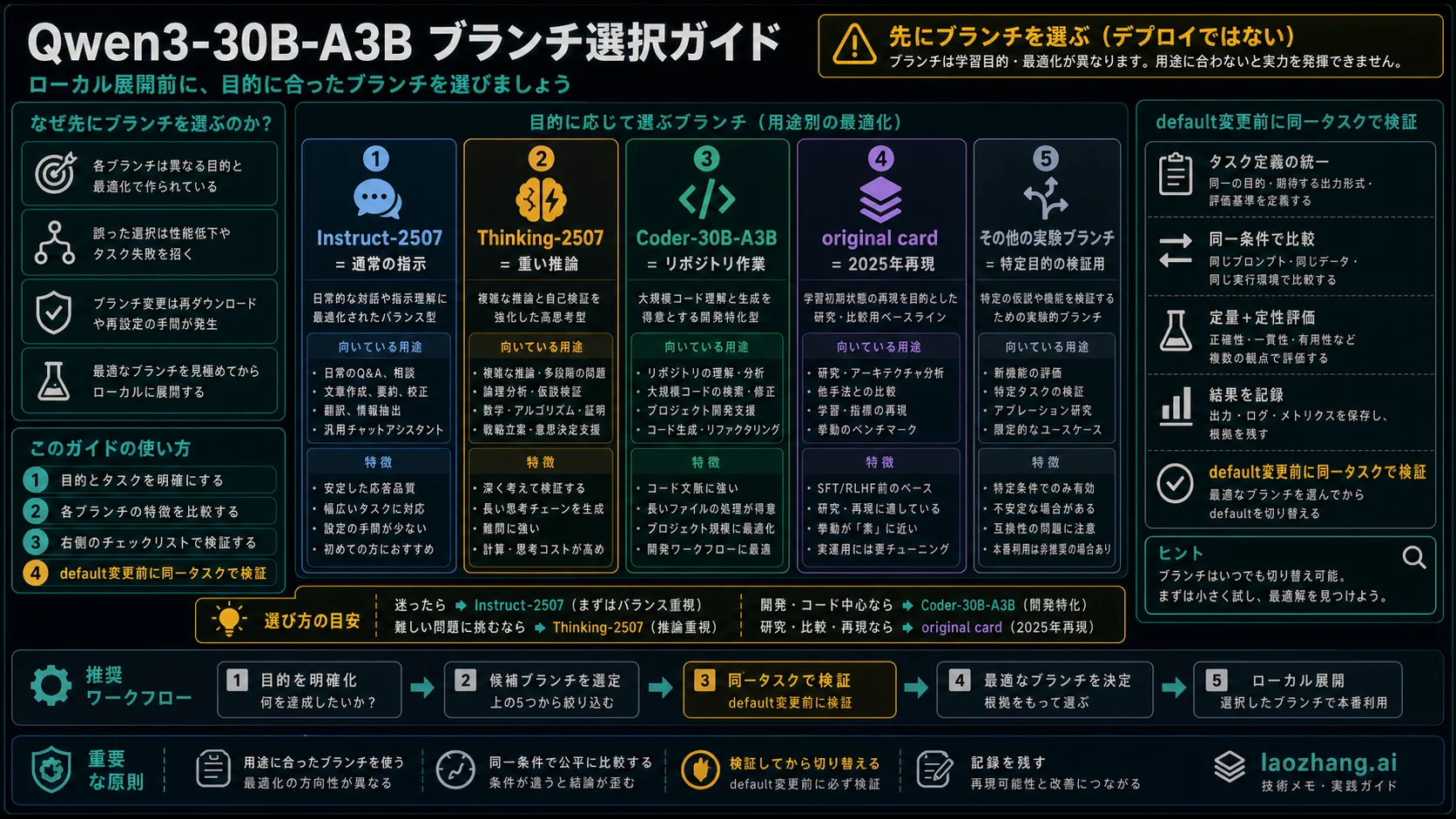
2026年5月22日時点では、Qwen3-30B-A3Bを一つのローカルdeployment choiceとして扱うのは危険です。まずブランチを選びます。普通のinstruction、summary、chat、軽いagent promptなら Qwen/Qwen3-30B-A3B-Instruct-2507。難しいreasoningなら Qwen/Qwen3-30B-A3B-Thinking-2507。repository単位のcodingなら Qwen/Qwen3-Coder-30B-A3B-Instruct。2025年4月のhybrid modelを再現するならoriginal Qwen/Qwen3-30B-A3B です。
A3B はsparse MoEで有効化されるparameter sliceを示す名前です。どのbranchか、どのruntime tagか、contextをどこまで伸ばすか、quantizationをどうするか、KV cacheがどれだけ増えるかまでは決めません。ローカルdefaultを変える前に、モデル名ではなく実際の仕事で分けて測る必要があります。
| 仕事 | 最初に試すブランチ | default変更前の確認 |
|---|---|---|
| 日常のローカル指示、要約、chat、普通のagent prompt | Qwen/Qwen3-30B-A3B-Instruct-2507 | non-thinking branchなので <think> traceを期待しない。 |
| 多段推論、計画、長いreview、複雑な分析 | Qwen/Qwen3-30B-A3B-Thinking-2507 | latency、verbosity、reviewer time、実タスクの正答率を見る。 |
| repository作業、tool loop、長いcode context | Qwen/Qwen3-Coder-30B-A3B-Instruct | Coder branchとして測り、original cardの別名にしない。 |
| 2025年4月の再現、旧eval、hybrid behavior確認 | Qwen/Qwen3-30B-A3B | original owner cardと32K native context boundaryを使う。 |
| 新しいQwen local/coding route探索 | Qwen3.6-35B-A3Bを別に見る | Qwen3.6はsuccessor boundaryで、同じmodel rowではない。 |
停止条件は先に置きます。同じprompt、同じfiles、同じtools、同じcontext budget、同じtests、同じlatency budget、同じretry policy、同じreview rubricで候補branchがcurrent defaultに負けないまで、defaultを切り替えないでください。
速い答え
Instruct-2507は、普通のローカルassistantとして最初に試すbranchです。要約、分類、下書き、文書整理、軽いagent task、短いログ説明のような作業では、長いthinking traceよりも、安定したformat、短いlatency、低いreview costが重要になります。Hugging Faceのbranch cardはnon-thinking branchとして位置づけ、262,144-token native contextを記録しています。
Thinking-2507は、hard reasoningを測るために別枠にします。複数制約のplanning、長文の統合、複雑なtroubleshooting、反例review、step-by-step reasoningが結果を改善する場面で意味があります。反対に、出力が長くなってreviewer timeだけ増えるなら、defaultには向きません。
Coder-30B-A3Bは、code taskのfirst testです。Qwen3-Coder materialsはcoding and tool useを中心にしているため、repo search、cross-file edits、test generation、refactor locality、tool-call disciplineを見るなら最初にこのbranchを置きます。branch名だけで品質は保証されないので、実際のrepository testsで確認します。
Original Qwen/Qwen3-30B-A3B はbaselineとして残します。April 2025のQwen3 coverage、古いquantized build、hybrid thinking/non-thinking behavior、昔のeval parityを再現する場面では正しいowner cardです。新しいdefault候補として使うなら、更新branchより優先する理由を明確にします。
A3Bの意味
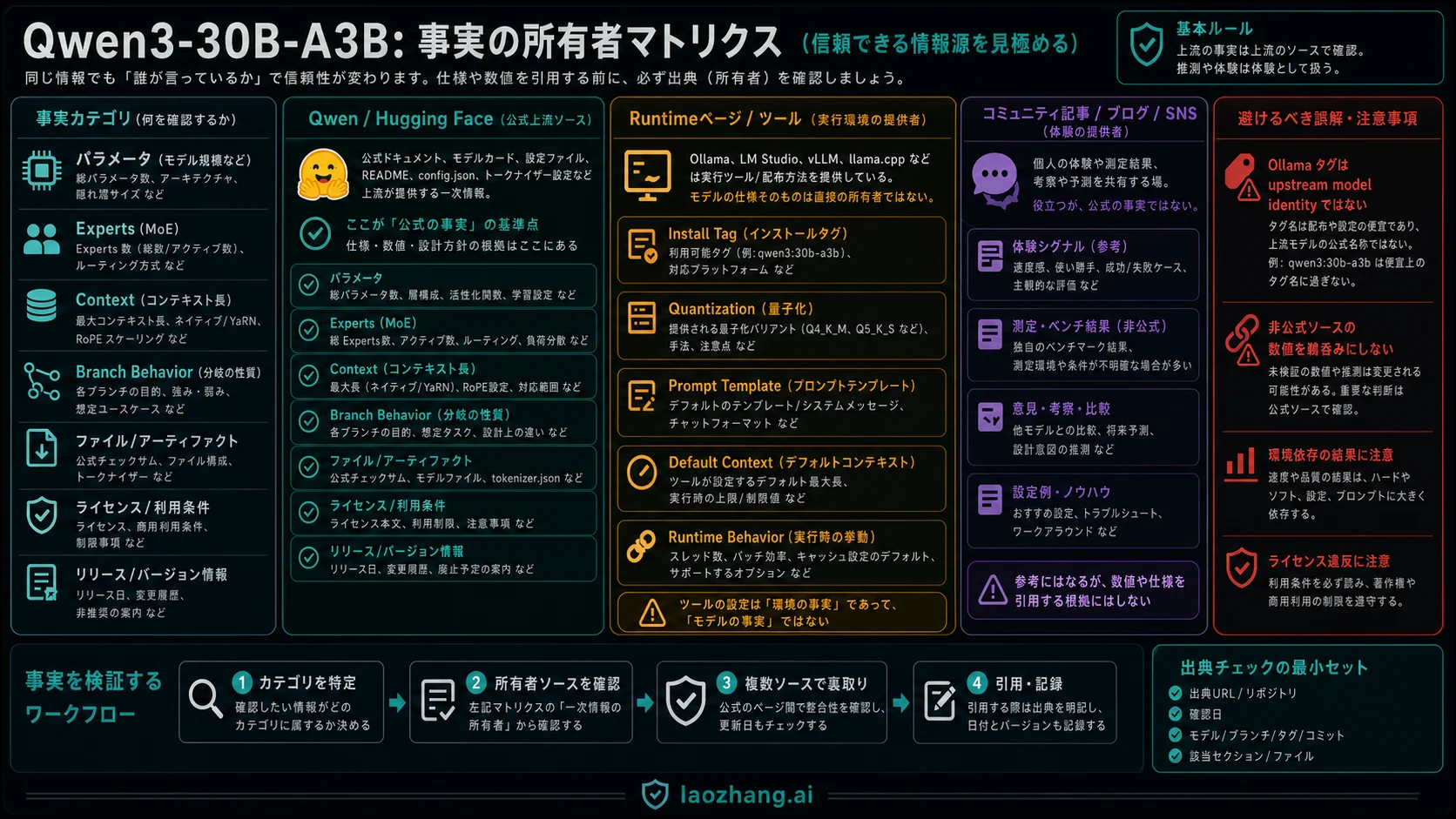
QwenのQwen3 announcementとoriginal Hugging Face cardは、Qwen3-30B-A3Bをsparse mixture-of-experts modelとして説明しています。Owner cardは30.5B total parameters、3.3B activated parameters、48 layers、128 experts、8 active expertsを記録しています。だからA3B labelは、ローカル実験で魅力的に見えます。大きいtotal modelを持ちながら、各tokenで有効化されるexpert sliceは小さいためです。
しかしA3Bは、memory budgetの答えではありません。実際のmemory pressureにはloaded weights、quantization、context length、KV cache、inference framework、batch size、concurrencyが入ります。短い4-bit chatと、長いcontextを使うcoding agentと、同時並列のserviceでは、同じmodel nameでも全く違うdeployになります。
Context boundaryもbranchごとに違います。Original cardは32,768 native contextと131,072 with YaRNを記録しています。Instruct-2507とThinking-2507は262,144 native contextです。Coder cardは262,144 native contextと1M with YaRN boundaryを持ちます。これらを一つの行にまとめると、speed、quality、memoryの比較が壊れます。
ブランチ選択の考え方
最初に見るべきなのは「失敗したときの費用」です。普通のinstruction taskは、多少の修正で回復できます。Reasoning taskは、間違った結論が判断を壊します。Code taskは、repositoryにhidden defectを残したり、不要なdiffを作ったり、testsを壊したりします。同じbranchが全ての場面で最初になるわけではありません。
Instruct-2507は、default assistant候補として測ります。短いanswer、format stability、instruction following、boundary handling、unnecessary verbosityを見ます。Visible reasoningを期待するeval promptを使うなら、そもそもbranch selectionが間違っています。
Thinking-2507は、重い推論のbranchとして測ります。良い評価taskは、長い中間推論によって最終errorが減るものです。多段planning、長いdocument synthesis、complex debug、adversarial reviewが該当します。品質が上がってもreviewer timeが倍になるなら、routine defaultには向きません。
Coder-30B-A3Bは、repository workに使います。見るべき点は、正しいfileを見つけるか、既存styleを守るか、edit scopeが小さいか、必要なtest commandを選べるか、tool failureから戻れるかです。code snippetが書けることと、repo-scale loopを任せられることは別です。
Qwen3.6は、後続比較として扱います。Qwen3.6-35B-A3BをKimiやGLMと比べたいなら、Qwen3.6・Kimi K2.6・GLM-5.1のroute guideに進みます。Qwen3-30B-A3Bの精密なbranch decisionを、cross-model rankingに拡張しないほうが安全です。
Runtime routeは事実の所有者ではない
Ollama、LM Studio、llama.cpp、vLLM、SGLangは、model choiceを実行可能なlocal setupに変えるために重要です。ただしruntime tagはupstream model identityではありません。Quantization、prompt template、default context、branch mapping、server parameterを含んでいる場合があります。
Ollamaの qwen3:30b-a3b は、速く試すための入口として便利です。Local speed、memory pressure、basic prompt behaviorを観察できます。しかしparameter count、expert count、context promise、branch behaviorのsource of recordではありません。そこはQwenとHugging Face owner pagesに戻ります。
Community quantized packageも同じです。あるGGUFやAWQ buildがあなたのGPUに最適なことはあります。ただしquantization、template、context、serverが変わった時点で、測っているのはmodel cardだけではなくdeployment stackです。Model identityとstack behaviorを分けると、失敗時の原因を追いやすくなります。
Hardwareとcontextの注意点
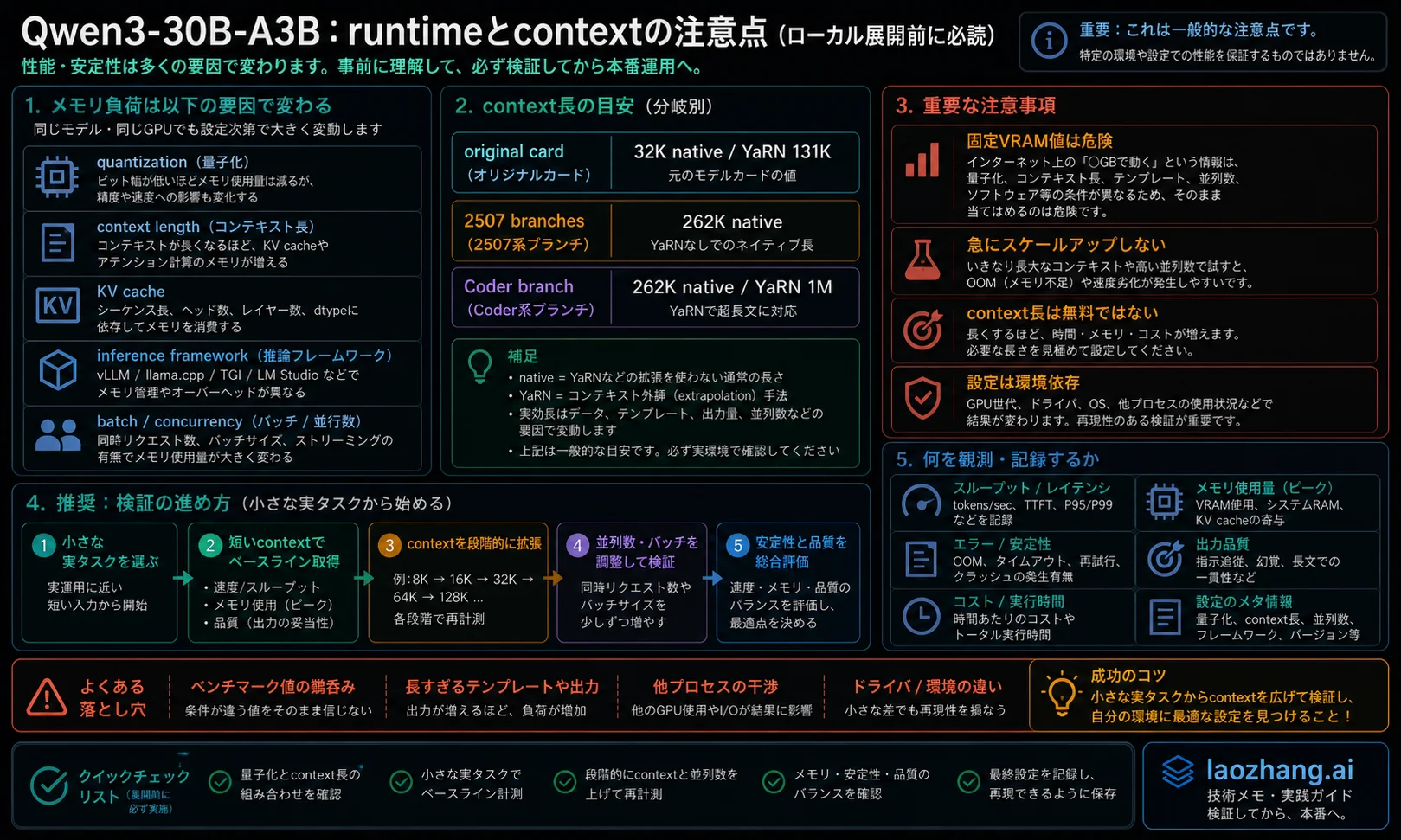
正直なhardware answerは必ず条件付きです。Quantizationを下げるとmemoryは減りますが、qualityやcompatibilityが変わることがあります。Contextを伸ばすとKV cacheが増えます。Batchとconcurrencyが上がるとpeak memoryが厳しくなります。Frameworkによってoffload、attention、pagingの挙動も変わります。
短いchatでは、load time、first token、token speed、answer stabilityを先に見ます。Code agentでは、repository files、tool outputs、retry、long contextを入れます。Thinking branchでは、output length、review time、error reductionを記録します。一つの小さなspeed testだけで全部のdefaultを決めるべきではありません。
安全なpilotは小さく始めます。実際に使う短いtaskでbranchとruntimeを確認し、contextを段階的に伸ばします。Memory pressure、crash、paging、quality drop、recovery behaviorを記録します。短いtaskが安定する前に最大contextへ飛ぶのは、判断を難しくします。
同一タスクpilot
モデル比較は、同じtaskで走らせて初めて判断材料になります。五から十個の実タスクを選びます。Log explanation、summary、multi-step reasoning、small bug fix、cross-file refactor、test writing、long-context reading、ambiguous requirementを入れると、失敗の種類が見えます。
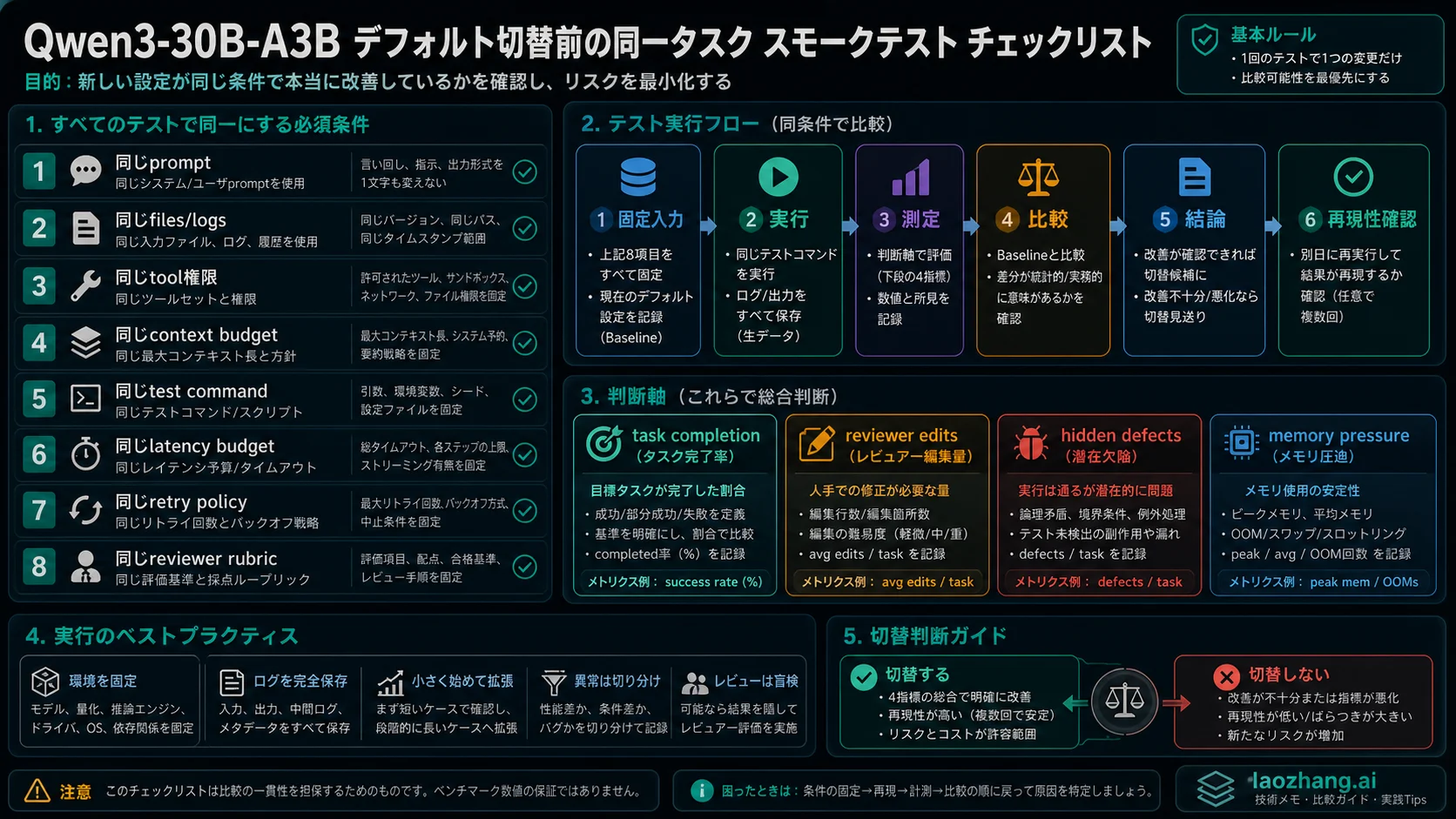
| テスト項目 | 同じにするもの | 記録するもの |
|---|---|---|
| Prompt | user task、system rules、output format | 追加修正なしでtaskを解けるか |
| Context | files、logs、snippets、token budget | 参照漏れ、context drift、制約落ち |
| Tools | commands、permissions、retry policy | tool-call accuracy、不要なactions |
| Tests | unit tests、eval set、manual checks | accepted diff、failed checks、hidden defects |
| Operations | hardware、runtime、quantization、batch | latency、memory pressure、crash、recovery |
Candidate branchがtask completion、reviewer edits、retry count、hidden defects、operating costでcurrent defaultに勝つか同等になるまでdefaultにしません。速いが手修正が増えるmodelは速くありません。賢いがmemory budgetに入らないmodelも、より良いdefaultではありません。
保守時の公式source
QwenのQwen3 announcementは、family framing、open-weight MoE release、model tableを確認するsourceです。Qwen/Qwen3-30B-A3B Hugging Face cardは、original model facts、parameters、experts、activated experts、hybrid behavior、original context boundaryを確認するsourceです。Instruct-2507とThinking-2507 cardsは、branch behaviorと262K native contextを確認するsourceです。
Qwen3-Coder-30B-A3B cardとQwen3-Coder blogは、coding-agent branch framingを確認するsourceです。Ollamaや他のruntime pagesはinstall convenienceを確認するsourceです。Qwen3.6 materialはsuccessor boundaryを確認するsourceです。所有者を分けると、次のbranch updateでも必要な行だけ直せます。
よくある質問
Qwen3-30B-A3Bはまだ使う価値がありますか?
あります。ただしbranchが仕事に合う場合です。Instruct-2507は普通のlocal instruction、Thinking-2507はheavy reasoning、Coder-30B-A3Bはcoding loopに向きます。Original branchは主にApril 2025 reproductionとold comparison向けです。
A3Bは3B modelという意味ですか?
違います。A3Bはsparse MoEで有効化されるparameter sliceを指します。Original owner cardは30.5B total parametersと3.3B activated parametersを記録しています。Deployment memoryはfull stackに依存します。
Instruct-2507とThinking-2507はどう選びますか?
速くてcleanなanswerが必要ならInstruct-2507です。問題が十分に難しく、追加のreasoningがerrorを減らすならThinking-2507を測ります。
Qwen3-Coder-30B-A3Bは同じmodelですか?
関連するCoder branchですが、original Qwen/Qwen3-30B-A3B cardの同義語ではありません。Repository-scale codingとtool useでは先に測る価値があります。
Ollamaだけでbranchは判断できますか?
Ollamaは実用的なlocal routeを提供しますが、upstream model ID、quantization、context setting、prompt templateを別に確認してください。
VRAMはどれくらい必要ですか?
全設定に共通する一つの数字はありません。Quantization、context length、KV cache、framework overhead、batch、concurrencyがmemory pressureを変えます。
いつQwen3.6を見るべきですか?
新しいQwen local/coding routeを検討する時です。Qwen3.6-35B-A3Bはsuccessor comparisonであり、Qwen3-30B-A3Bの静かなreplacementではありません。