OpenClaw 自定义模型设置本质是路由问题,不是复制粘贴模型名。你要证明四件事:provider 认证有效、OpenClaw 能看到 provider/model catalog、所选 provider/model ref 指向你想要的端点、fallback route 已配置且能在当前任务上工作。模型 ID、base URL、价格、上下文窗口和工具支持都会变化,所以这篇文章只给安全配置形状和验证流程,不把某个旧 provider 表当成长期合同。
什么时候需要 custom provider
如果目标 provider 已经在当前 OpenClaw 内置目录中,并且你不需要覆盖 base URL、headers 或模型列表,优先使用内置 onboarding/auth 流程。这样最少踩到 merge、allowlist、secret 和 route 命名问题。
需要自定义 provider 的典型情况包括:
- 公司内部网关或 LiteLLM/代理服务。
- OpenAI-compatible 第三方 API。
- Anthropic-compatible proxy。
- Ollama、vLLM、LM Studio、llama.cpp 等本地或自托管运行时。
- 想显式控制 allowlist、fallback、capabilities、成本字段或 route 命名。
判断规则很简单:端点接受 OpenAI chat completions 语义,就按 OpenAI-compatible 配置;端点接受 Anthropic messages 语义,才按 Anthropic-compatible 配置;两者都不是,就先用 gateway/adapter 转成稳定协议再接入 OpenClaw。
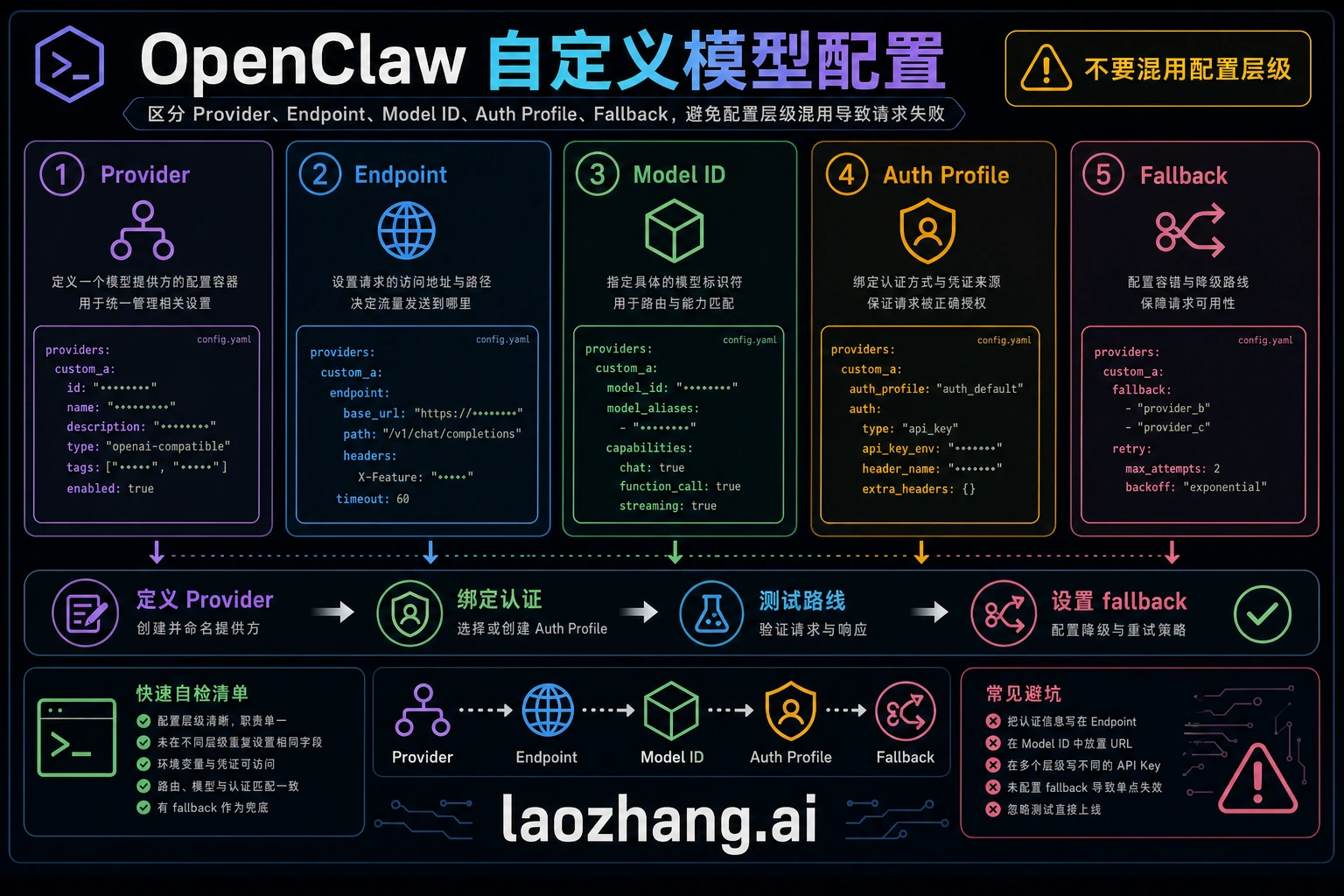
OpenClaw 模型系统的三个核心概念
第一,model ref 是 provider/model-id。 OpenClaw 用第一个斜杠区分 provider 和 model id。模型 ID 本身带斜杠时,也要让 provider 前缀保持清楚,避免路由到错误 provider。
第二,primary 与 fallback 是任务路线,不是装饰字段。 fallback 只有在备用 route 已认证、允许、配额充足,并且支持相同工具、上下文、附件和输出要求时才有意义。一个 text-only fallback 不能安全接替需要图像输入或工具调用的任务。
第三,allowlist 会拒绝未列出的模型。 如果 agents.defaults.models 或类似 allowlist 生效,新 provider 出现在 models.providers 里仍可能被拒绝。看到 Model 'provider/model' is not allowed 时,先查 allowlist,再查 auth。
models.providers 安全配置形状
下面是形状参考。替换 provider id、base URL、env name 和模型 ID 前,先查当前 provider 文档和你的账号权限。
json5{ agents: { defaults: { model: { primary: "providerid/provider-model-id" } } }, models: { mode: "merge", providers: { providerid: { baseUrl: "https://api.example.com/v1", apiKey: "${PROVIDER_API_KEY}", api: "openai-completions", models: [ { id: "provider-model-id", name: "Provider Model Name", input: ["text"] } ] } } } }
api 类型由 endpoint 协议决定,不由品牌名决定。看 provider 的最小 curl 示例:如果它调用 /v1/chat/completions 或 OpenAI-compatible SDK,一般用 openai-completions;如果它要求 Anthropic messages payload,才用 anthropic-messages。
成本、上下文窗口、最大输出、cache 字段和 reasoning/capability 字段都可以帮助 OpenClaw 做路由和预算判断,但只有当前验证过才应该写入。过期价格或错误窗口比不填更危险,因为它会误导 fallback 和成本判断。
添加 provider 后的验证流程
保存配置后,不要直接开始正式 agent run。按这个顺序验证:
bashopenclaw models list --provider providerid openclaw models status openclaw logs --follow
如果你的版本支持 live probe,再用 probe 验证 tool support、vision input 和真实连接。验证时要从启动 gateway 的同一个环境读取 secret,不要只在交互式 shell 里 export 变量。Docker、systemd、LaunchAgent 和 CI 环境都可能有自己的环境变量来源。
如果 provider 自己的 curl 示例失败,先修 provider key、base URL、模型 ID 或网络。只有当 provider curl 成功而 OpenClaw 失败时,才继续查 model ref、allowlist、generated models.json、merge/replace 行为和 gateway process environment。
云端 API、网关和代理
OpenAI-compatible 云端或网关 endpoint 适合统一 billing、fallback、budget routing、审计或简化多 provider 接入。但 gateway 不是“官方上游价格”,也不是“自动增加 quota”。每个上游 route 仍然有自己的账单 owner、rate limit、model coverage、tool behavior 和上下文窗口。
像 laozhang.ai 这样的 provider-gateway 只有在读者目标是多 provider 路由、成本控制、fallback 或简化接入时才应该加入配置。发布前必须验证当前 endpoint、模型 ID、价格、quota 行为、上下文窗口和工具支持。不要把任何 gateway 写成“保证可用”“不限速”或“自动翻倍额度”。
OAuth、plugin-backed route、免费层和区域端点都属于易变事实。只有当前 OpenClaw provider docs 明确支持,并且你在自己的环境中完成认证和 models status 验证后,才把它写成可执行路线。
本地模型:Ollama、vLLM、LM Studio、LiteLLM
本地模型可以减少 provider API spend,并让更多数据留在本机,但它把限制从 provider quota 转移到硬件、延迟、上下文、工具调用能力和维护成本上。不要把“本地”写成无成本、无限制或天然生产可用。
Ollama 适合快速本地实验。某些 OpenClaw 版本可能能自动发现本地 Ollama route;不能自动发现时,就按 OpenAI-compatible local provider 显式配置。模型 ID 应来自你当前 Ollama catalog,并用实际任务测试工具调用、上下文和延迟。
json5{ agents: { defaults: { model: { primary: "ollama/local-model-id" } } } }
vLLM 适合你自己管理 GPU server、batching 和吞吐的场景。http://localhost:8000/v1 是常见形状,不是保证 endpoint。Docker 中的 localhost 往往指容器本身,必要时改用 service name、host.docker.internal 或宿主机可达地址。模型长度、batching 和显存参数应按 vLLM 当前文档与实际硬件调优。
LM Studio 适合桌面测试本地模型。配置时 provider/model id 要匹配实际加载的模型,不要把模板里的 contextWindow 或 maxTokens 当成事实。
LiteLLM 是 proxy,不是本地推理运行时。它可以统一多 provider endpoint、日志、预算和策略,但不会自动创造更多 quota,也不保证 fallback 一定成功。只把 LiteLLM 实例实际服务的模型写进 catalog。
| Route 类型 | 适合场景 | 最常见错误 |
|---|---|---|
| 内置 provider | 当前 OpenClaw 已支持 provider/auth | 重复添加 custom provider,和内置目录冲突 |
| OpenAI-compatible endpoint | /v1/chat/completions 或兼容 SDK | base URL 少 /v1、env key 不在 gateway 环境 |
| Anthropic-compatible endpoint | 真正实现 Anthropic messages 语义 | 把 direct Anthropic beta/OAuth 假设发送给 proxy |
| 本地 runtime | Ollama、vLLM、LM Studio、llama.cpp | Docker 内用错 localhost |
| 多 provider gateway | 统一 billing/fallback/budget/logging | 把 gateway 当作官方上游能力或保证 quota |
Fallback 和安全
一个实用 fallback 配置会按任务风险分配 route:强模型处理架构、安全、多文件变更;便宜或本地 route 处理摘要、检索和低风险编辑;gateway route 用于已验证的多 provider fallback。
json5{ agents: { defaults: { model: { primary: "primary-provider/primary-model", fallbacks: [ "fallback-provider/fallback-model", "gateway-provider/gateway-model" ] } } } }
fallback 是可控降级,不是成功保证。它不能修复 invalid credentials、unsupported beta flags、broken hub download,也不能让所有模型都支持同样上下文、附件和工具。
安全上,API key 不应直接写进 openclaw.json。使用 ${VAR_NAME}、secret manager、Docker secrets 或 team vault。团队共享配置时,把结构化 config 放进版本控制,把实际 secret 放在外部系统;allowlist 用来限制可激活模型,成本字段只在当前价格验证后用于内部 routing hint。
常见错误
Model 'provider/model' is not allowed:allowlist 拒绝了新模型。把 model ref 加入当前 allowlist,或在个人环境中明确关闭 allowlist。
Connection refused 或 ECONNREFUSED:OpenClaw 访问不到 baseUrl。先用 provider 的 curl 示例或 /v1/models 端点测试。Docker 中尤其要确认 localhost 指向哪里。
Invalid API key 或 401 Unauthorized:secret 没进入 gateway 进程、变量名不匹配、key 被撤销、base URL 指向错误 provider,或模型不在账号权限内。先查有效环境,再查 provider console。
Unknown provider:model ref 里的 provider 名称和 models.providers key 不一致。my-llm/model、myllm/model 和 myLLM/model 是不同 route。
Tool calling failed:模型或 proxy 不支持 OpenClaw 所需的 structured tool call。不要把这类模型作为主 agent route,除非你的任务只是简单 completion。
响应很慢或 timeout:可能是本地模型未加载、硬件不足、网络延迟、provider queue、context 太大或 upstream throttling。延长 timeout 之前,先证明 endpoint 和 route 是正确的。
FAQ
自定义微调模型能用吗?
可以,只要它通过 OpenAI-compatible 或 Anthropic-compatible endpoint 服务,并且 id、context、output limit 和 tool support 都用当前环境验证过。
聊天中怎么切换模型?
使用 /model 加完整 provider/model 引用,并用 /model list 或当前版本的 models 命令确认可用性。运行中的请求是否立即切换取决于当前 OpenClaw 版本。
自定义 provider 宕机怎么办?
只有已配置、已认证、已测试的 fallback 才能接管。没有 fallback,当前请求会失败,你需要手动切换 route 或修复 provider。
能添加多少 custom provider?
这不是数字问题。更多 provider 意味着更多 key、日志、成本、model ID、allowlist 和 incident 分支。只添加你能持续测试和监控的 route。
models.providers 是否适用于 CLI 以外的界面?
只要该界面通过同一个 gateway/config 解析模型,理论上会使用同一套 provider 配置。但 dashboard、channel、API client 和 reload 行为都可能随版本变化。修改后要在实际使用的界面上验证。