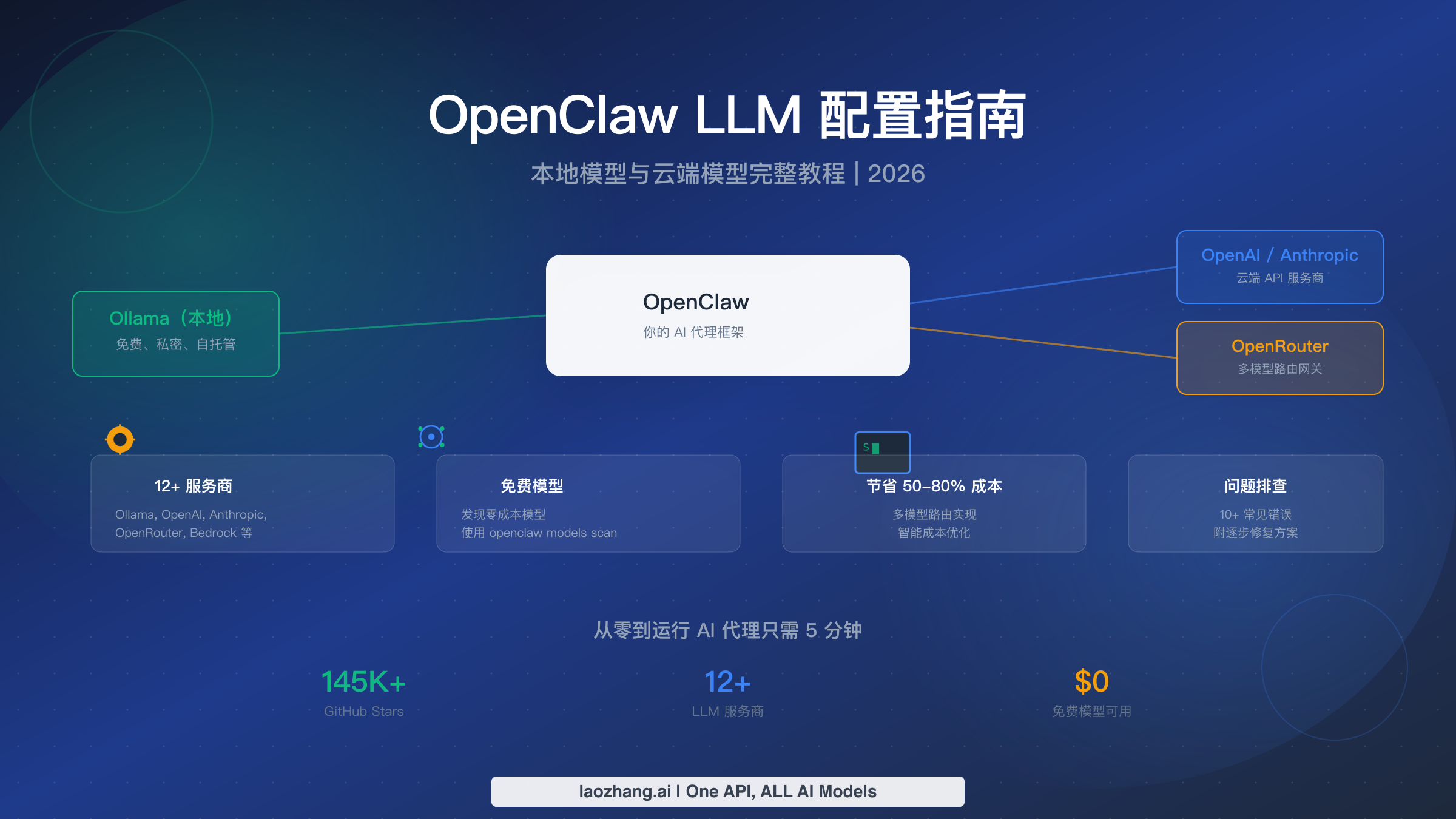
OpenClaw 模型配置已经不再是固定的“12 个 provider”清单。截至 2026 年 5 月 8 日,当前合约是:选择 provider surface,完成该 provider 的认证,把模型设为 provider/model,用 OpenClaw 的 model 命令验证;只有在需要覆盖内置 provider、添加自定义 base URL,或定义 OpenClaw 不能自动发现的代理/本地模型时,才使用 models.providers。
真正要问的不是“哪个模型最好”,而是“哪条路线拥有认证、限流、上下文行为、缓存行为和回退”。Anthropic API key、Claude CLI/OAuth 风格路线、OpenAI/Codex、Google Gemini、Bedrock、Ollama、LM Studio、OpenRouter、Vercel AI Gateway 和自定义代理,配置完成后看起来都像一个模型,但失败点完全不同。本指南从路线拆分开始,帮助你一次设对模型,并在出错时调试正确层级。
OpenClaw 是什么以及为什么 LLM 选择至关重要
OpenClaw 是一个自托管 agent Gateway,可连接聊天入口、Control UI、工具、技能、本地执行和模型提供商。与简单聊天壳不同,OpenClaw 会让所选模型通过工具、文件、Shell 命令、浏览器流程、记忆、频道和插件执行任务。因此 provider 选择是系统决策,不是偏好选择。
你配置的 provider 决定五件事:模型目录、凭据存储、请求传输、限流归属,以及 OpenClaw 能否安全发送 provider 专属请求特性。直接 Anthropic 路线可以使用 prompt caching 和符合条件时的显式 1M context beta;Bedrock 路线使用 AWS SDK 凭据链和 Bedrock Converse streaming,不是 Anthropic API key;自定义 OpenAI-compatible 代理也不能当作 native OpenAI,因为 OpenClaw 会在非 native endpoint 上跳过 native-only 的请求整形。
先用这张当前路线图定位:
| 路线 | 最适合 | 配置归属 | 模型引用格式 | 需要验证 |
|---|---|---|---|---|
| Direct Anthropic | Claude-first 编码、符合条件的长上下文 | openclaw onboard 或 Anthropic provider auth | anthropic/claude-opus-4-6 | API key/profile、cacheRetention、可选 params.context1m |
| OpenAI / Codex | GPT 或 Codex 工作流 | API key 或 OAuth 路线 | openai/... 或 openai-codex/... | native/proxy endpoint、权限、模型目录 |
| Google Gemini | Gemini API key 或 Gemini CLI | Google provider auth | google/... 或 google-gemini-cli/... | API key/OAuth 账号、project env、模型规范化 |
| Amazon Bedrock | 企业 AWS 控制和 IAM | AWS SDK 凭据链 | amazon-bedrock/<model-id> | 区域、模型权限、ListFoundationModels、ListInferenceProfiles |
| 本地运行时 | 隐私、离线测试、低成本回退 | Ollama/LM Studio/vLLM provider | ollama/...、lmstudio/... 或 custom | 本地服务、上下文上限、timeout、模型内存 |
| 自定义代理 | 区域访问、网关计费、私有 relay | models.providers.<id> | <custom-id>/<model-id> | Base URL、API shape、显式模型元数据、不支持的 native 参数 |
后文仍保留实践路径,但第一条规则更严格:不要把 2 月旧 provider 列表或价格表直接拿去做生产规划。先用 onboarding 或当前 provider 文档确认,再从运行 Gateway 的主机验证解析后的模型。
如何选择合适的 LLM 服务商
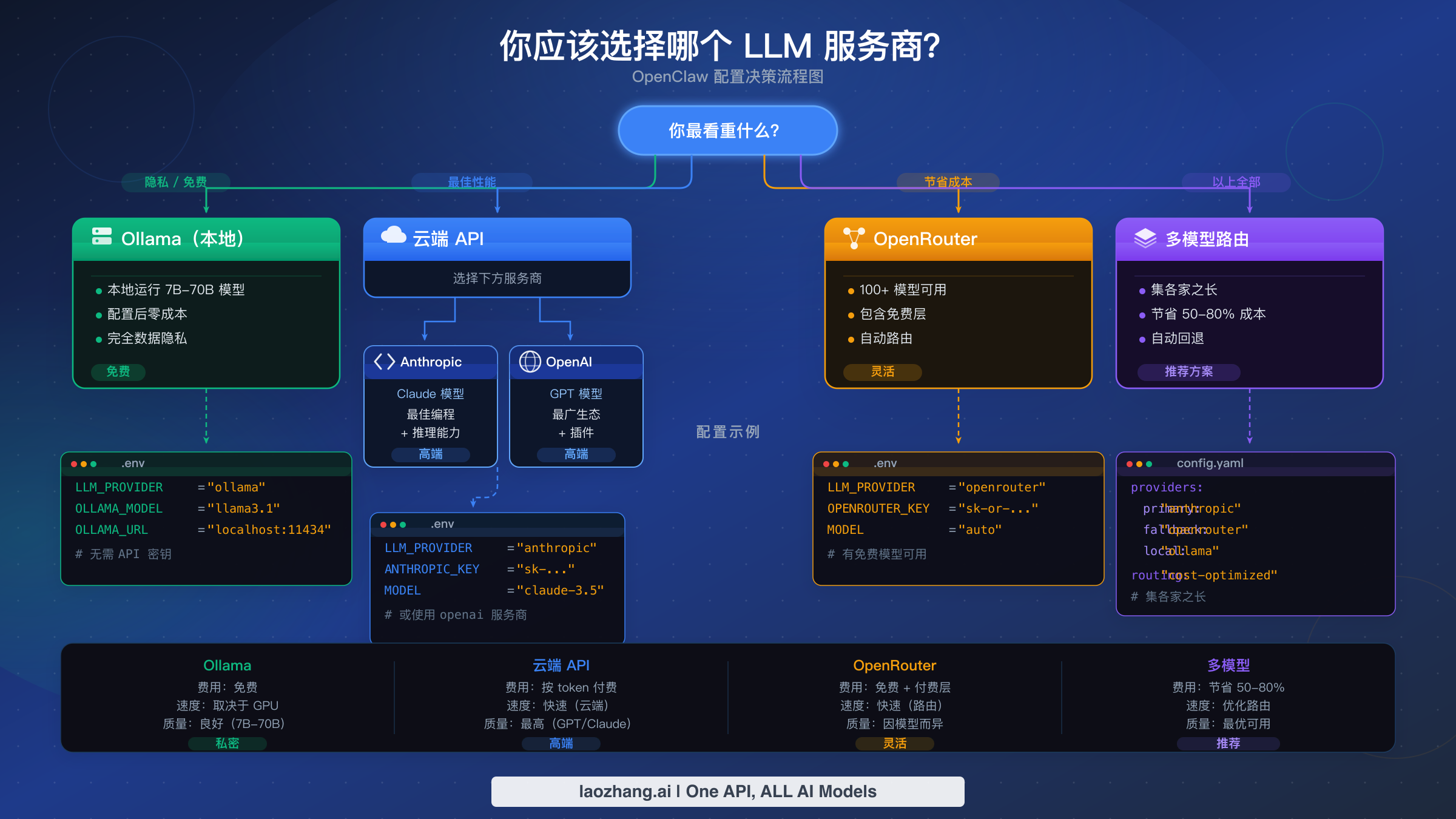
为 OpenClaw 选择合适的 LLM 服务商归结为四个因素:你的预算、你的硬件条件、你的隐私需求以及你计划运行的任务复杂度。本节不会罗列每个服务商让你自己去研究,而是根据你最看重的因素给出具体的决策路径。上方的流程图总结了四条主要路径,下方的决策表将常见场景映射到具体推荐方案。
| 优先级 | 推荐路线 | 第一测试模型 | 配置难度 | 主要风险 |
|---|---|---|---|---|
| 隐私 + 本地控制 | Ollama 或 LM Studio | 适合内存的小型编码模型 | 中等 | 模型弱或本地超时 |
| 最佳 Claude 工作流 | Direct Anthropic | anthropic/claude-opus-4-6 或当前 Sonnet | 简单 | API key 权限、限流、1M-context beta 资格 |
| OpenAI/Codex 工作流 | Native OpenAI 或 OpenAI Codex | 当前有权限的 GPT/Codex 模型 | 中等 | 把 native endpoint 和 proxy endpoint 混为一谈 |
| 云端企业控制 | Amazon Bedrock | amazon-bedrock/... Claude profile/model | 较难 | AWS 区域、模型访问、IAM 权限 |
| 区域或网关访问 | OpenAI/Anthropic-compatible proxy | provider 自有 model id | 中等 | 缺少元数据、不支持 headers、API shape 错误 |
如果隐私是首要目标,从 Ollama 或 LM Studio 这类本地运行时开始。重点不是“免费还是付费”,而是模型是否能可靠跟随工具调用。把本地模型用于私有草稿、简单文件编辑和离线回退;遇到深度多文件推理、长上下文或高可靠工具调用,再升级到更强云端路线。
如果你想要最佳 Claude 工作流,优先使用当前 OpenClaw 文档暴露的 direct Anthropic provider 或受认可的 Claude CLI/OAuth 路线。这样 Anthropic 专属行为、prompt caching 和可选长上下文设置都留在真正理解它们的路线里。如果你需要 AWS 控制,就使用 Bedrock,并接受它的请求 surface 与 direct Anthropic 不同。
如果你要云端灵活性,先理解 native 与 proxy-style 的差异。OpenClaw 会在非 native endpoint 上跳过 native-only OpenAI 请求整形,也会在非 direct Anthropic-compatible endpoint 上抑制隐式 Anthropic beta headers。这能保护很多配置,但也意味着不要期待每个 native 功能都能跨过 proxy。
如果你要最大韧性,把一个可靠默认模型和小型 fallback chain 组合起来。Fallback chain 不是自动省钱魔法;它通常在主路线失败或不可用时触发。真正的成本分层,应通过显式切换模型或为不同任务创建不同默认模型的 agent 来完成。
使用 Ollama 配置本地模型
Ollama 是 OpenClaw 最流行的本地 LLM 运行时,原因充分:它免费、所有数据留在本地、无需 API 密钥。配置过程分为三个阶段——安装 Ollama、拉取模型、连接到 OpenClaw。在网络连接良好的现代机器上,整个过程不到十分钟。
安装 Ollama 在三大主流平台上都很简单。在 macOS 上,从 ollama.com 下载安装程序或使用 Homebrew。在 Linux 上,官方安装脚本会处理一切。在 Windows 上,Ollama 提供了原生安装程序。
bashbrew install ollama # Linux (official script) curl -fsSL https://ollama.com/install.sh | sh # Windows: download from ollama.com/download
安装完成后,启动 Ollama 服务器。在 macOS 和 Windows 上,桌面应用会自动启动服务。在 Linux 上,你可能需要手动运行 ollama serve 来启动服务。服务器默认监听 http://127.0.0.1:11434——这就 是 OpenClaw 将要连接的端点。
拉取合适的模型完全取决于你的可用内存。这是大多数用户犯的第一个错误:他们试图在 16GB 笔记本上拉取一个 70B 参数的模型,然后困惑为什么一切都卡住了。经验法则是,对于量化模型,每十亿个参数大约需要 1GB 内存,还要为操作系统和 OpenClaw 本身留出额外空间。
| 可用内存 | 推荐模型 | 参数量 | 预期速度 | 适用场景 |
|---|---|---|---|---|
| 8GB | qwen2.5-coder:3b | 3B | 25-35 tok/s | 轻量编辑、简单脚本 |
| 16GB | qwen2.5-coder:7b | 7B | 15-20 tok/s | 单文件编程、调试 |
| 32GB | deepseek-coder-v2:16b | 16B | 12-18 tok/s | 多文件任务、中等推理 |
| 64GB+ | deepseek-coder-v2:33b | 33B | 10-15 tok/s | 复杂重构、架构设计 |
用一条命令拉取你选择的模型:
bash# For 16GB machines (most common) ollama pull qwen2.5-coder:7b # Verify the model is available ollama list
将 Ollama 连接到 OpenClaw 通过配置向导完成。运行 openclaw onboard 并选择 Ollama 作为服务商。向导会检测你已经拉取的模型并让你选择。在后台,它会将配置写入 OpenClaw 设置文件中的 agents.defaults.model.primary 键。
bash# Start the setup wizard openclaw onboard # Or configure manually via CLI openclaw models set ollama/qwen2.5-coder:7b
如果你更倾向于手动配置,关键的环境变量是 OLLAMA_API_KEY。尽管名字中包含"KEY",Ollama 实际上并不需要认证——设置为任意非空字符串如 ollama-local 即可满足 OpenClaw 的验证要求:
bashexport OLLAMA_API_KEY="ollama-local"
官方文档中有一个重要细节:OpenClaw 默认禁用了 Ollama 的流式输出。这意味着你会看到完整的响应一次性出现,而不是逐 token 显示。对于大多数代理工作流来说这没有问题,但如果你更喜欢流式输出,可以在服务商配置中启用。
验证配置是否正确 是很多教程跳过的关键步骤。将 Ollama 连接到 OpenClaw 后,发送一个简单的测试提示来确认一切端到端正常工作。如果代理能返回连贯的输出并执行基本的工具调用(比如列出目录中的文件),说明你的本地 LLM 已正确配置,所有 token 都在你自己的硬件上处理。如果你看到乱码输出或代理拒绝使用工具,可能是模型缺乏足够的工具调用能力。不要把问题归咎于 OpenClaw 之前,先换到明确支持 tool calling / function calling 的本地 coding 模型,再用一个真实文件操作任务验证。
本地模型的性能调优 会在日常使用中带来明显差异。如果响应感觉很慢,用 ollama ps 检查 Ollama 在内存中加载了多少个模型。Ollama 会将最近使用的模型保留在内存中,同时加载多个大型模型会降低性能。使用 ollama stop MODEL_NAME 卸载你不再使用的模型。在 Apple Silicon Mac 上,确保 Ollama 使用了 GPU 加速——这通常自动发生,但你可以在 Ollama 日志中验证。对于使用 NVIDIA GPU 的 Linux 用户,安装相应驱动后 Ollama 支持 CUDA 加速,与纯 CPU 推理相比可以将推理速度提升 3-5 倍。
配置云端 LLM 服务商

云端服务商让 OpenClaw 访问更强的推理模型,但真正需要判断的是“路由契约”,而不是只问哪个模型最强。Direct Anthropic、OpenAI/Codex、Google Gemini、AWS Bedrock、本地 Ollama 和 OpenAI-compatible gateway 的认证方式、模型命名、beta header、tool calling 支持都不完全相同。把这些路线混成一个 baseURL 是很多配置错误的来源。
OpenAI / Codex 路线适合已经有 OpenAI Platform 计费、团队密钥和审计流程的用户。设置时只需要把 key 写入环境变量或通过 onboard 向导保存,然后用 OpenClaw 的 model status 命令确认实际选中的 provider/model:
bashexport OPENAI_API_KEY="sk-proj-..." openclaw onboard --install-daemon openclaw models status
Direct Anthropic 路线适合明确需要 Claude 原生能力、Anthropic-native Messages API 行为或 1M context 显式开关的用户。这里的关键不是写入一个 key,而是确认你走的是 direct Anthropic provider,而不是把 Claude 模型名塞进 OpenAI-compatible endpoint。
bashexport ANTHROPIC_API_KEY="sk-ant-..." openclaw config validate openclaw models status
如果你遇到认证问题,先读 Anthropic API 密钥配置问题指南。如果错误是 invalid beta flag,不要回到旧的 beta_features: [] 片段,而是按 provider route 判断:direct Anthropic、Bedrock、custom proxy 的修复方式不同。
AWS Bedrock 路线适合企业 IAM、VPC endpoint、区域控制和合规审计优先的团队。它不是“Anthropic API 换了一个 baseURL”,而是单独的 provider 路径,通常需要 AWS 凭据链和 amazon-bedrock provider 配置。选择 Bedrock 的代价是部分 Anthropic beta/header 行为不能照搬 direct API。
OpenAI-compatible gateway 路线适合你已经有一个统一网关、私有代理或多模型平台,希望 OpenClaw 只面向一个兼容 endpoint。这里必须确认三件事:模型 ID 是否由网关公开、tool calling 是否透传、错误是否能回到真实上游。不要把任意代理当成 Anthropic 原生 API 使用。
使用免费或低成本模型运行 OpenClaw
OpenClaw 可以用本地模型降低 API 成本,也可以接入有免费额度或低价模型的云端平台。但“免费模型”不应被包装成生产答案。它更适合学习 OpenClaw、验证工具调用、跑轻量文件整理或作为 outage fallback。生产代码修改、复杂多文件推理、长上下文分析仍应优先使用能力更强且稳定的模型。
bash# Discover configured models where supported openclaw models list # Check the currently active route openclaw models status
使用免费模型时,评估标准不是“能不能回答 hello world”,而是能否完成你的真实任务:能不能读取项目文件、能不能按要求编辑、能不能处理工具调用失败、能不能在长上下文里保持约束。只要这些能力不足,就把它放在 fallback 或学习环境,而不是主模型。
本地 Ollama 仍然是隐私最强的低成本路线。敏感代码、不能出网的数据、离线演示都适合走本地模型;但本地模型的瓶颈通常是上下文窗口、推理速度和工具调用质量。用硬件能力和任务类型来决定,而不是因为“零 API 成本”就默认所有任务都本地化。
成本优化与多模型路由
成本优化的核心不是追逐某个固定价格表,而是让模型能力匹配任务难度。价格、免费额度和模型可用性都属于挥发性信息,发布文案里不应该写未经当轮验证的具体价格或节省百分比。更稳妥的做法是配置 fallback chain、消费提醒和任务分层。
yamlagents: defaults: model: primary: "openai/gpt-current" fallbacks: - "anthropic/claude-current" - "ollama/qwen-coder-local"
这个结构表达的是策略,而不是固定推荐:主模型负责日常工作,第二个云端 provider 用于 rate limit / outage 备用,本地模型负责离线或敏感任务。你可以把更便宜的模型放在主模型位置,但前提是它通过了真实工作流测试。否则便宜模型造成返工,实际成本会更高。
实际运行时,使用 openclaw dashboard 或 provider billing dashboard 观察三项指标:每次会话的上下文长度、fallback 触发频率、失败后重试次数。上下文越来越长时,先清理会话或拆任务;fallback 频繁触发时,说明主 provider 不稳定或限额太低;重试次数高则通常意味着模型能力不足或 route 配置错误。
OpenClaw LLM 常见问题排查
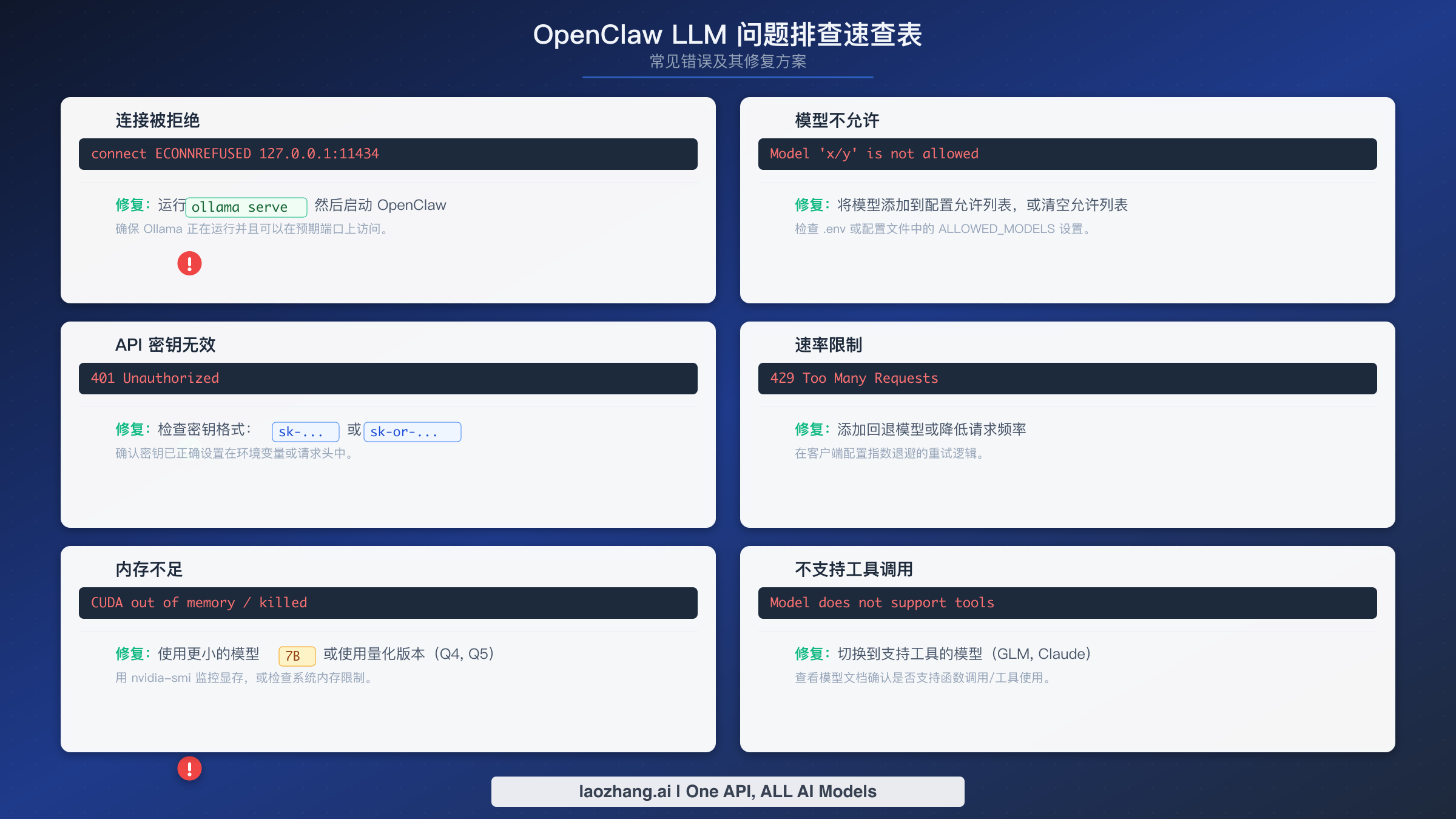
每个 OpenClaw 用户在配置过程中都会遇到这些错误中的至少一个。这种挫败感是真实的——你花了时间配置一切,然后一个晦涩的错误消息挡住了去路。本节涵盖十个最常见的 LLM 相关错误,包含它们的确切错误信息和经过验证的解决方案,让你能在几分钟而不是几小时内恢复正常工作。
错误 1:"Connection refused"(连接被拒绝)使用 Ollama 时。 这意味着 OpenClaw 无法连接到 http://127.0.0.1:11434 上的 Ollama 服务器。修复方法几乎总是因为 Ollama 服务器未运行。在 macOS 上,打开 Ollama 桌面应用。在 Linux 上,在单独的终端中运行 ollama serve。用 curl http://127.0.0.1:11434/api/tags 验证服务器是否可访问——如果你得到一个列出模型的 JSON 响应,说明服务器正在运行,问题可能是防火墙或代理配置阻止了 localhost 连接。
bash# Check if Ollama is running curl http://127.0.0.1:11434/api/tags # Start Ollama server (Linux) ollama serve # If using a custom port, update OpenClaw config export OLLAMA_BASE_URL="http://127.0.0.1:YOUR_PORT"
错误 2:"Model not allowed"(模型不允许)或"Model not found"(未找到模型)。 当你请求的模型在服务商上不存在或你的 API 层级不可用时会出现此错误。对于 Ollama,这意味着你还没有拉取该模型——运行 ollama pull MODEL_NAME。对于云端服务商,仔细检查模型标识符:OpenClaw 使用 provider/model-name 格式,任何一部分的拼写错误都会触发此错误。使用 openclaw models list 查看所有已配置服务商的可用模型。
错误 3:"Invalid API key"(无效 API 密钥)或认证失败。 API 密钥缺失、格式不正确或已过期。Anthropic 的密钥以 sk-ant- 开头,OpenAI 的密钥以 sk-proj-(新格式)或 sk-(旧格式)开头,OpenRouter 的密钥以 sk-or- 开头。检查你是否设置了正确的环境变量(ANTHROPIC_API_KEY、OPENAI_API_KEY 或 OPENROUTER_API_KEY),并确保密钥中没有尾随空格或换行符。一个常见错误是从密码管理器中复制密钥时带入了不可见字符。
错误 4:"Rate limit exceeded"(超出速率限制)(HTTP 429)。 你发送请求的速度太快了。这在具有较低速率限制的免费层 API 账户中特别常见。临时修复方法是等待 30-60 秒后重试。长期解决方案是配置带有回退的多模型路由,这样当一个服务商对你进行速率限制时,代理会自动切换到另一个。对于持续的速率限制问题,我们的速率限制超出错误详细指南涵盖了各服务商的具体限制和缓解策略。
错误 5:"Out of memory"(内存不足)运行本地模型时。 你试图运行的模型超出了可用内存。修复方法很简单:切换到更小的模型。如果你有 16GB 内存却拉取了 30B 参数的模型,切换到 7B 版本。使用 ollama list 查看已安装的模型,参考上方 Ollama 配置部分的硬件-模型对照表来找到适合你机器的模型。
错误 6:"Tool calling not supported"(不支持工具调用)或代理无法执行命令。 一些模型,特别是较小的开源模型或经过代理转换的 endpoint,不会完整支持函数调用。修复方法不是只换模型名,而是先确认当前 route 是否透传 tool schema,再切换到明确支持工具调用的云端或本地 coding 模型。
错误 7:"Invalid beta flag"(无效 beta 标志)错误。 这通常是 provider route 与 Anthropic beta header 不匹配:direct Anthropic、Bedrock、custom proxy 的处理不同。先用 openclaw logs --follow 和 openclaw models status 找到真实上游,再按 invalid beta flag 错误修复指南处理。
错误 8:上下文窗口超限。 长对话或大文件可能使总 token 数超过模型的上下文窗口。症状包括截断的响应或关于最大上下文长度的错误。使用 /clear 开始新对话,拆分文件范围,或切换到支持更大上下文的 route。不要在文章或配置注释里写死某个模型的上下文数字,除非你已经在当轮验证。
错误 9:本地模型响应速度慢。 如果本地模型能响应但每次需要 30 秒以上,你可能运行了对你硬件来说过大的模型。用 ollama ps 检查当前模型内存使用情况,并参考硬件对照表来选择合适的模型。同时确保使用 OpenClaw 搭配本地模型时没有其他占用大量内存的应用在运行。
错误 10:配置后 OpenClaw 未识别服务商。 运行 openclaw onboard 后,代理仍然默认使用错误的服务商。使用 openclaw models status 检查当前配置,使用 openclaw models set PROVIDER/MODEL 明确设置你需要的模型。在活跃的 OpenClaw 会话中使用 /model 命令也可以即时切换模型而无需重启。
配置完成后的下一步——提升生产力
LLM 服务商配置并验证完成后,你就可以开始将 OpenClaw 作为真正的生产力工具来使用,而不仅仅是一个实验玩具。那些从 OpenClaw 中获得真正价值的用户和那些一周后就放弃的用户之间的区别,通常归结为你现在就应该养成的三个习惯——趁配置还新鲜的时候。
首先,用一个真实任务来测试你的配置,而不是"hello world"提示。让 OpenClaw 分析你当前项目中的一个文件、重构一个函数或为现有代码编写测试。这能立即验证工具调用是否正常工作、模型是否有足够的能力胜任你的工作、响应时间是否可接受。如果任何方面感觉不对——响应太慢、代码不完整或工具调用失败——重新审视服务商选择部分,考虑是否有更合适的模型。
其次,即使你对主模型很满意,也要配置回退链。服务商中断会发生,关键时刻会遇到速率限制,拥有备选意味着你的工作流永远不会完全中断。至少添加一个云端替代方案和一个本地模型到你的回退配置中。你现在花的五分钟将在不可避免的服务商宕机时为你节省数小时的挫败。
最后,如果你使用的是云端模型,建立成本监控习惯。每周检查你的 API 使用仪表板,在你能接受的阈值处设置计费警报,跟踪你的实际支出是否符合预算预期。如果成本高于预期,上一节的多模型路由策略是你最有效的杠杆——将日常任务路由到更便宜的模型,将高端模型保留给真正需要更强推理能力的复杂工作。
OpenClaw 是一个回报配置投入的工具。获得最大价值的用户是那些将初始配置不视为一次性任务,而是视为不断演进的工作流基础的人。随着你的需求变化和新模型的发布,你的模型选择、回退链和成本策略也会改变。openclaw onboard 向导和 /model 命令让你能轻松适应——关键是保持迭代,而不是满足于一个"够用"的配置。
OpenClaw 生态系统正在快速发展。新的模型服务商定期增加,随着竞争加剧价格不断变化,本地模型能力也在每一代中提升。收藏本指南,每当你考虑更改配置时重新审视服务商决策框架。核心原则——将模型能力匹配到任务复杂度、配置回退以确保可靠性、主动监控成本——即使具体的模型推荐不断演变,这些原则也始终不变。你最初五分钟的配置只是一个开始,随着数周和数月的日常使用,你的工作流将会越来越强大。
常见问题解答
OpenClaw 能同时使用多个 LLM 服务商吗?
可以。OpenClaw 的 agents.defaults.model.fallbacks 回退链配置支持多个服务商。主模型优先处理请求,如果失败或被速率限制,代理会自动尝试链中的下一个模型。你也可以在会话中使用 /model 命令切换服务商。许多用户将本地 Ollama 模型配置为最终回退,确保即使所有云端服务商都不可达时代理仍能工作。
运行 OpenClaw 搭配本地 LLM 的最低硬件要求是什么?
最低要求是 8GB 内存,可以在可用速度下运行 3B 参数模型。要获得本地模型的高效使用体验,16GB 内存运行 7B 参数模型如 Qwen2.5-Coder 是实际的起点。你还需要 Node.js v24 或更高版本以及足够的磁盘空间来存储模型文件(通常每个模型 4-8GB)。配备统一内存的 Apple Silicon Mac 提供了性价比最高的本地推理性能。
如何在不重启 OpenClaw 的情况下切换模型?
在活跃的 OpenClaw 会话中使用 /model 命令。输入 /model 加上服务商和模型名称(例如 /model anthropic/claude-sonnet-4.5),下次交互即刻生效。你也可以在终端中使用 openclaw models set 来更改所有未来会话的默认模型。使用 openclaw models list 查看所有已配置服务商的可用模型。
使用云端 LLM 服务商时我的数据安全吗?
使用云端服务商(OpenAI、Anthropic、OpenRouter)时,你的提示和代码上下文会被发送到服务商的服务器进行处理。每个服务商都有自己的数据保留和隐私政策。如果数据隐私是硬性要求,请使用 Ollama——所有推理在本地进行,没有数据离开你的机器。折中方案是,通过多模型路由系统配置本地模型处理敏感任务、云端模型处理非敏感工作。
使用云端模型运行 OpenClaw 的费用是多少?
费用取决于模型价格、上下文长度、工具调用次数、失败重试和 fallback 策略。不要只看单次 token 单价:如果模型能力不足导致多次返工,实际成本会更高。上线前设置 provider billing alert,并在 OpenClaw 里观察会话长度、fallback 触发率和错误重试次数,这比引用某个旧价格表更可靠。