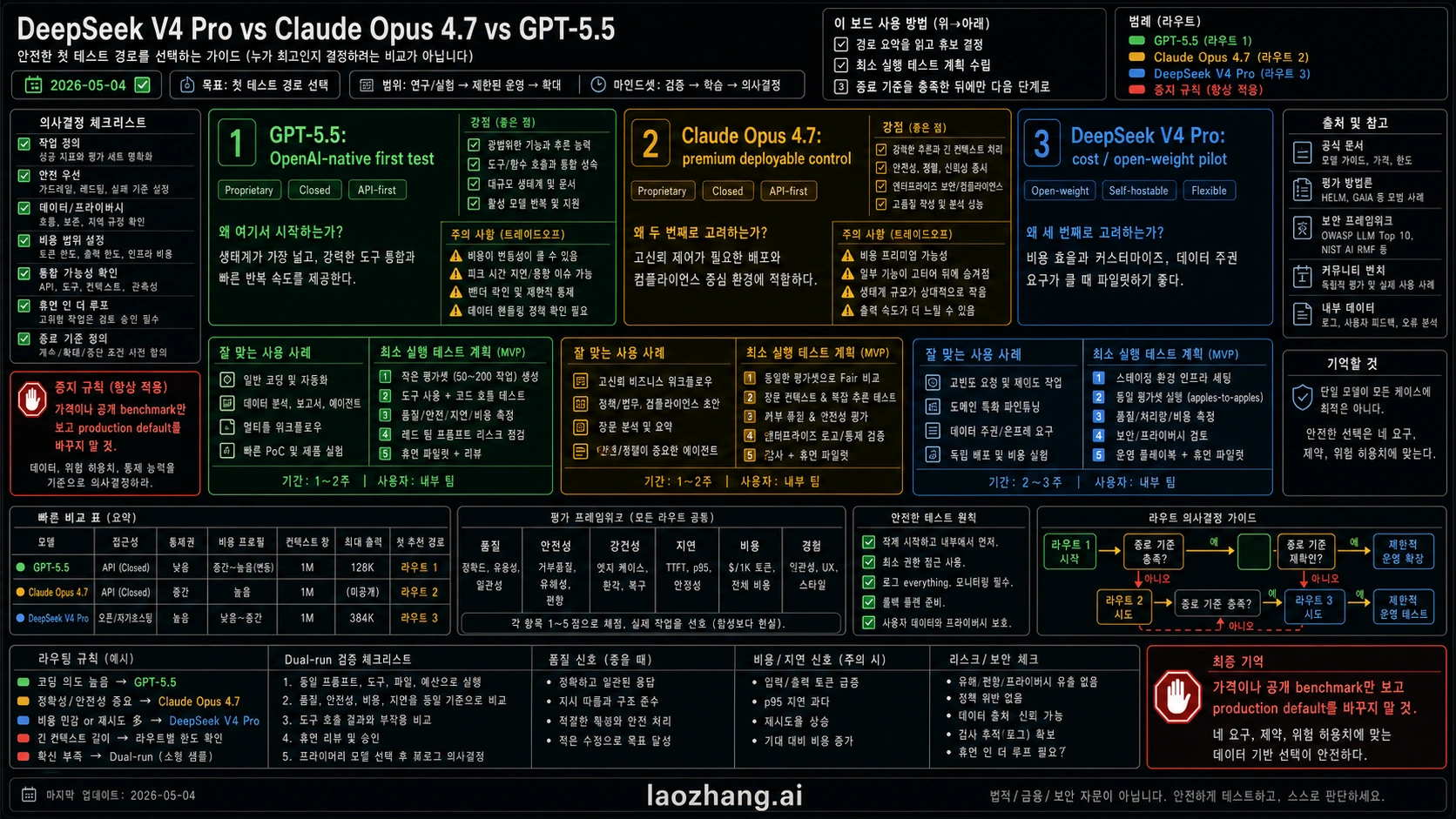
2026년 5월 4일 기준으로 DeepSeek V4 Pro, Claude Opus 4.7, GPT-5.5 비교는 한 명의 우승자를 뽑는 문제가 아니다. OpenAI 네이티브 coding, Codex, tool workflow라면 GPT-5.5를 먼저 시험한다. 정확성에 민감한 agent, cloud/API deployment, 비싼 rollback이 있는 작업이라면 Claude Opus 4.7을 premium control로 둔다. DeepSeek V4 Pro는 비용, open-weight governance, 대량 long-context 실험이 중요할 때 같은 작업으로 검증하는 pilot에 넣는다.
안전한 기본값은 이름이 아니라 검증 가능한 route를 고르는 것이다. GPT-5.5는 OpenAI account, tool surface, structured output, Codex에 가장 가깝다. Opus 4.7은 실패 비용이 높은 작업의 기준선이 된다. DeepSeek V4 Pro는 할인, compatible URL, open-weight model card가 있지만, 그것만으로 production default를 바꿀 수는 없다.
| 필요한 route | 먼저 시험할 모델 | 맞는 이유 | 중단 규칙 |
|---|---|---|---|
| OpenAI 네이티브 coding, Codex, tool-heavy API, structured output | GPT-5.5 | OpenAI developer docs가 GPT-5.5, 1M context, 128K max output을 보여 주므로 OpenAI stack에서 첫 테스트가 가장 자연스럽다. | production traffic 전 account access, limits, console behavior, 오래된 Help Center note와의 차이를 다시 확인한다. |
| correctness-sensitive agents, cloud/API deployment, premium control | Claude Opus 4.7 | Anthropic은 Opus 4.7을 coding, agents, tools, vision, cloud deployment에 배치한다. | defect, review time, rollback risk가 줄지 않으면 premium cost를 승인하지 않는다. |
| cost-sensitive pilots, open-weight governance, high-volume long-context tests | DeepSeek V4 Pro | DeepSeek docs는 V4 Pro discount, compatible URLs, 1M context, 384K max output을 제시한다. | route fidelity, quality, latency, rollback이 통과할 때까지 pilot으로 둔다. |
| production default 변경 | dual-run first | 공개 benchmark와 token price는 팀의 failure modes를 측정하지 않는다. | 같은 prompts, tools, files, budgets, acceptance tests, rollback threshold 없이 바꾸지 않는다. |
호출 가능한 계약부터 확인한다
실무 비교는 route owner에서 시작한다. GPT-5.5의 model/API facts는 OpenAI가 관리한다. Claude Opus 4.7의 availability와 pricing은 Anthropic이 관리한다. DeepSeek V4 Pro의 API, discount, open-weight route는 DeepSeek docs와 model card가 관리한다. 영상, 커뮤니티 글, 비교 표는 질문을 만들 수 있지만 model labels, prices, endpoint behavior, context windows, discount windows를 결정하면 안 된다.
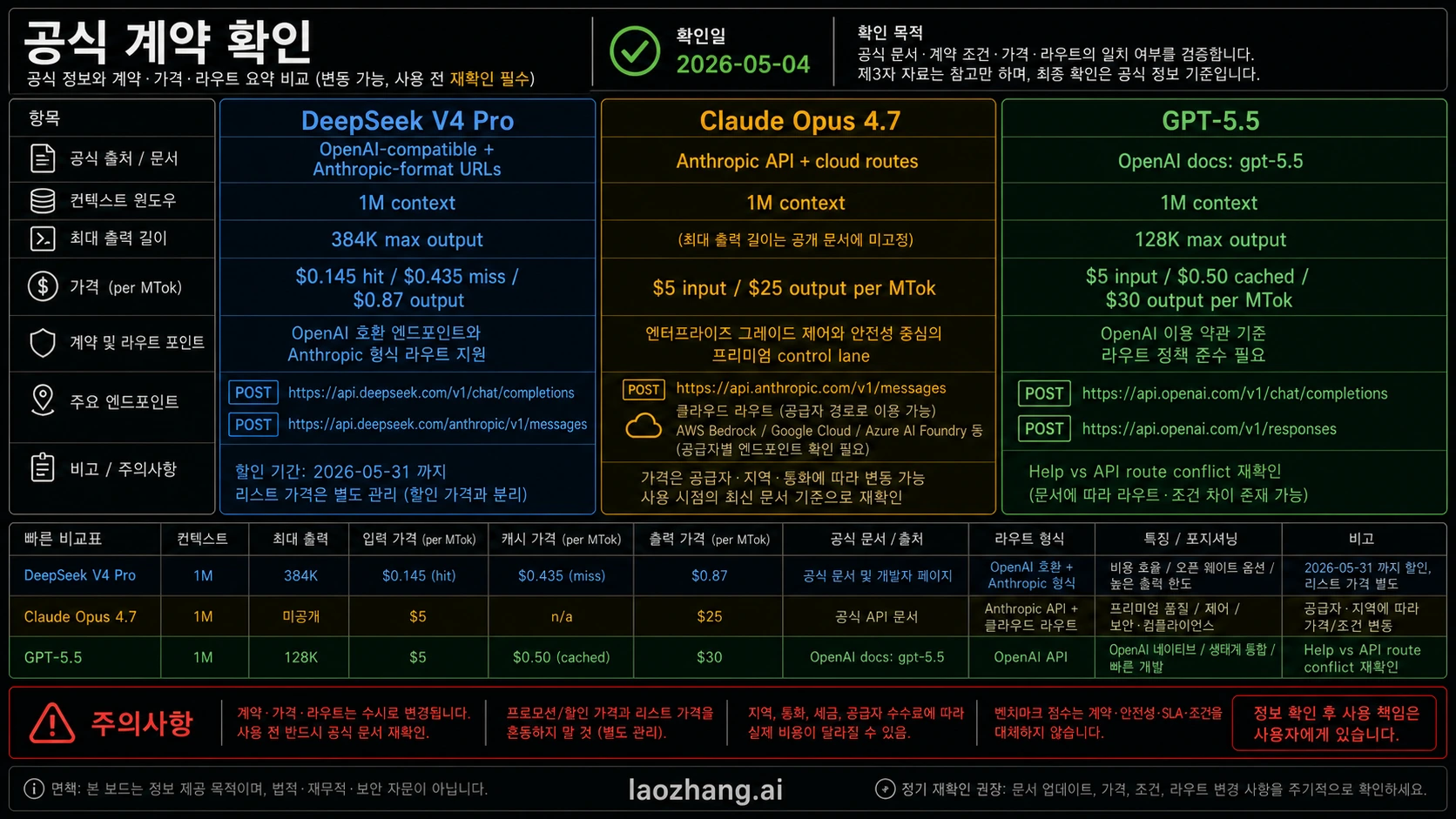
| 계약 항목 | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4 Pro |
|---|---|---|---|
| 주요 owner route | OpenAI developer platform과 OpenAI-native product/tool routes | Anthropic API, Claude products, major cloud partners | DeepSeek API와 official open-weight model card |
| 확인할 model label | OpenAI docs는 GPT-5.5, GPT-5.5 Chat, GPT-5.5 Thinking, dated variants를 열거한다 | deployment 전 Anthropic docs 또는 console에서 current model ID 확인 | DeepSeek API docs는 deepseek-v4-pro를 열거한다 |
| context와 output | OpenAI docs는 1M context, 128K max output을 제시한다 | Anthropic은 Opus 4.7을 long-context와 demanding agent work에 배치하지만 route별 limits는 확인해야 한다 | DeepSeek docs는 1M context, 384K max output을 제시한다 |
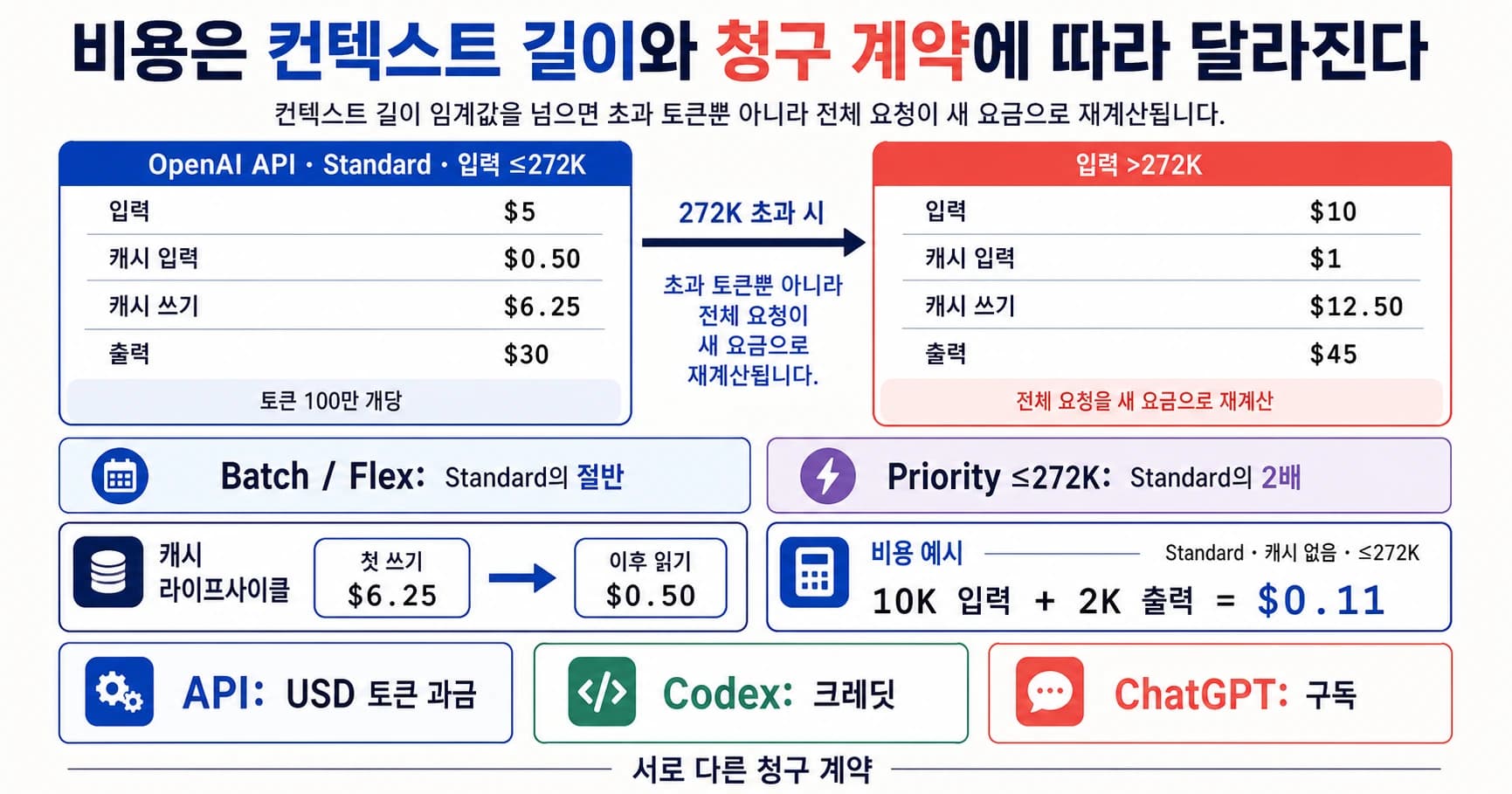
| 가격 owner | OpenAI docs는 standard short-context API row에서 million tokens당 input 5달러, cached input 0.50달러, output 30달러를 제시한다 | Anthropic launch material은 input 5달러, output 25달러를 제시한다 | DeepSeek docs는 2026-05-31까지 discount로 cache-hit input 0.145달러, cache-miss input 0.435달러, output 0.87달러를 제시한다 |
| 남겨야 할 경계 | 오래된 OpenAI Help Center rollout note는 그날 GPT-5.5 API 출시가 아니라고 했지만 현재 developer docs는 GPT-5.5를 열거한다. 운영 전 현행 환경에서 확인해야 한다. | premium cost는 defect, review time, rollout risk 감소로만 정당화된다. | compatible URL은 OpenAI나 Anthropic route와의 behavior parity를 증명하지 않는다. |
OpenAI model docs와 model comparison page가 GPT-5.5 API contract를 통제한다. 오래된 Help Center rollout note도 남겨야 하는 이유가 있다. 그 문서는 ChatGPT/Codex rollout을 설명하면서 GPT-5.5가 그날 API로 출시되지 않는다고 말했다. 현재 developer docs와 날짜가 다른 신호가 있으므로, paid traffic 전에는 organization의 model visibility, quota, limits, actual call을 확인해야 한다.
Anthropic의 Claude Opus 4.7 launch material은 Claude products, Anthropic API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry availability를 말하고 million tokens당 input 5달러, output 25달러를 제시한다. DeepSeek pricing docs는 V4 Pro price, OpenAI-compatible/Anthropic-format URLs, 1M context, 384K max output, temporary discount window를 제시한다. DeepSeek model card는 open-weight 측면에서 1.6T total parameters, 49B activated, 1M context를 보탠다.
작업별로 모델을 나눈다
DeepSeek V4 Pro, Claude Opus 4.7, GPT-5.5를 제대로 비교하려면 실제 작업으로 내려야 한다. OpenAI-native tool loop에서 강한 모델이 deployable multi-tool agent의 가장 안전한 control이라는 뜻은 아니다. million tokens당 가격이 낮아도 retries, defects, review load가 늘면 완료 작업 비용은 올라간다.
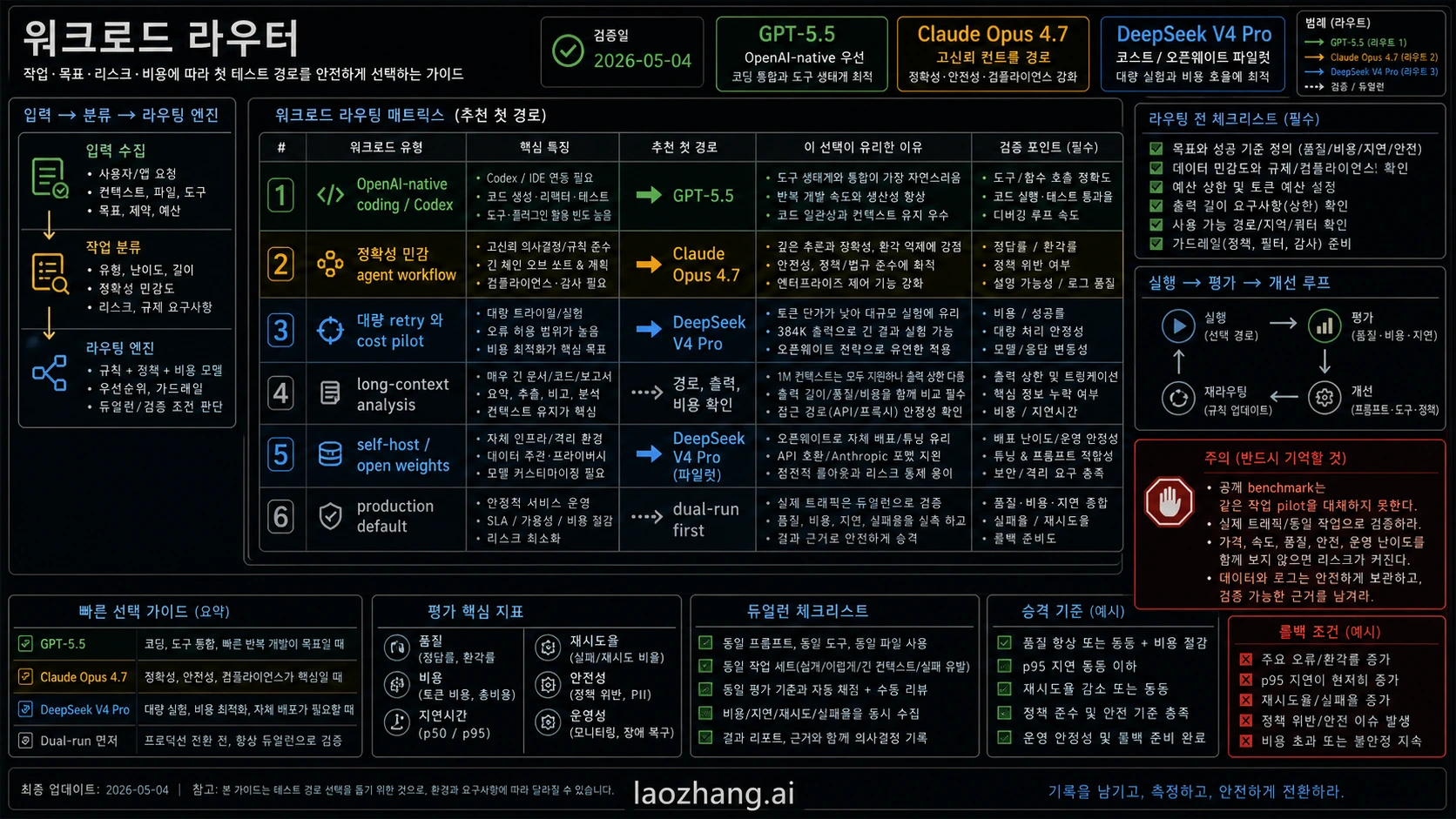
| Workload | 먼저 시험할 모델 | 이유 | 측정할 것 |
|---|---|---|---|
| OpenAI-native coding, Codex, Responses API tools, structured outputs | GPT-5.5 | OpenAI tool surface와 account controls에 가장 가깝다. | accepted diffs, tool recovery, format stability, review time, token cost. |
| correctness-sensitive coding agents 또는 multi-step orchestration | Claude Opus 4.7 | failure cost가 model cost보다 높을 때 premium control이 된다. | defect severity, tool-call reliability, rollback behavior, reviewer trust. |
| high-volume retries, batch exploration, cheap long-context tests | DeepSeek V4 Pro | temporary discount와 open-weight route가 cost pilot에 맞다. | task success rate, retry rate, latency under load, route fidelity. |
| repo, document, evidence analysis의 long-context work | route-specific test | 세 route는 큰 context를 서로 다른 방식으로 지원한다. | truncation, recall quality, output length, full prompt cost. |
| self-host, private cloud, open-weight governance | DeepSeek V4 Pro | GPT-5.5와 Opus는 closed hosted routes이고 DeepSeek는 open-weight path를 제공한다. | deployment complexity, security review, inference cost, maintenance burden. |
| existing production default | dual-run | 현재 default에는 이미 알려진 failure modes와 운영 이력이 있다. | regression count, total cost, human minutes, fallback success. |
OpenAI-native development에서는 GPT-5.5를 먼저 시험할 이유가 있다. Codex, OpenAI tools, structured outputs, file handling, account policy에 가까워 관찰이 쉽다. 그렇다고 모든 API workflow의 production default라는 뜻은 아니다. OpenAI stack에 이미 의존하는 작업에서 첫 검증 비용이 낮다는 뜻이다.
premium reliability에서는 Claude Opus 4.7이 control lane이다. multi-tool orchestration, complex code changes, vision/document review, conservative rollout처럼 실패 비용이 큰 작업에서 의미가 있다. Opus pilot이 비싸 보여도 serious defects와 senior review minutes를 줄이면 합리적이다.
cost와 open-weight pressure에서는 DeepSeek V4 Pro를 pilot에 넣는다. discount는 시험할 가치가 있고 compatible endpoints는 접속 부담을 줄이며 model card는 governance team에 중요하다. 하지만 tool errors, JSON stability, long-context recall, SDK edge cases에서 동일하게 동작한다는 증거는 아니다.
가격은 결론이 아니라 입력값이다
DeepSeek V4 Pro의 price advantage는 눈에 띈다. DeepSeek docs는 2026년 5월 31일 15:59 UTC까지 V4 Pro discount로 million tokens당 cache-hit input 0.145달러, cache-miss input 0.435달러, output 0.87달러를 제시한다. list price는 0.58, 1.74, 3.48달러다. discount window에서 시작한 pilot은 window 이후 경제성이 달라진다.
GPT-5.5는 현재 OpenAI comparison table에서 budget model이 아니다. standard short-context API row는 million tokens당 input 5달러, cached input 0.50달러, output 30달러를 제시한다. long-context pricing은 별도 route row로 재확인해야 하며 이 standard row와 섞어 계산하면 안 된다. Claude Opus 4.7은 Anthropic launch material에서 input 5달러, output 25달러다. raw hosted API price만 보면 DeepSeek가 훨씬 싸고, Claude는 premium control이며, GPT-5.5는 비싼 OpenAI-native frontier route다.
하지만 price row만으로 deployment를 결정하면 안 된다. 싼 모델이 retry를 늘리고 structured output을 깨고 manual review를 늘리고 별도 serving stack을 요구하면 비싸진다. 비싼 모델이 human review minutes와 failed generations를 줄이면 completed job 기준으로는 싸질 수 있다.
| Cost variable | 왜 중요한가 |
|---|---|
| input과 cached input | long prompts, repeated context, cache behavior가 ranking을 바꾼다. |
| output length | GPT-5.5의 output price와 DeepSeek의 384K max output은 long generation economics에 다르게 작용한다. |
| retry rate | token 단가가 낮아도 attempts가 늘면 할인 효과가 사라진다. |
| human review time | coding 또는 agent workflow에서 가장 비싼 것은 결과를 읽는 senior engineer일 때가 많다. |
예산 판단은 representative tasks로 해야 한다. 같은 prompts, files, tools, permissions, task budgets를 넣고 input, cached input, output, retries, task-level cost, p95 latency, review minutes를 기록한다. DeepSeek가 전체 작업 장부에서도 유리하면 확대 후보가 된다. Opus나 GPT-5.5가 review와 rollback을 줄이면 높은 가격도 정당화될 수 있다.
benchmark를 과하게 해석하지 않는다
공개 benchmark는 workload가 비슷할 때 유용하다. coding-agent rows, terminal-task evaluations, browsing/research scores, long-context tests, math/security benchmarks는 서로 다른 능력을 측정한다. GPT-5.5가 OpenAI-native benchmark에서 강하면 그 route에서 시험할 이유가 된다. DeepSeek V4 Pro가 cost pilot이 될 수 없다는 증거도 아니고, Opus 4.7이 premium control에서 빠져야 한다는 증거도 아니다.
반대도 같다. DeepSeek price/performance claim은 pilot harness를 만들 이유다. high-risk agent의 production replacement를 증명하지 않는다. Anthropic launch claim은 Opus를 control lane에 넣을 이유다. 모든 task에서 premium을 지불해야 한다는 증거는 아니다.
증거 순서는 이렇게 둔다.
- official docs가 route exists, model label, price, limits를 결정한다.
- provider or third-party benchmarks가 시험할 workloads를 제안한다.
- same-task harness가 default 후보인지 결정한다.
- production rollout이 real traffic, permissions, latency, failures에서 개선이 남는지 확인한다.
이 순서는 compatible endpoint 오해도 막는다. DeepSeek는 OpenAI-compatible과 Anthropic-format API URLs를 제공하지만 URL shape는 behavior parity가 아니다. tool calling, streaming, timeouts, tokenization, output format, safety behavior, retries, SDK edge cases는 다를 수 있다. compatibility는 시작 비용을 낮출 뿐 validation을 없애지 않는다.
전환 전에는 동일 작업 파일럿이 필요하다
실무 pilot은 작아도 된다. 다만 production conversation을 견딜 만큼 공정해야 한다. 한 모델에만 더 좋은 prompt, 더 넓은 budget, 더 쉬운 task를 주고 승자를 선언하면 안 된다. candidate는 같은 prompts, tools, files, budgets, acceptance tests로 측정해야 한다.

| Pilot gate | 할 일 | Pass condition |
|---|---|---|
| Route check | model label, endpoint, account access, region, quota, fallback 확인. | 팀이 deploy하려는 route를 호출할 수 있다. |
| Same prompt and tools | 가능한 범위에서 system prompt, files, tools, permissions, task budget을 맞춘다. | 차이가 harness가 아니라 model behavior에서 나온다. |
| Representative tasks | easy, hard, long-context, output-format, failure-prone tasks를 넣는다. | sample이 실제 비용과 review time을 만드는 작업에 가깝다. |
| Defect scoring | correctness, severity, security risk, recovery effort를 분류한다. | candidate가 high-severity failures를 줄인다. |
| Review-time scoring | human review minutes와 accepted-result rate를 센다. | candidate가 total work를 줄인다. |
| Cost and latency | input, cached input, output, retries, task-level cost, p95 latency를 측정한다. | savings가 full-task accounting에서도 남는다. |
| Rollback threshold | failure rate, latency, cost가 fallback을 부르는 기준을 정한다. | old route로 system rebuild 없이 돌아갈 수 있다. |
이미 GPT-5.4, Opus 4.7 또는 다른 stable default를 쓰는 팀은 "새 모델이 인상적"보다 높은 기준을 둬야 한다. current default를 유지하고 candidate를 shadow-run한다. total work가 줄고 regression이 허용 범위에 있으며 rollback path가 있을 때만 traffic을 올린다.
처음 route를 고르는 팀은 high-risk tasks에서 GPT-5.5와 Opus 4.7을 먼저 돌리고, cost나 open weights가 중요한 곳에 DeepSeek V4 Pro를 추가한다. DeepSeek가 같은 tasks를 통과하면 특정 workload의 default 후보가 된다. manual repair가 필요한 실패를 만들면 exploration lane에 남긴다.
인접한 결정
DeepSeek V4 Pro, Claude Opus 4.7, GPT-5.5의 3자 비교는 첫 테스트 route, control lane, production switch rule을 정하는 데 집중한다. 더 좁거나 넓은 route pool은 분리하는 편이 안전하다.
OpenAI와 Anthropic만 고르는 문제라면 GPT-5.5 vs Claude Opus 4.7을 사용한다. OpenAI-native testing과 Anthropic deployability를 더 깊게 볼 수 있다.
Kimi까지 포함한 cheap route pool이 필요하면 Kimi K2.6 vs DeepSeek V4 vs GPT-5.5 vs Claude Opus 4.7을 사용한다. 4자 allocation problem은 별도 판단이다.
이전 official frontier API routes를 비교한다면 Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro을 사용한다. DeepSeek release와 route background가 필요하면 DeepSeek V4부터 본다.
자주 묻는 질문
GPT-5.5가 Claude Opus 4.7과 DeepSeek V4 Pro보다 좋은가?
OpenAI-native work, 특히 coding, tool workflows, Codex, structured output에서는 GPT-5.5를 먼저 시험할 가치가 있다. 하지만 universal winner는 아니다. Claude Opus 4.7은 premium control이고 DeepSeek V4 Pro는 cost/open-weight pilot로 검증해야 한다.
DeepSeek V4 Pro가 더 싼가?
현재 documented API discount 기준으로는 그렇다. 다만 discount window에는 종료일이 있고 list price와 분리해야 한다. completed-task cost는 quality, retries, latency, review time에 따라 달라진다.
coding agents에는 Claude Opus 4.7을 써야 하나?
correctness-sensitive이고 Anthropic 또는 cloud routes로 deploy할 수 있으며 review와 rollback이 비싸다면 Claude Opus 4.7을 먼저 control로 둔다. OpenAI-native work는 GPT-5.5를 먼저 시험한다. cost나 open weights가 중요하면 DeepSeek V4 Pro를 pilot에 넣는다.
DeepSeek V4 Pro가 Claude Opus 4.7을 대체할 수 있나?
같은 작업 pilot로 증명한 뒤에만 가능하다. DeepSeek V4 Pro는 high-volume 또는 open-weight work의 후보가 될 수 있지만 price와 compatible endpoints만으로 production replacement가 증명되지 않는다.
GPT-5.5는 API로 쓸 수 있나?
현재 OpenAI developer docs는 GPT-5.5 model entries와 API price/context details를 열거한다. 오래된 Help Center rollout note는 그날 GPT-5.5가 API로 출시되지 않는다고 말했다. production traffic 전 current docs, account access, limits, console behavior를 확인해야 한다.
long-context work는 무엇을 먼저 시험해야 하나?
deployment need에 맞는 route를 시험한다. OpenAI와 DeepSeek docs는 relevant routes에서 1M context를 제시하고 Anthropic은 Opus 4.7을 demanding long-context agent work에 배치한다. 실제 task로 truncation, recall, output length, latency, full-task cost를 측정한다.
가장 안전한 production switch rule은 무엇인가?
public benchmarks, price gaps, launch excitement만으로 default를 바꾸지 않는다. 같은 prompts, tools, files, task budgets, acceptance tests로 dual-run한다. total work가 줄고 rollback path가 있을 때만 promote한다.
결론은 route plan이다. GPT-5.5는 OpenAI-native first tests, Claude Opus 4.7은 premium deployable control, DeepSeek V4 Pro는 cost 또는 open-weight pilots다. 같은 작업에서 자격을 얻은 모델만 production default가 된다.