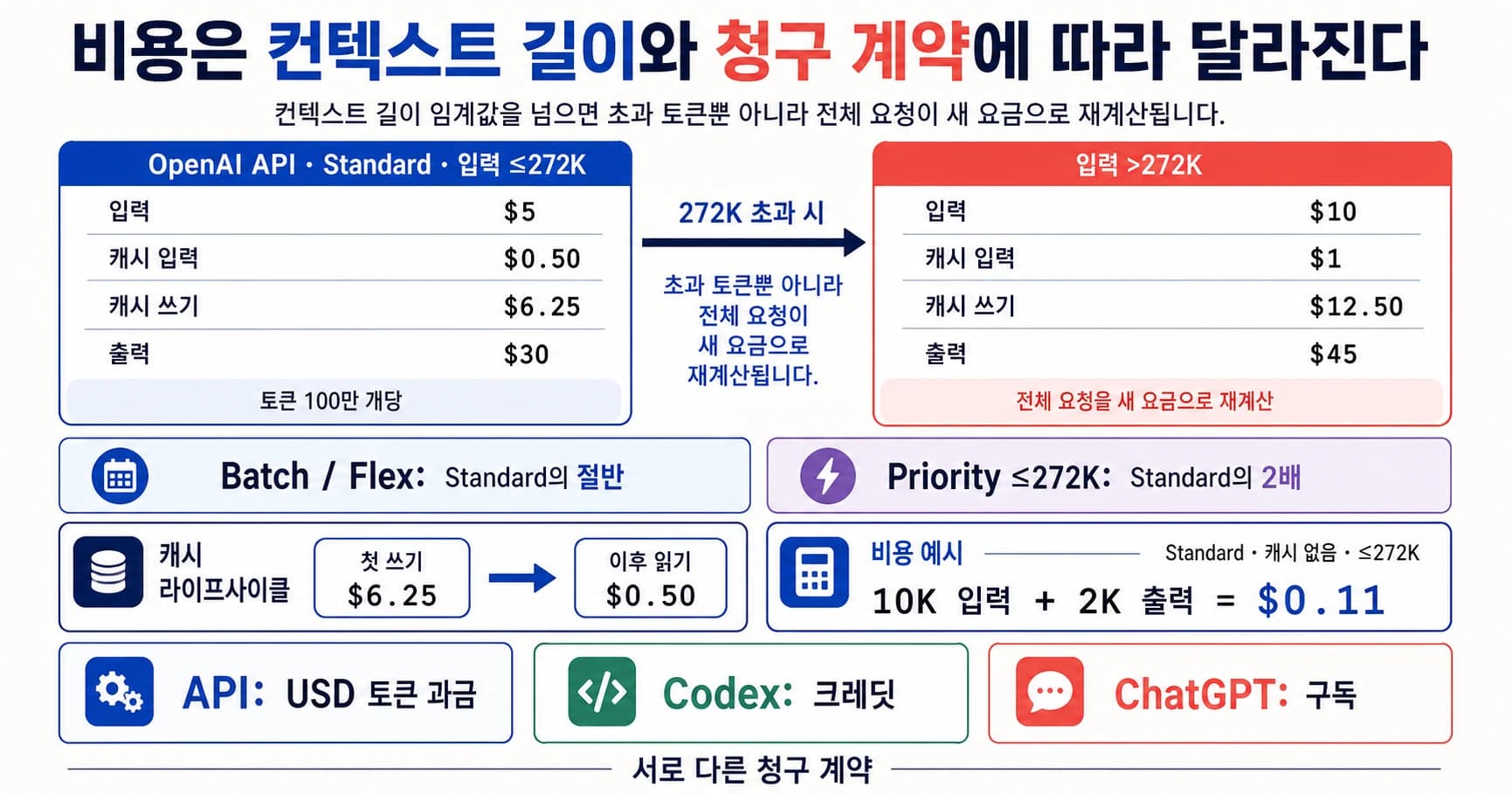
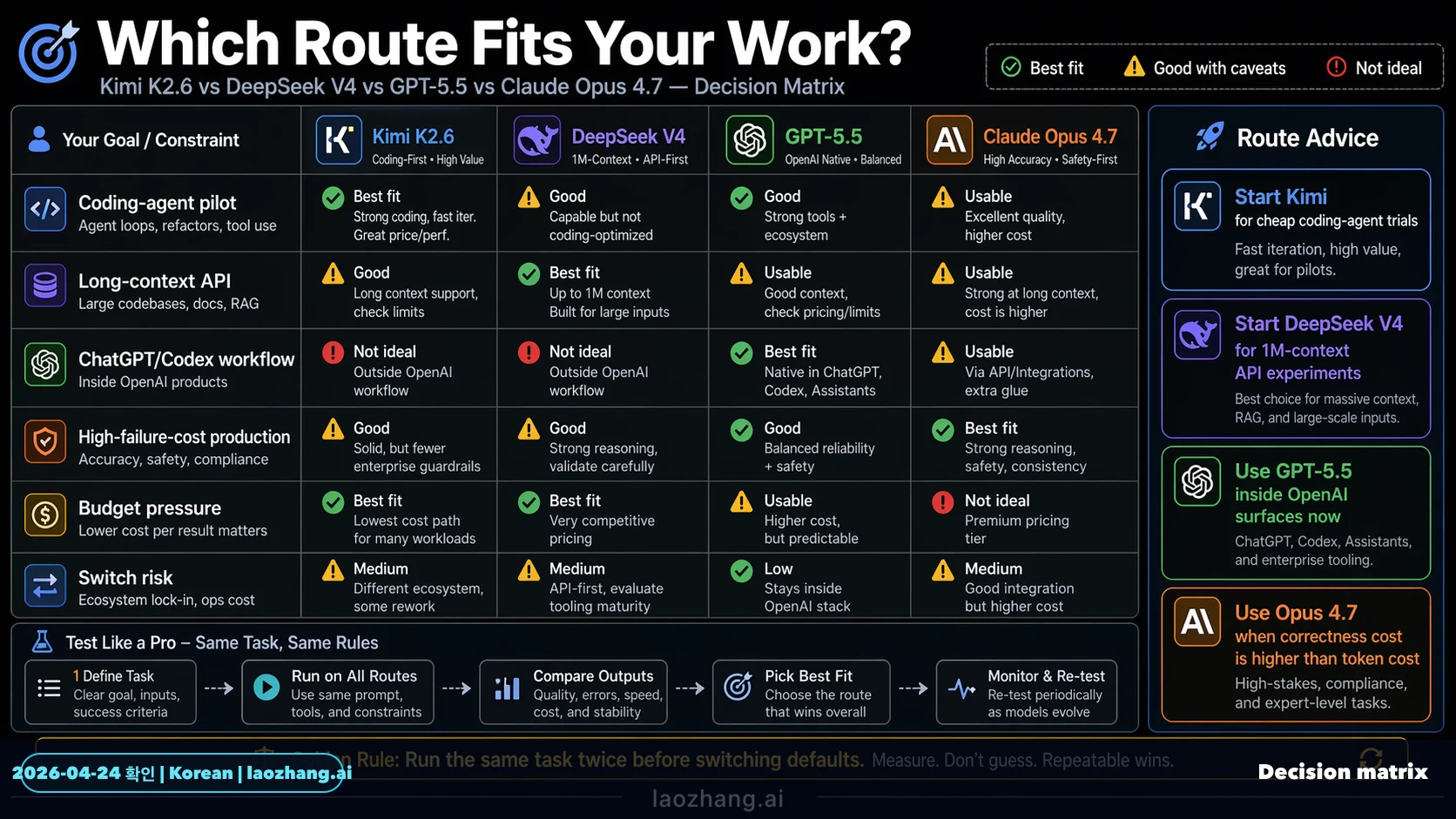
2026년 4월 24일 기준으로 이 비교는 DeepSeek V4를 중심으로 해야 합니다. 저비용 coding-agent 실험은 Kimi K2.6을 먼저 테스트하고, 현재 호출 가능한 저렴한 DeepSeek API가 필요하면 DeepSeek V4 Flash 또는 V4 Pro를 테스트합니다. OpenAI-native 작업 흐름은 ChatGPT나 Codex 안에서 GPT-5.5를 먼저 평가합니다. migration, long-context, review cost가 큰 production 작업은 Claude Opus 4.7을 control route로 유지합니다.
핵심은 순위표가 아니라 경로입니다. 공식 model ID, price owner, context, tool boundary가 있는지 먼저 확인하고, 이후 같은 task를 같은 조건으로 실행해야 합니다. 같은 repo snapshot, prompt, tools, tests, reviewer, rollback threshold가 아니면 default 변경 근거가 아닙니다.
| 경로 | 먼저 테스트할 때 | 현재 경계 | Stop rule |
|---|---|---|---|
| Kimi K2.6 | 저위험 bulk edit, scaffolding, cheap coding-agent pilot. | Kimi는 K2.6, RMB pricing, multimodal input, 256k급 context를 문서화합니다. | 같은 workflow에서 반복적으로 이기기 전에는 production default 금지. |
| DeepSeek V4 | 현재 저렴한 DeepSeek API가 필요할 때. | DeepSeek는 deepseek-v4-flash/pro, 1M context, 384K max output을 문서화합니다. | 오래된 DeepSeek label을 deploy target으로 쓰지 않기. |
| GPT-5.5 | ChatGPT 또는 Codex 안에서 OpenAI-native flow를 평가할 때. | OpenAI는 GPT-5.5가 ChatGPT와 Codex에서 가능하고 API는 coming soon이라고 말합니다. | API model ID나 price row를 만들지 않기. |
| Claude Opus 4.7 | migration, security-adjacent code, long context, hidden defect risk. | Anthropic은 claude-opus-4-7, 1M context, Opus pricing을 문서화합니다. | same-task dual-run 없이 default 전환 금지. |
빠른 답
먼저 테스트할 모델은 작업 경로에 따라 다릅니다. Kimi K2.6은 더 많은 시도와 low-risk coverage가 필요한 cheap pilot route입니다. DeepSeek V4는 Flash와 Pro의 API row가 현재 보이는 DeepSeek route입니다. GPT-5.5는 ChatGPT와 Codex 안에서 operator experience를 평가할 때 먼저 볼 수 있습니다. Claude Opus 4.7은 hidden defect와 review cost가 token bill보다 비싼 작업의 premium control route입니다.
따라서 이 비교의 핵심은 leaderboard가 아니라 router policy입니다. low-risk bulk work는 Kimi와 DeepSeek V4부터 봅니다. 어려운 repo migration은 Opus를 control로 둡니다. Codex 중심 팀은 GPT-5.5를 그 surface 안에서 먼저 평가하고, server-side API routing은 공식 문서 이후로 미룹니다.
공식 계약 경로
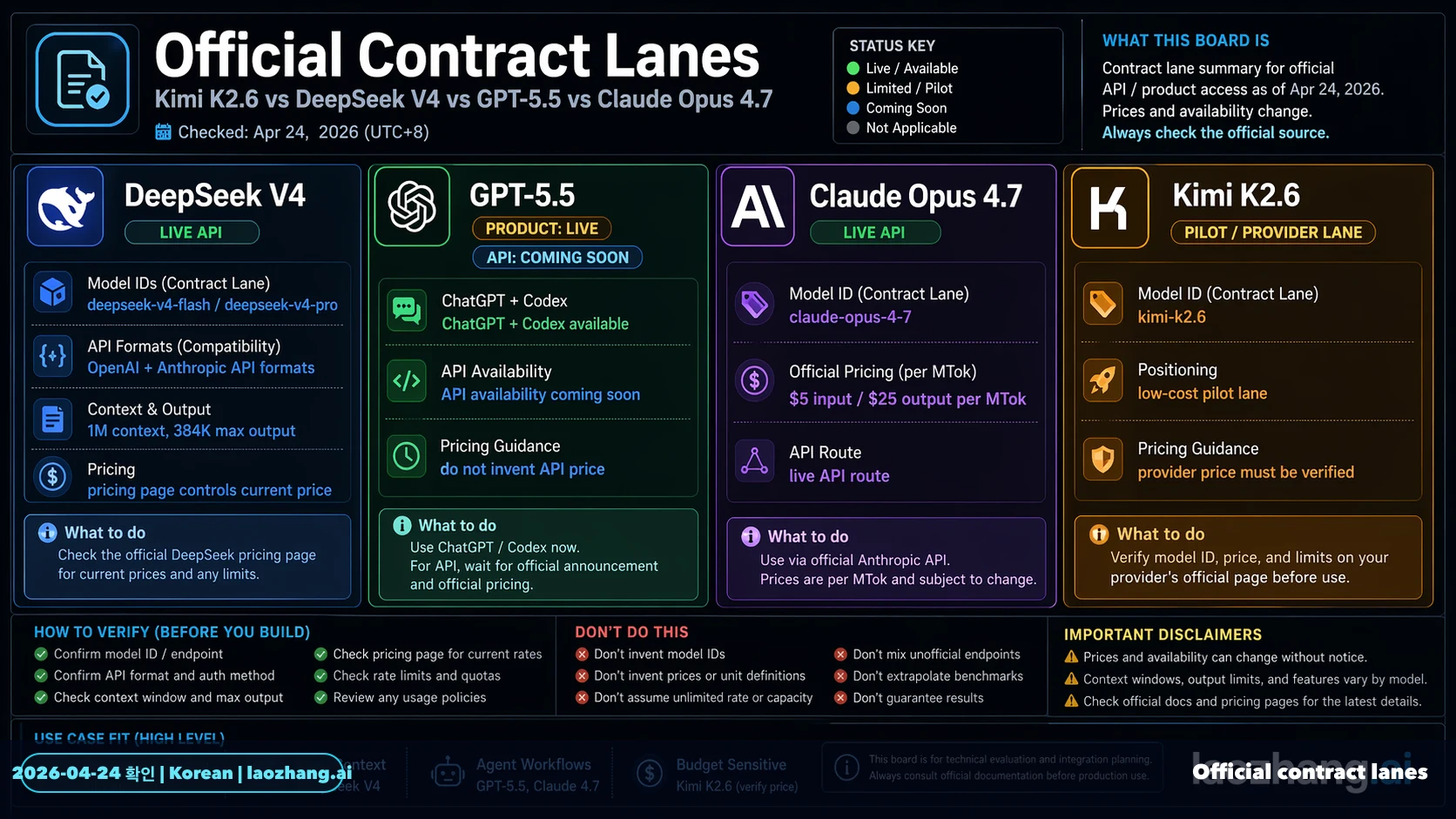
공식 문서가 비교의 경계를 정합니다. Kimi는 K2.6을 최신 모델로 설명하고 text, image, video input과 256k급 context를 제시합니다. DeepSeek pricing page는 deepseek-v4-flash와 deepseek-v4-pro, OpenAI-format 및 Anthropic-format base URL, 1M context, 384K maximum output, cache hit, cache miss, output 가격을 제시합니다. OpenAI의 현재 API guide는 GPT-5.4를 중심으로 하며 GPT-5.5는 ChatGPT와 Codex에서 가능하고 API availability coming soon이라고 말합니다. Anthropic은 Claude Opus 4.7의 1M context와 $5 input / $25 output per MTok을 제시합니다.
| Contract item | Kimi K2.6 | DeepSeek V4 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|---|---|
| Route owner | Kimi platform | DeepSeek API | ChatGPT and Codex first | Anthropic API and cloud |
| Deploy label | kimi-k2.6 | deepseek-v4-flash / deepseek-v4-pro | API docs 이후 재확인 | claude-opus-4-7 |
| Context | 256k급 | 1M, 384K max output | API context pending | 1M |
| Price owner | Kimi RMB page | DeepSeek USD page | API price row 없음 | Anthropic USD page |
2026년 4월 24일 확인한 출처: DeepSeek V4 release, DeepSeek pricing, Kimi K2.6 pricing, OpenAI latest model guide, Claude model overview, Claude pricing. production default 변경 전 다시 확인해야 합니다.
DeepSeek V4가 비교를 바꾸는 이유
DeepSeek V4는 단순한 이름 교체가 아닙니다. current model ID, price row, context route, compatibility route가 있기 때문에 DeepSeek 경로를 실제로 측정할 수 있게 합니다. Flash는 저렴한 DeepSeek candidate이고, Pro는 Opus 가격대로 바로 가지 않고 더 강한 DeepSeek route를 볼 때 쓰는 후보입니다.
따라서 현재 Kimi, 현재 OpenAI surface, 현재 Anthropic API를 오래된 DeepSeek 표현과 비교하면 안 됩니다. current route against current route로 측정해야 합니다. 개발자가 오늘 호출할 수 있는 것이 deepseek-v4-flash나 deepseek-v4-pro라면 그 행을 평가해야 합니다.
가격은 pilot signal이지 replacement verdict가 아니다
저렴한 tokens는 중요합니다. agentic work에는 retry, variant, recovery가 필요하기 때문입니다. 하지만 cheap run이 hidden defects, manual review, tool loops, rollback work를 늘리면 실제로는 싸지 않습니다.
| Cost area | 기록할 것 | 판단 사용 |
|---|---|---|
| Token cost | input, cache hit, cache miss, output, retries, tool calls | invoice shape 확인 |
| Quality cost | blocker, major, minor, format miss | 결과가 merge 가능한지 확인 |
| Time cost | latency, queue, reviewer minutes, reruns | 비용이 사람에게 전가되는지 확인 |
| Integration cost | model ID, auth, context behavior, tool behavior, billing owner | brittle default 방지 |
Same-task pilot checklist

default model switch는 production change입니다. small bug fix, refactor, test-writing, long-context analysis, ambiguous task를 포함해 다섯 개에서 열 개의 실제 작업을 고릅니다. candidate route와 current default는 같은 repo snapshot, spec, tools, timeout, test command, reviewer로 실행해야 합니다.
loss threshold는 테스트 전에 정합니다. one blocker defect는 promotion 중지입니다. three major defects는 pilot mode 유지입니다. reviewer time이 control route의 2배를 넘으면 token savings가 human labor로 옮겨진 것입니다. tool 또는 format instability는 chat에서는 작동해도 agent default에는 위험하다는 뜻입니다.
기존 사용자는 workload로 라우팅해야 한다
이미 Kimi를 쓰는 팀은 DeepSeek V4 Flash와 Pro를 cheap-route pool에 넣고 Opus를 high-risk control로 둡니다. 이미 DeepSeek를 쓰는 팀은 먼저 harness를 V4 model IDs로 업데이트합니다. OpenAI API를 쓰는 팀은 ChatGPT와 Codex 안에서 GPT-5.5를 학습하되 server routing은 official API contract 이후로 둡니다. Claude Opus 4.7을 쓰는 팀은 migration, correctness-sensitive work, long context에는 유지하고 cheaper routes는 low-risk class에서 증명하게 합니다.
좁은 비교는 Kimi K2.6 vs Claude Opus 4.7과 GPT-5.5 vs Claude Opus 4.7을 보면 됩니다.
자주 묻는 질문
지금 DeepSeek V4가 올바른 keyword인가요?
네. DeepSeek V4 Flash와 Pro가 현재 API row이므로 이 비교에서는 DeepSeek V4가 title과 deploy decision을 가져야 합니다.
GPT-5.5는 API로 사용할 수 있나요?
ChatGPT와 Codex에서는 live로 다룰 수 있습니다. production API는 official model ID, price row, limits, tool behavior가 나온 뒤 배포해야 합니다.
coding-agent team은 무엇을 먼저 테스트해야 하나요?
저위험 volume은 Kimi, cheap callable API는 DeepSeek V4, OpenAI-native flow는 Codex 안의 GPT-5.5, high-risk correctness는 Opus 4.7입니다.
DeepSeek V4가 Claude Opus 4.7을 대체할 수 있나요?
가격만으로는 아닙니다. DeepSeek V4는 cheap API workloads에서 이길 수 있지만 hidden-failure cost가 큰 작업에서는 Opus가 control route입니다.
가장 안전한 switch rule은 무엇인가요?
same-task dual-run 후 accepted diff, defect severity, reviewer time, latency, retry cost, rollback risk에서 반복적으로 이긴 경우에만 promote합니다.