
Choosing between Gemini, OpenAI, and Claude APIs in 2026 comes down to three factors: what you're building, how much you can spend, and which trade-offs you can live with. As of February 2026, GPT-5 and Gemini 2.5 Pro share identical flagship pricing at $1.25 per million input tokens, while Claude Opus 4.6 commands a premium at $5.00 but leads developer benchmarks like SWE-bench. This guide breaks down every pricing tier, walks through real cost scenarios, and gives you a decision framework based on verified data from official sources.
TL;DR
The AI API landscape has converged on pricing while diverging on capabilities. GPT-5 delivers the strongest general reasoning and math performance, scoring a perfect 100% on AIME 2025 and processing tokens at 187 tokens per second. Claude Opus 4.6 dominates coding benchmarks with an 80.9% score on SWE-bench Verified and excels at agentic, multi-step tasks. Gemini 2.5 Pro offers the largest context window at 1 million tokens and matches GPT-5's pricing at $1.25/$10.00 per million tokens, making it the clear choice for long-document processing. For budget-conscious developers, both GPT-4o mini and Gemini 2.5 Flash cost just $0.15/$0.60 per million tokens, delivering remarkable capability at a fraction of flagship prices.
Performance Showdown — Benchmarks That Actually Matter
Performance benchmarks can be misleading if you look at the wrong ones. A model that aces academic math might stumble on real-world coding tasks, and a benchmark leader in multiple-choice questions might produce slow, expensive output in production. The benchmarks that matter most to developers in 2026 are SWE-bench Verified for coding ability, AIME for mathematical reasoning, MMLU for general knowledge, and raw throughput speed for latency-sensitive applications. Understanding these numbers in context, rather than taking leaderboard positions at face value, is what separates informed API selection from marketing-driven decisions.
The coding benchmark that draws the most attention from engineering teams is SWE-bench Verified, which tests a model's ability to resolve real GitHub issues from popular open-source repositories. As of February 2026, Claude Opus 4.5 holds the top position at 80.9%, followed by Gemini 3 Pro at 76.8% and GPT-5.2 at 74.9% (humai.blog, February 2026). This roughly 6-percentage-point gap between Claude and GPT-5 is significant for teams building AI-assisted development tools, code review systems, or autonomous coding agents. Claude's dominance on SWE-bench reflects Anthropic's deliberate focus on agentic coding capabilities, and it shows in practice: Claude Code, Anthropic's CLI tool, consistently handles multi-file refactors and complex debugging sessions that other models struggle with. For teams where coding quality is the primary concern, this benchmark advantage translates directly into fewer review cycles, less manual correction, and higher developer trust in AI-generated code. You can explore the Claude Opus vs Sonnet comparison for more details on how Anthropic's models differ within their own lineup.
On the mathematical reasoning front, GPT-5.2 achieved a perfect 100% on AIME 2025, a result that no other model has matched (multiple sources, February 2026). This is not just an academic curiosity: strong math performance correlates with better performance on structured reasoning tasks, data analysis, financial modeling, and any application where logical deduction matters. Gemini 2.5 Pro performs well on math benchmarks too, though exact AIME scores are less widely reported. Claude's math performance is solid but not its headline strength, with Claude Opus scoring approximately 95.4% on GSM8K compared to GPT-5's 96.8%. For applications like automated financial analysis, scientific computation, or educational tutoring, GPT-5's mathematical edge is worth the comparable price point.
General knowledge performance, measured by MMLU (Massive Multitask Language Understanding), has reached a point where all three flagship models perform within a few percentage points of each other. GPT-5 scores approximately 94.2%, Claude Opus 4.5 hits 93.8%, and Gemini 2.5 Pro comes in around 92% (humai.blog, February 2026). These differences are small enough that MMLU alone should not drive your API choice. What MMLU does tell us is that all three providers have achieved a level of general knowledge competence where the differentiator is no longer "which model knows more" but rather "which model applies that knowledge most effectively for your specific task." The convergence on general benchmarks makes the divergence on specialized benchmarks like SWE-bench and AIME more meaningful, because they reveal the genuine architectural and training differences between the models rather than just scale advantages.
Speed matters enormously in production environments where users are waiting for responses. GPT-5.2 leads the field at approximately 187 tokens per second, making it roughly 3-4 times faster than Claude Opus at around 50 tokens per second (humai.blog, February 2026). Gemini Flash models offer exceptional latency at around 650 milliseconds average response time for shorter queries. When you are building a chatbot, real-time coding assistant, or any user-facing application where perceived responsiveness affects user satisfaction, these speed differences compound over millions of requests. OpenAI's speed advantage is one of its strongest selling points for latency-sensitive deployments, while Claude's slower output is often acceptable for background processing tasks like code generation, document analysis, and batch content creation. In practice, many teams find that a 3-4x speed difference matters less than you might expect, because the bottleneck in most applications is network latency and response parsing rather than raw token generation speed. However, for streaming applications where users watch text appear character by character, the difference between 50 and 187 tokens per second creates a noticeably different user experience.
The overall benchmark picture paints a clear story of specialization rather than general dominance. No single model wins across all dimensions. The following summary captures the key competitive advantages:
| Category | Leader | Score / Metric | Runner-Up |
|---|---|---|---|
| Coding (SWE-bench) | Claude Opus 4.5 | 80.9% | Gemini 3 Pro (76.8%) |
| Math (AIME 2025) | GPT-5.2 | 100% | Claude Opus (~95%) |
| General Knowledge (MMLU) | GPT-5 | 94.2% | Claude Opus (93.8%) |
| Speed (tok/s) | GPT-5.2 | 187 tok/s | Claude (~50 tok/s) |
| Context Window | Gemini 2.5 Pro | 1M tokens | GPT-5 (400K) |
This specialization is exactly why the multi-model routing strategy described in the cost optimization section is so effective: you can get the best model for each category of task without paying flagship prices for everything.
Complete API Pricing Breakdown (February 2026)

Pricing is where the 2026 AI API market tells its most interesting story. Two years ago, there were massive gaps between providers. Today, the flagship tier has largely converged while budget tiers have become remarkably affordable, creating a two-speed market that savvy developers can exploit. All prices below are per million tokens and were verified against official pricing pages and Google Search results on February 26, 2026.
Flagship Tier
The flagship tier is where you get the best reasoning, the most capable coding, and the highest accuracy on complex tasks. GPT-5 and Gemini 2.5 Pro are now priced identically at $1.25 input and $10.00 output per million tokens, which represents a dramatic price reduction from earlier generations. Claude Opus 4.6, at $5.00 input and $25.00 output, costs 4x more on input and 2.5x more on output compared to its direct competitors. This premium buys you the best coding performance available, as discussed in the benchmarks section, but it means you need to be strategic about when you deploy it. A reasonable approach is to reserve Claude Opus for complex coding and agentic tasks where its SWE-bench advantage justifies the cost, and use GPT-5 or Gemini Pro for general reasoning tasks where all three models perform comparably. It is worth noting that Gemini 2.5 Pro uses tiered pricing: requests under 200K tokens get the $1.25/$10.00 rate, while longer context requests above 200K tokens jump to $2.50/$15.00. For a deep dive into Claude's pricing structure and subscription options, see our detailed Claude pricing and subscription guide.
Mid-Range Tier
The mid-range tier offers an excellent balance of capability and cost for production workloads that need better-than-budget performance without flagship expense. Claude Sonnet 4.6 sits at $3.00/$15.00 per million tokens and delivers near-Opus coding quality, which is why many development teams use Sonnet as their default model and only escalate to Opus for the hardest problems. GPT-4o at $2.50/$10.00 remains a strong general-purpose option with its well-established ecosystem of tools and integrations. GPT-4.1 and the o3 reasoning model both price at $2.00/$8.00, offering specialized capabilities in extended context (1M for GPT-4.1) and structured reasoning (o3) respectively. This tier is where most production applications should start, as the quality-to-cost ratio is significantly better than flagship models for the majority of use cases.
Budget Tier and Free Access
The budget tier has become the most exciting part of the 2026 API landscape. GPT-4o mini and Gemini 2.5 Flash both cost $0.15 input and $0.60 output per million tokens, making them approximately 8x cheaper than flagships on input and 17x cheaper on output. At these prices, you can process enormous volumes of text for pennies. Claude Haiku 4.5 at $1.00/$5.00 is significantly more expensive than the other budget options but still much cheaper than mid-range models. For high-volume tasks like content classification, sentiment analysis, data extraction, and simple question-answering, budget models deliver surprisingly good results. The key distinction at this tier is context window: Gemini 2.5 Flash offers a full 1 million token context window, while GPT-4o mini is limited to 128K tokens. If you need to process long documents cheaply, Gemini Flash is the clear winner.
Free tiers also matter for prototyping and for indie developers building side projects. Google offers the most generous free tier for Gemini, with 1,500 requests per day on Gemini 2.5 Flash through Google AI Studio, which is enough to build and test a real application without spending anything. For more details on maximizing this, check out our guide on Gemini's generous free tier. OpenAI provides limited free credits for new accounts but no ongoing free tier for API access. Anthropic offers minimal free access through their API, though the Claude.ai web interface has a free tier for personal use. For developers in the experimentation phase, starting with Gemini's free tier to validate your idea before committing budget to any provider is a practical and risk-free approach. DeepSeek also deserves mention in the budget conversation: DeepSeek R1 at $0.55/$2.19 and DeepSeek V3.2 at $0.27/$1.10 per million tokens offer competitive reasoning capabilities at prices that undercut even the major providers' budget models, though availability and rate limits can be less predictable than the Big Three. The budget tier's overall message is clear: you no longer need to spend flagship money to get genuinely useful AI capabilities, and the 66x price difference between Claude Opus output tokens and Gemini Flash output tokens means that model routing is not just a nice optimization but an economic imperative.
What 10,000 API Calls Actually Cost You
Abstract per-token pricing becomes meaningful only when you translate it into real monthly bills for your specific use case. The following scenarios use consistent assumptions: each API call averages 2,000 input tokens and 500 output tokens, which is typical for a conversational application with moderate context. These calculations use official pricing verified on February 26, 2026, and cover three common developer profiles: the indie builder, the startup team, and the enterprise deployment.
The Indie Developer (10,000 calls per day) is building a side project or early-stage product, processing roughly 300,000 calls per month. With GPT-4o mini or Gemini 2.5 Flash at the budget tier, this costs approximately $0.30 per day in input ($0.15 x 20M tokens / 1M) plus $0.30 per day in output ($0.60 x 0.5M tokens / 1M), totaling roughly $0.60 per day or $18 per month. The same workload on GPT-5 costs approximately $2.50 input plus $5.00 output, or $7.50 per day and $225 per month. On Claude Opus 4.6, the cost jumps to $10.00 input plus $12.50 output, or $22.50 per day and $675 per month. The difference between $18/month on a budget model and $675/month on Claude Opus is enormous for an indie developer. This is precisely why model routing, which we will cover in the cost optimization section, is not optional but essential for anyone building on a budget.
The Startup Team (100,000 calls per day) is running a production application with real users. At 3 million calls per month, budget models cost roughly $180 per month, GPT-5 costs $2,250 per month, and Claude Opus costs $6,750 per month. Most startups in this range use a mixed strategy: route 70-80% of traffic through budget models for simple tasks (classification, basic Q&A, data extraction), 15-20% through mid-range models for standard reasoning, and only 5-10% through flagship models for complex tasks requiring top-tier quality. A startup using this 70/20/10 routing strategy with Gemini Flash, GPT-4o, and Claude Sonnet would pay approximately $180 (Flash) + $450 (4o) + $338 (Sonnet) = roughly $968 per month, compared to $6,750 if everything went through Claude Opus. That is an 86% cost reduction with minimal quality impact on the tasks that are routed to cheaper models.
The Enterprise Deployment (1,000,000+ calls per day) is operating at scale where every fraction of a cent per call matters. At 30 million calls per month, the bill on budget models is approximately $1,800/month, on GPT-5 it is $22,500/month, and on Claude Opus it is $67,500/month. Enterprise teams almost universally implement sophisticated model routing, prompt caching, and batch processing. A well-optimized enterprise deployment can typically reduce costs by 70-90% compared to naive single-model usage. The difference between a $67,500 and a $6,750 monthly bill is the difference between an AI initiative that gets greenlit and one that gets killed in budget review.
The following table summarizes monthly costs across all three scenarios and model tiers, giving you a quick reference for budget planning. All calculations assume the same 2,000 input / 500 output token average per call:
| Scenario | Daily Calls | Budget Model | GPT-5 | Claude Opus 4.6 | Mixed Routing |
|---|---|---|---|---|---|
| Indie Developer | 10,000 | $18/mo | $225/mo | $675/mo | ~$45/mo |
| Startup Team | 100,000 | $180/mo | $2,250/mo | $6,750/mo | ~$968/mo |
| Enterprise | 1,000,000 | $1,800/mo | $22,500/mo | $67,500/mo | ~$6,750/mo |
The "Mixed Routing" column assumes the 70/20/10 split described in the startup scenario above, where 70% of traffic goes to budget models, 20% to mid-range, and 10% to flagship. These numbers demonstrate why cost optimization is not a luxury but a necessity: without routing, even moderate-scale applications quickly accumulate bills that are difficult to justify to stakeholders. The gap between naive and optimized deployment is often the difference between a viable AI product and one that cannot sustain its own infrastructure costs.
How to Cut Your AI API Bill by 50% or More
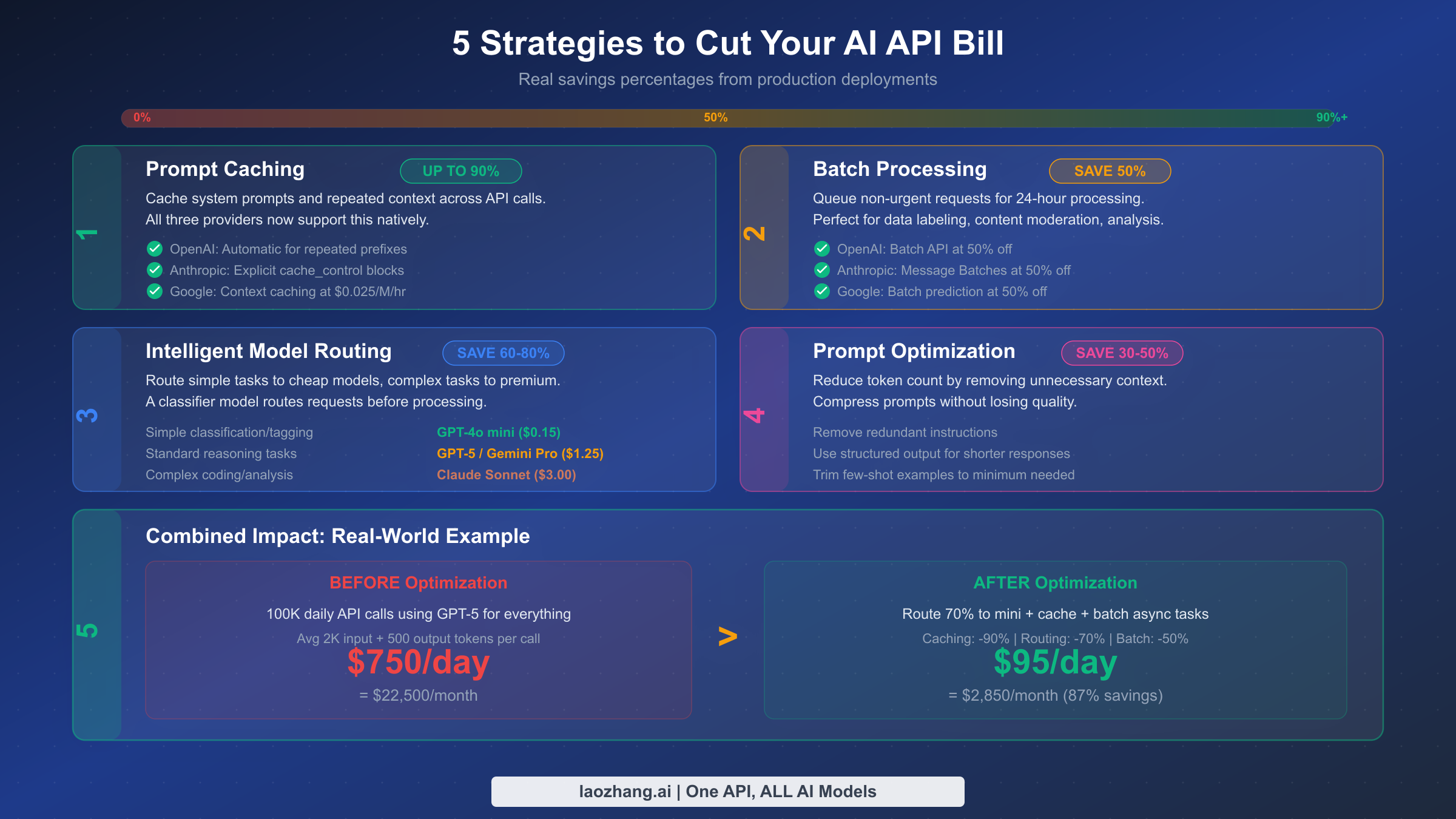
Cost optimization is not about being cheap; it is about being smart with your budget so you can afford to use AI at the scale your application demands. The five strategies below are ranked by potential savings, and combining them can reduce your total API spend by 70-90% without meaningful quality degradation. These are the same techniques used by companies processing millions of API calls daily, and they are accessible to teams of any size.
Prompt caching delivers the highest individual savings, up to 90% on cached tokens. All three providers now support this natively, though implementation details differ. OpenAI automatically caches repeated prompt prefixes, which means you get savings without code changes if your system prompts are consistent across calls. Anthropic uses explicit cache_control blocks that give you fine-grained control over what gets cached but require deliberate implementation. Google charges $0.025 per million tokens per hour for context caching, making it cost-effective for applications that repeatedly process the same long documents. If your application sends the same system prompt or context prefix on every call, which most applications do, prompt caching should be the first optimization you implement. The setup takes less than an hour and the payoff is immediate. For teams processing a 4,000-token system prompt across 100,000 daily calls, caching saves approximately $500/month on GPT-5 pricing alone. For more on managing API usage efficiently, see our guide on Gemini API rate limits in detail.
Intelligent model routing is the second most impactful strategy, delivering 60-80% savings by directing each request to the cheapest model capable of handling it. The concept is straightforward: a lightweight classifier (which can itself be a budget model) examines each incoming request and routes simple tasks like classification, extraction, and basic Q&A to GPT-4o mini or Gemini Flash at $0.15 per million input tokens, routes standard reasoning tasks to GPT-4o or Gemini Pro at the mid-range tier, and reserves complex coding, multi-step reasoning, and nuanced analysis for Claude Sonnet or Opus. In practice, 60-80% of requests in most applications are simple enough for budget models, which means you are paying budget prices for the majority of your traffic. The classifier itself adds minimal cost, perhaps $0.01-0.02 per request on a budget model, and the routing decision typically adds less than 100ms of latency.
Batch processing cuts costs by 50% for any request that does not need an immediate response. All three providers offer batch APIs: OpenAI's Batch API, Anthropic's Message Batches, and Google's batch prediction all provide a flat 50% discount in exchange for 24-hour processing windows. This is perfect for data labeling, content moderation, document analysis, and any background processing task. If 30% of your workload can tolerate delayed responses, batch processing alone saves 15% on your total bill.
Prompt optimization reduces your token consumption by 30-50% by eliminating unnecessary context, streamlining instructions, and using structured output formats. Common wins include replacing verbose system prompts with concise ones, trimming few-shot examples to the minimum needed for quality, using JSON output format to reduce response verbosity, and breaking complex prompts into focused sub-tasks that each use fewer tokens. A well-optimized prompt that achieves the same quality in 800 tokens as a naive prompt at 2,000 tokens saves 60% on that call.
Combining all four strategies produces dramatic results. Consider a real-world scenario: a company processing 100,000 API calls per day using GPT-5 for everything, averaging 2,000 input tokens and 500 output tokens per call. Without optimization, this costs approximately $750 per day or $22,500 per month. After implementing prompt caching on the system prompt (90% savings on cached portion), routing 70% of requests to budget models, batching 20% of non-urgent tasks, and optimizing prompts by 30%, the same workload costs approximately $95 per day or $2,850 per month, an 87% reduction. The optimization effort takes a few weeks of engineering time but pays for itself within the first month.
Developer Experience — From SDK to Production
The developer experience of integrating an AI API extends far beyond pricing and benchmarks. It encompasses SDK quality, documentation clarity, error handling, rate limit transparency, and the broader ecosystem of tools and community support. When you are evaluating these APIs for a production application, the friction of integration and maintenance often matters as much as raw model capability, because a model that is hard to use correctly will cost you in developer time what it saves in token pricing.
OpenAI's developer ecosystem is the most mature and extensive of the three providers. The Python SDK (openai) and Node.js SDK are well-maintained, thoroughly documented, and widely adopted. The API design follows a consistent pattern that is easy to learn and hard to misuse, with features like function calling, structured outputs, and streaming implemented cleanly. OpenAI's documentation is comprehensive and includes a playground for experimentation, a cookbook repository with practical examples, and an active developer forum. The sheer volume of third-party tutorials, Stack Overflow answers, and open-source integrations means that virtually any integration challenge you encounter has been solved by someone before you. Rate limits are clearly documented and error messages are descriptive, making debugging straightforward. The main criticism from developers is the pace of API changes, with model deprecations and parameter changes requiring occasional migration work, though OpenAI has improved its deprecation timeline communication significantly in 2025-2026.
Anthropic's Claude API has matured significantly and now rivals OpenAI's developer experience in most areas. The Python SDK is clean and well-documented, with particularly strong support for streaming, tool use, and the Messages API format. Anthropic's documentation is excellent, arguably the most technically precise of the three providers, with clear explanations of concepts like context window management, cache control, and system prompt best practices. Where Anthropic truly excels is in the developer tooling surrounding the API: Claude Code, the CLI-based coding assistant, provides a reference implementation for agentic AI that many teams adapt for their own use cases. The API's extended thinking feature, which exposes the model's chain-of-thought reasoning, is unique and valuable for debugging complex outputs. The developer community is smaller than OpenAI's but highly engaged, particularly among teams building agentic applications and coding tools. The most common developer complaint about Anthropic is rate limits during peak usage, though this has improved throughout 2025-2026.
Google's Gemini API offers the most generous free tier and the deepest integration with Google's cloud ecosystem. The Python SDK supports both the Google AI Studio (for experimentation and prototyping) and Vertex AI (for production) interfaces, and the transition between them is relatively smooth. Gemini's standout developer feature is its 1-million-token context window, which eliminates the need for complex chunking and retrieval strategies that other providers require for long-document processing. The API supports multimodal input natively, accepting text, images, audio, and video in a single request, which simplifies development of multimodal applications. Google's documentation is comprehensive but can be harder to navigate than Anthropic's or OpenAI's due to the broader cloud platform context. The developer community is growing rapidly, and Google's AI Studio playground provides an excellent experimentation environment. The main friction point for developers is the occasional confusion between AI Studio and Vertex AI pricing, capabilities, and rate limits, which are not always clearly delineated in documentation.
All three providers support streaming responses, function calling (tool use), structured JSON output, and system-level instructions. The code patterns are similar enough that switching between providers or implementing multi-provider routing is straightforward, typically requiring only changes to the client initialization and minor prompt adjustments. Here is a minimal example showing how similar the three APIs look in practice:
pythonfrom openai import OpenAI client = OpenAI(api_key="sk-...") response = client.chat.completions.create( model="gpt-5", messages=[{"role": "user", "content": "Explain quantum computing"}] ) # Anthropic from anthropic import Anthropic client = Anthropic(api_key="sk-ant-...") response = client.messages.create( model="claude-opus-4-6-20260214", max_tokens=1024, messages=[{"role": "user", "content": "Explain quantum computing"}] ) # Google Gemini import google.generativeai as genai genai.configure(api_key="AIza...") model = genai.GenerativeModel("gemini-2.5-pro") response = model.generate_content("Explain quantum computing")
The convergence in API design means your choice should be driven primarily by model capability and pricing rather than SDK differences. Any competent development team can integrate any of these APIs in a day or two of work.
One important consideration that often gets overlooked in API comparisons is error handling and reliability in production. OpenAI's API returns detailed error codes with clear remediation steps, and their rate limit headers make it easy to implement adaptive throttling. Anthropic's error responses are similarly well-structured, with explicit overload signals that help you implement graceful degradation. Google's Gemini API error handling is adequate but occasionally less descriptive, particularly when errors originate from the underlying Vertex AI infrastructure. All three providers experience occasional outages and degraded performance, which is why production applications should implement retry logic with exponential backoff as a baseline. Beyond individual provider reliability, this is another strong argument for multi-provider architectures: if one provider experiences an outage, your application can automatically route traffic to an alternative model, maintaining service availability even during infrastructure incidents. The operational resilience of a multi-model architecture is a benefit that does not show up in benchmarks or pricing tables but matters enormously when your application has paying users depending on it.
Which API Should You Choose? A Decision Framework
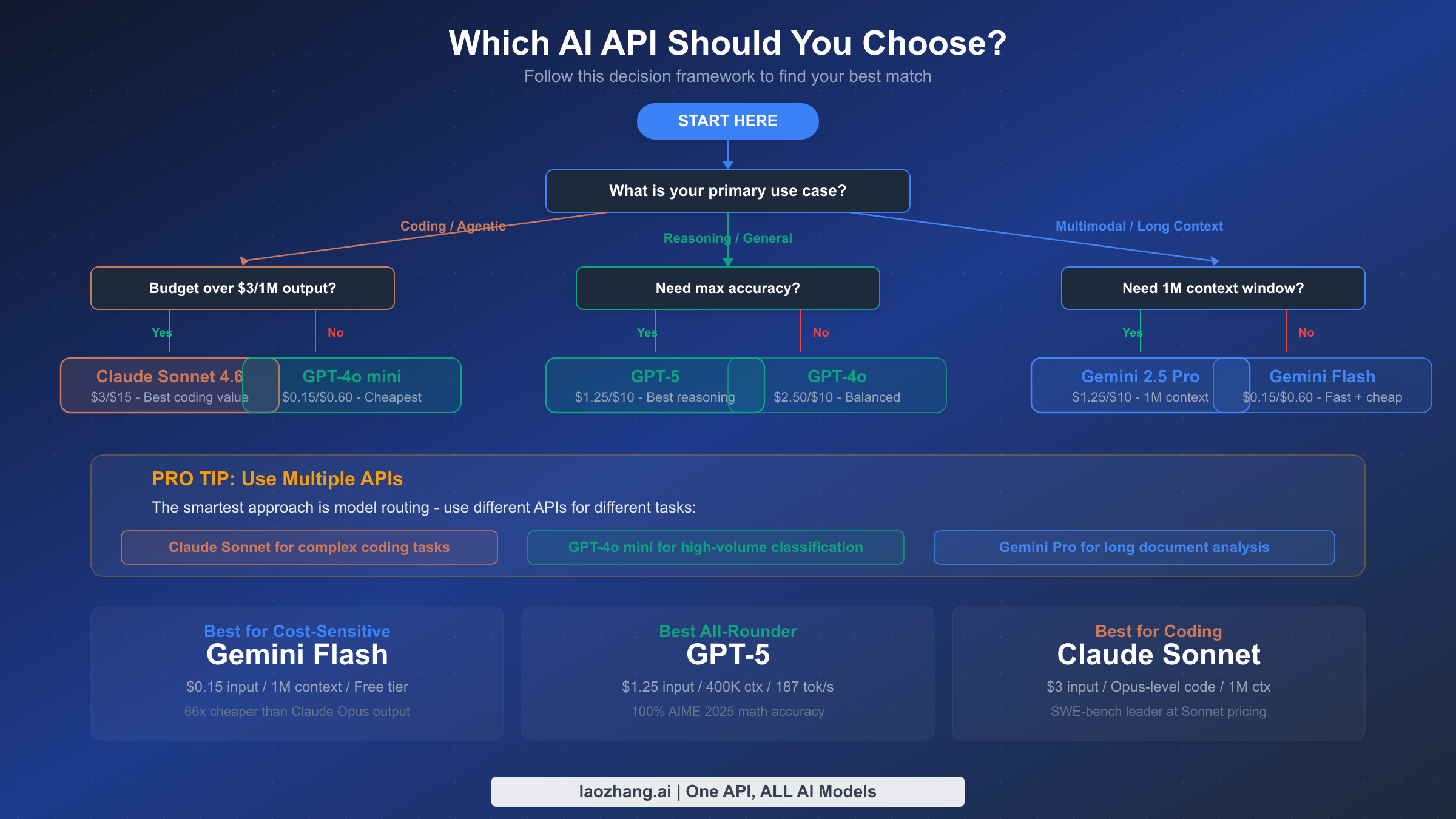
Rather than declaring one API "the best," the most useful approach is a decision framework that matches your specific needs to the right provider. The framework below walks through use case, budget constraints, and scaling considerations to arrive at a clear recommendation. This is the same methodology used by engineering teams at companies that process millions of API calls daily, adapted for developers at any scale.
Start with your primary use case. If your core need is coding assistance, code generation, or agentic multi-step tasks, Claude is your strongest option. Claude Sonnet 4.6 at $3.00/$15.00 delivers excellent coding performance at a reasonable price point, and you can escalate to Opus 4.6 for the most challenging problems. The SWE-bench gap between Claude and its competitors is wide enough to justify the premium for coding-centric workloads. If your primary need is general reasoning, question answering, mathematical analysis, or broad-capability tasks, GPT-5 at $1.25/$10.00 offers the best value: top-tier reasoning, the fastest output speed at 187 tokens per second, and the most mature ecosystem. If your application processes long documents, handles multimodal input, or lives within the Google Cloud ecosystem, Gemini 2.5 Pro is the natural choice. Its 1-million-token context window at $1.25/$10.00 is unmatched by any competitor, and its multimodal capabilities for processing text, images, and video in a single call simplify development significantly.
Next, consider your budget constraints. If cost is your primary concern and you need to keep monthly spend under $100, Gemini 2.5 Flash and GPT-4o mini are your workhorses at $0.15/$0.60. Gemini Flash wins if you need long context; GPT-4o mini wins if you value OpenAI's ecosystem and documentation. If your budget allows $500-2,000 per month, the mid-range tier opens up: Claude Sonnet for coding, GPT-4o for general tasks, and you can afford to route a small percentage of traffic to flagship models for quality-critical requests. If budget is not a primary constraint, use model routing to get the best quality for each task type without overspending.
Finally, think about scaling trajectory. If you expect to grow from 10K to 100K to 1M+ daily calls, invest early in model routing infrastructure, prompt caching, and batch processing. The engineering effort you put into optimization at 10K calls pays dividends at 100K and becomes essential at 1M.
The most effective approach for most production teams in 2026 is not choosing one API but using all three strategically. Route complex coding to Claude Sonnet, high-volume classification to GPT-4o mini or Gemini Flash, long-document processing to Gemini Pro, and general reasoning to GPT-5. This multi-model strategy delivers the best quality per dollar spent, reduces single-provider risk, and positions your application to take advantage of improvements from any provider. The days of "pick one API and use it for everything" are over. The developers and companies getting the most value from AI in 2026 are the ones treating model selection as a runtime decision, not a one-time choice.
It is also worth considering the trajectory of each provider. OpenAI has the deepest enterprise relationships and the most aggressive model release cadence, which means their ecosystem tends to get new features first (like structured outputs, vision capabilities, and realtime APIs). Anthropic has focused intensely on safety and reliability, which matters for regulated industries like healthcare, finance, and legal. Google has the advantage of infrastructure integration: if you are already using Google Cloud, BigQuery, or Firebase, Gemini slots into your existing stack with minimal friction. These ecosystem factors often weigh more heavily in long-term platform decisions than any single benchmark score or pricing point, because switching costs accumulate over time as your codebase grows more integrated with a specific provider's tooling.
Frequently Asked Questions
Is GPT-5 API free to use? GPT-5 is not free through the API. OpenAI offers limited free credits for new accounts, but ongoing API usage requires a paid account. GPT-5 costs $1.25 per million input tokens and $10.00 per million output tokens (openai.com, February 2026). For free AI API access, Google's Gemini API offers the most generous free tier with up to 1,500 free requests per day on Gemini 2.5 Flash through Google AI Studio, making it a viable option for prototyping and low-volume applications without any payment.
Which AI API is cheapest for high-volume applications? For pure per-token cost, GPT-4o mini and Gemini 2.5 Flash are tied at $0.15 input and $0.60 output per million tokens as of February 2026. However, Gemini 2.5 Flash offers a 1-million-token context window compared to GPT-4o mini's 128K, making Flash more cost-effective for applications that process long documents. When you factor in optimization strategies like prompt caching (up to 90% savings), batch processing (50% discount), and model routing, total effective costs can drop by 70-90% regardless of which provider you start with.
How do Gemini, GPT, and Claude compare for coding tasks? Claude leads coding benchmarks decisively, with Claude Opus 4.5 scoring 80.9% on SWE-bench Verified compared to Gemini 3 Pro at 76.8% and GPT-5.2 at 74.9% (humai.blog, February 2026). For budget coding tasks, Claude Sonnet 4.6 at $3.00/$15.00 delivers near-Opus coding quality at a fraction of the cost. GPT-5 excels at mathematical reasoning within code (100% AIME 2025) but trails on complex multi-file software engineering tasks. Gemini performs well on coding but its primary advantage lies in processing large codebases through its 1M context window rather than raw code generation quality.
Can I use multiple AI APIs in the same application? Yes, and this is the recommended approach for production applications in 2026. Using multiple APIs through a routing strategy lets you assign each task to the most cost-effective model. Simple tasks go to budget models ($0.15/M input), complex coding goes to Claude, and general reasoning goes to GPT-5. Most companies processing over 100K daily API calls use some form of model routing to optimize costs and quality simultaneously.
What context window should I use? Context window requirements depend on your use case. For conversational chatbots and short-form tasks, 128K tokens (GPT-4o, GPT-4o mini) is more than sufficient. For document analysis and long-form content processing, Gemini 2.5 Pro and Flash offer 1 million tokens, eliminating the need for document chunking. Claude Sonnet 4.6 offers 1M tokens in beta, while Claude Opus 4.6 is limited to 200K. GPT-5 provides 400K tokens. If your application requires processing documents longer than 200K tokens, Gemini or Claude Sonnet are your only options among flagship and mid-range models.