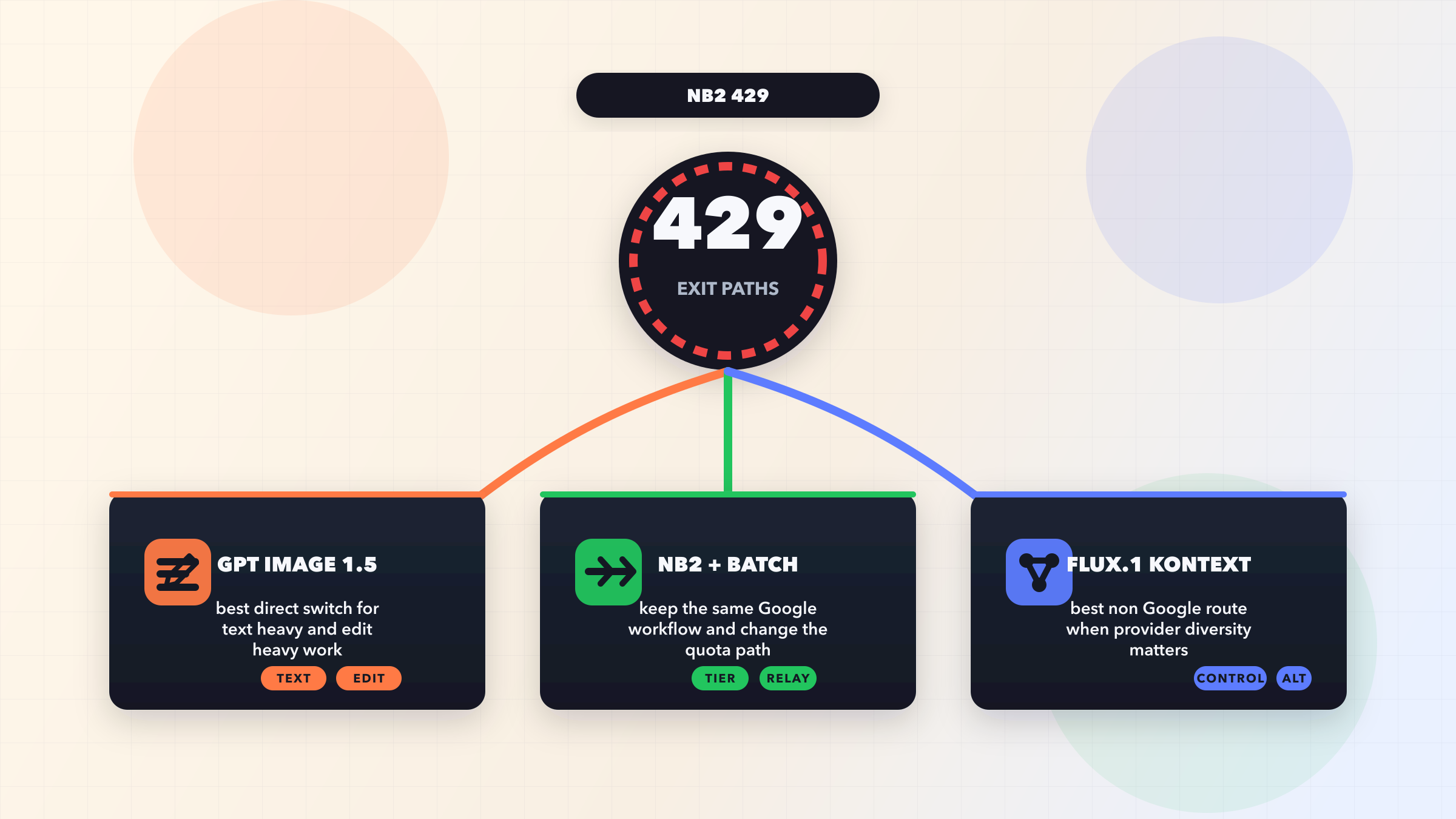
Gemini 이미지 생성 429 오류는 애플리케이션이 Google의 4가지 요청 제한 차원인 분당 요청 수(RPM), 일일 요청 수(RPD), 분당 토큰 수(TPM), 또는 많은 개발자가 간과하는 분당 이미지 수(IPM) 중 하나를 초과할 때 발생합니다. 가장 빠른 해결 방법은 지터를 포함한 지수 백오프를 구현하는 것으로, 버스트 트래픽에서 80%의 실패율을 99% 이상의 성공률로 전환할 수 있습니다. 다만 무료 티어를 사용 중이라면 먼저 결제를 활성화해야 합니다. 2025년 12월 이후 무료 티어의 IPM이 0으로 떨어져 유료 계정 없이는 이미지 생성이 사실상 불가능하기 때문입니다. Tier 1은 최소 지출 없이 즉시 10 IPM을 제공합니다.
Gemini 이미지 생성에서 429 오류가 발생하는 이유
모든 API 제공업체는 인프라를 남용으로부터 보호하고 전체 사용자에게 공정한 리소스 분배를 보장하기 위해 요청 제한을 구현합니다. Gemini API 요청이 결제 티어에 할당된 쿼터를 초과하면 Google 서버는 HTTP 상태 코드 429와 함께 RESOURCE_EXHAUSTED 오류 메시지를 반환합니다. 이는 코드의 버그나 Gemini 모델 자체의 문제가 아닙니다. Google이 프로젝트에 설정한 쿼터 경계를 API 게이트웨이가 적용하는 것입니다. 이 오류의 메커니즘을 이해하는 것이 중단 없이 프로덕션 규모의 워크로드를 처리할 수 있는 견고한 이미지 생성 파이프라인을 구축하기 위한 첫 번째 단계입니다.
Gemini API의 429 응답에는 많은 개발자가 간과하는 특정 구조가 포함되어 있습니다. 응답 본문에는 RESOURCE_EXHAUSTED 상태 코드, 어떤 쿼터가 초과되었는지 설명하는 메시지, 그리고 중요한 메타데이터 헤더인 x-ratelimit-limit, x-ratelimit-remaining, x-ratelimit-reset이 포함된 error 필드를 가진 JSON 객체가 있습니다. 이 헤더들은 정확히 어떤 차원이 제한을 트리거했는지와 언제 리셋되는지를 알려줍니다. 많은 개발자가 단순히 429를 잡고 무작정 재시도하지만, 이 헤더를 파싱하면 무차별적인 재시도 대신 목표에 맞는 해결책을 구현할 수 있는 정보를 얻을 수 있습니다. x-ratelimit-remaining에서 IPM이 0인데 RPM에는 아직 여유가 있다면, 병목이 일반 요청 볼륨이 아닌 이미지 생성 처리량에 있다는 것을 알 수 있습니다.
4가지 요청 제한 차원
Google은 4개의 독립적인 차원에 걸쳐 요청 제한을 적용하며, 어느 하나라도 초과하면 429 오류가 발생합니다. 대부분의 개발자는 RPM과 RPD에 익숙하지만, 2025년 말 Gemini의 네이티브 이미지 생성 기능과 함께 도입된 IPM은 많은 팀을 당황하게 했습니다. 각 차원은 독립적으로 운영됩니다. RPM 제한 이내에 있더라도 IPM 쿼터가 소진되면 제한될 수 있습니다. 아래 표는 각 차원과 이미지 생성 워크로드에 미치는 영향을 정리한 것입니다.
| 차원 | 전체 이름 | 측정 대상 | 이미지 생성에 미치는 영향 |
|---|---|---|---|
| RPM | 분당 요청 수 | 60초 윈도우 내 총 API 호출 | 텍스트 포함 모든 Gemini 호출에 영향 |
| RPD | 일일 요청 수 | 24시간 윈도우 내 총 API 호출 (태평양 시간 자정 리셋) | 모든 작업의 일일 볼륨 제한 |
| TPM | 분당 토큰 수 | 분당 처리되는 총 입출력 토큰 | 주로 텍스트에 영향; 이미지는 고정 토큰 블록으로 계산 |
| IPM | 분당 이미지 수 | 분당 생성되는 이미지 수 | 숨겨진 킬러 — 이미지 출력을 직접 제한 |
IPM: 대부분의 개발자가 놓치는 숨겨진 킬러
분당 이미지 수(IPM)는 Gemini의 이미지 생성 기능을 통합하는 개발자들 사이에서 가장 많은 혼란을 유발하는 요청 제한 차원입니다. 텍스트 완성을 포함한 모든 API 요청을 관리하는 RPM과 달리, IPM은 60초 슬라이딩 윈도우 내에서 애플리케이션이 생성하는 이미지 수를 구체적으로 계산합니다. 4개의 이미지를 생성하는 단일 API 호출은 1 RPM이 아닌 4 IPM을 소비합니다. 이는 RPM 쿼터 이내에 있더라도 요청이 자주 여러 이미지를 생성하면 IPM 상한에 도달할 수 있음을 의미합니다. 2025년 12월에 무료 티어의 IPM이 0으로 떨어졌기 때문에 문제는 더욱 심각해졌습니다. 미결제 계정에서의 모든 이미지 생성 시도는 요청을 처리하지도 않고 즉시 429를 반환합니다. 첫 429 오류를 디버깅하는 많은 개발자가 코드 로직을 확인하느라 몇 시간을 낭비하는데, 실제 문제는 단순히 결제 티어가 이미지 생성을 전혀 허용하지 않는다는 것입니다.
2026년 2월 고스트 429 버그
2026년 2월 초부터 유료 Tier 1 계정의 여러 개발자가 사용량 대시보드에서 쿼터 대비 0이거나 거의 0에 가까운 소비를 보여주고 있음에도 429 RESOURCE_EXHAUSTED 오류를 수신한다고 보고했습니다. 이 "고스트 429" 버그는 Google의 쿼터 추적 시스템에서 특정 프로젝트 구성에 대한 사용량을 잘못 계산하는 서버 측 이슈로 보입니다. 이 버그는 주로 무료에서 Tier 1로 최근 업그레이드한 계정에 영향을 미치며, 결제 활성화 후 첫 24-48시간 동안 가장 흔하게 나타납니다. Google은 개발자 포럼에서 이 이슈를 인정하고 엔지니어링 팀이 조사하는 동안 임시 해결 방법으로 다른 모델 변형으로 전환(예: gemini-3.1-flash에서 gemini-3-pro로)을 권장했습니다. Google Cloud Console 쿼터 대시보드에서 실제 사용량이 0인 상태에서 429 오류가 발생한다면, 설정 오류가 아닌 이 버그가 가장 유력한 원인입니다. Gemini API 오류 코드와 해결 방법에 대한 전반적인 이해가 필요하다면 Gemini API 오류 트러블슈팅 가이드를 참조하세요. 전체 요청 제한 시스템을 상세히 이해하고 싶다면 Gemini API 요청 제한 완벽 가이드에서 모든 티어와 차원을 다룹니다.
빠른 진단 — 어떤 요청 제한에 걸렸는가?
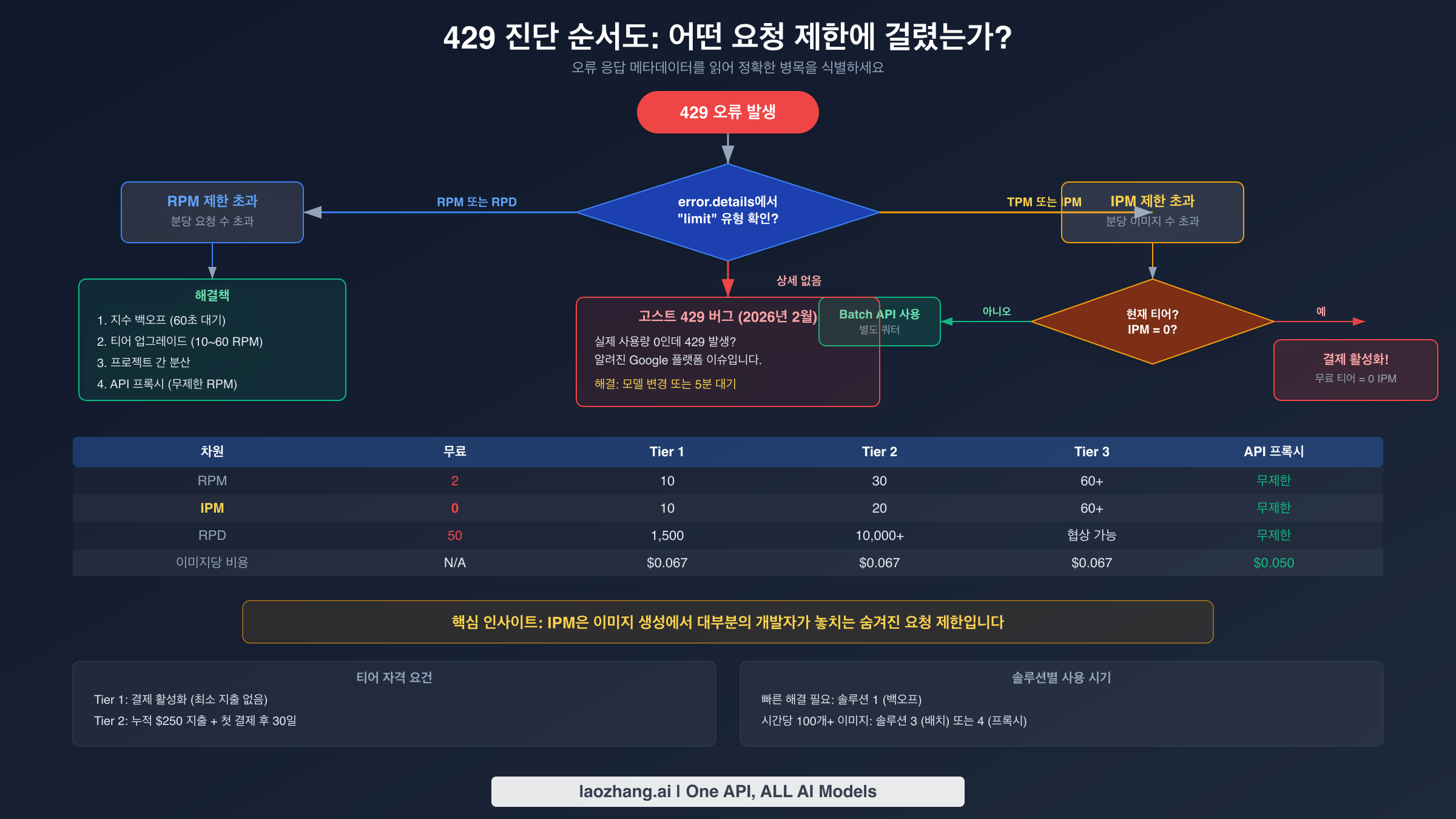
솔루션으로 넘어가기 전에 어떤 요청 제한 차원이 요청을 차단하고 있는지 정확히 파악해야 합니다. 잘못된 해결책을 적용하면 시간을 낭비합니다. 지수 백오프는 RPM 문제를 해결하지만 티어 업그레이드가 필요한 IPM 병목에는 아무런 효과가 없습니다. 진단 과정에서는 API의 오류 응답과 시간에 따른 사용 패턴을 모두 살펴봐야 합니다. Google은 429 오류 본문에 항상 명시적인 차원 정보를 포함하지는 않으므로, 오류 발생 시점과 알려진 요청 패턴을 상관시켜 원인을 좁혀야 하는 경우가 많습니다. 다행히 각 요청 제한 차원은 체계적인 접근으로 식별할 수 있는 고유한 실패 패턴을 생성합니다.
오류 응답 메타데이터 읽기
어떤 요청 제한에 걸렸는지 가장 직접적으로 확인하는 방법은 429 응답의 응답 헤더와 오류 본문을 파싱하는 것입니다. Google은 응답 헤더에 요청 제한 메타데이터를 포함하지만, 어떤 쿼터가 소진되었느냐에 따라 포함되는 정확한 헤더가 달라질 수 있습니다. 다음 Python 스니펫은 실패한 요청에서 이 진단 정보를 추출하고 로깅하는 방법을 보여줍니다. 이 코드는 429 예외를 잡고, 모든 요청 제한 관련 헤더를 추출하며, 어떤 차원이 병목인지 즉시 알 수 있는 구조화된 진단 보고서를 출력합니다.
pythonimport google.generativeai as genai from google.api_core.exceptions import ResourceExhausted def diagnose_rate_limit(api_key: str, prompt: str): genai.configure(api_key=api_key) model = genai.GenerativeModel("gemini-3.1-flash") try: response = model.generate_content(prompt) return response except ResourceExhausted as e: print(f"429 RESOURCE_EXHAUSTED: {e.message}") # Parse error details for quota dimension if hasattr(e, 'errors') and e.errors: for error in e.errors: metadata = error.get('metadata', {}) print(f" Quota dimension: {metadata.get('quota_dimension', 'unknown')}") print(f" Quota limit: {metadata.get('quota_limit', 'unknown')}") print(f" Quota usage: {metadata.get('quota_usage', 'unknown')}") # Check for ghost 429 pattern if "usage: 0" in str(e) or "quota_usage: 0" in str(e.errors): print(" WARNING: Ghost 429 detected (usage=0).") print(" This matches the known Feb 2026 bug.") print(" Try switching model: gemini-3-pro or imagen-4") raise
세 가지 실패 패턴
오류 메타데이터를 파싱하는 것 외에도, 실패의 시간적 패턴을 관찰하여 요청 제한 차원을 식별할 수 있습니다. RPM, RPD, IPM이 서로 다른 시간 윈도우에서 작동하기 때문에 각 차원은 고유한 시그니처를 생성합니다. 이러한 패턴을 이해하는 것은 오류 메타데이터가 불완전하거나 로그만으로 작업하는 프로덕션 환경에서 이슈를 디버깅할 때 필수적입니다. 주의해야 할 세 가지 패턴은 다음과 같습니다.
첫 번째 패턴은 "버스트 후 성공"입니다. 애플리케이션이 빠르게 요청을 연속 전송하고 여러 429 오류를 받은 후 30-60초 대기하면 성공합니다. 이 패턴은 RPM 제한 위반을 강하게 나타냅니다. 60초 슬라이딩 윈도우가 지속적으로 리셋되므로 짧은 대기가 쿼터를 복원합니다. 두 번째 패턴은 "아침에는 작동, 밤에는 실패"입니다. 애플리케이션이 하루 초반에는 잘 동작하다가 나중에는 지속적으로 실패합니다. 이는 RPD 소진을 나타내며, 일일 쿼터가 소비되어 태평양 시간 자정까지 리셋되지 않습니다. 세 번째이자 가장 교활한 패턴은 "이미지만 실패"입니다. 텍스트 생성 요청은 완벽하게 성공하지만 모든 이미지 생성 요청이 429를 반환합니다. 이것이 IPM 소진의 특징이며, RPM 제한 이내에 있지만 이미지 전용 쿼터를 모두 사용한 개발자에게 가장 흔한 함정입니다.
유료 계정에서 429 오류가 발생하지만 Google Cloud Console에서 쿼터 대비 사용량이 0으로 표시된다면, 위에서 문서화한 고스트 429 버그를 겪고 있을 가능성이 높습니다. 이는 정상적인 쿼터 소진과는 별개의 이슈입니다. 무료 티어에서 Tier 1로 최근 업그레이드한 개발자는 이 패턴에 특히 주의해야 합니다. 정당한 요청 제한과 결제 티어 불일치를 구분하는 방법에 대한 자세한 내용은 유료 티어 계정이 무료 티어 요청 제한을 받는 경우 가이드를 확인하세요.
솔루션 1 — 스마트 재시도를 포함한 지수 백오프
지수 백오프는 429 오류에 대해 구현할 수 있는 가장 효과적인 단일 해결책이며, 인프라 변경이나 결제 수정이 전혀 필요 없습니다. 원리는 간단합니다. 요청이 429로 실패하면 기하급수적으로 증가하는 시간만큼 대기한 후 재시도합니다 — 1초, 2초, 4초, 8초 순으로 증가합니다. 이를 통해 속도 제한기가 용량을 해제할 시간을 확보하고 쿼터 복구 기간 동안 API를 과도하게 호출하는 것을 방지합니다. 실제로 잘 구현된 지수 백오프는 피크 부하 시 80%의 시간 동안 실패하는 애플리케이션을 결국 99% 이상의 요청에서 성공하도록 변환합니다. 다만 트레이드오프로 여러 번 재시도가 필요한 요청의 지연 시간이 증가합니다.
지터가 중요한 이유: 선더링 허드 문제
단순한 지수 백오프는 애플리케이션의 여러 인스턴스에 배포할 때 치명적인 결함이 있습니다. 10개의 애플리케이션 서버가 모두 동일한 순간에 429에 도달하고 동일한 지수 백오프를 구현하면, 모두 정확히 같은 시간에 재시도합니다 — 1초 후, 2초 후, 4초 후. 이러한 동기화된 재시도 동작은 정확한 간격으로 속도 제한기를 반복적으로 압도하는 "선더링 허드"를 생성하여 혼잡을 개선하기보다 악화시킵니다. 랜덤 지터 — 각 대기 시간에 작은 랜덤 변동을 추가하면 — 모든 인스턴스에서 재시도 시도를 비동기화합니다. 10개 서버가 모두 t+1초에 재시도하는 대신 t+0.7초, t+1.2초, t+0.9초 등에 재시도하여 복구 윈도우 전체에 부하를 고르게 분산합니다. 이 간단한 추가는 분산 시스템에서 성공률을 극적으로 향상시키며 Google, AWS, Azure를 포함한 모든 주요 클라우드 제공업체가 모범 사례로 권장합니다.
Tenacity를 사용한 Python 구현
tenacity 라이브러리는 Python에서 지수 백오프를 구현하는 가장 우아한 방법을 제공합니다. 재시도 로직, 지터, 최대 시도 횟수 제한, 예외 필터링의 모든 복잡성을 깔끔한 데코레이터 구문으로 처리합니다. 다음 구현은 프로덕션에 바로 적용할 수 있으며 로깅, 구성 가능한 타임아웃, 429 오류와 재시도하지 않아야 하는 다른 API 예외에 대한 구체적인 처리를 포함합니다.
pythonimport tenacity import google.generativeai as genai from google.api_core.exceptions import ResourceExhausted import logging logger = logging.getLogger(__name__) @tenacity.retry( retry=tenacity.retry_if_exception_type(ResourceExhausted), wait=tenacity.wait_exponential(multiplier=1, min=2, max=60) + tenacity.wait_random(0, 2), # jitter stop=tenacity.stop_after_attempt(8), before_sleep=tenacity.before_sleep_log(logger, logging.WARNING), reraise=True, ) def generate_image_with_retry(model, prompt: str): """Generate image with automatic exponential backoff on 429 errors.""" response = model.generate_content( prompt, generation_config=genai.GenerationConfig( response_modalities=["image", "text"], ), ) return response genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash") try: result = generate_image_with_retry(model, "A futuristic cityscape at sunset") # Process result.candidates[0].content.parts for image data except ResourceExhausted: logger.error("All retries exhausted. Consider upgrading tier.")
p-retry를 사용한 Node.js 구현
Node.js 애플리케이션의 경우 p-retry 패키지가 async/await 패턴과 깔끔하게 통합되는 프로미스 기반 API로 동등한 기능을 제공합니다. 다음 구현은 Python 버전과 동일한 동작을 미러링하며 지터, 최대 시도 횟수, 로깅, 인증 실패나 유효하지 않은 프롬프트와 같이 재시도하지 않아야 하는 오류에 대한 적절한 분류 등 동일한 프로덕션 보호 장치를 포함합니다.
javascriptconst pRetry = require('p-retry'); const { GoogleGenerativeAI } = require('@google/generative-ai'); const genAI = new GoogleGenerativeAI('YOUR_API_KEY'); async function generateImageWithRetry(prompt) { const model = genAI.getGenerativeModel({ model: 'gemini-3.1-flash' }); return pRetry( async (attemptNumber) => { console.log(`Attempt ${attemptNumber} for image generation...`); const result = await model.generateContent({ contents: [{ role: 'user', parts: [{ text: prompt }] }], generationConfig: { responseModalities: ['image', 'text'] }, }); return result.response; }, { retries: 7, minTimeout: 2000, // 2 seconds initial wait maxTimeout: 60000, // 60 seconds maximum wait factor: 2, // exponential factor randomize: true, // adds jitter automatically onFailedAttempt: (error) => { if (error.status !== 429) { throw error; // don't retry non-429 errors } console.warn( `Rate limited. Attempt ${error.attemptNumber} failed. ` + `${error.retriesLeft} retries remaining.` ); }, } ); }
지수 백오프 프로덕션 팁: 최대 재시도 횟수를 6~10회로 설정하세요. 기본 대기 2초, 팩터 2일 때 8번의 시도가 약 8.5분의 총 대기 윈도우를 커버하며, 이는 RPM 제한 리셋에 충분합니다. 요청이 무한정 대기하는 것을 방지하기 위해 개별 재시도뿐 아니라 전체 작업에 절대 타임아웃을 설정하세요. 프로덕션 대시보드에서 429 비율을 모니터링하고 재시도에만 의존하기보다 티어 업그레이드가 필요한 시점을 파악할 수 있도록 시도 번호와 대기 시간을 포함하여 모든 재시도를 로깅하세요.
솔루션 2 — 결제 티어 업그레이드
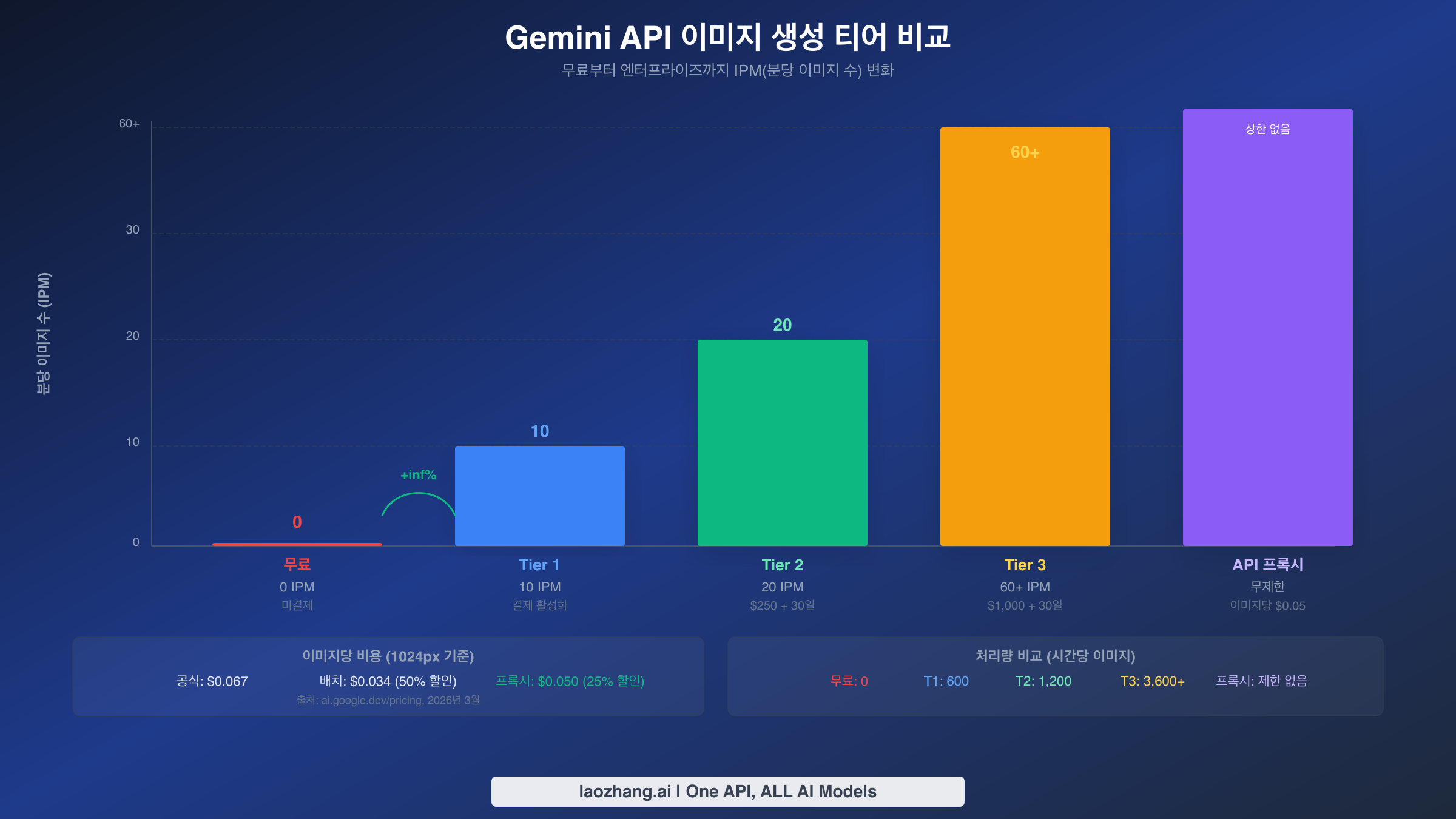
지수 백오프가 일시적인 요청 제한 스파이크를 처리하는 반면, 지속적인 429 오류에 대한 가장 신뢰할 수 있는 장기 솔루션은 Google Cloud 결제 티어를 업그레이드하는 것입니다. 각 티어 증가는 4가지 요청 제한 차원 모두에서 쿼터를 배가시키며, 이미지 생성에 있어서는 IPM 증가가 가장 큰 영향을 미칩니다. 많은 개발자가 무료 티어가 이미지 생성을 사실상 완전히 비활성화한다는 것을 모릅니다 — IPM 쿼터가 2025년 12월에 0으로 줄었기 때문입니다. Google Cloud 프로젝트에서 결제를 활성화하기만 하면 즉시 Tier 1로 승격되어 최소 지출 요건 없이 10 IPM이 해제됩니다. 이 단일 조치만으로 개발자가 초기 통합 및 테스트 중에 겪는 429 오류의 대부분이 해결됩니다.
이미지 생성을 위한 티어 비교
각 티어의 구체적인 쿼터를 이해하는 것은 워크로드에 맞는 올바른 수준을 선택하는 데 필수적입니다. 다음 표는 사용 가능한 모든 티어에서 이미지 생성에 직접 영향을 미치는 요청 제한을 보여줍니다. Tier 3 제한은 Google Cloud 영업팀과 협상 가능하므로 표시된 숫자는 하드 최댓값이 아닌 표준 기준선을 나타냅니다.
| 티어 | 월간 지출 요건 | 시간 요건 | RPM | RPD | IPM | Batch TPD | 이미지당 비용 (1K) |
|---|---|---|---|---|---|---|---|
| 무료 | 없음 | 없음 | 2 | 50 | 0 | N/A | N/A (차단됨) |
| Tier 1 | 결제 활성화 (최소 금액 없음) | 즉시 | 10 | 1,500 | 10 | 1M 토큰 | $0.067 |
| Tier 2 | 누적 $250 | Tier 1에서 30일 | 30 | 10,000+ | 20 | 250M 토큰 | $0.067 |
| Tier 3 | 누적 $1,000 | Tier 2에서 30일 | 60+ | 협상 가능 | 60+ | 750M 토큰 | $0.067 |
무료에서 Tier 1로의 업그레이드는 0 IPM(이미지 생성 전혀 불가)에서 10 IPM으로 전환하기 때문에 가장 큰 영향을 미칩니다. 이는 개발, 테스트 및 저트래픽 프로덕션 애플리케이션에 충분합니다. 분당 10개의 이미지는 시간당 600개 또는 지속적으로 유지할 경우 하루 약 14,400개의 이미지로 환산되며, 대부분의 중소 규모 애플리케이션에 충분합니다. Tier 1에서 Tier 2로의 업그레이드는 IPM을 20으로 두 배로 늘리고 RPD를 1,500에서 10,000 이상으로 대폭 증가시키므로, 버스트가 아닌 하루 종일 이미지를 생성하는 애플리케이션에 중요합니다.
현재 티어를 확인하고 업그레이드하는 방법
현재 결제 티어를 확인하려면 Google Cloud Console로 이동하여 프로젝트의 결제 상태를 확인해야 합니다. Google Cloud Console로 이동하여 프로젝트를 선택하고, 결제(Billing)로 이동한 다음 Generative Language API 섹션의 "쿼터 및 시스템 제한(Quotas & System Limits)" 페이지를 확인하세요. 현재 티어가 각 쿼터 메트릭과 함께 표시됩니다. IPM이 0으로 표시되면 결제 페이지에 무엇이 표시되든 무료 티어입니다 — 프로젝트에 결제 계정이 연결되어 있어도 Generative AI API에 대해 구체적으로 결제가 활성화된 것은 아니기 때문에 이것이 혼란의 일반적인 원인입니다. 결제 계정이 프로젝트에 연결되어 있고 Generative Language API의 API 대시보드에서 결제가 활성화되어 있는지 확인해야 합니다. 유료 계정이 무료 티어 제한을 받는 지속적인 이슈를 겪는 개발자는 모든 확인 단계를 안내하는 Gemini 이미지 생성 무료 티어 제한 전용 가이드를 참조하세요.
티어 업그레이드 일정: Tier 1 활성화는 결제가 활성화되면 즉시 이루어집니다. Tier 2는 누적 $250의 지출과 30일의 활성 Tier 1 사용이 모두 필요합니다 — 하루에 $250을 지출해도 가속할 수 없습니다. Tier 3도 마찬가지로 누적 $1,000의 지출과 Tier 2에서 30일이 필요합니다. 이러한 시간 게이트는 Google Cloud 지원 티켓을 통해 우회할 수 없으므로 확장 요구 사항보다 앞서 티어 진행을 계획하세요.
솔루션 3 — 대량 생성을 위한 Batch API 활용
Gemini Batch API는 대량의 이미지를 생성해야 하지만 실시간 응답이 필요하지 않은 개발자에게 활용도가 낮은 솔루션입니다. Batch API의 핵심 장점은 실시간 API와 완전히 별도의 쿼터 풀에서 작동한다는 것입니다. 즉, 배치 이미지 생성 요청은 RPM, RPD 또는 IPM 제한에 포함되지 않습니다. 이러한 분리로 인해 Batch API는 실시간 파이프라인의 강력한 보완 수단이 됩니다 — 비긴급 이미지 생성은 배치 처리로 오프로드하면서 대화형 사용자 대면 요청을 위해 실시간 쿼터를 보존할 수 있습니다. 또한 Google은 모든 배치 API 요청에 50% 비용 할인을 제공하여 대량 워크로드에서 실시간 생성보다 훨씬 저렴합니다.
배치 처리 작동 방식
Batch API는 비동기 작업 기반 모델을 따릅니다. 프롬프트 배치를 단일 작업으로 제출하면 Google이 처리를 위해 대기열에 넣고, 작업이 완료될 때까지 결과를 폴링합니다. 서비스 수준 계약은 24시간 이내 완료를 보장하지만, 실제로는 볼륨과 현재 시스템 부하에 따라 대부분의 배치 작업이 2-6시간 내에 완료됩니다. 각 배치 작업은 최대 100개의 요청을 포함할 수 있으며, 여러 배치 작업을 동시에 제출할 수 있습니다. 별도의 쿼터 풀이므로 실시간 요청에 10 IPM만 있는 Tier 1 계정도 배치 전용 토큰 할당에 의해서만 제한되는 수천 개의 이미지를 Batch API를 통해 처리할 수 있습니다. Tier 1은 하루 100만 토큰, Tier 2는 2억 5천만 토큰, Tier 3은 7억 5천만 토큰입니다. 일반적인 이미지 생성 요청이 약 1,000-2,000 토큰을 소비하므로, Tier 1 배치 할당만으로도 배치 파이프라인을 통해 하루 500-1,000개의 이미지를 지원합니다.
Python 구현: 배치 이미지 생성
다음 코드는 배치 이미지 생성 작업을 만들고 Gemini Batch API에 제출한 후 결과를 폴링하는 방법을 보여줍니다. 이 패턴은 전자상거래 카탈로그를 위한 제품 이미지 생성, 소셜 미디어 에셋 대량 생성, A/B 테스트를 위한 이미지 변형 전처리와 같은 워크플로에 적합합니다. 배치 작업은 재시도를 내부적으로 처리하므로 배치 제출에 대해 지수 백오프를 구현할 필요가 없습니다.
pythonimport google.generativeai as genai import time import json genai.configure(api_key="YOUR_API_KEY") def batch_generate_images(prompts: list[str], model_name="gemini-3.1-flash"): """Submit a batch of image generation prompts and wait for results.""" # Prepare batch request batch_requests = [] for i, prompt in enumerate(prompts): batch_requests.append({ "custom_id": f"image-{i}", "request": { "model": model_name, "contents": [{"role": "user", "parts": [{"text": prompt}]}], "generation_config": { "response_modalities": ["image", "text"], }, }, }) # Submit batch job batch_job = genai.create_batch( requests=batch_requests, display_name=f"image-batch-{int(time.time())}", ) print(f"Batch job created: {batch_job.name}") print(f"Status: {batch_job.state}") # Poll for completion (24h SLA, typically 2-6h) while batch_job.state in ("QUEUED", "PROCESSING"): time.sleep(30) # Check every 30 seconds batch_job = genai.get_batch(batch_job.name) completed = sum(1 for r in batch_job.results if r.state == "COMPLETED") print(f" Progress: {completed}/{len(prompts)} completed") # Collect results results = {} for result in batch_job.results: if result.state == "COMPLETED": results[result.custom_id] = result.response else: print(f" Failed: {result.custom_id} - {result.error}") return results # Example usage prompts = [ "A modern office workspace with natural lighting", "A coffee shop interior with warm ambiance", "A serene garden with Japanese maples", # ... up to 100 prompts per batch ] results = batch_generate_images(prompts) print(f"Successfully generated {len(results)} images")
비용 절감 및 티어 할당
50% 배치 할인은 모든 이미지 크기에 적용되어 이미지당 비용이 실시간 생성보다 크게 낮아집니다. 1K 해상도에서 비용은 이미지당 $0.067에서 약 $0.034로 감소합니다. 매일 수백 또는 수천 개의 이미지를 생성하는 팀의 경우 이 할인만으로도 배치 처리 인프라에 대한 아키텍처 투자를 정당화할 수 있습니다. 티어별 배치 전용 토큰 할당도 실시간 쿼터와 독립적으로 최대 배치 처리량을 결정하므로 주목할 가치가 있습니다.
| 티어 | 배치 토큰 할당 (일일) | 대략적인 이미지 용량 | 이미지당 비용 (1K, 50% 할인 적용) |
|---|---|---|---|
| Tier 1 | 1M 토큰 | ~500-1,000개 이미지 | $0.034 |
| Tier 2 | 250M 토큰 | ~125,000-250,000개 이미지 | $0.034 |
| Tier 3 | 750M 토큰 | ~375,000-750,000개 이미지 | $0.034 |
Tier 1에서 Tier 2로의 배치 할당 급격한 증가(1M에서 250M 토큰)는 배치 집약적 워크로드에 대해 Tier 2 업그레이드를 특히 가치 있게 만듭니다. 애플리케이션이 이미지 생성의 상당 부분에 대해 비동기 배치 처리를 허용할 수 있다면, 대화형 요청에는 실시간 API 호출을, 백그라운드 작업에는 배치 처리를 결합하여 두 가지 장점을 모두 얻을 수 있습니다. 배치 처리를 통한 비용 최적화 전략에 대한 자세한 내용은 배치 API 비용 최적화 가이드를 참조하세요.
솔루션 4 — 무제한 처리량을 위한 API 프록시
애플리케이션이 Tier 3 제한조차 초과하는 처리량을 필요로 하거나, Google Cloud 결제 티어 및 쿼터 모니터링을 관리하는 복잡성을 피하고 싶을 때, API 프록시 서비스는 요청 제한 문제에 대한 근본적으로 다른 접근 방식을 제공합니다. API 프록시는 여러 API 키와 Google Cloud 프로젝트를 단일 통합 엔드포인트 뒤에 집약하여 이 풀 전체에 요청을 분배함으로써 프로젝트별 요청 제한을 사실상 제거합니다. 애플리케이션 관점에서는 단일 엔드포인트와 단일 키로 API를 호출하고, 프록시가 로드 밸런싱, 쿼터 추적, 자동 페일오버를 뒤에서 처리합니다. 이 접근 방식은 여러 Google Cloud 프로젝트와 결제 계정을 관리하는 운영 오버헤드 없이 프로덕션급 처리량이 필요한 스타트업과 중규모 기업에 특히 유용합니다.
API 프록시가 요청 제한을 해결하는 방법
API 프록시의 핵심 인사이트는 Google의 요청 제한이 사용자별이나 조직별이 아닌 프로젝트별로 적용된다는 것입니다. 프록시 서비스는 각각 독립적인 쿼터 할당을 가진 N개의 프로젝트 풀을 유지합니다. 요청이 도착하면 프록시는 사용 가능한 쿼터가 있는 프로젝트로 라우팅하여 총 처리량을 풀 내 프로젝트 수만큼 효과적으로 곱합니다. 각 프로젝트에 10 IPM이 있고 풀에 20개의 프로젝트가 있으면 유효 제한은 200 IPM이 됩니다 — 단일 Tier 3 계정이 제공할 수 있는 것을 훨씬 넘어선 수치입니다. 프록시는 또한 모든 프로젝트의 쿼터 사용량을 실시간으로 모니터링하여 제한에 가까운 프로젝트로 요청을 보내지 않는 지능형 라우팅을 구현합니다. 이 분산 아키텍처는 프록시가 항상 여유 용량을 보유하고 있으므로 정상적인 운영 조건에서 429 오류를 사실상 불가능하게 만듭니다.
최소한의 코드 변경
직접 Gemini API 액세스에서 프록시 엔드포인트로 전환하는 데는 대부분의 구현에서 3줄의 코드만 변경하면 됩니다. OpenAI 호환 인터페이스를 지원하는 API 프록시를 사용하면 많은 개발자가 이미 익숙한 표준 OpenAI SDK를 사용할 수 있습니다. 다음 예제는 Python과 Node.js 모두에 대한 변경 전후를 보여줍니다.
python# Before: Direct Gemini API import google.generativeai as genai genai.configure(api_key="YOUR_GOOGLE_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash") # After: Through API proxy (OpenAI-compatible) from openai import OpenAI client = OpenAI( api_key="YOUR_PROXY_KEY", base_url="https://api.laozhang.ai/v1" # proxy endpoint ) response = client.chat.completions.create( model="gemini-3.1-flash", messages=[{"role": "user", "content": "Generate an image of a sunset"}], )
프록시 접근 방식은 원시 처리량 이상의 여러 장점을 제공합니다. 첫째, 정액제 가격 모델을 제공합니다 — laozhang.ai는 해상도에 관계없이 이미지당 $0.05를 청구하며, Google의 계층별 가격인 $0.045(512px), $0.067(1K), $0.101(2K), $0.151(4K)과 비교됩니다. 2K 또는 4K 해상도에서 이미지를 생성하는 애플리케이션의 경우 프록시가 실제로 직접 API 접근보다 저렴합니다. 둘째, 프록시가 모든 재시도 로직, 쿼터 관리, 오류 처리를 내부적으로 처리하여 애플리케이션 코드의 복잡성을 줄입니다. 셋째, 티어 업그레이드에 필요한 30일 시간 게이트를 피할 수 있습니다 — 프록시는 첫날부터 높은 처리량을 제공합니다.
API 프록시 사용 시기: 60 IPM 이상이 필요한 실시간 애플리케이션, Google Cloud 결제 복잡성을 피하고 싶은 팀, 정액제 가격이 공식 계층별 가격보다 저렴한 고해상도 이미지 생성 애플리케이션, 티어 업그레이드 자격 기간을 기다리지 않고 빠르게 확장해야 하는 프로젝트.
솔루션 5 — 멀티모델 폴백 전략
Gemini API는 이미지 생성이 가능한 여러 모델을 제공하며, 각 모델 변형은 자체적인 독립적 요청 제한을 유지합니다. 이 아키텍처적 특성은 강력한 폴백 전략의 기회를 만듭니다. 한 모델이 요청 제한에 도달하면 애플리케이션이 아직 사용 가능한 쿼터가 있는 대체 모델로 자동 전환합니다. 이 접근 방식은 티어 업그레이드, 추가 결제 계정 또는 외부 프록시 서비스 없이 유효 처리량을 곱합니다. 트레이드오프는 모델마다 이미지 품질과 스타일이 약간 다를 수 있으므로, 모든 생성된 이미지에서 일관성이 중요하지 않은 애플리케이션에 가장 적합합니다.
폴백 체인 구축
2026년 초 기준으로 이미지 생성을 위한 가장 효과적인 폴백 체인은 우선순위 순서로 세 가지 모델을 사용합니다: gemini-3.1-flash-image를 기본 모델(가장 빠르고 저렴), gemini-3-pro-image를 보조 모델(더 높은 품질, 약간 느림), imagen-4를 3차 폴백(전문 이미지 모델, 다른 스타일)으로 사용합니다. 각 모델은 Google의 속도 제한기에 의해 독립적으로 추적되는 자체 RPM, IPM, RPD 쿼터를 가집니다. 기본 모델의 IPM이 소진되더라도 보조 모델의 IPM 풀은 요청을 받지 않았기 때문에 손대지 않은 상태일 가능성이 높습니다. 이를 통해 단일 모델의 10 IPM 대신 Tier 1에서 유효 IPM 30(모델당 10 × 3개 모델)을 얻을 수 있습니다.
다음 Python 구현은 429 오류 발생 시 자동으로 모델을 순환하는 ModelFallbackClient 클래스를 생성합니다. 솔루션 1의 지수 백오프와 모델 순환을 결합하여 두 겹의 복원력을 제공합니다. 클라이언트는 현재 요청 제한 상태인 모델과 예상 복구 시간을 추적하여 제한된 것으로 알려진 모델에 대한 낭비적인 요청을 방지합니다.
pythonimport google.generativeai as genai from google.api_core.exceptions import ResourceExhausted import time import logging logger = logging.getLogger(__name__) class ModelFallbackClient: """Image generation client with automatic model fallback on 429 errors.""" FALLBACK_CHAIN = [ "gemini-3.1-flash", # Primary: fast, cheap "gemini-3-pro", # Secondary: higher quality "imagen-4", # Tertiary: specialized image model ] def __init__(self, api_key: str): genai.configure(api_key=api_key) self.models = { name: genai.GenerativeModel(name) for name in self.FALLBACK_CHAIN } self.cooldowns = {} # model_name -> earliest_retry_time def generate_image(self, prompt: str, max_retries: int = 3): """Generate image, falling back through model chain on 429 errors.""" for model_name in self.FALLBACK_CHAIN: # Skip models in cooldown if model_name in self.cooldowns: if time.time() < self.cooldowns[model_name]: logger.info(f"Skipping {model_name} (cooldown)") continue else: del self.cooldowns[model_name] for attempt in range(max_retries): try: logger.info(f"Trying {model_name} (attempt {attempt + 1})") response = self.models[model_name].generate_content( prompt, generation_config=genai.GenerationConfig( response_modalities=["image", "text"], ), ) return {"model": model_name, "response": response} except ResourceExhausted: wait = (2 ** attempt) + (time.time() % 1) # backoff + jitter logger.warning( f"{model_name} rate limited. " f"Waiting {wait:.1f}s before retry." ) time.sleep(wait) # All retries exhausted for this model — add cooldown and try next self.cooldowns[model_name] = time.time() + 60 logger.warning(f"{model_name} exhausted. Moving to next model.") raise ResourceExhausted("All models in fallback chain exhausted.") # Usage client = ModelFallbackClient("YOUR_API_KEY") result = client.generate_image("A photorealistic mountain landscape at dawn") print(f"Generated by: {result['model']}")
트레이드오프 및 고려 사항
멀티모델 폴백 전략은 한계가 없는 것이 아니며, 이러한 트레이드오프를 이해하는 것이 사용 사례에 적합한지 결정하는 데 필수적입니다. 가장 중요한 트레이드오프는 시각적 일관성입니다 — gemini-3.1-flash와 gemini-3-pro는 서로 다른 기본 아키텍처와 훈련 데이터를 사용하므로, 동일한 프롬프트가 모델마다 눈에 띄게 다른 결과를 생성할 수 있습니다. 소셜 미디어 콘텐츠 생성처럼 각 이미지가 독립적인 애플리케이션에서는 이러한 불일관성이 무관합니다. 모든 이미지에서 시각적 일관성이 중요한 제품 카탈로그 생성과 같은 애플리케이션에서는 다른 모델로 폴백하면 확립된 시각적 스타일과 충돌하는 결과를 생성할 수 있습니다. 또 다른 고려 사항은 imagen-4가 Gemini 모델과 다른 API 계약을 사용한다는 것입니다 — 멀티모달 LLM이 아닌 전용 이미지 생성 모델이므로, 최적의 결과를 얻기 위해 프롬프트에 약간의 조정이 필요할 수 있습니다. 위의 폴백 클라이언트는 이를 투명하게 처리하지만, 이 전략을 프로덕션에 배포하기 전에 세 모델 모두에서 특정 프롬프트를 테스트하여 품질 차이를 이해해야 합니다.
어떤 솔루션을 선택해야 하는가?
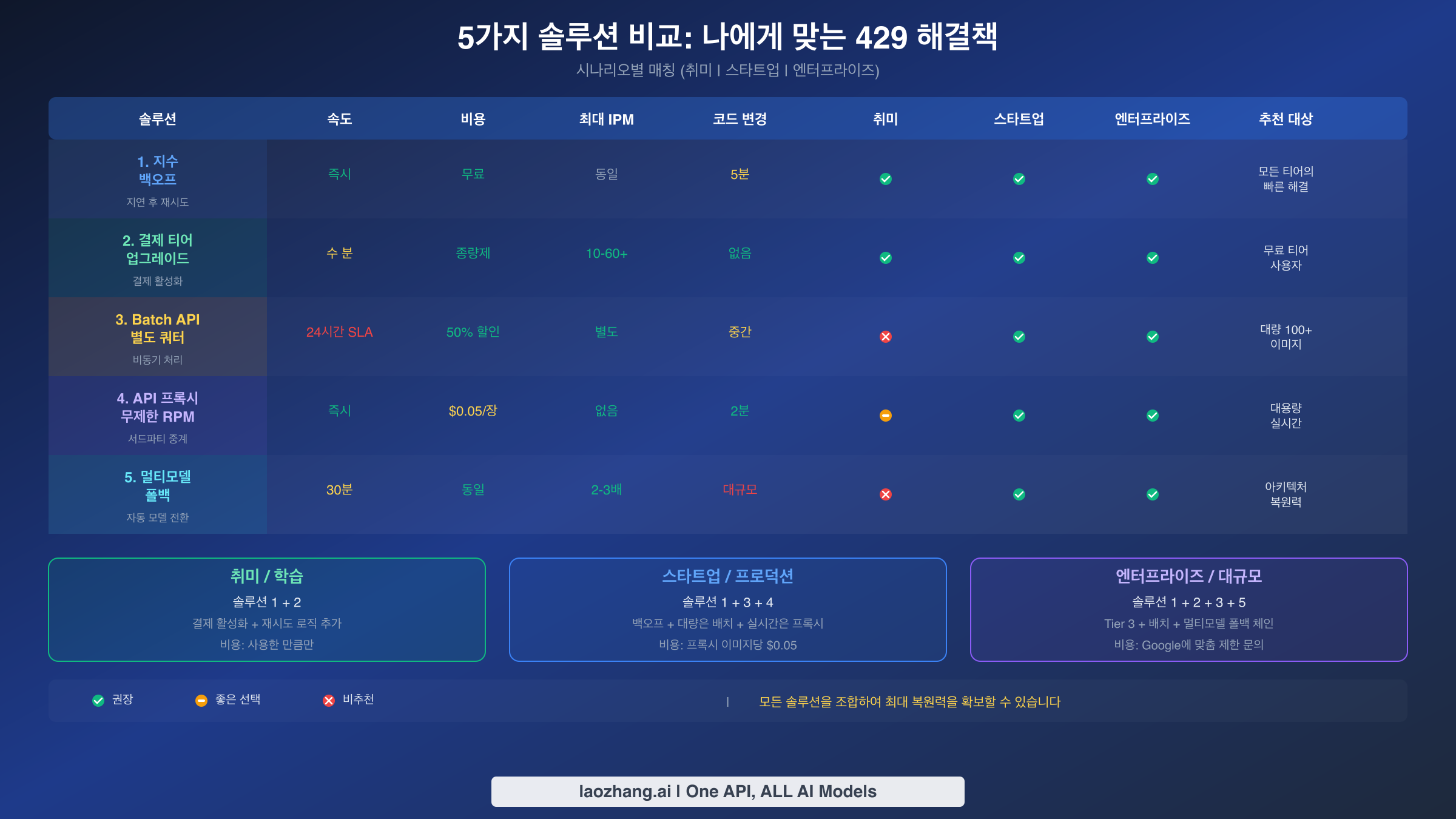
적절한 솔루션 조합을 선택하는 것은 애플리케이션의 처리량, 지연 시간, 비용, 운영 복잡성에 대한 특정 요구 사항에 따라 달라집니다. 단일 솔루션이 보편적으로 최적인 것은 아닙니다 — 간헐적인 이미지 생성이 필요한 취미 프로젝트는 수백만 사용자에게 서비스하는 엔터프라이즈 플랫폼과 근본적으로 다른 접근 방식이 필요합니다. 아래 표는 세 가지 일반적인 개발자 프로필을 각각의 권장 솔루션 조합과 근거를 함께 매핑합니다. 실제로 대부분의 프로덕션 애플리케이션은 최대 복원력을 위해 두세 가지 솔루션을 결합하며, 지수 백오프는 규모에 관계없이 모든 구현에 포함해야 하는 보편적 기반 역할을 합니다.
| 프로필 | 권장 솔루션 | 월간 이미지 볼륨 | 예상 비용 | 근거 |
|---|---|---|---|---|
| 취미 / 사이드 프로젝트 | 솔루션 1 (백오프) + 솔루션 2 (Tier 1) | < 10,000 | < $10 | Tier 1이 10 IPM 해제, 백오프가 버스트 처리 |
| 스타트업 / 성장 앱 | 솔루션 1 + 솔루션 3 (배치) + 솔루션 4 (프록시) | 10,000 - 500,000 | $50 - $500 | 대량은 배치, 실시간 오버플로는 프록시 |
| 엔터프라이즈 / 대규모 | 솔루션 1 + 솔루션 2 (Tier 3) + 솔루션 3 + 솔루션 5 (폴백) | 500,000+ | $500+ | 전용 쿼터를 갖춘 다중 계층 복원력 |
처음 429 오류를 겪는 대부분의 개발자에게 행동 계획은 명확합니다. 즉시 지수 백오프를 구현하고(솔루션 1, 15분 소요), 결제를 활성화하여 Tier 1에 도달하세요(솔루션 2, GCP Console에서 5분 소요). 이 두 가지 변경만으로 분당 10개 미만의 이미지를 생성하는 애플리케이션의 429 오류 중 95%가 해결됩니다. 그 이상의 요구가 있다면 비긴급 생성을 위해 Batch API를 추가하고 티어 제한을 초과하는 실시간 워크로드에는 API 프록시를 고려하세요.
429 요청 제한은 얼마나 지속되나요? 지속 시간은 어떤 차원에 걸렸느냐에 따라 다릅니다. RPM 제한은 60초 슬라이딩 윈도우에서 리셋되므로 단 1분만 기다리면 전체 분당 쿼터가 복원됩니다. RPD 제한은 태평양 시간 자정에 리셋되므로 오후에 일일 한도에 도달하면 몇 시간을 기다려야 합니다. IPM 제한은 RPM과 동일한 60초 윈도우를 따릅니다. 고스트 429 버그는 예측 가능한 지속 시간이 없습니다 — 일부 개발자는 몇 시간 내에 해결되었다고 보고하는 반면, 다른 개발자는 모델을 전환하거나 API 키를 재생성해야 했습니다.
60 IPM 이상을 받을 수 있나요? 네. Tier 3 제한은 협상 가능하기 때문에 "60+"로 표시됩니다. GCP Console을 통해 Google Cloud 영업팀에 연락하고 더 높은 처리량에 대한 합당한 비즈니스 필요성을 입증할 수 있다면, Google은 수백 또는 수천 IPM에 이르는 사용자 지정 쿼터 할당을 프로비저닝합니다. 약정 사용 계약에 따른 엔터프라이즈 계정은 일반적으로 전체 Google Cloud 계약의 일부로 사용자 지정 제한을 협상하며, 약정 볼륨에 따라 가격 할인이 제공됩니다.
API 프록시 사용은 안전한가요? 신뢰할 수 있는 API 프록시는 투명한 포워딩 레이어로 기능합니다 — 요청을 수신하고, 관리 중인 자격 증명 중 하나를 통해 Google의 API로 라우팅한 다음, 응답을 반환합니다. 프록시는 요청 완료에 필요한 시간 이상으로 프롬프트, 생성된 이미지 또는 API 응답을 저장하지 않습니다. 그럼에도 불구하고 프록시 운영자에게 요청 내용을 맡기는 것이므로, 명확한 개인정보 보호 정책과 개발자 커뮤니티에서의 실적이 있는 확립된 서비스를 선택하세요. 보안 모델은 모든 타사 SaaS API를 사용하는 것과 비슷합니다 — 민감한 프롬프트를 보내기 전에 제공업체의 평판과 데이터 처리 관행을 평가해야 합니다.
사용량이 0인데 429가 발생하는 이유는? 이는 거의 확실히 최근 업그레이드된 Tier 1 계정에 영향을 미치는 2026년 2월 고스트 429 버그입니다. 즉각적인 해결 방법은 모델 변형을 전환하는 것입니다 — gemini-3.1-flash를 사용 중이라면 gemini-3-pro를 시도하거나 그 반대로 해보세요. 일부 개발자는 같은 프로젝트 내에서 새 API 키를 생성하여 해결했지만, 이것이 일관되게 효과적이지는 않습니다. Google은 이 이슈를 인정하고 영구적인 수정 작업을 진행 중입니다. 티어 업그레이드 후 48시간 이상 문제가 지속되면 프로젝트 ID와 구체적인 오류 응답 본문(헤더의 쿼터 메타데이터 포함)을 포함하여 Google Cloud Console을 통해 지원 티켓을 여세요.