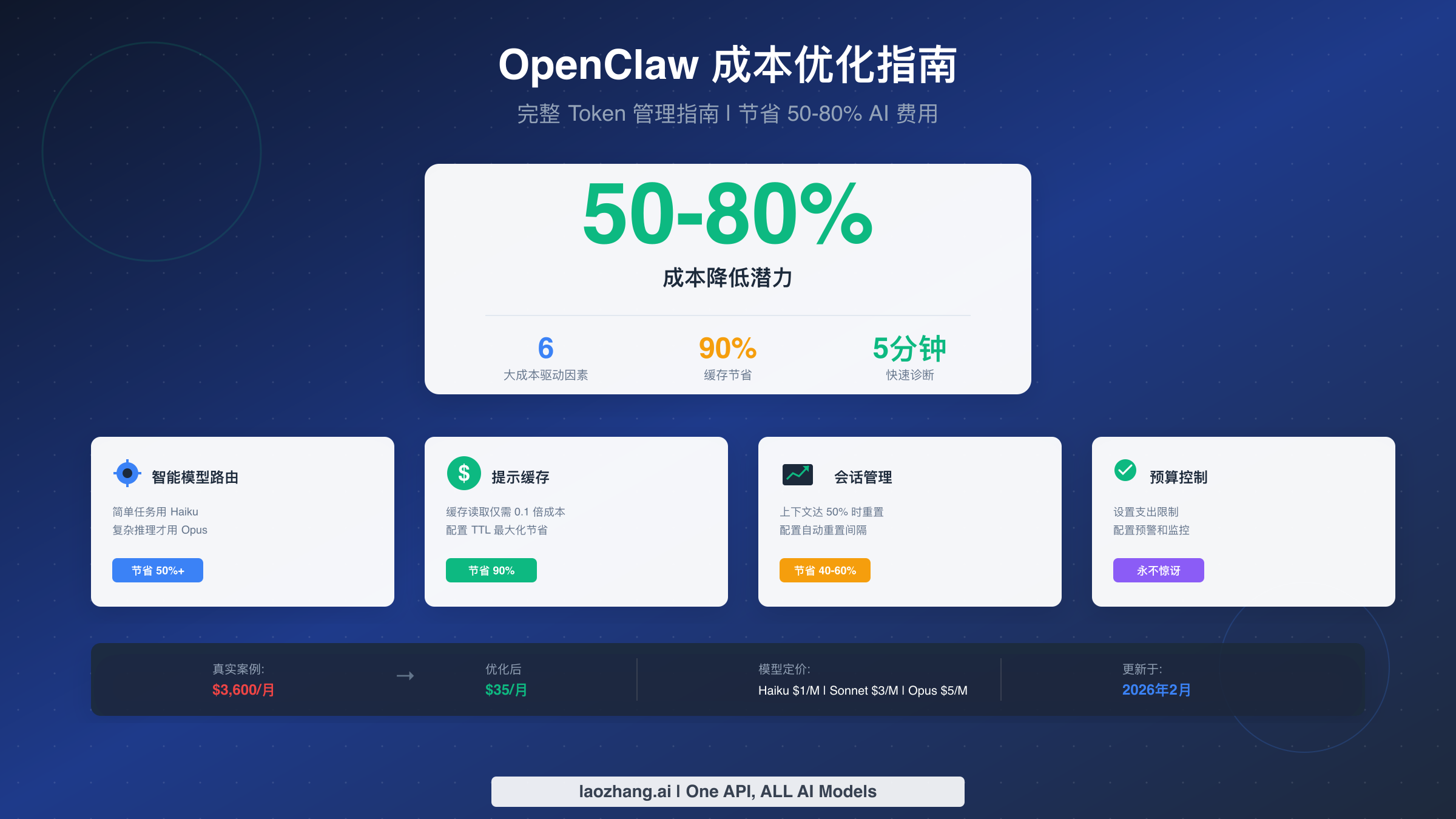
OpenClaw 用户经常面临意外的高额 API 账单,有些用户报告称每月因 Token 消耗失控而产生超过 3,600 美元的费用。这个开源 AI 助手在 GitHub 上已获得超过 135,000 颗星,变得异常流行,但其 Token 消耗速度让许多用户措手不及。这份完整指南揭示了 6 大成本驱动因素——从占用 40-50% Token 的上下文累积,到悄无声息消耗预算的配置错误的心跳功能——并提供可操作的策略,帮助你将 OpenClaw 成本降低 50-80%。你将获得智能模型路由、提示缓存和预算控制的完整配置模板,所有内容均已更新至 2026 年 2 月。
要点速览 - 成本优化速查表
在深入细节之前,这里是最具影响力的成本节省策略快速参考。仅实施前三项就可以将你的月账单削减 50% 以上。
立即行动(今天)
- 运行
/status检查当前 Token 使用量和成本估算 - 在提供商控制台设置支出限制,防止账单冲击
- 为新任务开启新会话,而不是继续长对话
高影响策略(本周)
- 配置模型路由:简单任务用 Haiku,编码用 Sonnet,仅在需要时用 Opus
- 启用提示缓存,TTL 与心跳间隔对齐
- 设置上下文容量达到 50% 时自动重置会话
高级优化(本月)
- 通过 LM Studio 部署本地模型,实现简单补全零成本
- 配置子代理使用比主会话更便宜的模型
- 为非紧急任务实施批处理(50% 折扣)
快速导航:Token 分解 | 模型路由 | 缓存 | 预算控制
快速诊断 - 为什么你的账单这么高
如果你刚收到一张意外的高额账单,不要惊慌。按照这个 5 分钟诊断流程,准确识别你的 Token 去向,以及哪种优化会产生最大影响。
第一步是了解你的当前状态。打开 OpenClaw 并运行 /status 命令。这会给你一个带表情符号的状态卡,显示会话模型、上下文使用百分比、上次响应的输入/输出 Token 数,以及估算成本。如果你直接使用 API 密钥(而非 OAuth),你会看到美元金额,帮助你理解即时的财务影响。
要进行更深入的调查,运行 /context detail 查看当前会话中每个文件和工具消耗了多少 Token。这经常揭示令人惊讶的罪魁祸首——一个目录列表或配置模式转储产生的单个大型 JSON 输出可能占用你上下文窗口的 20%。这些工具输出会存储在会话历史中,并随后续每个请求重新发送,导致成本呈指数级增长。
上下文累积问题是头号成本驱动因素,通常占总 Token 使用量的 40-50%。每次你与 OpenClaw 聊天时,所有历史消息都会保存在 .openclaw/agents.main/sessions/ 目录下的 JSONL 文件中。每次新请求,OpenClaw 都会将整个对话历史发送给 AI 模型。一位用户报告说他们的会话上下文占用了 400K Token 窗口的 56-58%——大约 230,000 个 Token 随每条消息重新发送。
接下来检查你的心跳配置。运行 openclaw config get heartbeat 查看当前设置。如果心跳触发太频繁——比如每 5 分钟——且每次触发都携带完整的会话上下文,即使你没有主动使用 OpenClaw,也可能在消耗 Token。一位用户发现他们设置为每 5 分钟运行一次的自动邮件检查,一天就烧掉了 50 美元。
最后,检查你的模型选择。如果你对每次交互都使用 Claude Opus,包括简单的状态检查和快速问题,你支付的费用比必要的多 5 倍。诊断通常会揭示 70-80% 的交互可以由更便宜的模型处理,而不会有任何质量下降。
理解 Token 消耗 - 6 大成本驱动因素
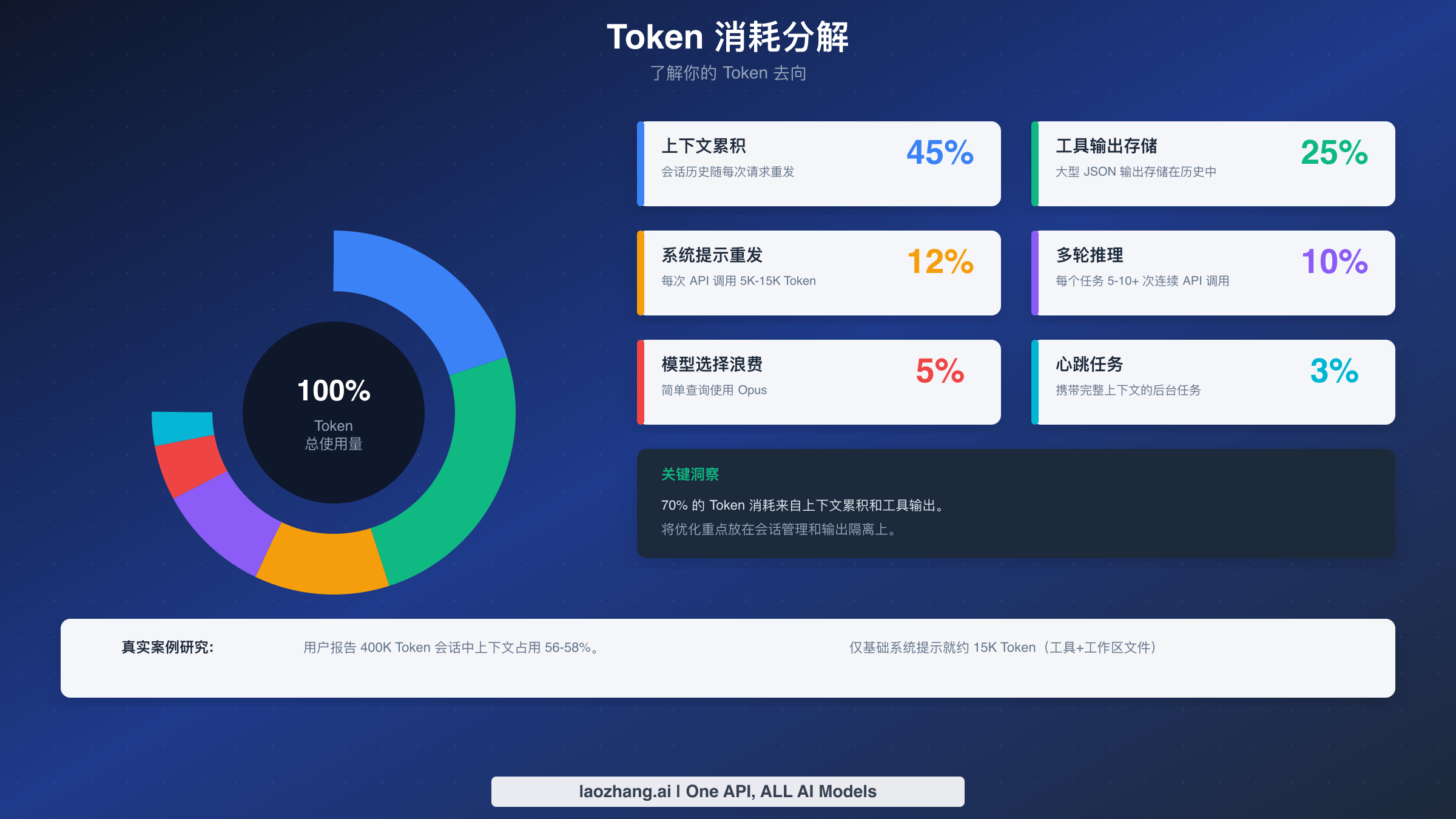
了解你的 Token 实际去向对有效优化至关重要。基于对真实 OpenClaw 使用模式的分析,以下是按典型影响排名的六大成本驱动因素。
上下文累积(占消耗的 40-50%) 代表了对 Token 预算最大的消耗。对话历史中的每条消息都会随每个新请求重新发送。这不仅包括你的问题和 AI 响应,还包括所有工具输出、文件内容和中间结果。问题会随时间复合——20 条消息的对话看起来可能很短,但如果每条消息平均 500 个 Token 并包含工具输出,你很容易达到 50,000 Token 的上下文,而这些上下文会随每次新交互重新发送。
仅基础系统提示就贡献了约 15,000 个 Token,在你开始聊天之前就已经产生。这包括 23 个工具定义及其模式、你的工作区文件如 AGENTS.md 和 SOUL.md、技能描述、自更新指令、时间和运行时元数据,以及安全头。这个开销无法避免,但了解它可以帮助你更有效地规划 Token 预算。
工具输出存储(20-30%) 是第二大成本驱动因素,通常也是最让用户惊讶的。当你运行产生大量输出的命令时——如 config.schema、status --all、目录列表或文件读取——这些输出会存储在会话历史中。它们不只是显示一次然后丢弃;它们成为你持久上下文的一部分,随后续每个请求重新发送。对大型项目的单次目录遍历可能给你的持续上下文增加 10,000+ Token。
系统提示重发(10-15%) 发生是因为复杂的系统提示必须包含在每个 API 调用中。虽然提示缓存可以大大降低这个成本(我们稍后会详细介绍),但缓存默认在 5 分钟后过期。如果你的交互间隔超过 5 分钟,你每次都要为整个系统提示支付全价。
多轮推理(10-15%) 指需要多个顺序 API 调用的复杂任务,每个调用都携带完整上下文。当 OpenClaw 需要研究、起草、修改和完成响应时,它可能为单个用户请求进行 5-10 次 API 调用。每次调用都包括整个对话历史加上不断增长的中间结果链。
不当的模型选择(5-10%) 是完全可预防的纯粹浪费。Claude Opus 每百万输入 Token 收费 5 美元,每百万输出 Token 收费 25 美元。Claude Haiku 只需 1 美元/5 美元。使用 Opus 来回答"现在几点?"或检查简单状态,浪费了 5 倍的必要资源。
心跳和后台任务(5-10%) 如果配置错误,可能会悄无声息地消耗你的预算。心跳功能允许 OpenClaw 主动唤醒并执行计划任务,但每次心跳触发都是携带完整会话上下文的完整 API 调用。配置错误的自动触发器可能比你实际的生产性工作花费更多。
智能模型路由 - 50%+ 成本杀手
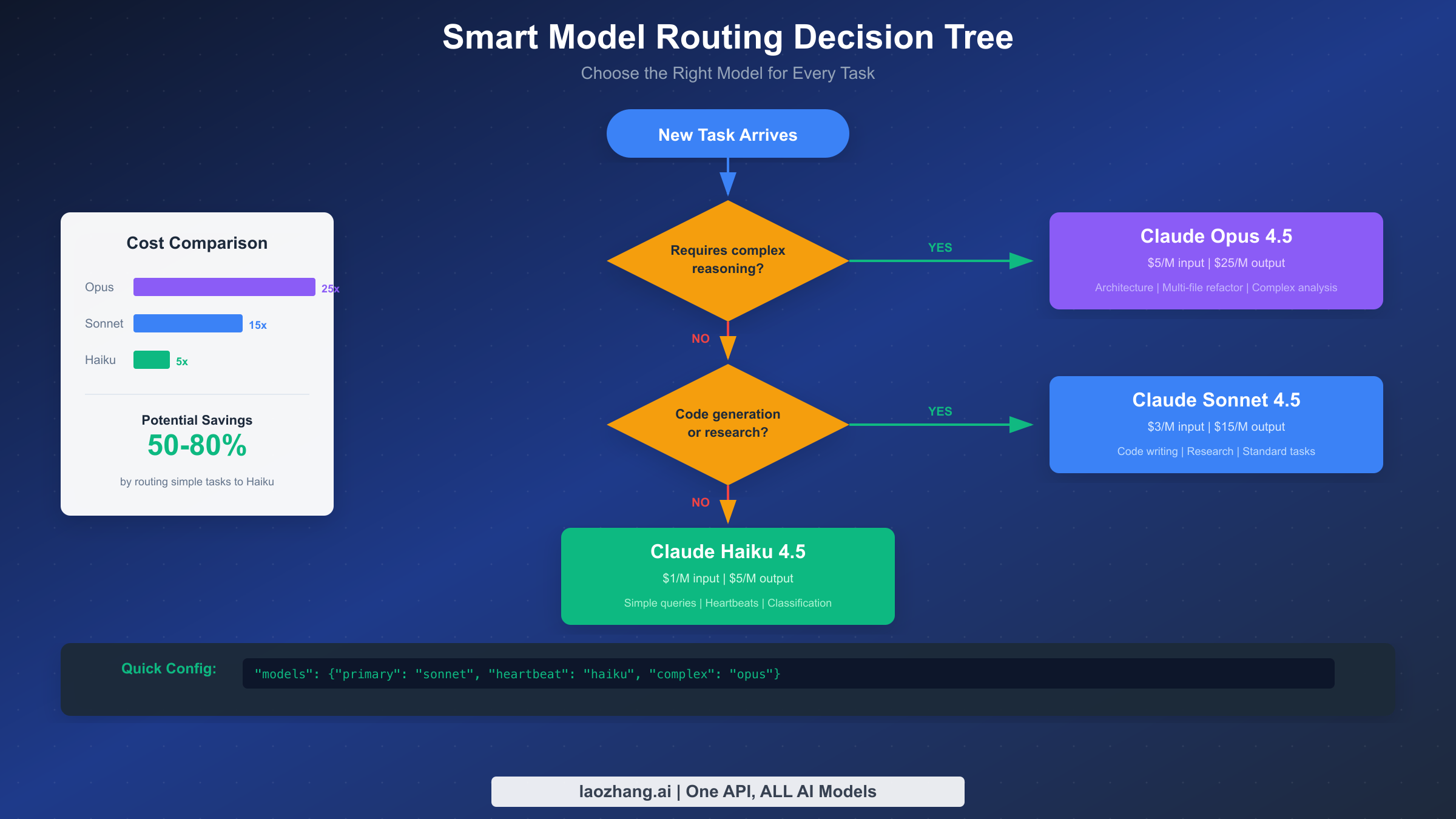
智能模型路由是你可以实施的最具影响力的单一优化,能够在保持关键任务所需质量的同时将成本削减 50% 或更多。基本洞察很简单:不是每个任务都值得使用你最昂贵的模型。
三层方法将模型能力与任务复杂度匹配。Claude Opus 4.5(每百万 Token 5 美元/25 美元)为架构决策、多文件重构和复杂分析提供卓越推理。Claude Sonnet 4.5(3 美元/15 美元)出色地处理大多数日常工作——代码生成、研究、标准任务。Claude Haiku 4.5(1 美元/5 美元)非常适合简单查询、心跳、分类和快速查找。对简单任务使用 Haiku 而非 Opus 意味着以相同结果支付 5 倍更少的费用。
这是实现智能模型路由的 ~/.openclaw/openclaw.json 完整配置模板:
json{ "agent": { "model": { "primary": "anthropic/claude-sonnet-4-5" }, "models": { "anthropic/claude-sonnet-4-5": { "alias": "sonnet" }, "anthropic/claude-opus-4-5": { "alias": "opus" }, "anthropic/claude-haiku-4-5": { "alias": "haiku" } } }, "heartbeat": { "model": "anthropic/claude-haiku-4-5", "interval": 55 }, "subagent": { "model": "anthropic/claude-haiku-4-5" } }
此配置使用 Sonnet 作为主要模型以获得平衡性能,将所有心跳路由到便宜的 Haiku 模型,并默认在 Haiku 上生成子代理。你可以随时使用 /model opus 为复杂任务覆盖到 Opus,无需重启会话。
管理路由的 CLI 命令很简单。运行 openclaw models fallbacks list 查看当前的回退链。使用 openclaw models fallbacks add openai/gpt-4o 添加回退以创建跨提供商的弹性。如果 Anthropic 被限速,OpenClaw 会自动切换到你的回退。这与速率限制处理直接相关——正确的回退配置既能防止停机,也能防止重试循环带来的意外成本。
模型路由的实际节省是可观的。轻度用户通常从 200 美元/月降到 70 美元/月(节省 65%)。重度用户看到从 943 美元/月减少到 347 美元/月,每月节省约 600 美元。超级用户报告从 2,750 美元/月降到约 1,000 美元/月——每月节省超过 1,700 美元。
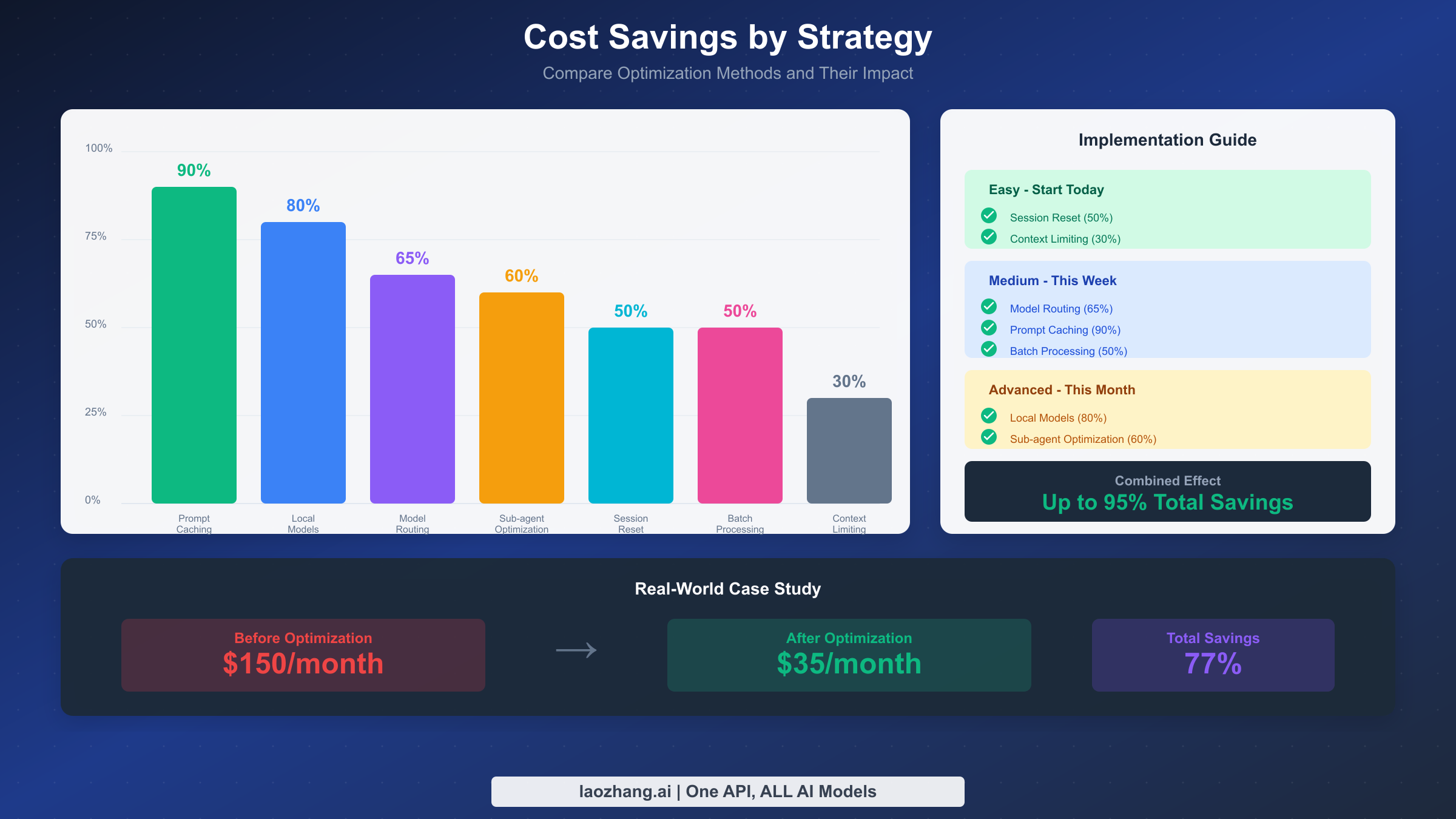
提示缓存策略 - 解锁 90% 节省
提示缓存是可用的最强大的成本优化,对重复上下文提供高达 90% 的节省。Anthropic 的缓存系统存储常用的提示前缀,这样你就不必为每次请求重新发送它们而支付全价。
经济效益非常诱人。写入 5 分钟缓存的成本是基础输入价格的 1.25 倍。写入 1 小时缓存的成本是 2 倍。但从缓存读取只需 0.1 倍——这是对缓存内容 90% 的节省。对于典型的 15,000 Token 系统提示会话,缓存该内容意味着每次请求支付 0.015 美元而不是 0.15 美元。经过数百次交互,这加起来是一笔可观的钱。
缓存命中率因内容类型而异。系统指令和工具描述等静态内容达到 95%+ 的命中率,因为它们很少改变。用户配置文件和偏好等半静态内容根据修改频率达到 60-80% 的命中率。实时数据等动态内容通常只有 0-20% 的命中率,不应依赖于缓存收益。
最大化缓存收益的关键是将心跳间隔与缓存 TTL 对齐。如果你的缓存 TTL 设置为 1 小时,将心跳间隔配置为 55 分钟。这确保心跳在缓存过期前触发,在空闲期间保持缓存温暖。没有这种对齐,你可能会遇到缓存未命中,迫使你对整个提示进行昂贵的重新缓存。
要启用缓存 TTL 修剪,在配置中添加:
json{ "cache": { "ttl": 3600, "pruning": true }, "heartbeat": { "interval": 55, "model": "anthropic/claude-haiku-4-5" } }
此配置告诉 OpenClaw 在缓存 TTL 过期后修剪会话,然后重置缓存窗口,以便后续请求可以重用新缓存的上下文,而不是重新缓存完整历史。结合将心跳路由到 Haiku,你可以同时最小化缓存成本和每次心跳成本。
对于生产部署,使用 /usage full 监控缓存命中率,它显示缓存利用率统计。如果你看到系统提示的命中率低于 80%,调查是否有什么东西过早地使缓存失效——可能是频繁更改的工作区文件,或者被包含在缓存部分的工具输出。
心跳和后台任务 - 停止静默消耗
心跳功能将 OpenClaw 从被动助手转变为可以唤醒并执行计划任务的主动代理。但这种能力带有一个让许多用户措手不及的成本陷阱。
每次心跳触发都是完整的 API 调用。如果你的心跳设置为每 5 分钟触发一次,而你的会话上下文是 50,000 Token,你每 5 分钟就燃烧 50,000 个输入 Token——每小时 600,000 Token——仅仅是为了保持助手"清醒"。按 Opus 定价,这是每小时 3 美元的纯心跳开销。一位用户报告说仅因配置错误的每 5 分钟邮件检查,一天就燃烧了 50 美元。
解决方法很简单:将心跳路由到你最便宜的模型。检查邮件是否到达或文件是否更改很少需要 Opus 级别的推理。Haiku 以 1/5 的成本完美处理这些任务。使用前面显示的心跳模型覆盖在设置中配置此项。
仔细考虑你的心跳间隔。默认值可能对你的用例来说太激进了。如果你检查的事件每天只发生几次,30 分钟或 60 分钟的间隔就足够了。根据你的实际需求匹配间隔,而不是默认最大响应度。
对于不需要立即关注的任务,在空闲期间完全禁用心跳。你可以在离开时使用 openclaw config set heartbeat.enabled false 切换它,然后在返回时重新启用。这完全消除了后台 Token 消耗。
如果你确实需要频繁的心跳,将它们与激进的缓存优化结合。心跳理想情况下应该命中系统提示的热缓存,将增量成本最小化到只有任务特定的 Token。前面提到的 55 分钟心跳配合 60 分钟缓存 TTL 模式实现了这种平衡。
会话和上下文管理 - 重置习惯
有效的会话管理可以防止驱动 40-50% 典型成本的上下文累积问题。解决方案是养成在正确时刻开始新会话的习惯。
一般建议是在上下文超过 50% 容量时开始新会话。你可以随时使用 /status 检查,它显示你当前的上下文利用率。当你看到该百分比超过 50% 时,是时候考虑重置了。如果响应时间开始明显滞后,一定要立即重置——这是模型正在与过多上下文作斗争的迹象。
对于像 Claude Opus 这样的昂贵模型,采用更激进的策略。完成每个独立任务后开启新会话。使 Opus 对复杂问题有价值的推理深度也使维护长上下文变得昂贵。完成复杂任务,得到结果,然后重新开始。
OpenClaw 提供多种方法来重置会话。最简单的是在对话中直接运行 /new 或 /reset。这会立即为当前 sessionKey 创建新的 sessionId,开始新的对话记录文件。
对于自动管理,配置每日重置:
json{ "session": { "reset": { "dailyTime": "04:00" } } }
这会在每天当地时间凌晨 4:00 触发自动会话更新,确保你永远不会累积超过 24 小时的上下文。
更好的是基于空闲的重置,用于自然工作间断:
json{ "session": { "reset": { "idleMinutes": 30 } } }
当会话空闲超过 30 分钟时,下一条消息会自动触发新会话。这匹配自然的工作模式——当你去吃午餐或参加会议时,你回来后是一张白纸。
结合这些策略以获得最大效果。使用 30 分钟空闲超时用于自然间断,加上凌晨 4:00 每日重置作为安全网。使用 /status 监控上下文使用,并在单个工作会话中处理不同项目时手动重置。这种组合与让会话无限增长相比,通常可以节省 40-60%。
预算控制与监控 - 永不惊讶
防止意外账单需要主动的预算控制和监控。这里的策略不会降低每次交互的成本,但确保你永远不会被失控的支出措手不及。
设置支出限制至关重要。每个主要 AI 提供商都在其计费控制台提供支出控制。对于 Anthropic,访问 console.anthropic.com/billing 设置月度和每日限制。典型方法是将月度限制设置为预期预算加 20% 缓冲,每日限制大约为其 1/20(假设每日使用有些变化)。当你达到这些限制时,API 调用会失败而不是累积意外费用——你可以在成本失控之前调查和调整。
在依赖支出限制之前,确保你的 API 密钥配置正确。配置错误的密钥可能会通过意外的计费路径路由请求。
对于实时监控,建立每日检查例程:
bashopenclaw usage --yesterday # 全天:快速状态检查 /status # 启用每响应跟踪 /usage full
/usage full 命令为每个回复附加每响应使用脚注,无需手动检查即可保持成本可见。这种意识自然鼓励成本意识行为。
第三方工具提供额外的可见性。GitHub 上的开源 clawdbot-cost-monitor 实时跟踪所有模型的支出,提供仪表板和警报,超越提供商控制台中可用的功能。
通过编程检查支出来创建简单的警报系统。这是一个在每日支出超过阈值时发送警报的 shell 脚本:
bash#!/bin/bash DAILY_LIMIT=10 # 美元 CURRENT=$(openclaw usage --today --format json | jq '.cost') if (( $(echo "$CURRENT > $DAILY_LIMIT" | bc -l) )); then echo "OpenClaw 支出警报: 今天 $CURRENT" | mail -s "预算警告" you@example.com fi
在工作时间通过 cron 每小时运行此脚本。结合提供商端限制,你有针对意外费用的纵深防御。
成本对比 - 直连 API vs 聚合平台
除了优化使用模式,你选择如何访问 AI API 也会影响成本。存在三种主要选择:直连 API 访问、聚合平台和订阅计划。
通过 Anthropic 和 OpenAI 等提供商直接访问 API 给你列出的价格——Sonnet 3 美元/15 美元,Opus 5 美元/25 美元。你获得完全控制、直接支持关系,以及发布后立即访问所有功能。然而,除非你在企业规模消费,否则你支付列表价格而没有批量折扣。
像 laozhang.ai 这样的聚合平台通过单一 API 端点提供对多个 AI 提供商的整合访问。好处包括跨提供商的统一计费、通过批量聚合的潜在成本节省、简化的提供商切换以用于回退链,以及内置的可靠性功能。对于使用来自不同提供商的多个模型的团队,仅运营简化就可能值得平台费用。
一些用户探索 Gemini 的 API 免费层级等免费层级选项用于对成本不敏感的任务,将昂贵的查询路由到付费服务,同时通过免费配额处理简单请求。
订阅计划代表另一种替代方案。Anthropic 的 Claude Pro 和 Max 计划提供可观的固定费率使用,对于稳定的重度用户可能比按 Token 付费提供更好的价值。然而,这些订阅不能与 OpenClaw 基于 API 的架构一起使用——它们只对 Claude.ai 网页界面有效。
每月消费 5000 万 Token 的典型重度用户的成本对比:
| 访问方式 | 月成本 | 备注 |
|---|---|---|
| 直连 Anthropic(Sonnet) | $225 | 列表价格 |
| 优化后 | ~$80 | 路由+缓存后 |
| 聚合平台 | ~$180 | 因平台而异 |
| 优化后 | ~$65 | 组合节省 |
关键洞察是优化策略无论访问方式如何都会复合。无论你是使用直连 API 还是通过聚合器,实施模型路由、缓存和会话管理都会大大降低每个有用输出的有效成本。
常见问题解答
为什么 OpenClaw 比 ChatGPT 使用这么多 Token?
差异源于架构。ChatGPT 对话在服务器端管理,具有优化的上下文处理。OpenClaw 每次请求都发送完整的对话历史,加上工具定义、工作区文件和安全头。这种透明度和控制的代价是更高的 Token 使用。本指南中的优化策略帮助你在保持 OpenClaw 灵活性的同时重新获得效率。
我可以用 Claude Pro 订阅和 OpenClaw 一起吗?
不能。Claude Pro 和 Max 订阅只能通过 Claude.ai 网页界面使用。OpenClaw 需要 API 访问,按 Token 单独计费。这是一个常见的困惑来源——拥有 Pro 订阅不会降低你的 OpenClaw 成本。
如何知道提示缓存是否在工作?
运行 /usage full 在响应脚注中查看缓存命中统计。在正常使用期间,你应该看到系统提示的缓存读取百分比高于 80%。如果比率较低,检查你的缓存 TTL 是否合适,以及请求之间是否有什么使缓存失效。
高效使用 OpenClaw 的最低预算是多少?
大多数用户通过适当优化可以在每月 20-40 美元的预算下高效运作。这假设主要使用 Haiku 和 Sonnet,偶尔为复杂任务使用 Opus。没有优化,相同的使用模式可能花费 100-200 美元/月。本指南中的优化不仅适用于重度用户——它们让 OpenClaw 对每个人都可及。
我应该对所有事情都使用批处理吗?
批处理提供 50% 折扣但需要 24 小时处理窗口。它非常适合非紧急任务,如批量分析、内容生成积压或不需要立即结果的研究。交互式工作应使用标准处理——响应性值得溢价。
我应该多久重置一次会话?
对于昂贵的模型(Opus),每个主要任务后重置。对于标准使用(Sonnet),当上下文超过 50% 或活跃使用 2-3 小时后重置。配置 30-60 分钟的自动空闲重置,这样自然的工作间断会自动触发新会话。