM (Images Per Minute) | 분당 생성 이미지 | 이미지 특정; 가장 중요 |
2025년 12월 7일부터 무료 요금제 IPM은 0입니다 — 즉, 무료 계정은 API를 통해 이미지를 생성할 수 없습니다. 이것은 이전에 제한된 이미지 생성을 허용했던 이전 무료 요금제에서의 변경입니다. 이 날짜 이전에 업그레이드하여 기존 할당량이 있는 경우, GCP 콘솔에 현재 허용량이 표시됩니다. 2025년 12월 7일 이후 계정을 생성하거나 처음으로 API를 활성화한 경우, 청구를 활성화할 때까지 IPM이 0이 됩니다.
유료 Tier 1 계정(청구 활성화, Tier 2 임계값 미만)의 경우, SERP 분석(wentuo.ai, Firebase 문서, 2026-03-16)의 검증된 데이터는 약 10 IPM을 보여줍니다. 유료 Tier 2(더 높은 사용량)는 약 20 IPM을 제공합니다. Provisioned Throughput이 있는 Vertex AI는 Google과 협상된 전용 할당량을 제공하며, 공유 풀 제약을 제거합니다.
할당량 대시보드 해석
할당량 대시보드는 현재 사용량을 한도의 백분율로 표시합니다. "100%" 읽기는 해당 시간 창에 대한 한도에 도달했음을 의미합니다. 중요: 할당량 재설정은 고정된 시계 분이 아닌 롤링 창입니다. IPM 할당량은 롤링 60초 창으로 계산되므로, 12:00:00에 10개의 이미지를 생성하고 유료 Tier 1(10 IPM 한도)에 있다면, 12:01:00까지 더 이상 생성할 수 없습니다.
할당량이 0%이지만 여전히 429가 발생한다면, Ghost 429 버그(챕터 2의 근본 원인 3) 또는 최근 청구 변경 후 할당량 전파 문제에 대한 강력한 진단 신호입니다. 그 경우, 할당량 변경이 전파될 15-30분을 기다리고, 몇 시간 후에도 문제가 지속되면 챕터 2의 Ghost 429 가이던스를 확인하세요.
Gemini 이미지 생성을 위한 올바른 요금제 선택
사용하는 요금제는 비용과 신뢰성 모두에 주요한 영향을 미치며, 특히 프로덕션 애플리케이션에 그렇습니다. 절충점을 이해하면 프로덕션 부하에서 한계를 발견하는 것보다 올바른 인프라 결정을 내릴 수 있습니다.
| 요금제 | IPM | RPM | RPD | 최적 용도 |
|---|---|---|---|---|
| 무료 | 0 | 10 | 1,500 | 학습 전용 (이미지 없음) |
| 유료 Tier 1 | ~10 | 10 | 1,500 | 가벼운 프로덕션 사용 |
| 유료 Tier 2 | ~20 | 20+ | 3,000+ | 중간 프로덕션 |
| Vertex AI | 협상 | 협상 | 협상 | 대용량 프로덕션 |
프리뷰 모델 vs. 프로덕션 모델
gemini-3.1-flash-image-preview와 gemini-3-pro-image-preview 모델은 프리뷰 모델입니다 — Dynamic Shared Quota로 실행되며 프로덕션 모델과 동일한 신뢰성 보장을 제공하지 않습니다. Gemini 이미지 생성 기능의 경우, 이 글 작성 시점에 gemini-2.5-flash-image만이 안정적인(비프리뷰) 모델입니다.
프로덕션 사용 사례의 경우, 이것은 두 가지 방식으로 중요합니다. 첫째, 개인 할당량 내에 있어도 전 세계 혼잡으로 인해 프리뷰 모델 429가 발생할 수 있습니다. 둘째, 프리뷰 모델은 프로덕션 모델이 받는 전체 지원 중단 공지 없이 변경되거나 지원 중단될 수 있습니다. 몇 달 동안 안정적으로 실행해야 하는 것을 구축하고 있다면, 기능이 약간 다르더라도 안정 모델이 더 나은 기반입니다. 프리뷰 모델이 제공하는 것에 대한 전체 분석은 Gemini 3.1 Flash Image Preview 모델 기능 가이드를 참조하세요.
대안 API 제공업체를 고려할 때
AI Studio 요금제가 제공하는 것보다 더 높은 처리량이 필요하지만 전체 Vertex AI 통합을 설정할 준비가 되지 않은 경우, laozhang.ai와 같은 서드파티 API 애그리게이터는 다른 속도 제한 구조로 Gemini 이미지 모델을 제공합니다. 이는 개발, 테스트 또는 최고 사용 시 기본 API 액세스를 보완하는 데 유용할 수 있습니다. 애그리게이터 방식은 네트워크 홉을 추가하므로 중요한 애플리케이션의 주요 프로덕션 인프라가 되어서는 안 되지만, 기본 할당량이 소진될 때 유용한 폴백으로 사용할 수 있습니다.
프로덕션 규모의 이미지 생성의 경우, Provisioned Throughput이 있는 Vertex AI가 올바른 장기 솔루션입니다 — 공유 풀 할당량에서 다른 사용자와 경쟁하는 대신 전용 용량을 협상합니다.
프로덕션 준비 오류 처리 코드
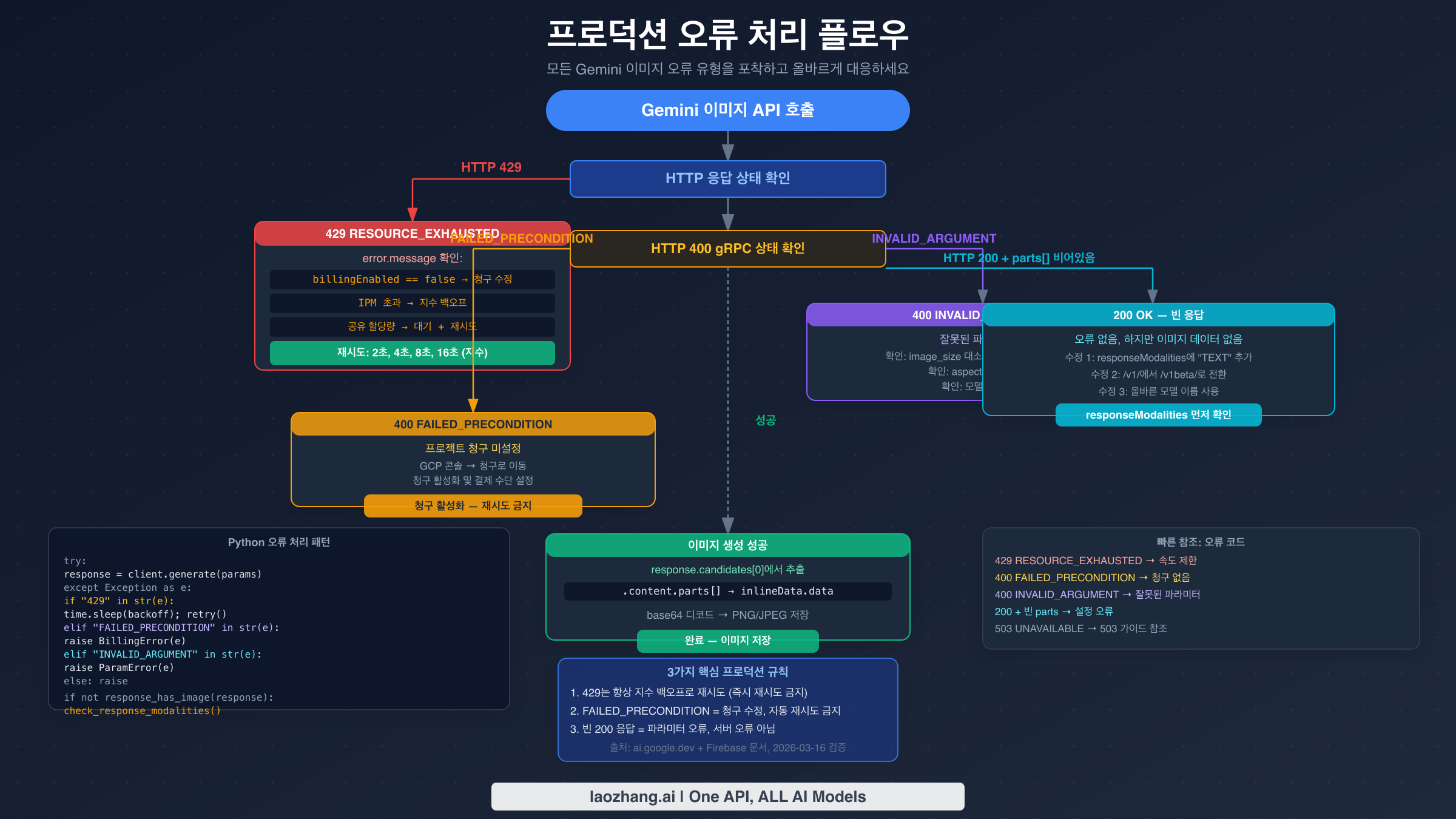
프로덕션 Gemini 이미지 생성은 세 가지 오류 카테고리를 모두 체계적으로 처리해야 합니다. 아래 코드는 올바른 오류 분류, 지수 백오프, 파라미터 유효성 검사, 빈 응답 감지가 포함된 완전한 Python 구현을 제공합니다.
pythonimport time import base64 import requests from typing import Optional from dataclasses import dataclass # Valid parameter constants (from official docs, verified 2026-03-16) VALID_IMAGE_SIZES = {"512", "1K", "2K", "4K"} VALID_ASPECT_RATIOS = {"1:1", "3:4", "4:3", "9:16", "16:9"} GEMINI_IMAGE_ENDPOINT = ( "https://generativelanguage.googleapis.com/v1beta/models/" "{model}:generateContent" ) @dataclass class ImageGenerationError(Exception): """Base class for Gemini image generation errors.""" message: str error_type: str # "rate_limit", "billing", "parameter", "empty_response" retryable: bool def validate_image_config(image_size: str, aspect_ratio: Optional[str] = None): """Validate imageConfig parameters before API call.""" if image_size not in VALID_IMAGE_SIZES: raise ImageGenerationError( message=f"Invalid image_size '{image_size}'. Valid values: {VALID_IMAGE_SIZES}. " f"Note: case-sensitive — use '1K' not '1k'.", error_type="parameter", retryable=False ) if aspect_ratio and aspect_ratio not in VALID_ASPECT_RATIOS: raise ImageGenerationError( message=f"Invalid aspect_ratio '{aspect_ratio}'. Valid: {VALID_ASPECT_RATIOS}", error_type="parameter", retryable=False ) def classify_error(response_or_exception) -> ImageGenerationError: """Classify API error into actionable categories.""" if isinstance(response_or_exception, requests.Response): status = response_or_exception.status_code try: body = response_or_exception.json() error_msg = str(body.get("error", {}).get("message", "")) grpc_status = body.get("error", {}).get("status", "") except Exception: error_msg = response_or_exception.text grpc_status = "" else: error_msg = str(response_or_exception) status = 500 grpc_status = "" if status == 429 or "RESOURCE_EXHAUSTED" in grpc_status: return ImageGenerationError( message=f"Rate limit exceeded: {error_msg}", error_type="rate_limit", retryable=True ) elif "FAILED_PRECONDITION" in grpc_status or "billing" in error_msg.lower(): return ImageGenerationError( message="Billing not enabled. Enable billing in GCP Console.", error_type="billing", retryable=False # Retrying won't help — fix billing first ) elif "INVALID_ARGUMENT" in grpc_status or status == 400: return ImageGenerationError( message=f"Invalid parameter: {error_msg}", error_type="parameter", retryable=False ) else: return ImageGenerationError( message=f"Unexpected error ({status}): {error_msg}", error_type="unknown", retryable=False ) def generate_image( prompt: str, api_key: str, model: str = "gemini-3.1-flash-image-preview", image_size: str = "1K", aspect_ratio: Optional[str] = None, max_retries: int = 5, initial_backoff: float = 2.0 ) -> bytes: """ Generate image with full error handling. Returns raw image bytes (PNG format). Raises ImageGenerationError with retryable flag for caller to handle. """ # Validate parameters before making API call validate_image_config(image_size, aspect_ratio) url = GEMINI_IMAGE_ENDPOINT.format(model=model) headers = {"Content-Type": "application/json"} params = {"key": api_key} image_config = {"image_size": image_size} if aspect_ratio: image_config["aspect_ratio"] = aspect_ratio payload = { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], # Both required "imageConfig": image_config } } last_error = None for attempt in range(max_retries): try: response = requests.post( url, json=payload, headers=headers, params=params, timeout=60 ) if not response.ok: error = classify_error(response) if not error.retryable: raise error last_error = error backoff = initial_backoff * (2 ** attempt) print(f"Attempt {attempt + 1}: {error.error_type}, retrying in {backoff}s") time.sleep(backoff) continue # HTTP 200 — check for actual image data data = response.json() candidates = data.get("candidates", []) if not candidates: raise ImageGenerationError( message="No candidates in response. Check model name and quota.", error_type="empty_response", retryable=False ) parts = candidates[0].get("content", {}).get("parts", []) for part in parts: if "inlineData" in part: return base64.b64decode(part["inlineData"]["data"]) # 200 OK but no image data — common config error raise ImageGenerationError( message=( "HTTP 200 but no image in response. " "Verify responseModalities includes both 'TEXT' and 'IMAGE'. " "Check you're using /v1beta/ endpoint." ), error_type="empty_response", retryable=False ) except ImageGenerationError: raise # Don't retry non-retryable errors except requests.RequestException as e: last_error = classify_error(e) if attempt < max_retries - 1: backoff = initial_backoff * (2 ** attempt) time.sleep(backoff) raise last_error or ImageGenerationError( message="Max retries exceeded", error_type="rate_limit", retryable=True ) # Usage example if __name__ == "__main__": try: image_bytes = generate_image( prompt="A serene mountain lake at sunset", api_key="YOUR_API_KEY", model="gemini-3.1-flash-image-preview", image_size="1K", aspect_ratio="16:9" ) with open("output.png", "wb") as f: f.write(image_bytes) print("Image saved to output.png") except ImageGenerationError as e: print(f"Error type: {e.error_type}") print(f"Message: {e.message}") print(f"Retryable: {e.retryable}") if e.error_type == "billing": print("Action: Enable billing at console.cloud.google.com/billing") elif e.error_type == "parameter": print("Action: Fix parameters — check image_size casing and aspect_ratio format") elif e.error_type == "empty_response": print("Action: Add 'TEXT' to responseModalities and verify /v1beta/ endpoint")
JavaScript/Node.js 버전
javascriptconst fetch = require('node-fetch'); const VALID_IMAGE_SIZES = new Set(['512', '1K', '2K', '4K']); async function generateImage(prompt, apiKey, options = {}) { const { model = 'gemini-3.1-flash-image-preview', imageSize = '1K', aspectRatio = null, maxRetries = 5, } = options; if (!VALID_IMAGE_SIZES.has(imageSize)) { throw new Error(`Invalid imageSize '${imageSize}'. Use: ${[...VALID_IMAGE_SIZES].join(', ')}`); } const url = `https://generativelanguage.googleapis.com/v1beta/models/${model}:generateContent?key=${apiKey}`; const imageConfig = { image_size: imageSize }; if (aspectRatio) imageConfig.aspect_ratio = aspectRatio; const payload = { contents: [{ parts: [{ text: prompt }] }], generationConfig: { responseModalities: ['TEXT', 'IMAGE'], imageConfig, }, }; for (let attempt = 0; attempt < maxRetries; attempt++) { const response = await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload), }); if (response.status === 429) { if (attempt === maxRetries - 1) throw new Error('Max retries exceeded (429)'); const delay = Math.pow(2, attempt + 1) * 1000; await new Promise(r => setTimeout(r, delay)); continue; } if (!response.ok) { const body = await response.json(); const status = body?.error?.status || ''; if (status === 'FAILED_PRECONDITION') { throw new Error('Billing not enabled. Enable billing in GCP Console.'); } throw new Error(`API error ${response.status}: ${JSON.stringify(body?.error)}`); } const data = await response.json(); const parts = data?.candidates?.[0]?.content?.parts || []; const imagePart = parts.find(p => p.inlineData); if (!imagePart) { throw new Error( 'HTTP 200 but no image data. Check responseModalities includes TEXT and IMAGE.' ); } return Buffer.from(imagePart.inlineData.data, 'base64'); } }
기본 할당량이 소진될 때 여러 모델과 폴백 전략을 처리해야 하는 고동시성 프로덕션 시나리오의 경우, laozhang.ai의 이미지 엔드포인트와 같은 API 애그리게이터가 폴백으로 사용될 수 있습니다. 애그리게이터는 내부적으로 속도 제한을 처리하므로, 기본 API가 제한될 때 오류 처리 코드가 단순화됩니다.
자주 묻는 질문
Gemini 이미지 API 호출이 HTTP 200을 반환하지만 이미지가 없는 이유는 무엇인가요?
가장 일반적인 원인은 responseModalities가 ["TEXT", "IMAGE"] 대신 ["IMAGE"]로 설정된 것입니다. Gemini 이미지 API는 TEXT와 IMAGE 모달리티 모두를 필요로 합니다 — TEXT를 생략하면 API가 오류 없이 빈 응답을 반환합니다. generationConfig를 확인하고 두 값이 모두 포함되어 있는지 확인하세요. 올바르다면, /v1/이나 OpenAI 호환 엔드포인트가 아닌 /v1beta/ 엔드포인트를 사용하고 있는지 확인하세요.
유료 플랜으로 업그레이드한 후 Gemini 이미지 API 429 오류를 어떻게 수정하나요?
먼저 업그레이드한 지 얼마나 되었는지 확인하세요. 24-48시간 이내라면 Ghost 429 버그(새 청구 활성화가 즉시 할당량을 전파하지 않는 2026년 2월의 알려진 문제)의 영향을 받을 수 있습니다. 일시적으로 다른 모델 변형으로 전환해 보세요. GCP 콘솔에 0이 아닌 할당량이 표시되는데 48시간 이상 429가 지속되면, 할당량 전파 문제를 참조하는 지원 티켓을 제출하세요. 또한 GCP 콘솔에서 IPM(Images Per Minute) 할당량이 실제로 0이 아닌지 확인하세요 — 청구 활성화가 자동으로 이미지 할당량을 0이 아닌 값으로 설정하는 것은 아닙니다.
imageConfig 설정이 왜 무시되나요?
두 가지 일반적인 원인: 대소문자 구분 또는 미들웨어 제거. 대소문자 구분의 경우, image_size 값이 대문자 K를 사용하는지 확인하세요 — "1K" (소문자 "1k" 아님). 미들웨어 제거의 경우, LiteLLM이나 유사한 프록시 레이어를 통해 라우팅하고 있다면 imageConfig가 Gemini API에 도달하기 전에 제거될 수 있습니다. 해결 방법은 미들웨어를 거치지 않고 이미지 생성을 위해 Gemini API에 직접 HTTP 호출을 하는 것입니다.
Gemini 이미지 모델의 IPM과 RPM 할당량의 차이는 무엇인가요?
RPM(Requests Per Minute)은 분당 API 호출 수를 제한하며 모든 Gemini 모델에 적용됩니다. IPM(Images Per Minute)은 이미지 특정이며 분당 생성할 수 있는 개별 이미지 수를 제한합니다. numberOfImages가 1보다 크게 설정된 경우 하나의 API 호출이 여러 이미지를 생성할 수 있으며, 각 이미지는 IPM 할당량에 개별적으로 집계됩니다. IPM 할당량은 이미지 생성의 구속 제약이 되는 경향이 있습니다 — 대부분의 사용 패턴에서 RPM보다 IPM에 먼저 도달합니다.
Gemini 프리뷰 이미지 모델을 프로덕션에서 사용해도 안전한가요?
프리뷰 모델(gemini-3.1-flash-image-preview, gemini-3-pro-image-preview)은 Dynamic Shared Quota를 사용하므로, 개인 할당량 한도 내에 있어도 전 세계 혼잡으로 인해 429 오류가 반환될 수 있습니다. 개발 및 가벼운 프로덕션 사용에는 괜찮지만, SLA 요구 사항이 있는 애플리케이션의 경우 안정적인 gemini-2.5-flash-image 모델이나 Provisioned Throughput이 있는 Vertex AI를 사용하세요. 프리뷰 모델은 프로덕션 모델보다 적은 공지로 변경되거나 지원 중단될 수도 있습니다.
결론 및 다음 단계
Gemini 이미지 API 오류는 다른 문제가 동일하게 보이는 증상을 만들어내기 때문에 진정으로 혼란스럽습니다. 429는 무료 요금제에 0 할당량이 있다는 것, 유료 할당량이 소진되었다는 것, 알려진 버그에 걸렸다는 것, 또는 전 세계 혼잡을 경험하고 있다는 것을 의미할 수 있습니다 — 각 시나리오는 완전히 다른 대응이 필요합니다. 빈 HTTP 200은 파라미터 설정 오류, 잘못된 엔드포인트, 또는 미들웨어 간섭을 의미할 수 있습니다.
모든 오류 유형에서 작동하는 진단 순서: 먼저 청구 확인 (GCP 콘솔 → API 및 서비스 → Generative Language API → 할당량), 그 다음 파라미터 확인 (responseModalities: ["TEXT", "IMAGE"], image_size: "1K" 대문자), 그 다음 엔드포인트 확인 (/v1beta/ 아니면 /v1/). 대부분의 문제는 이 세 가지 체크포인트 중 하나에서 해결됩니다.
프로덕션 애플리케이션의 경우, 처음부터 코드에 오류 분류를 포함하세요 — 재시도 가능한 429와 재시도할 수 없는 청구 오류 및 파라미터 오류를 구별하면 나중에 운영상의 어려움을 줄일 수 있습니다. 챕터 7의 완전한 코드 예제는 이 분류를 기본으로 제공합니다.
할당량 한도에 지속적으로 부딪히고 Vertex AI 프로비저닝의 복잡성 없이 더 많은 처리량이 필요한 경우, IPM 한도 내에 머물기 위한 일괄 생성 전략을 검토하거나, Tier 2 할당량 임계값이 요구 사항을 충족하는지 탐색해 보세요. 할당량 구조는 사용량에 따라 확장되도록 설계되었습니다 — 한계로 시작하는 것이 워크로드에 대한 구속 제약인 차원을 이해하면 관리 가능해집니다.