
지금 필요한 답은 “이 셋 중 누가 영원한 1등인가”가 아니다. 내 workload에서 첫 테스트를 무엇으로 시작해야 하느냐가 더 중요하다.
무거운 coding, 긴 agent loop, 복잡한 software engineering이 진짜 병목이라면 Claude Opus 4.7부터 보는 편이 맞다. ChatGPT, API, Codex까지 이어지는 넓은 실배포 route가 먼저 필요하다면 GPT-5.4가 더 안전하다. 반대로 백만 token 규모의 문맥, 대형 문서나 코드베이스, 그리고 token 비용 효율이 핵심이라면 Gemini 3.1 Pro가 먼저다.
2026년 4월 18일 기준으로도 이 셋은 하나의 만능 답으로 모이지 않았다. Gemini 3.1 Pro는 여전히 Preview이고, GPT-5.4는 OpenAI의 여러 실사용 surface에 이미 올라와 있으며, Opus 4.7은 Anthropic의 premium coding / agent route로 남아 있다. 그래서 먼저 봐야 할 것은 benchmark 줄이 아니라 workload의 모양이다.
먼저 결론

첫 평가 route를 먼저 나누면 비교가 훨씬 빨라진다.
| 지금 진짜 병목이 이쪽이라면 | 먼저 테스트할 모델 | 왜 이 route가 먼저인가 | 같이 기억해야 할 경계 |
|---|---|---|---|
| 무거운 coding, 긴 agent loop, 복잡한 엔지니어링 작업 | Claude Opus 4.7 | Anthropic이 지금 가장 분명하게 premium coding과 complex agent workflow용 route로 밀고 있다 | premium-price lane이며 실제 token cost가 더 커질 수 있다 |
| 넓은 배포 surface, tool-rich workflow, 여러 OpenAI surface 연결 | GPT-5.4 | ChatGPT, API, Codex를 함께 묶는 live contract가 가장 넓다 | 넓게 배포된다고 hardest coding이나 long-context economics까지 자동으로 이기는 것은 아니다 |
| 백만 token 분석, 대용량 문서, 큰 코드베이스, token 비용 민감 | Gemini 3.1 Pro | Google이 현재 model page와 pricing에서 long-context / lower-cost route를 가장 직접적으로 보여 준다 | 아직 Preview라서 rate limit과 maturity 경계를 계속 보이게 써야 한다 |
이 표가 사실상 글 전체의 답이다. 여기서 고르는 것은 “최강자”가 아니라 첫 번째로 돌려 볼 route다. 요구가 아직 흐릿하고 먼저 넓게 한 번만 봐야 한다면 GPT-5.4가 가장 무난하다. 하지만 일이 분명히 heavy coding이거나 long-context analysis라면 이런 중간 답은 오히려 판단을 늦춘다.
왜 Claude Opus 4.7부터 봐야 하나
Opus 4.7의 강점은 추상적인 “더 똑똑함”이 아니라, Anthropic이 지금 공개 자료에서 가장 분명하게 premium software engineering과 complex agent work용 route로 정의하고 있다는 점이다. 현행 Opus 제품 페이지는 여전히 그 포지셔닝을 유지하고 있고, 접근 surface도 하나에 갇혀 있지 않다. 진지하게 평가해 볼 만한 high-end route라는 뜻이다.
두 번째 이유는 긴 작업을 다루는 제어 수단이다. Anthropic은 1M context를 유지하면서 xhigh effort, beta 상태의 task budgets 같은 옵션을 함께 내놓고 있다. 이런 요소는 casual chat의 편의 기능이 아니라, 긴 추론과 repo 규모 수정, operator workflow에 가까운 작업에서 의미가 있다.
하지만 비용 경계는 반드시 같이 써야 한다. 현재 공개 가격은 입력 1M token당 5달러, 출력 25달러이고, 같은 입력도 콘텐츠 유형에 따라 대략 1.0x-1.35x 더 많은 token으로 매핑될 수 있다고 launch note가 밝힌다. 그래서 Opus 4.7은 “질이 높은 premium coding lane”으로 읽어야지, 그냥 기존 route의 무마찰 업그레이드로 읽으면 안 된다.
만약 여기까지 읽고 Anthropic route는 거의 확실하고, 다음 질문이 “4.6에서 지금 넘어가야 하나”라면 다음 페이지는 Claude Opus 4.7 vs Claude Opus 4.6다.
왜 GPT-5.4부터 봐야 하나
GPT-5.4는 가장 넓은 live contract가 중요할 때 이긴다. OpenAI는 지금 GPT-5.4를 ChatGPT, API, Codex에 모두 걸어 두고 있고, native computer use와 tool search, 1M context까지 공개하고 있다. 많은 팀에게 첫 테스트는 “누가 제일 높냐”보다 “누가 가장 빨리 실제 workflow에 붙느냐”의 문제이기 때문에, 이 surface의 넓이는 숫자 이상으로 중요하다.
실무에서 이 장점은 꽤 직접적이다. ChatGPT에서 먼저 방향을 잡고, API로 연결하고, Codex에서 operator workflow를 이어갈 수 있다. 하나의 family 안에서 이 전환이 가능한 것이 GPT-5.4의 가장 큰 현재 계약 가치다.
공식 수치도 이런 읽기를 지지한다. OSWorld, BrowseComp, GDPval, GPQA Diamond 같은 숫자는 “GPT가 다 이긴다”의 근거라기보다, mixed tool use가 섞인 professional work를 가장 넓게 받는 route라는 근거로 읽는 편이 실용적이다.
물론 경계도 분명하다. deployability가 넓다고 해서 premium coding을 자동으로 이기는 것은 아니고, long-context economics를 대신하는 것도 아니다. 일이 분명히 hardest coding 쪽이면 Opus 4.7이 먼저이고, context와 비용이 더 중요하면 Gemini가 먼저다.
왜 Gemini 3.1 Pro부터 봐야 하나
Gemini 3.1 Pro가 먼저가 되는 경우는 long-context와 token economics가 결정의 중심일 때다. Google의 현재 model page는 이 모델을 여전히 gemini-3.1-pro-preview로 두고 있고, 1,048,576 input tokens와 65,536 output tokens를 명시한다. 큰 문서, 큰 코드베이스, research synthesis에서는 이 숫자 자체가 route를 바꾸는 계약이 된다.
가격 구조도 또렷하다. Google은 현재 200k 이하에서 입력 2달러, 출력 12달러, 그 이상에서 입력 4달러, 출력 18달러를 제시한다. 이 차이는 단순한 catalog detail이 아니라, 대형 context 작업을 첫 테스트로 잡을 때 GPT나 Opus보다 먼저 Gemini를 돌려 볼 이유가 된다.
Preview라는 사실은 route를 무효화하지는 않지만, 쓰는 방식을 바꾼다. 더 정확한 표현은 이렇다. 긴 문맥과 비용이 workload를 지배한다면 Gemini 3.1 Pro는 여전히 가장 먼저 테스트할 가치가 있다. 다만 Preview에 따른 tighter limits와 낮은 maturity를 숨기면 안 된다. Google의 rate limit 문서도 preview models의 제한이 더 빡빡하다고 적고 있다.
그래서 Gemini는 삼자 비교에서 뒤쪽 보조 문장이 아니라, 어떤 일에서는 처음부터 메인 route가 된다.
공통 증거가 실제로 바꾸는 것
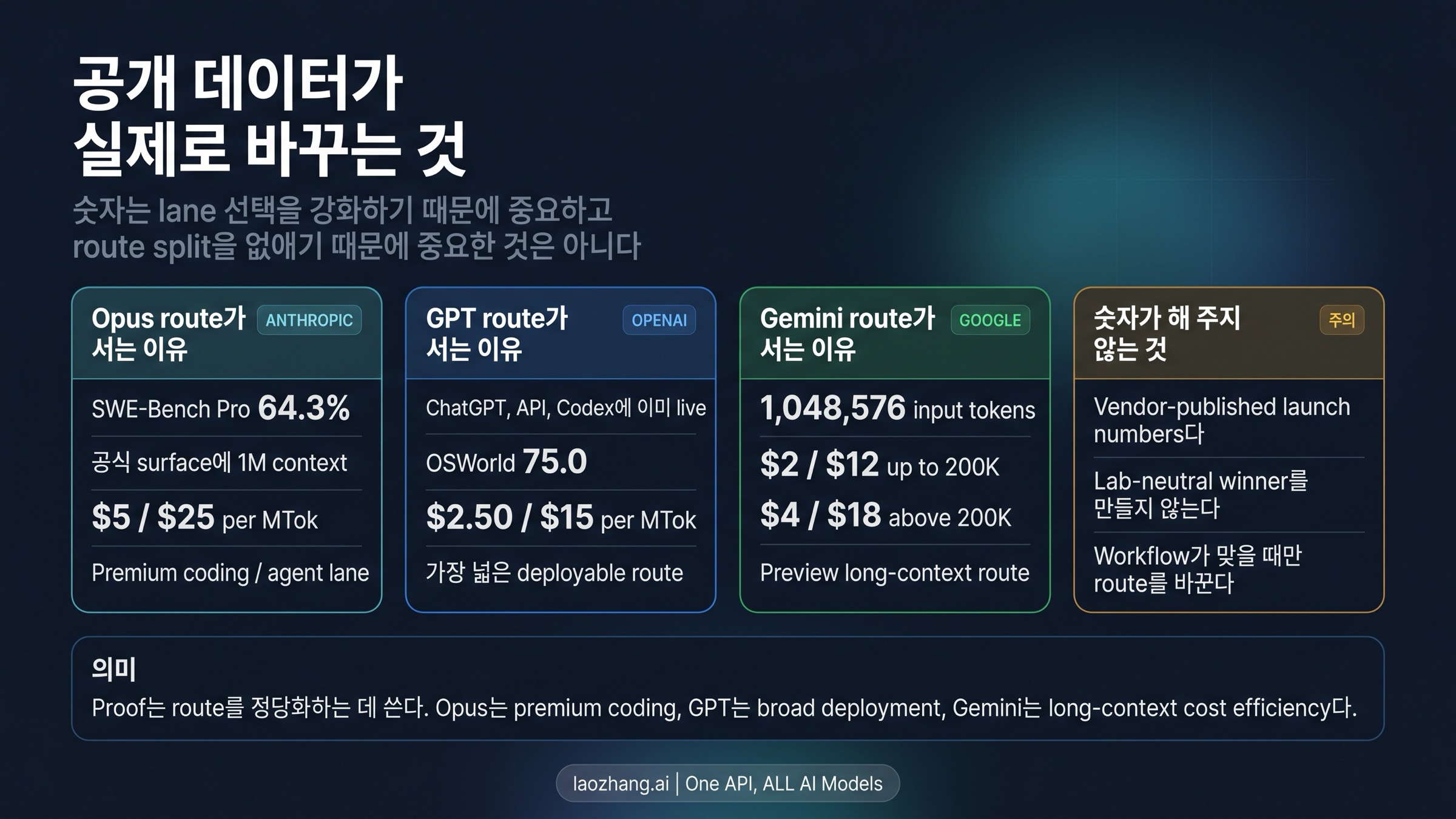
첫 번째 흔한 실수는 세 회사의 공개 숫자를 하나의 중립 leaderboard로 눌러 펴는 것이다. Anthropic, OpenAI, Google은 서로 다른 강점을 강조하고 있고, 많은 숫자는 vendor-published launch evidence다. 그래서 쓸모없다는 뜻이 아니라, route를 지지하는 증거로 읽어야 한다는 뜻이다.
두 번째 실수는 숫자만 보고 contract surface를 놓치는 것이다. GPT-5.4의 핵심은 한 줄 수치보다 ChatGPT, API, Codex를 잇는 deployable surface에 있고, Gemini의 핵심은 특정 benchmark보다 million-token scale과 lower standard rates의 결합에 있다. Opus 4.7의 핵심은 “제일 똑똑하다”가 아니라 premium coding과 long agent work에 맞게 설계된 lane이라는 점이다.
| 결정 질문 | Claude Opus 4.7 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|
| route를 가장 강하게 규정하는 공개 신호 | Anthropic의 premium software engineering / agent 포지셔닝과 1M context | ChatGPT, API, Codex 동시 배치와 native computer use | 1,048,576 input tokens와 현재 가격 구조 |
| 어떤 숫자가 route를 받쳐 주는가 | SWE-Bench Pro 64.3, 1M context, 5/25 pricing | OSWorld 75.0, 1M context, 2.50/15 pricing | 2/12와 4/18, 백만 token context |
| 어떤 경계가 선택을 바꾸는가 | premium-price lane과 실제 token drift | 넓은 deployability가 모든 세부 리더십을 뜻하지는 않음 | Preview와 tighter rate limits |
실전에서는 순서가 중요하다. 먼저 route를 정하고, 그 다음 proof를 읽는다. 순서를 뒤집으면 가장 화려한 숫자 하나를 쫓다가 정작 맞는 first test를 놓치기 쉽다.
다음에 무엇을 읽어야 하나

이 삼자 비교는 front door 역할을 할 때만 가치가 있다. 어느 lane이 더 유력한지 보였다면, 더 좁은 tradeoff는 그 질문을 실제로 담당하는 sibling 페이지로 넘기는 편이 낫다.
- Anthropic 내부 업그레이드와 control route가 진짜 질문이라면 Claude Opus 4.7 vs Claude Opus 4.6로 간다.
- 넓은 deploy와 long-context economics의 양자 비교라면 GPT-5.4 vs Gemini 3.1 Pro로 간다.
- premium coding과 long-context / cost의 비교라면 Gemini 3.1 vs Claude Opus 4.6로 간다.
모든 pairwise detail을 한 번의 삼자 비교 안에 다시 넣을 필요는 없다. 더 중요한 일은 첫 route를 빠르게 정하고, 그다음 더 좁은 sibling으로 넘어가는 것이다.
FAQ
요구가 아직 모호할 때는 보통 무엇부터 테스트하는 편이 안전한가
한 번의 넓은 테스트만 생각하면 GPT-5.4가 가장 안전한 기본값이다. 현재 deployable surface가 가장 넓기 때문이다. 다만 이것은 모호한 상황의 default일 뿐이고, universal winner는 아니다. 병목이 heavy coding이면 Opus 4.7, long-context analysis면 Gemini가 먼저다.
Gemini 3.1 Pro가 Preview면 먼저 테스트하지 않는 편이 나은가
그렇게 단순하지 않다. Preview는 limit와 maturity 경계를 뜻하지만 route 자체를 지우지 않는다. 일이 길고 크고 비용에 민감하다면 여전히 가장 먼저 돌려 볼 가치가 있다.
Claude Opus 4.7은 언제나 premium price를 정당화하는가
아니다. hardest coding, 긴 agent loop, 복잡한 engineering work가 실제 병목일 때만 first test로 정당화된다. 배포 surface가 중요하면 GPT가, context와 비용이 중요하면 Gemini가 먼저다.
benchmark 수치를 세 모델의 완전한 동일 기준표처럼 읽어도 되는가
안 된다. 더 유용한 읽기는 각 회사의 공개 launch evidence로 받아들이고, 어떤 route를 먼저 테스트할지 결정하는 재료로 쓰는 것이다. 그 정도면 충분하지만, 영구적인 종합 순위를 만들 수 있을 정도로 중립적이지는 않다.