
Codex と Claude Code を切り替えても context を失いたくないなら、会話全文を次の agent に渡すのは避けます。渡すべきなのは、repo のルール、今回の task、触った file、実行した command、失敗した証拠、決めたこと、次にやるべきことです。コードの事実は Git に置き、長く残すルールは AGENTS.md と CLAUDE.md に置き、一時的な作業状態は短い handoff packet にします。
Claude Code と Codex は、どちらが「コードを書けるか」で選ぶ段階を過ぎています。いま間違えやすいのは、弱いモデルを選ぶことではなく、作業の形に合わない契約を買い、limit 表示を読み違え、長い transcript を確かな記憶だと思い込むことです。五時間窓は五時間の実作業を保証しません。見るべきなのは、context、model、tool、retry、review を含めて、どれだけ review 可能な成果に変わるかです。
2026年5月23日時点の実用的な結論はこうです。月20ドルで迷うなら、幅広い coding-agent 体験を試せる Codex Plus から始めるのが安全です。ただし、日常の中心がローカルの長い探索、権限ルール、細かい会話であれば Claude Pro と Claude Code のほうが合います。月100ドルや200ドルでは、Claude Max と Codex Pro をブランドで比べず、Claude Code の長い対話が多いのか、Codex の委任、cloud task、review が多いのかで分け、最後は accepted diff、limit hit、手戻り時間で判断してください。
すぐ使える選び分け
| 状況 | 最初の候補 | 理由 |
|---|---|---|
| 途中で二つのツールを切り替える | 先に handoff packet | 次の agent が長い transcript から判断を推測する状態を避ける。 |
| 月20ドルで広く試したい | Codex | Plus で web、CLI、IDE、iOS、cloud integration、review を試せる。 |
| 月20ドルでローカル作業が中心 | Claude Code | 長い対話、ローカル状態、権限ルールに向く。 |
| 月100ドルで Claude セッションが重い | Claude Max 5x | Claude の作業容量を増やす選択。 |
| 月100ドルで Codex task と review が多い | Codex Pro 5x | Codex の五時間窓と作業カテゴリを増やす選択。 |
| 月200ドルで並列作業が多い | 役割で併用 | Max 20x は大きい Claude セッション、Codex Pro 20x は委任向き。 |
| チームで両方使う | routing rule | ツール統一より作業の分流が重要。 |
Context 引き継ぎ:切り替えても作業を失わない
信頼できる context は、片方のチャット履歴ではなく、両方のツールが読み直せる場所に置きます。Codex は AGENTS.md の project guidance を読みます。Claude Code は AGENTS.md ではなく CLAUDE.md を主に読みます。すでに AGENTS.md がある repo では、CLAUDE.md から @AGENTS.md を import し、Claude 専用の注意だけを下に足すのが安全です。
| Context の層 | 置き場所 | 引き継ぎルール |
|---|---|---|
| repo の長期ルール | AGENTS.md と、それを import する CLAUDE.md | 同じルールを二重管理しない。 |
| 今回の task 状態 | issue、PR note、HANDOFF.md | 目的、進捗、失敗、次の行動を書く。transcript 全文は不要。 |
| コードの事実 | Git diff、branch、test output、log | 次の tool は file と検証結果から始める。 |
| 権限と安全 | task packet の許可/禁止範囲 | API key、token、private log は貼らない。 |
| 長期記憶 | 繰り返すルールだけ | 一回限りの作業ノイズを policy にしない。 |
最小の packet はこれで十分です。
md## Agent handoff packet Goal: Current state: Files touched: Commands/tests run: Known failures: Decisions already made: Do not redo: Next best action: Safety/permissions:
良い handoff は「上の続き」ではありません。どの test が落ちているか、どの file を触ったか、何を変更してはいけないか、次にどの command を走らせるかを書きます。これなら Claude Code の探索を Codex が implementation task として受け取れますし、Codex の diff を Claude Code がローカル文脈で説明できます。
チームで使うなら、handoff packet に三つの項目を追加します。まず Git status を明記し、committed、dirty、untracked、agent が作った一時 file を分けます。次に「やり直さないこと」を書きます。たとえば auth flow を再設計しない、重い migration を再実行しない、reviewer が受け入れた file を触らない、という禁止です。最後に、二つ目の tool の責任を狭くします。Codex は reviewable diff と検証 command を返す。Claude Code はローカル失敗、permission boundary、曖昧な設計判断を説明する。ここまで書くと、切り替えは会話の持ち越しではなく、レビュー可能な工程になります。
上限、token、実作業時間の見方
開発者向けの比較では「Claude Code 100 hours vs Codex 20 hours」や「5-hour limit」のような言い方が出てきます。これはユーザーの痛みを表しますが、そのまま計算式にはできません。実作業時間は、再送される context、選ぶ model、local か cloud か、最後に人間が review する時間で変わります。
Codex は容量を帳簿にしやすいです。OpenAI の現行 Codex pricing は、local messages と cloud tasks が五時間窓を共有し、追加の weekly limits もあり得ると説明します。同じ message でも、model、repo の大きさ、複雑さ、実行面によって重さが変わります。残りパーセントだけでなく、完了 task、accepted diff、失敗 branch、review 時間を記録してください。
Claude Code は一つの session を操縦しやすい一方で、session が伸びるほど消費も伸びます。Anthropic の説明では、各 turn がこれまでの会話、project context、新しい prompt を送ります。読んだ file、作った diff、議論した判断が後続 turn に乗ります。'/clear'、'/compact'、model choice、不要な tool の停止は、実作業時間を伸ばすための操作です。
比べるべき指標は「1ドルあたり何時間」ではなく、「limit に当たる前に何個の受け入れ可能な作業単位を得たか」です。Claude Code が難しい原因調査を二つ片付け、Codex が六つの branch を返すなら、どちらも価値があります。自分の workflow で復旧しやすい limit を選んでください。
実測するときは、task の目的、agent が読んだ・変更した範囲、人間の review 時間、main branch に入ったかどうかを同じ表に残します。Claude Code の価値は、迷いを減らして正しい方向へ早く寄せることに出やすいです。Codex の価値は、task を queue に積み、失敗 branch を捨てやすいことに出やすいです。この二つは単純な時間割り算だけでは比べられません。
もう一つ見るべきなのは中断コストです。Claude Code で limit に当たると、ローカル調査の流れをもう一度作り直す必要があります。Codex の失敗は branch を捨てれば済む場合もありますが、setup や review の待ち時間は残ります。limit hit の回数だけでなく、作業へ戻るまでの時間も記録してください。
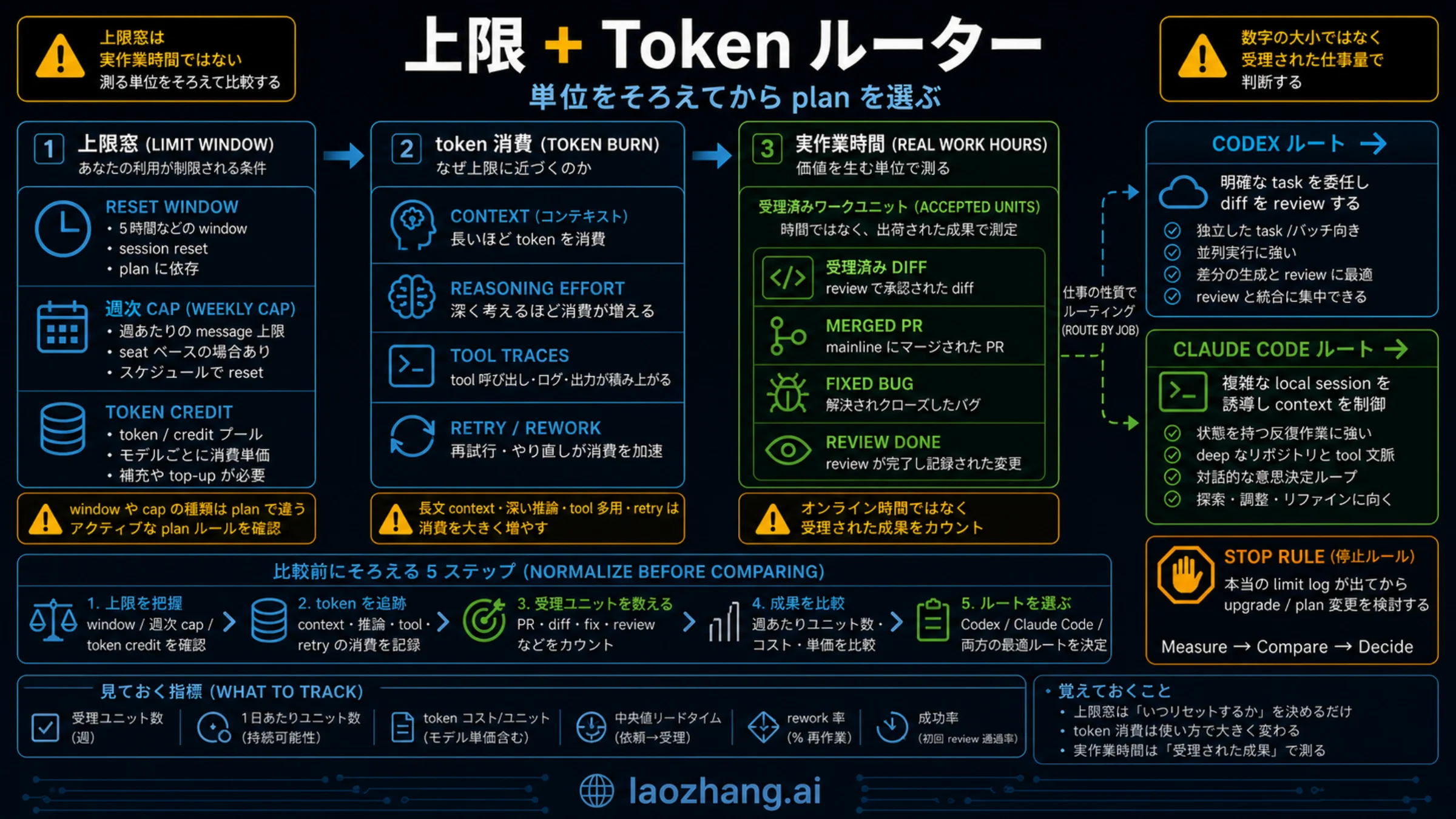
利用枠:一つの数字にまとめない
Codex の現行ドキュメントは、利用枠をかなり細かく分けて見せています。OpenAI の Codex pricing では Plus が月20ドルで、週に数回の focused coding sessions 向けと説明されています。含まれるのは web、CLI、IDE extension、iOS、automatic code review や Slack などの cloud integration、そして GPT-5.5、GPT-5.4、GPT-5.3-Codex、GPT-5.4-mini です。
大事なのは、Codex の上限が local messages、cloud tasks、code reviews、model choice に分かれることです。フォーラムで「Codex は上限が多い」「すぐ切れる」と言われても、どのモデル、どの作業カテゴリ、どの時間窓なのかを見ないと判断できません。
Claude Code は別の読み方になります。Claude Code usage のドキュメントは、まずサインイン方法で metering が変わると言います。Enterprise seat は組織プラン内の使用量、API key は token 課金です。また、長い会話は context window を消費し、品質にも影響します。'/clear' は別タスクに移るとき、'/compact' は長い作業を続けるときに使うべき操作です。
Anthropic は 2026年5月6日に Claude Code の五時間 rate limit を Pro、Max、Team、seat-based Enterprise で倍増し、Pro と Max の peak-hours reduction も取り除きました。古い limit 体験をそのまま現在に当てはめるのは危険です。ただし、増えた上限は無制限ではありません。
コスト:表示価格だけでは足りない
価格表だけを見ると似ています。Claude Pro は月20ドル、Max 5x は月100ドル、Max 20x は月200ドル。Codex Plus は月20ドル、Codex Pro は月100ドルからで、Plus より大きい制限が用意されています。
しかし実コストは下の層で変わります。Claude Code は subscription でも使えますが、API key で動かすと token 消費に応じた課金になります。Anthropic の cost docs は、Pro と Max の subscriber は使用量が subscription に含まれ、'/usage' の dollar figure は請求額ではないと説明しています。企業利用では、active developer day あたり約13ドル、月150から250ドルという目安も出ていますが、model、codebase size、複数 instance、automation、context が大きく左右します。
Codex は個人にとって入り口が単純です。Plus と Pro に Codex が含まれます。ただし、GPT-5.5 local messages、cloud tasks、review は有限の作業枠を使います。API 請求ではなくても、scarce capacity を使っている点は変わりません。
最初は一か月だけ20ドルで試し、実測メモを残してください。どの作業で上限に近づいたか、どの diff が review しやすかったか、どのツールが無駄な修正を少なくしたか。この記録なしに100ドルへ上げると、改善ではなく期待を買うことになります。
安定性:印象ではなく status を読む
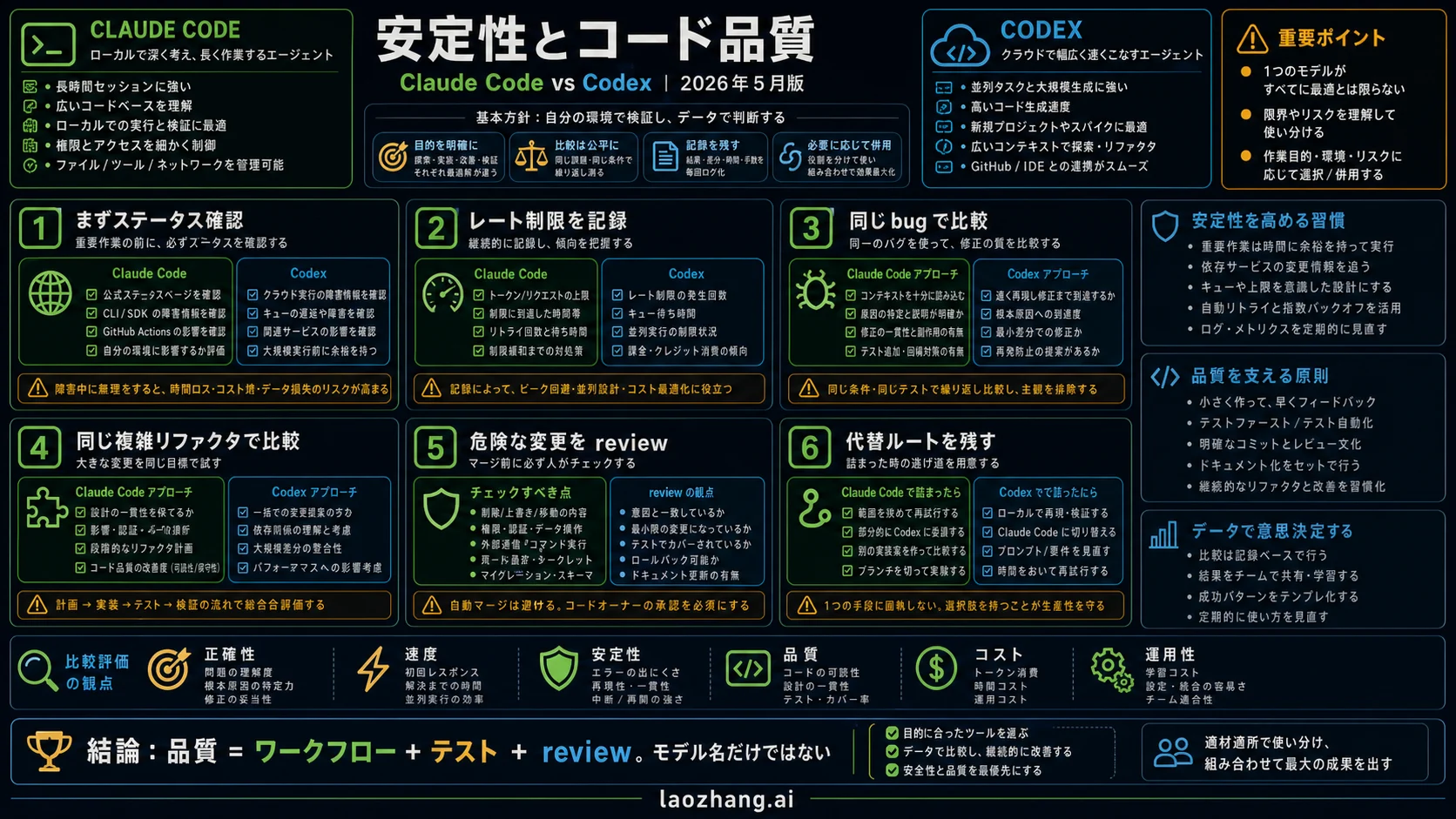
2026年5月23日、OpenAI の status は Codex rate limits に関する ongoing incident を表示していました。一方で、Codex の February-May 2026 の uptime は 99.98% と出ています。これは矛盾ではありません。全体の uptime が高くても、今日必要な rate-limit surface が痛むことはあります。
同じ日に Claude の status は 5月23日の incident を表示していませんでした。ただし 5月12日から22日には Claude.ai、Opus 4.7、Haiku 4.5、Claude Code login や web surface で複数の resolved incidents がありました。Claude が長い reasoning に強いことと、最近の障害がないことは同じ意味ではありません。
重要な作業では fallback を先に決めます。対話型の作業は中断が痛いので、小さい代替 task や別モデルを用意します。非同期 task は時間ロスが痛いので、捨てやすい branch と review checkpoint を使います。
コード品質:モデル名ではなく作業ループを見る
OpenAI は GPT-5.5 について、agentic coding が強く、Codex tasks で少ない token で結果を出し、GPT-5.4 より coding evals が改善したと説明しています。Codex の強みは、明確な task を委任し、tool で確認し、reviewable diff にする場面で出やすいです。
Anthropic は Claude Opus 4.7 について、advanced software engineering、long-running tasks、instruction following、self-verification が改善したと説明しています。Claude Code では Opus 4.7 の default effort が xhigh になっており、難しい作業で深く考える設計が前に出ています。
実務では四つのテストをしてください。既存テスト付きの bug、未コミット状態を含む refactor、明確な async implementation、危険な変更を拒否する review。勝つのは、もっとも自信満々の答えではなく、reviewable diff、少ない手戻り、よい検証、明確な不確実性を出すツールです。
権限と安全境界
Claude Code は permission vocabulary が細かいです。allow、ask、deny rules を設定でき、version control に入れて組織へ配布できます。mode には 'default'、'acceptEdits'、'plan'、'auto'、'dontAsk'、'bypassPermissions' があります。'bypassPermissions' は隔離環境向けです。
Codex は説明しやすい境界を持ちます。Codex cloud は OpenAI-managed container で動き、setup phase では依存関係を入れられ、agent phase はデフォルトで offline です。CLI と IDE は OS-level sandbox を使い、デフォルトでは network なし、書き込みは active workspace に限定されます。Auto preset は作業ディレクトリ内での read、edit、command を自動化し、外部書き込みや network は approval を求めます。
細かいローカル権限を組織で設計したいなら Claude Code。少ない preset と local/cloud の説明しやすさを優先するなら Codex です。
使い分けワークフロー
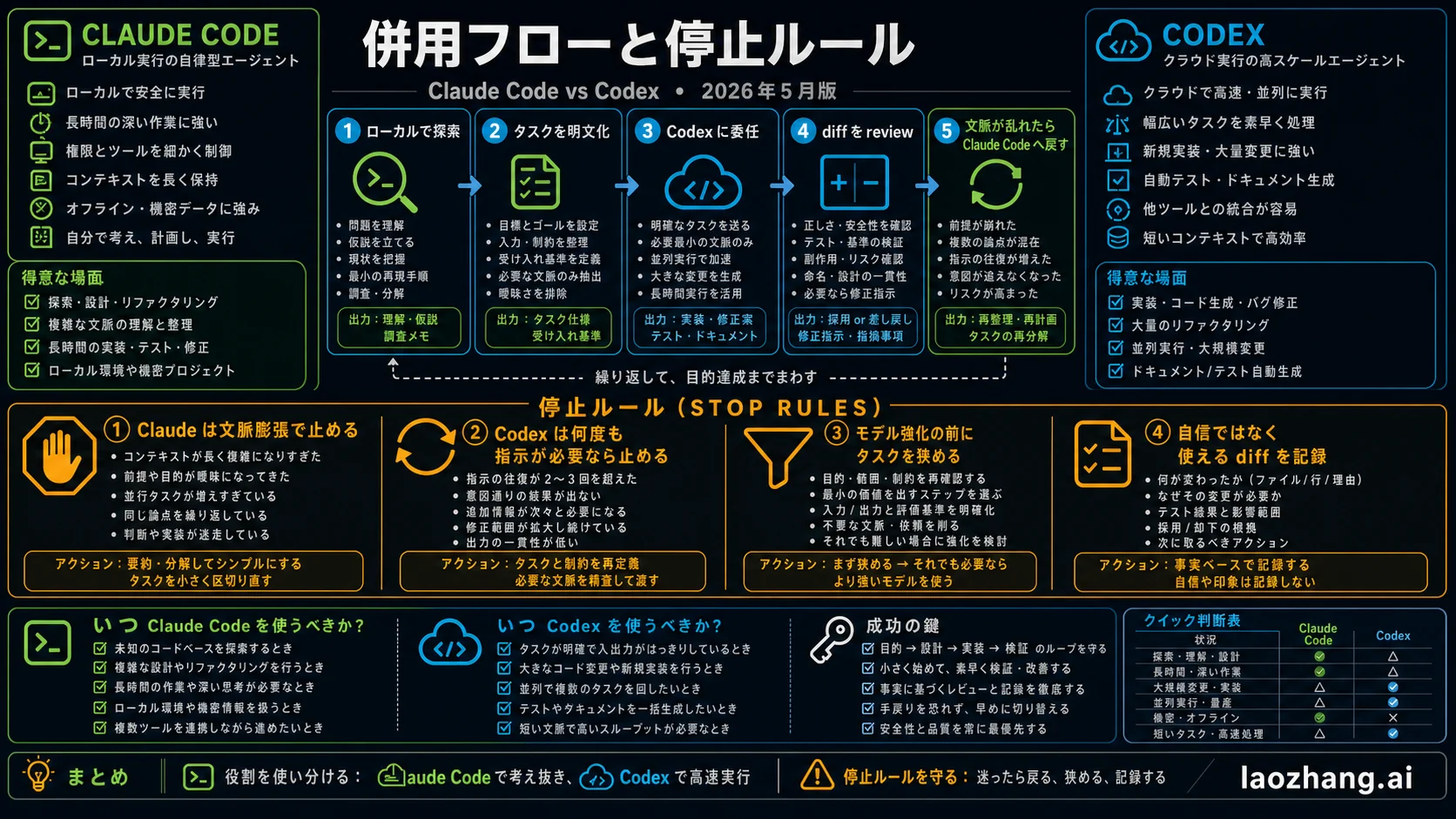
不確実な最初の一時間は Claude Code が向きます。repo を読み、失敗を見て、仮説を検証し、どこを変えるべきか決める。作業が明確になったら Codex に渡し、branch、review、test 付きの task として走らせます。
Claude Code を止めるべきなのは、context が膨らみすぎたとき、同じ案を繰り返すとき、task が十分に整理されたときです。Codex を止めるべきなのは、repo 固有の文脈を何度も落とすとき、途中 steering が必要すぎるとき、diff が review しにくいときです。
購入前の1週間テスト
最初の判断は、1回のデモではなく1週間の記録で行います。初日は低リスクのタスクだけにします。Codex には範囲が明確な修正を渡し、Claude Code にはよく知っているローカルリポジトリを読ませます。この段階で見るべきなのは「賢そうに話すか」ではありません。どの程度早く使える diff になるか、どの時点で利用枠に当たるか、文脈が長くなったときに出力が雑になるか、レビューしにくい巨大 diff を作らないかです。
2日目から4日目は、タスクを3つに分けて試します。ひとつ目は委任できる作業です。テスト追加、明確な bug 修正、設定移行、レビュー指摘の反映などは Codex に向きます。結果が branch、ログ、diff として戻ってくるため、失敗しても捨てやすいからです。ふたつ目は方向を見ながら進める作業です。歴史的な負債を読む、未コミット状態を含む修正を考える、失敗の根本原因を探す、といった作業は Claude Code のほうが自然です。三つ目は、まだ人間が問題を定義できていない作業です。これはどちらにも直接投げず、目的、失敗条件、実行コマンド、変更禁止範囲を先に書きます。
5日目以降はコストを見ます。月額だけでなく、使える成果ひとつ当たりのコストで比べます。20ドルのプランでも、毎週の機械的レビューを減らせるなら十分に価値があります。逆に100ドルのプランでも、返工が増えるだけなら高い買い物です。記録する項目は、使えた diff の数、全面的に書き直した数、limit や待ち時間に当たった回数、agent の出力が原因で余分に調査した回数です。この記録が、SNS の勝敗論よりもあなたのチームに近い答えになります。
アップグレード前の質問は単純です。足りないのは Claude Code の長いローカル会話なのか、それとも Codex の委任・レビュー枠なのか。前者なら Claude Max を検討し、後者なら Codex Pro を検討します。どちらを選んでも固定ではありません。作業の形が変われば、予算配分も変えるべきです。
チームでの導入メモ
チームでは、まずツール名ではなくタスク種別を決めます。local-investigation は Claude Code に寄せます。担当者がローカルでテスト、権限範囲、停止条件を見ながら進めるべき作業だからです。delegated-implementation は Codex に寄せます。目標ファイル、検証コマンド、変更禁止ディレクトリ、期待する diff の大きさを書ける作業だからです。review-only は Codex review または Claude Code の補助説明に使えますが、採用判断は人間が持ちます。blocked-human-decision は agent に渡しません。まだ問題の所有者が決まっていないためです。
安定性も抽象語で終わらせません。「不安定だった」ではなく、ログイン失敗、rate limit、クラウドタスク失敗、ローカル権限ブロック、出力品質低下、レビュー遅延、モデル切替後の変化として記録します。日付、プラン、モデル、作業種別、影響を残すと、数週間後にはどちらを標準化すべきかではなく、どの作業をどちらに流すべきかが見えてきます。
すでに両方を契約している場合も、同じタスクを二重に走らせて「見た目が良い方」を選ぶ使い方は避けます。主経路と検証経路を分けます。たとえば安全に関わる変更は Claude Code でローカル調査を行い、Codex に独立 review をさせる。依存関係の機械的更新は Codex で branch を作り、失敗した test の説明を Claude Code に求める。比較するのは全体の好みではなく、ひとつの検証質問だけです。
このルールは issue テンプレートにも入れられます。主経路、検証経路、検証する質問、停止する時間を先に書けば、二つの agent が同じ実装を競うのではなく、別々の責任を持つようになります。
検証経路が見つけた問題が実装ではなくタスク定義の曖昧さなら、次はモデルを強くするのではなく、人間が条件を分解し直します。
この判断を残すことで、次の選定も同じ基準で見直せます。
よくある質問
Claude Code は AGENTS.md を直接読めますか?
主入口としては読みません。Claude Code は CLAUDE.md を読みます。Codex 用に AGENTS.md がある repo では、CLAUDE.md で @AGENTS.md を import して、共有ルールを一か所に寄せます。
Codex の transcript 全文を Claude Code に貼るべきですか?
貼るべきではありません。目的、file、command、failure、決定事項、繰り返してはいけないこと、次の action を handoff packet にします。残りの context は repo、diff、test、task packet に置きます。
月20ドルならどちらから始めるべきですか?
広く試すなら Codex Plus です。ローカルで長く操縦する仕事が中心なら Claude Pro と Claude Code が合います。
Claude Code はまだ limit に当たりますか?
当たります。5月の増枠は大きいですが、context、model、effort は引き続き消費を左右します。
コード品質はどちらが上ですか?
委任して review する作業は Codex、ローカルで深く操縦する作業は Claude Code が有利です。品質は model だけでなく、テスト、review、context hygiene、停止判断で決まります。
安定しているのはどちらですか?
重要作業前に status を見てください。OpenAI は 5月23日に Codex rate-limit incident を出していました。Claude は同日 incident なしでしたが、直近に複数の resolved incidents がありました。
チームは一つに統一すべきですか?
多くの場合は統一しないほうがよいです。探索とローカル制御は Claude Code、明確な委任と review は Codex、という routing rule のほうが実用的です。