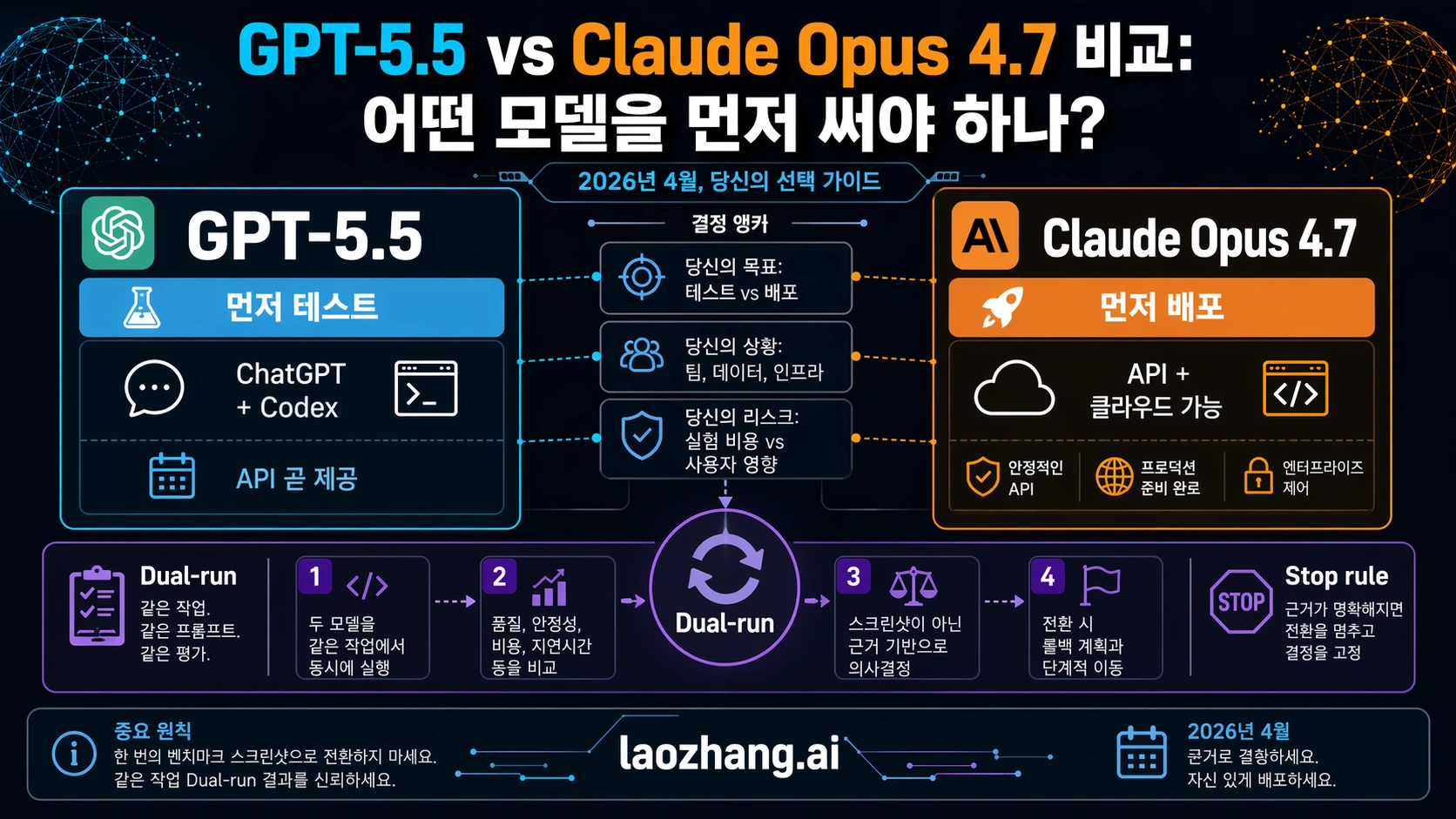
GPT-5.5와 Claude Opus 4.7은 아직 같은 조건의 API 선택지가 아닙니다. 2026년 4월 24일 기준으로 GPT-5.5는 ChatGPT와 Codex 같은 OpenAI 유료 surface에서 사용할 수 있지만, API access는 coming soon입니다. Claude Opus 4.7은 이미 Anthropic API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry를 통해 프로덕션 평가에 넣을 수 있습니다.
그래서 먼저 물어야 할 것은 “누가 이겼나”가 아니라 “내 작업이 어느 경로에서 돌아가나”입니다. ChatGPT, Codex, OpenAI 내부 코드 작업, 사람 리뷰가 중심이면 GPT-5.5를 먼저 테스트할 수 있습니다. 서버 API, cloud endpoint, rollout, 로그, 권한, fallback이 오늘 필요하면 Claude Opus 4.7을 먼저 평가해야 합니다. 이미 돈을 벌거나 고객에게 닿는 기본 모델을 바꾸려면, 같은 작업으로 두 모델을 모두 돌리기 전에는 전환하지 않는 것이 맞습니다.
| 사용 경로 | 첫 행동 | 맞는 이유 | 중단 규칙 |
|---|---|---|---|
| ChatGPT 또는 Codex 테스트 | GPT-5.5 먼저 테스트 | OpenAI가 professional work와 agentic coding을 위해 내놓은 최신 경로이고, 해당 surface가 이미 열려 있다. | OpenAI API가 계정에서 공식 제공되기 전에는 프로덕션 migration을 계획하지 않는다. |
| 프로덕션 API 또는 클라우드 배포 | Claude Opus 4.7 먼저 평가 | Claude API와 주요 클라우드 플랫폼에서 이미 live이다. | launch-week 벤치마크 한 장으로 premium default를 바꾸지 않는다. |
| 출력량이 많거나 예산 민감 | 실제 prompt로 양쪽 비용 계산 | GPT-5.5 API는 coming soon 가격으로 input $5, output $30이고, Opus 4.7은 live로 input $5, output $25이다. | cache, batch, region, tokenizer, retry를 확인하지 않고 예산 승인하지 않는다. |
| 기존 default 교체 | dual-run 후 결정 | 교체 가치는 실패율, 리뷰 시간, rollback cost로 결정된다. | 같은 repo, 같은 prompt, 같은 tool budget, 같은 test 전에는 default를 바꾸지 않는다. |
빠른 답
세부 내용을 보기 전에 모델 이름이 아니라 경로로 선택해야 합니다.
| 상황 | 먼저 쓸 모델 | 이유 | 다시 확인할 것 |
|---|---|---|---|
| ChatGPT, Codex, OpenAI-native coding flow가 중심 | GPT-5.5 | OpenAI는 GPT-5.5를 professional work와 agentic work의 새 frontier route로 제시했고, 해당 surface는 이미 live이다. | API status, model ID, account limit, production constraints. |
| 오늘 production API나 cloud endpoint가 필요 | Claude Opus 4.7 | Anthropic은 Opus 4.7을 Claude API와 주요 cloud platform에 이미 제공하고 있다. | latency, region, rate limit, token usage, deployment policy. |
| 출력이 많거나 예산 승인이 엄격 | Opus 4.7을 live API baseline으로 둔다 | Anthropic의 live price는 input $5, output $25다. GPT-5.5는 coming-soon API price라서 API live 시점에 다시 봐야 한다. | cached input, batch discount, regional multiplier, tokenizer effect. |
| GPT-5.5 API pilot을 준비 | 공식 callable route를 기다린다 | coming-soon price는 계획용이지 production endpoint가 아니다. | 시작일의 OpenAI docs와 pricing page. |
| 작동 중인 default를 교체 | 두 모델을 dual-run | launch-week comparison은 내 failure mode, review load, recovery cost를 측정하지 않는다. | same task set, same tools, same acceptance tests, same cost accounting. |
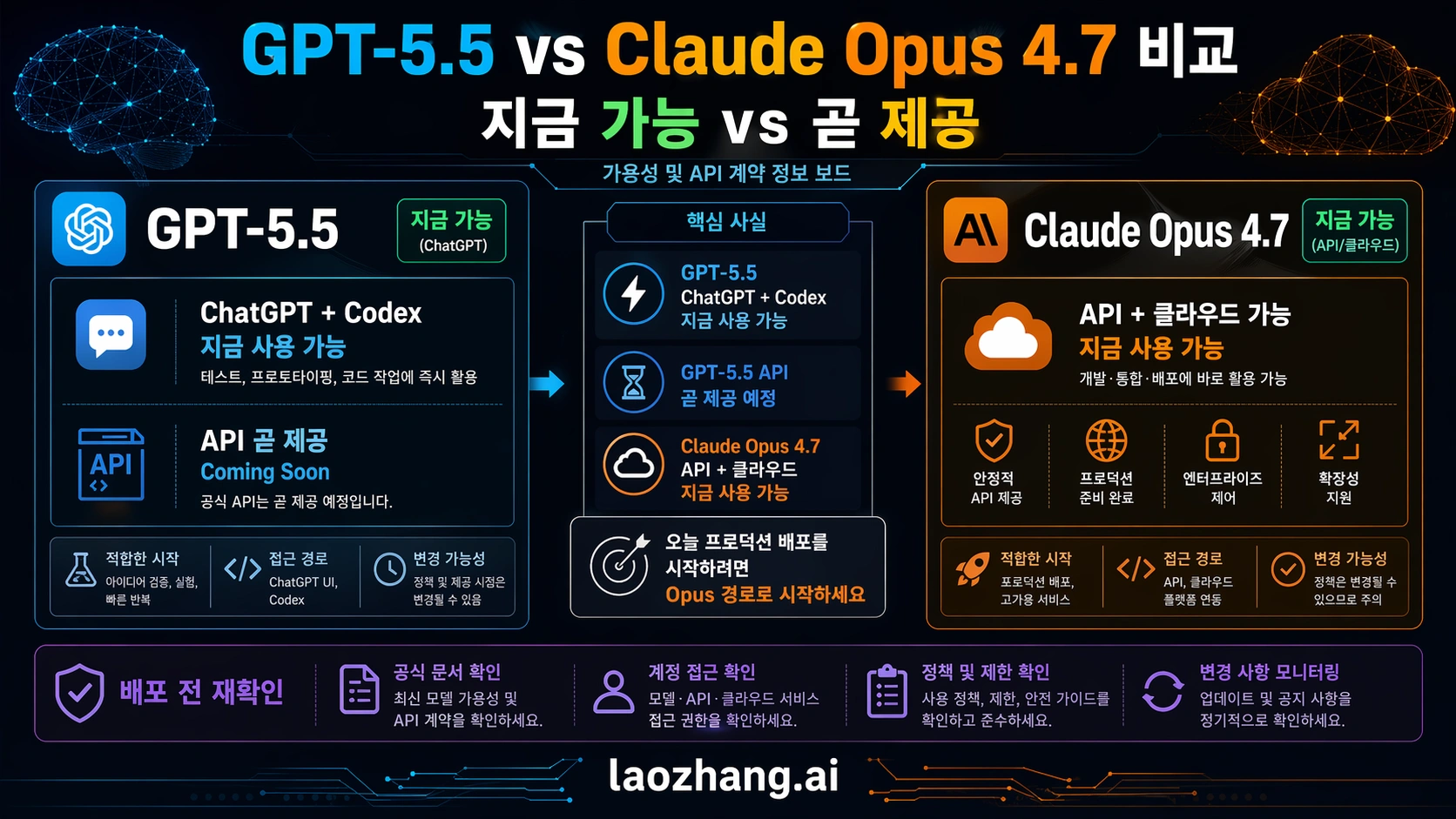
결론은 “GPT-5.5가 이긴다”도 “Claude가 이긴다”도 아닙니다. GPT-5.5는 OpenAI live surface 안에 있는 일을 먼저 테스트할 모델입니다. Claude Opus 4.7은 API route나 cloud route가 오늘 필요한 일을 먼저 배포 평가할 모델입니다. 비용, SLA, 고객 결과물, 자동화가 걸려 있으면 동일 작업에서 두 모델이 직접 증명해야 합니다.
가용성과 가격이 첫 분기점
가격 비교는 가용성에서 시작합니다. 한 모델은 필요한 API route에서 live이고, 다른 모델은 coming soon이라면 첫 번째 판단은 벤치마크가 아닙니다. 사용할 수 없는 endpoint를 중심으로 프로덕션 계획을 세우면 model ID, rate limit, tool support, billing behavior 중 하나가 반드시 blocker가 됩니다.
| 계약 항목 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| 현재 user surface | OpenAI launch 정보 기준 paid users에게 ChatGPT와 Codex에서 rollout. | Anthropic Opus page 기준 Claude products에서 사용 가능. |
| 2026년 4월 24일 API status | API access coming soon. 가격표는 live endpoint 증거가 아니다. | Anthropic API와 major cloud platforms에서 live. |
| API model ID | API route가 live된 날 OpenAI docs를 확인하고 임의 ID를 쓰지 않는다. | Anthropic model overview의 claude-opus-4-7. |
| Standard API price | coming soon: input $5, cached input $0.50, output $30 per million tokens. | input $5, output $25 per million tokens, cache와 batch options 포함. |
| Context와 output | GPT-5.5 API가 계정에서 live된 후 재확인. | Messages API 기준 1M context와 128k max output. |
| High-end variant | GPT-5.5 Pro는 future high-accuracy route이며 가격이 훨씬 높은 별도 경로. | Opus 4.7은 현재 premium Opus route. |
이 표만으로도 기본 행동이 달라집니다. 오늘 production integration을 만드는 개발자는 Opus 4.7을 live evaluation path에 넣을 수 있습니다. GPT-5.5 API를 원하는 팀은 evaluation harness를 준비해 두고, 공식 callable route가 열린 날 실행해야 합니다. 비공식 model ID나 SNS screenshot, 가격만 보고 deployment를 설계하면 안 됩니다.
output price도 중요합니다. GPT-5.5가 현재 listed price로 API에 들어오면 output side는 Opus 4.7보다 높습니다. 그렇다고 Opus가 모든 작업에서 무조건 더 싸다는 뜻은 아닙니다. cached input, batch pricing, prompt length, tokenizer behavior, retries, human edit가 invoice를 바꿀 수 있습니다. 그래서 output-heavy workflow는 API live 후 실제 prompt로 양쪽을 다시 측정해야 합니다.
벤치마크 읽는 법
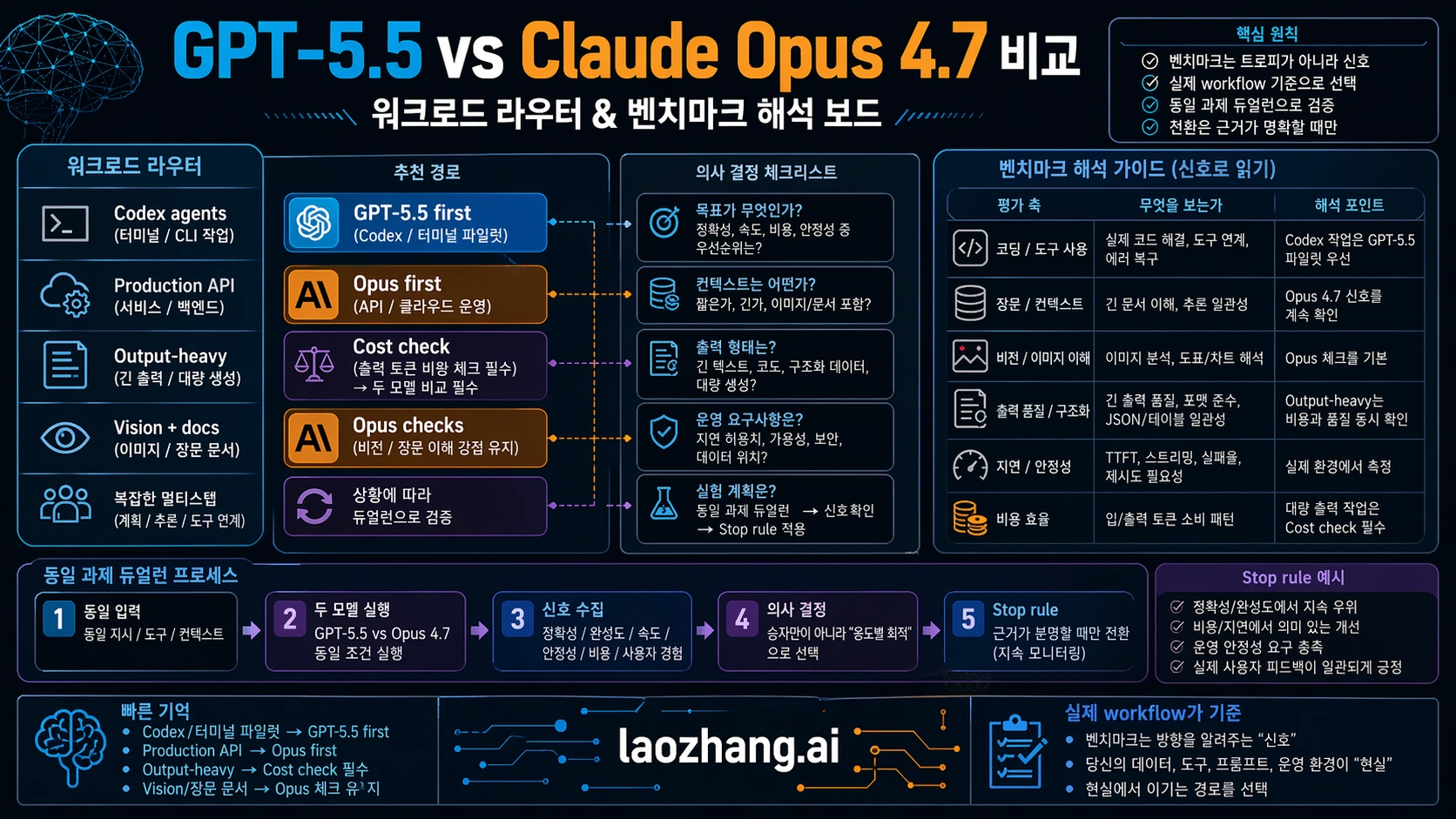
벤치마크 표는 workload에 연결될 때만 의미가 있습니다. provider가 발표한 launch rows는 evidence이지만 neutral universal crown은 아닙니다. 실무 비교에서는 영상 후기, 커뮤니티 감상, 비용 주장, 체감 성능, 공식 수치가 쉽게 섞입니다. 여기서 필요한 것은 “전체 승자”가 아니라 “내 작업에 가까운 항목”입니다.
| Benchmark | GPT-5.5 공개 결과 | Claude Opus 4.7 비교값 | 실무 해석 |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | Codex나 terminal-style OpenAI workflow에서 GPT-5.5를 먼저 테스트할 강한 이유. |
| GDPval-agentic | 84.9% | 80.3% | professional task quality 참고값이지만 domain-specific review loop가 필요하다. |
| OSWorld-Verified | 78.7% | 78.0% | 거의 비슷하므로 deploy route와 harness quality가 더 중요하다. |
| BrowseComp | 84.4% | source table 확인 | browsing/research signal로 보고 API 결정에 바로 연결하지 않는다. |
| FrontierMath Tier 4 | 35.4% | source table 확인 | hard reasoning pilot에는 유용하지만 workload tests를 대체하지 않는다. |
| CyberGym | 81.8% | source table 확인 | 보안형 작업이 benchmark와 비슷할 때만 가치가 크다. |
이 숫자들은 GPT-5.5를 agentic coding과 professional tasks에서 진지하게 테스트하기에 충분합니다. 하지만 blanket replacement를 승인하기에는 부족합니다. OpenAI는 benchmark context를 가지고, Anthropic은 Opus API contract를 가지고, 최종 결정권은 당신의 workload가 가집니다.
가장 큰 실수는 live API model과 not-yet-live API model을 동일하게 deployable한 것처럼 비교하는 것입니다. ChatGPT나 Codex에서 무엇을 먼저 테스트할지라면 GPT-5.5 rows가 중요합니다. 오늘 API route 뒤에 넣을 모델을 고르는 것이라면 availability가 첫 필터이고, Opus 4.7이 더 명확한 deployability contract를 갖고 있습니다.
코딩과 agent에서의 선택
실제 route가 OpenAI-native이면 GPT-5.5를 먼저 사용합니다. ChatGPT analysis, Codex repo work, terminal tasks, code review, OpenAI account 안의 협업에서는 operator experience와 model quality가 함께 중요합니다. 이때 질문은 “GPT-5.5가 내가 이미 쓰는 tool 안에서 review load를 줄이고 더 어려운 작업을 끝낼 수 있나”입니다. surface가 live이므로 즉시 검증할 수 있습니다.
실제 route가 API-first, Claude-native, cloud-provider-first이면 Claude Opus 4.7을 먼저 사용합니다. Anthropic materials는 coding, agents, long context, high-resolution images, higher-effort control을 강조합니다. 하지만 더 중요한 것은 route가 already deployable하다는 점입니다. server workflow, scheduled jobs, logs, permissions, region, rollout, rollback이 필요하면 coming-soon 기대보다 live contract가 중요합니다.
공정한 엔지니어링 테스트는 단순합니다. 이미 review time을 소비하는 10개 작업을 고릅니다. GPT-5.5를 live OpenAI surface에서 실행합니다. Opus 4.7을 실제 배포할 API나 cloud route에서 실행합니다. first-pass correctness, tool recovery, format stability, token use, latency, human review minutes를 기록합니다. 모델 승격은 benchmark story가 아니라 total work reduction으로 판단해야 합니다.
repo edits, terminal tasks, OpenAI-native coding이 테스트의 중심이면 GPT-5.5가 first seat입니다. production agent, explicit API budgets, cloud routing, long context, controlled rollout이 중심이면 Opus 4.7이 first seat입니다.
Context, output, migration risk
짧은 chat에서는 context와 output limit이 잘 보이지 않지만, 긴 코드베이스, 문서 리뷰, 감사, report generation, agent loop에서는 결정적입니다. Claude Opus 4.7의 live contract는 분명합니다. Anthropic docs는 Messages API에서 1M context와 128k max output을 제시합니다. pricing docs도 Opus 4.7이 standard pricing에서 full 1M context를 포함한다고 설명합니다.
GPT-5.5의 API context, production limit, rate limit, tool availability, billing behavior는 계정에서 API access가 live된 날 확인해야 합니다. 그 전에는 planned API route 또는 coming-soon API pricing이라고 쓰는 것이 정확합니다. model ID, context window, rate limit, tool support, billing behavior는 실제 production migration을 막는 조건입니다.
Opus 4.7에도 migration hazards가 있습니다. Anthropic current notes에 따르면 temperature, top_p, top_k 같은 non-default sampling parameters는 400을 반환합니다. old extended-thinking budget fields는 removed입니다. newer tokenizer는 content에 따라 fixed text에서 최대 약 35% more tokens를 사용할 수 있습니다. 이것은 Opus를 피할 이유가 아니라 실제 harness로 검증할 이유입니다.
long-form coding agents, document review, production workflow에서는 “어느 모델 context가 더 큰가”만으로 부족합니다. 필요한 context를 담고, 필요한 output을 만들고, cost limit 안에 머물며, failure가 system recovery 가능한 방식으로 발생하는 route를 골라야 합니다.
이미 GPT-5.4 또는 Opus 4.7을 쓰고 있다면
이미 GPT-5.4를 API로 쓰고 있다면, GPT-5.5가 나왔다고 바로 제거하지 마세요. GPT-5.5는 OpenAI-native pilot로는 올바른 새 후보지만, GPT-5.5 API route가 account에서 live되기 전까지 GPT-5.4는 deployable OpenAI API baseline입니다. OpenAI, Anthropic, Google route 중 무엇이 더 적합한지라는 넓은 선택이라면 Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro가 더 맞는 인접 글입니다.
이미 Claude Opus 4.7을 쓰고 있다면, GPT-5.5 release는 pilot trigger이지 automatic replacement trigger가 아닙니다. API contract, cloud deployment, long context가 Opus를 선택한 이유라면 production route는 유지합니다. 그다음 GPT-5.5를 OpenAI live surfaces에서 비교하고, API access가 official이 된 뒤 production route를 다시 평가합니다.
Anthropic-side same-family migration이 실제 질문이라면 OpenAI-vs-Anthropic 비교보다 Claude Opus 4.7 vs Claude Opus 4.6가 더 좁고 정확합니다. prompt behavior, token drift, same-family cost는 그 글이 담당하는 주제입니다.
실전 전환 계획
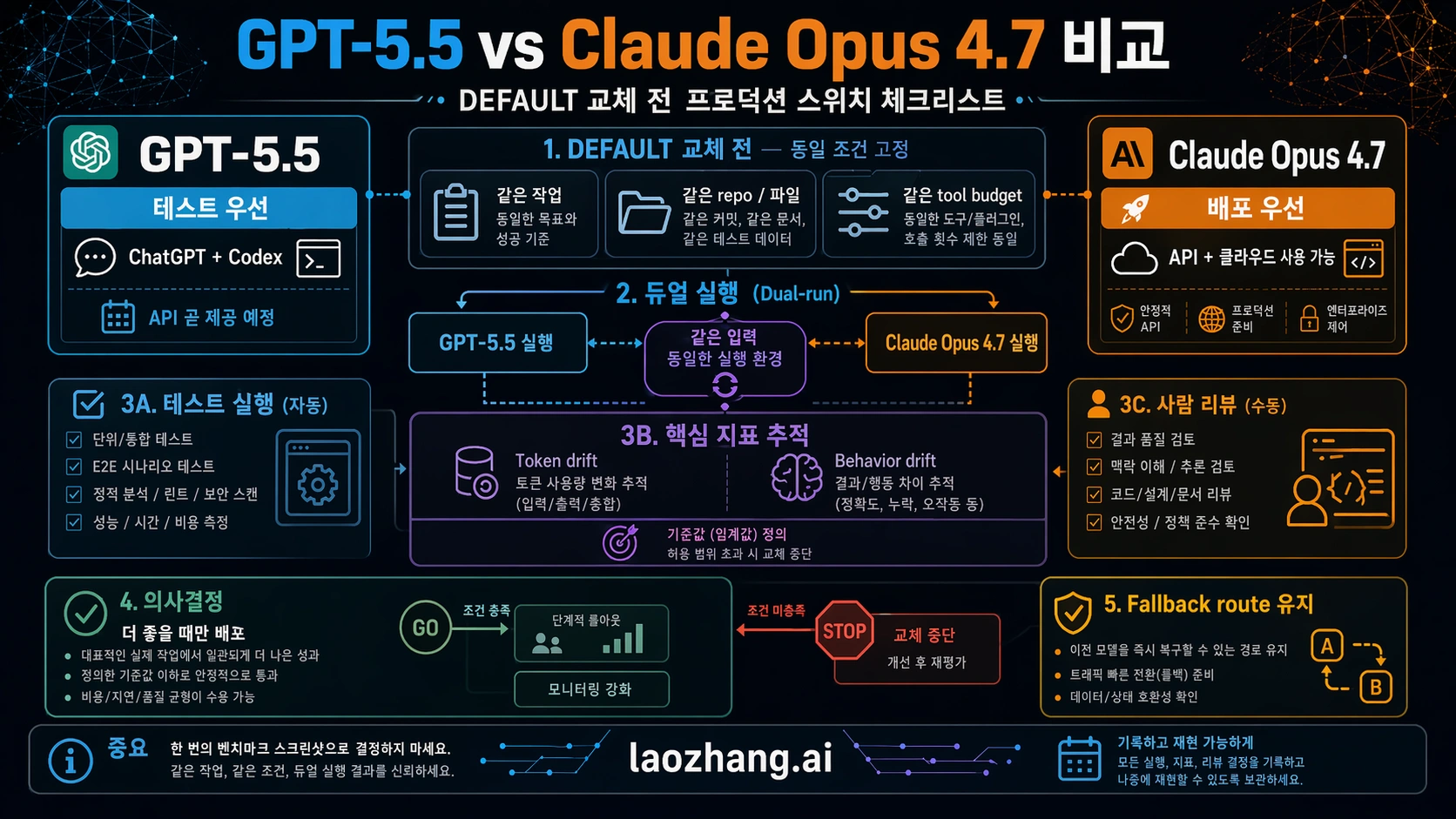
model switch에는 release plan이 있어야 합니다. 최소한의 유용한 plan은 여섯 가지입니다.
| 체크 | 할 일 | 통과 조건 |
|---|---|---|
| Route check | 필요한 ChatGPT, Codex, API, cloud에서 model이 live인지 확인한다. | production plan이 coming-soon endpoint에 의존하지 않는다. |
| Task set | demo가 아니라 representative tasks를 고른다. | easy, hard, long-context, output-format, failure-prone tasks를 포함한다. |
| Harness parity | 가능한 범위에서 same prompts, same tools, same files, same budgets로 실행한다. | 차이가 test setup이 아니라 model behavior에서 나온다. |
| Quality score | correctness, recovery, formatting, human review minutes를 추적한다. | winner가 total work를 줄인다. |
| Cost score | input, cached input, output, retries, task-level cost를 측정한다. | selected route가 real workload에서 지불 가능하다. |
| Rollback route | rollout 중 old model 또는 fallback route를 유지한다. | failed migration을 pipeline rebuild 없이 되돌릴 수 있다. |
작은 팀이라면 하루 안에 disciplined testing으로 끝낼 수 있습니다. enterprise workflow라면 private pilot, shadow run, limited production route, default switch로 나누는 것이 맞습니다. 기준은 같습니다. 모델이 새로 나왔기 때문에 바꾸는 것이 아니라, 실제 작업에서 failure, time, cost를 줄였기 때문에 바꾸는 것입니다.
FAQ
GPT-5.5가 Claude Opus 4.7보다 낫나요?
route와 workload에 따라 다릅니다. OpenAI-native ChatGPT와 Codex 작업에서는 GPT-5.5를 먼저 테스트하는 것이 맞습니다. 오늘 live API나 cloud endpoint가 필요하면 Claude Opus 4.7을 먼저 평가하는 것이 현실적입니다.
GPT-5.5는 API에서 사용할 수 있나요?
2026년 4월 24일 기준 OpenAI는 GPT-5.5 API access를 coming soon으로 설명합니다. pricing page는 planning에는 유용하지만 오늘 production에서 callable하다는 증거는 아닙니다.
어느 모델이 더 저렴한가요?
오늘 live API deployment에서는 Opus 4.7 가격이 더 명확합니다. input $5, output $25 per million tokens이며 cache, batch, regional adjustment는 별도입니다. GPT-5.5는 coming soon price로 input $5, output $30이므로 output-heavy work는 API live 후 real prompts로 다시 계산해야 합니다.
코딩 agent에는 어느 쪽이 좋나요?
Codex와 OpenAI-native coding workflow는 GPT-5.5를 먼저 테스트합니다. Claude API agents, cloud deployment, long-context loop, production endpoint가 필요한 팀은 Opus 4.7을 먼저 테스트합니다.
Opus 4.7이 여전히 이기는 영역이 있나요?
있습니다. 오늘 API와 cloud route에서의 deployability, 1M context, 128k output, multiple platforms availability는 Opus 4.7의 분명한 강점입니다.
GPT-5.5 API를 기다려야 하나요?
목표가 OpenAI API migration to GPT-5.5라면 기다려야 합니다. 지금 필요한 것이 production API route이고 Opus 4.7이 맞는다면 기다릴 필요는 없습니다. GPT-5.5는 pilot plan에 두고 API가 live된 날 다시 확인하면 됩니다.
GPT-5.5 Pro는 어떻게 봐야 하나요?
GPT-5.5 Pro는 future higher-accuracy route이고 listed API price도 훨씬 높은 별도 경로입니다. 대부분의 팀에게 오늘 GPT-5.5와 Claude Opus 4.7을 비교할 때의 default option은 아닙니다. 고가 경로가 필요한지 별도 task로 검증해야 합니다.
OpenAI live surfaces에서 일한다면 GPT-5.5를 먼저 테스트하세요. 오늘 deployable API나 cloud route가 필요하다면 Claude Opus 4.7을 먼저 평가하세요. 예산이나 reliability가 걸려 있다면, 같은 작업에서 두 모델이 직접 전환 자격을 얻도록 만드세요.