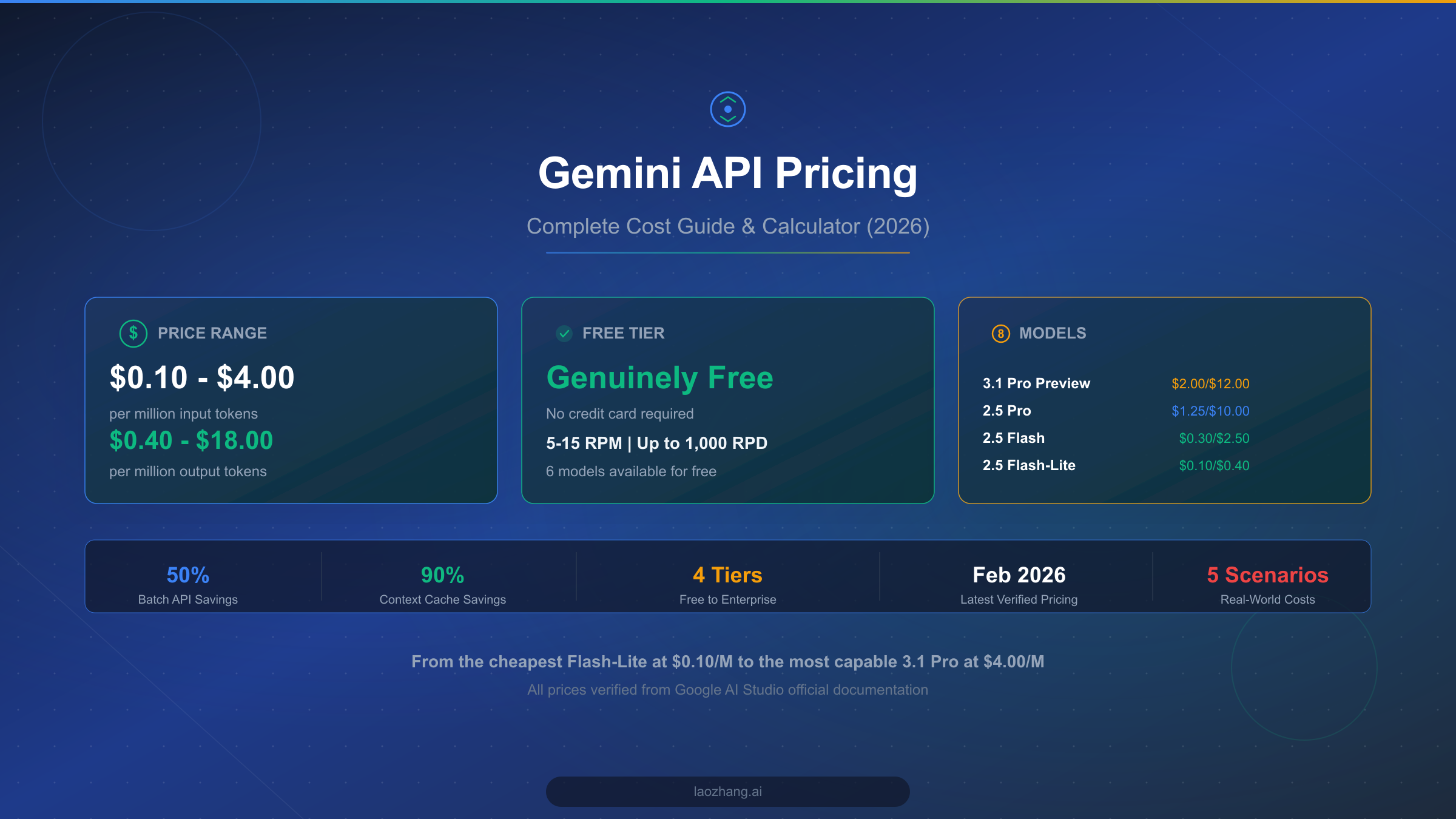
Gemini API pricing spans a remarkably wide range, from just $0.10 per million input tokens with the budget-friendly Flash-Lite model all the way up to $4.00 per million input tokens for the most capable 3.1 Pro Preview, according to the official Google AI Studio pricing page verified on February 26, 2026. Output tokens range from $0.40 to $18.00 per million tokens. Google also offers a genuinely free tier with no credit card required, supporting 5 to 15 requests per minute and up to 1,000 daily requests across six different models. Whether you are building a weekend project or scaling an enterprise AI pipeline, understanding these pricing tiers is essential to keeping your costs predictable while accessing Google's most advanced language models.
TL;DR
Gemini API costs between $0.10 and $4.00 per million input tokens depending on the model you choose. The free tier gives you access to six models including Gemini 2.5 Flash and 3 Flash Preview with 5-15 RPM limits and up to 1,000 requests per day. For paid usage, Gemini 2.5 Flash-Lite offers the best value at $0.10/$0.40 per million tokens, while Gemini 2.5 Pro provides the best balance of capability and cost at $1.25/$10.00. You can reduce costs by up to 90% using context caching, batch processing, and smart model selection.
Complete Gemini API Pricing Table (February 2026)
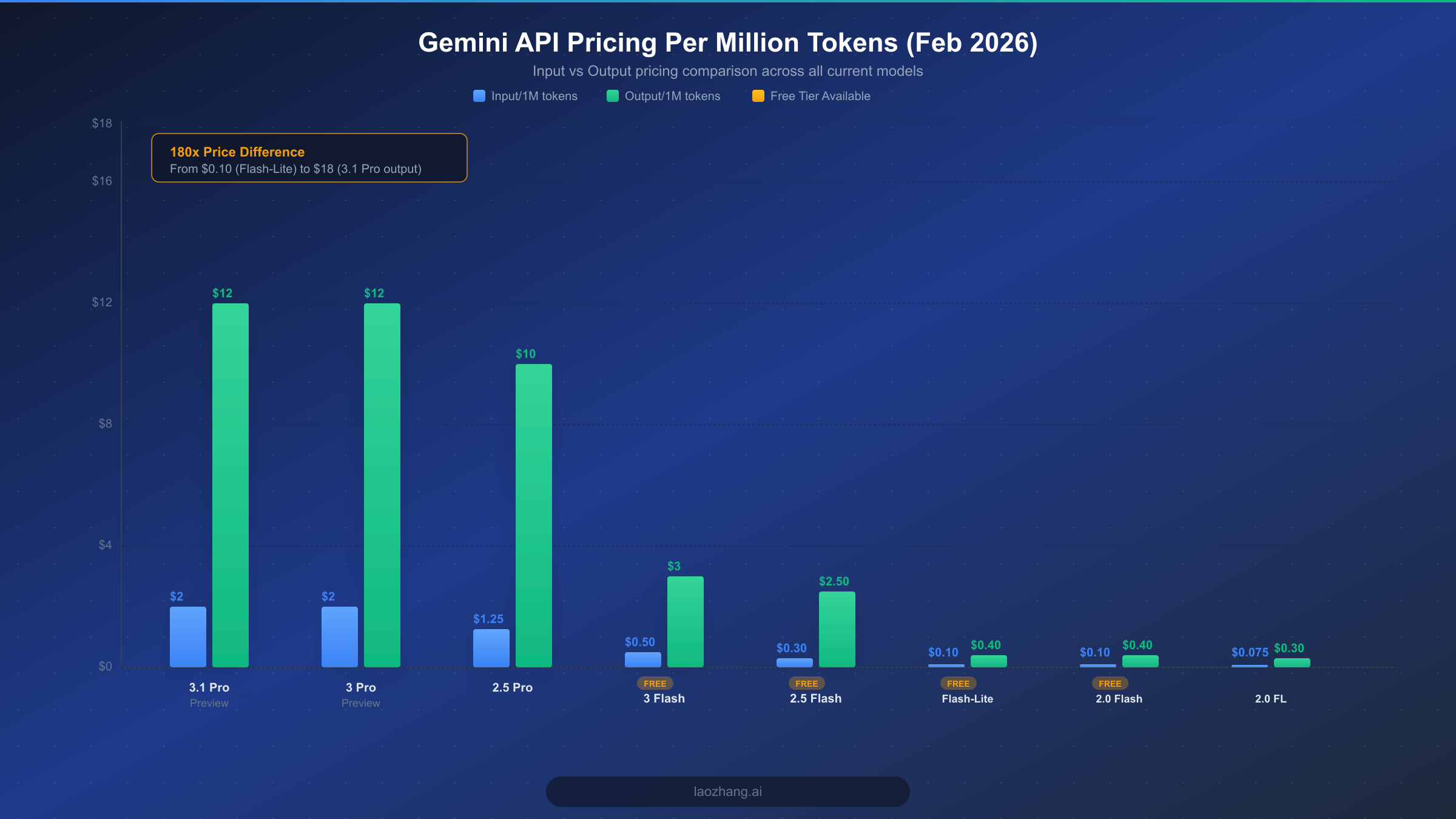
Google currently offers eight distinct models through the Gemini API, each targeting different use cases and budget levels. The pricing structure follows a straightforward per-token model, where you pay separately for input tokens (your prompts and context) and output tokens (the model's responses). Understanding the full pricing landscape is critical because the difference between the cheapest and most expensive options represents a 180x cost multiplier, meaning the wrong model choice could inflate your monthly bill dramatically.
The flagship models in the Gemini lineup are the 3.1 Pro Preview and 3 Pro Preview, both priced at $2.00 per million input tokens and $12.00 per million output tokens for context windows up to 200,000 tokens (ai.google.dev, February 2026). When your prompts exceed the 200K token threshold, these prices double to $4.00 and $18.00 respectively, making it crucial to monitor your context length when working with large documents or extended conversations. These Pro models deliver the highest reasoning capability and are best suited for complex analysis, multi-step problem solving, and tasks where accuracy matters more than cost efficiency.
Gemini 2.5 Pro sits in a compelling middle ground at $1.25 per million input tokens and $10.00 per million output tokens for standard context, rising to $2.50 and $15.00 for contexts exceeding 200K tokens (ai.google.dev, February 2026). For many production workloads, this model represents the optimal balance between capability and cost, delivering near-flagship performance at roughly 60% of the Pro Preview pricing. Developers building applications that need strong reasoning without the premium price tag often find that 2.5 Pro handles their requirements effectively while leaving headroom in their budget for scaling.
The Flash family of models is where cost-conscious developers find the most value. Gemini 3 Flash Preview costs $0.50 per million input tokens for text and $1.00 for audio, with output priced at $3.00 per million tokens. Gemini 2.5 Flash drops further to $0.30 per million text input tokens and $2.50 for output. For the absolute lowest per-token cost, Gemini 2.5 Flash-Lite charges just $0.10 per million input tokens and $0.40 per million output tokens, making it one of the most affordable commercial-grade language models available anywhere. Gemini 2.0 Flash matches Flash-Lite at $0.10/$0.40 for text, while the even older 2.0 Flash-Lite reaches the floor at $0.075 per million input tokens and $0.30 for output (invertedstone.com, February 2026).
| Model | Input/1M (≤200K) | Output/1M (≤200K) | Input/1M (>200K) | Output/1M (>200K) |
|---|---|---|---|---|
| Gemini 3.1 Pro Preview | $2.00 | $12.00 | $4.00 | $18.00 |
| Gemini 3 Pro Preview | $2.00 | $12.00 | $4.00 | $18.00 |
| Gemini 2.5 Pro | $1.25 | $10.00 | $2.50 | $15.00 |
| Gemini 3 Flash Preview | $0.50 (text) | $3.00 | - | - |
| Gemini 2.5 Flash | $0.30 (text) | $2.50 | - | - |
| Gemini 2.5 Flash-Lite | $0.10 (text) | $0.40 | - | - |
| Gemini 2.0 Flash | $0.10 (text) | $0.40 | - | - |
| Gemini 2.0 Flash-Lite | $0.075 | $0.30 | - | - |
Audio input carries a premium across all Flash models. Gemini 2.5 Flash charges $1.00 per million audio tokens compared to $0.30 for text, while Flash-Lite charges $0.30 for audio versus $0.10 for text. If your application processes significant audio content, factor this 3x multiplier into your cost calculations. For applications that can work with Gemini's latest capabilities, check our guide to Gemini 3.1 Pro free API access for the most current model availability.
Is Gemini API Free? Complete Free Tier Guide
One of the most compelling aspects of the Gemini API is its genuinely free tier, which requires no credit card and no billing setup whatsoever. Unlike many competitors that offer limited trial credits or time-bound free trials, Google provides ongoing free access to six models including Gemini 3 Flash Preview, Gemini 2.5 Flash, Gemini 2.5 Flash-Lite, Gemini 2.0 Flash, Gemini Embedding, and the open-source Gemma 3 and 3n models (ai.google.dev, February 2026). This makes it one of the most accessible AI API platforms for developers who want to prototype, experiment, or build low-traffic applications without any financial commitment.
The free tier does come with meaningful rate limits that determine how much you can realistically accomplish without paying. Request-per-minute (RPM) limits range from 5 to 15 depending on the specific model, with most Flash models allowing around 10 RPM. Daily request limits (RPD) vary more significantly, ranging from approximately 100 to 1,000 requests per day depending on the model and current allocation. Token-per-minute (TPM) limits sit at around 250,000 tokens, which provides enough throughput for moderate interactive use but can become a bottleneck for batch processing or high-traffic applications. For a more detailed breakdown of these limits and how they affect different use cases, see our comprehensive Gemini API free tier guide.
It is important to understand what changed in December 2025, when Google significantly reduced free tier quotas by an estimated 50 to 80 percent (confirmed via Reddit and HowToGeek reports). Before these cuts, free tier users enjoyed substantially more generous allowances, and the reduction caught many developers off guard. The current limits still provide genuine utility for personal projects and prototyping, but developers who relied on the free tier for production workloads found themselves needing to migrate to paid plans or dramatically reduce their usage. If you are planning around the free tier, build in some buffer and monitor your usage closely, because quotas can change without much advance notice.
There is one critical limitation that many developers overlook: content submitted through the free tier may be used by Google to improve their models. This means that sensitive data, proprietary code, or confidential business information should never be processed through free tier access. Paid tier usage, by contrast, comes with data processing agreements that prevent Google from using your inputs for model training. This distinction alone is often the deciding factor for businesses evaluating whether the free tier is suitable for their use case. For the complete picture on rate limits across all tiers, see our complete rate limits guide.
When Should You Upgrade from Free to Paid?
The decision to upgrade from the free tier to a paid plan typically comes down to three factors: throughput needs, data privacy requirements, and reliability expectations. If you find yourself consistently hitting RPM or RPD limits during normal operations, or if your application serves real users who expect consistent response times, upgrading to Tier 1 (which requires simply setting up a billing account) immediately boosts your RPM to 150-300 depending on the model. The cost is purely usage-based with no minimum commitment, so you only pay for what you actually consume. Tier 2 requires at least $250 in accumulated spend over 30 days and unlocks 1,000+ RPM, while Tier 3 at $1,000+ spend provides even higher limits suitable for enterprise-scale deployments (aifreeapi.com, January 2026).
What Gemini API Actually Costs: 5 Real-World Scenarios
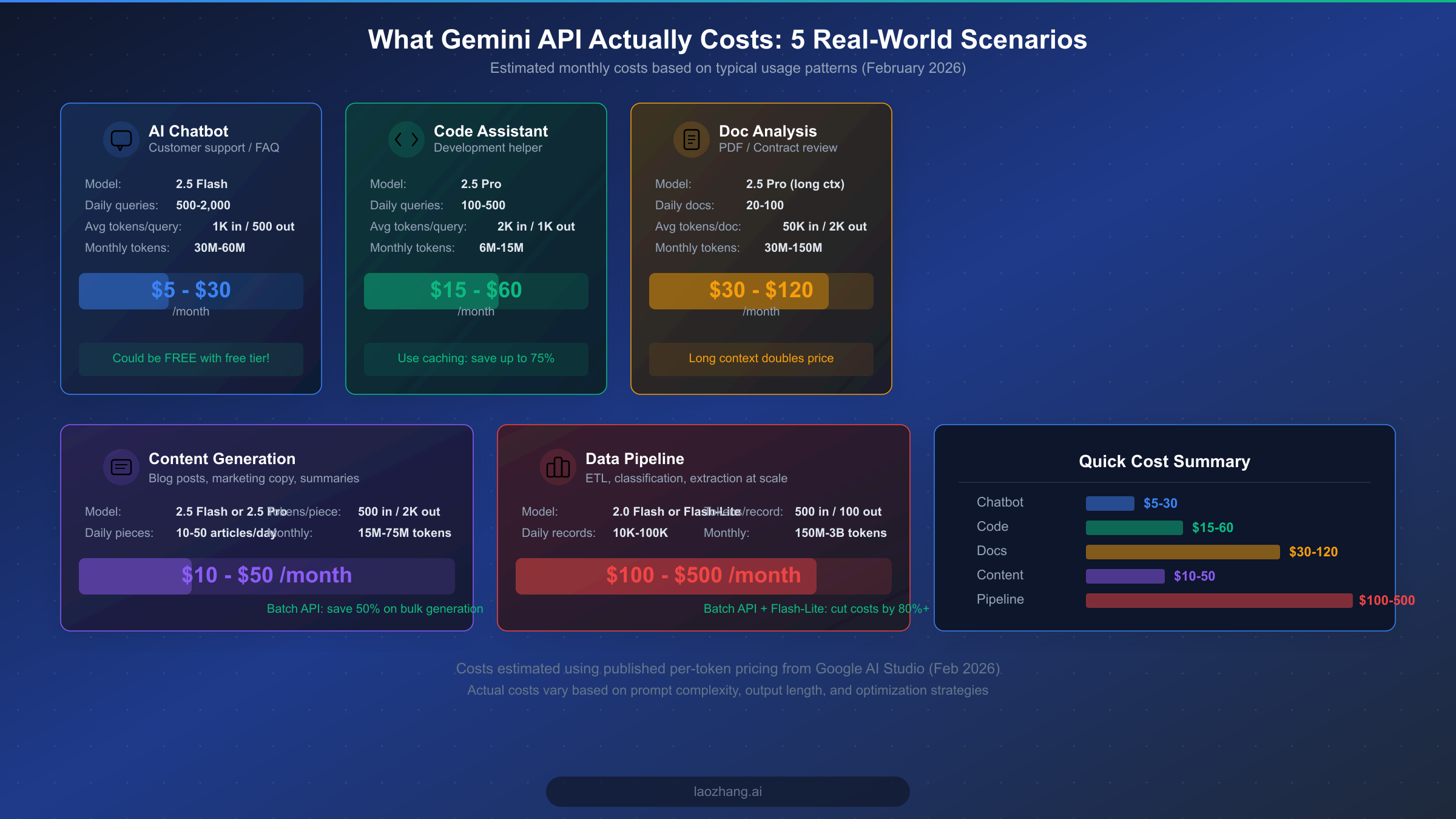
Per-token pricing tables are useful for comparison, but most developers really want to know one thing: what will this actually cost me each month? The answer depends heavily on your specific use case, the model you choose, how efficiently you structure your prompts, and whether you take advantage of optimization features like caching and batch processing. Raw per-token pricing can be misleading because it does not account for the different input-to-output ratios that different applications generate, nor does it reflect the impact of model selection on the total number of tokens needed to achieve acceptable results. Below are five detailed real-world scenarios based on common Gemini API applications, with token estimates derived from typical usage patterns and costs calculated using the official pricing verified in February 2026. These estimates assume standard usage without optimization, so your actual costs could be significantly lower if you implement the strategies covered later in this guide.
Scenario 1: Customer Support Chatbot ($5-$30/month)
A customer support chatbot handling 500 to 2,000 daily queries represents one of the most common Gemini API use cases. Using Gemini 2.5 Flash at $0.30 per million input tokens and $2.50 per million output tokens, with an average conversation consuming roughly 1,000 input tokens (system prompt plus user query plus conversation history) and generating about 500 output tokens per response, you would process between 15 million and 60 million tokens per month. At the lower end with 500 daily queries, your monthly bill would be approximately $5 to $8, while 2,000 daily queries pushes costs to $20 to $30. The compelling part is that if your traffic stays under the free tier limits of roughly 1,000 RPD, this entire chatbot could potentially run at zero cost, making it one of the most affordable ways to deploy an AI-powered customer support system.
Scenario 2: Code Assistant ($15-$60/month)
A developer-focused code assistant typically requires a more capable model like Gemini 2.5 Pro to handle complex code generation, debugging, and architectural suggestions. With 100 to 500 daily queries averaging 2,000 input tokens (code context, file contents, and instructions) and 1,000 output tokens (generated code and explanations), monthly token consumption ranges from 6 million to 15 million tokens. At 2.5 Pro's pricing of $1.25 per million input tokens and $10.00 per million output tokens, this translates to roughly $15 at the low end and up to $60 for heavier usage. Context caching can dramatically reduce these costs if your users frequently work within the same codebase, as the cached system context and repository structure would be charged at reduced rates, potentially cutting costs by 50 to 75 percent.
Scenario 3: Document Analysis Pipeline ($30-$120/month)
Document analysis workloads, such as contract review, PDF extraction, and report summarization, tend to have high input token counts because each document may contain tens of thousands of tokens. Processing 20 to 100 documents daily with Gemini 2.5 Pro, where each document averages 50,000 input tokens and generates 2,000 output tokens of extracted information, means monthly consumption of 30 million to 150 million tokens. Here is where the context length pricing tier becomes important: if your documents push individual requests past the 200K token threshold, input pricing doubles from $1.25 to $2.50 per million tokens. At standard context lengths, monthly costs range from $30 to $120, but long documents could push this significantly higher. Batch processing through the Batch API at 50% off regular pricing can meaningfully reduce costs for non-time-sensitive document processing workflows.
7 Ways to Cut Your Gemini API Costs by Up to 90%
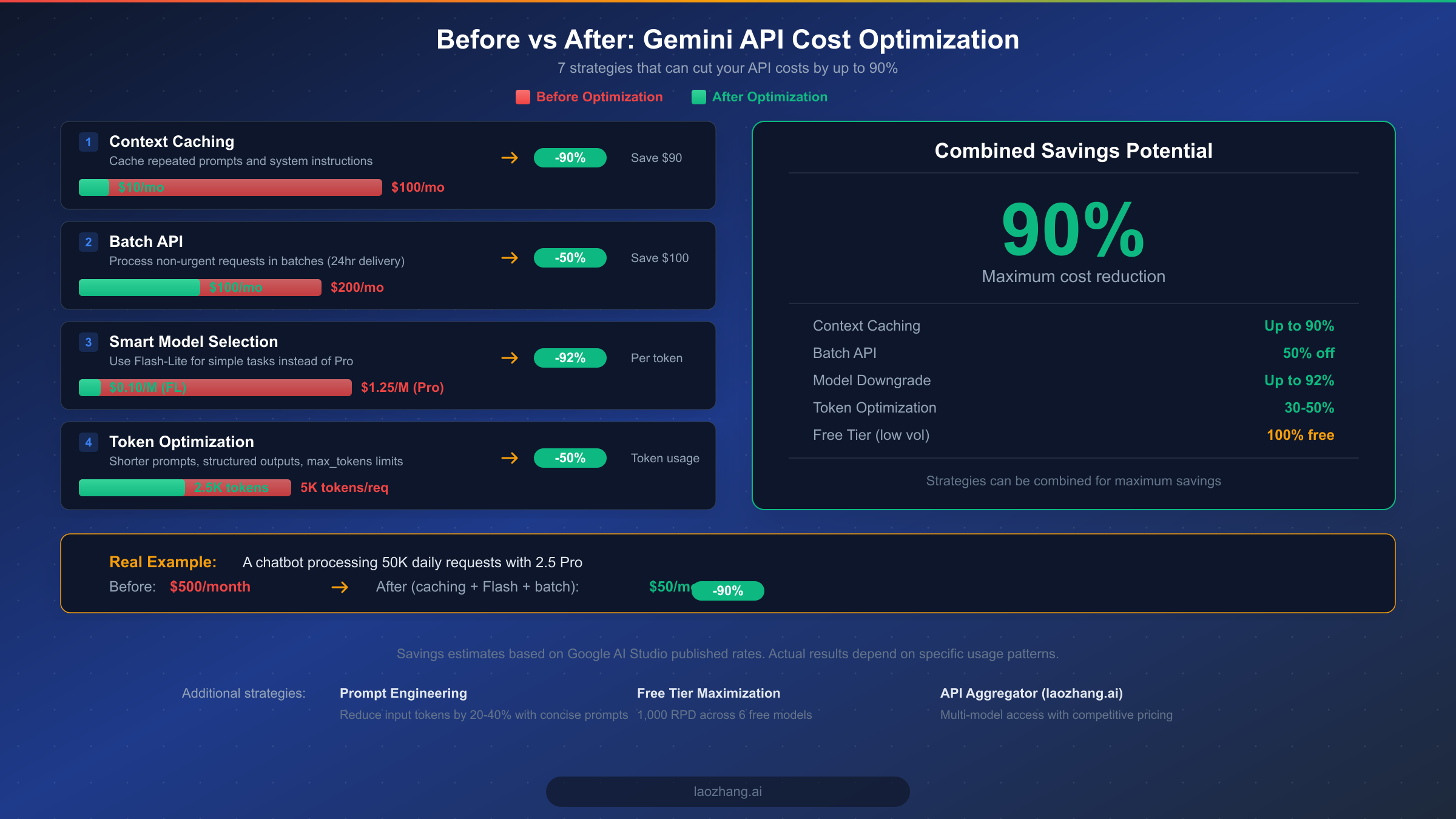
Cost optimization is where the real savings happen, and the Gemini API offers several powerful mechanisms that most developers underutilize. By combining the right strategies, it is entirely realistic to reduce your API spending by 70 to 90 percent compared to a naive implementation. The key is understanding which optimizations apply to your specific usage patterns and stacking them effectively.
Context Caching: The Biggest Single Savings (Up to 90%)
Context caching is the most impactful optimization available in the Gemini API, and it is surprising how few developers take advantage of it. When your application repeatedly sends the same system prompt, few-shot examples, or reference documents with each request, you are paying full input token pricing every single time for identical content. Context caching lets you store this repeated context and reference it across multiple requests at dramatically reduced rates, with cached tokens costing up to 90% less than regular input tokens (ai.google.dev, February 2026). The trade-off is a cache storage fee of $4.50 per million tokens per hour, so this optimization only makes sense when the cached content is reused frequently enough that the storage cost is offset by the input token savings. For a chatbot with a 2,000-token system prompt handling 1,000 daily requests, caching that prompt saves roughly $0.60 per day in input costs while the storage might cost $0.22 per day, resulting in a clear net savings.
Batch API: 50% Off for Non-Urgent Work
The Batch API provides a flat 50% discount on both input and output token pricing in exchange for accepting a 24-hour delivery window for your results (ai.google.dev, February 2026). This makes it ideal for workloads where you do not need immediate responses, such as overnight content generation, bulk data classification, document summarization pipelines, and periodic analytics processing. The implementation is straightforward: instead of making individual synchronous requests, you submit a batch of prompts and retrieve the results when processing completes. For a content generation pipeline producing 50 articles daily at a normal cost of $30 per month, switching to batch processing would immediately cut that to $15 per month with no reduction in output quality.
Smart Model Selection: Match the Model to the Task
One of the most common and expensive mistakes is using a powerful Pro model for tasks that a Flash model handles equally well. Gemini 2.5 Flash-Lite at $0.10 per million input tokens is 12.5 times cheaper than Gemini 2.5 Pro at $1.25, yet for many routine tasks like text classification, simple extraction, and straightforward Q&A, Flash-Lite delivers comparable results. A practical approach is to build a routing layer that evaluates incoming requests and directs them to the appropriate model tier. Complex reasoning tasks go to Pro, standard tasks go to Flash, and simple classification goes to Flash-Lite. This tiered approach often cuts overall costs by 60 to 80 percent while maintaining quality where it matters most.
Prompt Engineering: Reduce Tokens by 20-40%
Prompt engineering is an underappreciated cost lever because it reduces costs at the source by minimizing the number of tokens you send and receive. The most impactful technique is replacing verbose natural language instructions with structured formats. Instead of writing "Please analyze the following text and provide a detailed summary including the main topics, key findings, and any recommendations mentioned," you can use a structured prompt like "Summarize: topics, findings, recommendations" with a clear output format specification. This kind of compression routinely reduces input tokens by 20 to 40 percent without affecting output quality. Similarly, setting explicit max_tokens limits prevents the model from generating unnecessarily verbose responses. If you need a 100-word summary, setting max_tokens to 150 prevents the model from producing a 500-word essay, saving you roughly 70 percent on output token costs for that request.
Free Tier Maximization and Strategic Model Routing
Even after upgrading to a paid tier, the free tier quotas still apply as a separate allocation that does not count toward your billed usage. Smart architecture can route development traffic, internal testing, and low-priority background tasks through free tier access while reserving paid tier capacity for production user-facing requests. With 1,000 daily requests available for free across six models, this strategy can offset a meaningful portion of your overall costs, particularly for smaller teams. For organizations working across multiple AI providers, API aggregator platforms like laozhang.ai offer multi-model access with competitive pricing and simplified billing, which can further reduce costs through volume-based discounts and intelligent model routing that automatically selects the most cost-effective model for each request type.
Gemini vs OpenAI vs Claude: Which API Costs Less?
Choosing between Gemini, OpenAI, and Anthropic's Claude API often comes down to the intersection of price, capability, and specific use case requirements. As of February 2026, the pricing landscape shows clear differentiation between these three major providers, with each offering distinct value propositions for different types of workloads and budgets.
Looking at flagship model pricing, Google's Gemini 2.5 Pro at $1.25 per million input tokens and $10.00 per million output tokens is significantly cheaper than OpenAI's GPT-4o at $5.00/$15.00 and dramatically more affordable than Anthropic's Claude Opus at $15.00/$75.00 per million tokens (intuitionlabs.ai, February 2026). This means that for equivalent workloads, Gemini 2.5 Pro costs roughly 75% less than GPT-4o on input tokens and 33% less on output tokens. When compared to Claude Opus, the savings are even more dramatic at over 90% on both input and output. For cost-sensitive applications that do not specifically require OpenAI or Claude capabilities, Gemini offers a compelling economic argument.
At the budget end of the spectrum, Gemini's Flash-Lite models at $0.10 per million input tokens compete favorably with OpenAI's GPT-4o Mini and Anthropic's Claude Haiku. The xAI Grok models offer even lower per-token pricing at $0.20 per million input and $0.50 per million output tokens, though with a smaller ecosystem, fewer integrations, and less extensive documentation compared to the established providers. For production workloads processing millions of tokens daily, these per-token differences compound into substantial monthly savings, often amounting to thousands of dollars per month at scale. To put this in concrete terms, an application processing 100 million tokens per month would cost approximately $125 with Gemini 2.5 Pro, $500 with GPT-4o, and $1,500 with Claude Opus for input tokens alone, illustrating just how significantly provider choice affects the bottom line. When output token costs are included, the gap widens even further because Gemini's output pricing is proportionally more competitive than its input pricing at every model tier.
| Provider | Flagship Model | Input/1M | Output/1M | Best For |
|---|---|---|---|---|
| Google Gemini | 2.5 Pro | $1.25 | $10.00 | Best value for capability |
| OpenAI | GPT-4o | $5.00 | $15.00 | Ecosystem and plugins |
| Anthropic | Claude Opus | $15.00 | $75.00 | Complex reasoning |
| xAI | Grok | $0.20 | $0.50 | Budget applications |
However, price is not the only consideration when selecting an API provider. OpenAI's GPT-4o maintains advantages in certain coding tasks and has the broadest ecosystem of third-party integrations, plugins, and fine-tuning tools. Its developer community is the largest, which means more tutorials, libraries, and community support are available. Claude Opus excels at nuanced analysis, long-form content generation, and tasks requiring careful instruction following, making it the preferred choice for applications where precision and safety matter most. For a detailed analysis of Claude's pricing structure, see our Claude API pricing guide.
Gemini's unique strengths include native multimodal capabilities with audio and video input at the API level, the most generous free tier among major providers with no credit card required, and seamless integration with Google Cloud services including Vertex AI for enterprise deployments. The context window sizes for Gemini Pro models also tend to be larger than competitors at comparable price points, making Gemini particularly well-suited for document analysis and long-form processing workloads. When choosing between providers, consider running a benchmark with your actual production prompts across two or three services to measure real-world quality differences alongside the pricing differences.
For developers and teams working across multiple providers, the practical challenge of managing separate API keys, billing accounts, and client libraries for each service adds operational overhead. Platforms like laozhang.ai address this by providing unified API access to all major models through a single endpoint, simplifying multi-provider management and often offering competitive pricing through volume aggregation. This approach also enables easy A/B testing between providers and seamless fallback routing if one provider experiences an outage.
Hidden Costs and How to Control Your Gemini API Budget
Beyond the straightforward per-token pricing, several additional costs can catch developers off guard if they are not accounted for in budgeting. Understanding these hidden costs before they appear on your bill is essential for maintaining predictable API spending.
Context cache storage fees represent the most commonly overlooked cost. While caching reduces your per-request input token costs, the cached content itself incurs a storage charge of $4.50 per million tokens per hour (ai.google.dev, February 2026). For a modest cache of 10 million tokens (roughly a medium-sized codebase or document collection), this translates to $45 per hour or $1,080 per day if left running continuously. The lesson is clear: context caches should be created strategically, monitored carefully, and deleted promptly when no longer needed. Setting up automated cache lifecycle management can prevent storage costs from silently accumulating.
Google Search grounding and Maps grounding are powerful features that connect your Gemini API responses to real-time web data and location information, but they come with their own pricing. Google Search grounding provides 1,500 free requests per day, after which each additional 1,000 prompts costs $35. Google Maps grounding similarly offers 1,500 free daily requests with a $25 per 1,000 prompts charge beyond that threshold. For applications that rely heavily on grounded responses, such as research assistants or location-based services, these costs can add up quickly and should be factored into your per-request cost calculations alongside token pricing.
Audio and video processing carry premium rates compared to text, and these costs can dominate your bill if your application handles significant multimedia content. As noted earlier, audio input tokens cost 3 to 10 times more than text tokens depending on the model, with Gemini 2.5 Flash charging $1.00 per million audio tokens versus $0.30 for text. Video processing through models like Veo 3.1 is priced separately at $0.15 to $0.60 per second of generated video, and image generation through Imagen 4 costs $0.02 to $0.06 per image depending on resolution and quality settings (ai.google.dev, February 2026). For the increasingly popular Gemini 2.5 Flash native image generation capability, each generated image costs approximately $0.039. If your application processes mixed media content, the single most important thing you can do is build separate cost tracking for each modality, because a blended average cost metric will hide the true expense of your most expensive processing type and make optimization decisions much harder to make with confidence.
Budget Controls and Billing Alerts
Google provides several tools for controlling your Gemini API spending, and configuring them before scaling to production is strongly recommended. The most essential first step is setting up billing alerts in Google Cloud Console, which sends you email notifications when spending reaches predefined thresholds such as 50%, 80%, and 100% of your monthly budget. These alerts provide early warning so you can investigate unexpected cost increases before they become significant problems.
Beyond alerts, you can configure hard spending caps that automatically disable API access when your budget is exceeded, providing a critical safety net against runaway costs from bugs, traffic spikes, or misconfigured retry logic. This is particularly important during development when experimental code might accidentally generate thousands of API calls through infinite loops or overly aggressive retry mechanisms. For production applications, implementing request-level cost tracking in your application code gives you real-time visibility into spending patterns at a granular level. By logging the token count and estimated cost of each API call, you can identify which features or users are consuming the most budget and make informed decisions about where optimization efforts will have the greatest impact. Many teams find that adding a simple middleware layer that calculates and logs the cost of each request pays for itself within the first month by revealing inefficiencies that would otherwise go unnoticed.
How to Choose the Right Gemini Model for Your Budget
Selecting the right model is the most fundamental cost decision you will make with the Gemini API, and the wrong choice can mean paying 10 to 40 times more than necessary for equivalent results. The decision framework below helps match your specific requirements to the most cost-effective model tier.
For simple, high-volume tasks like text classification, entity extraction, sentiment analysis, and basic Q&A, Gemini 2.5 Flash-Lite or 2.0 Flash at $0.10 per million input tokens delivers excellent results at minimal cost. These models handle structured tasks reliably and their speed makes them ideal for real-time applications where latency matters. When your tasks require moderate reasoning, code generation, or nuanced language understanding, Gemini 2.5 Flash at $0.30 per million tokens offers a significant capability step-up at just 3x the cost of Flash-Lite, representing outstanding value for most production workloads.
For complex analysis, advanced coding, multi-step reasoning, and tasks where accuracy is paramount, Gemini 2.5 Pro at $1.25 per million tokens is the recommended choice. It costs more than the Flash models but delivers meaningfully better results on challenging tasks, making the per-task cost-to-quality ratio favorable when high accuracy matters. Reserve the Pro Preview models (3.1 and 3 Pro) at $2.00 per million tokens for cutting-edge requirements where you need the absolute latest capabilities and are willing to work with preview-stage models. For a deeper comparison of model capabilities across generations, see our Gemini 3 model comparison.
A practical upgrade path for most developers follows a predictable progression. Start with the free tier during the prototyping and validation phase, where you can experiment with different models and prompt strategies without any financial commitment. Once your application is ready for real users, move to Tier 1 by enabling billing and deploy with Flash models, which provide the best combination of low cost and production-ready reliability. As your user base grows and you gather real usage data, selectively introduce Pro models for specific high-value tasks while keeping Flash models for routine operations. Finally, scaling to Tier 2 after accumulating $250 in spend unlocks the higher rate limits needed for enterprise-scale deployments. This staged progression lets you validate your use case economics at each step before committing to higher-cost models, ensuring that every dollar of API spending delivers measurable value to your users.
The most common mistake developers make is choosing a model during prototyping and never revisiting that decision as their application matures and usage patterns become clearer. Schedule quarterly reviews of your model selection against actual usage data, because the rapidly evolving Gemini model lineup means that newer, cheaper models may handle your workload just as well as the more expensive option you originally selected.
FAQ: Your Gemini API Pricing Questions Answered
How much does Gemini API cost per million tokens?
Gemini API pricing ranges from $0.075 to $4.00 per million input tokens and $0.30 to $18.00 per million output tokens, depending on the model and context length. The most affordable option is Gemini 2.0 Flash-Lite at $0.075/$0.30, while the most capable Gemini 3.1 Pro Preview costs $2.00/$12.00 for standard context and $4.00/$18.00 for contexts exceeding 200K tokens (ai.google.dev, February 2026).
Is Gemini API free to use?
Yes, Google offers a genuinely free tier that requires no credit card and no billing setup. Six models are available for free, including Gemini 2.5 Flash and 3 Flash Preview, with rate limits of 5 to 15 requests per minute and up to 1,000 requests per day. However, free tier usage may be used for model improvement, so avoid sending sensitive data through free tier access.
Which is cheaper, Gemini API or ChatGPT API?
Gemini API is significantly cheaper for comparable models. Gemini 2.5 Pro costs $1.25 per million input tokens compared to GPT-4o at $5.00, making Gemini roughly 75% cheaper on input costs. At the budget tier, Gemini Flash-Lite at $0.10 per million tokens competes with GPT-4o Mini, offering similar value at the lower end of the market.
What are Gemini API rate limits?
Rate limits depend on your billing tier and the specific model you are using. Free tier provides 5-15 RPM and 100-1,000 RPD, which is sufficient for development and testing but will throttle production applications under moderate load. Tier 1, which activates simply by setting up any paid billing account with no minimum spend required, offers 150-300 RPM depending on the model. Tier 2 requires at least $250 in accumulated spend over 30 days and unlocks 1,000+ RPM, which is where most production applications with real user traffic need to operate. Tier 3 at $1,000+ spend provides the highest limits suitable for enterprise-scale deployments and high-traffic applications that serve thousands of concurrent users.
How can I reduce Gemini API costs?
The three most effective strategies are context caching (saves up to 90% on repeated input tokens), Batch API (flat 50% discount for non-urgent requests), and smart model selection (using Flash-Lite at $0.10/M instead of Pro at $1.25/M saves 92% per token). Combining these strategies can reduce total API costs by 70-90%.
Does Gemini API pricing change for long context?
Yes, Pro models charge double rates for context lengths exceeding 200,000 tokens. Gemini 2.5 Pro input pricing increases from $1.25 to $2.50 per million tokens, and output from $10.00 to $15.00. Flash models do not currently have context-length-based pricing tiers.
Getting Started with Gemini API
Getting started with the Gemini API is straightforward and takes just a few minutes. Visit the Google AI Studio at ai.google.dev to create your API key, which gives you immediate free tier access to six models without any billing setup required. The quickest way to experiment is through the AI Studio web interface, which lets you test prompts against different models and compare outputs before writing any code.
For programmatic access, Google provides official client libraries for Python, JavaScript, Go, and several other languages, all available through their respective package managers. A basic Python implementation requires installing the google-generativeai package with pip and then just three lines of functional code: configure your API key, create a model instance, and call generate_content with your prompt. The response object includes the generated text along with metadata about token usage, which is invaluable for cost tracking from the very beginning. Start with Gemini 2.5 Flash for most use cases as it offers the best balance of speed, capability, and cost at just $0.30 per million input tokens. As your usage grows and requirements become clearer, you can upgrade to Pro models for specific tasks, implement caching strategies for frequently repeated contexts, and scale through the paid tier system as your request volume increases.
Once your initial setup is complete and running, the recommended next steps are to benchmark your specific use case across two or three models to find the cost-to-quality sweet spot for your particular prompts and requirements. Different models exhibit varying strengths depending on the task type, so empirical testing with your actual data is far more reliable than relying on general benchmarks. Implement basic cost tracking from day one so you have clear visibility into spending patterns across all your API calls, and set up billing alerts before enabling paid tier access to prevent unexpected and potentially significant charges.
Building a cost-effective AI application is not a one-time optimization exercise but an ongoing process of monitoring, measuring, and adjusting. As Google continues to release new models and adjust pricing, staying informed about the latest changes ensures you are always using the most cost-effective options available. The Gemini ecosystem moves quickly, with new model releases, pricing updates, and feature additions happening regularly. By combining the pricing knowledge from this guide with a methodical approach to model selection, cost monitoring, and continuous optimization, you can build powerful AI-powered applications that deliver exceptional value while keeping costs firmly under control.