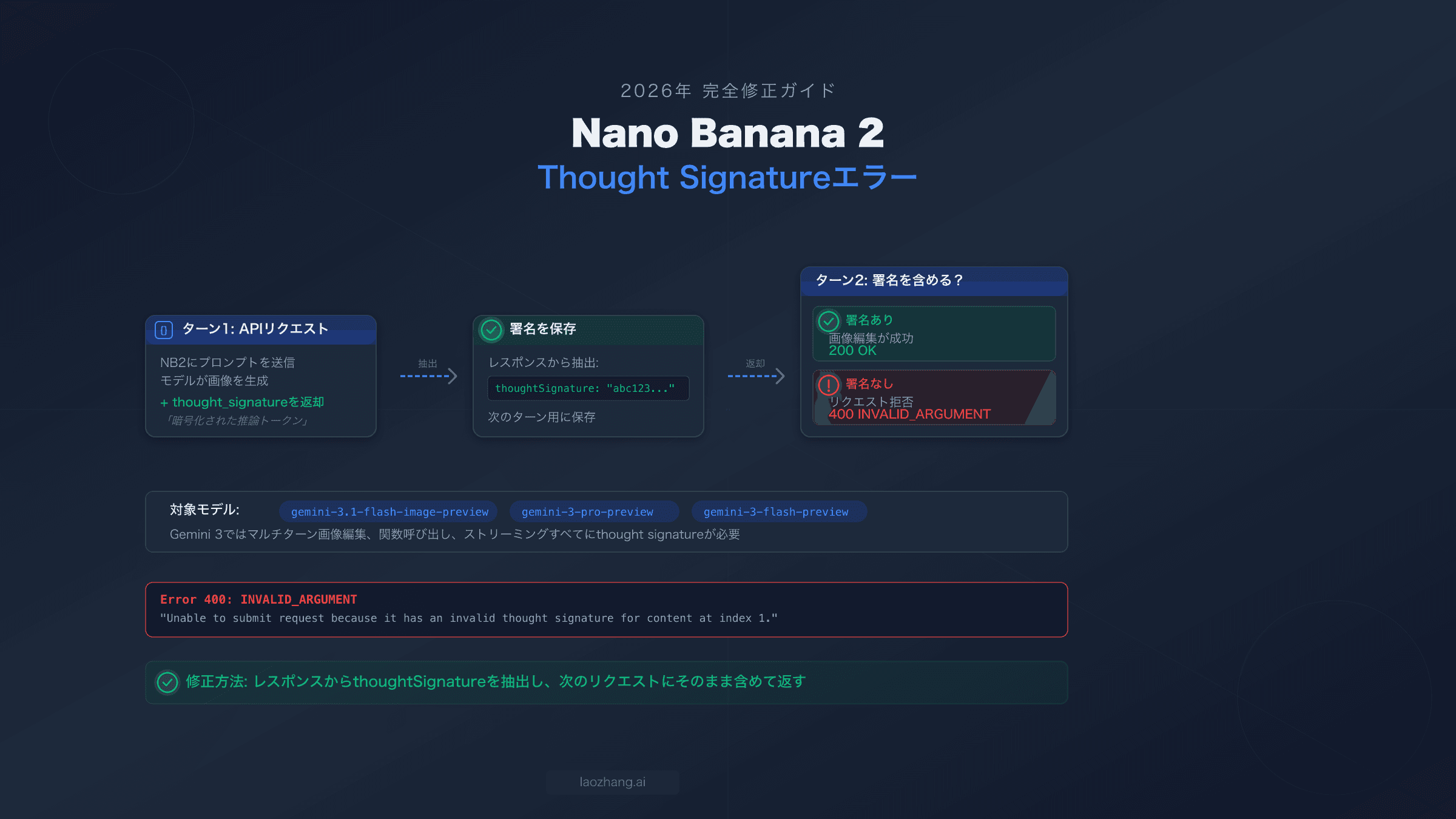
Gemini画像APIのエラーは3つのカテゴリに分類されます。429レート制限(請求上限ゼロ、IPM超過、Ghost Bug、Dynamic Shared Quotaが原因)、サイレント生成失敗(誤ったエンドポイント、responseModalities設定ミス、または請求未有効化)、パラメータの問題(imageConfigが無視される、大文字小文字を区別するimage_size、responseModalitiesにTEXTが欠如)です。まずGCPコンソールのクォータダッシュボードを確認し、次に請求が有効になっているか確認してください。無料ティアのIPMは2025年12月7日以降0になっています。正しい/v1beta/エンドポイントとresponseModalities: ["TEXT", "IMAGE"]を使用してください。
まとめ
3つのエラーカテゴリ、3つの診断パス。429エラーには4つの異なる根本原因があり、それぞれ異なる修正が必要です。どのタイプかを特定せずに「待ってリトライ」するだけでは解決しません。サイレント失敗(画像なしのHTTP 200)はほぼ必ずresponseModalitiesの設定ミスです。パラメータ失敗(設定は受け付けられるが無視される)は通常、image_sizeの大文字小文字の問題か、ミドルウェアによるimageConfigの除去です。まず請求を確認し、次にエンドポイントを確認し、その後パラメータを確認してください。この順番が重要です。
Gemini画像APIエラーの理解:診断マップ
Gemini画像生成が失敗する場合、開発者は通常3つの異なる障害モードのいずれかに直面します。それぞれまったく異なる診断アプローチが必要です。最初の障害モードはハードエラーで、API呼び出しがHTTP 429またはHTTP 400を返し、生成が始まる前にリクエストが拒否されます。2番目はサイレント失敗で、HTTP 200で呼び出しは成功しますが、レスポンスに画像データが含まれていません。3番目は設定の失敗で、画像は正常に生成されますが、出力が設定した内容と一致しない場合です。解像度が違う、アスペクト比が違う、または指定した設定とまったく異なる出力になります。
どの障害モードにいるかを理解することが最初の重要なステップです。誤って特定すると、間違った診断パスをたどることになり、時間を無駄にします。以下の表は各エラータイプをHTTPステータス、gRPCステータスコード、そしてこのガイドで扱う章にマッピングしています。
| エラータイプ | HTTPステータス | gRPCステータス | 典型的な症状 | 修正の章 |
|---|---|---|---|---|
| 請求上限 = 0 | 429 | RESOURCE_EXHAUSTED | 無料ティア、画像なし | 第2章 |
| IPMレート制限 | 429 | RESOURCE_EXHAUSTED | 生成後に失敗 | 第2章 |
| Ghost 429バグ | 429 | RESOURCE_EXHAUSTED | 請求アップグレード後 | 第2章 |
| Dynamic Shared Quota | 429 | RESOURCE_EXHAUSTED | プレビューモデルのトラフィック | 第2章 |
| 誤ったresponseModalities | 200 | — | 空のparts[]配列 | 第3章 |
| 誤ったエンドポイント | 404/400 | NOT_FOUND | サポートされていない操作 | 第3章 |
| 誤ったモデル名 | 400 | INVALID_ARGUMENT | モデルが見つからない | 第3章 |
| 請求未有効化 | 400 | FAILED_PRECONDITION | 明示的なエラーメッセージ | 第3章 |
| image_sizeの大文字小文字エラー | 200 | — | 誤った解像度の出力 | 第4章 |
| imageConfigが除去される | 200 | — | 設定がサイレントに無視される | 第4章 |
| TEXTモダリティが欠如 | 200 | — | 空のレスポンス | 第4章 |
画像固有でない一般的なGemini APIエラーについては、一般的なGemini APIエラートラブルシューティングガイドで非画像エラーの全範囲をカバーしています。この記事は画像生成に固有の3つのエラーカテゴリのみに焦点を当てています。Image APIには独自のクォータ次元(IPM — Images Per Minute)、独自の必須パラメータ、そしてテキスト生成には適用されない独自のモデルエンドポイントがあります。
最も重要な診断原則はこれです:429エラーを「待てば解決するレート制限」と決して思い込まないでください。4つのまったく異なる根本原因が同一の429レスポンスを生成します。待つことが正しい対応なのはそのうちの1つだけです。同様に、HTTP 200レスポンスが成功したことを意味するとも決して思い込まないでください。200は空のレスポンスを生成する設定エラーを隠すことがあります。
429エラー:4つの根本原因、4つの異なる修正
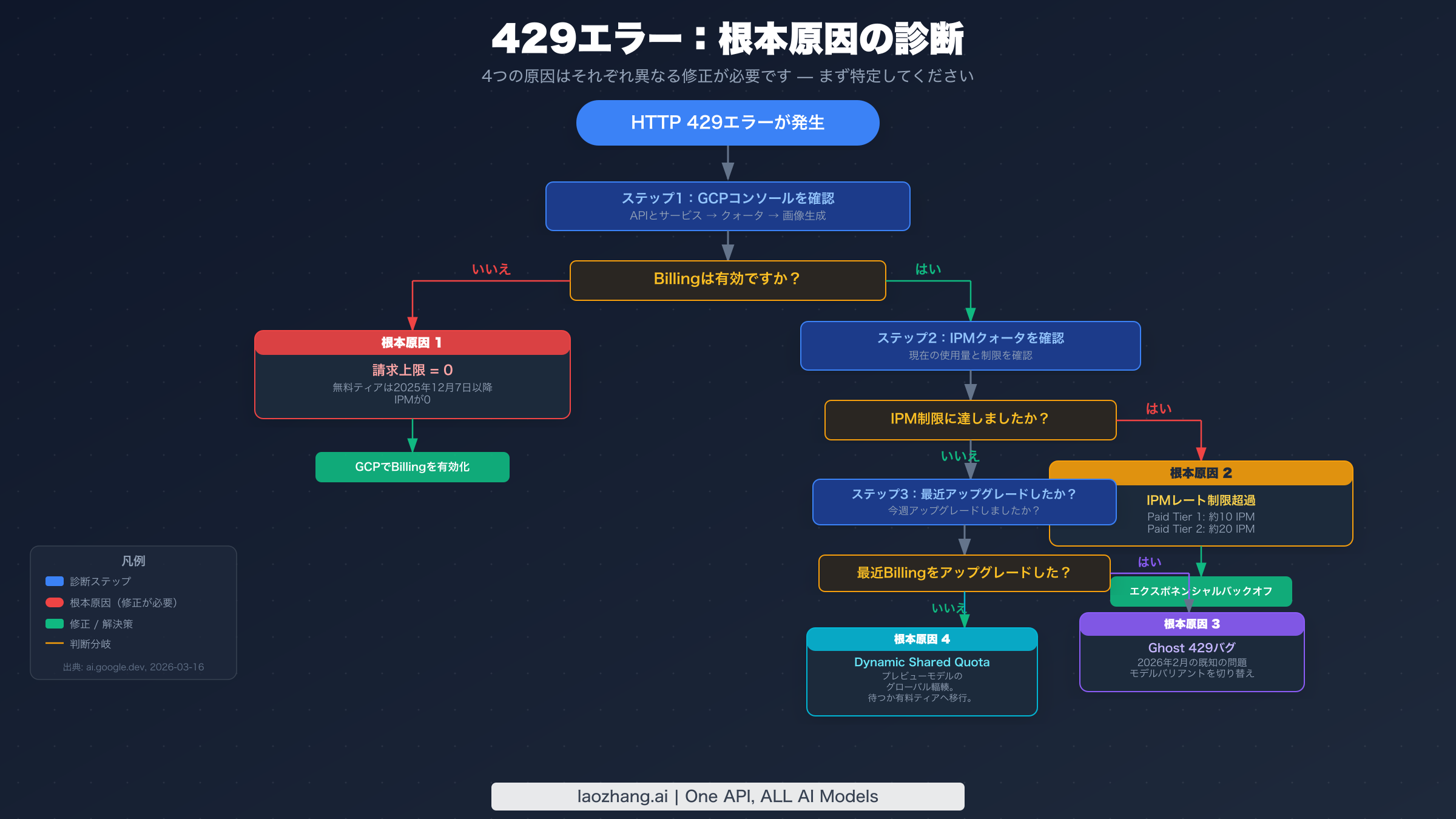
429 RESOURCE_EXHAUSTEDエラーはGemini画像APIで最も一般的なエラーですが、4つのまったく異なる問題のどれが引き起こしたとしても見た目が同一のため、誤解を招きます。すべてのGemini画像開発者がこれに遭遇し、オンラインのほぼすべてのリソースが「レート制限を超えた」という単一の問題として扱っています。その見方は時間の無駄につながります。4つの根本原因には4つのまったく異なる修正があり、間違った修正を適用しても解決しません。
根本原因1:請求上限 = 0(無料ティア)
新しい開発者にとって最も一般的な429の原因は最も単純なものです。無料ティアは2025年12月7日以降、画像ごとのクォータ(IPM)が正確にゼロになっています(Firebase AI Logicドキュメント、2026-03-16確認済み)。つまり、無料ティアアカウントはAPIを通じて画像を生成できません。低い制限ではなく、ゼロです。これに当たると、429は「制限を超えた」ではなく、制限がすでにゼロであることを伝えます。
これが問題かどうかを確認するには、GCPコンソール → APIとサービス → Generative Language API → クォータと制限に移動してください。「image」でフィルタリングして、IPM(Images Per Minute)クォータを確認してください。0が表示された場合は根本原因1です。修正方法は、Google CloudプロジェクトでBillingを有効にし、少なくともPaid Tier 1にアップグレードすることです。Billingを有効にするだけではクォータがすぐに復元されないことがあります。15〜30分の伝播遅延が生じる場合があります。
根本原因2:IPMレート制限超過(有料ティア)
Billingが有効になると、1分あたりの画像生成クォータが設定されます。Gemini画像429レート制限の詳細ガイドの検証済みデータによると、Paid Tier 1は約10 IPM(Images Per Minute)をサポートし、Paid Tier 2は約20 IPMをサポートします。これらはRPM(Requests Per Minute)とは別のものです。画像モデルには、画像生成呼び出しに特化して適用される独自のIPMクォータがあります。
根本原因2の診断上の特徴はパターンです。アプリケーションは最初は正常に動作しますが、短時間に複数の画像を生成した後に429エラーが発生し始めます。GCPコンソールのクォータダッシュボードでIPM制限に近づいているか到達していることが確認できます。修正方法はエクスポネンシャルバックオフです。最初の429の後に2秒の遅延から始め、リトライごとに倍増させます(2秒、4秒、8秒、16秒)。バッチ処理ジョブは、制限に当たってリアクティブにバックオフするのではなく、IPM制限内に収まるために必要な遅延を事前に計算すべきです。
根本原因3:Ghost 429バグ(2026年2月)
このバグは最近Billingティアをアップグレードしたアカウントに影響します。症状は、Billingのアップグレードが成功した後も429エラーが続くことです。GCPコンソールは非ゼロのIPMクォータを表示し、Billingは有効ですが、画像生成はまだ429を返します。Googleは2026年2月にAI Developers Forumでこれを既知の問題として確認しました。このバグはアカウントレベルのクォータ強制レイヤーに影響し、新しいクォータ割り当てが正しく伝播されません。
一時的な回避策は、別のモデルバリアントに切り替えることです。gemini-3.1-flash-image-previewを使用している場合はgemini-2.5-flash-imageに、またはその逆を試してみてください。多くの場合、これにより影響を受けたクォータ強制パスをバイパスできます。さらに、24〜48時間待つとクォータの伝播が完了して解決することが多いです。バグが続く場合は、Google Cloudに2026年2月のGhost 429問題を明示的に参照してサポートチケットを提出すると解決が加速します。
503オーバーロードエラー(類似して見えることがある)については、503オーバーロードエラーの修正ガイドを参照してください。
根本原因4:Dynamic Shared Quota(プレビューモデル)
プレビューモデル(gemini-3.1-flash-image-previewとgemini-3-pro-image-preview)は、本番モデルのようにプロジェクトごとのクォータ割り当てを使用しません。代わりに、Googleが「Dynamic Shared Quota」と呼ぶものを使用します。利用可能な容量はプレビューモデルのすべてのユーザーにグローバルに共有され、個々の使用量に関係なく、グローバルシステムの輻輳が高い場合に429エラーが発生します。Googleは2026年1月29日のsupport.google.comのサポートスレッドでこの動作を確認しました。
これは待つことが本当に正しい対応である唯一の根本原因です。429はあなたが何か間違ったことをしたからではなく、グローバルなプレビューモデルの容量が一時的に制限されているからです。より長い遅延のエクスポネンシャルバックオフ(2秒ではなく5秒から開始)がここでは有効です。信頼性要件のある本番アプリケーションでは、正しいアーキテクチャの対応はgemini-2.5-flash-imageのような本番モデルを使用するか、プロビジョンドスループットを持つVertex AIを使用することです。これにより共有プールではなく専用の容量が提供されます。
4つの429タイプのどれに当たっているかを特定する完全なエクスポネンシャルバックオフの実装を以下に示します。
pythonimport time import google.generativeai as genai def generate_image_with_backoff(prompt: str, max_retries: int = 5) -> dict: """Generate image with exponential backoff for 429 errors.""" client = genai.GenerativeModel("gemini-3.1-flash-image-preview") for attempt in range(max_retries): try: response = client.generate_content( contents=prompt, generation_config={ "responseModalities": ["TEXT", "IMAGE"], } ) return response except Exception as e: error_str = str(e) if "429" not in error_str and "RESOURCE_EXHAUSTED" not in error_str: raise # Not a rate limit error if attempt == max_retries - 1: raise # Exhausted retries # Exponential backoff: 2s, 4s, 8s, 16s, 32s delay = 2 ** (attempt + 1) print(f"429 on attempt {attempt + 1}, waiting {delay}s...") time.sleep(delay) raise Exception("Max retries exceeded")
画像生成が何も返さない:サイレント失敗の修正
サイレント失敗はGemini画像エラーの中で最も厄介なタイプです。なぜなら、実行可能なフィードバックがまったく得られないからです。API呼び出しはHTTP 200(成功)を返し、レスポンスは有効なJSONですが、画像データを探すとparts配列が空か、テキストのみが含まれています。例外はスローされず、何が間違っているかを説明するエラーメッセージもありません。このカテゴリの失敗には4つの異なる原因があり、それぞれ異なる調査が必要です。
最も一般的な原因:responseModalitiesの設定ミス
最も頻繁なサイレント失敗は、設定の1つの単語が欠けていることから来ます。Gemini Image APIはresponseModalitiesに"TEXT"と"IMAGE"の両方を含める必要があります。["IMAGE"]のみを含めると、HTTPレスポンスは200成功でpartsが空の配列になります。エラーはスローされません。APIはリクエストを受け付け、処理し、なぜかを伝えずに何も有用なものを返しません。
この要件は公式Gemini画像生成ドキュメント(ai.google.dev/gemini-api/docs/image-generation、2026-03-16確認済み)に記載されていますが、非公式のソースからの例が["IMAGE"]のみを示していたり、"IMAGE"モダリティを指定すれば十分だと思い込む開発者が多いため、多くの開発者がこれに遭遇します。正しい設定:
pythongeneration_config = { "responseModalities": ["TEXT", "IMAGE"], # Both required "imageConfig": { "image_size": "1K" # Note: uppercase K } }
なぜTEXTが必要なのでしょうか?Geminiイメージモデルはマルチモーダルとしてデザインされています。画像と一緒にテキストレスポンス(通常は説明やキャプション)を生成します。APIはこのデュアル出力モデルに基づいて構築されており、responseModalitiesからTEXTを省略してテキスト出力を抑制しようとすると、画像のみの出力を返すのではなく、レスポンス全体が失敗します。TEXTをモダリティリストに含めずに画像のみの出力を得る方法は現在ありません。
誤ったAPIエンドポイント
一部の開発者はOpenAI互換クライアントを通じてGemini画像生成を統合するか、/v1beta/の代わりに/v1/エンドポイントを使用します。Gemini画像生成APIには/v1beta/エンドポイントパスが必要です。OpenAI互換エンドポイント(/v1/images/generations)または安定版/v1/パスへのリクエストは、404エラーまたは明示的な「サポートされていない操作」メッセージを返します。
正しいエンドポイント構造:
POST https://generativelanguage.googleapis.com/v1beta/models/{model-name}:generateContent
GeminiでOpenAI互換ライブラリを使用している場合は、ベースURLが正しく設定されていることを確認してください。Geminiでopenai Pythonライブラリを使用している開発者の多くは、base_urlをGeminiのサーバーを指すように変更しますが、/v1/パスを指している場合、画像モデルにアクセスできません。
誤ったモデル名
3つの現在のGemini画像モデルには、ドキュメントに記載されているとおりに使用する必要がある特定の名前があります。執筆時点(ai.google.dev、2026-03-16確認済み)での現在のモデル名:
gemini-3.1-flash-image-preview— 高速生成、プレビューモデルgemini-3-pro-image-preview— 高品質、プレビューモデルgemini-2.5-flash-image— 効率的、安定版モデル
一般的な間違いには、gemini-2.5-flash-preview-image(サフィックスの順序が違う)、gemini-flash-image(バージョンが欠如)、または非推奨になった古いモデル名の使用が含まれます。モデル名のエラーは通常400 INVALID_ARGUMENTまたは404 NOT_FOUNDを返します。これらは通常レート制限とは異なるエラーシグネチャを持つサイレントな200レスポンスを生成しません。
Billingが有効になっていない:設定エラーと間違えやすい400
Billingが有効になっていない場合、無料ティアのゼロクォータ制限を超えると、明確なエラーが期待されるかもしれません。Gemini Image APIは実際にHTTP 400とgRPCステータスFAILED_PRECONDITIONを返し、「billing」を含むメッセージが表示されます。これは、Billingが有効でクォータが使い果たされた場合に受け取る429とは異なります。FAILED_PRECONDITIONステータスは、操作の前提条件が満たされていないことを意味します。この場合、前提条件は画像生成APIを使用するためにBillingが有効になっていなければならないということです。
レスポンスにFAILED_PRECONDITIONが表示された場合、修正は常にGCPコンソールでBillingを有効にすることであり、APIパラメータを調整することではありません。このエラーはresponseModalitiesやimageConfigを変更しても解決されません。
サイレントに失敗するパラメータ:imageConfigとresponseModalities

パラメータの失敗はGemini画像APIの特別なカテゴリの問題です。APIはリクエストを文句なしに受け付け、画像を生成して返しますが、画像が仕様と一致しません。2K解像度を要求したのに512pxが返ってきた。アスペクト比を設定したのに1:1になった。imageConfigを設定したが効果がなかった。APIはパラメータを拒否せず、単に無視しただけです。
image_sizeの大文字小文字の罠
imageConfig内のimage_sizeパラメータは非自明な方法で大文字小文字を区別します。有効な値は大文字の「K」を使用します。"512"、"1K"、"2K"、"4K"。小文字の"1k"を使用してもエラーは発生しません。デフォルトの解像度(512px)にサイレントにフォールバックします。つまり、正しく見えるコードを書いてテストしても、解像度設定が無視されていることに気づかない可能性があります。
この特定の問題は公式のGemini APIドキュメント(ai.google.dev、2026-03-16確認済み)に対して検証されています。この罠は、文字列値が大文字小文字を区別しない小文字規約の言語やAPIから来た開発者にとって特に危険です。"1k"が無効だったことについてレスポンスに警告はありません。画像が予想より小さく出力されるだけです。
有効なimage_sizeの値の完全なリスト:"512"、"1K"、"2K"、"4K"。アスペクト比パラメータ(aspect_ratio)は"1:1"、"3:4"、"4:3"、"9:16"、"16:9"を受け付けます。これらは大文字小文字を区別せず、コロン表記を使用します。
responseModalitiesにTEXTが必要な理由
サイレント失敗のセクションで述べたように、responseModalitiesには"TEXT"と"IMAGE"の両方を含める必要があります。しかし、パラメータの順序に関する追加のニュアンスがあります。responseModalities配列は"TEXT"を最初に、"IMAGE"を2番目にリストするべきです。APIは現在どちらの順序も受け付けますが、ドキュメントに記載されている順序は["TEXT", "IMAGE"]であり、これから逸脱すると将来のAPIバージョンで問題が発生する可能性があります。小さなことですが、本番コードはドキュメントの規約に従うべきです。
python"responseModalities": ["TEXT", "IMAGE"] # Accepted but not recommended "responseModalities": ["IMAGE", "TEXT"] # WRONG - silently returns empty response "responseModalities": ["IMAGE"] # WRONG - no images even requested "responseModalities": ["TEXT"]
ミドルウェアによるimageConfigの除去
これは最も微妙なパラメータ失敗モードです。LiteLLMのようなミドルウェアレイヤーを使用してGemini API呼び出しをプロキシする場合、imageConfigパラメータはGemini APIに到達する前にリクエストから除去されることがよくあります。LiteLLM GitHubのissue #18656がこの動作を記録しています。LiteLLMはパラメータを内部フォーマットに正規化し、imageConfigはこの正規化を通り抜けられません。
症状:画像は生成されますが、解像度とアスペクト比の設定が効果を持ちません。修正方法はGemini画像生成のためにミドルウェアをバイパスし、ネイティブHTTP APIを直接使用することです。インフラにLiteLLMや類似ツールを使用しなければならない場合は、テキスト生成をミドルウェアを通してルーティングしながら、画像生成リクエストを直接ルーティングする必要があります。
ミドルウェアをバイパスしてAPIを直接呼び出す方法を以下に示します。
pythonimport requests import base64 def generate_image_direct(prompt: str, api_key: str, size: str = "1K") -> bytes: """Direct HTTP call to Gemini Image API — bypasses middleware.""" url = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-flash-image-preview:generateContent" headers = {"Content-Type": "application/json"} params = {"key": api_key} payload = { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], "imageConfig": { "image_size": size, # Must be "512", "1K", "2K", or "4K" "aspect_ratio": "16:9" # Optional } } } response = requests.post(url, json=payload, headers=headers, params=params) response.raise_for_status() data = response.json() for part in data["candidates"][0]["content"]["parts"]: if "inlineData" in part: return base64.b64decode(part["inlineData"]["data"]) raise ValueError("No image data in response — check responseModalities config")
generationConfigがネイティブHTTPペイロードでimageConfigをラップすることに注意してください。一部のSDKバージョンはフラットなgeneration_config辞書を使用しますが、ネイティブREST APIは上記のネスト構造を使用します。これもパラメータの混乱のもう一つの原因です。SDKインターフェースは常に基礎となるHTTPリクエスト構造と一致するわけではありません。
クォータの確認:GCPコンソール診断ガイド
クォータの状況を理解することは429エラーの診断に不可欠ですが、多くの開発者は正確なクォータ情報の場所や数値の意味を知りません。GCPコンソールに権威あるデータがありますが、そこへのナビゲーションは明白ではありません。
画像生成クォータの見つけ方
GCPコンソールでの正確なナビゲーションパス(2026-03-16確認済み):
- console.cloud.google.comにアクセス
- 上部のドロップダウンからプロジェクトを選択
- APIとサービス → Generative Language APIに移動
- 左サイドバーのクォータとシステム制限をクリック
- フィルターバーに「image」と入力して画像固有のクォータをフィルタリング
クォータビューには複数の次元が表示されます。画像生成で重要なのはIPM(Images Per Minute)です。Gemini画像生成はこの次元に対してスロットリングされます。RPM(Requests Per Minute)と混同しないでください。RPMはテキスト生成呼び出しを管理し、画像API呼び出しの拘束制約ではありません。
クォータ次元の理解
Gemini画像モデルには3つのクォータ次元があります:
| 次元 | 制限の対象 | 典型的なスコープ |
|---|---|---|
| RPM(Requests Per Minute) | 1分あたりのAPI呼び出し数 | テキストモデルと共有 |
| RPD(Requests Per Day) | 1日あたりのAPI呼び出し数 | プレビューモデル:1,500/日 |
| IPM(Images Per Minute) | 1分あたりに生成される画像数 | 画像固有;最も重要 |
2025年12月7日以降、無料ティアのIPMは0です。つまり、無料アカウントはAPIを通じて画像を生成できません。これは以前の無料ティアから変更されたもので、以前は限られた画像生成が許可されていました。この日付より前にアップグレードしてグランドファザーされたクォータを持っている場合、GCPコンソールは現在の許容量を表示します。2025年12月7日以降にアカウントを作成したか、最初にAPIを有効にした場合、Billingを有効にするまでIPMは0になります。
Paid Tier 1アカウント(Billing有効、Tier 2のしきい値以下)については、SERPアナリシスからの検証済みデータ(wentuo.ai、Firebaseドキュメント、2026-03-16)が約10 IPMを示しています。Paid Tier 2(より高い使用量)は約20 IPMを提供します。プロビジョンドスループットを持つVertex AIはGoogleと交渉した専用クォータを提供し、共有プールの制約を取り除きます。
クォータダッシュボードの解釈
クォータダッシュボードは制限に対するパーセンテージとして現在の使用量を表示します。「100%」の読み取りはその時間ウィンドウの制限に達したことを意味します。重要:クォータリセットはローリングウィンドウで、固定のクロック分ではありません。IPMクォータはローリング60秒ウィンドウで計算されます。つまり、12:00:00に10枚の画像を生成してPaid Tier 1(10 IPM制限)にいる場合、12:01:00まで追加の生成はできません。
クォータが0%なのにまだ429が発生している場合、それはGhost 429バグ(第2章の根本原因3)または最近のBilling変更後のクォータ伝播問題の強い診断シグナルです。その場合、クォータ変更が伝播するまで15〜30分待ち、数時間後も問題が続く場合は第2章のGhost 429のガイダンスを確認してください。
Gemini画像生成に適したティアの選択
使用するティアはコストと信頼性の両方に大きな影響を与えます。特に本番アプリケーションでは重要です。トレードオフを理解することで、本番負荷での制限を発見するのではなく、適切なインフラの決定を下すことができます。
| ティア | IPM | RPM | RPD | 最適な用途 |
|---|---|---|---|---|
| 無料 | 0 | 10 | 1,500 | 学習のみ(画像なし) |
| Paid Tier 1 | ~10 | 10 | 1,500 | 軽い本番使用 |
| Paid Tier 2 | ~20 | 20+ | 3,000+ | 中程度の本番 |
| Vertex AI | 交渉済み | 交渉済み | 交渉済み | 大量の本番 |
プレビューモデルと本番モデル
gemini-3.1-flash-image-previewとgemini-3-pro-image-previewモデルはプレビューモデルです。Dynamic Shared Quotaで動作し、本番モデルと同じ信頼性保証を提供しません。Gemini画像生成機能のうち、この執筆時点で安定版(非プレビュー)モデルはgemini-2.5-flash-imageのみです。
本番ユースケースでは、これが2つの点で重要です。まず、プレビューモデルの429はあなたが個人クォータ内にいても発生する可能性があります。グローバルな輻輳を反映しているだけで、あなたの使用量ではありません。次に、プレビューモデルは本番モデルが受ける完全な廃止通知なしに変更されたり廃止されたりする可能性があります。数ヶ月間信頼性高く動作する必要があるものを構築している場合、わずかに異なる機能を持つとしても、安定版モデルがより良い基盤です。プレビューモデルが提供するものの完全な説明については、Gemini 3.1 Flash Image Previewモデルの機能ガイドを参照してください。
代替APIプロバイダーの検討時期
AI Studioのティアが提供するよりも高いスループットが必要だが、完全なVertex AI統合を設定する準備ができていない場合、laozhang.aiのようなサードパーティAPIアグリゲーターは異なるレート制限構造でGemini画像モデルを提供しています。これらは開発、テスト、またはピーク使用時のプライマリAPIアクセスの補完に役立ちます。アグリゲーターアプローチはネットワークホップを追加し、重要なアプリケーションのプライマリ本番インフラであるべきではありませんが、プライマリクォータが枯渇した場合のフォールバックとして役立ちます。
本番規模の画像生成には、プロビジョンドスループットを持つVertex AIが正しい長期的なソリューションです。共有プールクォータで他のユーザーと競争するのではなく、専用の容量を交渉できます。
プロダクション対応エラーハンドリングコード
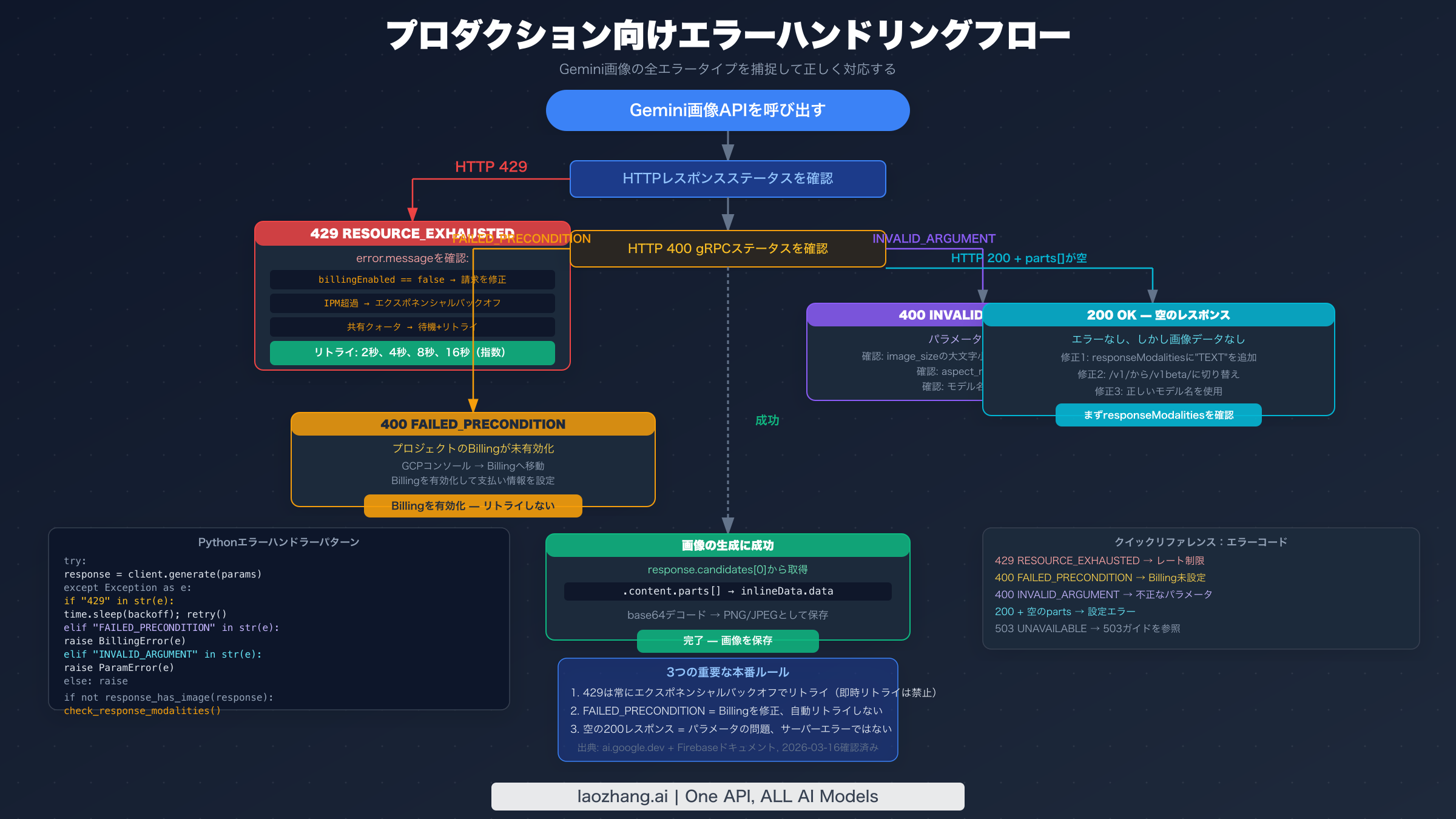
プロダクションのGemini画像生成は、3つのエラーカテゴリすべてを系統的に処理する必要があります。以下のコードは、適切なエラー分類、エクスポネンシャルバックオフ、パラメータ検証、空レスポンス検出を含む完全なPython実装を提供します。
pythonimport time import base64 import requests from typing import Optional from dataclasses import dataclass # Valid parameter constants (from official docs, verified 2026-03-16) VALID_IMAGE_SIZES = {"512", "1K", "2K", "4K"} VALID_ASPECT_RATIOS = {"1:1", "3:4", "4:3", "9:16", "16:9"} GEMINI_IMAGE_ENDPOINT = ( "https://generativelanguage.googleapis.com/v1beta/models/" "{model}:generateContent" ) @dataclass class ImageGenerationError(Exception): """Base class for Gemini image generation errors.""" message: str error_type: str # "rate_limit", "billing", "parameter", "empty_response" retryable: bool def validate_image_config(image_size: str, aspect_ratio: Optional[str] = None): """Validate imageConfig parameters before API call.""" if image_size not in VALID_IMAGE_SIZES: raise ImageGenerationError( message=f"Invalid image_size '{image_size}'. Valid values: {VALID_IMAGE_SIZES}. " f"Note: case-sensitive — use '1K' not '1k'.", error_type="parameter", retryable=False ) if aspect_ratio and aspect_ratio not in VALID_ASPECT_RATIOS: raise ImageGenerationError( message=f"Invalid aspect_ratio '{aspect_ratio}'. Valid: {VALID_ASPECT_RATIOS}", error_type="parameter", retryable=False ) def classify_error(response_or_exception) -> ImageGenerationError: """Classify API error into actionable categories.""" if isinstance(response_or_exception, requests.Response): status = response_or_exception.status_code try: body = response_or_exception.json() error_msg = str(body.get("error", {}).get("message", "")) grpc_status = body.get("error", {}).get("status", "") except Exception: error_msg = response_or_exception.text grpc_status = "" else: error_msg = str(response_or_exception) status = 500 grpc_status = "" if status == 429 or "RESOURCE_EXHAUSTED" in grpc_status: return ImageGenerationError( message=f"Rate limit exceeded: {error_msg}", error_type="rate_limit", retryable=True ) elif "FAILED_PRECONDITION" in grpc_status or "billing" in error_msg.lower(): return ImageGenerationError( message="Billing not enabled. Enable billing in GCP Console.", error_type="billing", retryable=False # Retrying won't help — fix billing first ) elif "INVALID_ARGUMENT" in grpc_status or status == 400: return ImageGenerationError( message=f"Invalid parameter: {error_msg}", error_type="parameter", retryable=False ) else: return ImageGenerationError( message=f"Unexpected error ({status}): {error_msg}", error_type="unknown", retryable=False ) def generate_image( prompt: str, api_key: str, model: str = "gemini-3.1-flash-image-preview", image_size: str = "1K", aspect_ratio: Optional[str] = None, max_retries: int = 5, initial_backoff: float = 2.0 ) -> bytes: """ Generate image with full error handling. Returns raw image bytes (PNG format). Raises ImageGenerationError with retryable flag for caller to handle. """ # Validate parameters before making API call validate_image_config(image_size, aspect_ratio) url = GEMINI_IMAGE_ENDPOINT.format(model=model) headers = {"Content-Type": "application/json"} params = {"key": api_key} image_config = {"image_size": image_size} if aspect_ratio: image_config["aspect_ratio"] = aspect_ratio payload = { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["TEXT", "IMAGE"], # Both required "imageConfig": image_config } } last_error = None for attempt in range(max_retries): try: response = requests.post( url, json=payload, headers=headers, params=params, timeout=60 ) if not response.ok: error = classify_error(response) if not error.retryable: raise error last_error = error backoff = initial_backoff * (2 ** attempt) print(f"Attempt {attempt + 1}: {error.error_type}, retrying in {backoff}s") time.sleep(backoff) continue # HTTP 200 — check for actual image data data = response.json() candidates = data.get("candidates", []) if not candidates: raise ImageGenerationError( message="No candidates in response. Check model name and quota.", error_type="empty_response", retryable=False ) parts = candidates[0].get("content", {}).get("parts", []) for part in parts: if "inlineData" in part: return base64.b64decode(part["inlineData"]["data"]) # 200 OK but no image data — common config error raise ImageGenerationError( message=( "HTTP 200 but no image in response. " "Verify responseModalities includes both 'TEXT' and 'IMAGE'. " "Check you're using /v1beta/ endpoint." ), error_type="empty_response", retryable=False ) except ImageGenerationError: raise # Don't retry non-retryable errors except requests.RequestException as e: last_error = classify_error(e) if attempt < max_retries - 1: backoff = initial_backoff * (2 ** attempt) time.sleep(backoff) raise last_error or ImageGenerationError( message="Max retries exceeded", error_type="rate_limit", retryable=True ) # Usage example if __name__ == "__main__": try: image_bytes = generate_image( prompt="A serene mountain lake at sunset", api_key="YOUR_API_KEY", model="gemini-3.1-flash-image-preview", image_size="1K", aspect_ratio="16:9" ) with open("output.png", "wb") as f: f.write(image_bytes) print("Image saved to output.png") except ImageGenerationError as e: print(f"Error type: {e.error_type}") print(f"Message: {e.message}") print(f"Retryable: {e.retryable}") if e.error_type == "billing": print("Action: Enable billing at console.cloud.google.com/billing") elif e.error_type == "parameter": print("Action: Fix parameters — check image_size casing and aspect_ratio format") elif e.error_type == "empty_response": print("Action: Add 'TEXT' to responseModalities and verify /v1beta/ endpoint")
JavaScript/Node.jsバージョン
javascriptconst fetch = require('node-fetch'); const VALID_IMAGE_SIZES = new Set(['512', '1K', '2K', '4K']); async function generateImage(prompt, apiKey, options = {}) { const { model = 'gemini-3.1-flash-image-preview', imageSize = '1K', aspectRatio = null, maxRetries = 5, } = options; if (!VALID_IMAGE_SIZES.has(imageSize)) { throw new Error(`Invalid imageSize '${imageSize}'. Use: ${[...VALID_IMAGE_SIZES].join(', ')}`); } const url = `https://generativelanguage.googleapis.com/v1beta/models/${model}:generateContent?key=${apiKey}`; const imageConfig = { image_size: imageSize }; if (aspectRatio) imageConfig.aspect_ratio = aspectRatio; const payload = { contents: [{ parts: [{ text: prompt }] }], generationConfig: { responseModalities: ['TEXT', 'IMAGE'], imageConfig, }, }; for (let attempt = 0; attempt < maxRetries; attempt++) { const response = await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload), }); if (response.status === 429) { if (attempt === maxRetries - 1) throw new Error('Max retries exceeded (429)'); const delay = Math.pow(2, attempt + 1) * 1000; await new Promise(r => setTimeout(r, delay)); continue; } if (!response.ok) { const body = await response.json(); const status = body?.error?.status || ''; if (status === 'FAILED_PRECONDITION') { throw new Error('Billing not enabled. Enable billing in GCP Console.'); } throw new Error(`API error ${response.status}: ${JSON.stringify(body?.error)}`); } const data = await response.json(); const parts = data?.candidates?.[0]?.content?.parts || []; const imagePart = parts.find(p => p.inlineData); if (!imagePart) { throw new Error( 'HTTP 200 but no image data. Check responseModalities includes TEXT and IMAGE.' ); } return Buffer.from(imagePart.inlineData.data, 'base64'); } }
複数のモデルとフォールバック戦略を処理する必要がある高並行の本番シナリオでは、laozhang.aiの画像エンドポイントのようなAPIアグリゲーターをプライマリクォータが枯渇した場合のフォールバックとして使用できます。アグリゲーターはレート制限を内部的に処理するため、プライマリAPIがスロットリングされている場合のエラーハンドリングコードが簡素化されます。
よくある質問
GeminiイメージAPI呼び出しがHTTP 200を返すのに画像がない理由は?
最も一般的な原因はresponseModalitiesが["TEXT", "IMAGE"]ではなく["IMAGE"]に設定されていることです。Gemini画像APIはTEXTとIMAGEの両方のモダリティを必要とします。TEXTを省略するとAPIはエラーなしで空のレスポンスを返します。generationConfigを確認して両方の値が含まれていることを確認してください。それが正しい場合は、/v1/やOpenAI互換エンドポイントではなく/v1beta/エンドポイントを使用していることを確認してください。
有料プランにアップグレードした後もGemini画像API 429エラーが続く場合の修正方法は?
まずアップグレードからどのくらい経つかを確認してください。過去24〜48時間以内の場合、Ghost 429バグ(2026年2月の既知の問題で、新しいBillingの有効化がすぐにクォータを伝播しない)の影響を受けている可能性があります。一時的に別のモデルバリアントに切り替えてみてください。GCPコンソールに非ゼロのクォータが表示されているのに48時間以上429が続く場合は、クォータ伝播問題を参照してサポートチケットを提出してください。また、GCPコンソールでIPM(Images Per Minute)クォータが実際に非ゼロであることを確認してください。Billingを有効にしても、自動的に画像クォータが非ゼロ値に設定されるわけではありません。
imageConfig設定が無視される理由は?
2つの一般的な原因:大文字小文字の区別またはミドルウェアの除去。大文字小文字の区別については、image_size値が大文字のKを使用していることを確認してください("1k"ではなく"1K")。ミドルウェアの除去については、LiteLLMや類似のプロキシレイヤーを通してルーティングしている場合、imageConfigがGemini APIに到達する前に除去される可能性があります。修正方法はプロキシを通さずに画像生成のためにGemini APIに直接HTTPを呼び出すことです。
GeminiイメージモデルのIPMとRPMクォータの違いは?
RPM(Requests Per Minute)は1分あたりに行えるAPI呼び出し数を制限し、すべてのGeminiモデルに適用されます。IPM(Images Per Minute)は画像固有で、1分あたりに生成できる個々の画像数を制限します。1回のAPI呼び出しでnumberOfImagesが1より大きく設定されている場合、複数の画像を生成できます。各画像は個別にIPMクォータにカウントされます。IPMクォータは通常、画像生成の拘束制約です。ほとんどの使用パターンでRPMより前にIPMに達します。
Geminiのプレビューイメージモデルを本番で使用しても安全か?
プレビューモデル(gemini-3.1-flash-image-preview、gemini-3-pro-image-preview)はDynamic Shared Quotaを使用するため、個人クォータ制限内にいても、グローバルな輻輳のために429エラーを返すことがあります。開発および軽い本番使用には問題ありませんが、SLA要件のあるアプリケーションには安定版のgemini-2.5-flash-imageモデルまたはプロビジョンドスループットを持つVertex AIを使用してください。プレビューモデルは本番モデルより少ない通知で変更または廃止される可能性もあります。
結論と次のステップ
Gemini画像APIエラーは、異なる問題が見た目に同じ症状を生成するため、本当に混乱しやすいです。429は無料ティアのゼロクォータ、有料クォータの枯渇、既知のバグ、またはグローバルな輻輳を意味する可能性があり、それぞれのシナリオにはまったく異なる対応が必要です。空のHTTP 200はパラメータの設定ミス、誤ったエンドポイント、またはミドルウェアの干渉を意味する可能性があります。
すべてのエラータイプで機能する診断シーケンス:まずBillingを確認(GCPコンソール → APIとサービス → Generative Language API → クォータ)、次にパラメータを確認(responseModalities: ["TEXT", "IMAGE"]、image_size: "1K" 大文字)、次にエンドポイントを確認(/v1/ではなく/v1beta/)。ほとんどの問題はこれら3つのチェックポイントのいずれかで解決します。
本番アプリケーションの場合は、最初からコードにエラー分類を組み込んでください。リトライ可能な429を、リトライできないBillingエラーやパラメータエラーと区別することで、後の運用上の問題を節約できます。第7章の完全なコード例は、このような分類をすぐに使える形で提供しています。
クォータ制限に一貫して当たっており、Vertex AIプロビジョニングの複雑さなしにより多くのスループットが必要な場合は、IPM制限内に収まるようにバッチ生成戦略を見直すか、Tier 2クォータのしきい値が要件を満たしているかを調べることを検討してください。クォータ構造は使用量に応じてスケールするように設計されています。制限として始まるものも、ワークロードの拘束制約となる次元を理解すれば管理可能になります。