
GPT-5.6 Sol、Claude Fable 5、Claude Opus 4.8 は、いま同じように使える三択ではありません。2026年6月28日時点で、OpenAI は GPT-5.6 Sol を approved organization 向け limited preview と説明しています。Anthropic は Claude Fable 5 を current access unavailable としています。Claude Opus 4.8 は、今日 coding-agent evaluation に入れられる live Anthropic route です。
実務上の答えは明確です。必要な API org または Codex workspace で Sol preview access があるなら、Sol を高難度 coding task の pilot に入れます。Fable 5 を検討しているなら、Anthropic の official access を待って再確認します。今日 production endpoint、logs、policy、rollback が必要なら、Opus 4.8 を live baseline にします。default model は、同じ repo、同じ prompt、同じ tools、同じ tests、同じ cost log で勝つまで切り替えません。
| 2026-06-28 の current route | 最初の動き | 理由 | stop rule |
|---|---|---|---|
| Sol preview access が該当 surface にある | Sol を hard coding-agent tasks で試す | OpenAI は Sol を GPT-5.6 flagship と位置づけ、terminal-driven coding を強調しています。 | preview workspace の結果を access のない team に広げない。 |
| Claude Fable 5 を検討している | Anthropic access を待って再確認する | Anthropic の current material は Fable 5 unavailable です。 | list price や古い demo を deployability と扱わない。 |
| 今日 production model が必要 | Claude Opus 4.8 を live baseline にする | Opus 4.8 は Anthropic と listed partner routes で available とされています。 | same-task evidence なしに default を変えない。 |
すぐ使える答え
coding team の比較は、モデル名ではなく access から始まります。Sol は興味深い preview model、Fable は現在 production route にできない premium promise、Opus 4.8 は live fallback です。この順序は変わり得るため、access、price、platform claim は 2026年6月28日 に公式資料で確認したものとして扱います。
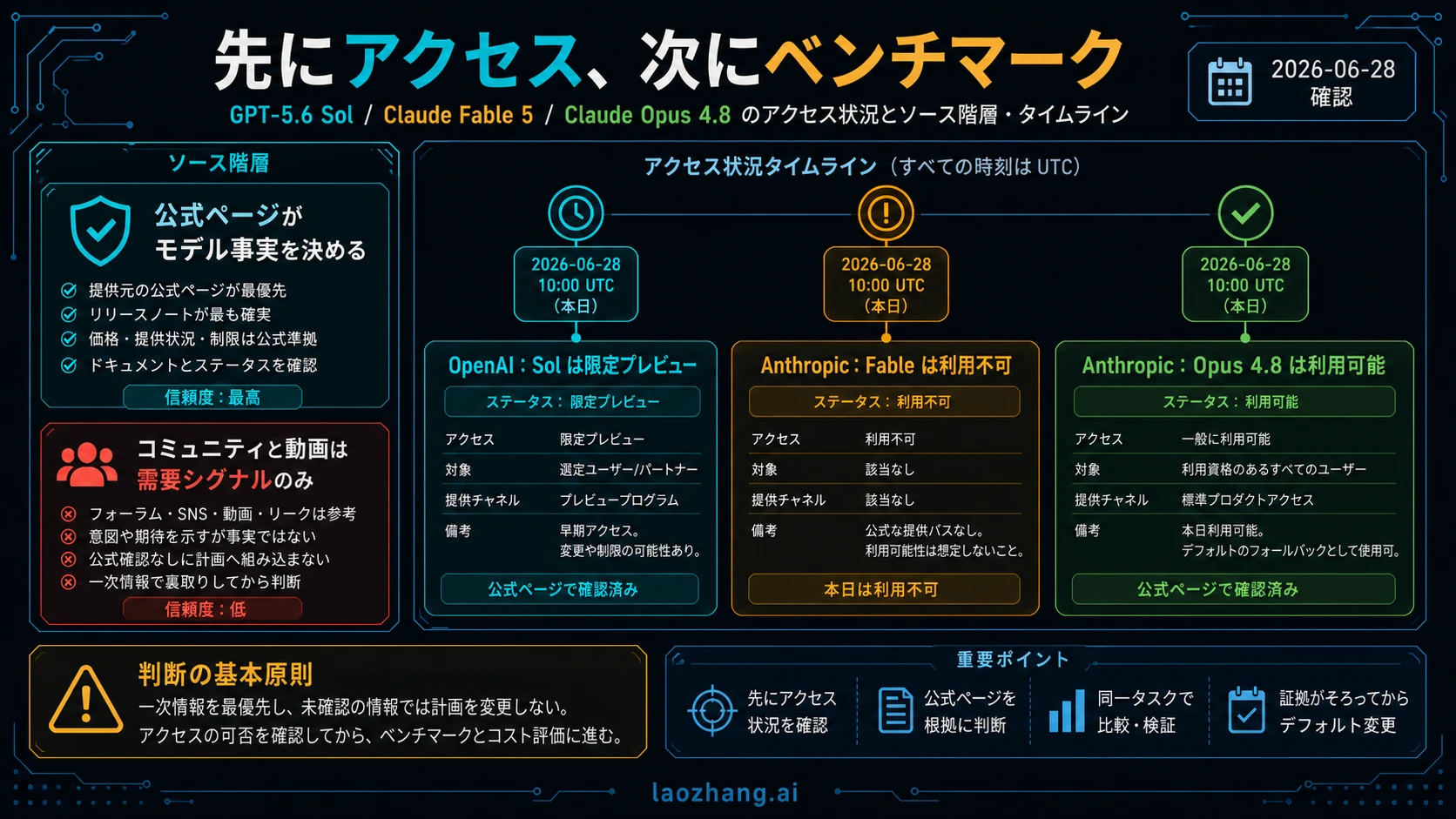
Sol は、approved OpenAI route があり、preview risk を取る価値がある仕事で使います。Opus 4.8 は、supported endpoint、account policy、logs、rollout path が必要な仕事で使います。Fable 5 は、Anthropic が access を戻すまで waitlist/recheck であり、production recommendation ではありません。
精密な比較記事は benchmark table を先に置きがちです。scan には便利ですが、最重要の判断を隠すことがあります。アクセスできない強いモデルは default production model ではありません。unavailable model の高い list price も planning number にすぎません。
Access status が本当の分岐点
OpenAI の GPT-5.6 Sol material は limited preview を説明しており、self-service launch ではありません。Help page は API organization access と Codex workspace access も分けています。つまり、API org の approval は、Codex workspace で Sol が使える証明にはなりません。Codex 依存の migration なら、workspace entitlement を先に確認します。
Anthropic の Fable 5 は逆の境界です。model page、price row、benchmark discussion が残っていても、current access statement が unavailable なら traffic route ではありません。古い video、screenshot、third-party demo は official access status を上書きできません。
Claude Opus 4.8 は今日もっとも deployability contract が明確です。Anthropic Opus page と model overview は、Claude products、Claude Platform、AWS、Google Cloud、Microsoft Foundry を listed route として示します。implementation では `claude-opus-4-8` を確認し、social shorthand や old Opus ID で置き換えません。
| contract item | GPT-5.6 Sol | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|---|
| access status | approved organization と scoped workspace の limited preview。 | current Anthropic materials では unavailable。 | Anthropic と listed partner routes で generally available。 |
| 今日の役割 | access がある場合の preview test。 | wait and recheck。 | live baseline または fallback。 |
| API/model ID | approved OpenAI org で再確認してから実装。 | access disabled の間は production calls を計画しない。 | `claude-opus-4-8`。 |
| 主なリスク | entitlement mismatch と preview の過大解釈。 | 古い demo や list price を live access と誤解する。 | same-task test なしに勝者扱いする。 |
Cost は同じタスクで比較する
official list price は、同じ unit of work に置いたときだけ役に立ちます。OpenAI は Sol preview pricing を `5\` input、\`30` output per million tokens としています。Anthropic は Fable 5 list price を `10\` input、\`50` output としていますが、unavailable の間は deployable row ではありません。Anthropic model docs は Opus 4.8 を `5\` input、\`25` output としています。

200k input と 40k output の coding-agent run では、cache、batch、retry、regional terms を除く単純計算で Sol は約 `2.20\`、Fable は約 \`4.00` ですが unavailable、Opus 4.8 は約 `$2.00` です。これは Opus が常に勝つという意味ではありません。Sol が品質、時間短縮、failure rate 低下で超えるべき live price baseline が Opus だという意味です。
本当に見るべきものは task cost です。output rate が高くても一回で終わり、review minutes が少ない model は安くなります。token row が安くても、tool loop、format drift、人手修正が増えれば高くなります。input、cached input、output、retry、tool call、elapsed time、human review minutes を記録してから switch を承認します。
Benchmark は最初に試す対象を決めるだけ
benchmark は access table を飛ばす理由ではありません。OpenAI の Sol launch は terminal-driven agentic coding を強調し、強い結果を出しています。Sol preview access があり、repository edits、terminal recovery、multi-step coding に近い workload なら、pilot に入れる十分な理由です。
ただし provider benchmark は production team が必要とする答えより狭いものです。account access、tool harness compatibility、long-context prompt drift、total review time の削減までは証明しません。Anthropic が unavailable と書いている Fable 5 を deployable にする力もありません。
benchmark rows は workload hints として使います。terminal coding かつ Sol access があるなら、Sol を first pilot lane に置きます。customer-facing output を持つ live API agent なら、Opus 4.8 を stable lane に置きます。Fable-specific research は harness を残し、Anthropic access page が変わるまで production cutover を予定しません。
Coding-agent test plan
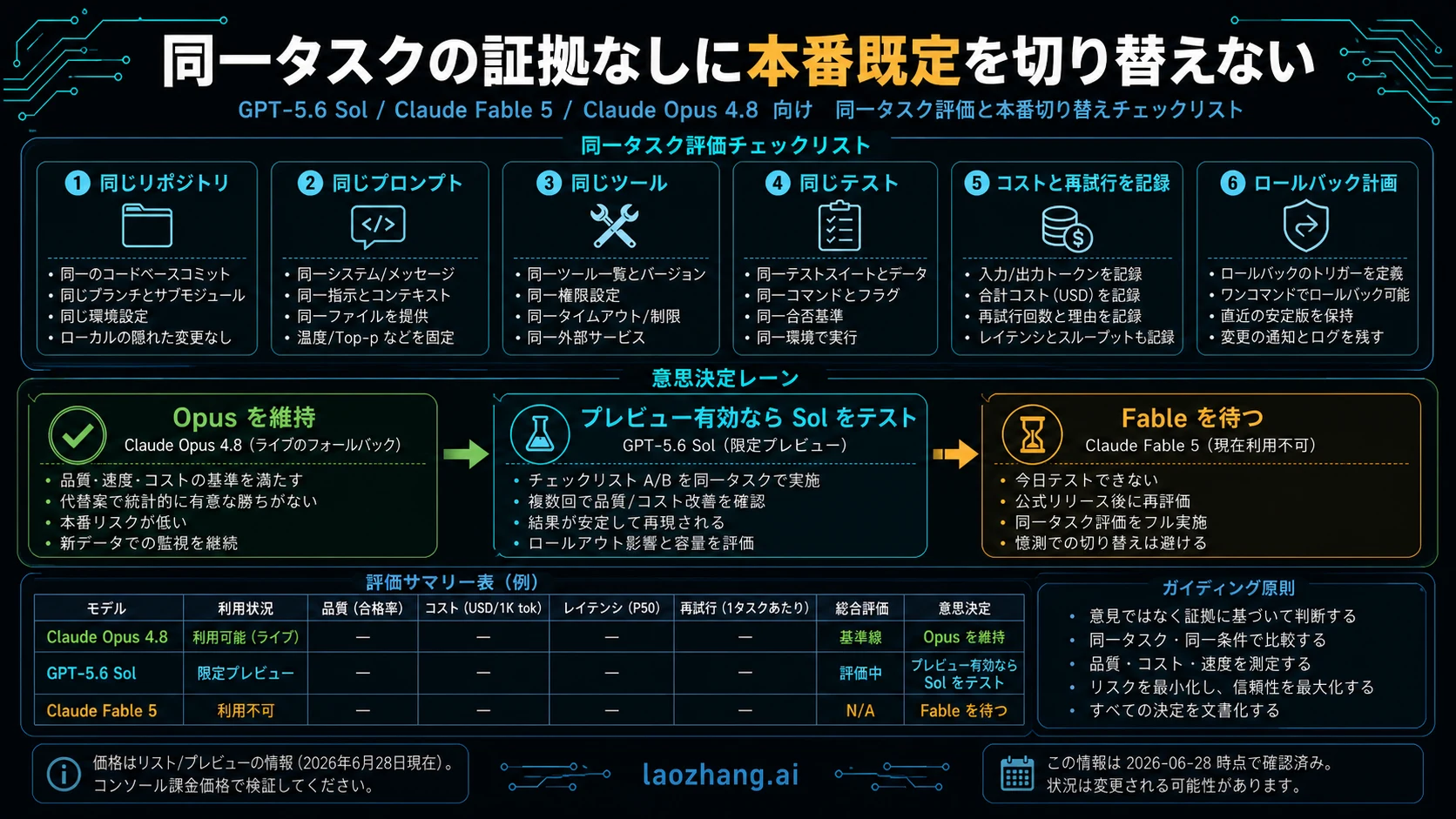
公平な比較は同じ headline ではなく同じ仕事で行います。すでに review time を消費している 10-20 個の task を選びます。failing test fix、hidden constraints のある refactor、long-context bug hunt、code verification を伴う docs update、tool recovery task などです。好みの model が勝ちやすい demo prompt は使いません。
Opus 4.8 は、実際に deploy できる endpoint で走らせます。Sol は、実際に approved された OpenAI surface だけで走らせます。Fable は access が戻るまで future-test column に置きます。各 run で first-pass correctness、tool recovery、format stability、output length、total tokens、retry count、latency、review minutes を記録します。
default-switch threshold は保守的にします。同じ task set で total work を減らし、rollback route がある場合だけ production default にします。Sol が preview workspace だけで勝つなら specialist route に留めます。Opus が reliability と live support で勝つなら baseline を維持します。Fable が戻ったら、古い比較ではなく同じ harness で再評価します。
すでに近いモデルを使っている場合
GPT-5.5 や Opus 4.7 の比較を読んでいるなら、持ち越すべきものは route-first habit であって、古い facts ではありません。GPT-5.5 vs Claude Opus 4.7 は評価構造として有用ですが、access state、model names、price rows は変わっています。price、context、availability は official page で再確認します。
Fable を待つべきかが主題なら、Claude Fable 5 vs GLM 5.2 が以前の Fable framing を補います。ただし current production rule は明確です。Anthropic が unavailable としている間、Fable 5 は next production step ではありません。
耐久性のある rule は短いです。今日 system を支える live model を維持する。access があり risk が許容できる場所だけ preview model を追加する。unavailable model は watchlist に置く。same-task evidence なしに default に昇格させない。
よくある質問
GPT-5.6 Sol は公開利用できますか?
いいえ。OpenAI は GPT-5.6 Sol を approved organizations 向け limited preview と説明しています。API org と Codex workspace access は別に確認します。該当 access がなければ、Sol は今日の production option ではありません。
Claude Fable 5 は今使えますか?
Anthropic の current Fable materials は unavailable と示しています。6月12日の statement でも Fable 5 と Mythos 5 は disabled for all customers とされています。今は wait-and-recheck model です。
Claude Opus 4.8 は最も安全な default ですか?
この三択では、Opus 4.8 が最も clear な live Anthropic baseline です。ただし、すでに動いている default を置き換えるには same-task evaluation が必要です。
どれが安いですか?
200k input と 40k output の simple list math では、Opus 4.8 は約 `2.00\`、Sol preview は約 \`2.20`、Fable list row は約 `$4.00` ですが unavailable です。実コストは cache、batch、retry、latency、review minutes で変わります。
Benchmarks で勝者を決められますか?
いいえ。benchmark は first pilot を決めます。production default は access status、task fit、cost logs、failure rate、rollback safety で決めます。