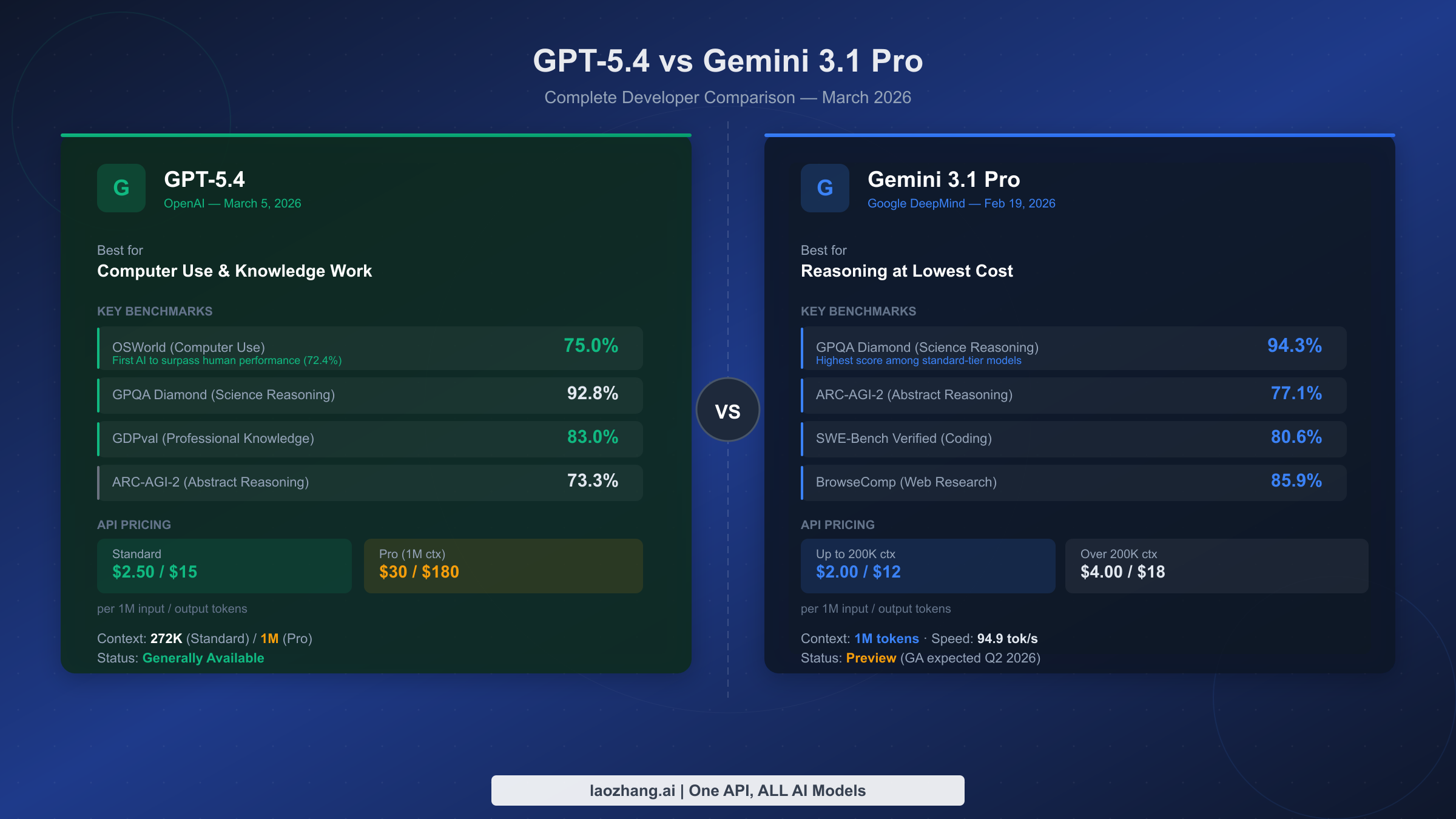
GPT-5.4 と Gemini 3.1 Pro は、2026年3月のAI業界で最も激しい競争を繰り広げています。2週間の差でリリースされ——Gemini 3.1 Pro が2月19日、GPT-5.4 が3月5日——ベンチマークスコアはほぼ均等に分かれています。Gemini は抽象的推論でリード(GPQA Diamond 94.3% 対 92.8%)し、最大15倍安くなります。GPT-5.4 はデスクトップPC操作タスクで人間水準を超えた初のAIです(OSWorld 75%)。絶対的な勝者はなく、正しい選択はユースケースと予算によって異なります。
まとめ
- GPT-5.4 はPC操作自動化(OSWorld 75%、人間水準超え)、専門知識業務(GDPval 83%)、ターミナル作業(Terminal-Bench 2.0 75.1%)でリード
- Gemini 3.1 Pro は抽象的推論(GPQA Diamond 94.3%、ARC-AGI-2 77.1%)、Web調査(BrowseComp 85.9%)、コーディング(SWE-Bench Verified 80.6%)でリード
- 料金差は見出しほど大きくない:標準プランの差はわずか約20%。15倍の差は GPT-5.4 Pro($30/M)対 Gemini 3.1 Pro Standard($2/M)の比較時のみ
- Gemini 3.1 Pro はまだ Preview 状態(2月19日リリース、GA は Q2 2026予定)——本番環境計画に要考慮
- レイテンシ警告:Gemini 3.1 Pro のTTFT(初回トークン生成時間)は44.5秒——リアルタイムチャットには不向き
クイック概要:GPT-5.4 と Gemini 3.1 Pro とは?
ベンチマークと料金に踏み込む前に、重要な点を明確にしましょう:GPT-5.4 は1つのモデルではなく、価格帯が大きく異なる2つの製品です。混同するとコスト見積もりが大幅にずれ、アーキテクチャ決定を誤る可能性があります。
GPT-5.4 Standard は OpenAI が2026年3月5日に正式リリース(GA)したフラッグシップモデルで、コンテキストウィンドウ272Kトークン、入力$2.50/M・出力$15/Mの料金です。GPT-5.4 Pro は別の高価な製品で、コンテキストウィンドウ1Mトークン、入力$30/M・出力$180/M——Standard の12倍です。「Gemini は GPT-5.4 より15倍安い」という見出しは、ほぼ確実に GPT-5.4 Pro の料金を使った比較です。GPT-5.4 Standard との比較では、Gemini 3.1 Pro はわずか約20%安いだけです。
Gemini 3.1 Pro は Google DeepMind が2026年2月19日にリリースし、現在 Preview 状態です。標準プランでネイティブに1Mトークンのコンテキストウィンドウを提供し、追加料金不要です。料金はコンテキスト長により異なります:200K以下は入力$2/M・出力$12/M、200K超は入力$4/M・出力$18/M。Google は GA を Q2 2026に予定しています。
| スペック | GPT-5.4 Standard | GPT-5.4 Pro | Gemini 3.1 Pro |
|---|---|---|---|
| リリース | 2026年3月5日 | 2026年3月5日 | 2026年2月19日 |
| 状態 | 一般提供(GA) | 一般提供(GA) | Preview |
| コンテキスト | 272Kトークン | 1Mトークン | 1Mトークン |
| 入力料金 | $2.50/M | $30/M | $2/M(≤200K)/$4/M(>200K) |
| 出力料金 | $15/M | $180/M | $12/M(≤200K)/$18/M(>200K) |
| 提供元 | OpenAI | OpenAI | Google DeepMind |
ベンチマーク対決:完全スコア表
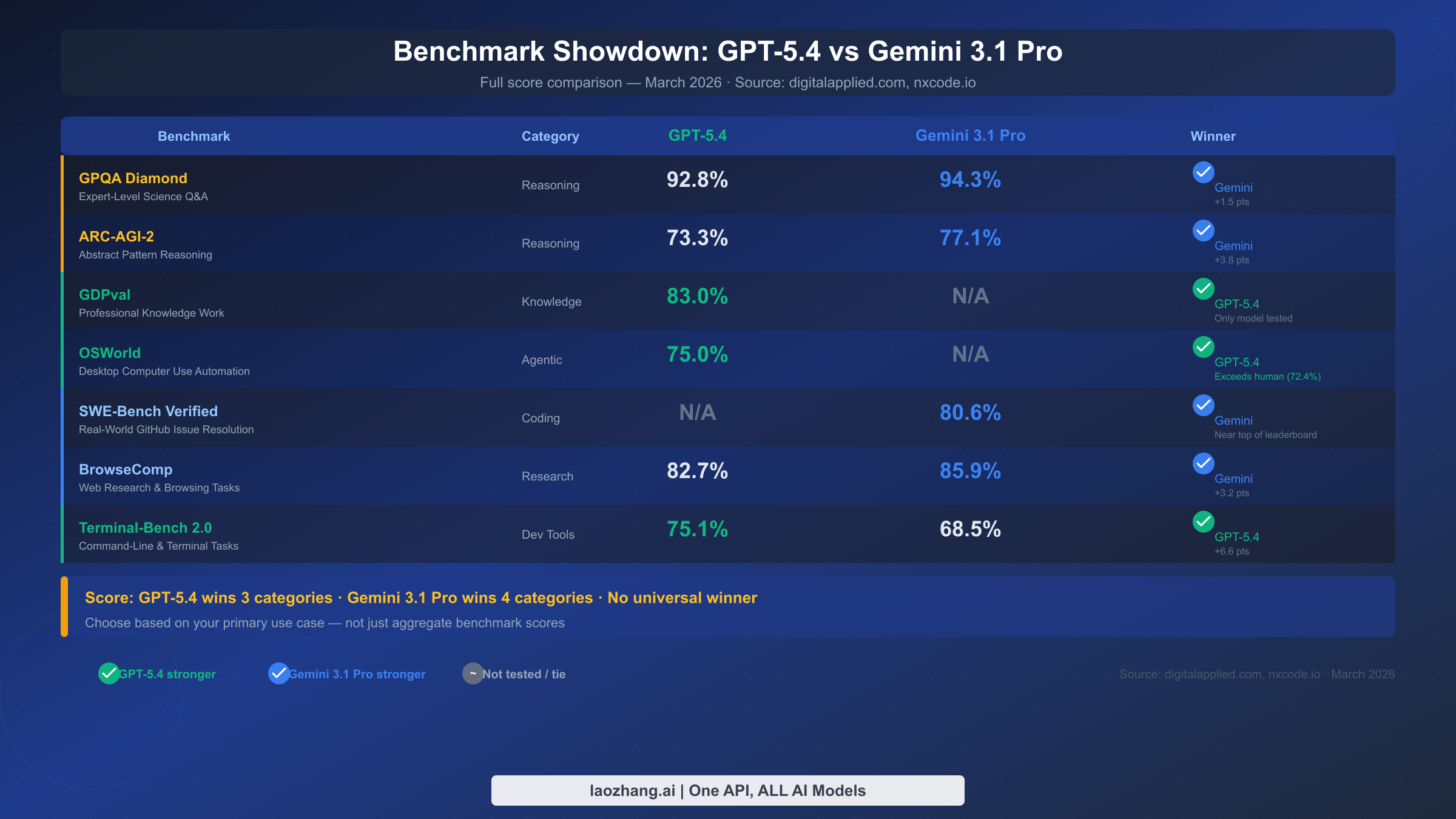
核心的な結論:この2つのモデルはベンチマーク評価項目をほぼ均等に分け合っており、どちらも明確な全体的優位性を持ちません。GPT-5.4 は3項目でリード——GDPval、OSWorld、Terminal-Bench 2.0。Gemini 3.1 Pro は4項目でリード——GPQA Diamond、ARC-AGI-2、SWE-Bench Verified、BrowseComp。Claude や他のプロバイダーとの広範な比較については、主要AIプロバイダーのAPI比較をご参照ください。
| ベンチマーク | カテゴリ | GPT-5.4 | Gemini 3.1 Pro | 勝者 |
|---|---|---|---|---|
| GPQA Diamond | 専門家レベルの科学推論 | 92.8% | 94.3% | Gemini(+1.5pt) |
| ARC-AGI-2 | 抽象パターン推論 | 73.3% | 77.1% | Gemini(+3.8pt) |
| GDPval | 専門知識業務 | 83.0% | N/A | GPT-5.4 |
| OSWorld | デスクトップPC操作 | 75.0% | N/A | GPT-5.4(人間水準72.4%超え) |
| SWE-Bench Verified | GitHub問題解決 | N/A | 80.6% | Gemini |
| BrowseComp | Web調査 | 82.7% | 85.9% | Gemini(+3.2pt) |
| Terminal-Bench 2.0 | CLIとターミナル | 75.1% | 68.5% | GPT-5.4(+6.6pt) |
出典:digitalapplied.com, nxcode.io — 2026年3月
GPT-5.4 の OSWorld 75% は最も注目すべき結果です:デスクトップPC操作タスクで人間水準(72.4%)を超えた初のAIモデルです。これはブラウザ、Excel、アプリケーションをプラグインなしで自律的に制御できることを意味します。RPA代替や自動化エージェントを構築するチームにとって、他のスコアに関わらずこのベンチマークが決定要因となる可能性があります。Gemini 3.1 Pro の GPQA Diamond 94.3% も同様に注目に値します——標準プランモデルの中で最高スコアで、生物学・化学・物理学の専門家レベルの推論能力を示しています。
推論と専門知識業務
GPT-5.4 は応用的な専門推論——法律文書、財務モデル、ビジネスインテリジェンスワークフローで必要な構造化分析——に優れています。GDPval 83% は実際の専門知識業務タスクでの性能を測定しており、現在このベンチマークでテストされた唯一のフロンティアモデルです。Gemini 3.1 Pro は一方で、GPQA Diamond と ARC-AGI-2 が測定する多段階仮説形成と科学的演繹など、より抽象的・学術的な推論領域で優れています。
Gemini 3.1 Pro にはまた、複雑な推論チェーンに追加計算を割り当てる専用の思考モード(Thinking Mode)があります。Gemini の思考モード機能は、難しい数学・論理問題での性能を大幅に向上させることができますが、すでに高いベース TTFTに追加のレイテンシが加わります。実用的な意味:アプリケーションが専門的なビジネス分析に似た質問——「この契約書のリスク条項を要約して」「これらの四半期データから財務モデルを作成して」——をする場合は GPT-5.4 の GDPval アドバンテージが有利です。科学的な推論に似た質問——「この実験デザインを評価して」「これらの研究論文の知見を統合して」——をする場合は Gemini 3.1 Pro の優位性が活きます。
スピードとレイテンシ:隠れた決定要因
レイテンシデータはモデル比較記事では一貫して軽視されていますが、本番アプリケーションで最も運用上重要な要因であることが多いです。GPT-5.4 のレイテンシプロファイルは本稿執筆時点で完全には公開されていませんが、現在のフロンティアモデルに匹敵する応答性が期待されます。Gemini 3.1 Pro のレイテンシは独立した測定機関 artificialanalysis.ai によって測定されており、TTFT(初回トークン生成時間)は約44.5秒と報告されています。
これは本番APIとして極めて高い TTFTです——最適化されたほとんどのフロンティアモデルは1〜5秒で最初のトークンを出力します。最初のトークンが到達した後は約94.9トークン/秒で出力されるため、生成自体は速いです——遅延は最初のトークンを開始することにあります。したがって、バッチ・非同期ワークロードでは Gemini 3.1 Pro が適切ですが、インタラクティブなユーザー向けアプリケーションには適していません。クライアント側のタイムアウト設定を少なくとも60秒に設定し、ストリーミング応答の失敗と判断しないようにしてください。
実際のコスト計算
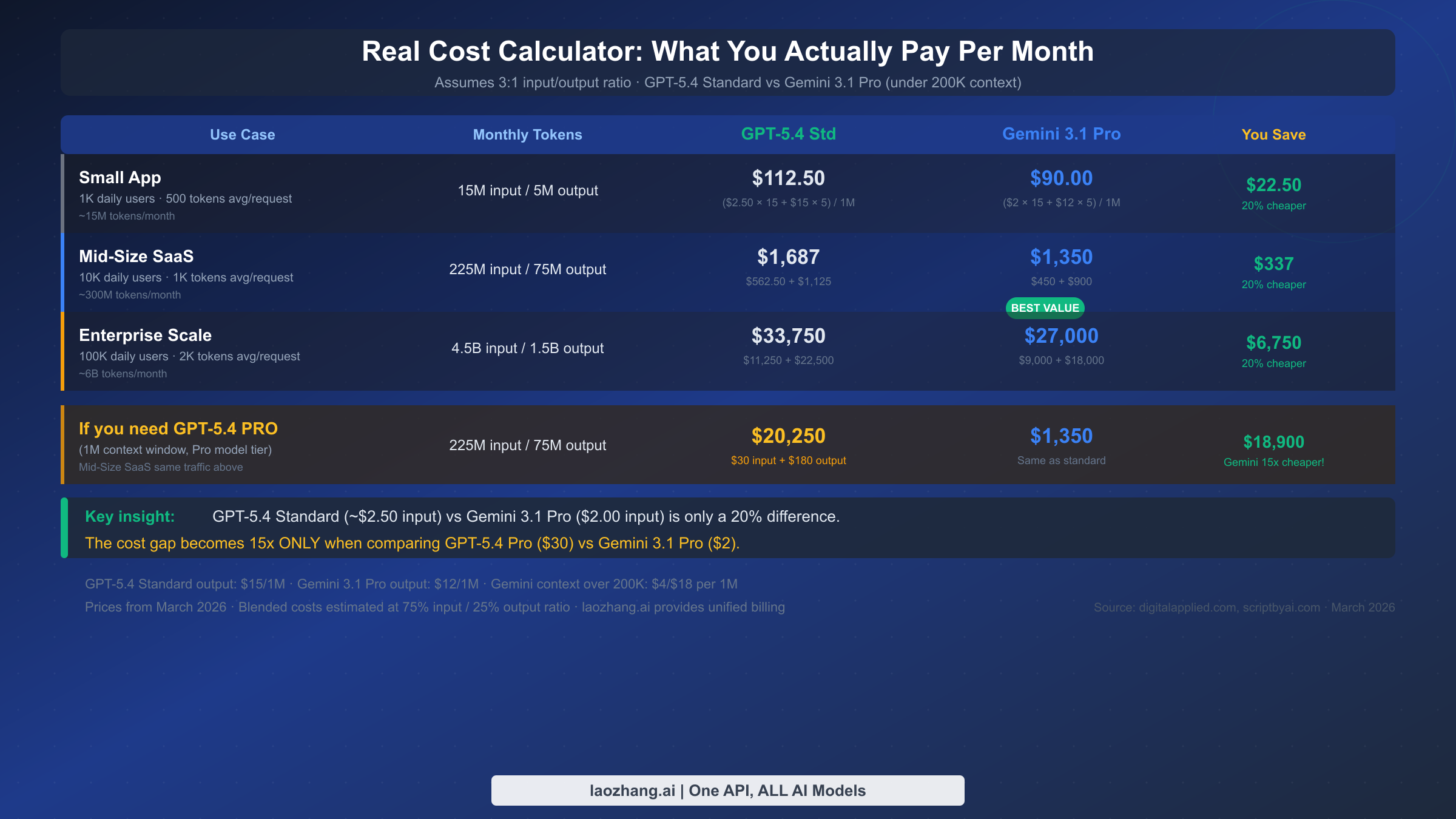
以下の計算は3:1の入力/出力比を使用します。Gemini料金の詳細な内訳は、Gemini API料金ガイドでご確認ください。
小規模アプリ(日次1Kユーザー、~500トークン/リクエスト)
月間約1500万入力トークンと500万出力トークン。GPT-5.4 Standard:$37.50 + $75.00 = $112.50/月。Gemini 3.1 Pro:$30.00 + $60.00 = $90.00/月。差額$22.50——Gemini は約20%安い。
中規模SaaS(日次1万ユーザー、~1Kトークン/リクエスト)
月間約2.25億入力・7500万出力トークン。GPT-5.4 Standard:$562.50 + $1,125 = $1,687/月。Gemini 3.1 Pro:$450 + $900 = $1,350/月。月$337の節約は大きくなりますが、パーセンテージの差は依然として約20%です。
エンタープライズ規模(日次10万ユーザー、~2Kトークン/リクエスト)
月間約45億入力・15億出力トークン。GPT-5.4 Standard:$11,250 + $22,500 = $33,750/月。Gemini 3.1 Pro:$9,000 + $18,000 = $27,000/月。月$6,750の節約は年間$80,000以上に相当します。
Proプランのコスト差(実際に適用される場合)
GPT-5.4 Pro で同じ中規模SaaSトラフィックを処理すると$20,250/月——対して Gemini 3.1 Pro の$1,350/月。この月$18,900の差は、非常に長いドキュメントや大規模なコードベースを処理するチームにとって実質的な選択ポイントです。両方のモデルを異なるワークロードに使用するチームには、laozhang.ai のような統合APIサービスで単一APIキーの下で GPT-5.4 と Gemini 3.1 Pro を統合することで、運用コストを削減できます。
どのモデルを選ぶべきか?
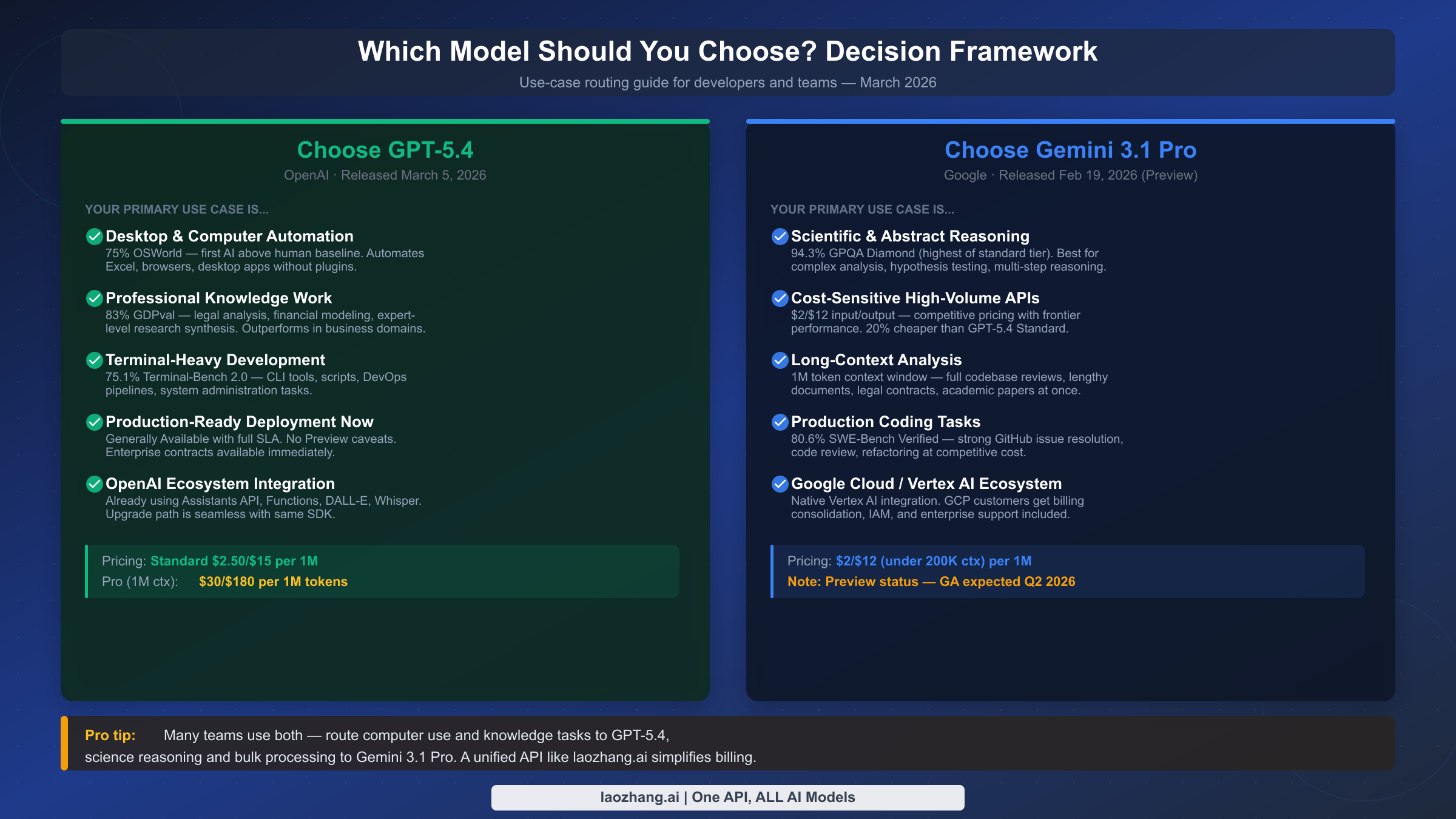
どのモデルも普遍的に優れているわけではありません——正しい選択は何を構築するかによって決まります。
GPT-5.4 を選ぶ場合:
PC操作とデスクトップ自動化が主なワークロードの場合。OSWorld 75% で GPT-5.4 はこのベンチマークで人間水準を超えた唯一のフロンティアモデルです。専門知識ドメインで GDPval タイプのタスクが多い場合。法律分析、財務モデリング、ビジネスインテリジェンス。アプリケーションがユーザー向けで低レイテンシが必要な場合。今すぐ本番環境対応のデプロイが必要で完全なSLA保証が必要な場合。
Gemini 3.1 Pro を選ぶ場合:
科学的・抽象的推論がアプリケーションの中核の場合。GPQA Diamond 94.3% と ARC-AGI-2 77.1% は研究ツール、科学分析プラットフォームでの実際の能力アドバンテージです。ワークロードがバッチ処理・非同期でレイテンシ非感応の場合。長コンテキスト分析が重要な要件の場合——コードベース全体、長い契約書、研究論文のコレクション処理。インフラが Google Cloud の場合——ネイティブの Vertex AI 統合と IAM サポート。
ハイブリッド戦略
多くの本番チームは最終的に両方のモデルを実行します。PC操作、知識業務、リアルタイム機能は GPT-5.4 へ。科学的推論、バッチ処理、長コンテキスト分析は Gemini 3.1 Pro へ。
本番環境への対応:可用性・SLA・安定性
GPT-5.4 は一般提供(GA)です。これは標準アップタイム SLA でサポートされ、企業契約の交渉も可能で、API 動作が安定していることを意味します。OpenAI は GA モデルの後方互換性維持と廃止前の事前通知の実績があります。
Gemini 3.1 Pro は Preview 状態です。Preview 状態では、より頻繁にバージョン更新(モデル動作を変える可能性がある)が来る可能性があり、完全な GA SLA 保証がなく、Google のエンタープライズサポート条件下では提供されない場合があります。今すぐ始めたい開発者は、Google AI Studio での Gemini 3.1 Pro Preview 無料 API アクセスを通じて費用なしで評価できます。GA は Q2 2026 を予定しています。
APIインテグレーション クイックスタート
GPT-5.4 — Python(OpenAI SDK)
pythonfrom openai import OpenAI client = OpenAI(api_key="your-openai-api-key") response = client.chat.completions.create( model="gpt-5.4", # 標準プラン、272Kコンテキスト messages=[ {"role": "system", "content": "あなたは財務モデリングの専門アナリストです。"}, {"role": "user", "content": "以下の四半期業績データを分析し、主要なトレンドを特定してください..."} ], max_tokens=2048, temperature=0.3, ) print(response.choices[0].message.content)
Gemini 3.1 Pro — Python(google-genai SDK)
pythonimport google.generativeai as genai genai.configure(api_key="your-google-api-key") model = genai.GenerativeModel(model_name="gemini-3.1-pro") response = model.generate_content("以下の論文アブストラクトの実験デザインを評価してください...") print(response.text)
両モデル対応の統合APIエンドポイント
pythonfrom openai import OpenAI client = OpenAI( api_key="your-unified-api-key", base_url="https://api.laozhang.ai/v1" ) response = client.chat.completions.create( model="gemini-3.1-pro", # または "gpt-5.4"——同じSDK messages=[{"role": "user", "content": "プロンプトをここに"}], )
完全な APIドキュメントは docs.laozhang.ai でご確認ください。Gemini 3.1 Pro の高い TTFT のため、クライアント側のタイムアウトを少なくとも60秒に設定してください。
よくある質問
GPT-5.4 は本当に Gemini 3.1 Pro より15倍高いですか?
GPT-5.4 Pro($30/M入力)と Gemini 3.1 Pro Standard($2/M)を比較した場合のみです。GPT-5.4 Standard($2.50/M)は Gemini 3.1 Pro より約20〜25%高い程度です。ほとんどのAPIユースケースはProプランの1Mコンテキストウィンドウを必要としません。
今日から Gemini 3.1 Pro を本番環境で使えますか?
はい、ただし注意が必要です。Gemini 3.1 Pro Preview は機能しており、多くのチームが非ユーザー向けの本番ワークロードで使用しています。ただし、完全な GA SLA 保証はなく、規制業界や SLA 保証が契約上必要なアプリケーションには GA(Q2 2026予定)を待つことをお勧めします。
コーディングにはどちらのモデルが適していますか?
Gemini 3.1 Pro は SWE-Bench Verified 80.6% で、実際の GitHub 問題解決で競争力があります。GPT-5.4 は Terminal-Bench 2.0 で 75.1% を記録しています。一般的なコーディングとコードレビューでは Gemini 3.1 Pro の方が強力なベンチマーク根拠があります。DevOps、スクリプト、ターミナル自動化では GPT-5.4 のアドバンテージが活きます。
TTFT 44.5秒は Gemini 3.1 Pro の実用性にどう影響しますか?
バッチ・非同期ワークロードでは全く影響しません。インタラクティブなアプリケーションでは、44.5秒の待ち時間は深刻なUX問題です。最初のトークン到達後は約94.9トークン/秒で生成され、生成自体は速いです——遅延は最初のトークンを開始することにあります。
まとめ
GPT-5.4 と Gemini 3.1 Pro は実際には競合するより補完し合う関係です。GPT-5.4 はPC操作自動化、専門知識業務、ターミナル重視の開発、GA安定性と低レイテンシが不可欠なアプリケーションで真価を発揮します。Gemini 3.1 Pro は科学的推論、長コンテキスト分析、バッチ処理、コスト重視の高ボリュームワークロードで真価を発揮します。規模で構築するほとんどのチームは、ハイブリッドルーティング戦略でそれぞれのモデルの強みを最大限に活用できるでしょう。