Claude API と OpenAI API のどちらが安いかは、価格表の一行だけでは決まりません。短い入力、短い出力、大量処理で GPT-5.4 mini が品質ラインを満たすなら、OpenAI が安い起点になりやすいです。一方で、長いコンテキスト、コード Agent、複雑な reasoning、同じ文脈のキャッシュ再利用が大きい仕事では、Claude の総コストが低くなることもあります。
2026年5月2日に確認した公式情報では、OpenAI API Pricing は GPT-5.5 を入力 $5、cached input $0.50、出力 $30 / 1M tokens と表示しています。GPT-5.4 は $2.50 / $0.25 / $15、GPT-5.4 mini は $0.75 / $0.075 / $4.50 です。OpenAI の GPT-5.5 発表は 2026年4月24日に更新され、GPT-5.5 と GPT-5.5 Pro は API で利用可能とされていますが、実運用では自分のアカウントで利用できるかを確認してください。Anthropic Pricing は Claude Opus 4.7 を $5 input / $25 output、Sonnet 4.6 を $3 / $15、Haiku 4.5 を $1 / $5 と示し、cache、batch、data residency、long context、tools も別に扱っています。
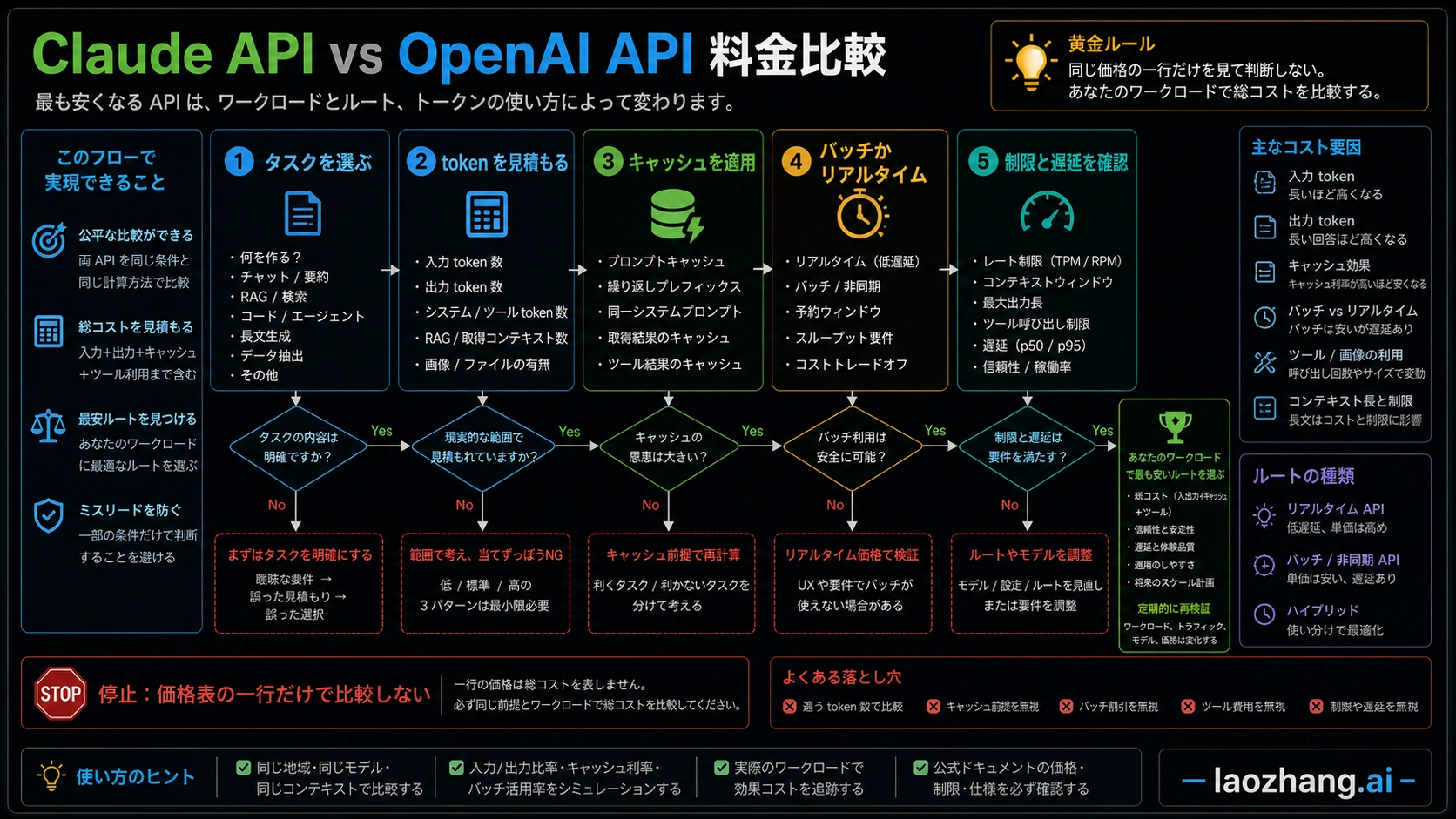
早見表:先にワークロードを決める
| 仕事 | 最初に試すルート | 理由 |
|---|---|---|
| 分類、抽出、短い要約 | OpenAI GPT-5.4 mini | Claude Haiku 4.5 より基本行が低い。 |
| 複雑な coding / professional reasoning | GPT-5.5 と Claude Opus 4.7 を同じタスクで比較 | input は近く、output は Opus が低いが、retry と品質で変わる。 |
| 長い文書や大きなコードベース | Claude Opus 4.7 / Sonnet 4.6 | Anthropic は 1M context を standard pricing として説明している。 |
| 大量の offline summary / evaluation | 両社の batch | どちらも batch discount がある。 |
| 固定 system prompt や RAG を何度も使う | cache hit rate を比較 | cached input が総コストを変える。 |
価格行は出発点であって結論ではない
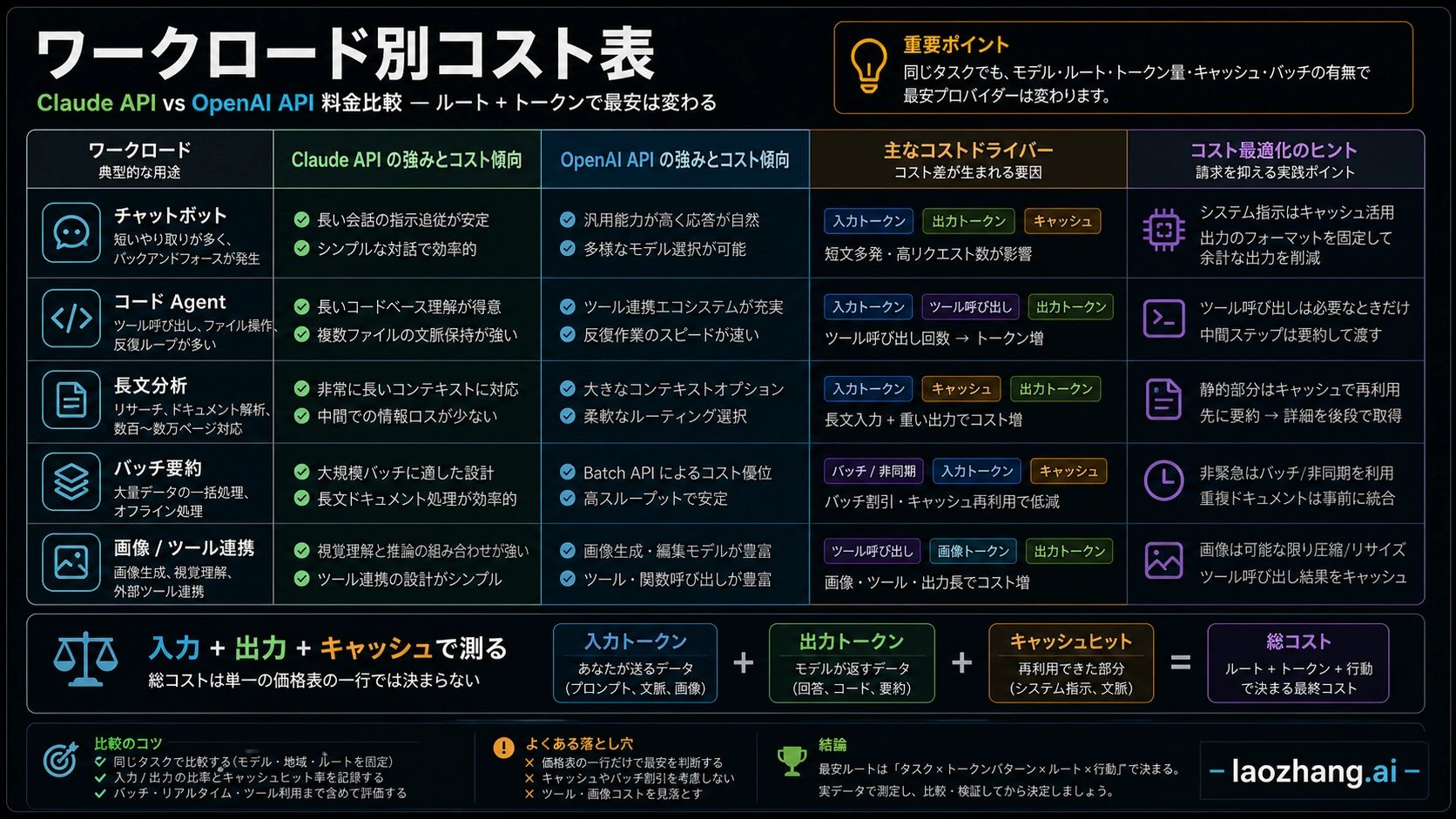
単純な表では、GPT-5.4 mini は Haiku 4.5 より安く、GPT-5.4 は Sonnet 4.6 より input が低く output は同じです。GPT-5.5 と Opus 4.7 は input が同じで、Opus 4.7 の output が低い形です。ただし GPT-5.5 はアカウントの API 利用可否を確認してから production math に入れるべきです。
重要なのは token 単価ではなく、成功したタスク一件あたりの費用です。安いモデルでも retry が増えたり、出力が長くなったり、tool calls が増えたりすれば総額は上がります。逆に Claude が長い文脈を一度で保持でき、分割や再試行を減らせるなら、表の見た目より安くなることがあります。
キャッシュとバッチで勝者は変わる
Anthropic の cache は 5分 write が base input の 1.25x、1時間 write が 2x、cache hit が 0.1x です。OpenAI も cached input 行を出しています。固定の system prompt、tool schema、policy pack、RAG 文書を何度も送る場合、初回 write と以後の read を別々に計算してください。
Batch はリアルタイムでなくてよい仕事に効きます。OpenAI は Batch API で input/output 50% savings、Anthropic も batch で 50% discount を示しています。評価、分類、移行 QA、大量要約では、provider を変える前に batch にできるかを確認する価値があります。
OpenAI が安い出発点になる場面
OpenAI は、短く、定型的で、量が多い仕事に向きます。classification、extraction、JSON 変換、短い support draft、title generation、短い summary では、GPT-5.4 mini が品質を満たすかを最初に確認します。
GPT-5.5 が API アカウントにない場合は、無理に比較表へ入れないでください。現在利用できる GPT-5.4 系列と Claude の現行行で計算し、GPT-5.5 は有効化確認待ちの候補として扱います。
Claude が費用対効果で勝つ場面
Claude は、長文研究、複数ファイルのコード理解、契約レビュー、Agent loop、大規模サポートナレッジで強い候補になります。ここでは一番安い token ではなく、切り分け、再要約、失敗、手戻りが減るかを見ます。
Anthropic は Opus 4.7 の新 tokenizer により、同じ固定テキストでも最大 35% token が増える可能性を説明しています。したがって文字数ではなく、実際の tokenizer と実プロンプトで低・標準・高出力ケースを測るべきです。
チーム用の計算表
| 項目 | 測る内容 |
|---|---|
| input tokens | system prompt、user text、RAG、tools、files、image input |
| output tokens | answer、code、JSON、summary、explanation |
| cache | write size、read size、hit rate、TTL |
| batch | 待てるか、必要な feature が対応しているか |
| tools | web search、code execution、image、server-side tools |
| retries | failed calls、truncation、manual reruns |
| route premium | data residency、regional endpoint、priority、fast mode |
デプロイ前チェック
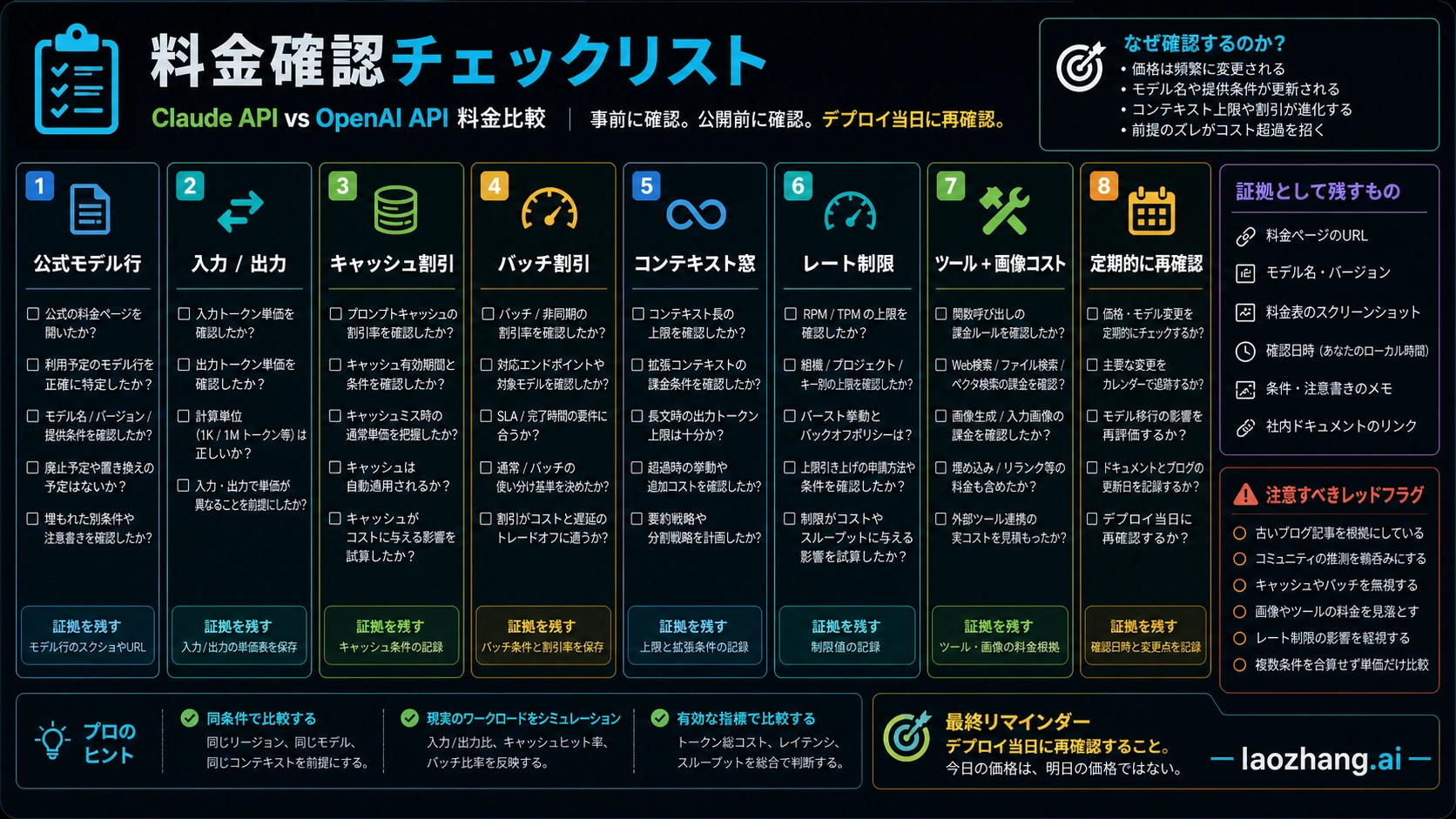
デプロイ当日に OpenAI API pricing、GPT-5.5 availability note、Anthropic pricing を再確認します。モデル行、アカウントでの利用可否、input/output、cache、batch、context、rate limits、tool costs、route premium を確認してください。
実データで追加確認すること
平均的な一回のリクエストだけで判断しないでください。短い入力と短い出力、長い入力と短い出力、長い入力と長い出力の三つを最低限用意します。それぞれで input tokens、output tokens、再利用できる文脈、batch 化の可否、cache hit rate、retry の回数を記録します。こうすると、短い定型作業では mini モデルが勝ち、長い分析や Agent では Claude が勝つような分岐が見えます。
もう一つは境界ケースです。最大サイズの文書、最も重い tool schema、最長の Agent loop、引用確認が必要な回答を使って、Claude と OpenAI を同じ条件で試します。見るべきものは token 単価だけではありません。truncation、JSON 形式崩れ、手作業の修正時間、再実行率、最初の一回で quality bar を超えた割合を一緒に記録してください。
よくある質問
Claude API と OpenAI API はどちらが安いですか?
短く大量の単純処理は OpenAI が安くなりやすいです。長い context、Agent、cache-heavy な仕事、retry 削減が重要な仕事は Claude も同じ条件で測るべきです。
GPT-5.5 と Claude Opus 4.7 を比べてよいですか?
比べてよいですが、日付と API 利用可否を明記してください。OpenAI は価格を示し、2026年4月24日の更新で GPT-5.5 は API 利用可能としています。Anthropic は Opus 4.7 を現在の API 価格行として示しています。
cache は必ず安くなりますか?
いいえ。write だけで read がない場合は安くなりません。同じ大きな文脈を何度も読む場合に効果が出ます。
batch は常に使うべきですか?
いいえ。offline jobs には有効ですが、interactive agent や低遅延 UX では discount より latency が重要です。